
 Périphériques technologiques
IA
Le modèle SOTA innovant de Meta peut générer des vidéos étonnantes basées sur une seule phrase, déclenchant un engouement sur Internet !
Périphériques technologiques
IA
Le modèle SOTA innovant de Meta peut générer des vidéos étonnantes basées sur une seule phrase, déclenchant un engouement sur Internet !
Le modèle SOTA innovant de Meta peut générer des vidéos étonnantes basées sur une seule phrase, déclenchant un engouement sur Internet !

Je vais vous donner un paragraphe et vous demander de faire une vidéo, pouvez-vous le faire ?
Meta a dit, je peux le faire.
Vous avez bien entendu : grâce à l'IA, vous pouvez aussi devenir cinéaste !
Récemment, Meta a lancé un nouveau modèle d'IA, et le nom est très simple : Make-A-Video.
Quelle est la puissance de ce modèle ?
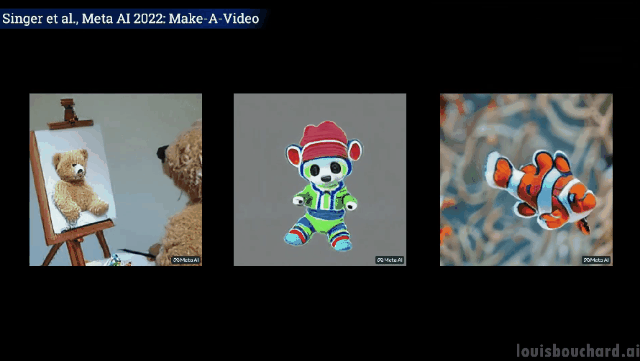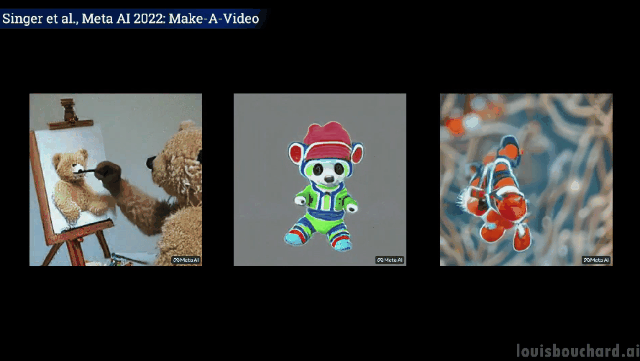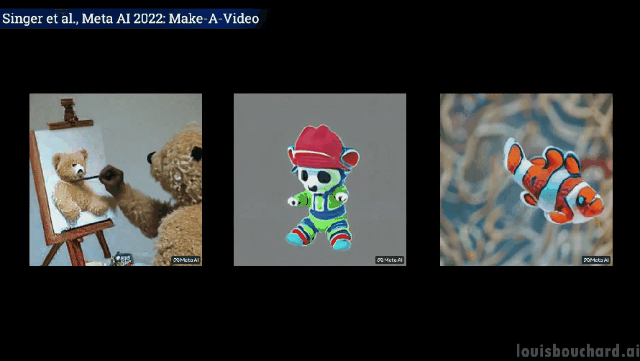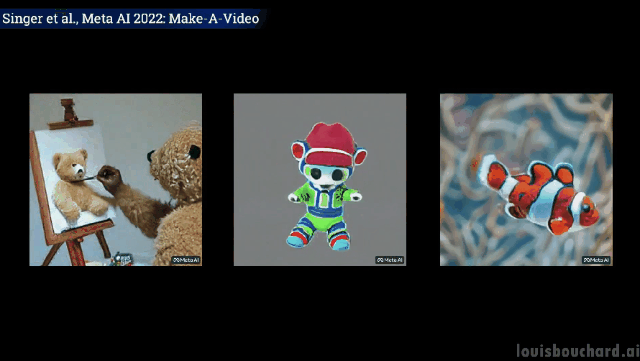
Avec une seule phrase, vous pouvez réaliser la scène de "Trois chevaux au galop".

Même LeCun a dit que ce qui est censé arriver viendra toujours.

