
 Périphériques technologiques
IA
« Analyse approfondie » : exploration de l'algorithme de segmentation des nuages de points LiDAR dans la conduite autonome
Périphériques technologiques
IA
« Analyse approfondie » : exploration de l'algorithme de segmentation des nuages de points LiDAR dans la conduite autonome
« Analyse approfondie » : exploration de l'algorithme de segmentation des nuages de points LiDAR dans la conduite autonome

Les algorithmes de segmentation de nuages de points laser actuellement courants incluent des méthodes basées sur l'ajustement plan et des méthodes basées sur les caractéristiques des données de nuages de points laser. Les détails sont les suivants :
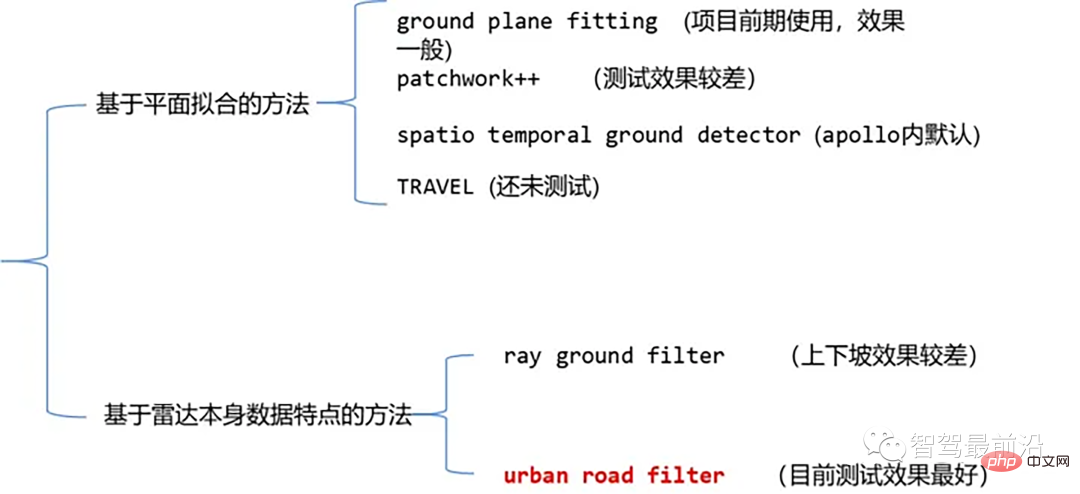
Algorithme de segmentation au sol des nuages de points
01 Méthode basée sur l'ajustement de plan - Ajustement du plan de sol
Idée d'algorithme : Une méthode de traitement simple est dans la direction x (La direction de l'avant de la voiture) divise l'espace en plusieurs sous-plans, puis utilise l'algorithme d'ajustement du plan de sol (GPF) pour chaque sous-plan afin d'obtenir une méthode de segmentation du sol capable de gérer les pentes raides. Cette méthode consiste à adapter un plan global dans un nuage de points à image unique. Elle fonctionne mieux lorsque le nombre de nuages de points est important. Lorsque le nuage de points est clairsemé, il est facile de provoquer des détections manquées et des détections fausses, telles que 16 lignes. lidar.
Pseudo-code de l'algorithme :

Pseudo-code
Le processus de l'algorithme est que pour un nuage de points donné P, le résultat final de la segmentation est deux ensembles de nuages de points, un nuage de points au sol et un nuage de points non- Nuage de points au sol Nuage de points. Cet algorithme a quatre paramètres importants, comme suit :
- Niter : le nombre de fois pour effectuer une décomposition en valeurs singulières (SVD), c'est-à-dire le nombre d'ajustements d'optimisation
- NLPR : utilisé pour sélectionner la hauteur la plus basse point de quantité LPR
- Thseed : Seuil de sélection des points de départ Lorsque la hauteur d'un point dans le nuage de points est inférieure à la hauteur de LPR plus ce seuil, nous ajoutons le point à l'ensemble de points de départ
- . Thdist : Seuil de distance dans le plan, nous calculerons la distance de chaque point du nuage de points à la projection orthogonale du plan que nous ajustons, et ce seuil de distance dans le plan est utilisé pour déterminer si le point appartient au sol
Sélection d'un ensemble de points de départ
Nous sélectionnons d'abord un ensemble de points de départ (ensemble de points de départ). Ces points de départ sont dérivés de points avec des hauteurs plus petites (c'est-à-dire des valeurs z) dans le nuage de points. modèle plan initial décrivant le sol Alors comment sélectionner ? Qu'en est-il de cette collection de graines ? Nous introduisons le concept de représentant du point le plus bas (LPR). LPR est la moyenne des points de hauteur les plus bas du NLPR garantit que l'étage de montage plan n'est pas affecté par le bruit de mesure.

