

Les ordinateurs modernes utilisent le binaire (bit, bit) comme unité d'information de base. 1 octet est égal à 8 bits. Par exemple, une chaîne big est composée de 3 octets, mais en réalité. ordinateurs Lors du stockage, il est représenté en binaire. Les codes ASCII correspondants de big sont respectivement 98, 105 et 103, et les nombres binaires correspondants sont respectivement 01100010, 01101001 et 01100111. big字符串是由 3 个字节组成,但实际在计算机存储时将其用二进制表示,big分别对应的 ASCII 码分别是 98、105、103,对应的二进制分别是 01100010、01101001 和 01100111。
许多开发语言都提供了操作位的功能,合理地使用位能够有效地提高内存使用率和开发效率。
Bit-map 的基本思想就是用一个 bit 位来标记某个元素对应的 value,而 key 即是该元素。由于采用了 bit 为单位来存储数据,因此在存储空间方面,可以大大节省。
在 Java 中,int 占 4 字节,1 字节 = 8位(1 byte = 8 bit),如果我们用这个 32 个 bit 位的每一位的值来表示一个数的话是不是就可以表示 32 个数字,也就是说 32 个数字只需要一个 int 所占的空间大小就可以了,那就可以缩小空间 32 倍。
1 Byte = 8 Bit,1 KB = 1024 Byte,1 MB = 1024 KB,1GB = 1024 MB
假设网站有 1 亿用户,每天独立访问的用户有 5 千万,如果每天用集合类型和 BitMap 分别存储活跃用户:
1.假如用户 id 是 int 型,4 字节,32 位,则集合类型占据的空间为 50 000 000 * 4/1024/1024 = 200M;
2.如果按位存储,5 千万个数就是 5 千万位,占据的空间为 50 000 000/8/1024/1024 = 6M。
那么如何用 BitMap 来表示一个数呢?
上面说了用 bit 位来标记某个元素对应的 value,而 key 即是该元素,我们可以把 BitMap 想象成一个以位为单位的数组,数组的每个单元只能存储 0 和 1(0 表示这个数不存在,1 表示存在),数组的下标在 BitMap 中叫做偏移量。比如我们需要表示{1,3,5,7}这四个数,如下:
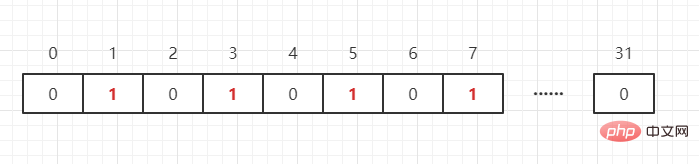
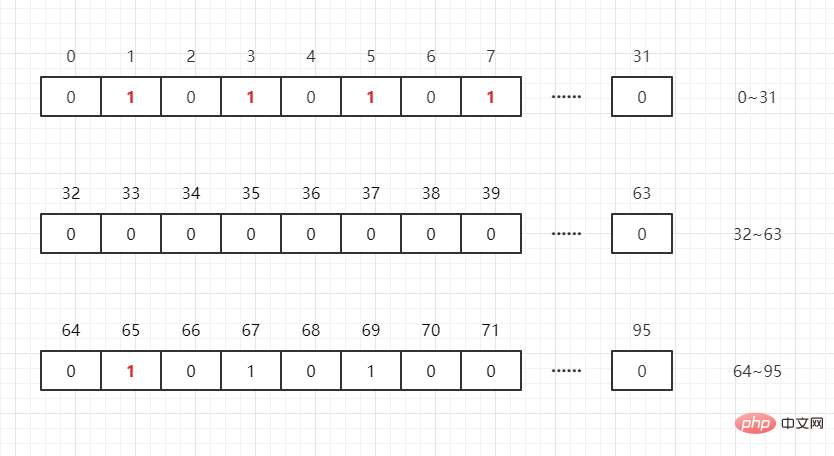
那如果还存在一个数 65 呢?只需要开int[N/32+1]个 int 数组就可以存储完这些数据(其中 N 表示这群数据中的最大值),即:
int[0]:可以表示 0~31
int[1]:可以表示 32~63
int[2]:可以表示 64~95
假设我们要判断任意整数是否在列表中,则 M/32 就得到下标,M%32就知道它在此下标的哪个位置,如:
65/32 = 2,65%32=1,即 65 在int[2]
1 octet = 8 bits, 1 Ko = 1024 octets, 1 Mo = 1024 Ko, 1 Go = 1024 MoSupposons que le site Web compte 100 millions d'utilisateurs et que 50 millions d'utilisateurs uniques le visitent chaque jour . Si le type de collection et BitMap sont utilisés pour stocker les utilisateurs actifs chaque jour : 1 Si l'identifiant de l'utilisateur est de type int, 4 octets, 32 bits, l'espace occupé par le type de collection est de 50 000 000 * 4/1024/. 1024 = 200M ; 2. S'ils sont stockés en bits, 50 millions de nombres font 50 millions de bits et l'espace occupé est de 50 000 000/8/1024/1024 = 6M. Alors comment utiliser BitMap pour représenter un nombre ? Comme mentionné ci-dessus, les bits sont utilisés pour marquer la valeur correspondant à un élément, et la clé est l'élément. Nous pouvons imaginer BitMap comme un
tableau
en unités de bits. 1 (0 signifie que le nombre n'existe pas, 1 signifie qu'il existe), l'indice du tableau est appelé décalage dans BitMap. Par exemple, nous devons représenter les quatre nombres{1,3,5,7} comme suit :
 Et s'il y a encore un nombre 65 ? Il vous suffit d'ouvrir les tableaux
Et s'il y a encore un nombre 65 ? Il vous suffit d'ouvrir les tableaux int[N/32+1] int pour stocker ces données (où N représente la valeur maximale dans ce groupe de données), c'est-à-dire :
int[ 0 ] : Peut représenter 0~31
int[1] : Peut représenter 32~63
int[2] : Peut représenter 64~95
