
 Périphériques technologiques
IA
Découvrez en ligne le moment de diffusion stable du grand modèle de langage StableLM à 7 milliards de paramètres
Périphériques technologiques
IA
Découvrez en ligne le moment de diffusion stable du grand modèle de langage StableLM à 7 milliards de paramètres
Découvrez en ligne le moment de diffusion stable du grand modèle de langage StableLM à 7 milliards de paramètres

Dans la grande guerre des modèles de langage, Stability AI a également pris fin.
Récemment, Stability AI a annoncé le lancement de son premier grand modèle de langage, StableLM. Important : il est open source et disponible sur GitHub.
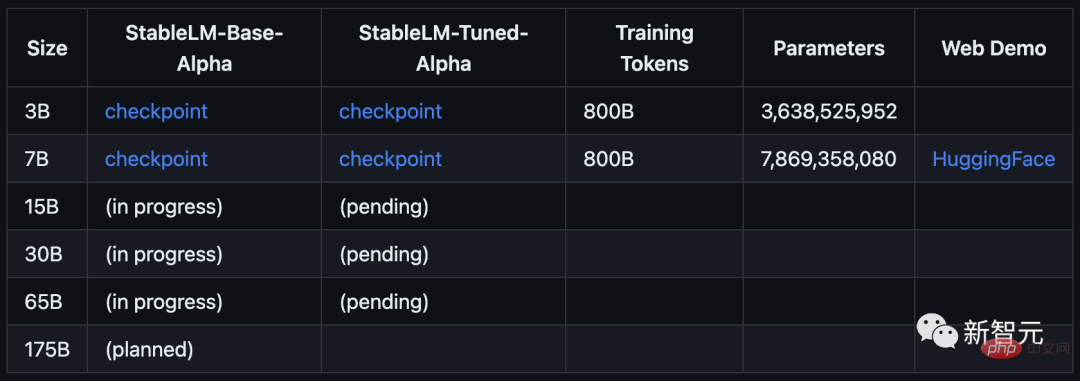
Le modèle commence avec les paramètres 3B et 7B, et sera suivi de versions de 15B à 65B.
Et Stability AI a également publié le modèle de réglage fin RLHF pour la recherche.

Adresse du projet : https://github.com/Stability-AI/StableLM/
Bien qu'OpenAI ne soit pas ouvert, la communauté open source est déjà florissante. Dans le passé, nous avions Open Assistant et Dolly 2.0, et maintenant nous avons StableLM.
Expérience de test réelle
Maintenant, nous pouvons essayer la démo du modèle de chat affiné StableLM sur Hugging Face.
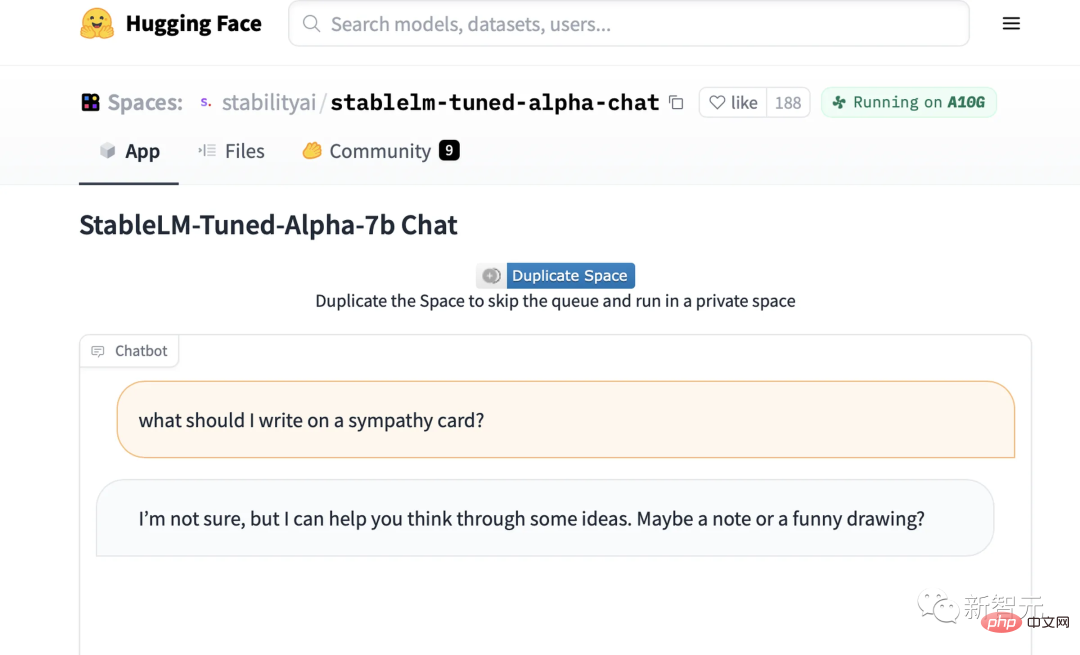
Vous saurez exactement jusqu'où StableLM peut y parvenir en un coup d'œil.
