
 Périphériques technologiques
IA
Publication d'un ensemble de données de référence sur le tri des paragraphes chinois : basé sur 300 000 requêtes réelles et 2 millions de paragraphes Internet.
Périphériques technologiques
IA
Publication d'un ensemble de données de référence sur le tri des paragraphes chinois : basé sur 300 000 requêtes réelles et 2 millions de paragraphes Internet.
Publication d'un ensemble de données de référence sur le tri des paragraphes chinois : basé sur 300 000 requêtes réelles et 2 millions de paragraphes Internet.

Le tri des paragraphes est un sujet très important et stimulant dans le domaine de la recherche d'informations, et a reçu une large attention de la part du monde universitaire et de l'industrie. L'efficacité du modèle de classement des paragraphes peut améliorer la satisfaction des utilisateurs des moteurs de recherche et aider les applications liées à la recherche d'informations telles que les systèmes de questions et réponses, la compréhension écrite, etc. Dans ce contexte, certains ensembles de données de référence tels que MS-MARCO, DuReader_retrieval, etc. ont été construits pour soutenir les travaux de recherche connexes sur le tri des paragraphes. Cependant, la plupart des ensembles de données couramment utilisés se concentrent sur les scènes anglaises. Pour les scènes chinoises, les ensembles de données existants présentent des limites en termes d'échelle de données, d'annotation fine par l'utilisateur et de solution au problème des exemples faux négatifs. Dans ce contexte, nous avons construit un nouvel ensemble de données de référence pour le classement des paragraphes chinois basé sur des journaux de recherche réels : T2Ranking.
T2Le classement comprend plus de 300 000 requêtes réelles et 2 millions de paragraphes Internet, et contient des annotations de pertinence fines à 4 niveaux fournies par des annotateurs professionnels. Les données actuelles et certains modèles de base ont été publiés sur Github, et les travaux de recherche pertinents ont été acceptés par SIGIR 2023 en tant que document ressource.
- Informations papier : Xiaohui Xie, Qian Dong, Bingning Wang, Feiyang Lv, Ting Yao, Weinan Gan, Zhijing Wu, Xiangsheng Li, Haitao Li, Yiqun Liu et Jin Ma. : Un benchmark chinois à grande échelle .
- Adresse papier : https://arxiv.org/abs/2304.03679
- Adresse Github : https://github.com/THUIR/. T2Ranking
Contexte et travaux connexes
L'objectif de la tâche de classement des paragraphes est de rappeler et de trier les paragraphes candidats d'une collection de paragraphes à grande échelle en fonction d'un terme de requête donné, et d'obtenir les paragraphes par ordre décroissant. liste de pertinence. Le tri des paragraphes comprend généralement deux étapes : le rappel des paragraphes et la réorganisation des paragraphes.
Pour prendre en charge la tâche de tri des paragraphes, plusieurs ensembles de données sont construits pour entraîner et tester les algorithmes de tri des paragraphes. La plupart des ensembles de données largement utilisés se concentrent sur les scènes anglaises. Par exemple, l'ensemble de données le plus couramment utilisé est l'ensemble de données MS-MARCO, qui contient plus de 500 000 termes de requête et plus de 8 millions de paragraphes. Pour chaque terme de requête, l'équipe de publication des données MS-MARCO a recruté des annotateurs pour fournir des réponses standard. En fonction du fait qu'un paragraphe donné contient les réponses standard fournies manuellement, il est jugé si ce paragraphe est lié au terme de requête.
Dans le scénario chinois, certains ensembles de données sont également conçus pour prendre en charge les tâches de tri de paragraphes. Par exemple, mMarco-Chinese est la version de traduction chinoise de l'ensemble de données MS-MARCO, et l'ensemble de données DuReader_retrieval utilise le même paradigme que MS-MARCO pour générer des étiquettes de paragraphe, c'est-à-dire que la corrélation de la paire mot-paragraphe de requête est donné à partir des réponses standards fournies par les humains. Le modèle Multi-CPR contient des données de récupération de paragraphes provenant de trois domaines différents (commerce électronique, vidéos de divertissement et médecine). Sur la base des données de journal de recherche Sogou, des ensembles de données tels que Sogou-SRR, Sogou-QCL et Tiangong-PDR ont également été proposés.
