

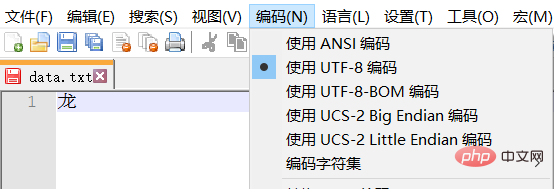
Remarque : Le texte du test est codé en UTF-8 et les caractères chinois occupent généralement trois octets. Les caractères chinois en GBK occupent généralement 2 octets.
import os
# 对于单个文件进行操作的函数,如果需要对文件夹进行操作,可以使用一个函数包装它,这样不用修改本函数,即达到扩展的目的了。
def transfer_encode(source_path, target_path, source_encode='GBK', target_encode='UTF-8'):
with open(source_path, mode='r', errors='ignore', encoding=source_encode) as source_file: # 读取文件时,如果直接忽略报错,则程序正常执行,但是文件已经损坏了。
with open(target_path, mode='w', encoding=target_encode) as target_file: # 所以,应该捕获异常,停止程序执行。
line = source_file.readline()
while line != '':
target_file.write(line)
line = source_file.readline()
print("Execute End!")
# 这个函数的功能和上面是一样的,区别在于它是以二进制读取的,然后解码、转码再写入的
def transfer_encode2(source_path, target_path, source_encode='GBK', target_encode='UTF-8'):
with open(source_path, mode='rb') as source_file:
with open(target_path, mode="wb") as target_file:
bs = source_file.read(1024)
while len(bs) != 0:
target_file.write(bs.decode(source_encode).encode(target_encode))
bs = source_file.read(1024)
print("Execute End!")
source_path = r'C:\Users\Alfred\Desktop\test_data\test\data.txt'
target_path = r'C:\Users\Alfred\Desktop\test_data\test\data1.txt'
transfer_encode(source_path=source_path, target_path=target_path, source_encode="UTF-8", target_encode="GBK")
# transfer_encode2(source_path=source_path, target_path=target_path)
# 在cmd中使用 type命令,可以查看文件的内容,并且使用cmd默认的编码。
# 使用 chcp 命令可以查看当前使用的编码的数字编号Sortie de la console La sortie de l'exécution de cette fonction n'a aucun sens, mais je veux savoir si elle a été exécutée, alors je l'imprime.

