


À la fin du chapitre Stream, nous nous retrouvons avec une question : quel est le morceau généré par le code suivant ?
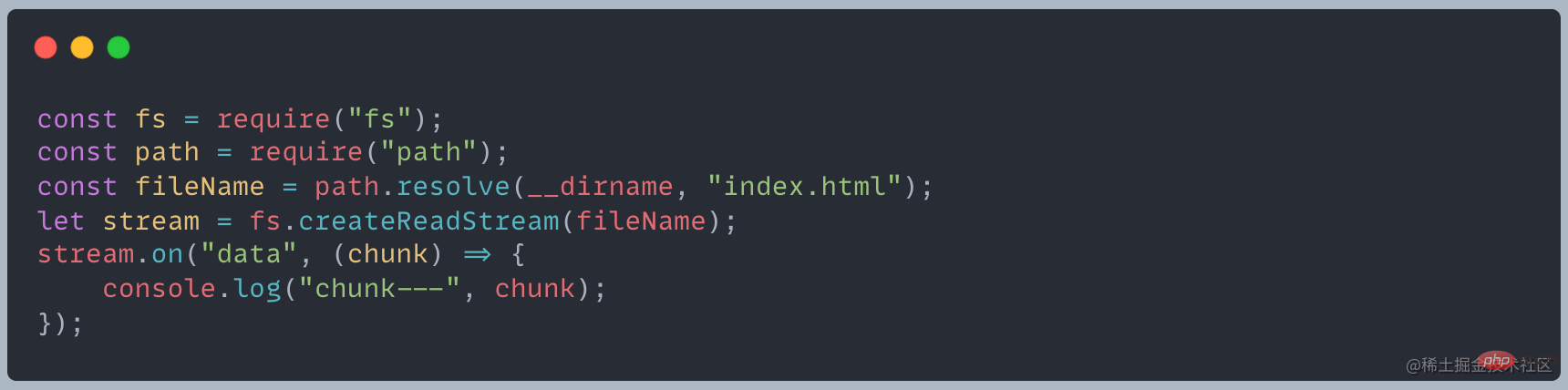
En imprimant, nous constatons que chunk est un objet Buffer dont les éléments sont des nombres hexadécimaux à deux chiffres, c'est-à-dire des valeurs de 0 à 255. [Recommandations de tutoriel associées : tutoriel vidéo Nodejs, Enseignement de la programmation]

explique que les données circulant dans le Stream sont le Buffer, explorons donc le vrai visage du Buffer !
? Pourquoi Buffer est-il introduit dans Node ?
Au début, JS ne fonctionnait que du côté du navigateur. Il était facile de traiter les chaînes codées en Unicode, mais il était difficile de traiter les chaînes codées en binaire et non Unicode. . Et le binaire est le format de données de niveau le plus bas de l'ordinateur. Les paquets vidéo/audio/programme/réseau sont tous stockés en binaire. Node doit donc introduire un objet pour faire fonctionner le binaire, c'est pourquoi Buffer est né, qui est utilisé pour le flux/système de fichiers TCP et d'autres opérations pour traiter les octets binaires.
Comme Buffer est trop couramment utilisé dans Node, Buffer a été introduit au démarrage de Node. Il n'est pas nécessaire d'utiliser require()
ArrayBuffer est un morceau de données binaires dans la mémoire et ne peut pas fonctionner. la mémoire elle-même, doit être exploitée via un Objet TypedArray ou DataView. Représentez les données dans le tampon dans un format spécifique, et lisez et écrivez le contenu du tampon via ces formats. Il déploie une interface de tableau et peut utiliser des tableaux pour manipuler les données
La plus couramment utilisée est la vue TypeArray. , utilisé pour lire et écrire des types simples d'ArrayBuffer, tels que la vue tableau Uint8Array (entier non signé de 8 bits), la vue tableau Int16Array (entier 16 bits)
et Buffer
Structure du tampon
Structure du module
Structure de l'objet
L'objet Buffer est similaire à un tableau, ses éléments sont des nombres hexadécimaux à deux chiffres, c'est-à-dire des valeurs de 0 à 255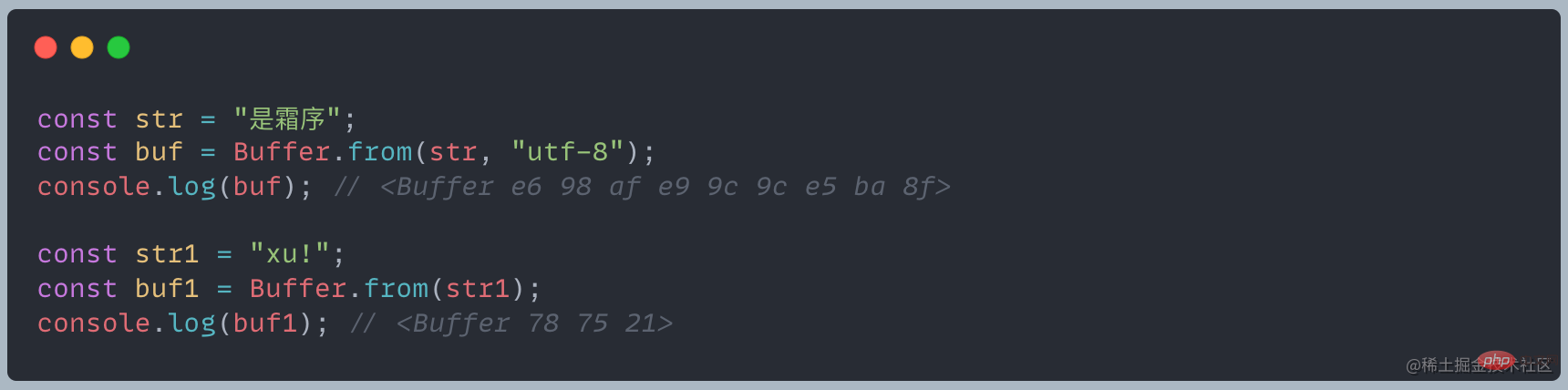
Comme le montre cet exemple, les octets occupés par différents caractères dans le tampon sont différents, sous l'encodage UTF-8, le chinois occupe 3 octets, l'anglais et les symboles demi-largeur occupent 1 octetQue se passera-t-il si l'élément d'entrée est un nombre décimal/négatif/dépasse 255 ? ?