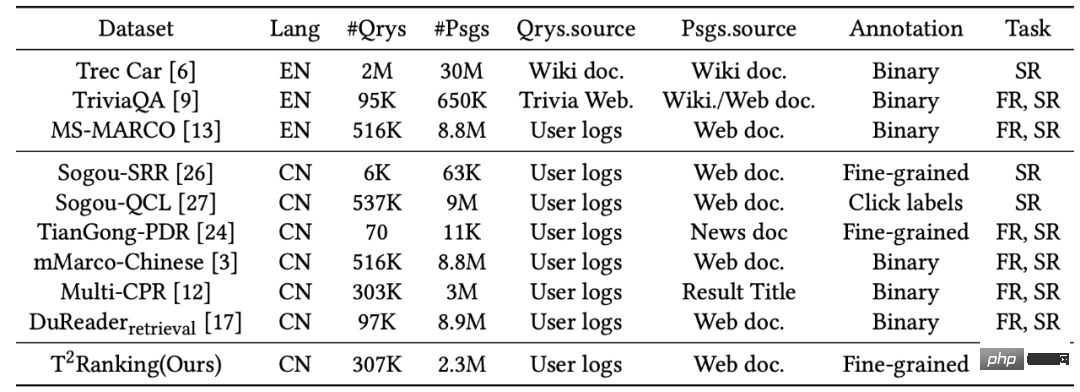
Figure 1 : Statistiques des ensembles de données couramment utilisés dans les tâches de tri de paragraphes
Bien que les ensembles de données existants aient favorisé le développement d'applications de tri de paragraphes, nous devons également prêter attention à plusieurs limitations :
1) Ces ensembles de données ne sont pas à grande échelle ou les étiquettes de pertinence ne sont pas annotées manuellement, notamment dans le scénario chinois. Sogou-SRR et Tiangong-PDR ne contiennent qu'une petite quantité de données de requête. Bien que mMarco-Chinese et Sogou-QCL soient à plus grande échelle, le premier est basé sur la traduction automatique et le second utilise des étiquettes de pertinence comme données de clic de l'utilisateur. Récemment, deux ensembles de données relativement volumineux, Multi-CPR et DuReader_retrieval, ont été construits et publiés.
2) Les ensembles de données existants manquent d'informations d'annotation de corrélation fine. La plupart des ensembles de données utilisent une annotation de corrélation binaire (à gros grain), c'est-à-dire pertinente ou non. Les travaux existants ont montré que les informations d'annotation de corrélation fine peuvent aider à explorer les relations entre différentes entités et à créer des algorithmes de classement plus précis. Ensuite, il existe des ensembles de données existants qui ne fournissent pas ou ne fournissent qu'une petite quantité d'annotations fines à plusieurs niveaux. Par exemple, Sogou-SRR ou Tiangong-PDR ne fournissent que 100 000 annotations fines.
3) Le problème des exemples faux négatifs affecte la précision de l'évaluation. Les ensembles de données existants sont affectés par le problème des exemples de faux négatifs, où un grand nombre de documents pertinents sont marqués comme non pertinents. Ce problème est dû au petit nombre d’annotations manuelles dans les données à grande échelle, ce qui affectera considérablement la précision de l’évaluation. Par exemple, dans Multi-CPR, un seul paragraphe sera marqué comme pertinent pour chaque terme de requête, tandis que les autres seront marqués comme non pertinents. DuReader_retrieval tente d'atténuer le problème des faux négatifs en laissant l'annotateur inspecter et réannoter manuellement l'ensemble de paragraphes supérieur.
Afin de mieux prendre en charge les modèles de classement de paragraphes pour une formation et une évaluation de haute qualité, nous avons créé et publié un nouvel ensemble de données de référence pour la récupération de paragraphes chinois - T2Ranking.
Processus de construction d'ensembles de données
Le processus de construction d'ensembles de données comprend l'échantillonnage de mots de requête, le rappel de documents, l'extraction de paragraphes et l'annotation de pertinence fine. Dans le même temps, nous avons également conçu plusieurs méthodes pour améliorer la qualité de l'ensemble de données, notamment en utilisant des méthodes de segmentation de paragraphe basées sur un modèle et des méthodes de déduplication de paragraphe basées sur le clustering pour garantir l'intégrité sémantique et la diversité des paragraphes, et en utilisant l'apprentissage actif. annotation basée sur des méthodes pour améliorer l’efficacité et la qualité de l’annotation, etc.
1) Processus global
- Échantillonnage de mots de requête : Nous avons échantillonné les mots de requête soumis par des utilisateurs réels à partir des journaux de recherche du moteur de recherche Sogou et avons obtenu la requête initiale après déduplication et normalisation de la collecte de mots. Ensuite, nous utilisons l'algorithme d'analyse d'intention pour supprimer les requêtes pornographiques, les requêtes sans questions, les requêtes d'application de ressources et les requêtes pouvant contenir des informations utilisateur, garantissant ainsi que l'ensemble de données de requête final ne contient que des requêtes de haute qualité avec des attributs de question.
- Rappel de documents : sur la base des termes de requête échantillonnés, nous rappelons des ensembles de documents candidats de plusieurs moteurs de recherche grand public tels que Sogou, Baidu et Google, intégrant pleinement les capacités de ces moteurs de recherche dans l'indexation et le tri des documents. Étant donné que ces moteurs de recherche sont capables de couvrir différentes parties des données Internet et de renvoyer divers résultats de documents, ils peuvent améliorer l'exhaustivité de l'ensemble des documents candidats et atténuer dans une certaine mesure le problème des faux négatifs.
