
 Périphériques technologiques
IA
Une nouvelle recherche menée par l'équipe de Stanford Li Feifei a révélé que la conception, l'amélioration et l'évaluation des données sont les clés pour parvenir à une intelligence artificielle fiable.
Périphériques technologiques
IA
Une nouvelle recherche menée par l'équipe de Stanford Li Feifei a révélé que la conception, l'amélioration et l'évaluation des données sont les clés pour parvenir à une intelligence artificielle fiable.
Une nouvelle recherche menée par l'équipe de Stanford Li Feifei a révélé que la conception, l'amélioration et l'évaluation des données sont les clés pour parvenir à une intelligence artificielle fiable.

Avec la tendance actuelle du développement de modèles d'IA passant d'un modèle centré à un modèle centré sur les données, la qualité des données est devenue particulièrement importante.
Dans le processus de développement passé de l'IA, l'ensemble de données est généralement fixe et le travail de développement se concentre sur l'itération de l'architecture du modèle ou du processus de formation pour améliorer les performances de base. Désormais, alors que l’itération des données occupe une place centrale, nous avons besoin de moyens plus systématiques pour évaluer, filtrer, nettoyer et annoter les données utilisées pour entraîner et tester les modèles d’IA.
Récemment, Weixin Liang, Li Feifei et d'autres du Département d'informatique de l'Université de Stanford ont publié conjointement un article intitulé « Avances, défis et opportunités dans la création de données pour une IA fiable » dans « Nature-Machine Intelligence », dans AI Data Key. les facteurs et les méthodes permettant de garantir la qualité des données sont discutés à chaque maillon de l’ensemble du processus.

Adresse papier : https://www.nature.com/articles/s42256-022-00516-1.epdf?sharing_token=VPzI-KWAm8tLG_BiXJnV9tRgN0jAjWel9jnR3ZoTv0MRS1pu9dXg73FQ0NTrwhu7Hi_V BEr 6peszIAFc6XO1tdlvV1lLJQtOvUFnSXpvW6_nu0Knc_dRekx6lyZNc6PcM1nslocIcut_qNW9OUg1IsbCfuL058R4MsYFqyzlb2E%3D
Les principales étapes du flux de données de l'IA comprennent : la conception des données (collecte et enregistrement des données), l'amélioration des données (criblage des données, nettoyage, annotation, amélioration) et les stratégies de données pour l'évaluation et la surveillance des modèles d'IA, dont chacune affectera la crédibilité du modèle d'IA final.
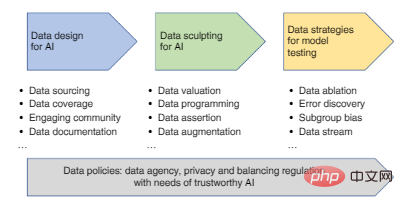
Figure 1 : Feuille de route pour développer une approche centrée sur les données, de la conception des données à l'évaluation.
1. Conception de données pour l'IA
Après avoir identifié une application d'intelligence artificielle, la première étape du développement d'un modèle d'IA consiste à concevoir les données (c'est-à-dire identifier et enregistrer la source des données).
La conception doit être un processus itératif : utiliser des données expérimentales pour développer un modèle d'IA initial, puis collecter des données supplémentaires pour corriger les limites du modèle. Les critères clés de conception sont de garantir que les données sont adaptées à la tâche et couvrent une portée suffisante pour représenter les différents utilisateurs et scénarios que le modèle peut rencontrer.
Et les ensembles de données actuellement utilisés pour développer l’IA ont souvent une couverture limitée ou sont biaisés. Dans l’IA médicale, par exemple, la collecte de données sur les patients utilisée pour développer des algorithmes est répartie géographiquement de manière disproportionnée, ce qui peut limiter l’applicabilité des modèles d’IA à différentes populations.
Une façon d'améliorer la couverture des données consiste à impliquer la communauté au sens large dans la création des données. En témoigne le projet Common Voice, le plus grand ensemble de données publiques actuellement disponible, qui contient 11 192 heures de transcriptions vocales en 76 langues provenant de plus de 166 000 participants.