Les effets visuels sont époustouflants
Sans plus tard, regardons simplement les effets.
Deux kangourous sont occupés à cuisiner dans la cuisine (qu'ils puissent manger, c'est une autre affaire)

Plan rapproché : Le peintre peint sur la toile

Le monde à deux les gens marchent sous la forte pluie (pas uniformes)

Le cheval boit de l'eau

La ballerine danse sur le gratte-ciel

Un golden retriever est manger sur une belle plage tropicale d'été Glace (les pattes ont évolué)

Le propriétaire du chat regarde la télévision avec la télécommande (les pattes ont évolué)

Un ours en peluche dessine un auto- portrait de lui-même

Ce qui est inattendu mais raisonnable, c'est que les "mains" utilisées par les chiens pour tenir les glaces, les chats pour tenir les télécommandes et les ours en peluche pour dessiner ont toutes "évolué" comme les humains ! (Tactical Backward)
Bien sûr, en plus de transformer du texte en vidéo, Make-A-Video peut également transformer des images statiques en Gifs.
Entrée :

Sortie :

Entrée :

Sortie : (La lumière semble un peu déplacée)

2 images statiques dans GIF, saisissez l'image de la météorite

Sortie :

Et transformer la vidéo en vidéo ?
Entrée :

Sortie :

Entrée :

Sortie :

Principes techniques
Aujourd'hui, Meta a publié son propre dernier recherche MAKE-A-VIDEO : GÉNÉRATION DE TEXTE À VIDÉO SANS DONNÉES TEXTE-VIDÉO.

Adresse papier : https://makeavideo.studio/Make-A-Video.pdf
Avant l'apparition de ce modèle, nous avions déjà la diffusion stable.
Des scientifiques intelligents ont déjà demandé à l'IA de générer des images avec une seule phrase. Que feront-ils ensuite ?
Évidemment, il s'agit de générer une vidéo.

Un chien de super-héros portant une cape rouge volant dans le ciel
Générer une vidéo est bien plus difficile que générer une image. Non seulement nous devons générer plusieurs images du même sujet et de la même scène, mais nous devons également les rendre opportunes et cohérentes.
Cela augmente la complexité de la tâche de génération d'images - nous ne pouvons pas simplement utiliser DALLE pour générer 60 images puis les assembler dans une vidéo. L'effet sera très médiocre et irréaliste.
Par conséquent, nous avons besoin d'un modèle capable de comprendre le monde de manière plus puissante et de lui permettre de générer une série cohérente d'images basées sur ce niveau de compréhension. Ce n’est qu’alors que les images peuvent se fondre harmonieusement.
En d'autres termes, notre objectif est de simuler un monde puis de simuler ses records. Comment faire ?

Selon les idées précédentes, les chercheurs utiliseraient un grand nombre de paires texte-vidéo pour entraîner le modèle, mais dans la situation actuelle, cette méthode de traitement n'est pas réaliste. Parce que ces données sont difficiles à obtenir et que les coûts de formation sont très chers.
Les chercheurs ont donc ouvert leur esprit et adopté une toute nouvelle approche.
Ils ont choisi de développer un modèle texte-image puis de l'appliquer aux vidéos.
Par coïncidence, il y a quelque temps, Meta a développé Make-A-Scene, un modèle du texte à l'image.
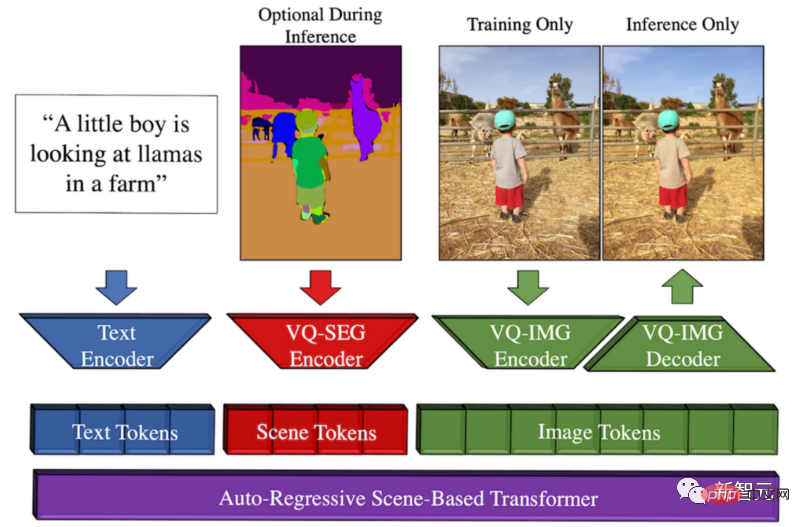
Aperçu de la méthode Make-A-Scene
L'opportunité de ce modèle est que Meta espère promouvoir l'expression créative et comparer cette tendance du texte à l'image avec la précédente esquisse -modèle d'image Combiné, résultant en une fusion fantastique entre le texte et la génération d'images conditionnées par des croquis.
Cela signifie que nous pouvons rapidement dessiner un chat et écrire le type d'image que nous voulons. En suivant les croquis et le texte, le modèle produira l'illustration parfaite que nous souhaitons en quelques secondes.