Sélection des points de départ
L'entrée est un cadre de nuage de points. Les points de ce nuage de points ont été triés dans la direction z (c'est-à-dire la hauteur). Prenez num_lpr_ points minimum et trouvez. Obtenez la hauteur moyenne lpr_height (c'est-à-dire LPR) et sélectionnez le point avec une hauteur inférieure à lpr_height + th_seeds_ comme point de départ.
L'implémentation spécifique du code est la suivante
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
|
Modèle d'avion
Ensuite, nous construisons un modèle d'avion si la distance de projection orthogonale d'un point dans le nuage de points à ce plan est inférieure à la distance de projection orthogonale d'un point dans le nuage de points à ce plan. seuil Thdist, le point est considéré comme appartenant au sol, sinon il appartient au non-sol. Un modèle linéaire simple est utilisé pour l'estimation du modèle plan, comme suit :
ax+by+cz+d=0
soit :

où
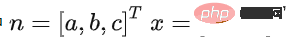
, par La matrice de covariance C de l'ensemble de points initial est utilisée pour résoudre n afin de déterminer un plan. L'ensemble de points de départ est utilisé comme ensemble de points initial, et sa matrice de covariance est
.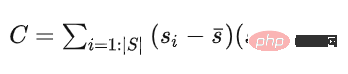
这个协方差矩阵 C 描述了种子点集的散布情况,其三个奇异向量可以通过奇异值分解(SVD)求得,这三个奇异向量描述了点集在三个主要方向的散布情况。由于是平面模型,垂直于平面的法向量 n 表示具有最小方差的方向,可以通过计算具有最小奇异值的奇异向量来求得。
那么在求得了 n 以后, d 可以通过代入种子点集的平均值 ,s(它代表属于地面的点) 直接求得。整个平面模型计算代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 |
|
优化平面主循环
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
|
得到这个初始的平面模型以后,我们会计算点云中每一个点到该平面的正交投影的距离,即 points * normal_,并且将这个距离与设定的阈值(即th_dist_d_) 比较,当高度差小于此阈值,我们认为该点属于地面,当高度差大于此阈值,则为非地面点。经过分类以后的所有地面点被当作下一次迭代的种子点集,迭代优化。
02 基于雷达数据本身特点的方法-Ray Ground Filter
代码
https://www.php.cn/link/a8d3b1e36a14da038a06f675d1693dd8
算法思想
Ray Ground Filter算法的核心是以射线(Ray)的形式来组织点云。将点云的 (x, y, z)三维空间降到(x,y)平面来看,计算每一个点到车辆x正方向的平面夹角 θ, 对360度进行微分,分成若干等份,每一份的角度为0.2度。
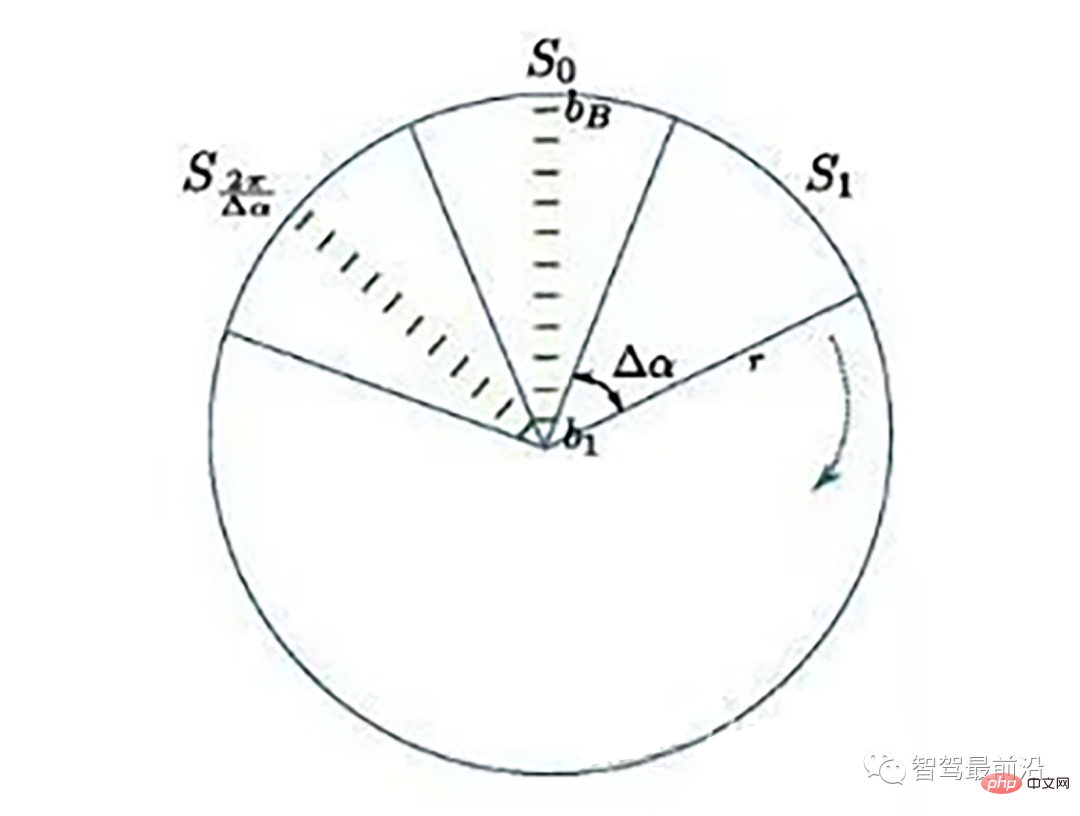
激光线束等间隔划分示意图(通常以激光雷达角度分辨率划分)
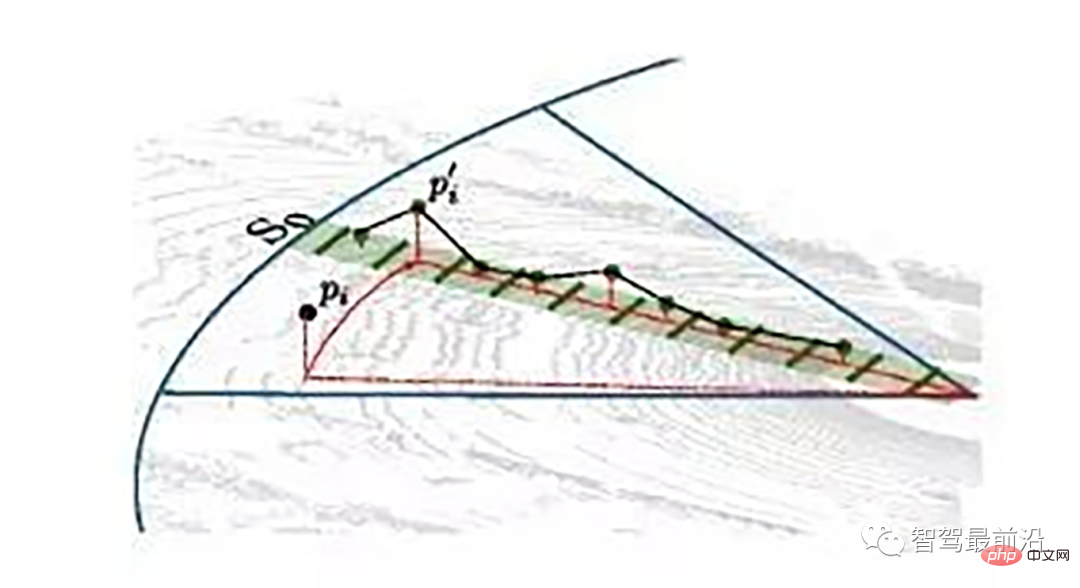
同一角度范围内激光线束在水平面的投影以及在Z轴方向的高度折线示意图
为了方便对同一角度的线束进行处理,要将原来直角坐标系的点云转换成柱坐标描述的点云数据结构。对同一夹角的线束上的点按照半径的大小进行排序,通过前后两点的坡度是否大于我们事先设定的坡度阈值,从而判断点是否为地面点。
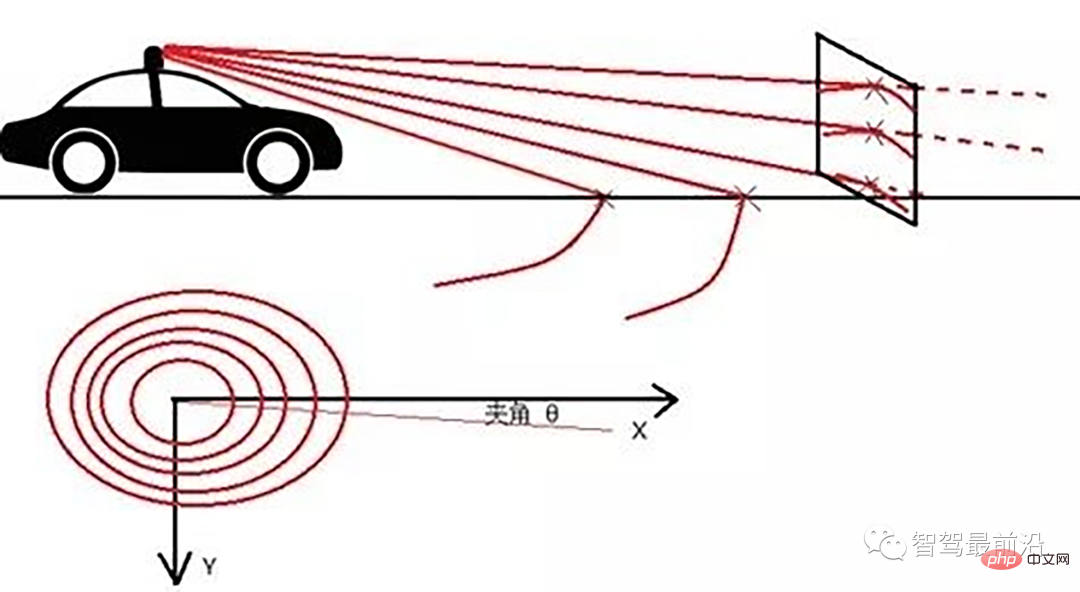
线激光线束纵截面与俯视示意图(n=4)
通过如下公式转换成柱坐标的形式:
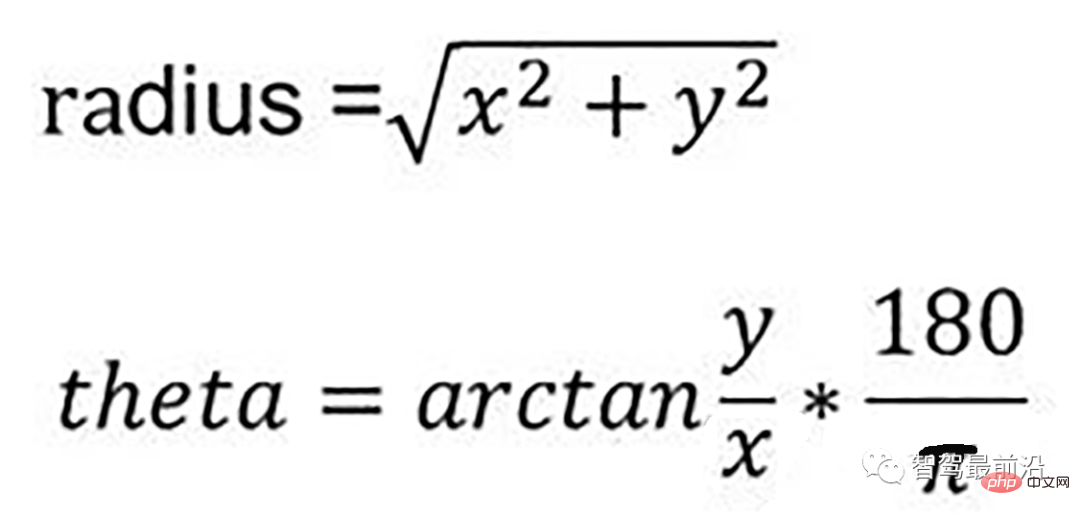
转换成柱坐标的公式