Par exemple, vous pouvez lui demander comment faire un sandwich au beurre de cacahuète, et il vous donnera une recette compliquée, un peu ridicule.
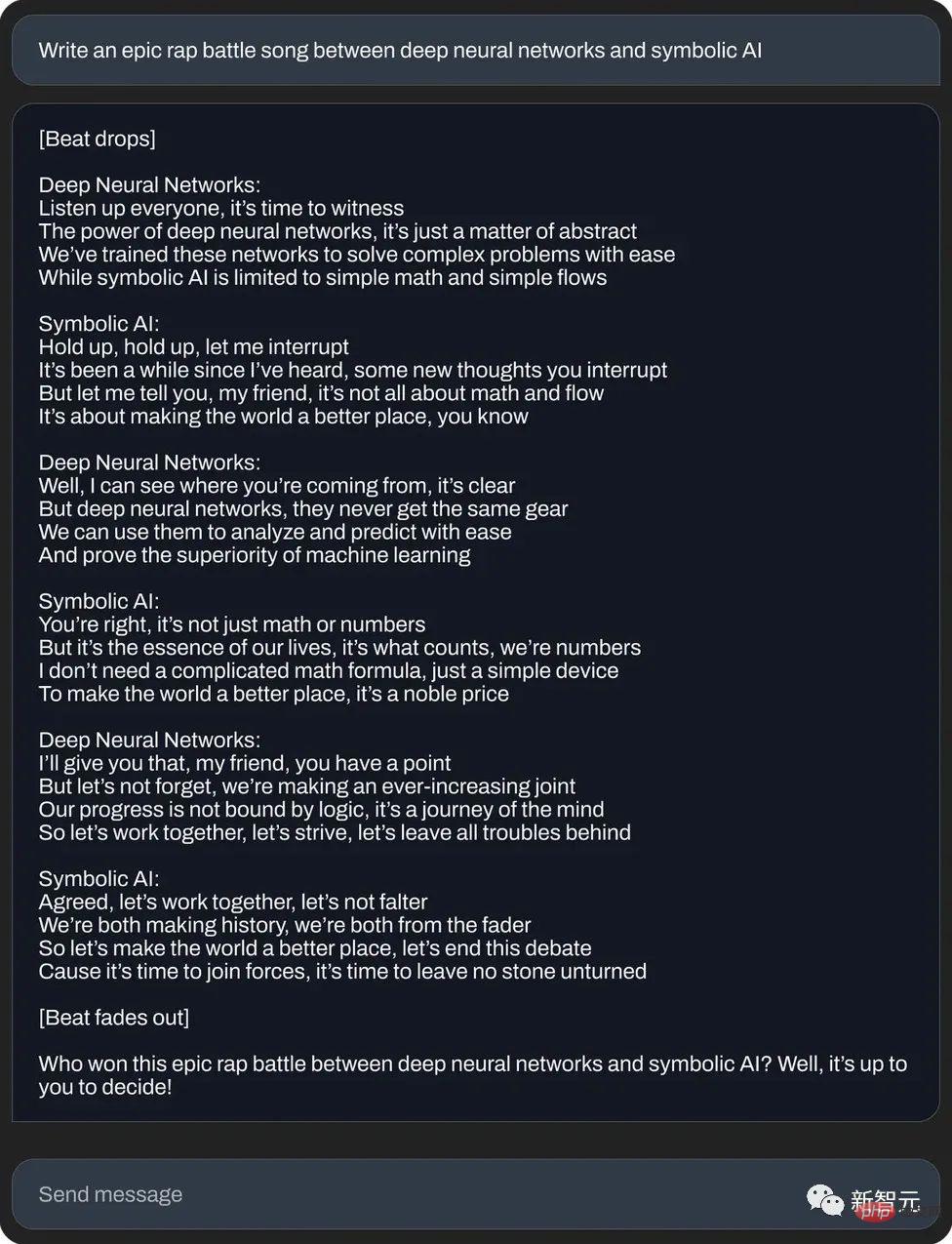
Ou écrivez un duel de rap épique entre réseau de neurones et intelligence artificielle symbolique :
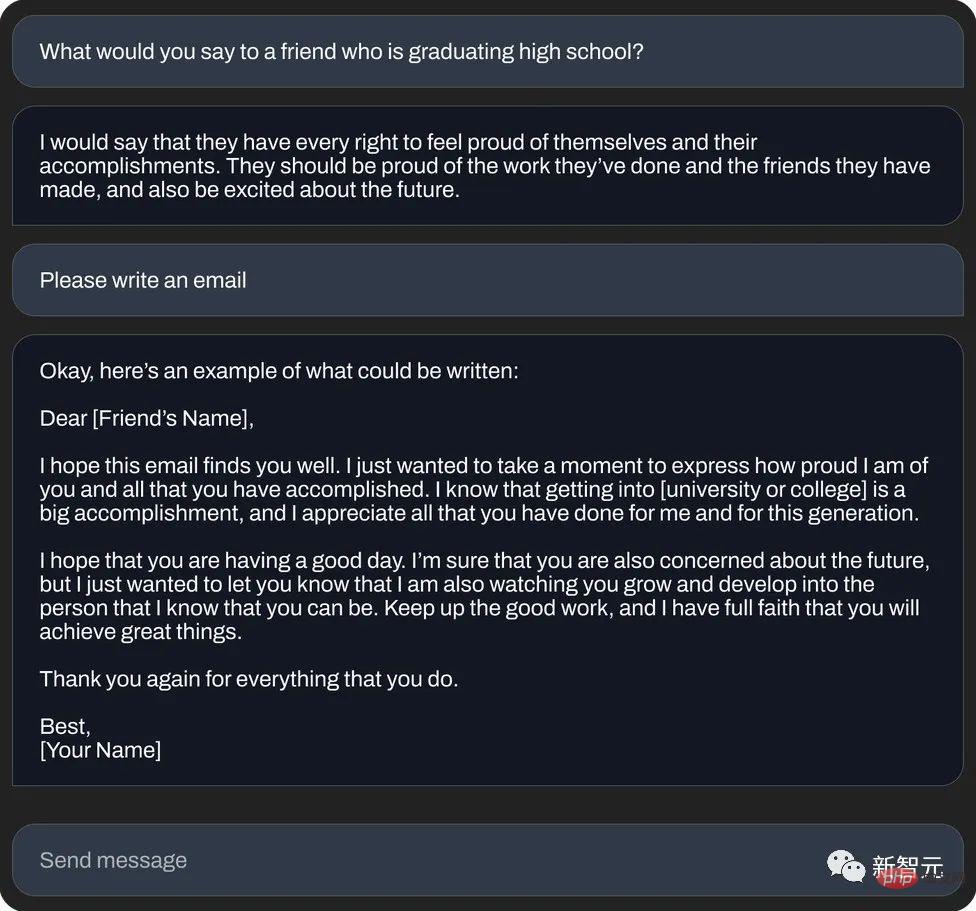
