
 Périphériques technologiques
IA
Battez à nouveau OpenAI ! Google lance un modèle universel de 2 milliards de paramètres pour reconnaître et traduire automatiquement plus de 100 langues
Périphériques technologiques
IA
Battez à nouveau OpenAI ! Google lance un modèle universel de 2 milliards de paramètres pour reconnaître et traduire automatiquement plus de 100 langues
Battez à nouveau OpenAI ! Google lance un modèle universel de 2 milliards de paramètres pour reconnaître et traduire automatiquement plus de 100 langues

La semaine dernière, OpenAI a publié l'API ChatGPT et l'API Whisper, ce qui vient de déclencher un carnaval des développeurs.
Le 6 mars, Google a lancé un modèle de référence-USM. Non seulement il peut prendre en charge plus de 100 langues, mais le nombre de paramètres a également atteint 2 milliards.
Bien sûr, le modèle n'est toujours pas ouvert au public, "C'est très Google" !
En termes simples, le modèle USM est pré-entraîné sur un ensemble de données non étiquetées couvrant 12 millions d'heures de parole, 28 milliards de phrases et 300 langues différentes, et formé sur un ensemble de données annotées plus petit. -réglage.
Les chercheurs de Google ont déclaré que bien que l'ensemble d'entraînement aux annotations utilisé pour le réglage fin ne représente que 1/7 de Whisper, USM a des performances équivalentes, voire meilleures, et peut s'adapter efficacement à de nouvelles langues et données. Les résultats montrent que l'USM n'est pas seulement efficace dans la reconnaissance vocale automatique multilingue et la traduction de textes vocaux. évaluation des tâches SOTA est implémenté et peut réellement être utilisé dans la génération de sous-titres YouTube.
 Actuellement, les langues qui prennent en charge la détection et la traduction automatiques incluent l'anglais traditionnel, le chinois et les petites langues telles que l'assamais.
Actuellement, les langues qui prennent en charge la détection et la traduction automatiques incluent l'anglais traditionnel, le chinois et les petites langues telles que l'assamais.
Le plus important est qu'il peut également être utilisé pour la traduction en temps réel des futures lunettes AR présentées par Google lors de la conférence IO de l'année dernière.
Jeff Dean a personnellement annoncé : Laissez l'IA prendre en charge 1000 languesLorsque Microsoft et Google se disputent pour savoir qui a le meilleur chatbot IA, vous devez savoir que les grands modèles de langage Les utilisations ne s'arrêtent pas là.
En novembre de l'année dernière, Google a annoncé pour la première fois un nouveau projet "visant à développer un modèle de langage d'intelligence artificielle prenant en charge les 1 000 langues les plus couramment utilisées dans le monde".

La même année, Meta a également publié un modèle appelé "No Language Left Behind", affirmant qu'il pouvait traduire plus de 200 langues, dans le but de créer un "traducteur universel".
La sortie du dernier modèle, Google le décrit comme une "étape cruciale" vers l'objectif.
 On peut dire qu'il existe de nombreux héros en compétition dans la construction de modèles linguistiques.
On peut dire qu'il existe de nombreux héros en compétition dans la construction de modèles linguistiques.
Selon les rumeurs, Google prévoit de présenter plus de 20 produits alimentés par l'intelligence artificielle lors de la conférence annuelle I/O de cette année.
Cartement, la reconnaissance automatique de la parole est confrontée à de nombreux défis:
Méthodes d'apprentissage supervisées par voie de l'argent, ou une collecte à partir de sources avec des transcriptions préexistantes, difficiles à trouver pour les langues qui manquent d'une large représentation.
Cela nécessite que l'algorithme soit capable d'utiliser de grandes quantités de données provenant de différentes sources sans devoir complètement Activer les mises à jour du modèle avec recyclage et possibilité de généralisation à de nouveaux langages et cas d'utilisation. Selon l'article, la formation USM utilise trois bases de données : un ensemble de données audio non appariées, un ensemble de données textuelles non appariées et un corpus ASR apparié. YT-NTL-U (plus de 12 millions d'heures de données audio non balisées YouTube) et Pub-U (plus de 429 000 heures) Contenu du discours en 51 langues) Web-NTL (28 milliards de phrases dans plus de 1140 langues différentes) ... Le processus de formation est divisé en trois étapes. Apprentissage auto-supervisé affiné

Dans l'étape suivante, le modèle d'apprentissage de la représentation vocale est entraîné davantage.