radius表示点到lidar的水平距离(半径),theta是点相对于车头正方向(即x方向)的夹角。对点云进行水平角度微分之后,可得到1800条射线,将这些射线中的点按照距离的远近进行排序。通过两个坡度阈值以及当前点的半径求得高度阈值,通过判断当前点的高度(即点的z值)是否在地面加减高度阈值范围内来判断当前点是为地面。
伪代码

伪代码
- local_max_slope_ :设定的同条射线上邻近两点的坡度阈值。
- general_max_slope_ :整个地面的坡度阈值
遍历1800条射线,对于每一条射线进行如下操作:
1.计算当前点和上一个点的水平距离pointdistance
2.根据local_max_slope_和pointdistance计算当前的坡度差阈值height_threshold
3.根据general_max_slope_和当前点的水平距离计算整个地面的高度差阈值general_height_threshold
4.若当前点的z坐标小于前一个点的z坐标加height_threshold并大于前一个点的z坐标减去height_threshold:
5.若当前点z坐标小于雷达安装高度减去general_height_threshold并且大于相加,认为是地面点
6.否则:是非地面点。
7.若pointdistance满足阈值并且前点的z坐标小于雷达安装高度减去height_threshold并大于雷达安装高度加上height_threshold,认为是地面点。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 |
|
03 基于雷达数据本身特点的方法-urban road filter
原文
Real-Time LIDAR-Based Urban Road and Sidewalk Detection for Autonomous Vehicles
代码
https://www.php.cn/link/305fa4e2c0e76dd586553d64c975a626
z_zero_method
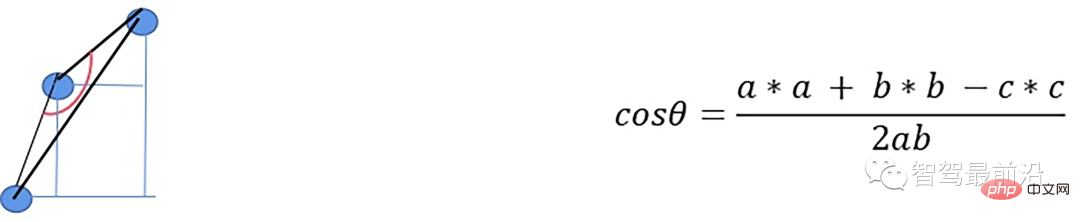
z_zero_method
首先将数据组织成[channels][thetas]
对于每一条线,对角度进行排序
- 以当前点p为中心,向左选k个点,向右选k个点
- 分别计算左边及右边k个点与当前点在x和y方向差值的均值
- 同时计算左边及右边k个点的最大z值max1及max2
- 根据余弦定理求解余弦角
如果余弦角度满足阈值且max1减去p.z满足阈值或max2减去p.z满足阈值且max2-max1满足阈值,认为此点为障碍物,否则就认为是地面点。
x_zero_method
X-zero和Z-zero方法可以找到避开测量的X和Z分量的人行道,X-zero和Z-zero方法都考虑了体素的通道数,因此激光雷达必须与路面平面不平行,这是上述两种算法以及整个城市道路滤波方法的已知局限性。X-zero方法去除了X方向的值,使用柱坐标代替。
