
 Périphériques technologiques
IA
Implémentation de conversations à plusieurs tours Tsinghua UltraChat à l'aide de plusieurs API ChatGPT
Périphériques technologiques
IA
Implémentation de conversations à plusieurs tours Tsinghua UltraChat à l'aide de plusieurs API ChatGPT
Implémentation de conversations à plusieurs tours Tsinghua UltraChat à l'aide de plusieurs API ChatGPT

Depuis la sortie de ChatGPT, la popularité des modèles de conversation n'a fait qu'augmenter durant cette période. Même si nous admirons les performances étonnantes de ces modèles, nous devons également deviner l’énorme puissance de calcul et la prise en charge massive des données qui les sous-tendent.
En ce qui concerne les données, des données de haute qualité sont cruciales. Pour cette raison, OpenAI a déployé beaucoup d'efforts dans le travail de données et d'annotations. Plusieurs études ont montré que ChatGPT est un annotateur de données plus fiable que les humains. Si la communauté open source peut obtenir de grandes quantités de données de dialogue à partir de modèles de langage puissants tels que ChatGPT, elle peut former des modèles de dialogue avec de meilleures performances. Ceci est prouvé par la famille de modèles Alpaca – Alpaca, Vicuna, Koala. Par exemple, Vicuna a reproduit le succès en neuf étapes de ChatGPT en affinant les instructions du modèle LLaMA à l'aide des données de partage d'utilisateurs collectées à partir de ShareGPT. De plus en plus de preuves montrent que les data constituent la principale productivité pour la formation de modèles linguistiques puissants.
ShareGPT est un site Web de partage de données ChatGPT sur lequel les utilisateurs téléchargent les réponses ChatGPT qu'ils trouvent intéressantes. Les données sur ShareGPT sont ouvertes mais triviales et doivent être collectées et organisées par les chercheurs eux-mêmes. S'il existe un ensemble de données étendu et de haute qualité, la communauté open source obtiendra deux fois le résultat avec la moitié de l'effort nécessaire pour développer des modèles de conversation.
Sur cette base, un projet récent appelé UltraChat a systématiquement construit un ensemble de données de conversation de très haute qualité. Les auteurs du projet ont essayé d'utiliser deux API ChatGPT Turbo indépendantes pour mener des conversations afin de générer plusieurs séries de données de conversation.
- Adresse du projet : https://github.com/thunlp/UltraChat
- Adresse de l'ensemble de données : http://39.101.77.220/
- Interaction avec l'ensemble de données https://atlas.nomic.ai/map/0ce65783-c3a9-40b5-895d-384933f50081/a7b46301-022f-45d8-bbf4-98107eabdbac
Plus précisément, ce projet vise à construire un open source, à grande échelle- des données de dialogue à grande échelle et multi-tours basées sur les API Turbo, pratiques pour les chercheurs qui souhaitent développer des modèles de langage puissants avec des capacités de dialogue universelles. De plus, compte tenu de la protection de la vie privée et d'autres facteurs, le projet n'utilisera pas directement les données sur Internet comme invites. Afin de garantir la qualité des données générées, les chercheurs ont utilisé deux API ChatGPT Turbo indépendantes dans le processus de génération, dans lesquelles un modèle joue le rôle de l'utilisateur pour générer des questions ou des instructions, et l'autre modèle génère des commentaires.

Si vous utilisez directement ChatGPT et autorisez sa génération libre sur la base de certaines conversations et questions de départ, il sera sujet à des problèmes tels que des sujets uniques et des contenus répétés, ce qui rendra difficile la garantie de la diversité du données elles-mêmes. À cette fin, UltraChat a systématiquement classé et conçu les sujets et les types de tâches couverts par les données de conversation, et a également mené une ingénierie détaillée des invites pour le modèle d'utilisateur et le modèle de réponse. Il contient trois parties :
- Questions sur le monde (. Questions sur le monde) : Cette partie de la conversation provient d’enquêtes générales sur les concepts, les entités et les objets du monde réel. Les sujets abordés couvrent la technologie, l’art, la finance et d’autres domaines.