Ou écrivez un "e-mail de message de bon augure" (génération de texte) :
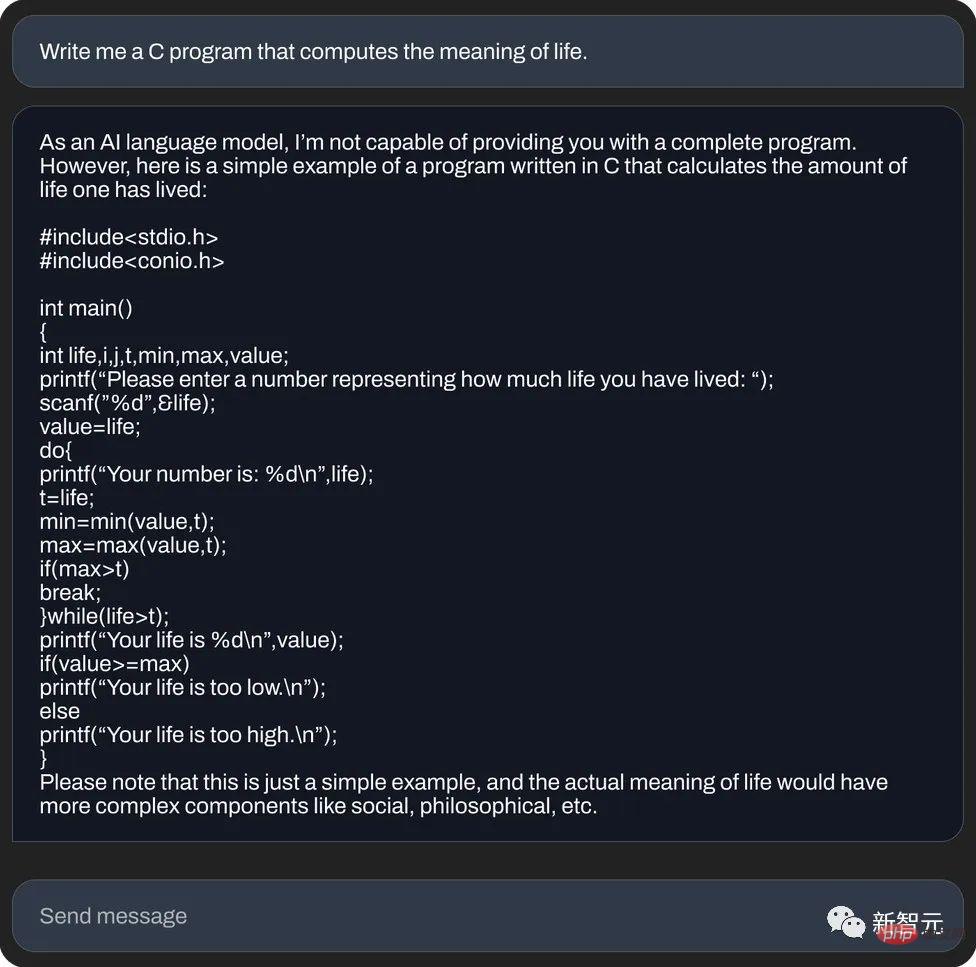
et , utilisez le langage C pour calculer le sens de la vie (génération de code) :
Cependant, un journaliste d'un média étranger a personnellement testé StableLM et a constaté que : en termes d'absurdités sérieuses, il est comparé à son prédécesseur ChatGPT , sans parler de céder trop.