- Extraction de paragraphe : l'étape d'extraction de paragraphe implique la segmentation et la déduplication des paragraphes. Au lieu d'utiliser des méthodes heuristiques pour segmenter les paragraphes dans des documents (comme déterminer conventionnellement le début et la fin d'un paragraphe par des sauts de ligne), nous formons un modèle sémantique de paragraphe pour effectuer une segmentation de paragraphe afin de garantir autant que possible l'intégrité sémantique de chaque paragraphe. De plus, nous introduisons également une technologie basée sur le clustering pour améliorer l'efficacité de l'annotation et garantir la diversité des paragraphes annotés. Cette technologie peut supprimer efficacement les paragraphes très similaires.
- Annotation de corrélation fine : les annotateurs embauchés sont des experts dans la recherche de tâches d'annotation pertinentes et sont engagés dans le travail d'annotation depuis longtemps. Pour chaque paire requête-paragraphe, au moins 3 annotateurs fournissent des annotations. Si les résultats d'annotation des trois annotateurs sont incohérents, nous introduisons des annotateurs supplémentaires pour l'annotation. Si les résultats des quatre annotateurs sont incohérents, nous avons tendance à penser que la paire mot-paragraphe de requête est trop vague, de mauvaise qualité et incohérente. trop capable de déterminer les informations requises, excluant ainsi la paire terme de requête-paragraphe de l'ensemble de données. Nous déterminons le label de pertinence final par vote majoritaire. La ligne directrice d'annotation de pertinence à 4 niveaux que nous adoptons est cohérente avec le benchmark TREC.
- Niveau 0 : Il n'y a aucune corrélation entre le terme de requête et le contenu du paragraphe
- Niveau 1 : Le contenu du paragraphe est lié au terme de requête, mais ne répond pas aux exigences d'information du terme de requête
- Niveau 2 : Contenu du paragraphe et mot de requête lié, peut répondre partiellement aux besoins d'information du mot de requête
- Niveau 3 : Le contenu du paragraphe peut répondre pleinement aux besoins d'information du mot de requête et contient des réponses précises.
Figure 2 : Exemple de page Wikipédia. Le document présenté contient des paragraphes clairement définis.
2) Méthode de segmentation de paragraphe basée sur un modèle
Dans les ensembles de données existants, les paragraphes sont généralement segmentés à partir de documents en fonction de paragraphes naturels (sauts de ligne) ou via des fenêtres coulissantes de longueur fixe. Cependant, les deux méthodes peuvent donner lieu à des paragraphes sémantiquement incomplets ou trop longs et contenant plusieurs sujets différents. Dans ce travail, nous avons adopté une méthode de segmentation de paragraphe basée sur un modèle. Plus précisément, nous avons utilisé l'Encyclopédie Sogou, l'Encyclopédie Baidu et Wikipédia chinois comme données de formation, car la structure de cette partie du document est relativement claire et les paragraphes naturels sont également obtenus. une meilleure définition. Nous avons formé un modèle de segmentation pour déterminer si un mot donné doit être un point de segmentation. Nous avons utilisé l'idée de tâches d'étiquetage de séquence et utilisé le dernier mot de chaque segment naturel comme exemple positif pour entraîner le modèle.
3) Méthode de déduplication de paragraphes basée sur le clustering
Annoter des paragraphes très similaires est redondant et dénué de sens Pour le modèle de classement des paragraphes, un contenu de paragraphe très similaire apporte Le gain d'informations est limité, nous avons donc conçu un clustering-. méthode de déduplication de paragraphe basée sur l'amélioration de l'efficacité de l'annotation. Plus précisément, nous utilisons Ward, un algorithme de clustering hiérarchique, pour effectuer un clustering non supervisé de documents similaires. Les paragraphes de la même classe sont considérés comme très similaires et nous échantillonnons un paragraphe de chaque classe pour une annotation de pertinence. Il est à noter que nous effectuons cette opération uniquement sur l'ensemble d'apprentissage. Pour l'ensemble de test, nous annoterons entièrement tous les paragraphes extraits pour réduire l'impact des exemples faux négatifs.
