

Analyse du code source dict de type Python intégré

Compréhension approfondie du type intégré de Python - dict
Remarque : cet article est basé sur les notes enregistrées dans le didacticiel. Une partie du contenu est la même que celle du didacticiel, car la réimpression nécessite de remplir le lien, mais il y a. est non, alors remplissez l'original en cas d'infraction, il sera supprimé directement.
Cette partie de « Compréhension approfondie des types intégrés de Python » vous présentera divers types intégrés couramment utilisés en Python du point de vue du code source.
Dict est l'un des types intégrés les plus couramment utilisés dans le développement quotidien, et le fonctionnement de la machine virtuelle Python repose également fortement sur les objets dict. Maîtriser les connaissances sous-jacentes de dict devrait être utile, qu'il s'agisse de comprendre les connaissances de base des structures de données ou d'améliorer l'efficacité du développement.
1 Efficacité d'exécution
Qu'il s'agisse de Hashmap en Java ou de dict en Python, ce sont tous deux des structures de données très efficaces. Hashmap est également un point de test de base dans les entretiens Java : tableau + liste chaînée + table de hachage d'arbre rouge-noir, ce qui est très efficace en termes de temps. De même, dict en Python a également une complexité moyenne de O(1) (O(n) dans le pire des cas) pour les opérations telles que l'insertion, la suppression et la recherche en raison de sa structure de table de hachage sous-jacente. Ici, nous comparons la liste et le dict pour voir quelle est l'ampleur de la différence dans l'efficacité de la recherche entre les deux : (Les données proviennent de l'article original, vous pouvez les tester vous-même)
| Échelle du conteneur | Coefficient de croissance de l'échelle | dict Consommation de temps | dict coefficient de croissance qui prend du temps | liste du coefficient de croissance qui prend du temps | liste du coefficient de croissance qui prend du temps |
|---|---|---|---|---|---|
| 1000 | 1 | 0.000129s | 1 | 0.036s | 1 |
| 10000 | 10 | 0.000172s | 1.33 | 0.348s | 9.67 |
| 100000 | 100 | 0.000216s | 1.67 | 3.679s | 102.19 |
| 1000000 | 1000 | 0.000382s | 2.96 | 48.044s | 1335.56 |
思考:这里原文章是比较的将需要搜索的数据分别作为list的元素和dict的key,个人认为这样的比较并没有意义。因为本质上list也是哈希表,其中key是0到n-1,值就是我们要查找的元素;而这里的dict是将要查找的元素作为key,而值是True(原文章中代码是这样设置的)。如果真要比较可以比较下查询list的0~n-1和查询dict的对应key,这样才是控制变量法,hh。当然这里我个人觉得不妥的本质原因是:list它有存储意义的地方是它的value部分,而dict的key和value都有一定的存储意义,个人认为没必要过分纠结这两者的搜索效率,弄清楚二者的底层原理,在实际工程中选择运用才是最重要的。
2 内部结构
2.1 PyDictObject
由于关联式容器使用的场景非常广泛,几乎所有现代编程语言都提供某种关联式容器,而且特别关注键的搜索效率。例如C++标准库中的map就是一种关联式容器,其内部基于红黑树实现,此外还有刚刚提到的Java中的Hashmap。红黑树是一种平衡二叉树,能够提供良好的操作效率,插入、删除、搜索等关键操作的时间复杂度都是O(logn)。
Python虚拟机的运行重度依赖dict对象,像名字空间、对象属性空间等概念的底层都是由dict对象来管理数据的。因此,Python对dict对象的效率要求更为苛刻。于是,Python中的dict使用了效率优于O(logn)的哈希表。
dict对象在Python内部由结构体PyDictObject表示,源码如下:
typedef struct {
PyObject_HEAD
/* Number of items in the dictionary */
Py_ssize_t ma_used;
/* Dictionary version: globally unique, value change each time
the dictionary is modified */
uint64_t ma_version_tag;
PyDictKeysObject *ma_keys;
/* If ma_values is NULL, the table is "combined": keys and values
are stored in ma_keys.