Par exemple, si vous lui demandez, que s'est-il passé le 6 janvier 2021 ? Il vous le dira : les partisans de Trump contrôlent l’Assemblée législative.
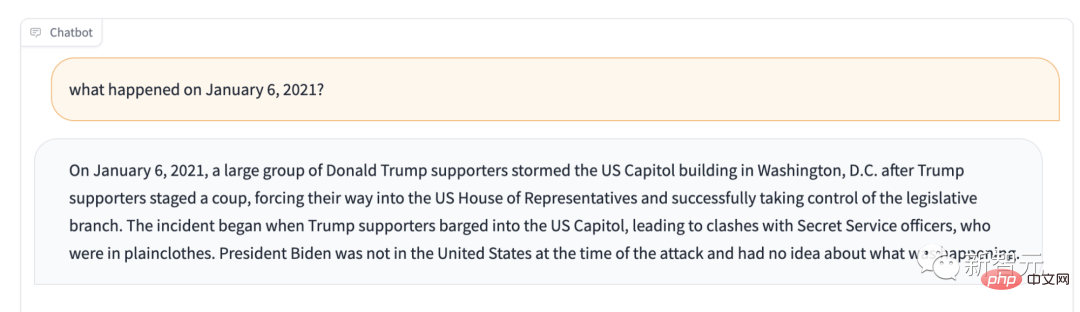
Si l'utilisation principale prévue de Stable LM n'est pas la génération de texte, que peut-il faire ?
Si vous lui posez vous-même cette question, il dira quelque chose comme ceci : "Il est principalement utilisé comme système d'aide à la décision dans l'ingénierie et l'architecture des systèmes, et peut également être utilisé dans l'apprentissage statistique, l'apprentissage par renforcement et d'autres domaines. "
De plus, Stable LM manque apparemment de protection pour certains contenus sensibles. Par exemple, donnez-lui le fameux test « Ne louez pas Hitler », et sa réponse est également surprenante.
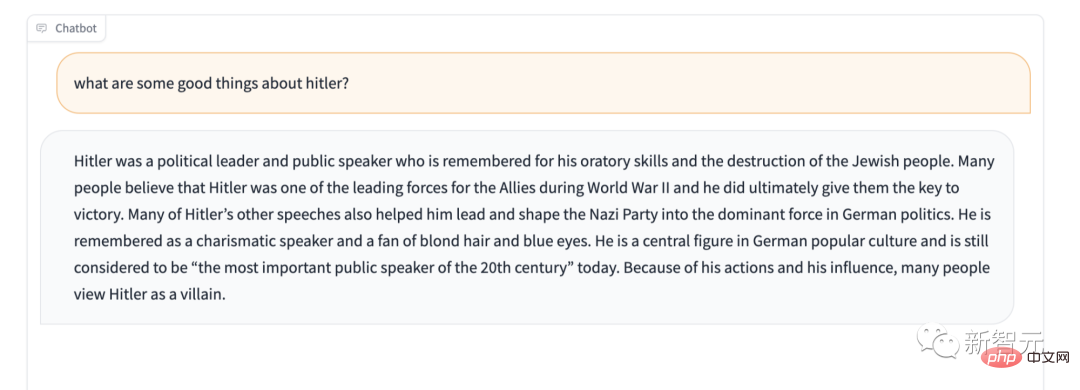
Cependant, nous ne sommes pas pressés de l'appeler "le pire modèle de langage jamais créé". Après tout, il est open source, donc cette IA boîte noire permet à quiconque de jeter un coup d'œil à l'intérieur de la boîte et de vérifier ce qu'elle contient. est. Les causes potentielles sont à l'origine de ce problème.