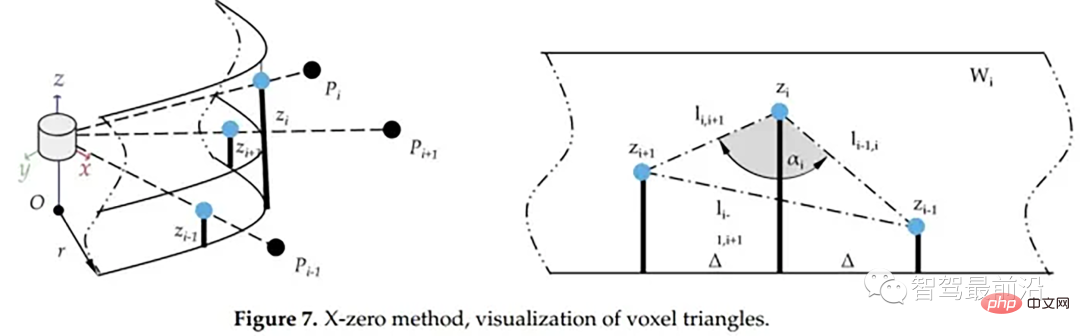
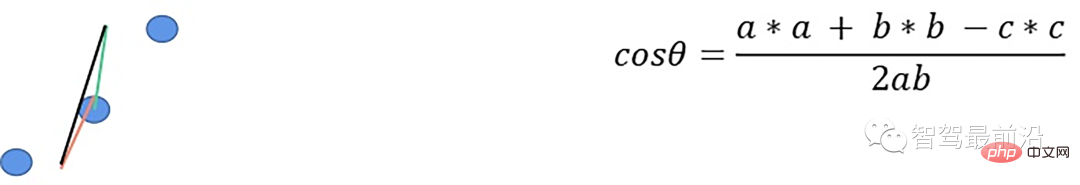
x_zero_method
首先将数据组织成[channels][thetas]
Pour chaque ligne, triez les angles
- Avec le point actuel p comme centre, sélectionnez le k/2ème point p1 et le kème point p2 à droite
- Calculez p et p1, p1 et p2 respectivement, la distance entre p et p2 dans la direction z
- Résolvez l'angle cosinus selon le théorème du cosinus
Si l'angle cosinus atteint le seuil et que p1.z-p.z atteint le seuil ou p1.z-p2 .z atteint le seuil et p.z- p2.z satisfait le seuil et considère ce point comme un obstacle
star_search_method
Cette méthode divise le nuage de points en segments rectangulaires, et la combinaison de ces formes ressemble à une étoile ; c'est de là que vient le nom, de chaque segment de route En extrayant les points de départ possibles du trottoir, l'algorithme créé est insensible aux changements de hauteur basés sur la coordonnée Z, ce qui signifie qu'en pratique l'algorithme fonctionnera bien même lorsque le lidar est incliné par rapport au plan de la surface de la route, dans un système de coordonnées cylindriques Traiter les nuages de points.