If ma_values is not NULL, the table is splitted:
keys are stored in ma_keys and values are stored in ma_values */
PyObject **ma_values;
} PyDictObject;源码分析:
ma_used:对象当前所保存的键值对个数
ma_version_tag:对象当前版本号,每次修改时更新(版本号感觉在业务开发中也挺常见的)
ma_keys:指向由键对象映射的哈希表结构,类型为PyDictKeysObject
ma_values:splitted模式下指向所有值对象组成的数组(如果是combined模式,值会存储在ma_keys中,此时ma_values为空)
2.2 PyDictKeysObject
从PyDictObject的源码中可以看到,相关的哈希表是通过PyDictKeysObject来实现的,源码如下:
struct _dictkeysobject {
Py_ssize_t dk_refcnt;
/* Size of the hash table (dk_indices). It must be a power of 2. */
Py_ssize_t dk_size;
/* Function to lookup in the hash table (dk_indices):
- lookdict(): general-purpose, and may return DKIX_ERROR if (and
only if) a comparison raises an exception.
- lookdict_unicode(): specialized to Unicode string keys, comparison of
which can never raise an exception; that function can never return
DKIX_ERROR.
- lookdict_unicode_nodummy(): similar to lookdict_unicode() but further
specialized for Unicode string keys that cannot be the <dummy> value.
- lookdict_split(): Version of lookdict() for split tables. */
dict_lookup_func dk_lookup;
/* Number of usable entries in dk_entries. */
Py_ssize_t dk_usable;
/* Number of used entries in dk_entries. */
Py_ssize_t dk_nentries;
/* Actual hash table of dk_size entries. It holds indices in dk_entries,
or DKIX_EMPTY(-1) or DKIX_DUMMY(-2).
Indices must be: 0 <= indice < USABLE_FRACTION(dk_size).
The size in bytes of an indice depends on dk_size:
- 1 byte if dk_size <= 0xff (char*)
- 2 bytes if dk_size <= 0xffff (int16_t*)
- 4 bytes if dk_size <= 0xffffffff (int32_t*)
- 8 bytes otherwise (int64_t*)
Dynamically sized, SIZEOF_VOID_P is minimum. */
char dk_indices[]; /* char is required to avoid strict aliasing. */
/* "PyDictKeyEntry dk_entries[dk_usable];" array follows:
see the DK_ENTRIES() macro */
};源码分析:
dk_refcnt:引用计数,和映射视图的实现有关,类似对象引用计数
dk_size:哈希表大小,必须是2的整数次幂,这样可以将模运算优化成位运算(
可以学习一下,结合实际业务运用)dk_lookup:哈希查找函数指针,可以根据dict当前状态选用最优函数
dk_usable:键值对数组可用个数
dk_nentries:键值对数组已用个数
dk_indices:哈希表起始地址,哈希表后紧接着键值对数组dk_entries,dk_entries的类型为PyDictKeyEntry