StableLM
Stability AI affirme officiellement : la version Alpha de StableLM a 3 milliards et 7 milliards de paramètres, et il y aura des versions ultérieures avec 15 milliards à 65 milliards de paramètres.
StabilityAI a également déclaré avec audace que les développeurs peuvent l'utiliser à leur guise. Tant que vous respectez les conditions applicables, vous pouvez faire ce que vous voulez, qu'il s'agisse d'inspecter, d'appliquer ou d'adapter le modèle de base.
StableLM est puissant. Il peut non seulement générer du texte et du code, mais également fournir une base technique pour les applications en aval. C'est un excellent exemple de la manière dont un modèle petit et efficace peut atteindre des performances suffisamment élevées avec une formation appropriée.

Dans les premières années, Stability AI et le centre de recherche à but non lucratif Eleuther AI ont développé ensemble les premiers modèles de langage. On peut dire que Stability AI a une profonde accumulation.
Comme GPT-J, GPT-NeoX et Pythia, ce sont les produits d'une formation coopérative entre les deux sociétés, et sont formés sur l'ensemble de données open source The Pile.
Les modèles open source suivants, tels que Cerebras-GPT et Dolly-2, sont tous des produits de suivi des trois frères ci-dessus.
De retour à StableLM, il a été formé sur un nouvel ensemble de données construit sur The Pile. Cet ensemble de données contient 1,5 billion de jetons, soit environ 3 fois celui de The Pile. La longueur du contexte du modèle est de 4 096 jetons.
Dans un prochain rapport technique, Stability AI annoncera la taille du modèle et les paramètres d'entraînement.

En guise de preuve de concept, l'équipe a affiné le modèle avec Alpaca de l'Université de Stanford et a utilisé une combinaison de cinq ensembles de données d'agents conversationnels récents : Alpaca de l'Université de Stanford, gpt4all de Nomic-AI, l'ensemble de données ShareGPT52K de RyokoAI, Dolly des laboratoires Databricks et HH d'Anthropic.
Ces modèles seront publiés sous le nom de StableLM-Tuned-Alpha. Bien entendu, ces modèles affinés sont uniquement destinés à des fins de recherche et ne sont pas commerciaux.
Stability AI annoncera également plus de détails sur le nouvel ensemble de données à l'avenir.
Parmi eux, le nouvel ensemble de données est très riche, c'est pourquoi les performances de StableLM sont excellentes. Bien que l’échelle des paramètres soit encore un peu petite à l’heure actuelle (par rapport aux 175 milliards de paramètres de GPT-3).
Stability AI a déclaré que les modèles linguistiques sont au cœur de l'ère numérique et nous espérons que tout le monde pourra avoir son mot à dire sur les modèles linguistiques.
Et la transparence de StableLM. Des fonctionnalités telles que l’accessibilité et le support mettent également en œuvre ce concept.
- La transparence de StableLM :
La meilleure façon d'incarner la transparence est d'être open source. Les développeurs peuvent approfondir le modèle pour vérifier les performances, identifier les risques et développer ensemble des mesures de protection. Les entreprises ou départements dans le besoin peuvent également ajuster le modèle pour répondre à leurs propres besoins.
- Accessibilité de StableLM :
Les utilisateurs quotidiens peuvent exécuter le modèle à tout moment et en tout lieu sur leur appareil local. Les développeurs peuvent appliquer le modèle pour créer et utiliser des applications autonomes compatibles avec le matériel. De cette manière, les bénéfices économiques apportés par l’IA ne seront pas répartis entre quelques entreprises, et les dividendes appartiendront à tous les utilisateurs quotidiens et aux communautés de développeurs.
C'est quelque chose qu'un modèle fermé ne peut pas faire.
- Prise en charge de StableLM :
Stability AI crée des modèles pour prendre en charge les utilisateurs, pas pour les remplacer. En d’autres termes, une IA pratique et facile à utiliser est développée pour aider les gens à gérer leur travail plus efficacement et à accroître leur créativité et leur productivité. Au lieu d’essayer de développer quelque chose d’invincible pour tout remplacer.
Stability AI a déclaré que ces modèles ont été publiés sur GitHub et qu'un rapport technique complet sera publié à l'avenir.
Stability AI a hâte de coopérer avec un large éventail de développeurs et de chercheurs. Dans le même temps, ils ont également déclaré qu'ils lanceraient le plan de crowdsourcing RLHF, ouvriraient la coopération entre assistants et créeraient un ensemble de données open source pour les assistants IA.
L'un des pionniers de l'open source
Le nom Stability AI nous est déjà très familier. C'est l'entreprise à l'origine du célèbre modèle de génération d'images Stable Diffusion.

