

Cet article présente le modèle chinois de représentation d'images et de texte de pré-formation à grande échelle CLIP récemment open source par la Damo Academy Magic Community ModelScope, qui peut mieux comprendre les images Internet chinoises et chinoises et peut être implémenté dans plusieurs tâches telles que l'image et récupération de texte et classification d'images sans échantillon. Le meilleur effet est obtenu en même temps, le code et les modèles sont tous open source et les utilisateurs peuvent utiliser Magic pour démarrer rapidement.

Dans l'écosystème Internet actuel, il existe d'innombrables tâches et scénarios liés multimodaux, tels que la récupération d'images et de texte, la classification d'images, le contenu vidéo et d'images et de texte et d'autres scénarios. Ces dernières années, la génération d’images, devenue populaire sur Internet, est devenue encore plus populaire et est rapidement sortie du cercle. Derrière ces tâches, un modèle puissant de compréhension des images et des textes est évidemment nécessaire. Je pense que tout le monde connaîtra le modèle CLIP lancé par OpenAI en 2021. Grâce à un simple apprentissage par comparaison image-texte à deux tours et à une grande quantité de corpus image-texte, le modèle possède d'importantes capacités d'alignement des caractéristiques image-texte et peut être utilisé dans la classification d'images à échantillon nul, il donne des résultats exceptionnels en matière de récupération multimodale et est également utilisé comme module clé dans les modèles de génération d'images tels que DALLE2 et Stable Diffusion.