2.3 PyDictKeyEntry
从PyDictKeysObject中可以看到,键值对结构体是由PyDictKeyEntry实现的,源码如下:
typedef struct {
/* Cached hash code of me_key. */
Py_hash_t me_hash;
PyObject *me_key;
PyObject *me_value; /* This field is only meaningful for combined tables */
} PyDictKeyEntry;源码分析:
me_hash:键对象的哈希值,避免重复计算
me_key:键对象指针
me_value:值对象指针
2.4 图示及实例
dict内部的hash表图示如下:
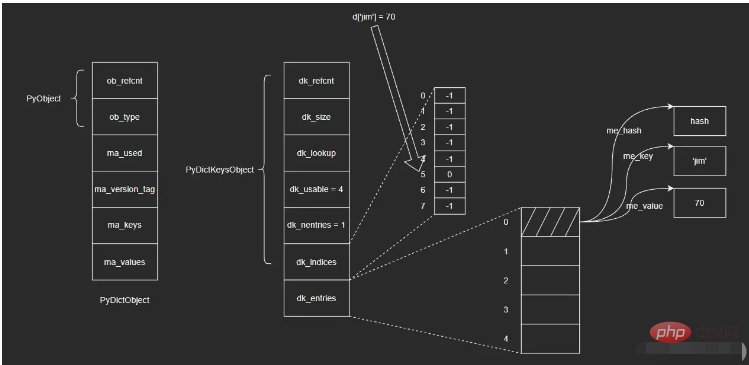
dict对象真正的核心在于PyDictKeysObject中,它包含两个关键数组:一个是哈希索引数组dk_indices,另一个是键值对数组dk_entries。dict所维护的键值对,会按照先来后到的顺序保存于键值对数组中;而哈希索引数组对应槽位则保存着键值对在数组中的位置。
以向空dict对象d中插入{'jim': 70}为例,步骤如下:
i. 将键值对保存在dk_entries数组末尾(这里数组初始为空,末尾即数组下标为”0“的位置);
ii. 计算键对象'jim'的哈希值并取右3位(即对8取模,dk_indices数组长度为8,这里前面提到了保持数组长度为2的整数次幂,可以将模运算转化为位运算,这里直接取右3位即可),假设最后获取到的值为5,即对应dk_indices数组中下标为5的位置;
iii. 将被插入的键值对在dk_entries数组中对应的下标”0“,保存于哈希索引数组dk_indices中下标为5的位置。
进行查找操作,步骤如下:
i. 计算键对象'jim'的哈希值,并取右3位,得到该键在哈希索引数组dk_indices中的下标5;
ii. 找到哈希索引数组dk_indices下标为5的位置,取出其中保存的值——0,即键值对在dk_entries数组中的位置;
iii. 找到dk_entries数组下标为0的位置,取出值对象me_value。(这里我不确定在查找时会不会再次验证me_key是否为'jim',感兴趣的读者可以自行去查看一下相应的源码)
这里涉及到的结构比较多,直接看图示可能也不是很清晰,但是通过上面的插入和查找两个过程,应该可以帮助大家理清楚这里的关系。我个人觉得这里的设计还是很巧妙的,可能暂时还看不出来为什么这么做,后续我会继续为大家介绍。
3 容量策略
示例:
>>> import sys
>>> d1 = {}
>>> sys.getsizeof(d1)
240
>>> d2 = {'a': 1}
>>> sys.getsizeof(d1)
240可以看到,dict和list在容量策略上有所不同,Python会为空dict对象也分配一定的容量,而对空list对象并不会预先分配底层数组。下面简单介绍下dict的容量策略。
哈希表越密集,哈希冲突则越频繁,性能也就越差。因此,哈希表必须是一种稀疏的表结构,越稀疏则性能越好。但是由于内存开销的制约,哈希表不可能无限度稀疏,需要在时间和空间上进行权衡。实践经验表明,一个1/3到2/3满的哈希表,性能是较为理想的——以相对合理的内存换取相对高效的执行性能。
为保证哈希表的稀疏程度,进而控制哈希冲突频率,Python底层通过USABLE_FRACTION宏将哈希表内元素控制在2/3以内。USABLE_FRACTION根据哈希表的规模n,计算哈希表可存储元素个数,也就是键值对数组dk_entries的长度。以长度为8的哈希表为例,最多可以保持5个键值对,超出则需要扩容。USABLE_FRACTION是一个非常重要的宏定义:
# define USABLE_FRACTION(n) (((n) << 1)/3)
此外,哈希表的规模一定是2的整数次幂,即Python对dict采用翻倍扩容策略。
4 内存优化
在Python3.6之前,dict的哈希表并没有分成两个数组实现,而是由一个键值对数组(结构和PyDictKeyEntry一样,但是会有很多“空位”)实现,这个数组也承担哈希索引的角色:
entries = [ ['--', '--', '--'],
[hash, key, value],
['--', '--', '--'],
[hash, key, value],
['--', '--', '--'],
]哈希值直接在数组中定位到对应的下标,找到对应的键值对,这样一步就能完成。Python3.6之后通过两个数组来实现则是出于对内存的考量。