Et lorsque des données représentatives sont difficiles à obtenir, des données synthétiques peuvent être utilisées pour combler le déficit de couverture. Par exemple, la collecte de visages réels implique souvent des problèmes de confidentialité et des biais d’échantillonnage, tandis que les visages synthétiques créés par des modèles génératifs profonds sont désormais utilisés pour atténuer le déséquilibre et les biais des données. Dans le domaine de la santé, les dossiers médicaux synthétiques peuvent être partagés pour faciliter la découverte de connaissances sans divulguer les informations réelles sur les patients. En robotique, les défis du monde réel constituent le banc d'essai ultime, et des environnements de simulation haute fidélité peuvent être utilisés pour permettre aux agents d'apprendre plus rapidement et de manière plus sûre sur des tâches complexes et à long terme.
Mais il y a aussi quelques problèmes avec les données synthétiques. Il existe toujours un écart entre les données synthétiques et les données du monde réel. Ainsi, lorsqu'un modèle d'IA formé sur des données synthétiques est transféré dans le monde réel, une dégradation des performances se produit souvent. Les données synthétiques peuvent également exacerber les disparités entre les données si les simulateurs ne sont pas conçus en tenant compte des groupes minoritaires. Les performances des modèles d'IA dépendent fortement du contexte de leurs données de formation et d'évaluation. Il est donc important de documenter le contexte de la conception des données de manière standardisée et. rapports transparents.
Maintenant, les chercheurs ont créé diverses « étiquettes nutritionnelles de données » pour capturer des métadonnées sur le processus de conception et d'annotation des données. Les métadonnées utiles incluent des statistiques sur le sexe, le genre, la race et la situation géographique des participants dans l'ensemble de données, qui peuvent aider à découvrir s'il existe des sous-groupes sous-représentés qui ne sont pas couverts. La provenance des données est également un type de métadonnées qui suit la source et l'heure des données ainsi que les processus et méthodes qui ont produit les données.
Les métadonnées peuvent être enregistrées dans un document de conception de données dédié, ce qui est très important pour observer le cycle de vie et le contexte socio-technique des données. Les documents peuvent être téléchargés vers des référentiels de données stables et centralisés tels que Zenodo.
2. Améliorer les données : filtrer, nettoyer, étiqueter, améliorer
Une fois l'ensemble de données initial collecté, nous devons encore améliorer les données afin de fournir des données plus efficaces pour le développement de l'IA. C'est la principale différence entre les approches d'IA centrées sur les modèles et les approches centrées sur les données, comme le montre la figure 2a. La recherche centrée sur les modèles est généralement basée sur des données données et se concentre sur l'amélioration de l'architecture du modèle ou l'optimisation de ces données. La recherche centrée sur les données, quant à elle, se concentre sur des méthodes évolutives pour améliorer systématiquement les données grâce à des processus tels que le nettoyage, le filtrage, l'annotation et l'amélioration des données, et peut utiliser une plateforme de développement de modèles unique.

Figure 2a : Comparaison des approches centrées sur les modèles d'IA et centrées sur les données. MNIST, COCO et ImageNet sont des ensembles de données couramment utilisés dans la recherche sur l'IA.
Criblage des données
Si l'ensemble de données est très bruyant, nous devons soigneusement filtrer les données avant la formation, ce qui peut améliorer considérablement la fiabilité et la généralisation du modèle. L'image de l'avion sur la figure 2a est le point de données bruyant qui doit être supprimé de l'ensemble de données sur les oiseaux.
Dans la figure 2b, quatre modèles de pointe formés sur des données dermatologiques volumineuses précédemment utilisées fonctionnent tous mal en raison de biais dans les données de formation, avec un diagnostic particulièrement mauvais sur des images de peau foncée, tandis que le modèle 1, formé sur des images plus petites, des données de haute qualité, sont relativement plus fiables sur les peaux foncées et claires.
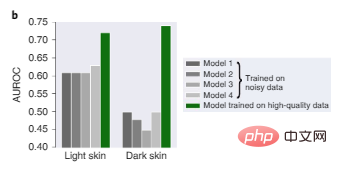
Figure 2b : Performances des tests de diagnostic dermatologique sur des images de peau claire et de peau foncée.
La figure 2c montre que ResNet, DenseNet et VGG, trois architectures d'apprentissage en profondeur populaires pour la classification d'images, fonctionnent toutes mal si elles sont entraînées sur des ensembles de données d'images bruyantes. Après filtrage par la valeur Shapley des données, les données de mauvaise qualité sont supprimées. À ce stade, les performances du modèle ResNet formé sur un sous-ensemble de données plus propre sont nettement meilleures.