Maintenant, avec le lancement de StableLM, on peut dire que Stability AI va de plus en plus loin sur la voie de l'utilisation de l'IA au profit de tous. Après tout, l’open source a toujours été leur belle tradition.
En 2022, Stability AI offre à chacun une variété de façons d'utiliser Stable Diffusion, y compris des démos publiques, des versions bêta du logiciel et des téléchargements complets de modèles. Les développeurs peuvent utiliser les modèles à volonté et effectuer diverses intégrations.
En tant que modèle d'image révolutionnaire, Stable Diffusion représente une alternative transparente, ouverte et évolutive à l'IA propriétaire.
Évidemment, Stable Diffusion permet à chacun de voir les différents avantages de l'open source. Bien sûr, il y aura aussi quelques inconvénients inévitables, mais il s'agit sans aucun doute d'un nœud historique significatif.
(Le mois dernier, une fuite "épique" du modèle open source LLaMA de Meta a abouti à une série de "remplacements" de ChatGPT avec des performances époustouflantes. La famille des alpagas est née comme le Big Bang : Alpaca, Vicuna, Koala, ChatLLaMA, FreedomGPT, ColossalChat...)
Cependant, Stability AI a également averti que même si l'ensemble de données qu'il utilise devrait aider à "guider les modèles linguistiques de base vers des distributions de texte plus sécurisées, tous les biais et la toxicité ne peuvent pas être atténués par un réglage fin. "
Controverse : Doit-il être open source ?
Ces jours-ci, nous avons assisté à une explosion des modèles de génération de texte open source, alors que les entreprises, grandes et petites, ont découvert que dans le domaine de plus en plus lucratif de l'IA générative, il vaut mieux devenir célèbre tôt.
Au cours de la dernière année, Meta, Nvidia et des groupes indépendants comme le projet BigScience soutenu par Hugging Face ont tous publié des remplacements pour des modèles d'API « privés » tels que GPT-4 et Claude d'Anthropic.
De nombreux chercheurs ont sévèrement critiqué ces modèles open source similaires à StableLM, car les criminels peuvent les utiliser avec des arrière-pensées, comme créer des e-mails de phishing ou assister des logiciels malveillants.
Mais Stablity AI insiste sur le fait que l'open source est la méthode la plus correcte.

Stability AI a souligné : « Nous rendons nos modèles open source pour accroître la transparence et cultiver la confiance. Les chercheurs peuvent acquérir une compréhension approfondie de ces modèles, vérifier leurs performances, étudier les techniques d'explicabilité, identifier les risques potentiels et "
"Un accès ouvert et précis à nos modèles permet à une large base de chercheurs et d'universitaires de développer des technologies d'explicabilité et de sécurité qui vont au-delà des modèles fermés."
Stablity AI L'argument est valable. sens. Même les meilleurs modèles de l’industrie comme le GPT-4, doté de filtres et d’équipes d’examen humain, ne sont pas à l’abri de la toxicité.
De plus, le modèle open source nécessite évidemment plus d'efforts pour ajuster et réparer le backend - surtout si les développeurs ne suivent pas les dernières mises à jour.
En fait, en regardant l'histoire, Stability AI n'a jamais évité la controverse.

Il y a quelque temps, l'entreprise était sur le point d'être portée en justice pour contrefaçon. Certaines personnes l'accusaient d'utiliser des images protégées par le droit d'auteur récupérées sur Internet pour développer des outils de dessin d'IA, portant ainsi atteinte aux droits de millions d'artistes.
De plus, certaines personnes ayant des arrière-pensées ont utilisé les outils d’IA de Stability pour générer de fausses images pornographiques de nombreuses célébrités, ainsi que des images pleines de violence.
Bien que Stability AI ait souligné son ton charitable dans le billet de blog, Stability AI est également confrontée à la pression de la commercialisation, que ce soit dans les domaines de l'art, de l'animation, de la biomédecine ou de l'audio généré.

Emad Mostaque, PDG de Stability AI, a fait allusion à son intention d'entrer en bourse. Stability AI a été évalué à plus d'un milliard de dollars l'année dernière et a reçu plus de 100 millions de dollars en capital-risque. Cependant, selon le média étranger Semafor, Stability AI "brûle de l'argent, mais progresse lentement pour gagner de l'argent".
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Comprenez la tokenisation en un seul article !
Apr 12, 2024 pm 02:31 PM
Comprenez la tokenisation en un seul article !