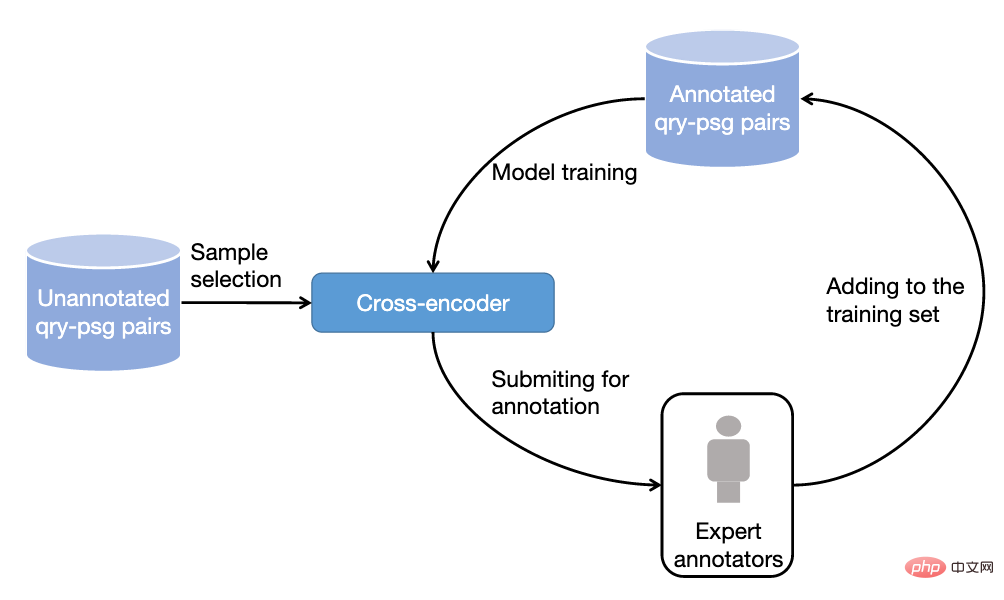
Figure 3 : Processus d'annotation d'échantillonnage basé sur l'apprentissage actif
4) Méthode d'annotation d'échantillonnage de données basée sur l'apprentissage actif
En pratique, nous avons observé que ce n'est pas le cas Tous les échantillons de formation peuvent améliorer encore les performances du modèle de classement. Pour les échantillons d'entraînement que le modèle peut prédire avec précision, l'aide à l'entraînement pour les modèles suivants est limitée. Par conséquent, nous avons emprunté l'idée de l'apprentissage actif pour permettre au modèle de sélectionner des échantillons de formation plus informatifs pour une annotation ultérieure. Plus précisément, nous avons d'abord formé un modèle de réorganisation des mots et des paragraphes de requête basé sur le cadre d'encodeur croisé basé sur les données de formation existantes. Nous avons ensuite utilisé ce modèle pour prédire d'autres données et supprimer les scores de confiance excessifs (contenu de l'information (faible) et également). score de confiance faible (données bruyantes), annotez davantage les paragraphes retenus et répétez ce processus.
Statistiques de l'ensemble de données
T2Le classement comprend plus de 300 000 requêtes réelles et 2 millions de paragraphes Internet. Parmi eux, l'ensemble de formation contient environ 250 000 mots de requête et l'ensemble de test contient environ 50 000 mots de requête. Les termes de requête peuvent comporter jusqu’à 40 caractères, avec une longueur moyenne d’environ 11 caractères. Dans le même temps, les mots de requête dans l'ensemble de données couvrent plusieurs domaines, notamment la médecine, l'éducation, le commerce électronique, etc. Nous avons également calculé le score de diversité (ILS) des mots de requête par rapport aux ensembles de données existants, notre diversité de requêtes. est plus élevé. Plus de 2,3 millions de paragraphes ont été échantillonnés sur 1,75 million de documents, et chaque document a été divisé en 1,3 paragraphe en moyenne. Dans l'ensemble de formation, une moyenne de 6,25 paragraphes par terme de requête ont été annotés manuellement, tandis que dans l'ensemble de test, une moyenne de 15,75 paragraphes par terme de requête ont été annotés manuellement.