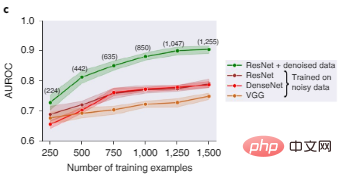
Figure 2c : Comparaison des performances des tests de reconnaissance d'objets de différents modèles avant et après le filtrage des données. Les nombres entre parenthèses représentent le nombre de points de données d'entraînement restants après filtrage des données bruyantes, avec des résultats regroupés sur cinq valeurs aléatoires, et la zone ombrée représente l'intervalle de confiance de 95 %.
C'est à cela que sert l'évaluation des données, elle vise à quantifier l'importance de différentes données et à filtrer les données qui peuvent nuire aux performances du modèle en raison d'une mauvaise qualité ou d'un biais.
Nettoyage des données
Dans cet article, l'auteur présente deux méthodes d'évaluation des données pour aider à nettoyer les données :
Une méthode consiste à mesurer le changement dans les performances du modèle d'IA lorsque différentes données sont supprimées pendant le processus de formation, ce qui peut utiliser Shapley de la valeur des données ou de l’approximation de l’influence, comme le montre la figure 3a ci-dessous. Cette approche permet une évaluation informatique efficace des grands modèles d’IA.
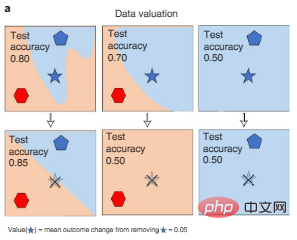
Figure 3a : Évaluation des données. La valeur Shapley des données mesure le changement de performance d'un modèle formé sur différents sous-ensembles de données lorsqu'un point spécifique est supprimé de la formation (l'étoile à cinq branches fanée barrée sur la figure), quantifiant ainsi chaque point de données (le symbole étoile à cinq branches). Les couleurs représentent les étiquettes de catégorie.
Une autre approche consiste à prédire l'incertitude pour détecter des points de données de mauvaise qualité. Les annotations humaines des points de données peuvent systématiquement s'écarter des prédictions du modèle d'IA, et les algorithmes d'apprentissage de la confiance peuvent détecter ces écarts, avec plus de 3 % des données de test qui sont mal étiquetées sur des références courantes comme ImageNet. Le filtrage de ces erreurs peut grandement améliorer les performances du modèle.
Annotation des données
L'annotation des données est également une source majeure de biais dans les données. Bien que les modèles d’IA puissent tolérer un certain niveau de bruit d’étiquette aléatoire, les erreurs biaisées produisent des modèles biaisés. Actuellement, nous nous appuyons principalement sur l'annotation manuelle, qui est très coûteuse. Par exemple, le coût de l'annotation d'un seul scan LIDAR peut dépasser 30 $. Puisqu'il s'agit de données tridimensionnelles, l'annotateur doit dessiner un cadre de délimitation tridimensionnel, ce qui est nécessaire. est plus exigeant que les tâches d'annotation générales.
Par conséquent, l'auteur estime que nous devons soigneusement calibrer les outils d'annotation sur les plateformes de crowdsourcing telles que MTurk pour fournir des règles d'annotation cohérentes. Dans le milieu médical, il est également important de considérer que les annotateurs peuvent nécessiter des connaissances spécialisées ou disposer de données sensibles qui ne peuvent pas être externalisées.
Une façon de réduire le coût de l'annotation est la programmation des données. Dans la programmation de données, les développeurs d’IA n’ont plus besoin d’étiqueter manuellement les points de données, mais plutôt d’écrire des fonctions d’étiquetage programmatiques pour étiqueter automatiquement les ensembles d’apprentissage. Comme le montre la figure 3b, après avoir généré automatiquement plusieurs étiquettes potentiellement bruyantes pour chaque entrée à l'aide d'une fonction d'étiquette définie par l'utilisateur, nous pouvons concevoir des algorithmes supplémentaires pour regrouper plusieurs fonctionnalités d'étiquette afin de réduire le bruit.
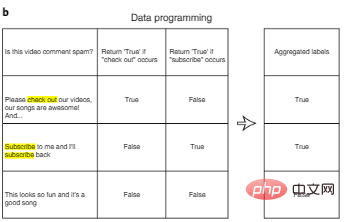
Figure 3b : Programmation des données.
