

Apprendre plusieurs tâches dans un environnement ouvert est une capacité importante des agents polyvalents. En tant que jeu populaire en monde ouvert, Minecraft possède un monde complexe généré à l'infini et un grand nombre de tâches ouvertes. Il est devenu ces dernières années un environnement de test important pour la recherche sur l'apprentissage ouvert.
Apprendre des tâches complexes dans Minecraft est un énorme défi pour les algorithmes d'apprentissage par renforcement actuels. D'une part, l'agent recherche des ressources à travers des observations locales dans un monde infini et se retrouve confronté à la difficulté de l'exploration. D’un autre côté, les tâches complexes nécessitent souvent des temps d’exécution longs et nécessitent la réalisation de nombreuses sous-tâches implicites. Par exemple, fabriquer une pioche en pierre implique plus de dix sous-tâches telles que couper des arbres, fabriquer des pioches en bois et creuser des pierres brutes, etc., ce qui nécessite que l'agent effectue des milliers d'étapes. L'agent ne peut recevoir des récompenses qu'en accomplissant des tâches, et il est difficile d'apprendre des tâches avec des récompenses rares.

Photo : Le processus de fabrication d'une pioche en pierre dans Minecraft.
Les recherches actuelles autour du concours d'extraction de diamants MineRL utilisent généralement des ensembles de données démontrés par des experts, tandis que des recherches telles que VPT utilisent un grand nombre de stratégies d'apprentissage de données étiquetées. En l’absence d’ensembles de données supplémentaires, la tâche de formation de Minecraft avec apprentissage par renforcement est très inefficace. MineAgent ne peut effectuer que quelques tâches simples à l'aide de l'algorithme PPO ; la méthode SOTA basée sur un modèle Dreamer-v3 doit également échantillonner 10 millions d'étapes pour apprendre à obtenir des pierres brutes lors de la simplification du simulateur d'environnement.
L'équipe de l'Université de Pékin et de l'Institut de recherche sur l'intelligence artificielle Zhiyuan de Pékin a proposé Plan4MC, une méthode pour résoudre efficacement le multitâche de Minecraft sans données d'experts. L'auteur combine des méthodes d'apprentissage par renforcement et de planification pour décomposer la résolution de tâches complexes en deux parties : l'apprentissage des compétences de base et la planification des compétences. Les auteurs utilisent des méthodes d’apprentissage par renforcement par récompense intrinsèque pour former trois types de compétences de base fines. L'agent utilise un grand modèle de langage pour créer un graphique de relations de compétences et obtient une planification des tâches grâce à une recherche sur le graphique. Dans la partie expérimentale, Plan4MC peut actuellement accomplir 24 tâches complexes et diverses, et le taux de réussite a été considérablement amélioré par rapport à toutes les méthodes de base.

Dans Minecraft, les joueurs peuvent obtenir des centaines d'objets grâce à l'exploration. Une tâche est définie comme une combinaison de conditions initiales et d'éléments cibles, par exemple « Initialiser l'établi
et obtenir du bœuf cuit ». La résolution de cette tâche comprend des étapes telles que « obtenir du bœuf » et « faire un four avec un établi et de la pierre brute. Ces étapes subdivisées sont appelées compétences ». Les humains acquièrent et combinent ces compétences pour accomplir diverses tâches dans le monde, plutôt que d’apprendre chaque tâche indépendamment. L'objectif de Plan4MC est d'apprendre des stratégies pour maîtriser un grand nombre de compétences, puis de combiner ces compétences en tâches grâce à la planification.