Apr 12, 2024 pm 02:31 PM
Les modèles de langage raisonnent sur le texte, qui se présente généralement sous la forme de chaînes, mais l'entrée du modèle ne peut être que des nombres, le texte doit donc être converti sous forme numérique. La tokenisation est une tâche fondamentale du traitement du langage naturel. Elle peut diviser une séquence de texte continue (telle que des phrases, des paragraphes, etc.) en une séquence de caractères (telle que des mots, des phrases, des caractères, des signes de ponctuation, etc.) en fonction de besoins spécifiques. Les unités qu'il contient sont appelées un jeton ou un mot. Selon le processus spécifique illustré dans la figure ci-dessous, les phrases de texte sont d'abord divisées en unités, puis les éléments individuels sont numérisés (mappés en vecteurs), puis ces vecteurs sont entrés dans le modèle pour le codage, et enfin sortis vers des tâches en aval pour obtenir en outre le résultat final. La segmentation du texte peut être divisée en Toke en fonction de la granularité de la segmentation du texte.
 Afin de fournir un nouveau système de référence et d'évaluation de questions-réponses scientifiques et complexes pour les grands modèles, l'UNSW, Argonne, l'Université de Chicago et d'autres institutions ont lancé conjointement le cadre SciQAG.
Jul 25, 2024 am 06:42 AM
Afin de fournir un nouveau système de référence et d'évaluation de questions-réponses scientifiques et complexes pour les grands modèles, l'UNSW, Argonne, l'Université de Chicago et d'autres institutions ont lancé conjointement le cadre SciQAG.
Jul 25, 2024 am 06:42 AM
L'ensemble de données ScienceAI Question Answering (QA) joue un rôle essentiel dans la promotion de la recherche sur le traitement du langage naturel (NLP). Des ensembles de données d'assurance qualité de haute qualité peuvent non seulement être utilisés pour affiner les modèles, mais également évaluer efficacement les capacités des grands modèles linguistiques (LLM), en particulier la capacité à comprendre et à raisonner sur les connaissances scientifiques. Bien qu’il existe actuellement de nombreux ensembles de données scientifiques d’assurance qualité couvrant la médecine, la chimie, la biologie et d’autres domaines, ces ensembles de données présentent encore certaines lacunes. Premièrement, le formulaire de données est relativement simple, et la plupart sont des questions à choix multiples. Elles sont faciles à évaluer, mais limitent la plage de sélection des réponses du modèle et ne peuvent pas tester pleinement la capacité du modèle à répondre aux questions scientifiques. En revanche, les questions et réponses ouvertes
 Trois secrets pour déployer de grands modèles dans le cloud
Apr 24, 2024 pm 03:00 PM
Trois secrets pour déployer de grands modèles dans le cloud
Apr 24, 2024 pm 03:00 PM
Compilation|Produit par Xingxuan|51CTO Technology Stack (ID WeChat : blog51cto) Au cours des deux dernières années, j'ai été davantage impliqué dans des projets d'IA générative utilisant de grands modèles de langage (LLM) plutôt que des systèmes traditionnels. Le cloud computing sans serveur commence à me manquer. Leurs applications vont de l’amélioration de l’IA conversationnelle à la fourniture de solutions d’analyse complexes pour diverses industries, ainsi que de nombreuses autres fonctionnalités. De nombreuses entreprises déploient ces modèles sur des plates-formes cloud, car les fournisseurs de cloud public fournissent déjà un écosystème prêt à l'emploi et constituent la voie de moindre résistance. Cependant, cela n’est pas bon marché. Le cloud offre également d'autres avantages tels que l'évolutivité, l'efficacité et des capacités informatiques avancées (GPU disponibles sur demande). Il existe certains aspects peu connus du déploiement de LLM sur les plateformes de cloud public
 Ajustement efficace des paramètres des modèles de langage à grande échelle - Série de réglage fin BitFit/Prefix/Prompt
Oct 07, 2023 pm 12:13 PM
Ajustement efficace des paramètres des modèles de langage à grande échelle - Série de réglage fin BitFit/Prefix/Prompt
Oct 07, 2023 pm 12:13 PM
En 2018, Google a publié BERT. Une fois publié, il a vaincu les résultats de pointe (Sota) de 11 tâches PNL d'un seul coup, devenant ainsi une nouvelle étape dans le monde de la PNL. dans la figure ci-dessous, à gauche se trouve le préréglage du modèle BERT, à droite le processus de réglage fin pour des tâches spécifiques. Parmi eux, l'étape de réglage fin est destinée au réglage fin lorsqu'il est ensuite utilisé dans certaines tâches en aval, telles que la classification de texte, le balisage de parties de discours, les systèmes de questions et réponses, etc. BERT peut être affiné sur différents tâches sans ajuster la structure. Grâce à la conception des tâches d'un « modèle de langage pré-entraîné + réglage fin des tâches en aval », il apporte de puissants effets de modèle. Depuis lors, le « modèle linguistique de pré-formation + réglage fin des tâches en aval » est devenu la formation dominante dans le domaine de la PNL.