Une autre approche « humaine dans la boucle » pour réduire les coûts d'étiquetage consiste à donner la priorité aux données les plus précieuses afin que nous puissions les étiqueter grâce à un apprentissage actif. L'apprentissage actif tire des idées d'une conception expérimentale optimale. Dans l'apprentissage actif, l'algorithme sélectionne les points les plus informatifs à partir d'un ensemble de points de données non étiquetés, tels que les points avec un gain d'informations élevé ou les points sur lesquels le modèle présente une incertitude, puis effectue une exécution manuelle. annotation. L’avantage de cette approche est que la quantité de données requise est bien inférieure à celle requise pour l’apprentissage supervisé standard.
Augmentation des données
Enfin, lorsque les données existantes sont encore très limitées, l'augmentation des données est une méthode efficace pour élargir l'ensemble de données et améliorer la fiabilité du modèle.
Les données de vision par ordinateur peuvent être améliorées par la rotation de l'image, le retournement et d'autres transformations numériques, et les données de texte peuvent être améliorées en transformant les styles d'écriture automatique. Il existe également le récent Mixup, une technique d'augmentation plus complexe qui crée de nouvelles données d'entraînement en interpolant des paires d'échantillons d'entraînement, comme le montre la figure 3c.
En plus de l'amélioration manuelle des données, le processus actuel d'amélioration automatisée des données par l'IA est également une solution populaire. De plus, lorsque des données non étiquetées sont disponibles, l'augmentation des étiquettes peut également être obtenue en utilisant un modèle initial pour faire des prédictions (ces prédictions sont appelées pseudo-étiquettes), puis en entraînant un modèle plus large sur les données combinées avec des pseudo-étiquettes réelles et de haute confiance. étiquettes.
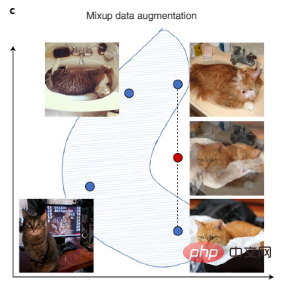
Figure 3c : Mixup augmente l'ensemble de données en créant des données synthétiques qui interpolent les données existantes. Les points bleus représentent les points de données existants dans l'ensemble d'apprentissage et les points rouges représentent les points de données synthétiques créés en interpolant deux points de données existants.
3. Données pour l'évaluation et le suivi des modèles d'IA
Une fois le modèle formé, l'objectif de l'évaluation de l'IA est la généralisabilité et la crédibilité du modèle.
Pour atteindre cet objectif, nous devons concevoir soigneusement les données d'évaluation pour trouver les paramètres du monde réel du modèle, et les données d'évaluation doivent également être suffisamment différentes des données d'entraînement du modèle.
Par exemple, dans la recherche médicale, les modèles d'IA sont généralement formés sur la base des données d'un petit nombre d'hôpitaux. Lorsqu’un tel modèle est déployé dans un nouvel hôpital, sa précision diminuera en raison des différences dans la collecte et le traitement des données. Afin d'évaluer la généralisation du modèle, il est nécessaire de collecter des données d'évaluation provenant de différents hôpitaux et de différents pipelines de traitement de données. Dans d'autres applications, les données d'évaluation doivent être collectées à partir de différentes sources, de préférence étiquetées comme données de formation par différents annotateurs. Dans le même temps, les étiquettes humaines de haute qualité restent l’évaluation la plus importante.
Un rôle important de l'évaluation de l'IA est de déterminer si le modèle d'IA utilise de fausses corrélations comme « raccourcis » dans les données d'entraînement qui ne peuvent pas bien former des concepts. Par exemple, en imagerie médicale, la manière dont les données sont traitées (comme le recadrage ou la compression d’images) peut créer de fausses corrélations (c’est-à-dire des raccourcis) qui sont captées par le modèle. Ces raccourcis peuvent être utiles en apparence, mais peuvent échouer de manière catastrophique lorsque le modèle est déployé dans un environnement légèrement différent.
L'ablation systématique des données est un excellent moyen d'examiner les « raccourcis » potentiels du modèle. Lors de l'ablation de données, les modèles d'IA sont entraînés et testés sur des entrées ablées de signaux de surface faussement corrélés.