Supposons que nous voulions juger Si un entier est dans la liste, alors M/32 obtiendra l'indice, et M%32 saura où il se trouve dans l'indice, par exemple : 65/32 = 2, 65%32=1, c'est-à-dire que 65 est le premier bit de int[2]. Filtre Bloom🎜🎜Essentiellement, le filtre Bloom est une structure de données, une structure de données probabiliste relativement intelligente, caractérisée par une insertion et une requête efficaces, qui peut être utilisée pour vous dire "quelque chose ne doit pas exister ou peut exister". 🎜🎜Par rapport aux structures de données traditionnelles telles que List, Set, Map, etc., elle est plus efficace et prend moins de place, mais l'inconvénient est que les résultats qu'elle renvoie sont probabilistes et non exacts. 🎜🎜En fait, les filtres Bloom sont largement utilisés dans le 🎜système de liste noire de pages Web🎜, le 🎜le système de filtrage du spam🎜, le 🎜le système de jugement de poids des sites Web d'exploration🎜, etc. La célèbre base de données distribuée de Google, Bigtable, utilise les filtres Bloom pour effectuer des recherches afin de réduire le nombre de Le disque IO recherche des lignes ou des colonnes inexistantes, Google Chrome utilise des filtres Bloom pour accélérer les services de navigation sécurisés. 🎜🎜 Les filtres Bloom sont également utilisés dans de nombreux systèmes clé-valeur pour accélérer le processus de requête, tels que Hbase, Accumulo, Leveldb. De manière générale, la valeur est enregistrée sur le disque et l'accès au disque prend beaucoup de temps. en utilisant le filtre Bloom, le processeur peut déterminer rapidement si la valeur correspondant à une clé existe, ce qui permet d'éviter de nombreuses opérations d'E/S disque inutiles. 🎜🎜Mappez un élément en un point dans un tableau de bits (Bit Array) via une fonction de hachage. De cette façon, il suffit de voir si le point est 1 pour savoir s’il est dans l’ensemble. C'est l'idée de base du filtre Bloom. 🎜🎜Scénarios d'application🎜🎜1. Il existe actuellement 1 milliard de nombres naturels, disposés dans un ordre aléatoire, et ils doivent être triés. Les restrictions sont implémentées sur les machines 32 bits et la limite de mémoire est de 2 Go. Comment ça se fait ? 🎜🎜2. Comment savoir rapidement si l'adresse URL est dans la liste noire ? (Chaque URL fait en moyenne 64 octets)🎜🎜3. Avez-vous besoin d'analyser le comportement de connexion des utilisateurs pour déterminer leur activité ? 🎜🎜4. Crawler Web : comment déterminer si une URL a été explorée ? 🎜🎜5. Localiser rapidement les attributs des utilisateurs (liste noire, liste blanche, etc.) ? 🎜🎜6. Les données sont stockées sur le disque, comment éviter un grand nombre d'IO invalides ? 🎜🎜7. Déterminer si un élément existe dans des milliards de données ? 🎜🎜8. Pénétration du cache. 🎜De manière générale, il est acceptable de stocker l'URL de la page Web dans la base de données pour la recherche ou de créer une table de hachage pour la recherche.