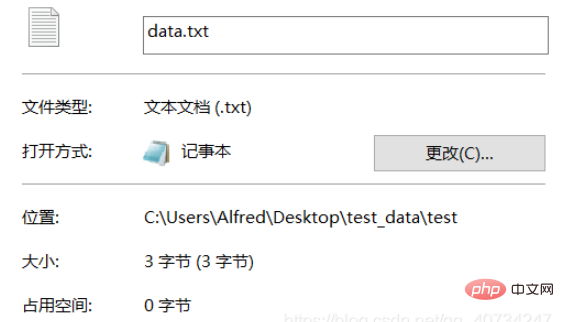
Dossier Test data1.txt est le texte converti et codé.
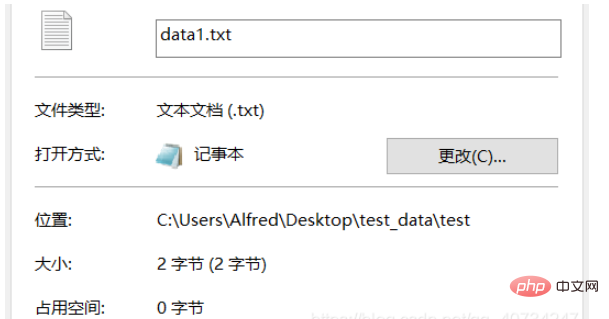
À en juger par le fichier généré, comme il ne contient qu'un seul mot, vous pouvez savoir si la conversion a réussi en comparant simplement la taille. Bien entendu, il est également possible de l'ouvrir directement en visualisation, mais si vous l'ouvrez directement en visualisation, cela n'aura aucun effet et un caractère chinois 龙 s'affichera. Nous adoptons donc ici une approche différente et utilisons une méthode de visualisation différente !
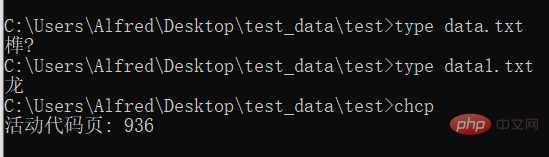
Remarque : data.txt est codé en UTF-8, tandis que data1.txt est codé en GBK. Étant donné que Windows utilisé en Chine adopte par défaut la méthode de codage chinoise, il ne peut pas afficher le texte codé en UTF-8. La troisième sortie consiste à afficher l'encodage actuellement utilisé. Elle renvoie le code d'encodage. Voir la figure ci-dessous pour plus de détails :
Remarque : GBK est un encodage compatible avec GB2312.
Si vous utilisez python, vous n'avez besoin que de 7 lignes de code pour convertir un seul fichier ! J'ai écrit deux fonctions ci-dessus, mais les fonctions sont les mêmes. La différence est que la première fonction lit les informations textuelles dans un encodage spécifique, puis les écrit directement dans un autre encodage. La deuxième fonction lit le contenu du fichier sous forme binaire, puis le décode et le transcode pour l'écriture. Son principe est le même, c'est-à-dire qu'il doit inclure des opérations séquentielles de décodage et de transcodage.
L'encodage, le décodage et les jeux de caractères eux-mêmes sont très compliqués et je ne sais pas comment les expliquer en profondeur. La compréhension ici peut être simplifiée comme ceci. Deux jeux de caractères d'encodage différents ont les mêmes caractères, donc le but de la lecture du fichier encodé en UTF-8 est d'obtenir les caractères qu'il mappe, puis de l'écrire à nouveau pour le mapper à un autre encodage. jeu de caractères, le caractère est donc similaire à la fonction d'une station de transfert. Si vous utilisez directement un jeu de caractères pour lire le contenu d'un autre jeu de caractères, les caractères tronqués affichés dans la cmd ci-dessus apparaîtront.
PS : Par conséquent, cela peut aussi expliquer un problème, c'est-à-dire pourquoi l'ouverture d'un gros fichier texte entraînera le blocage du programme ! Parce qu'un gros fichier texte contient de nombreux caractères qui doivent être décodés. Cela ressemble un peu à la mise en file d'attente. Chaque caractère attend d'être décodé. Bien que le traitement d'un caractère soit rapide, un fichier texte volumineux contient un grand nombre de caractères. Par exemple, Notepad++ n'a aucun problème à ouvrir des textes volumineux. Mais lorsque j'ai ouvert ce très gros texte, il est toujours resté bloqué ! (La file d'attente ici n'est qu'une métaphore, et je ne connais pas la situation réelle, mais elle doit être traitée un par un.)
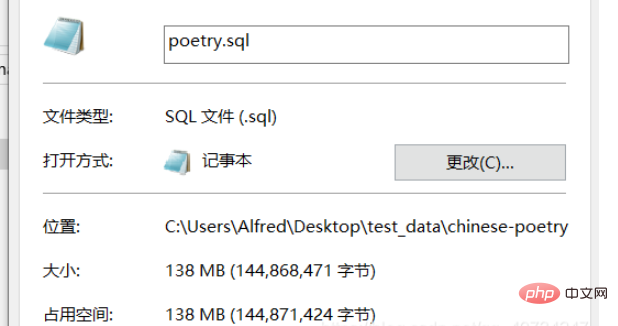
Nous l'estimons, en supposant que tous les caractères sont en chinois (en fait, c'est toujours contient Certains sont en anglais, mais en général, le chinois est majoritaire.) Cela montre qu'il y a environ 50 millions de caractères qui doivent être décodés, il est donc toujours très difficile pour l'ordinateur de traiter le résumé, mais il est possible de voir le résumé. se fige lorsqu’il est ouvert directement, je ne l’essaierai pas ici.

Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
















![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