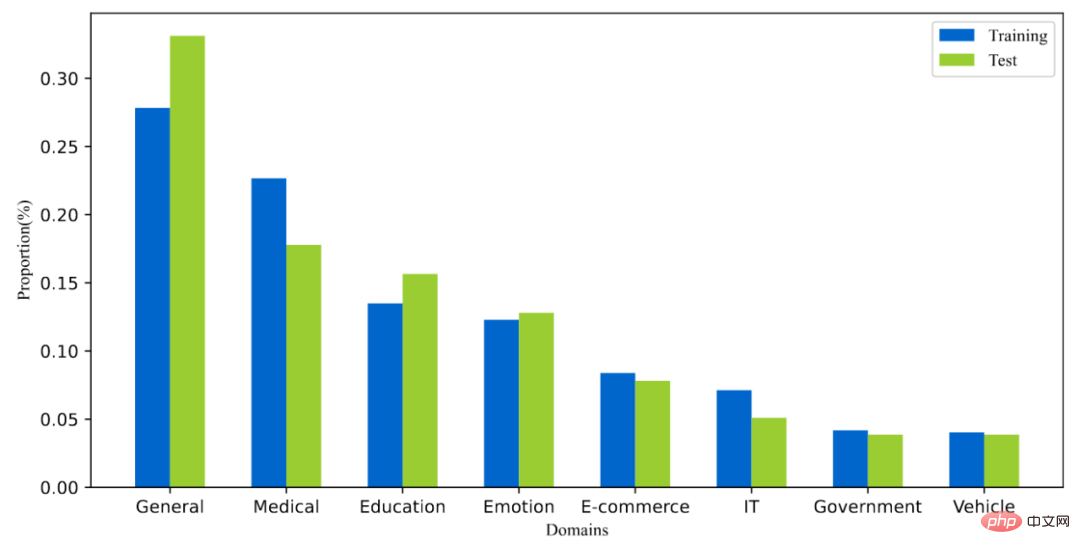
Figure 4 : Répartition des domaines des mots de requête dans l'ensemble de données
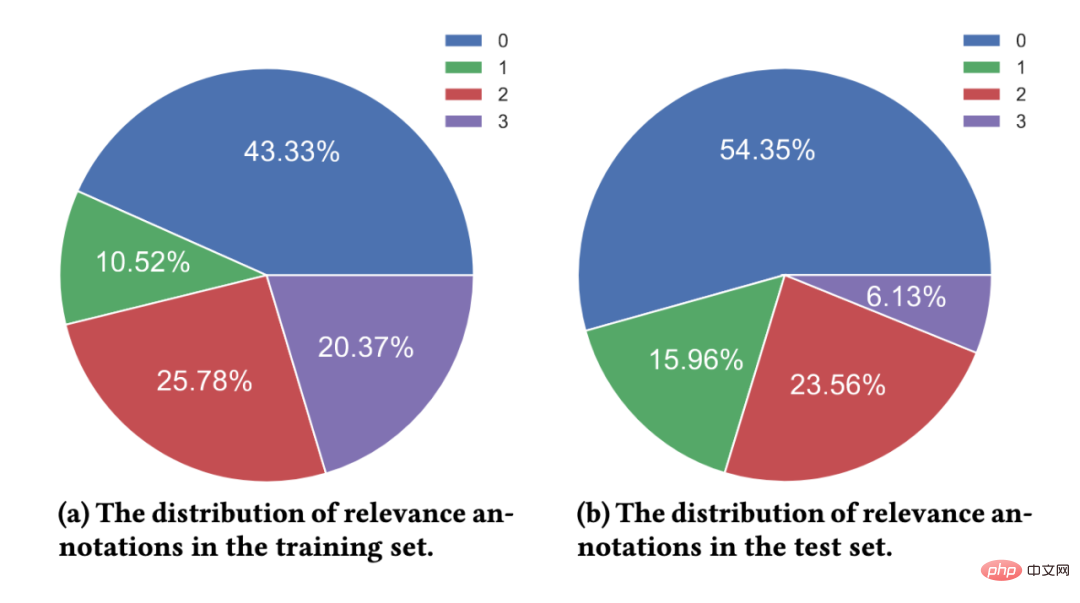
Figure 5 : Répartition des annotations par pertinence
Résultats expérimentaux de modèles couramment utilisés
Nous avons testé les performances de certains modèles de tri de paragraphes couramment utilisés sur l'ensemble de données obtenu. Nous avons également évalué les performances des méthodes existantes dans les deux étapes de rappel de paragraphe et de réorganisation des paragraphes.
1) Expérience de rappel de paragraphe
Les modèles de rappel de paragraphe existants peuvent être grossièrement divisés en modèles de rappel clairsemés et en modèles de rappel denses.
- Les modèles de rappel clairsemés se concentrent sur des signaux de correspondance exacte pour concevoir des fonctions de notation de pertinence. Par exemple, BM25 est le modèle de référence le plus représentatif.
- Le modèle de rappel dense utilise un réseau neuronal profond pour apprendre des vecteurs denses de basse dimension pour représenter les mots et les paragraphes de requête.
Nous avons testé les performances des modèles de rappel suivants :
- QL (vraisemblance de requête) : QL est un modèle de langage statistique représentatif qui évalue la pertinence en fonction de la probabilité qu'un paragraphe génère un terme de requête donné.
- BM25 : un modèle de référence de rappel clairsemé couramment utilisé.
- DE avec BM25 Neg : modèle DPR, structure d'encodeur à double tour (Dual-Encoder), ce modèle est le modèle de rappel du premier paragraphe qui utilise un modèle de langage pré-entraîné comme cadre principal.
- DE w/Mined Neg : structure à double encodeur, qui améliore les performances du modèle DPR en rappelant des exemples négatifs concrets du corpus complet.
- DPTDR : Le modèle de rappel du premier paragraphe utilisant le réglage rapide.