L'auteur a construit 24 tâches de test sur le simulateur MineDojo, qui couvrent une variété de comportements (couper des arbres, creuser des roches brutes, interagir avec des animaux), une variété de terrains et impliquent 37 compétences de base. Des dizaines d’étapes de compétences et des milliers d’étapes d’interaction environnementale sont nécessaires pour accomplir des tâches individuelles.务 Figure : Paramètres de 24 tâches
2, méthode Plan4mc 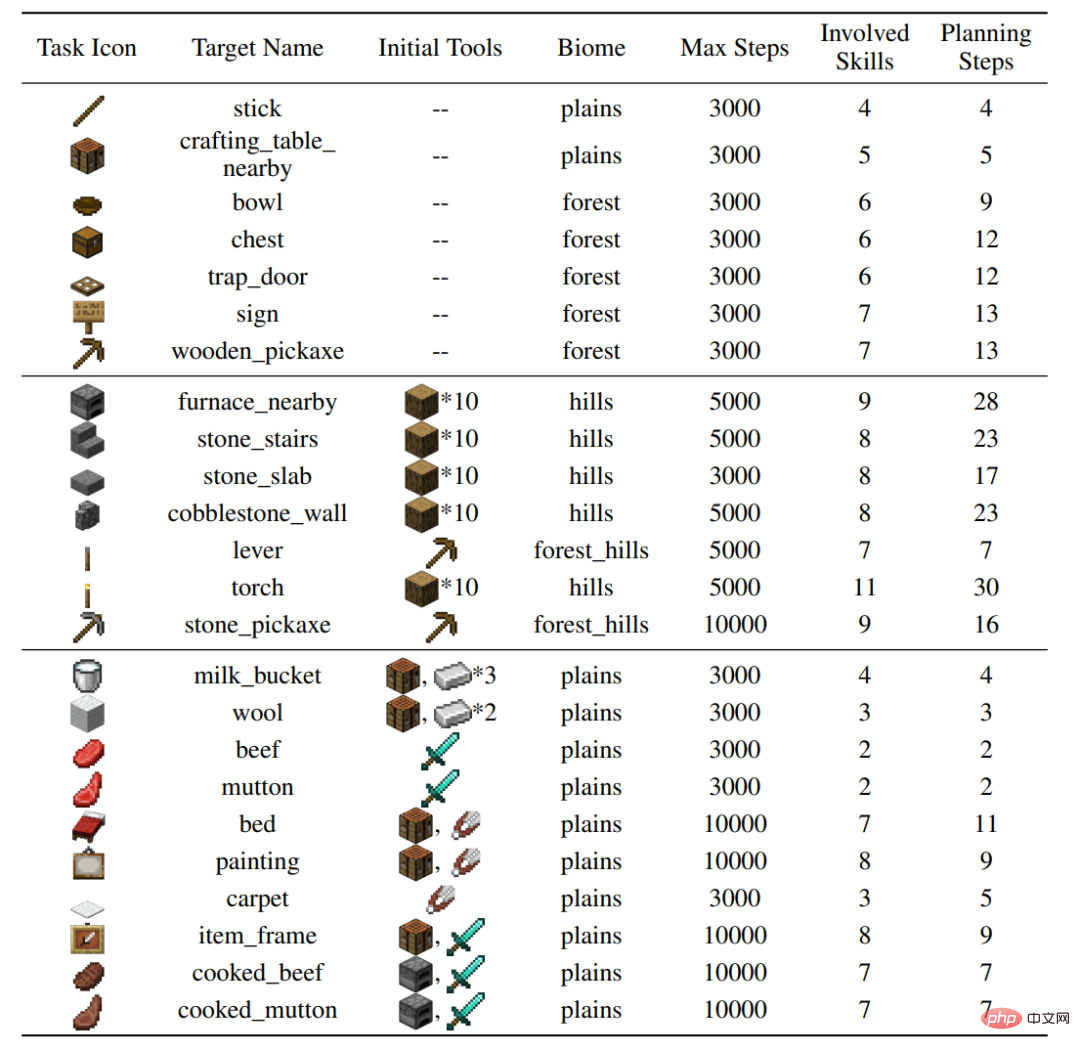
Compétences d'apprentissage
Étant donné que l'apprentissage par renforcement rend difficile pour les joueurs de courir et d'explorer le monde à grande échelle pendant l'entraînement, de nombreuses compétences ne peuvent toujours pas être maîtrisées. L'auteur a proposé de séparer les étapes d'exploration et de recherche, et d'affiner davantage la compétence « coupe d'arbres » en « trouver des arbres » et « obtenir du bois ». Toutes les compétences dans Minecraft sont divisées en trois catégories de compétences de base fines :
Pour chaque type de compétence, l'auteur conçoit un modèle d'apprentissage par renforcement et des récompenses intrinsèques pour un apprentissage efficace. Les compétences de recherche utilisent une stratégie hiérarchique, dans laquelle la stratégie de niveau supérieur est chargée de donner l'emplacement cible et