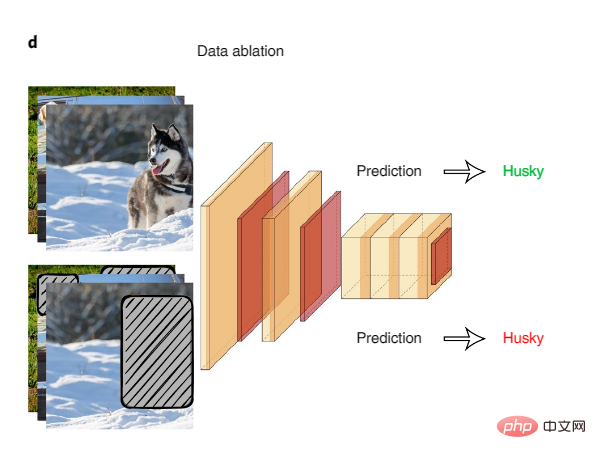
Figure 4 : Ablation de données
Un exemple d'utilisation de l'ablation de données pour détecter les raccourcis de modèle est qu'une étude sur un ensemble de données d'inférence en langage naturel commun a révélé que les modèles d'IA entraînés uniquement sur la première moitié de la saisie de texte ont atteint une grande précision. en déduisant des relations logiques entre la première et la seconde moitié du texte, alors que les humains sur la même entrée fonctionneraient à peu près au même niveau qu'une devinette aléatoire. Cela suggère que les modèles d’IA exploitent de fausses corrélations comme raccourci pour accomplir cette tâche. L’équipe de recherche a découvert que des phénomènes linguistiques spécifiques sont exploités par les modèles d’IA, tels que la négation dans le texte étant fortement corrélée aux balises.
L'ablation de données est largement utilisée dans divers domaines. Par exemple, dans le domaine médical, les parties biologiquement pertinentes d’une image peuvent être masquées afin d’évaluer si l’IA apprend à partir d’un faux arrière-plan ou d’un artefact de la qualité de l’image.
L'évaluation de l'IA se limite souvent à comparer les mesures de performances globales sur l'ensemble d'un ensemble de données de test. Mais même si un modèle d’IA fonctionne bien au niveau global des données, il peut toujours présenter des erreurs systématiques sur des sous-groupes spécifiques de données, et caractériser des groupes de ces erreurs peut permettre de mieux comprendre les limites du modèle.
Lorsque des métadonnées sont disponibles, les méthodes d'évaluation fines doivent, dans la mesure du possible, diviser les données d'évaluation en fonction du sexe, du sexe, de la race et de la situation géographique des participants dans l'ensemble de données – par exemple, « Homme plus âgé d'origine asiatique » ou « Femme amérindienne ». » – et quantifier les performances du modèle sur chaque sous-groupe de données. L'audit multi-précision est un algorithme qui recherche automatiquement les sous-groupes de données dans lesquels les modèles d'IA fonctionnent mal. Ici, les algorithmes d’audit sont formés pour prédire et regrouper les erreurs du modèle d’origine à l’aide de métadonnées, puis fournir des réponses explicables à des questions telles que les erreurs commises par le modèle d’IA et pourquoi.
Lorsque les métadonnées ne sont pas disponibles, des méthodes comme Domino identifient automatiquement les clusters de données où les modèles d'évaluation sont sujets à des erreurs et utilisent la génération de texte pour créer des explications en langage naturel de ces erreurs de modèle.
4. L'avenir des données
Actuellement, la plupart des projets de recherche sur l'IA ne développent des ensembles de données qu'une seule fois, mais les utilisateurs d'IA du monde réel doivent souvent mettre à jour en permanence les ensembles de données et les modèles. Le développement continu des données entraînera les défis suivants :
Premièrement, les tâches liées aux données et à l'IA peuvent changer au fil du temps : par exemple, peut-être qu'un nouveau modèle de véhicule apparaît sur la route (c'est-à-dire un changement de domaine), ou peut-être que l'IA qu'un développeur souhaite reconnaître une nouvelle classe d'objets (par exemple, un type d'autobus scolaire différent d'un autobus régulier), qui modifie la classification de l'étiquette. Il serait inutile de jeter des millions d’heures d’anciennes données de balises. Les mises à jour sont donc impératives. De plus, les mesures de formation et d’évaluation doivent être soigneusement conçues pour peser les nouvelles données et utiliser les données appropriées pour chaque sous-tâche.