Mais malheureusement, la pré-formation d'OpenAI CLIP utilise principalement des données graphiques et textuelles du monde anglais et ne peut naturellement pas prendre en charge le chinois. Même s'il existe des chercheurs dans la communauté qui ont distillé la version multilingue de Multilingual-CLIP (mCLIP) à travers des textes traduits, elle ne peut toujours pas répondre aux besoins du monde chinois. La compréhension des textes dans le domaine chinois n'est pas très bonne, par exemple. comme recherchant "Distiques de la Fête du Printemps", mais ce qui est renvoyé est du contenu lié à Noël :

mCLIP Récupérer la démo Rechercher "Distiques de la Fête du Printemps" Retourner les résultats
Cela montre également que nous J'ai besoin d'un CLIP qui comprend mieux le chinois, non seulement notre langue comprend également mieux les images du monde chinois.
Les chercheurs de la DAMO Academy ont collecté des données sur les paires image-texte chinoises à grande échelle (à l'échelle d'environ 200 millions), y compris des données chinoises du sous-ensemble chinois LAION-5B, Wukong et de COCO, le graphique traduit de Visual Genome. et données texte, etc. La plupart des images et textes de formation proviennent d’ensembles de données publiques, ce qui réduit considérablement la difficulté de reproduction. En termes de méthodes de formation, afin d'améliorer efficacement l'efficacité de la formation et l'effet de modèle du modèle, les chercheurs ont conçu un processus de formation en deux étapes :
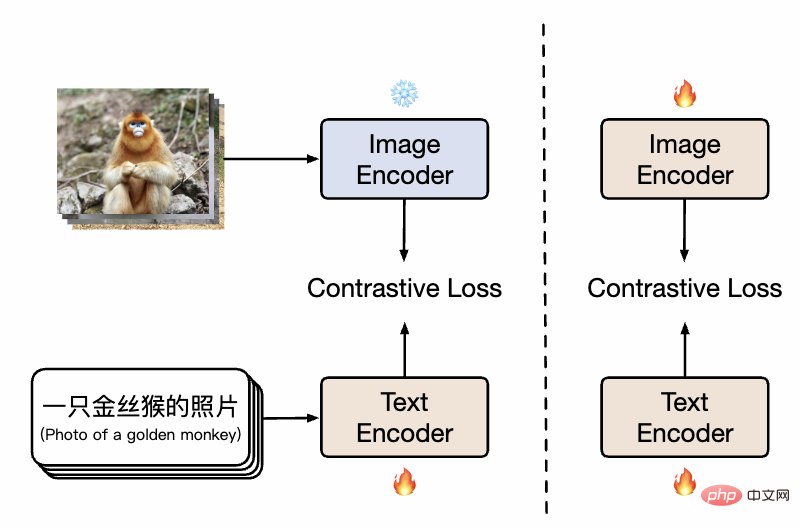
Diagramme de la méthode CLIP chinoise
comme le montre l'image, dans la première étape, le modèle utilise le modèle de pré-entraînement d'image et le modèle de pré-entraînement de texte existants pour initialiser respectivement les tours jumelles de Chinese-CLIP, et gèle les paramètres côté image pour permettre au modèle de langage à associer à l'espace de représentation de pré-entraînement d'image existant. Dans le même temps, les frais généraux de formation