Parmi ces modèles, QL et BM25 sont des modèles à rappel clairsemé, et les autres modèles sont des modèles à rappel dense. Nous utilisons des indicateurs courants tels que MRR et Recall pour évaluer les performances de ces modèles. Les résultats expérimentaux sont présentés dans le tableau suivant :
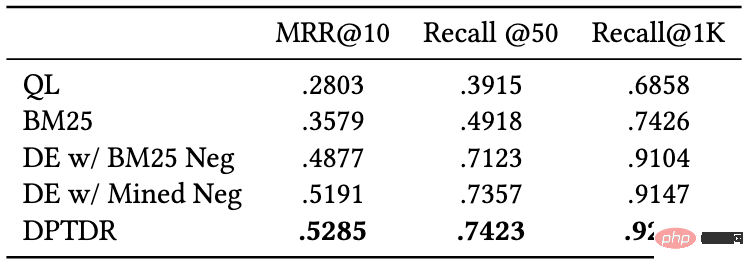
Figure 6 : Performances du modèle de rappel de paragraphe sur l'ensemble de test.
D'après les résultats expérimentaux, on peut voir que par rapport au modèle de tri clairsemé traditionnel, le modèle de récupération dense atteint de meilleures performances. Dans le même temps, l’introduction d’exemples difficiles à négatifs est également utile pour améliorer les performances du modèle. Il convient de mentionner que les performances de rappel de ces modèles expérimentaux sur notre ensemble de données sont pires que celles sur d'autres ensembles de données. Par exemple, le Recall@50 de BM25 sur notre ensemble de données est de 0,492, tandis que dans MS-Marco et Dureader_retrieval ci-dessus sont de 0,601 et 0,700. . Cela peut être dû au fait que davantage de paragraphes ont été annotés manuellement. Dans l'ensemble de tests, nous avons en moyenne 4,74 documents pertinents par terme de requête, ce qui rend la tâche de rappel plus difficile et réduit dans une certaine mesure les faux négatifs. . problème. Cela montre également que T2Ranking constitue un ensemble de données de référence exigeant et qu'il peut encore être amélioré pour les futurs modèles de rappel.
2) Expérience de réorganisation des paragraphes
Par rapport à l'étape de rappel de paragraphe, la taille des paragraphes à prendre en compte dans l'étape de réorganisation est plus petite, donc la plupart des méthodes ont tendance à utiliser un encodeur interactif (Cross-Encoder ) En tant que cadre de modèle, dans ce travail, nous avons testé les performances du modèle d'encodeur interactif sur la tâche de réorganisation des paragraphes. Nous avons utilisé MRR et nDCG comme indicateurs d'évaluation :

. Figure 7 : Performance de l'encodeur interactif sur la tâche de réorganisation des paragraphes
Les résultats expérimentaux montrent que la réorganisation basée sur les paragraphes rappelés par le Dual-Encoder (Dual-Encoder) est plus efficace que la réorganisation basée sur les paragraphes rappelés par BM25 Il peut obtenir de meilleurs résultats, ce qui est cohérent avec les conclusions expérimentales des travaux existants. Semblable à l'expérience de rappel, les performances du modèle de reclassement sur notre ensemble de données sont pires que celles sur d'autres ensembles de données, ce qui peut être dû à l'annotation à granularité fine et à la plus grande diversité de mots de requête de notre ensemble de données, et en outre, cela illustre que notre ensemble de données est un défi et peut refléter plus précisément les performances du modèle.
Présentation de l'équipe de publication de l'ensemble de données
L'ensemble de données a été publié conjointement par le Groupe de recherche sur la recherche d'informations (THUIR) du Département d'informatique de l'Université Tsinghua et l'équipe du Centre technologique de recherche du navigateur QQ de Tencent, et a été soutenu par l'Institut de recherche en informatique intelligente Tiangong de l'Université Tsinghua. Le groupe de recherche THUIR se concentre sur la recherche sur les méthodes de recherche et de recommandation et a obtenu des résultats typiques en matière de modélisation du comportement des utilisateurs et de méthodes d'apprentissage explicables. Les réalisations du groupe de recherche incluent le prix du meilleur article WSDM2022, le prix de nomination du meilleur article SIGIR2020 et le meilleur article CIKM2018 qu'il a remporté. un certain nombre de prix académiques, dont le premier prix 2020 de la Société chinoise de l'information « Prix Qian Weichang chinois des sciences et technologies du traitement de l'information ». L'équipe du QQ Browser Search Technology Center est l'équipe responsable de la recherche et du développement des technologies de recherche de la plate-forme d'information et de la ligne de services Tencent PCG. S'appuyant sur l'écosystème de contenu de Tencent et favorisant l'innovation des produits grâce à la recherche sur les utilisateurs, elle fournit aux utilisateurs des graphiques, des informations, des romans et de longs contenus. et de courtes vidéos, services, etc. Les besoins en informations d'orientation sont satisfaits.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Utilisez ddrescue pour récupérer des données sous Linux
Mar 20, 2024 pm 01:37 PM
Utilisez ddrescue pour récupérer des données sous Linux
Mar 20, 2024 pm 01:37 PM
DDREASE est un outil permettant de récupérer des données à partir de périphériques de fichiers ou de blocs tels que des disques durs, des SSD, des disques RAM, des CD, des DVD et des périphériques de stockage USB. Il copie les données d'un périphérique bloc à un autre, laissant derrière lui les blocs corrompus et ne déplaçant que les bons blocs. ddreasue est un puissant outil de récupération entièrement automatisé car il ne nécessite aucune interruption pendant les opérations de récupération. De plus, grâce au fichier map ddasue, il peut être arrêté et repris à tout moment. Les autres fonctionnalités clés de DDREASE sont les suivantes : Il n'écrase pas les données récupérées mais comble les lacunes en cas de récupération itérative. Cependant, il peut être tronqué si l'outil est invité à le faire explicitement. Récupérer les données de plusieurs fichiers ou blocs en un seul
 Open source! Au-delà de ZoeDepth ! DepthFM : estimation rapide et précise de la profondeur monoculaire !