Vous pouvez considérer cette approche d'IA générative multimodale comme un modèle Dall-E avec plus de contrôle sur la génération, car elle peut également prendre des croquis rapides en entrée.
La raison pour laquelle on l'appelle multimodal est qu'il peut prendre plusieurs modalités en entrée, telles que du texte et des images. En revanche, Dall-E ne peut générer des images qu'à partir de texte.
Pour générer une vidéo, la dimension du temps doit être ajoutée, c'est pourquoi les chercheurs ont ajouté un pipeline spatio-temporel au modèle Make-A-Scene.
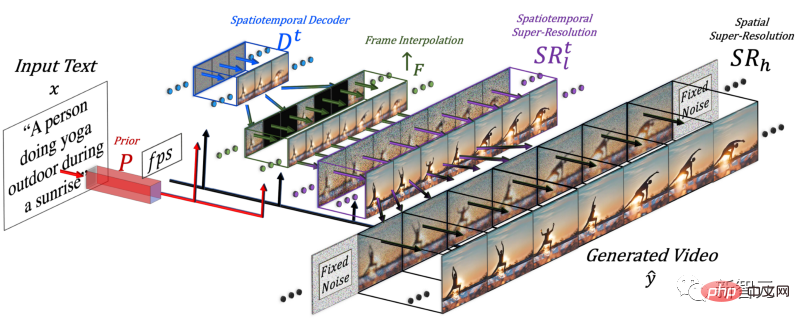
Après avoir ajouté la dimension temporelle, ce modèle ne génère pas une seule image, mais 16 images basse résolution pour créer une courte vidéo cohérente.
Cette méthode est en fait similaire au modèle texte-image, mais la différence est que, basée sur la convolution bidimensionnelle conventionnelle, elle ajoute une convolution unidimensionnelle.
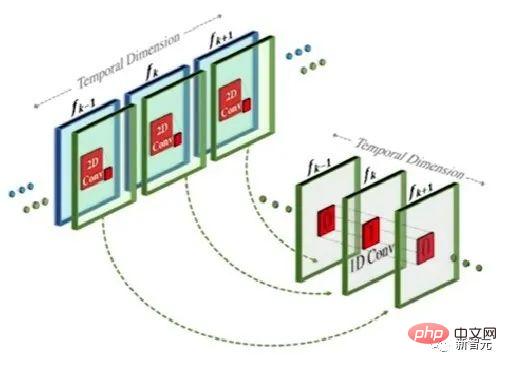
En ajoutant simplement une convolution unidimensionnelle, les chercheurs ont pu maintenir inchangée la convolution bidimensionnelle pré-entraînée tout en ajoutant une dimension temporelle. Les chercheurs peuvent ensuite s’entraîner à partir de zéro, en réutilisant une grande partie du code et des paramètres du modèle d’image Make-A-Scene.
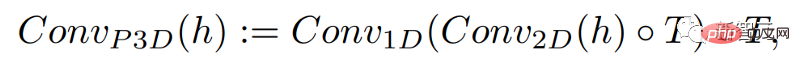
Dans le même temps, les chercheurs souhaitent également utiliser la saisie de texte pour guider ce modèle, qui sera très similaire au modèle d'image utilisant l'intégration CLIP.
Dans ce cas, les chercheurs ont augmenté la dimension spatiale en mélangeant des caractéristiques de texte avec des caractéristiques d'image. La méthode est la même que ci-dessus : conserver le module d'attention dans le modèle Make-A-Scene et ajouter une dimension unidimensionnelle à celui-ci. time. Module Attention - copiez et collez le modèle du générateur d'images et répétez le module de génération pour une dimension supplémentaire pour obtenir 16 images initiales.
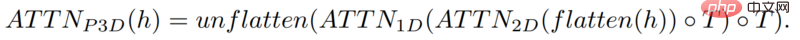
Mais en s'appuyant uniquement sur ces 16 images initiales, la vidéo ne peut pas être générée.
Les chercheurs doivent produire une vidéo haute définition à partir de ces 16 images principales. Leur approche consiste à accéder aux images précédentes et futures et à les interpoler de manière itérative simultanément dans les dimensions temporelle et spatiale.
De cette façon, entre ces 16 images initiales, ils ont généré de nouvelles images plus grandes basées sur les images avant et après, de sorte que le mouvement devienne cohérent et que la vidéo globale devienne fluide.
Cela se fait via un réseau d'interpolation de trames, qui peut prendre des images existantes pour combler les lacunes et générer des informations intermédiaires. Dans la dimension spatiale, il fait la même chose : agrandit l'image, comble les lacunes en pixels et rend l'image plus haute définition.