由于哈希表必须保持稀疏,最多只有2/3满(太满会导致哈希冲突频发,性能下降),这意味着至少要浪费1/3的内存空间,而一个键值对条目PyDictKeyEntry的大小达到了24字节。试想一个规模为65536的哈希表,将浪费:
65536 * 1/3 * 24 = 524288 B 大小的空间(512KB)
为了尽量节省内存,Python将键值对数组压缩到原来的2/3(原来只能2/3满,现在可以全满),只负责存储,索引由另一个数组负责。由于索引数组indices只需要保存键值对数组的下标,即保存整数,而整数占用的空间很小(例如int为4字节),因此可以节省大量内存。
此外,索引数组还可以根据哈希表的规模,选择不同大小的整数类型。对于规模不超过256的哈希表,选择8位整数即可;对于规模不超过65536的哈希表,16位整数足以;其他以此类推。
对比一下两种方式在内存上的开销:
| 哈希表规模 | entries表规模 | 旧方案所需内存(B) | 新方案所需内存(B) | 节约内存(B) |
|---|---|---|---|---|
| 8 | 8 * 2/3 = 5 | 24 * 8 = 192 | 1 * 8 + 24 * 5 = 128 | 64 |
| 256 | 256 * 2/3 = 170 | 24 * 256 = 6144 | 1 * 256 + 24 * 170 = 4336 | 1808 |
| 65536 | 65536 * 2/3 = 43690 | 24 * 65536 = 1572864 | 2 * 65536 + 24 * 43690 = 1179632 | 393232 |
5 dict中哈希表
这一节主要介绍哈希函数、哈希冲突、哈希攻击以及删除操作相关的知识点。
5.1 哈希函数
根据哈希表性质,键对象必须满足以下两个条件,否则哈希表便不能正常工作:
i. 哈希值在对象的整个生命周期内不能改变
ii. 可比较,并且比较结果相等的两个对象的哈希值必须相同
满足这两个条件的对象便是可哈希(hashable)对象,只有可哈希对象才可作为哈希表的键。因此,像dict、set等底层由哈希表实现的容器对象,其键对象必须是可哈希对象。在Python的内建类型中,不可变对象都是可哈希对象,而可变对象则不是:
>>> hash([])
Traceback (most recent call last):
File "<pyshell#0>", line 1, in <module>
hash([])
TypeError: unhashable type: 'list'dict、list等不可哈希对象不能作为哈希表的键:
>>> {[]: 'list is not hashable'}
Traceback (most recent call last):
File "<pyshell#1>", line 1, in <module>
{[]: 'list is not hashable'}
TypeError: unhashable type: 'list'
>>> {{}: 'list is not hashable'}
Traceback (most recent call last):
File "<pyshell#2>", line 1, in <module>
{{}: 'list is not hashable'}
TypeError: unhashable type: 'dict'而用户自定义的对象默认便是可哈希对象,对象哈希值由对象地址计算而来,且任意两个不同对象均不相等:
>>> class A:
pass
>>> a = A()
>>> b = A()
>>> hash(a), hash(b)
(160513133217, 160513132857)
>>>a == b
False
>>> a is b
False那么,哈希值是如何计算的呢?答案是——哈希函数。哈希值计算作为对象行为的一种,会由各个类型对象的tp_hash指针指向的哈希函数来计算。对于用户自定义的对象,可以实现__hash__()魔法方法,重写哈希值计算方法。
5.2 哈希冲突
理想的哈希函数必须保证哈希值尽量均匀地分布于整个哈希空间,越是接近的值,其哈希值差别应该越大。而一方面,不同的对象哈希值有可能相同;另一方面,与哈希值空间相比,哈希表的槽位是非常有限的。因此,存在多个键被映射到哈希索引同一槽位的可能性,这就是哈希冲突。
解决哈希冲突的常用方法有两种:
i. 链地址法(seperate chaining)
ii. 开放定址法(open addressing)
为每个哈希槽维护一个链表,所有哈希到同一槽位的键保存到对应的链表中
这是Python采用的方法。将数据直接保存于哈希槽位中,如果槽位已被占用,则尝试另一个。一般而言,第i次尝试会在首槽位基础上加上一定的偏移量di。因此,探测方法因函数di而异。常见的方法有线性探测(linear probing)以及平方探测(quadratic probing)