Mise en œuvre spécifique :
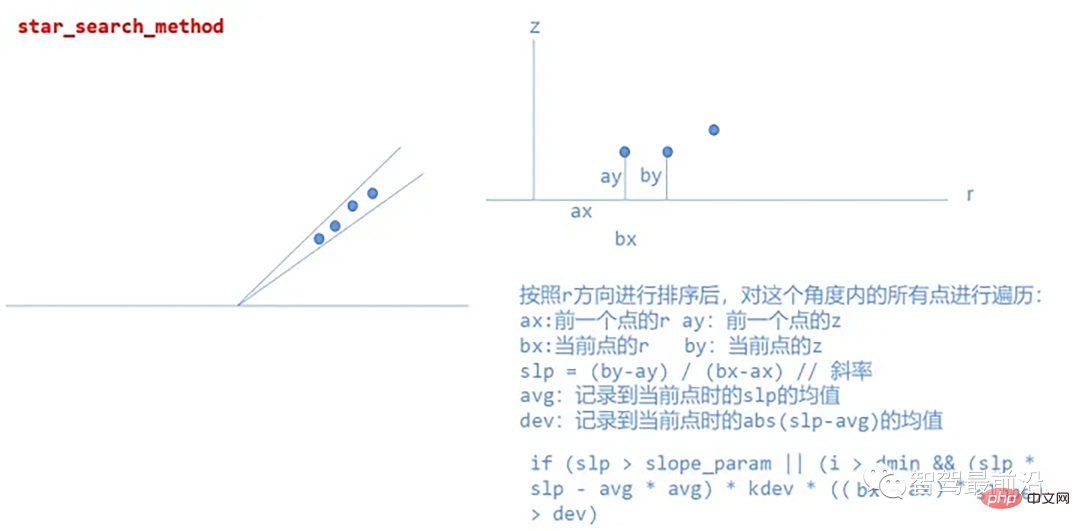
star_search_method
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.
Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Pourquoi le Gaussian Splatting est-il si populaire dans la conduite autonome que le NeRF commence à être abandonné ?
Jan 17, 2024 pm 02:57 PM
Pourquoi le Gaussian Splatting est-il si populaire dans la conduite autonome que le NeRF commence à être abandonné ?
Jan 17, 2024 pm 02:57 PM
Écrit ci-dessus et compréhension personnelle de l'auteur Le Gaussiansplatting tridimensionnel (3DGS) est une technologie transformatrice qui a émergé dans les domaines des champs de rayonnement explicites et de l'infographie ces dernières années. Cette méthode innovante se caractérise par l’utilisation de millions de gaussiennes 3D, ce qui est très différent de la méthode du champ de rayonnement neuronal (NeRF), qui utilise principalement un modèle implicite basé sur les coordonnées pour mapper les coordonnées spatiales aux valeurs des pixels. Avec sa représentation explicite de scènes et ses algorithmes de rendu différenciables, 3DGS garantit non seulement des capacités de rendu en temps réel, mais introduit également un niveau de contrôle et d'édition de scène sans précédent. Cela positionne 3DGS comme un révolutionnaire potentiel pour la reconstruction et la représentation 3D de nouvelle génération. À cette fin, nous fournissons pour la première fois un aperçu systématique des derniers développements et préoccupations dans le domaine du 3DGS.
 Comment résoudre le problème de la longue traîne dans les scénarios de conduite autonome ?