sont réduits. Par la suite, dans un deuxième temps, les paramètres côté image sont dégelés, permettant d'associer le modèle d'image et le modèle de langage tout en modélisant la distribution des données avec les caractéristiques chinoises. Les chercheurs ont découvert que par rapport à la pré-formation à partir de zéro, cette méthode a montré des résultats expérimentaux nettement meilleurs sur plusieurs tâches en aval, et son efficacité de convergence nettement plus élevée signifiait également une charge de formation réduite. Par rapport à la formation uniquement du côté texte dans une étape de formation, l'ajout de la deuxième étape de formation peut effectivement améliorer encore l'effet sur les tâches graphiques et textuelles en aval, en particulier les tâches graphiques et textuelles natives du chinois (plutôt que traduites à partir d'ensembles de données anglais).
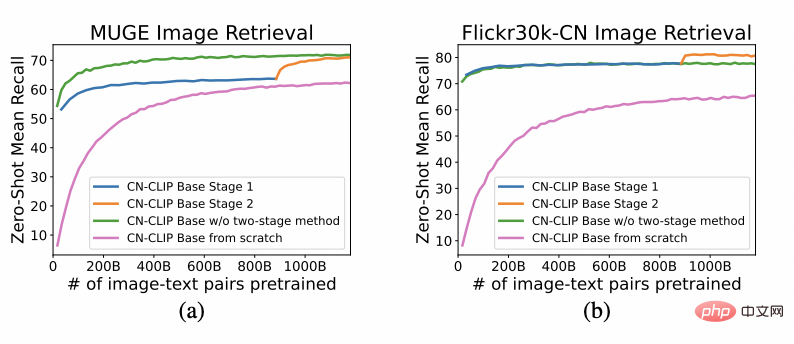
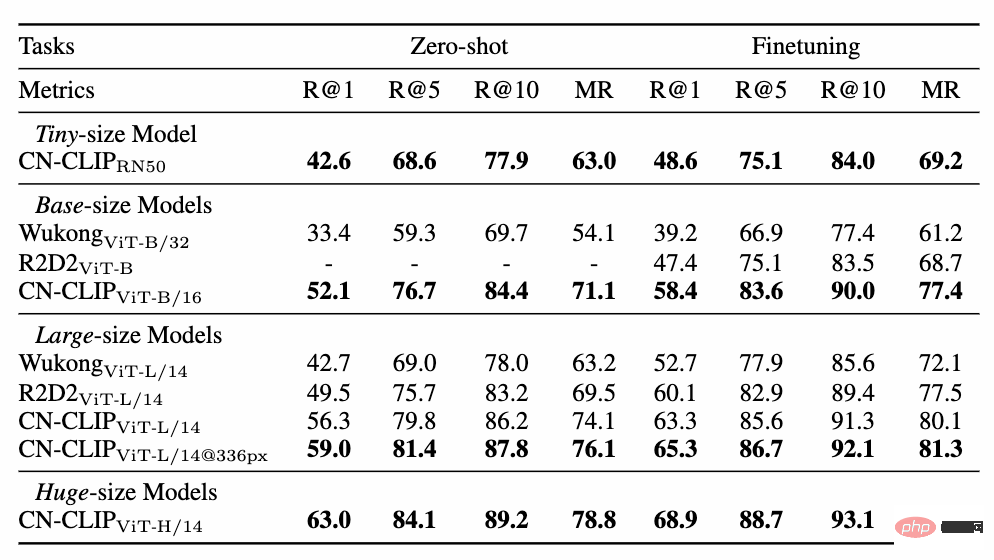
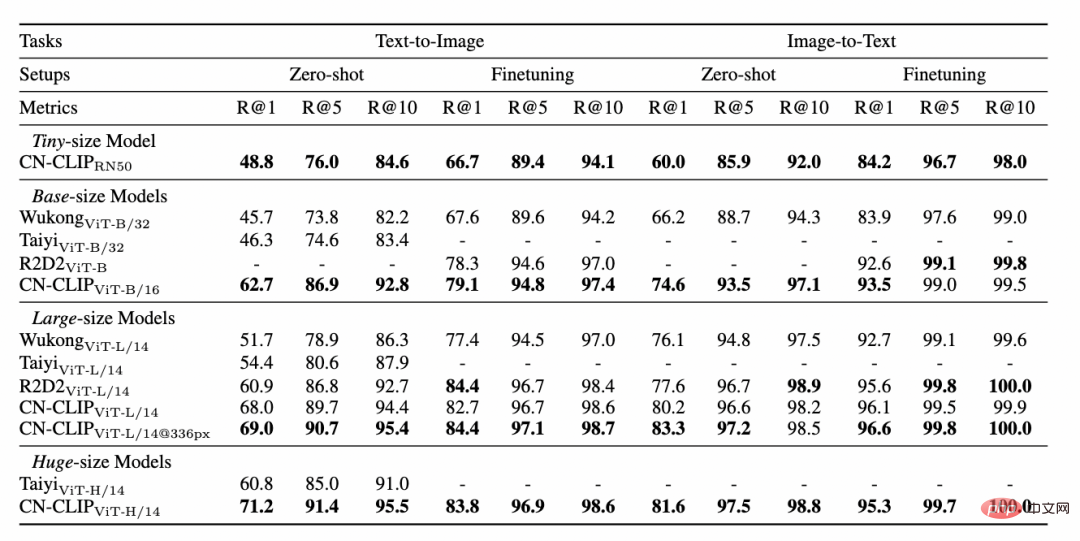
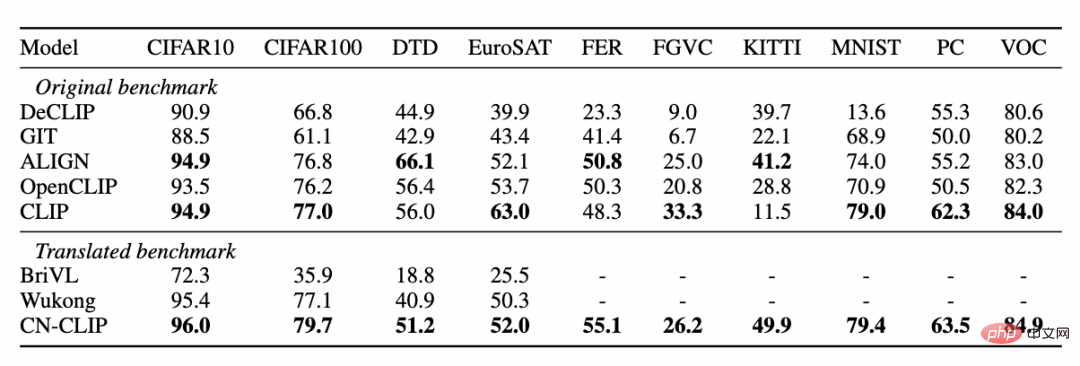
Observez la tendance changeante de l'effet du tir zéro alors que la pré-formation se poursuit sur deux ensembles de données : la récupération d'images et de textes du commerce électronique chinois MUGE et la version de traduction Flickr30K-CN, la récupération générale d'images et de textes. Grâce à cette stratégie, les chercheurs ont formé des modèles de plusieurs tailles, du plus petit ResNet-50, ViT-Base et Large au ViT-Huge. Ils sont tous désormais ouverts et les utilisateurs peuvent utiliser le modèle qui leur convient le mieux sur demande. modèle : De multiples données expérimentales montrent que le chinois-CLIP peut atteindre les meilleures performances en matière de récupération intermodale chinoise, parmi lesquelles l'ensemble de données de