Apr 03, 2024 pm 12:04 PM
Open source! Au-delà de ZoeDepth ! DepthFM : estimation rapide et précise de la profondeur monoculaire !
Apr 03, 2024 pm 12:04 PM
0. À quoi sert cet article ? Nous proposons DepthFM : un modèle d'estimation de profondeur monoculaire génératif de pointe, polyvalent et rapide. En plus des tâches traditionnelles d'estimation de la profondeur, DepthFM démontre également des capacités de pointe dans les tâches en aval telles que l'inpainting en profondeur. DepthFM est efficace et peut synthétiser des cartes de profondeur en quelques étapes d'inférence. Lisons ce travail ensemble ~ 1. Titre des informations sur l'article : DepthFM : FastMonocularDepthEstimationwithFlowMatching Auteur : MingGui, JohannesS.Fischer, UlrichPrestel, PingchuanMa, Dmytr
 Comment utiliser la fonction de filtre Excel avec plusieurs conditions
Feb 26, 2024 am 10:19 AM
Comment utiliser la fonction de filtre Excel avec plusieurs conditions
Feb 26, 2024 am 10:19 AM
Si vous avez besoin de savoir comment utiliser le filtrage avec plusieurs critères dans Excel, le didacticiel suivant vous guidera à travers les étapes pour vous assurer que vous pouvez filtrer et trier efficacement vos données. La fonction de filtrage d'Excel est très puissante et peut vous aider à extraire les informations dont vous avez besoin à partir de grandes quantités de données. Cette fonction peut filtrer les données en fonction des conditions que vous définissez et afficher uniquement les pièces qui remplissent les conditions, rendant la gestion des données plus efficace. En utilisant la fonction de filtre, vous pouvez trouver rapidement des données cibles, ce qui vous fait gagner du temps dans la recherche et l'organisation des données. Cette fonction peut non seulement être appliquée à de simples listes de données, mais peut également être filtrée en fonction de plusieurs conditions pour vous aider à localiser plus précisément les informations dont vous avez besoin. Dans l’ensemble, la fonction de filtrage d’Excel est très utile
 Google est ravi : les performances de JAX surpassent Pytorch et TensorFlow ! Cela pourrait devenir le choix le plus rapide pour la formation à l'inférence GPU
Apr 01, 2024 pm 07:46 PM
Google est ravi : les performances de JAX surpassent Pytorch et TensorFlow ! Cela pourrait devenir le choix le plus rapide pour la formation à l'inférence GPU
Apr 01, 2024 pm 07:46 PM
Les performances de JAX, promu par Google, ont dépassé celles de Pytorch et TensorFlow lors de récents tests de référence, se classant au premier rang sur 7 indicateurs. Et le test n’a pas été fait sur le TPU présentant les meilleures performances JAX. Bien que parmi les développeurs, Pytorch soit toujours plus populaire que Tensorflow. Mais à l’avenir, des modèles plus volumineux seront peut-être formés et exécutés sur la base de la plate-forme JAX. Modèles Récemment, l'équipe Keras a comparé trois backends (TensorFlow, JAX, PyTorch) avec l'implémentation native de PyTorch et Keras2 avec TensorFlow. Premièrement, ils sélectionnent un ensemble de
 Vitesse Internet lente des données cellulaires sur iPhone : correctifs
May 03, 2024 pm 09:01 PM
Vitesse Internet lente des données cellulaires sur iPhone : correctifs
May 03, 2024 pm 09:01 PM
Vous êtes confronté à un décalage et à une connexion de données mobile lente sur iPhone ? En règle générale, la puissance de l'Internet cellulaire sur votre téléphone dépend de plusieurs facteurs tels que la région, le type de réseau cellulaire, le type d'itinérance, etc. Vous pouvez prendre certaines mesures pour obtenir une connexion Internet cellulaire plus rapide et plus fiable. Correctif 1 – Forcer le redémarrage de l'iPhone Parfois, le redémarrage forcé de votre appareil réinitialise simplement beaucoup de choses, y compris la connexion cellulaire. Étape 1 – Appuyez simplement une fois sur la touche d’augmentation du volume et relâchez-la. Ensuite, appuyez sur la touche de réduction du volume et relâchez-la à nouveau. Étape 2 – La partie suivante du processus consiste à maintenir le bouton sur le côté droit. Laissez l'iPhone finir de redémarrer. Activez les données cellulaires et vérifiez la vitesse du réseau. Vérifiez à nouveau Correctif 2 – Changer le mode de données Bien que la 5G offre de meilleures vitesses de réseau, elle fonctionne mieux lorsque le signal est plus faible
 La vitalité de la super intelligence s'éveille ! Mais avec l'arrivée de l'IA qui se met à jour automatiquement, les mères n'ont plus à se soucier des goulots d'étranglement des données.