- Écriture et création : cette partie des données de conversation se concentre sur l'instruction à l'IA de créer un texte complet à partir de zéro, et sur cette base, des questions de suivi ou des conseils supplémentaires pour améliorer l'écriture et le contenu du Les types de matériel écrit comprennent des articles, des blogs, des poèmes, des histoires, des pièces de théâtre, des courriels et bien plus encore.
- Réécriture assistée (Écriture et Création) de données existantes : Ces données de dialogue sont générées à partir de données existantes. Les instructions incluent, sans s'y limiter, la réécriture, la suite, la traduction, l'induction, le raisonnement, etc., et les sujets abordés sont. également très diversifié.
Ces trois parties de données couvrent les exigences de la plupart des utilisateurs en matière de modèles d'IA. Dans le même temps, ces trois types de données seront également confrontés à des défis différents et nécessiteront des méthodes de construction différentes.
Par exemple, le principal défi de la première partie des données est de savoir comment couvrir le plus largement possible les connaissances communes dans la société humaine dans un total de centaines de milliers de conversations. Pour cela, les chercheurs sont partis de sujets et de sujets générés automatiquement. entités dérivées de Wikidata filtrées et structurées.
Les défis des deuxième et troisième parties proviennent principalement de la manière de simuler les instructions utilisateur et de rendre la génération de modèles utilisateur aussi diversifiée que possible dans les conversations ultérieures sans s'écarter du but ultime de la conversation (générer des matériaux ou réécrire des matériaux comme requis), pour cette raison, les chercheurs ont entièrement conçu et expérimenté les invites de saisie du modèle utilisateur. Une fois la construction terminée, les auteurs ont également post-traité les données pour atténuer le problème des hallucinations.
Actuellement, le projet a publié les deux premières parties de données, avec un volume de données de 1,24 million, ce qui devrait être le plus grand ensemble de données associées dans la communauté open source. Le contenu contient des conversations riches et colorées dans le monde réel, et la dernière partie des données sera publiée ultérieurement.
Les données sur les problèmes mondiaux proviennent de 30 méta-thèmes représentatifs et divers, comme le montre la figure ci-dessous :

- Sur la base des méta-thèmes ci-dessus, le projet a généré plus de 1 100 sous-thèmes. sujets Pour la construction des données ;
- Pour chaque sous-thème, générez jusqu'à 10 questions spécifiques
- Utilisez ensuite l'API Turbo pour générer de nouvelles questions connexes pour chacune des 10 questions ; décrit ci-dessus, utilise de manière itérative deux modèles pour générer 3 à 7 cycles de dialogue.
- De plus, ce projet a collecté les 10 000 entités nommées les plus couramment utilisées à partir de Wikidata ; a utilisé l'API ChatGPT pour générer 5 méta-questions pour chaque entité, généré 10 questions plus spécifiques et 20 questions connexes mais générales ; questions ; 200 000 questions spécifiques, 250 000 questions générales et 50 000 méta-questions ont été échantillonnées, et 3 à 7 cycles de dialogue ont été générés pour chaque question.