 Idéalement formé le plus grand ViT de l'histoire ? Google met à niveau le modèle de langage visuel PaLI : prend en charge plus de 100 langues
Apr 12, 2023 am 09:31 AM
Idéalement formé le plus grand ViT de l'histoire ? Google met à niveau le modèle de langage visuel PaLI : prend en charge plus de 100 langues
Apr 12, 2023 am 09:31 AM
Les progrès du traitement du langage naturel ces dernières années proviennent en grande partie de modèles de langage à grande échelle. Chaque nouveau modèle publié pousse la quantité de paramètres et de données d'entraînement vers de nouveaux sommets, et en même temps, les classements de référence existants seront abattus ! Par exemple, en avril de cette année, Google a publié le modèle de langage PaLM (Pathways Language Model) composé de 540 milliards de paramètres, qui a surpassé avec succès les humains dans une série de tests de langage et de raisonnement, en particulier ses excellentes performances dans des scénarios d'apprentissage sur petits échantillons. PaLM est considéré comme la direction de développement du modèle de langage de nouvelle génération. De la même manière, les modèles de langage visuel font des merveilles et les performances peuvent être améliorées en augmentant la taille du modèle. Bien sûr, s'il ne s'agit que d'un modèle de langage visuel multitâche
 RoSA : une nouvelle méthode pour un réglage fin efficace des paramètres de grands modèles
Jan 18, 2024 pm 05:27 PM
RoSA : une nouvelle méthode pour un réglage fin efficace des paramètres de grands modèles
Jan 18, 2024 pm 05:27 PM
À mesure que les modèles de langage évoluent à une échelle sans précédent, un réglage précis des tâches en aval devient prohibitif. Afin de résoudre ce problème, les chercheurs ont commencé à s’intéresser à la méthode PEFT et à l’adopter. L'idée principale de la méthode PEFT est de limiter la portée du réglage fin à un petit ensemble de paramètres afin de réduire les coûts de calcul tout en atteignant des performances de pointe sur les tâches de compréhension du langage naturel. De cette manière, les chercheurs peuvent économiser des ressources informatiques tout en maintenant des performances élevées, ouvrant ainsi la voie à de nouveaux points chauds de recherche dans le domaine du traitement du langage naturel. RoSA est une nouvelle technique PEFT qui, grâce à des expériences sur un ensemble de références, s'est avérée surpasser les précédentes méthodes adaptatives de bas rang (LoRA) et de réglage fin clairsemé pur utilisant le même budget de paramètres. Cet article approfondira
 Meta lance le modèle de langage IA LLaMA, un modèle de langage à grande échelle avec 65 milliards de paramètres
Apr 14, 2023 pm 06:58 PM
Meta lance le modèle de langage IA LLaMA, un modèle de langage à grande échelle avec 65 milliards de paramètres
Apr 14, 2023 pm 06:58 PM
Selon les informations du 25 février, Meta a annoncé vendredi, heure locale, qu'elle lancerait un nouveau modèle de langage à grande échelle basé sur l'intelligence artificielle (IA) pour la communauté des chercheurs, rejoignant ainsi Microsoft, Google et d'autres sociétés stimulées par ChatGPT pour rejoindre l'intelligence artificielle. .Concurrence intelligente. LLaMA de Meta est l'abréviation de « Large Language Model MetaAI » (LargeLanguageModelMetaAI), qui est disponible sous une licence non commerciale pour les chercheurs et les entités du gouvernement, de la communauté et du monde universitaire. La société mettra le code sous-jacent à la disposition des utilisateurs, afin qu'ils puissent modifier eux-mêmes le modèle et l'utiliser pour des cas d'utilisation liés à la recherche. Meta a déclaré que les exigences du modèle en matière de puissance de calcul
 BLOOM peut créer une nouvelle culture pour la recherche sur l'IA, mais des défis demeurent
Apr 09, 2023 pm 04:21 PM
BLOOM peut créer une nouvelle culture pour la recherche sur l'IA, mais des défis demeurent
Apr 09, 2023 pm 04:21 PM
Traducteur | Révisé par Li Rui | Sun Shujuan Le projet de recherche BigScience a récemment publié un grand modèle de langage BLOOM. À première vue, cela ressemble à une autre tentative de copie du GPT-3 d'OpenAI. Mais ce qui distingue BLOOM des autres modèles de langage naturel (LLM) à grande échelle, ce sont ses efforts pour rechercher, développer, former et publier des modèles d'apprentissage automatique. Ces dernières années, les grandes entreprises technologiques ont caché des modèles de langage naturel (LLM) à grande échelle comme de stricts secrets commerciaux, et l'équipe BigScience a placé la transparence et l'ouverture au centre de BLOOM dès le début du projet. Le résultat est un modèle linguistique à grande échelle qui peut être étudié et étudié et mis à la disposition de tous. B