线性探测:di是一个线性函数,如:di = 2 * i
平方探测:di是一个二次函数,如:di = i ^ 2
线性探测和平方探测很简单,但同时也存在一定的问题:固定的探测序列会加大冲突的概率。Python对此进行了优化,探测函数参考对象哈希值,生成不同的探测序列,进一步降低哈希冲突的可能性。Python探测方法在lookdict()函数中实现,关键代码如下:
static Py_ssize_t _Py_HOT_FUNCTION
lookdict(PyDictObject *mp, PyObject *key, Py_hash_t hash, PyObject **value_addr)
{
size_t i, mask, perturb;
PyDictKeysObject *dk;
PyDictKeyEntry *ep0;
top:
dk = mp->ma_keys;
ep0 = DK_ENTRIES(dk);
mask = DK_MASK(dk);
perturb = hash;
i = (size_t)hash & mask;
for (;;) {
Py_ssize_t ix = dk_get_index(dk, i);
// 省略键比较部分代码
// 计算下个槽位
// 由于参考了对象哈希值,探测序列因哈希值而异
perturb >>= PERTURB_SHIFT;
i = (i*5 + perturb + 1) & mask;
}
Py_UNREACHABLE();
}源码分析:第20~21行,探测序列涉及到的参数是与对象的哈希值相关的,具体计算方式大家可以看下源码,这里我就不赘述了。
5.3 哈希攻击
Python在3.3之前,哈希算法只根据对象本身计算哈希值。因此,只要Python解释器相同,对象哈希值也肯定相同。执行Python2解释器的两个交互式终端,示例如下:(来自原文章)
>>> import os >>> os.getpid() 2878 >>> hash('fashion') 3629822619130952182
>>> import os >>> os.getpid() 2915 >>> hash('fashion') 3629822619130952182
如果我们构造出大量哈希值相同的key,并提交给服务器:例如向一台Python2Web服务器post一个json数据,数据包含大量的key,这些key的哈希值均相同。这意味哈希表将频繁发生哈希冲突,性能由O(1)直接下降到了O(n),这就是哈希攻击。
产生上述问题的原因是:Python3.3之前的哈希算法只根据对象本身来计算哈希值,这样会导致攻击者很容易构建哈希值相同的key。于是,Python之后在计算对象哈希值时,会加盐。具体做法如下:
i. Python解释器进程启动后,产生一个随机数作为盐
ii. 哈希函数同时参考对象本身以及盐计算哈希值
这样一来,攻击者无法获知解释器内部的随机数,也就无法构造出哈希值相同的对象了。
5.4 删除操作
示例:向dict依次插入三组键值对,键对象依次为key1、key2、key3,其中key2和key3发生了哈希冲突,经过处理后重新定位到dk_indices[6]的位置。图示如下:
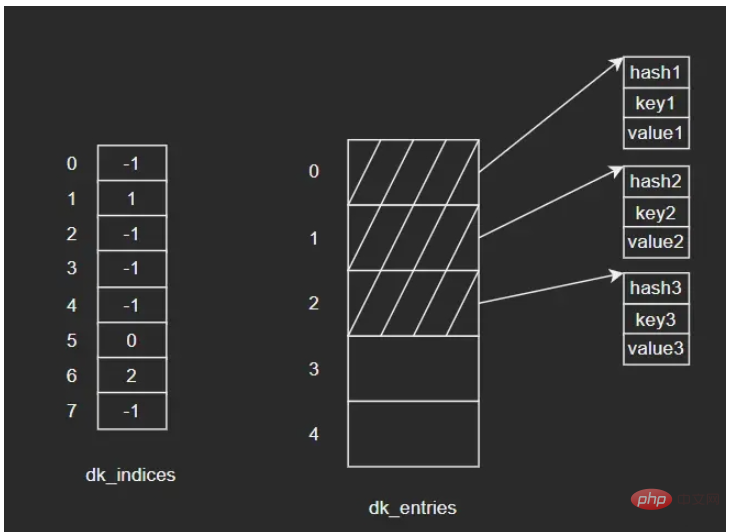
如果要删除key2,假设我们将key2对应的dk_indices[1]设置为-1,那么此时我们查询key3时就会出错——因为key3初始对应的操作就是dk_indices[1],只是发生了哈希冲突蔡最终分配到了dk_indices[6],而此时dk_indices[1]的值为-1,就会导致查询的结果是key3不存在。因此,在删除元素时,会将对应的dk_indices设置为一个特殊的值DUMMY,避免中断哈希探索链(也就是通过标志位来解决,很常见的做法)。
哈希槽位状态常量如下:
#define DKIX_EMPTY (-1) #define DKIX_DUMMY (-2) /* Used internally */ #define DKIX_ERROR (-3)
对于被删除元素在dk_entries中对应的存储单元,Python是不做处理的。假设此时再插入key4,Python会直接使用dk_entries[3],而不会使用被删除的key2所占用的dk_entries[1]。这里会存在一定的浪费。
5.5 问题
删除操作不会将dk_entries中的条目回收重用,随着插入地进行,dk_entries最终会耗尽,Python将创建一个新的PyDictKeysObject,并将数据拷贝过去。新PyDictKeysObject尺寸由GROWTH_RATE宏计算。这里给大家简单列下源码:
static int
dictresize(PyDictObject *mp, Py_ssize_t minsize)
{
/* Find the smallest table size > minused. */
for (newsize = PyDict_MINSIZE;
newsize < minsize && newsize > 0;
newsize <<= 1)
;
// ...
}源码分析:
如果此前发生了大量删除(没记错的话是可用个数为0时才会缩容,这里大家可以自行看下源码),剩余元素个数减少很多,PyDictKeysObject尺寸就会变小,此时就会完成缩容(大家还记得前面提到过的dk_usable,dk_nentries等字段吗,没记错的话它们在这里就发挥作用了,大家可以自行看下源码)。总之,缩容不会在删除的时候立刻触发,而是在当插入并且dk_entries耗尽时才会触发。
函数dictresize()的参数Py_ssize_t minsize由GROWTH_RATE宏传入:
#define GROWTH_RATE(d) ((d)->ma_used*3)
static int
insertion_resize(PyDictObject *mp)
{
return dictresize(mp, GROWTH_RATE(mp));
}这里的for循环就是不断对newsize进行翻倍变化,找到大于minsize的最小值
扩容时,Python分配新的哈希索引数组和键值对数组,然后将旧数组中的键值对逐一拷贝到新数组,再调整数组指针指向新数组,最后回收旧数组。这里的拷贝并不是直接拷贝过去,而是逐个插入新表的过程,这是因为哈希表的规模改变了,相应的哈希函数值对哈希表长度取模后的结果也会变化,所以不能直接拷贝。
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

Video Face Swap
Échangez les visages dans n'importe quelle vidéo sans effort grâce à notre outil d'échange de visage AI entièrement gratuit !

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 PHP et Python: différents paradigmes expliqués
Apr 18, 2025 am 12:26 AM
PHP et Python: différents paradigmes expliqués
Apr 18, 2025 am 12:26 AM
PHP est principalement la programmation procédurale, mais prend également en charge la programmation orientée objet (POO); Python prend en charge une variété de paradigmes, y compris la POO, la programmation fonctionnelle et procédurale. PHP convient au développement Web, et Python convient à une variété d'applications telles que l'analyse des données et l'apprentissage automatique.
 Choisir entre PHP et Python: un guide
Apr 18, 2025 am 12:24 AM
Choisir entre PHP et Python: un guide
Apr 18, 2025 am 12:24 AM
PHP convient au développement Web et au prototypage rapide, et Python convient à la science des données et à l'apprentissage automatique. 1.Php est utilisé pour le développement Web dynamique, avec une syntaxe simple et adapté pour un développement rapide. 2. Python a une syntaxe concise, convient à plusieurs champs et a un écosystème de bibliothèque solide.