Lorsque la quantité de données est petite, il est juste de penser ainsi. Vous pouvez en effet mapper la valeur à la clé de HashMap, puis renvoyer le résultat dans une complexité temporelle O(1), ce qui est extrêmement efficace. Cependant, la mise en œuvre de HashMap présente également des inconvénients, comme une proportion élevée de capacité de stockage. Compte tenu de l'existence de facteurs de charge, l'espace ne peut généralement pas être entièrement utilisé. Par exemple, si un HashMap de 10 millions, Key=String (la longueur n'est pas). dépasse 16 caractères et très peu de répétabilité), Valeur = Entier, combien d'espace occupera-t-il ? 1,2 G.
En fait, en utilisant bitmap, 10 millions de types int ne nécessitent qu'environ 40 M (10 000 000 * 4/1024/1024 = 40 M) d'espace, soit 3 %. 10 millions d'entiers nécessitent environ 161 M d'espace, soit 13,3 %. .
On peut voir qu'une fois que vos valeurs sont nombreuses, comme des centaines de millions, la taille de la mémoire occupée par HashMap peut être imaginée.
Mais si l'ensemble du système de liste noire de pages Web contient 10 milliards d'URL de pages Web, la recherche dans la base de données prend beaucoup de temps, et si chaque espace d'URL est de 64 Mo, alors 640 Go de mémoire sont nécessaires, ce qui est difficile pour les serveurs ordinaires de répondre à cette exigence. .
Supposons que nous ayons un ensemble A et qu'il y ait n éléments dans A. À l'aide des fonctions de hachage k , chaque élément de A est mappé à différentes positions dans un tableau B d'une longueur de a bits, et les nombres binaires à ces positions sont tous définis sur 1. Si l'élément à vérifier est mappé par ces k fonctions de hachage et qu'il s'avère que les nombres binaires à ses k positions sont tous 1, cet élément appartient probablement à l'ensemble A. Au contraire, ne doit pas appartenir à l'ensemble A. .