Jun 02, 2024 pm 02:44 PM
Comment résoudre le problème de la longue traîne dans les scénarios de conduite autonome ?
Jun 02, 2024 pm 02:44 PM
Hier, lors de l'entretien, on m'a demandé si j'avais posé des questions à longue traîne, j'ai donc pensé faire un bref résumé. Le problème à longue traîne de la conduite autonome fait référence aux cas extrêmes dans les véhicules autonomes, c'est-à-dire à des scénarios possibles avec une faible probabilité d'occurrence. Le problème perçu de la longue traîne est l’une des principales raisons limitant actuellement le domaine de conception opérationnelle des véhicules autonomes intelligents à véhicule unique. L'architecture sous-jacente et la plupart des problèmes techniques de la conduite autonome ont été résolus, et les 5 % restants des problèmes à longue traîne sont progressivement devenus la clé pour restreindre le développement de la conduite autonome. Ces problèmes incluent une variété de scénarios fragmentés, de situations extrêmes et de comportements humains imprévisibles. La « longue traîne » des scénarios limites dans la conduite autonome fait référence aux cas limites dans les véhicules autonomes (VA). Les cas limites sont des scénarios possibles avec une faible probabilité d'occurrence. ces événements rares
 Choisir une caméra ou un lidar ? Une étude récente sur la détection robuste d'objets 3D
Jan 26, 2024 am 11:18 AM
Choisir une caméra ou un lidar ? Une étude récente sur la détection robuste d'objets 3D
Jan 26, 2024 am 11:18 AM
0. Écrit à l'avant&& Compréhension personnelle que les systèmes de conduite autonome s'appuient sur des technologies avancées de perception, de prise de décision et de contrôle, en utilisant divers capteurs (tels que caméras, lidar, radar, etc.) pour percevoir l'environnement et en utilisant des algorithmes et des modèles pour une analyse et une prise de décision en temps réel. Cela permet aux véhicules de reconnaître les panneaux de signalisation, de détecter et de suivre d'autres véhicules, de prédire le comportement des piétons, etc., permettant ainsi de fonctionner en toute sécurité et de s'adapter à des environnements de circulation complexes. Cette technologie attire actuellement une grande attention et est considérée comme un domaine de développement important pour l'avenir des transports. . un. Mais ce qui rend la conduite autonome difficile, c'est de trouver comment faire comprendre à la voiture ce qui se passe autour d'elle. Cela nécessite que l'algorithme de détection d'objets tridimensionnels du système de conduite autonome puisse percevoir et décrire avec précision les objets dans l'environnement, y compris leur emplacement,
 Avez-vous vraiment maîtrisé la conversion des systèmes de coordonnées ? Des enjeux multi-capteurs indispensables à la conduite autonome
Oct 12, 2023 am 11:21 AM
Avez-vous vraiment maîtrisé la conversion des systèmes de coordonnées ? Des enjeux multi-capteurs indispensables à la conduite autonome
Oct 12, 2023 am 11:21 AM
Le premier article pilote et clé présente principalement plusieurs systèmes de coordonnées couramment utilisés dans la technologie de conduite autonome, et comment compléter la corrélation et la conversion entre eux, et enfin construire un modèle d'environnement unifié. L'objectif ici est de comprendre la conversion du véhicule en corps rigide de caméra (paramètres externes), la conversion de caméra en image (paramètres internes) et la conversion d'image en unité de pixel. La conversion de 3D en 2D aura une distorsion, une traduction, etc. Points clés : Le système de coordonnées du véhicule et le système de coordonnées du corps de la caméra doivent être réécrits : le système de coordonnées planes et le système de coordonnées des pixels Difficulté : la distorsion de l'image doit être prise en compte. La dé-distorsion et l'ajout de distorsion sont compensés sur le plan de l'image. 2. Introduction Il existe quatre systèmes de vision au total : système de coordonnées du plan de pixels (u, v), système de coordonnées d'image (x, y), système de coordonnées de caméra () et système de coordonnées mondiales (). Il existe une relation entre chaque système de coordonnées,
 Cet article vous suffit pour en savoir plus sur la conduite autonome et la prédiction de trajectoire !
Feb 28, 2024 pm 07:20 PM
Cet article vous suffit pour en savoir plus sur la conduite autonome et la prédiction de trajectoire !