d'augmenter la portée d'exploration, et la stratégie de niveau inférieur est responsable d'atteindre l'emplacement cible. Les compétences opérationnelles sont formées à l'aide de l'algorithme PPO combiné à la récompense intrinsèque du modèle MineCLIP. Les compétences synthétiques n’utilisent qu’une seule action à accomplir. Sur le simulateur MineDojo non modifié, l'apprentissage de toutes les compétences ne nécessite que 6,5 millions d'étapes d'interaction avec l'environnement.
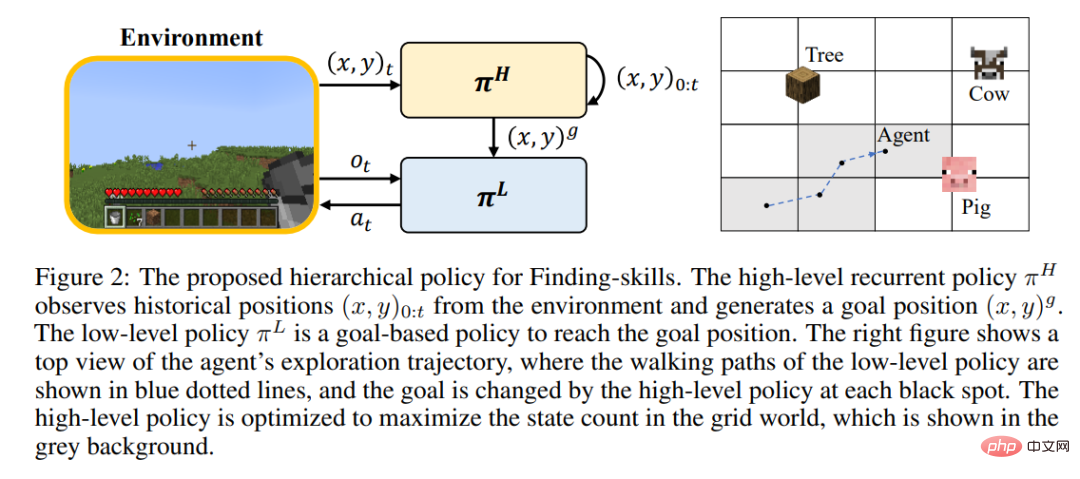
Algorithme de planification
Plan4MC utilise les dépendances entre les compétences pour la planification. Par exemple, il existe la relation suivante entre l'obtention d'une pioche en pierre et l'obtention de pierres brutes, de bâtons de bois, d'un établi placé et. d'autres compétences.

L'auteur a généré la relation entre toutes les compétences en interagissant avec le grand modèle de langage ChatGPT, et a construit un graphe acyclique dirigé de compétences. L'algorithme de planification est une recherche approfondie sur le graphique des compétences, comme le montre la figure ci-dessous.

Comparé à Inner Monologue, DEPS et d'autres méthodes de planification interactive avec de grands modèles de langage, Plan4MC peut efficacement éviter les erreurs dans le processus de planification de grands modèles de langage.