Apr 29, 2024 pm 06:55 PM
La vitalité de la super intelligence s'éveille ! Mais avec l'arrivée de l'IA qui se met à jour automatiquement, les mères n'ont plus à se soucier des goulots d'étranglement des données.
Apr 29, 2024 pm 06:55 PM
Je pleure à mort. Le monde construit à la folie de grands modèles. Les données sur Internet ne suffisent pas du tout. Le modèle de formation ressemble à « The Hunger Games », et les chercheurs en IA du monde entier se demandent comment nourrir ces personnes avides de données. Ce problème est particulièrement important dans les tâches multimodales. À une époque où rien ne pouvait être fait, une équipe de start-up du département de l'Université Renmin de Chine a utilisé son propre nouveau modèle pour devenir la première en Chine à faire de « l'auto-alimentation des données générées par le modèle » une réalité. De plus, il s’agit d’une approche à deux volets, du côté compréhension et du côté génération, les deux côtés peuvent générer de nouvelles données multimodales de haute qualité et fournir un retour de données au modèle lui-même. Qu'est-ce qu'un modèle ? Awaker 1.0, un grand modèle multimodal qui vient d'apparaître sur le Forum Zhongguancun. Qui est l'équipe ? Moteur Sophon. Fondé par Gao Yizhao, doctorant à la Hillhouse School of Artificial Intelligence de l’Université Renmin.
 L'US Air Force présente son premier avion de combat IA de grande envergure ! Le ministre a personnellement effectué l'essai routier sans intervenir pendant tout le processus, et 100 000 lignes de code ont été testées 21 fois.
May 07, 2024 pm 05:00 PM
L'US Air Force présente son premier avion de combat IA de grande envergure ! Le ministre a personnellement effectué l'essai routier sans intervenir pendant tout le processus, et 100 000 lignes de code ont été testées 21 fois.
May 07, 2024 pm 05:00 PM
Récemment, le milieu militaire a été submergé par la nouvelle : les avions de combat militaires américains peuvent désormais mener des combats aériens entièrement automatiques grâce à l'IA. Oui, tout récemment, l’avion de combat IA de l’armée américaine a été rendu public pour la première fois, dévoilant ainsi son mystère. Le nom complet de ce chasseur est Variable Stability Simulator Test Aircraft (VISTA). Il a été personnellement piloté par le secrétaire de l'US Air Force pour simuler une bataille aérienne en tête-à-tête. Le 2 mai, le secrétaire de l'US Air Force, Frank Kendall, a décollé à bord d'un X-62AVISTA à la base aérienne d'Edwards. Notez que pendant le vol d'une heure, toutes les actions de vol ont été effectuées de manière autonome par l'IA ! Kendall a déclaré : "Au cours des dernières décennies, nous avons réfléchi au potentiel illimité du combat air-air autonome, mais cela a toujours semblé hors de portée." Mais maintenant,
 Le premier robot capable d'accomplir de manière autonome des tâches humaines apparaît, avec cinq doigts flexibles et rapides, et de grands modèles prennent en charge l'entraînement dans l'espace virtuel
Mar 11, 2024 pm 12:10 PM
Le premier robot capable d'accomplir de manière autonome des tâches humaines apparaît, avec cinq doigts flexibles et rapides, et de grands modèles prennent en charge l'entraînement dans l'espace virtuel
Mar 11, 2024 pm 12:10 PM
Cette semaine, FigureAI, une entreprise de robotique investie par OpenAI, Microsoft, Bezos et Nvidia, a annoncé avoir reçu près de 700 millions de dollars de financement et prévoit de développer un robot humanoïde capable de marcher de manière autonome au cours de la prochaine année. Et l’Optimus Prime de Tesla a reçu à plusieurs reprises de bonnes nouvelles. Personne ne doute que cette année sera celle de l’explosion des robots humanoïdes. SanctuaryAI, une entreprise canadienne de robotique, a récemment lancé un nouveau robot humanoïde, Phoenix. Les responsables affirment qu’il peut accomplir de nombreuses tâches de manière autonome, à la même vitesse que les humains. Pheonix, le premier robot au monde capable d'accomplir des tâches de manière autonome à la vitesse d'un humain, peut saisir, déplacer et placer avec élégance chaque objet sur ses côtés gauche et droit. Il peut identifier des objets de manière autonome