Pour résumer, pour générer des vidéos, les chercheurs ont affiné un modèle de conversion texte-image. Ils ont pris un modèle puissant déjà formé, l'ont peaufiné et formé pour s'adapter à la vidéo.
Grâce à l'ajout de modules spatiaux et temporels, vous pouvez simplement adapter le modèle à ces nouvelles données sans avoir à le recycler, ce qui permet d'économiser beaucoup de coûts.
Ce type de recyclage utilise des vidéos non étiquetées et n'a besoin que d'apprendre au modèle à comprendre la cohérence de la vidéo et des images vidéo, ce qui facilite la construction de l'ensemble de données.
Enfin, les chercheurs ont à nouveau utilisé le modèle d'optimisation d'image pour améliorer la résolution spatiale et ont utilisé le composant d'interpolation d'images pour ajouter plus d'images afin de rendre la vidéo plus fluide.
Bien entendu, les résultats actuels de Make-A-Video présentent encore des lacunes, tout comme le modèle texte-image. Mais nous savons tous à quel point les progrès dans le domaine de l’IA sont rapides.
Si vous souhaitez en savoir plus, vous pouvez vous référer à l'article Meta AI dans le lien. La communauté développe également une implémentation de PyTorch, alors restez à l'écoute si vous souhaitez l'implémenter vous-même.
Introduction à l'auteur
Un certain nombre de chercheurs chinois ont participé à cet article : Yin Xi, An Jie, Zhang Songyang, Qiyuan Hu.
Yin Xi, chercheur scientifique FAIR. Auparavant, il a travaillé pour Microsoft en tant que scientifique principal des applications pour Microsoft Cloud et l'IA. Il a obtenu son doctorat du Département d'informatique et d'ingénierie de l'Université d'État du Michigan et son baccalauréat en génie électrique de l'Université de Wuhan en 2013. Les principaux domaines de recherche sont la compréhension multimodale, la détection de cibles à grande échelle, le raisonnement facial, etc.
Anjie est doctorante au Département d'informatique de l'Université de Rochester. Étude auprès du professeur Roger Bo. A déjà obtenu une licence et une maîtrise de l'Université de Pékin en 2016 et 2019. Les intérêts de recherche incluent la vision par ordinateur, les modèles génératifs profonds et l’IA+art. Participation à la recherche Make-A-Video en tant que stagiaire.
Zhang Songyang est doctorant au Département d'informatique de l'Université de Rochester, étudiant sous la direction du professeur Roger Bo. Il a obtenu son baccalauréat de l'Université du Sud-Est et sa maîtrise de l'Université du Zhejiang. Les intérêts de recherche incluent la localisation des moments du langage naturel, l'induction grammaticale non supervisée, la reconnaissance d'actions basée sur le squelette, etc. Participation à la recherche Make-A-Video en tant que stagiaire.
Qiyuan Hu, alors résident en IA à FAIR, était engagé dans des recherches sur des modèles génératifs multimodaux qui améliorent la créativité humaine. Elle a obtenu son doctorat en physique médicale à l’Université de Chicago et a travaillé sur l’analyse d’images médicales assistée par l’IA. Je travaille actuellement chez Tempus Labs en tant que scientifique en apprentissage automatique.
Les internautes ont été choqués
Il y a quelque temps, de grandes entreprises comme Google ont publié leurs propres modèles de conversion texte-image, comme Parti, etc.
Certains pensent même que les modèles génératifs texte-vidéo sont encore loin.
De façon inattendue, Meta a largué une bombe cette fois.
En fait, il existe aujourd'hui également un modèle de génération texte-vidéo Phenaki, qui a été soumis à l'ICLR 2023. Comme il est encore en phase de révision à l'aveugle, l'institution de l'auteur est encore inconnue.