Deuxièmement, afin d'acquérir et d'utiliser des données en continu, les utilisateurs devront automatiser la plupart des processus d'IA centrés sur les données. Cette automatisation implique l'utilisation d'algorithmes pour choisir les données à envoyer à l'annotateur et comment les utiliser pour recycler le modèle, et alerter les développeurs de modèles uniquement en cas de problème dans le processus (par exemple, lorsque les mesures de précision chutent). Dans le cadre de la tendance « MLOps (Machine Learning Operations) », les entreprises du secteur commencent à utiliser des outils pour automatiser le cycle de vie du machine learning.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Géospatial de Laravel: optimisation des cartes interactives et de grandes quantités de données
Apr 08, 2025 pm 12:24 PM
Géospatial de Laravel: optimisation des cartes interactives et de grandes quantités de données
Apr 08, 2025 pm 12:24 PM
Traiter efficacement 7 millions d'enregistrements et créer des cartes interactives avec la technologie géospatiale. Cet article explore comment traiter efficacement plus de 7 millions d'enregistrements en utilisant Laravel et MySQL et les convertir en visualisations de cartes interactives. Exigences initiales du projet de défi: extraire des informations précieuses en utilisant 7 millions d'enregistrements dans la base de données MySQL. Beaucoup de gens considèrent d'abord les langages de programmation, mais ignorent la base de données elle-même: peut-il répondre aux besoins? La migration des données ou l'ajustement structurel est-il requis? MySQL peut-il résister à une charge de données aussi importante? Analyse préliminaire: les filtres et les propriétés clés doivent être identifiés. Après analyse, il a été constaté que seuls quelques attributs étaient liés à la solution. Nous avons vérifié la faisabilité du filtre et établi certaines restrictions pour optimiser la recherche. Recherche de cartes basée sur la ville
 Comment résoudre MySQL ne peut pas être démarré
Apr 08, 2025 pm 02:21 PM
Comment résoudre MySQL ne peut pas être démarré
Apr 08, 2025 pm 02:21 PM
Il existe de nombreuses raisons pour lesquelles la startup MySQL échoue, et elle peut être diagnostiquée en vérifiant le journal des erreurs. Les causes courantes incluent les conflits de port (vérifier l'occupation du port et la configuration de modification), les problèmes d'autorisation (vérifier le service exécutant les autorisations des utilisateurs), les erreurs de fichier de configuration (vérifier les paramètres des paramètres), la corruption du répertoire de données (restaurer les données ou reconstruire l'espace de la table), les problèmes d'espace de la table InNODB (vérifier les fichiers IBDATA1), la défaillance du chargement du plug-in (vérification du journal des erreurs). Lors de la résolution de problèmes, vous devez les analyser en fonction du journal d'erreur, trouver la cause profonde du problème et développer l'habitude de sauvegarder régulièrement les données pour prévenir et résoudre des problèmes.
 Comment utiliser MySQL après l'installation
Apr 08, 2025 am 11:48 AM
Comment utiliser MySQL après l'installation
Apr 08, 2025 am 11:48 AM
L'article présente le fonctionnement de la base de données MySQL. Tout d'abord, vous devez installer un client MySQL, tel que MySQLWorkBench ou le client de ligne de commande. 1. Utilisez la commande MySQL-UROot-P pour vous connecter au serveur et connecter avec le mot de passe du compte racine; 2. Utilisez Createdatabase pour créer une base de données et utilisez Sélectionner une base de données; 3. Utilisez CreateTable pour créer une table, définissez des champs et des types de données; 4. Utilisez InsertInto pour insérer des données, remettre en question les données, mettre à jour les données par mise à jour et supprimer les données par Supprimer. Ce n'est qu'en maîtrisant ces étapes, en apprenant à faire face à des problèmes courants et à l'optimisation des performances de la base de données que vous pouvez utiliser efficacement MySQL.