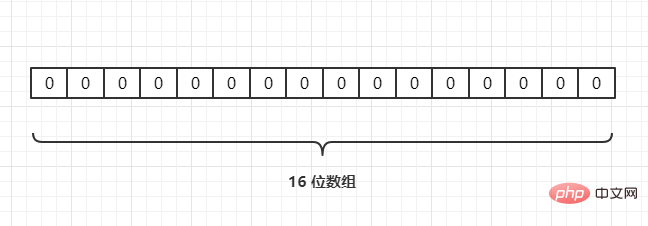
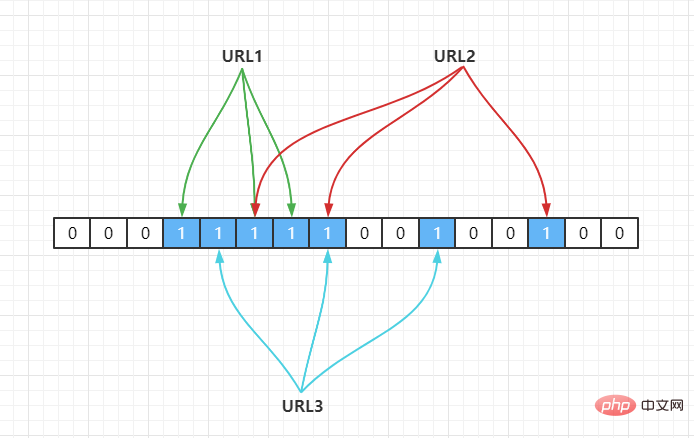
Par exemple, nous avons 3 URL {URL1,URL2,URL3}, et les mappons sur un tableau de longueur 16 via une fonction de hachage, comme suit : {URL1,URL2,URL3},通过一个hash 函数把它们映射到一个长度为 16 的数组上,如下:
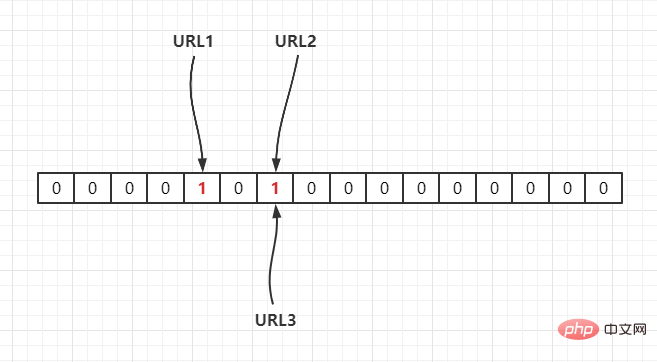
若当前哈希函数为 Hash2(),通过哈希运算映射到数组中,假设Hash2(URL1) = 3,Hash2(URL2) = 6,Hash2(URL3) = 6,如下:
因此,如果我们需要判断URL1是否在这个集合中,则通过Hash(1)计算出其下标,并得到其值若为 1 则说明存在。
由于 Hash 存在哈希冲突,如上面URL2,URL3都定位到一个位置上,假设 Hash 函数是良好的,如果我们的数组长度为 m 个点,那么如果我们想将冲突率降低到例如 1%, 这个散列表就只能容纳 m/100 个元素,显然空间利用率就变低了,也就是没法做到空间有效(space-efficient)。
解决方法也简单,就是使用多个 Hash 算法,如果它们有一个说元素不在集合中,那肯定就不在,如下:
Hash2(URL1) = 3,Hash3(URL1) = 5,Hash4(URL1) = 6 Hash2(URL2) = 5,Hash3(URL2) = 8,Hash4(URL2) = 14 Hash2(URL3) = 4,Hash3(URL3) = 7,Hash4(URL3) = 10
上面的做法同样存在问题,因为随着增加的值越来越多,被置为 1 的 bit 位也会越来越多,这样某个值即使没有被存储过,但是万一哈希函数返回的三个 bit 位都被其他值置位了 1 ,那么程序还是会判断这个值存在。比如此时来一个不存在的 URL1000,经过哈希计算后,发现 bit 位为下:
Hash2(URL1000) = 7,Hash3(URL1000) = 8,Hash4(URL1000) = 14
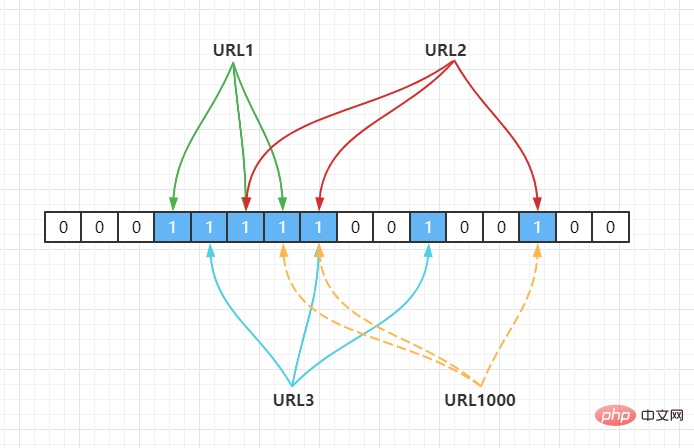
但是上面这些 bit 位已经被URL1,URL2,URL3置为 1 了,此时程序就会判断 URL1000

Si la fonction de hachage actuelle est Hash2() < /code>, mappé au tableau via une opération de hachage, en supposant que <code>Hash2(URL1) = 3, Hash2(URL2) = 6, Hash2(URL3) = 6 , comme suit :
Par conséquent, si nous devons déterminer si URL1 est dans cet ensemble, calculez son indice via Hash(1) et obtenez sa valeur si une valeur de 1 indique qu'il existe.