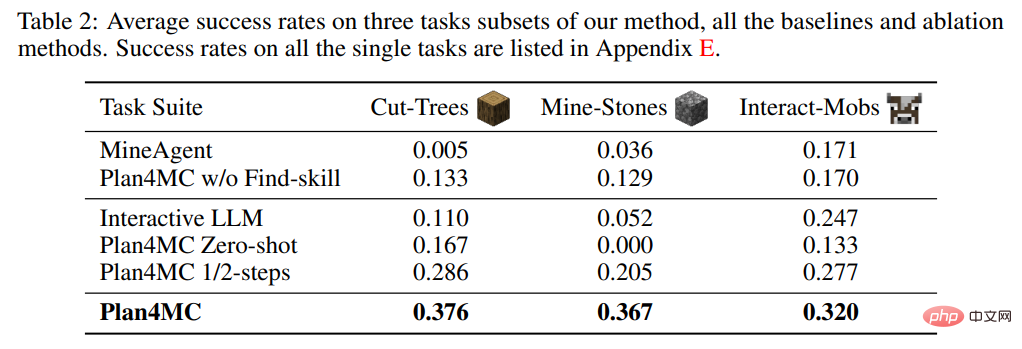
Dans l'étude des compétences d'apprentissage, l'auteur a introduit MineAgent sans décomposition des tâches et une expérience d'ablation Plan4MC sans Find - qui n'a pas subdivisé les compétences de recherche. Le tableau 2 montre que Plan4MC surpasse considérablement les méthodes de base sur les trois ensembles de tâches. Les performances de MineAgent sont proches de celles de Plan4MC sur des tâches simples telles que la traite des vaches et la tonte des moutons, mais il ne peut pas accomplir des tâches telles que l'abattage d'arbres et le creusement de pierres brutes difficiles à explorer. La méthode sans segmentation des compétences a un taux de réussite inférieur à Plan4MC sur toutes les tâches.
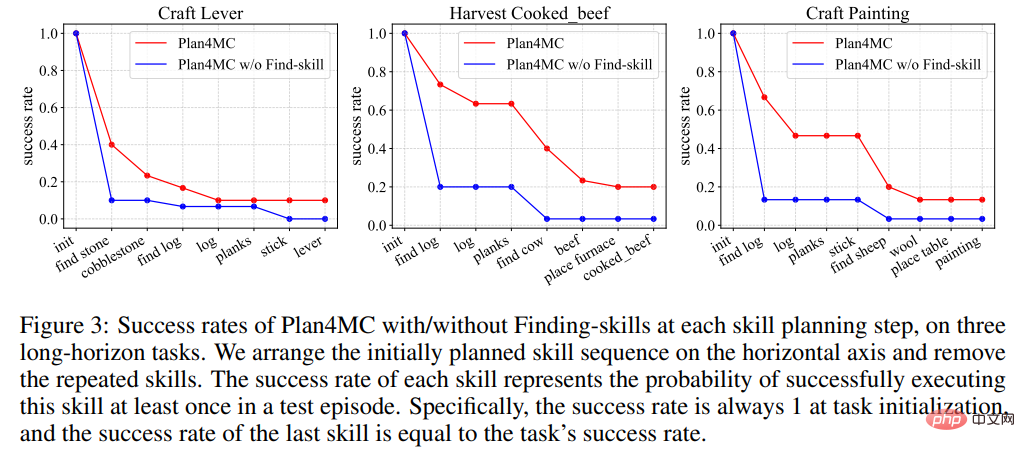
La figure 3 montre que dans le processus d'achèvement de la tâche, chaque méthode a une plus grande probabilité d'échec au stade de la recherche de la cible, ce qui entraîne une baisse de la courbe du taux de réussite. La probabilité d’échec de la méthode sans segmentation des compétences à ces étapes est nettement supérieure à celle de Plan4MC.