 Comprendre les propriétés acides: les piliers d'une base de données fiable
Apr 08, 2025 pm 06:33 PM
Comprendre les propriétés acides: les piliers d'une base de données fiable
Apr 08, 2025 pm 06:33 PM
Une explication détaillée des attributs d'acide de base de données Les attributs acides sont un ensemble de règles pour garantir la fiabilité et la cohérence des transactions de base de données. Ils définissent comment les systèmes de bases de données gérent les transactions et garantissent l'intégrité et la précision des données même en cas de plantages système, d'interruptions d'alimentation ou de plusieurs utilisateurs d'accès simultanément. Présentation de l'attribut acide Atomicité: une transaction est considérée comme une unité indivisible. Toute pièce échoue, la transaction entière est reculée et la base de données ne conserve aucune modification. Par exemple, si un transfert bancaire est déduit d'un compte mais pas augmenté à un autre, toute l'opération est révoquée. BeginTransaction; UpdateAccountSsetBalance = Balance-100Wh
 Les ingénieurs de backend senior à distance (plates-formes) ont besoin de cercles
Apr 08, 2025 pm 12:27 PM
Les ingénieurs de backend senior à distance (plates-formes) ont besoin de cercles
Apr 08, 2025 pm 12:27 PM
Ingénieur backend à distance Emploi Vacant Société: Emplacement du cercle: Bureau à distance Type d'emploi: Salaire à temps plein: 130 000 $ - 140 000 $ Description du poste Participez à la recherche et au développement des applications mobiles Circle et des fonctionnalités publiques liées à l'API couvrant l'intégralité du cycle de vie de développement logiciel. Les principales responsabilités complètent indépendamment les travaux de développement basés sur RubyOnRails et collaborent avec l'équipe frontale React / Redux / Relay. Créez les fonctionnalités de base et les améliorations des applications Web et travaillez en étroite collaboration avec les concepteurs et le leadership tout au long du processus de conception fonctionnelle. Promouvoir les processus de développement positifs et hiérarchiser la vitesse d'itération. Nécessite plus de 6 ans de backend d'applications Web complexe
 Mysql peut-il renvoyer JSON
Apr 08, 2025 pm 03:09 PM
Mysql peut-il renvoyer JSON
Apr 08, 2025 pm 03:09 PM
MySQL peut renvoyer les données JSON. La fonction JSON_Extract extrait les valeurs de champ. Pour les requêtes complexes, envisagez d'utiliser la clause pour filtrer les données JSON, mais faites attention à son impact sur les performances. Le support de MySQL pour JSON augmente constamment, et il est recommandé de faire attention aux dernières versions et fonctionnalités.
 MySQL ne peut pas être installé après le téléchargement
Apr 08, 2025 am 11:24 AM
MySQL ne peut pas être installé après le téléchargement
Apr 08, 2025 am 11:24 AM
Les principales raisons de la défaillance de l'installation de MySQL sont les suivantes: 1. Problèmes d'autorisation, vous devez s'exécuter en tant qu'administrateur ou utiliser la commande sudo; 2. Des dépendances sont manquantes et vous devez installer des packages de développement pertinents; 3. Conflits du port, vous devez fermer le programme qui occupe le port 3306 ou modifier le fichier de configuration; 4. Le package d'installation est corrompu, vous devez télécharger et vérifier l'intégrité; 5. La variable d'environnement est mal configurée et les variables d'environnement doivent être correctement configurées en fonction du système d'exploitation. Résolvez ces problèmes et vérifiez soigneusement chaque étape pour installer avec succès MySQL.
 Solutions au service qui ne peuvent pas être démarrées après l'installation de MySQL
Apr 08, 2025 am 11:18 AM
Solutions au service qui ne peuvent pas être démarrées après l'installation de MySQL
Apr 08, 2025 am 11:18 AM
MySQL a refusé de commencer? Ne paniquez pas, vérifions-le! De nombreux amis ont découvert que le service ne pouvait pas être démarré après avoir installé MySQL, et ils étaient si anxieux! Ne vous inquiétez pas, cet article vous emmènera pour le faire face calmement et découvrez le cerveau derrière! Après l'avoir lu, vous pouvez non seulement résoudre ce problème, mais aussi améliorer votre compréhension des services MySQL et vos idées de problèmes de dépannage, et devenir un administrateur de base de données plus puissant! Le service MySQL n'a pas réussi et il y a de nombreuses raisons, allant des erreurs de configuration simples aux problèmes système complexes. Commençons par les aspects les plus courants. Connaissances de base: une brève description du processus de démarrage du service MySQL Service Startup. Autrement dit, le système d'exploitation charge les fichiers liés à MySQL, puis démarre le démon mysql. Cela implique la configuration