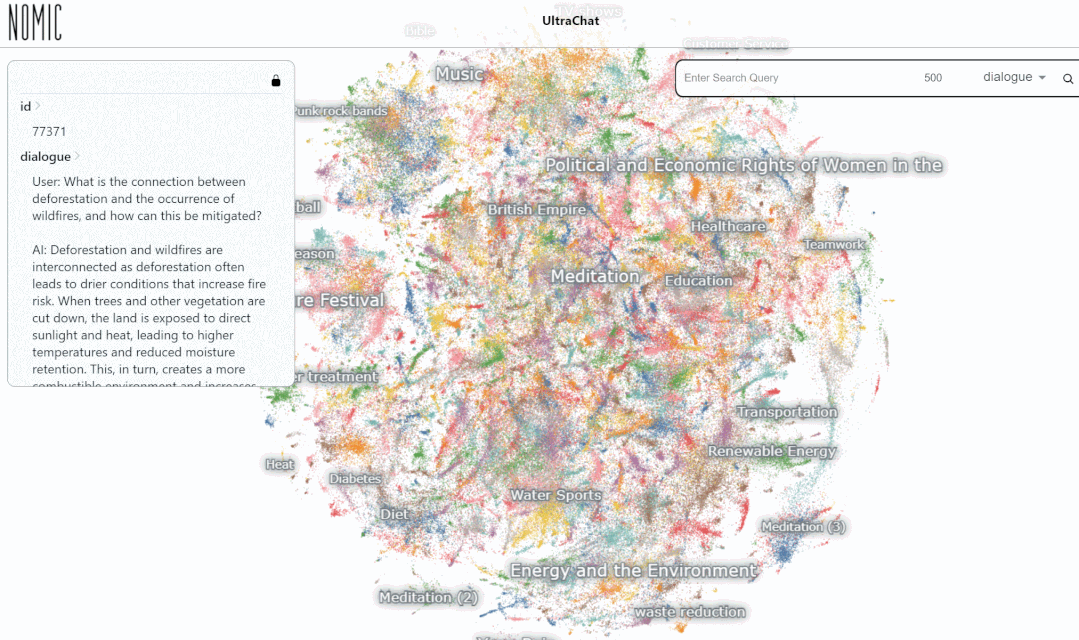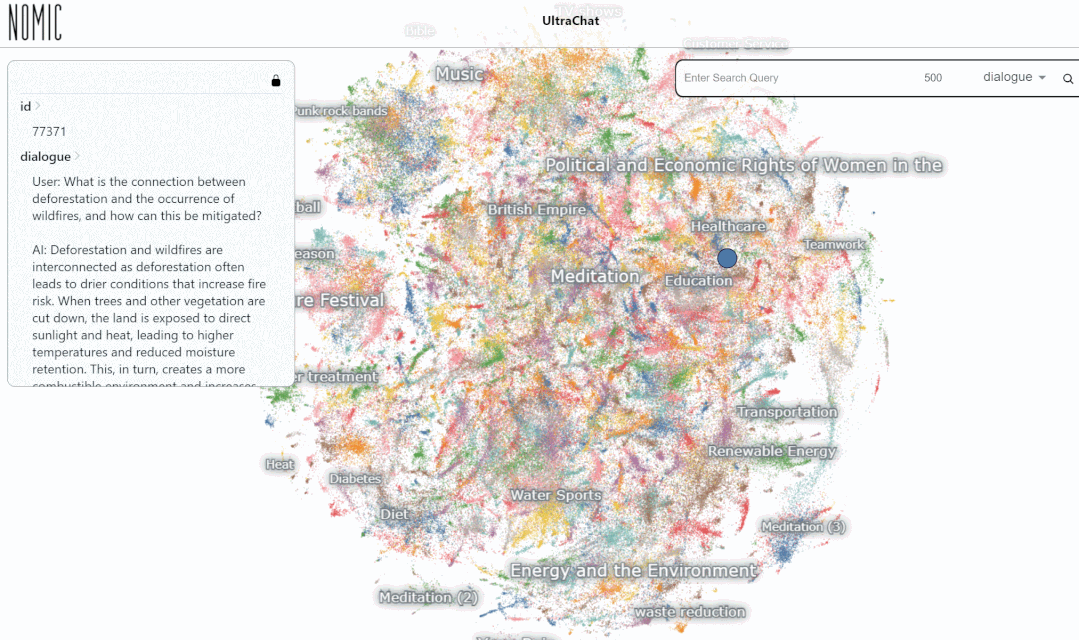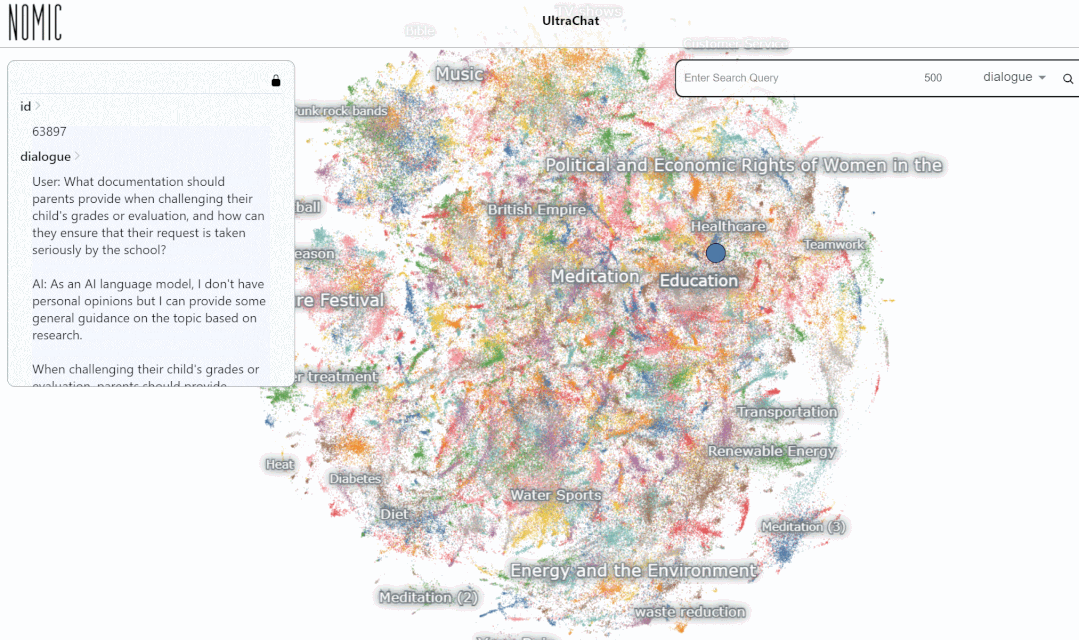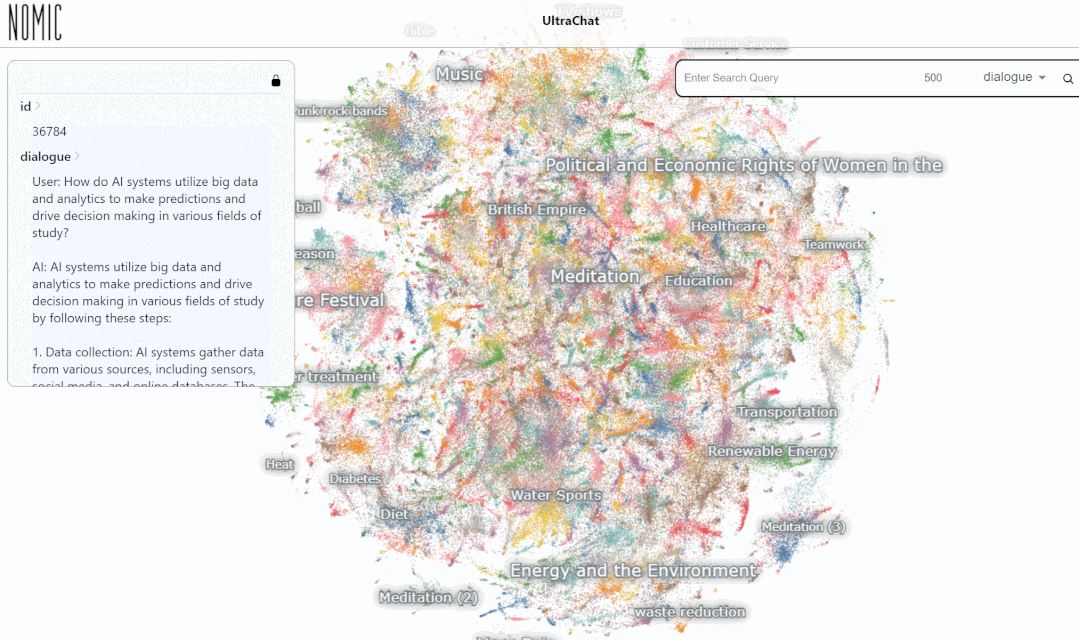
Regardons ensuite un exemple spécifique :
Nous avons testé l'effet de recherche de données sur la plateforme UltraChat. Par exemple, si vous saisissez « musique », le système recherchera automatiquement 10 000 ensembles de données de conversation ChatGPT liées à la musique, et chaque ensemble est une conversation à plusieurs tours 
Entrez le mot-clé « maths » La recherche les résultats montrent 3346 groupes de conversations à plusieurs tours : 
Actuellement, UltraChat couvre de nombreux domaines d'information, notamment la médecine, l'éducation, les sports, la protection de l'environnement et d'autres sujets. Dans le même temps, l'auteur a essayé d'utiliser le modèle open source LLaMa-7B pour effectuer un réglage fin des instructions supervisées sur UltraChat, et a constaté qu'après seulement 10 000 étapes de formation, l'effet était très impressionnant. Voici quelques exemples : 
 Connaissance du monde : répertoriées séparément Voici 10 bonnes universités chinoises et américaines
Connaissance du monde : répertoriées séparément Voici 10 bonnes universités chinoises et américaines
 Imaginez la question : Quelles sont les conséquences possibles lorsque le voyage dans l'espace devient possible ?