Feb 28, 2024 pm 07:20 PM
La prédiction de trajectoire joue un rôle important dans la conduite autonome. La prédiction de trajectoire de conduite autonome fait référence à la prédiction de la trajectoire de conduite future du véhicule en analysant diverses données pendant le processus de conduite du véhicule. En tant que module central de la conduite autonome, la qualité de la prédiction de trajectoire est cruciale pour le contrôle de la planification en aval. La tâche de prédiction de trajectoire dispose d'une riche pile technologique et nécessite une connaissance de la perception dynamique/statique de la conduite autonome, des cartes de haute précision, des lignes de voie, des compétences en architecture de réseau neuronal (CNN&GNN&Transformer), etc. Il est très difficile de démarrer ! De nombreux fans espèrent se lancer dans la prédiction de trajectoire le plus tôt possible et éviter les pièges. Aujourd'hui, je vais faire le point sur quelques problèmes courants et des méthodes d'apprentissage introductives pour la prédiction de trajectoire ! Connaissances introductives 1. Existe-t-il un ordre d'entrée pour les épreuves de prévisualisation ? R : Regardez d’abord l’enquête, p
 SIMPL : un benchmark de prédiction de mouvement multi-agents simple et efficace pour la conduite autonome
Feb 20, 2024 am 11:48 AM
SIMPL : un benchmark de prédiction de mouvement multi-agents simple et efficace pour la conduite autonome
Feb 20, 2024 am 11:48 AM
Titre original : SIMPL : ASimpleandEfficientMulti-agentMotionPredictionBaselineforAutonomousDriving Lien article : https://arxiv.org/pdf/2402.02519.pdf Lien code : https://github.com/HKUST-Aerial-Robotics/SIMPL Affiliation de l'auteur : Université des sciences de Hong Kong et technologie Idée DJI Paper : cet article propose une base de référence de prédiction de mouvement (SIMPL) simple et efficace pour les véhicules autonomes. Par rapport au cent agent traditionnel
 NuScenes dernier SOTA SparseAD : les requêtes clairsemées contribuent à une conduite autonome efficace de bout en bout !
Apr 17, 2024 pm 06:22 PM
NuScenes dernier SOTA SparseAD : les requêtes clairsemées contribuent à une conduite autonome efficace de bout en bout !
Apr 17, 2024 pm 06:22 PM
Écrit à l'avant et point de départ Le paradigme de bout en bout utilise un cadre unifié pour réaliser plusieurs tâches dans les systèmes de conduite autonome. Malgré la simplicité et la clarté de ce paradigme, les performances des méthodes de conduite autonome de bout en bout sur les sous-tâches sont encore loin derrière les méthodes à tâche unique. Dans le même temps, les fonctionnalités de vue à vol d'oiseau (BEV) denses, largement utilisées dans les méthodes de bout en bout précédentes, rendent difficile l'adaptation à davantage de modalités ou de tâches. Un paradigme de conduite autonome de bout en bout (SparseAD) centré sur la recherche clairsemée est proposé ici, dans lequel la recherche clairsemée représente entièrement l'ensemble du scénario de conduite, y compris l'espace, le temps et les tâches, sans aucune représentation BEV dense. Plus précisément, une architecture clairsemée unifiée est conçue pour la connaissance des tâches, notamment la détection, le suivi et la cartographie en ligne. De plus, lourd
 Parlons des systèmes de conduite autonome de bout en bout et de nouvelle génération, ainsi que de quelques malentendus sur la conduite autonome de bout en bout ?
Apr 15, 2024 pm 04:13 PM
Parlons des systèmes de conduite autonome de bout en bout et de nouvelle génération, ainsi que de quelques malentendus sur la conduite autonome de bout en bout ?
Apr 15, 2024 pm 04:13 PM
Au cours du mois dernier, pour des raisons bien connues, j'ai eu des échanges très intensifs avec divers professeurs et camarades de classe du secteur. Un sujet inévitable dans l'échange est naturellement le populaire Tesla FSDV12 de bout en bout. Je voudrais profiter de cette occasion pour trier certaines de mes pensées et opinions en ce moment pour votre référence et votre discussion. Comment définir un système de conduite autonome de bout en bout et quels problèmes devraient être résolus de bout en bout ? Selon la définition la plus traditionnelle, un système de bout en bout fait référence à un système qui saisit les informations brutes des capteurs et génère directement les variables pertinentes pour la tâche. Par exemple, en reconnaissance d'images, CNN peut être appelé de bout en bout par rapport à la méthode traditionnelle d'extraction de caractéristiques + classificateur. Dans les tâches de conduite autonome, saisir les données de divers capteurs (caméra/LiDAR