récupération d'images de commerce électronique natif chinois MUGE, chinois. CLIP à plusieurs échelles a obtenu les meilleures performances à cette échelle. Sur le Flickr30K-CN d'origine anglaise et d'autres ensembles de données, le CLIP chinois peut dépasser considérablement les modèles de référence nationaux tels que Wukong, Taiyi et R2D2, quels que soient les paramètres d'échantillonnage nul ou de réglage fin. Cela est en grande partie dû au plus grand corpus d'images et de texte de pré-formation en chinois de Chinese-CLIP, et Chinese-CLIP est différent de certains modèles nationaux existants de représentation d'images et de texte afin de minimiser le coût de formation et de geler tout le côté de l'image. utilise deux stratégies de formation par étapes pour mieux s'adapter au domaine chinois : MUGE chinois e-commerce récupération d'images et de textes résultats expérimentaux Flickr30K-CN chinois Résultats expérimentaux sur l'ensemble de données de récupération d'images et de textes Dans le même temps, les chercheurs ont vérifié l'effet du CLIP chinois sur l'ensemble de données de classification d'images zéro plan. Puisqu’il n’existe pas beaucoup de tâches de classification d’images à tir nul faisant autorité dans le domaine chinois, les chercheurs testent actuellement la version traduite en anglais de l’ensemble de données. Chinese-CLIP peut atteindre des performances comparables à CLIP sur ces tâches grâce aux invites et aux étiquettes de catégorie chinoises : Comment utiliser Chinese-CLIP ? C'est très simple. Cliquez sur le lien au début de l'article pour visiter la communauté Moda ou utiliser du code open source. Vous pouvez effectuer l'extraction des caractéristiques des images et du texte et le calcul de similarité en quelques lignes seulement. Pour une utilisation et une expérience rapides, la communauté Moda propose un Notebook avec un environnement configuré. Vous pouvez l'utiliser en cliquant sur le coin supérieur droit. 5. Conclusion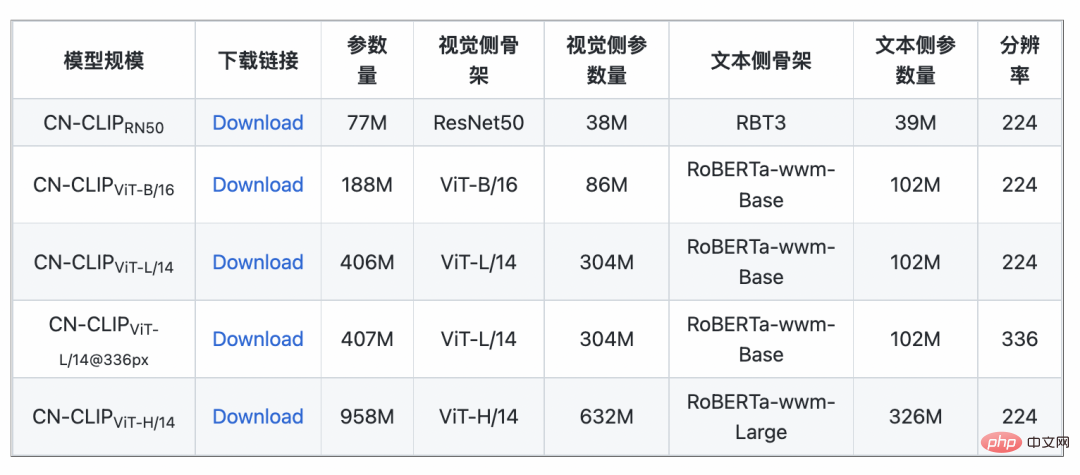