Imaginez la question : Quelles sont les conséquences possibles lorsque le voyage dans l'espace devient possible ?
Syllogisme : Une baleine est-elle un poisson ?

Question hypothétique : prouver que Jackie Chan est meilleur que Bruce Lee
Dans l'ensemble, UltraChat est un ensemble de données de conversation ChatGPT étendu et de haute qualité qui peut être combiné avec d'autres ensembles de données, améliorant considérablement la qualité des modèles de dialogue open source. À l'heure actuelle, UltraChat ne publie que la version anglaise, mais il publiera également la version chinoise des données à l'avenir. Les lecteurs intéressés sont invités à l’explorer.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Géospatial de Laravel: optimisation des cartes interactives et de grandes quantités de données
Apr 08, 2025 pm 12:24 PM
Géospatial de Laravel: optimisation des cartes interactives et de grandes quantités de données
Apr 08, 2025 pm 12:24 PM
Traiter efficacement 7 millions d'enregistrements et créer des cartes interactives avec la technologie géospatiale. Cet article explore comment traiter efficacement plus de 7 millions d'enregistrements en utilisant Laravel et MySQL et les convertir en visualisations de cartes interactives. Exigences initiales du projet de défi: extraire des informations précieuses en utilisant 7 millions d'enregistrements dans la base de données MySQL. Beaucoup de gens considèrent d'abord les langages de programmation, mais ignorent la base de données elle-même: peut-il répondre aux besoins? La migration des données ou l'ajustement structurel est-il requis? MySQL peut-il résister à une charge de données aussi importante? Analyse préliminaire: les filtres et les propriétés clés doivent être identifiés. Après analyse, il a été constaté que seuls quelques attributs étaient liés à la solution. Nous avons vérifié la faisabilité du filtre et établi certaines restrictions pour optimiser la recherche. Recherche de cartes basée sur la ville
 Comment résoudre MySQL ne peut pas être démarré
Apr 08, 2025 pm 02:21 PM
Comment résoudre MySQL ne peut pas être démarré
Apr 08, 2025 pm 02:21 PM
Il existe de nombreuses raisons pour lesquelles la startup MySQL échoue, et elle peut être diagnostiquée en vérifiant le journal des erreurs. Les causes courantes incluent les conflits de port (vérifier l'occupation du port et la configuration de modification), les problèmes d'autorisation (vérifier le service exécutant les autorisations des utilisateurs), les erreurs de fichier de configuration (vérifier les paramètres des paramètres), la corruption du répertoire de données (restaurer les données ou reconstruire l'espace de la table), les problèmes d'espace de la table InNODB (vérifier les fichiers IBDATA1), la défaillance du chargement du plug-in (vérification du journal des erreurs). Lors de la résolution de problèmes, vous devez les analyser en fonction du journal d'erreur, trouver la cause profonde du problème et développer l'habitude de sauvegarder régulièrement les données pour prévenir et résoudre des problèmes.
 Comment utiliser MySQL après l'installation
Apr 08, 2025 am 11:48 AM
Comment utiliser MySQL après l'installation
Apr 08, 2025 am 11:48 AM
L'article présente le fonctionnement de la base de données MySQL. Tout d'abord, vous devez installer un client MySQL, tel que MySQLWorkBench ou le client de ligne de commande. 1. Utilisez la commande MySQL-UROot-P pour vous connecter au serveur et connecter avec le mot de passe du compte racine; 2. Utilisez Createdatabase pour créer une base de données et utilisez Sélectionner une base de données; 3. Utilisez CreateTable pour créer une table, définissez des champs et des types de données; 4. Utilisez InsertInto pour insérer des données, remettre en question les données, mettre à jour les données par mise à jour et supprimer les données par Supprimer. Ce n'est qu'en maîtrisant ces étapes, en apprenant à faire face à des problèmes courants et à l'optimisation des performances de la base de données que vous pouvez utiliser efficacement MySQL.