Les internautes ont dit que de DALLE à Stable Diffuson en passant par Make-A-Video, tout s'est passé trop vite.

Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Comment vérifier la configuration de CentOS HDFS
Apr 14, 2025 pm 07:21 PM
Comment vérifier la configuration de CentOS HDFS
Apr 14, 2025 pm 07:21 PM
Guide complet pour vérifier la configuration HDFS dans les systèmes CentOS Cet article vous guidera comment vérifier efficacement la configuration et l'état de l'exécution des HDF sur les systèmes CentOS. Les étapes suivantes vous aideront à bien comprendre la configuration et le fonctionnement des HDF. Vérifiez la variable d'environnement Hadoop: Tout d'abord, assurez-vous que la variable d'environnement Hadoop est correctement définie. Dans le terminal, exécutez la commande suivante pour vérifier que Hadoop est installé et configuré correctement: HadoopVersion Check HDFS Fichier de configuration: Le fichier de configuration de base de HDFS est situé dans le répertoire / etc / hadoop / conf / le répertoire, où Core-site.xml et hdfs-site.xml sont cruciaux. utiliser
 Ligne de commande de l'arrêt CentOS
Apr 14, 2025 pm 09:12 PM
Ligne de commande de l'arrêt CentOS
Apr 14, 2025 pm 09:12 PM
La commande de fermeture CENTOS est arrêtée et la syntaxe est la fermeture de [options] le temps [informations]. Les options incluent: -H Arrêtez immédiatement le système; -P éteignez l'alimentation après l'arrêt; -r redémarrer; -t temps d'attente. Les temps peuvent être spécifiés comme immédiats (maintenant), minutes (minutes) ou une heure spécifique (HH: mm). Des informations supplémentaires peuvent être affichées dans les messages système.
 Quelles sont les méthodes de sauvegarde pour Gitlab sur Centos
Apr 14, 2025 pm 05:33 PM
Quelles sont les méthodes de sauvegarde pour Gitlab sur Centos
Apr 14, 2025 pm 05:33 PM
La politique de sauvegarde et de récupération de GitLab dans le système CentOS afin d'assurer la sécurité et la récupérabilité des données, Gitlab on CentOS fournit une variété de méthodes de sauvegarde. Cet article introduira plusieurs méthodes de sauvegarde courantes, paramètres de configuration et processus de récupération en détail pour vous aider à établir une stratégie complète de sauvegarde et de récupération de GitLab. 1. MANUEL BACKUP Utilisez le Gitlab-RakegitLab: Backup: Créer la commande pour exécuter la sauvegarde manuelle. Cette commande sauvegarde des informations clés telles que le référentiel Gitlab, la base de données, les utilisateurs, les groupes d'utilisateurs, les clés et les autorisations. Le fichier de sauvegarde par défaut est stocké dans le répertoire / var / opt / gitlab / backups. Vous pouvez modifier / etc / gitlab
 CentOS installe MySQL
Apr 14, 2025 pm 08:09 PM
CentOS installe MySQL
Apr 14, 2025 pm 08:09 PM
L'installation de MySQL sur CENTOS implique les étapes suivantes: Ajout de la source MySQL YUM appropriée. Exécutez la commande YUM Install MySQL-Server pour installer le serveur MySQL. Utilisez la commande mysql_secure_installation pour créer des paramètres de sécurité, tels que la définition du mot de passe de l'utilisateur racine. Personnalisez le fichier de configuration MySQL selon les besoins. Écoutez les paramètres MySQL et optimisez les bases de données pour les performances.
 Comment est la prise en charge du GPU pour Pytorch sur Centos
Apr 14, 2025 pm 06:48 PM
Comment est la prise en charge du GPU pour Pytorch sur Centos
Apr 14, 2025 pm 06:48 PM