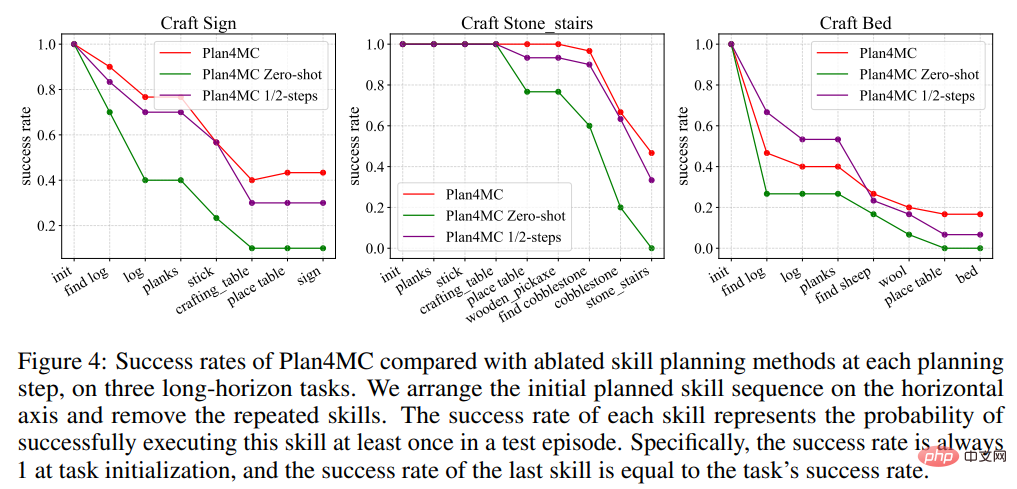
Dans la recherche sur la planification, l'auteur a présenté Interactive LLM, une méthode de base pour la planification interactive utilisant ChatGPT, et deux expériences d'ablation : la méthode Zero-shot qui ne replanifie pas lorsque l'exécution des compétences échoue et l'utilisation de la moitié du maximum. nombre d'étapes d'interaction La méthode des 1/2 étapes. Le tableau 2 montre que Interactive LLM fonctionne de manière proche de Plan4MC sur l'ensemble de tâches d'interaction avec les animaux, mais fonctionne mal sur les deux autres ensembles de tâches qui nécessitent plus d'étapes de planification. Les méthodes Zero-shot fonctionnent mal sur toutes les tâches. Le taux de réussite en utilisant la moitié du nombre d'étapes n'est pas bien inférieur à celui de Plan4MC. Il semble que Plan4MC puisse accomplir la tâche efficacement avec moins d'étapes.
L'auteur a proposé Plan4MC, qui utilise l'apprentissage par renforcement et la planification pour résoudre le multitâche dans Minecraft. Afin de résoudre les problèmes de difficulté d'exploration et d'efficacité des échantillons, l'auteur utilise l'apprentissage par renforcement avec des récompenses intrinsèques pour former les compétences de base et utilise de grands modèles de langage pour créer des graphiques de compétences pour la planification des tâches. Les auteurs ont vérifié les avantages de Plan4MC par rapport à diverses méthodes de base, dont ChatGPT, sur un grand nombre de tâches Minecraft difficiles.
Conclusion : Compétences d'apprentissage par renforcement + grands modèles de langage + planification des tâches permettent de mettre en œuvre le modèle de prise de décision humaine System1/2 décrit par Daniel Kahneman.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
 Base de données de restauration MySQL
Base de données de restauration MySQL
 Quels sont les frameworks Spring ?
Quels sont les frameworks Spring ?
 Comment débloquer les restrictions d'autorisation Android
Comment débloquer les restrictions d'autorisation Android
 Langage C pour trouver le multiple le plus petit commun
Langage C pour trouver le multiple le plus petit commun
 Qu'est-ce que la rigidité de l'utilisateur
Qu'est-ce que la rigidité de l'utilisateur
 Quel est le code espace en HTML
Quel est le code espace en HTML
 utilisation de la commande head
utilisation de la commande head
 Le but du niveau
Le but du niveau
 Quelles sont les principales différences entre Linux et Windows
Quelles sont les principales différences entre Linux et Windows








![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