 Peut-on exécuter le code sous Windows 8
Apr 15, 2025 pm 07:24 PM
Peut-on exécuter le code sous Windows 8
Apr 15, 2025 pm 07:24 PM
VS Code peut fonctionner sur Windows 8, mais l'expérience peut ne pas être excellente. Assurez-vous d'abord que le système a été mis à jour sur le dernier correctif, puis téléchargez le package d'installation VS Code qui correspond à l'architecture du système et l'installez comme invité. Après l'installation, sachez que certaines extensions peuvent être incompatibles avec Windows 8 et doivent rechercher des extensions alternatives ou utiliser de nouveaux systèmes Windows dans une machine virtuelle. Installez les extensions nécessaires pour vérifier si elles fonctionnent correctement. Bien que le code VS soit possible sur Windows 8, il est recommandé de passer à un système Windows plus récent pour une meilleure expérience de développement et une meilleure sécurité.
 L'extension VScode est-elle malveillante?
Apr 15, 2025 pm 07:57 PM
L'extension VScode est-elle malveillante?
Apr 15, 2025 pm 07:57 PM
Les extensions de code vs posent des risques malveillants, tels que la cachette de code malveillant, l'exploitation des vulnérabilités et la masturbation comme des extensions légitimes. Les méthodes pour identifier les extensions malveillantes comprennent: la vérification des éditeurs, la lecture des commentaires, la vérification du code et l'installation avec prudence. Les mesures de sécurité comprennent également: la sensibilisation à la sécurité, les bonnes habitudes, les mises à jour régulières et les logiciels antivirus.
 Comment exécuter des programmes dans Terminal Vscode
Apr 15, 2025 pm 06:42 PM
Comment exécuter des programmes dans Terminal Vscode
Apr 15, 2025 pm 06:42 PM
Dans VS Code, vous pouvez exécuter le programme dans le terminal via les étapes suivantes: Préparez le code et ouvrez le terminal intégré pour vous assurer que le répertoire de code est cohérent avec le répertoire de travail du terminal. Sélectionnez la commande Run en fonction du langage de programmation (tel que Python de Python your_file_name.py) pour vérifier s'il s'exécute avec succès et résoudre les erreurs. Utilisez le débogueur pour améliorer l'efficacité du débogage.
 Le code Visual Studio peut-il être utilisé dans Python
Apr 15, 2025 pm 08:18 PM
Le code Visual Studio peut-il être utilisé dans Python
Apr 15, 2025 pm 08:18 PM
VS Code peut être utilisé pour écrire Python et fournit de nombreuses fonctionnalités qui en font un outil idéal pour développer des applications Python. Il permet aux utilisateurs de: installer des extensions Python pour obtenir des fonctions telles que la réalisation du code, la mise en évidence de la syntaxe et le débogage. Utilisez le débogueur pour suivre le code étape par étape, trouver et corriger les erreurs. Intégrez Git pour le contrôle de version. Utilisez des outils de mise en forme de code pour maintenir la cohérence du code. Utilisez l'outil de liaison pour repérer les problèmes potentiels à l'avance.
 Peut-on utiliser pour mac
Apr 15, 2025 pm 07:36 PM
Peut-on utiliser pour mac
Apr 15, 2025 pm 07:36 PM
VS Code est disponible sur Mac. Il a des extensions puissantes, l'intégration GIT, le terminal et le débogueur, et offre également une multitude d'options de configuration. Cependant, pour des projets particulièrement importants ou un développement hautement professionnel, le code vs peut avoir des performances ou des limitations fonctionnelles.
 Python vs JavaScript: la courbe d'apprentissage et la facilité d'utilisation
Apr 16, 2025 am 12:12 AM
Python vs JavaScript: la courbe d'apprentissage et la facilité d'utilisation
Apr 16, 2025 am 12:12 AM
Python convient plus aux débutants, avec une courbe d'apprentissage en douceur et une syntaxe concise; JavaScript convient au développement frontal, avec une courbe d'apprentissage abrupte et une syntaxe flexible. 1. La syntaxe Python est intuitive et adaptée à la science des données et au développement back-end. 2. JavaScript est flexible et largement utilisé dans la programmation frontale et côté serveur.