Utilisez MOST (Multi-Object Supervised Pre-training) pour intégrer des informations provenant d'autres données textuelles.
Le modèle introduit un module d'encodeur supplémentaire qui prend le texte en entrée et introduit des couches supplémentaires pour combiner les sorties de l'encodeur vocal et de l'encodeur de texte et combiner la sortie de la parole non étiquetée, la parole étiquetée Entraîner conjointement le modèle sur les données textuelles .
La dernière étape consiste à affiner les tâches ASR (reconnaissance automatique de la parole) et AST (traduction automatique de la parole). Le modèle USM pré-entraîné peut obtenir de bonnes performances avec seulement une petite quantité de données de supervision.
Processus global de formation USM
Quelles sont les performances d'USM Google l'a testé sur les sous-titres YouTube, la promotion des tâches ASR en aval et la traduction automatique de la parole.
Performance sur les sous-titres multilingues YouTube
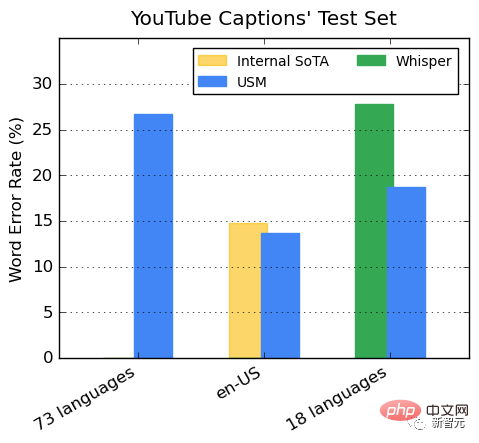
Les données YouTube supervisées comprennent 73 langues, avec une moyenne d'un peu moins de 3 000 heures de données par langue. Malgré des données de supervision limitées, le modèle a atteint un taux d'erreur de mots (WER) moyen inférieur à 30 % dans 73 langues, ce qui est inférieur aux modèles de pointe aux États-Unis.
De plus, Google l'a comparé au modèle Whisper (big-v2) entraîné avec plus de 400 000 heures de données annotées.
Parmi les 18 langues que Whisper peut décoder, son taux d'erreur de décodage est inférieur à 40%, tandis que l'erreur moyenne de l'USM le taux n’est que de 32,7%. Promotion des tâches ASR en aval
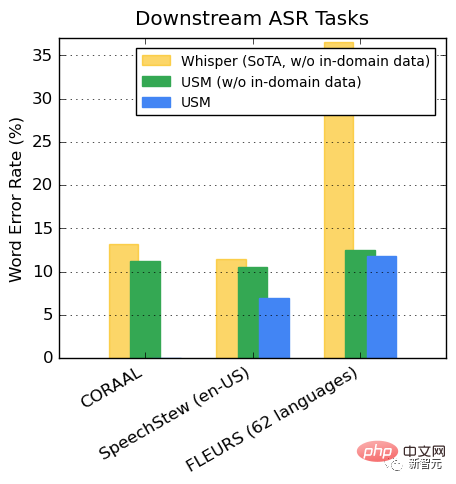
 Sur l'ensemble de données publiques, par rapport à Whisper, USM a de meilleures performances en CORAAL (Dialecte afro-américain anglais ), SpeechStew (anglais-US) et FLEURS (102 langues) affichent un WER inférieur, avec ou sans données de formation dans le domaine. La différence entre les deux modèles de FLEURS est particulièrement évidente. Performance sur la tâche AST
Sur l'ensemble de données publiques, par rapport à Whisper, USM a de meilleures performances en CORAAL (Dialecte afro-américain anglais ), SpeechStew (anglais-US) et FLEURS (102 langues) affichent un WER inférieur, avec ou sans données de formation dans le domaine. La différence entre les deux modèles de FLEURS est particulièrement évidente. Performance sur la tâche AST
Affiner l'USM sur l'ensemble de données CoVoST.