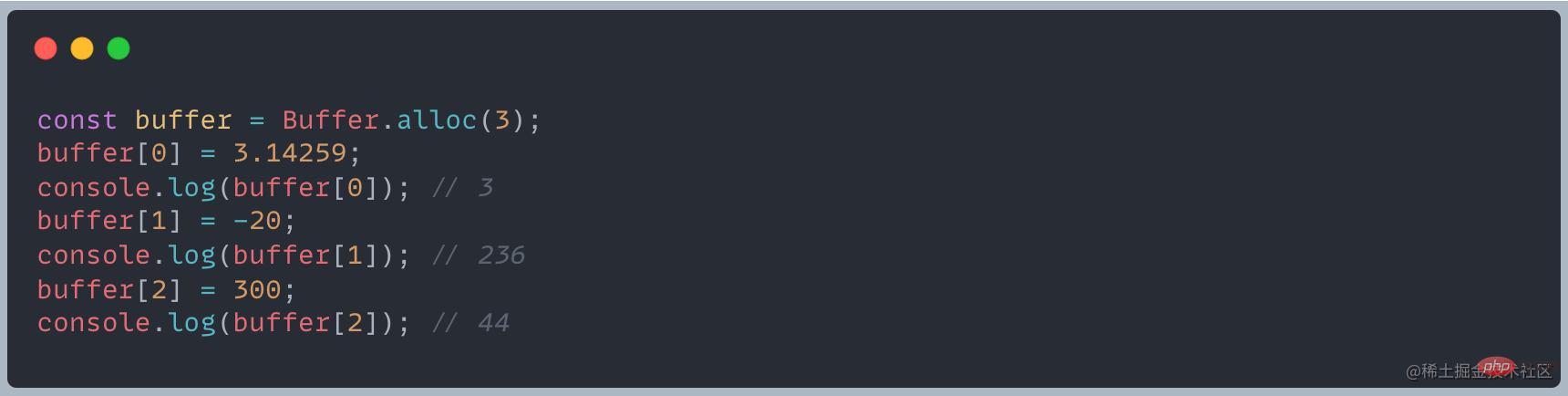
Pourquoi le système hexadécimal affiché dans le Buffer
en fait toujours stocké dans la mémoire. Il s'agit d'un nombre binaire, mais Buffer utilise l'hexadécimal lors de l'affichage des données de la mémoire. La taille du tampon est de 2 octets, avec un total de 16 bits. création de 00000001 00100011,如果直接这样显示不太方便就转成为了16进制<buffer></buffer>
Créer un buffer de taille fixe

Alloue un tampon de taille en octets. allocUnsafe s'exécute plus rapidement que alloc. Nous avons constaté que ses résultats ne sont pas initialisés à 00 comme Buffer.alloc.
Le segment de mémoire alloué lors de l'appel de allocUnsafe n'a pas été initialisé, la vitesse d'allocation de mémoire est donc très lente, mais le segment de mémoire alloué peut contenir d'anciennes données. Si ces anciennes données ne sont pas écrasées lors de l'utilisation, des fuites de mémoire peuvent survenir. Bien que ce soit rapide, essayez d'éviter de l'utiliser. Le module Buffer pré-allouera une instance Buffer interne d'une taille de Buffer.poolSize comme pool de mémoire à allocation rapide. . Utilisez Utilisez allocUnsafe pour créer une nouvelle instance de Buffer Buffer.from
Buffer.from
Créez un Buffer directement basé sur le contenu
Buffer.from(string [, encoding])Buffer.from(array)Buffer. from(buffer) Utilisez Buffer.alloc(size ) Le passage d'une taille spécifiée s'appliquera à une zone mémoire de taille fixe. La dalle a les trois états suivants : complet : état entièrement alloué
Utilisez Buffer.alloc(size ) Le passage d'une taille spécifiée s'appliquera à une zone mémoire de taille fixe. La dalle a les trois états suivants : complet : état entièrement alloué
vide : état non alloué.