3. Expérience
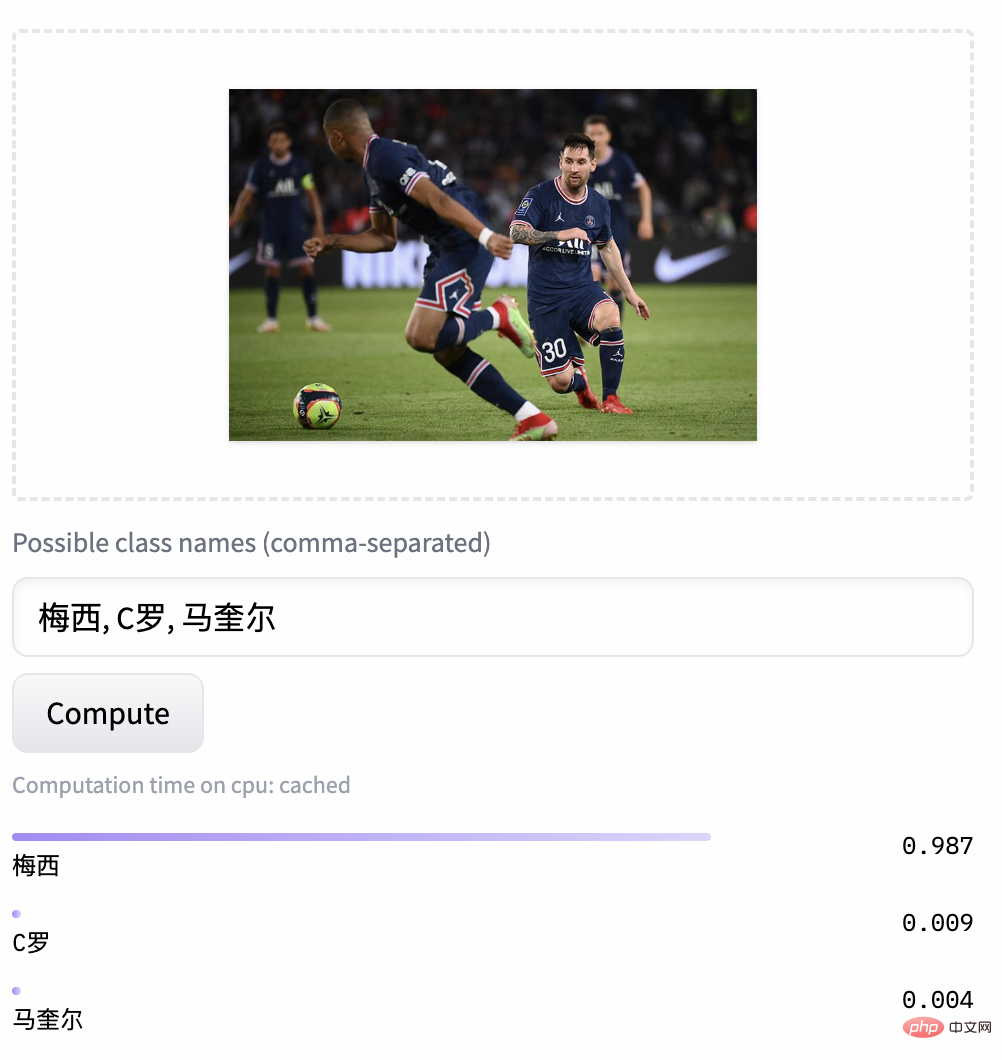 Chinese-CLIP aide également les utilisateurs à utiliser leurs propres données pour un réglage fin, et fournit également une démonstration de récupération d'images et de texte pour que chacun puisse réellement expérimenter les effets des modèles Chinese-CLIP de différentes tailles :
Chinese-CLIP aide également les utilisateurs à utiliser leurs propres données pour un réglage fin, et fournit également une démonstration de récupération d'images et de texte pour que chacun puisse réellement expérimenter les effets des modèles Chinese-CLIP de différentes tailles :
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
 La solution au paramètre d'interface chinoise de vscode ne prend pas effet
La solution au paramètre d'interface chinoise de vscode ne prend pas effet
 Tutoriel de modification du logiciel C++ en chinois
Tutoriel de modification du logiciel C++ en chinois
 Utilisation de l'image d'arrière-plan
Utilisation de l'image d'arrière-plan
 Quelles sont les méthodes de production de production d'animation html5 ?
Quelles sont les méthodes de production de production d'animation html5 ?
 Comment configurer la mémoire virtuelle
Comment configurer la mémoire virtuelle
 html définir la taille de la couleur de la police
html définir la taille de la couleur de la police
 Le WiFi est connecté mais il y a un point d'exclamation
Le WiFi est connecté mais il y a un point d'exclamation
 Quel est le format de fichier mkv ?
Quel est le format de fichier mkv ?








![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