Activer l'accélération du GPU Pytorch sur le système CentOS nécessite l'installation de versions CUDA, CUDNN et GPU de Pytorch. Les étapes suivantes vous guideront tout au long du processus: CUDA et CUDNN Installation détermineront la compatibilité de la version CUDA: utilisez la commande NVIDIA-SMI pour afficher la version CUDA prise en charge par votre carte graphique NVIDIA. Par exemple, votre carte graphique MX450 peut prendre en charge CUDA11.1 ou plus. Téléchargez et installez Cudatoolkit: visitez le site officiel de Nvidiacudatoolkit et téléchargez et installez la version correspondante selon la version CUDA la plus élevée prise en charge par votre carte graphique. Installez la bibliothèque CUDNN:
 Explication détaillée du principe docker
Apr 14, 2025 pm 11:57 PM
Explication détaillée du principe docker
Apr 14, 2025 pm 11:57 PM
Docker utilise les fonctionnalités du noyau Linux pour fournir un environnement de fonctionnement d'application efficace et isolé. Son principe de travail est le suivant: 1. Le miroir est utilisé comme modèle en lecture seule, qui contient tout ce dont vous avez besoin pour exécuter l'application; 2. Le Système de fichiers Union (UnionFS) empile plusieurs systèmes de fichiers, ne stockant que les différences, l'économie d'espace et l'accélération; 3. Le démon gère les miroirs et les conteneurs, et le client les utilise pour l'interaction; 4. Les espaces de noms et les CGROUP implémentent l'isolement des conteneurs et les limitations de ressources; 5. Modes de réseau multiples prennent en charge l'interconnexion du conteneur. Ce n'est qu'en comprenant ces concepts principaux que vous pouvez mieux utiliser Docker.
 Comment choisir une base de données Gitlab dans CentOS
Apr 14, 2025 pm 05:39 PM
Comment choisir une base de données Gitlab dans CentOS
Apr 14, 2025 pm 05:39 PM
Lors de l'installation et de la configuration de GitLab sur un système CentOS, le choix de la base de données est crucial. Gitlab est compatible avec plusieurs bases de données, mais PostgreSQL et MySQL (ou MARIADB) sont le plus couramment utilisés. Cet article analyse les facteurs de sélection de la base de données et fournit des étapes détaillées d'installation et de configuration. Guide de sélection de la base de données Lors du choix d'une base de données, vous devez considérer les facteurs suivants: PostgreSQL: la base de données par défaut de GitLab est puissante, a une évolutivité élevée, prend en charge les requêtes complexes et le traitement des transactions et convient aux grands scénarios d'application. MySQL / MARIADB: une base de données relationnelle populaire largement utilisée dans les applications Web, avec des performances stables et fiables. MongoDB: base de données NoSQL, se spécialise dans
 Comment afficher les journaux Gitlab sous Centos
Apr 14, 2025 pm 06:18 PM
Comment afficher les journaux Gitlab sous Centos
Apr 14, 2025 pm 06:18 PM
Un guide complet pour consulter les journaux GitLab sous Centos System Cet article vous guidera comment afficher divers journaux GitLab dans le système CentOS, y compris les journaux principaux, les journaux d'exception et d'autres journaux connexes. Veuillez noter que le chemin du fichier journal peut varier en fonction de la version Gitlab et de la méthode d'installation. Si le chemin suivant n'existe pas, veuillez vérifier le répertoire d'installation et les fichiers de configuration de GitLab. 1. Afficher le journal GitLab principal Utilisez la commande suivante pour afficher le fichier journal principal de l'application GitLabRails: Commande: sudocat / var / log / gitlab / gitlab-rails / production.log Cette commande affichera le produit