Divisez les langues de l'ensemble de données en catégories élevées, moyennes et faibles en fonction de la disponibilité des ressources, et calculez le score BLEU dans chaque catégorie (plus c'est haut, mieux c'est), USM surpasse Whisper dans toutes les catégories.
La recherche a révélé que la pré-formation BEST-RQ est un moyen efficace d'étendre l'apprentissage de la représentation vocale à de grands ensembles de données.
En formant des modules adaptateurs résiduels légers, MOST représente la capacité de s'adapter rapidement à de nouveaux domaines. Ces modules adaptateurs restants n'augmentent les paramètres que de 2 %. Actuellement, USM prend en charge plus de 100 langues et s'étendra à plus de 1 000 langues à l'avenir. Grâce à cette technologie, tout le monde peut voyager en toute sécurité à travers le monde.
Même les produits de lunettes Google AR avec traduction en temps réel attireront de nombreux fans à l'avenir.
Cependant, l'application de cette technologie a encore un long chemin à parcourir.
Après tout, dans son discours à la conférence IO face au monde, Google a également écrit le texte arabe à l'envers, attirant de nombreux internautes à montre.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

Video Face Swap
Échangez les visages dans n'importe quelle vidéo sans effort grâce à notre outil d'échange de visage AI entièrement gratuit !

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Sesame Open Door Exchange Page d'enregistrement de page Enregistrement Gate Trading App The Registration Site Web
Feb 28, 2025 am 11:06 AM
Sesame Open Door Exchange Page d'enregistrement de page Enregistrement Gate Trading App The Registration Site Web
Feb 28, 2025 am 11:06 AM
Cet article présente le processus d'enregistrement de la version Web de Sesame Open Exchange (GATE.IO) et l'application Gate Trading en détail. Qu'il s'agisse de l'enregistrement Web ou de l'enregistrement de l'application, vous devez visiter le site Web officiel ou l'App Store pour télécharger l'application authentique, puis remplir le nom d'utilisateur, le mot de passe, l'e-mail, le numéro de téléphone mobile et d'autres informations et terminer la vérification des e-mails ou du téléphone mobile.
 Pourquoi le lien d'échange de Bybit ne peut-il pas être téléchargé directement et installé?
Feb 21, 2025 pm 10:57 PM
Pourquoi le lien d'échange de Bybit ne peut-il pas être téléchargé directement et installé?
Feb 21, 2025 pm 10:57 PM
Pourquoi le lien d'échange de Bybit ne peut-il pas être téléchargé directement et installé? Bybit est un échange de crypto-monnaie qui fournit des services de trading aux utilisateurs. Les applications mobiles de l'échange ne peuvent pas être téléchargées directement via AppStore ou GooglePlay pour les raisons suivantes: 1. La politique de l'App Store empêche Apple et Google d'avoir des exigences strictes sur les types d'applications autorisées dans l'App Store. Les demandes d'échange de crypto-monnaie ne répondent souvent pas à ces exigences car elles impliquent des services financiers et nécessitent des réglementations et des normes de sécurité spécifiques. 2. Conformité des lois et réglementations Dans de nombreux pays, les activités liées aux transactions de crypto-monnaie sont réglementées ou restreintes. Pour se conformer à ces réglementations, l'application ByBit ne peut être utilisée que via des sites Web officiels ou d'autres canaux autorisés
 Sesame Open Door Exchange Page Web Login Dernière version GATEIO Entrée du site officiel
Mar 04, 2025 pm 11:48 PM
Sesame Open Door Exchange Page Web Login Dernière version GATEIO Entrée du site officiel
Mar 04, 2025 pm 11:48 PM
Une introduction détaillée à l'opération de connexion de la version Web Sesame Open Exchange, y compris les étapes de connexion et le processus de récupération de mot de passe.