URL2, URL3 sont tous situés à la même position. En supposant que la fonction de hachage est bonne, si la longueur de notre tableau est de m points, alors si nous. Je veux Si le taux de conflit est réduit à, par exemple, m/100 éléments. Évidemment, le taux d'utilisation de l'espace devient faible, ce qui signifie qu'elle ne peut pas. soyez public static void main(String[] args) {
Config config = new Config();
// 单机环境
config.useSingleServer().setAddress("redis://192.168.153.128:6379");
//构造Redisson
RedissonClient redisson = Redisson.create(config);
RBloomFilter<String> bloomFilter = redisson.getBloomFilter("nameList");
//初始化布隆过滤器:预计元素为100000000L,误差率为3%,根据这两个参数会计算出底层的 bit 数组大小
bloomFilter.tryInit(100000L, 0.03);
//将 10086 插入到布隆过滤器中
bloomFilter.add("10086");
//判断下面号码是否在布隆过滤器中
System.out.println(bloomFilter.contains("10086"));//true
System.out.println(bloomFilter.contains("10010"));//false
System.out.println(bloomFilter.contains("10000"));//false
} Phénomène d'erreur de jugementL'approche ci-dessus pose également des problèmes, car comme la valeur augmente, S'il y a plus de bits mis à 1, de plus en plus de bits seront mis à 1. De cette façon, même si une certaine valeur n'a pas été stockée, si les trois bits renvoyés par la fonction de hachage sont tous définis à 1 par d'autres valeurs, alors le programme sera toujours jugé que cette valeur existe. Par exemple, s'il existe un
Phénomène d'erreur de jugementL'approche ci-dessus pose également des problèmes, car comme la valeur augmente, S'il y a plus de bits mis à 1, de plus en plus de bits seront mis à 1. De cette façon, même si une certaine valeur n'a pas été stockée, si les trois bits renvoyés par la fonction de hachage sont tous définis à 1 par d'autres valeurs, alors le programme sera toujours jugé que cette valeur existe. Par exemple, s'il existe un URL1000 inexistant à ce moment, après calcul de hachage, on constate que le bit est le suivant : rrreee
 Mais les bits ci-dessus ont été définis sur 1 par
Mais les bits ci-dessus ont été définis sur 1 par URL1,URL2,URL3 , à ce moment le programme déterminera que la valeur URL1000 existe. C'est le phénomène d'erreur de jugement du filtre Bloom. Par conséquent, 🎜Ce que le filtre Bloom juge exister peut ne pas exister, mais ce qu'il juge n'existe pas ne doit pas exister. 🎜🎜🎜 Le filtre Bloom peut représenter avec précision un ensemble et déterminer avec précision si un élément se trouve dans cet ensemble. La précision est déterminée par la conception spécifique de l'utilisateur. Il est impossible d'atteindre une précision à 100 %. Mais l’avantage du filtre Bloom est qu’il permet d’obtenir une grande précision en utilisant très peu d’espace. 🎜🎜Implémente le bitmap de Redis🎜🎜 et l'exécute en fonction des instructions pertinentes de la structure de données bitmap de Redis. 🎜🎜RedisBloom🎜🎜 Les filtres Bloom peuvent être implémentés à l'aide d'opérations bitmap dans Redis. Ce n'est que lorsque la version Redis 4.0 a fourni la fonction de plug-in que le filtre Bloom officiellement fourni par Redis Bloom est officiellement apparu en tant que plug-in chargé. dans le serveur Redis Le site officiel recommande un RedisBloom comme module pour le filtre Redis Bloom. 🎜🎜BloomFilter de Guava🎜🎜Lorsque le projet Guava a publié la version 11.0, l'une des fonctionnalités nouvellement ajoutées était la classe BloomFilter. 🎜🎜Redisson🎜🎜Redisson implémente un filtre bloom basé sur bitmap en bas. 🎜public static void main(String[] args) {
Config config = new Config();
// 单机环境
config.useSingleServer().setAddress("redis://192.168.153.128:6379");
//构造Redisson
RedissonClient redisson = Redisson.create(config);
RBloomFilter<String> bloomFilter = redisson.getBloomFilter("nameList");
//初始化布隆过滤器:预计元素为100000000L,误差率为3%,根据这两个参数会计算出底层的 bit 数组大小
bloomFilter.tryInit(100000L, 0.03);
//将 10086 插入到布隆过滤器中
bloomFilter.add("10086");
//判断下面号码是否在布隆过滤器中
System.out.println(bloomFilter.contains("10086"));//true
System.out.println(bloomFilter.contains("10010"));//false
System.out.println(bloomFilter.contains("10000"));//false
}缓存穿透是指查询一个根本不存在的数据,缓存层和存储层都不会命中,如果从存储层查不到数据则不写入缓存层。
缓存穿透将导致不存在的数据每次请求都要到存储层去查询,失去了缓存保护后端存储的意义。缓存穿透问题可能会使后端存储负载加大,由于很多后端存储不具备高并发性,甚至可能造成后端存储宕掉。
因此我们可以用布隆过滤器来解决,在访问缓存层和存储层之前,将存在的 key 用布隆过滤器提前保存起来,做第一层拦截。
例如:一个推荐系统有 4 亿个用户 id,每个小时算法工程师会根据每个用户之前历史行为计算出推荐数据放到存储层中,但是最新的用户由于没有历史行为,就会发生缓存穿透的行为,为此可以将所有推荐数据的用户做成布隆过滤器。如果布隆过滤器认为该用户 id 不存在,那么就不会访问存储层,在一定程度保护了存储层。
注:布隆过滤器可能会误判,放过部分请求,当不影响整体,所以目前该方案是处理此类问题最佳方案
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
















![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