 Mysql peut-il renvoyer JSON
Apr 08, 2025 pm 03:09 PM
Mysql peut-il renvoyer JSON
Apr 08, 2025 pm 03:09 PM
MySQL peut renvoyer les données JSON. La fonction JSON_Extract extrait les valeurs de champ. Pour les requêtes complexes, envisagez d'utiliser la clause pour filtrer les données JSON, mais faites attention à son impact sur les performances. Le support de MySQL pour JSON augmente constamment, et il est recommandé de faire attention aux dernières versions et fonctionnalités.
 Les ingénieurs de backend senior à distance (plates-formes) ont besoin de cercles
Apr 08, 2025 pm 12:27 PM
Les ingénieurs de backend senior à distance (plates-formes) ont besoin de cercles
Apr 08, 2025 pm 12:27 PM
Ingénieur backend à distance Emploi Vacant Société: Emplacement du cercle: Bureau à distance Type d'emploi: Salaire à temps plein: 130 000 $ - 140 000 $ Description du poste Participez à la recherche et au développement des applications mobiles Circle et des fonctionnalités publiques liées à l'API couvrant l'intégralité du cycle de vie de développement logiciel. Les principales responsabilités complètent indépendamment les travaux de développement basés sur RubyOnRails et collaborent avec l'équipe frontale React / Redux / Relay. Créez les fonctionnalités de base et les améliorations des applications Web et travaillez en étroite collaboration avec les concepteurs et le leadership tout au long du processus de conception fonctionnelle. Promouvoir les processus de développement positifs et hiérarchiser la vitesse d'itération. Nécessite plus de 6 ans de backend d'applications Web complexe
 Comprendre les propriétés acides: les piliers d'une base de données fiable
Apr 08, 2025 pm 06:33 PM
Comprendre les propriétés acides: les piliers d'une base de données fiable
Apr 08, 2025 pm 06:33 PM
Une explication détaillée des attributs d'acide de base de données Les attributs acides sont un ensemble de règles pour garantir la fiabilité et la cohérence des transactions de base de données. Ils définissent comment les systèmes de bases de données gérent les transactions et garantissent l'intégrité et la précision des données même en cas de plantages système, d'interruptions d'alimentation ou de plusieurs utilisateurs d'accès simultanément. Présentation de l'attribut acide Atomicité: une transaction est considérée comme une unité indivisible. Toute pièce échoue, la transaction entière est reculée et la base de données ne conserve aucune modification. Par exemple, si un transfert bancaire est déduit d'un compte mais pas augmenté à un autre, toute l'opération est révoquée. BeginTransaction; UpdateAccountSsetBalance = Balance-100Wh
 MySQL ne peut pas être installé après le téléchargement
Apr 08, 2025 am 11:24 AM
MySQL ne peut pas être installé après le téléchargement
Apr 08, 2025 am 11:24 AM
Les principales raisons de la défaillance de l'installation de MySQL sont les suivantes: 1. Problèmes d'autorisation, vous devez s'exécuter en tant qu'administrateur ou utiliser la commande sudo; 2. Des dépendances sont manquantes et vous devez installer des packages de développement pertinents; 3. Conflits du port, vous devez fermer le programme qui occupe le port 3306 ou modifier le fichier de configuration; 4. Le package d'installation est corrompu, vous devez télécharger et vérifier l'intégrité; 5. La variable d'environnement est mal configurée et les variables d'environnement doivent être correctement configurées en fonction du système d'exploitation. Résolvez ces problèmes et vérifiez soigneusement chaque étape pour installer avec succès MySQL.
 La clé principale de MySQL peut être nul
Apr 08, 2025 pm 03:03 PM
La clé principale de MySQL peut être nul
Apr 08, 2025 pm 03:03 PM
La clé primaire MySQL ne peut pas être vide car la clé principale est un attribut de clé qui identifie de manière unique chaque ligne dans la base de données. Si la clé primaire peut être vide, l'enregistrement ne peut pas être identifié de manière unique, ce qui entraînera une confusion des données. Lorsque vous utilisez des colonnes entières ou des UUIdes auto-incrémentales comme clés principales, vous devez considérer des facteurs tels que l'efficacité et l'occupation de l'espace et choisir une solution appropriée.