 Sesame Open Door Trading Platform Download Version mobile Gateio Trading Plateforme de téléchargement Adresse de téléchargement
Feb 28, 2025 am 10:51 AM
Sesame Open Door Trading Platform Download Version mobile Gateio Trading Plateforme de téléchargement Adresse de téléchargement
Feb 28, 2025 am 10:51 AM
Il est crucial de choisir un canal formel pour télécharger l'application et d'assurer la sécurité de votre compte.
 Top 10 recommandé pour l'application de trading d'actifs numériques crypto (2025 Global Ranking)
Mar 18, 2025 pm 12:15 PM
Top 10 recommandé pour l'application de trading d'actifs numériques crypto (2025 Global Ranking)
Mar 18, 2025 pm 12:15 PM
Cet article recommande les dix principales plates-formes de trading de crypto-monnaie qui méritent d'être prêtées, notamment Binance, Okx, Gate.io, Bitflyer, Kucoin, Bybit, Coinbase Pro, Kraken, Bydfi et Xbit décentralisées. Ces plateformes ont leurs propres avantages en termes de quantité de devises de transaction, de type de transaction, de sécurité, de conformité et de fonctionnalités spéciales. Le choix d'une plate-forme appropriée nécessite une considération complète en fonction de votre propre expérience de trading, de votre tolérance au risque et de vos préférences d'investissement. J'espère que cet article vous aide à trouver le meilleur costume pour vous-même
 Binance Binance Site officiel Dernière version Portail de connexion
Feb 21, 2025 pm 05:42 PM
Binance Binance Site officiel Dernière version Portail de connexion
Feb 21, 2025 pm 05:42 PM
Pour accéder à la dernière version du portail de connexion du site Web de Binance, suivez simplement ces étapes simples. Accédez au site officiel et cliquez sur le bouton "Connectez-vous" dans le coin supérieur droit. Sélectionnez votre méthode de connexion existante. Entrez votre numéro de mobile ou votre mot de passe enregistré et votre mot de passe et complétez l'authentification (telles que le code de vérification mobile ou Google Authenticator). Après une vérification réussie, vous pouvez accéder à la dernière version du portail de connexion du site Web officiel de Binance.
 Bitget Trading Plateforme Adresse de téléchargement et d'installation de l'application officielle
Feb 25, 2025 pm 02:42 PM
Bitget Trading Plateforme Adresse de téléchargement et d'installation de l'application officielle
Feb 25, 2025 pm 02:42 PM
Ce guide fournit des étapes de téléchargement et d'installation détaillées pour l'application officielle Bitget Exchange, adaptée aux systèmes Android et iOS. Le guide intègre les informations de plusieurs sources faisant autorité, y compris le site officiel, l'App Store et Google Play, et met l'accent sur les considérations pendant le téléchargement et la gestion des comptes. Les utilisateurs peuvent télécharger l'application à partir des chaînes officielles, y compris l'App Store, le téléchargement officiel du site Web APK et le saut de site Web officiel, ainsi que des paramètres d'enregistrement, de vérification d'identité et de sécurité. De plus, le guide couvre les questions et considérations fréquemment posées, telles que
 La dernière adresse de téléchargement de Bitget en 2025: étapes pour obtenir l'application officielle
Feb 25, 2025 pm 02:54 PM
La dernière adresse de téléchargement de Bitget en 2025: étapes pour obtenir l'application officielle
Feb 25, 2025 pm 02:54 PM
Ce guide fournit des étapes de téléchargement et d'installation détaillées pour l'application officielle Bitget Exchange, adaptée aux systèmes Android et iOS. Le guide intègre les informations de plusieurs sources faisant autorité, y compris le site officiel, l'App Store et Google Play, et met l'accent sur les considérations pendant le téléchargement et la gestion des comptes. Les utilisateurs peuvent télécharger l'application à partir des chaînes officielles, y compris l'App Store, le téléchargement officiel du site Web APK et le saut de site Web officiel, ainsi que des paramètres d'enregistrement, de vérification d'identité et de sécurité. De plus, le guide couvre les questions et considérations fréquemment posées, telles que