Node .js utilise 8 Ko comme limite pour distinguer les petits objets des gros objets. La taille du Buffer est déterminée lors de sa création et ne peut pas être ajustée ! Une unité de dalle
Une unité de dalle
Allouer un tampon de 2 KoAprès avoir créé un tampon de 2 Ko, une La dalle la mémoire de l'unité est la suivante :
Ce processus d'allocation est complété par la méthode d'allocation 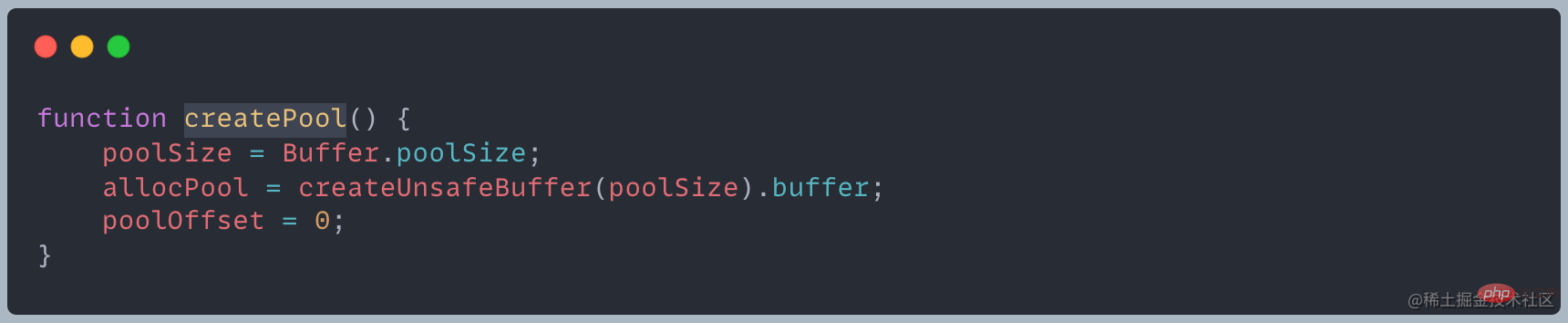
Après avoir créé un tampon de 2 Ko, l'état actuel de la dalle est partiel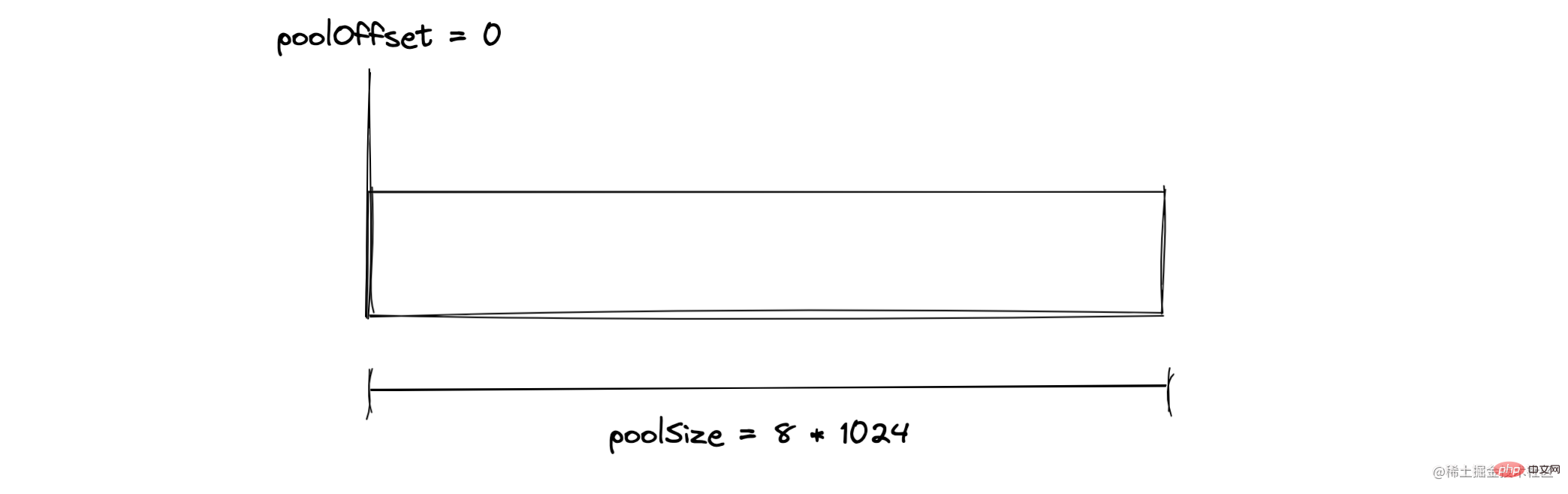
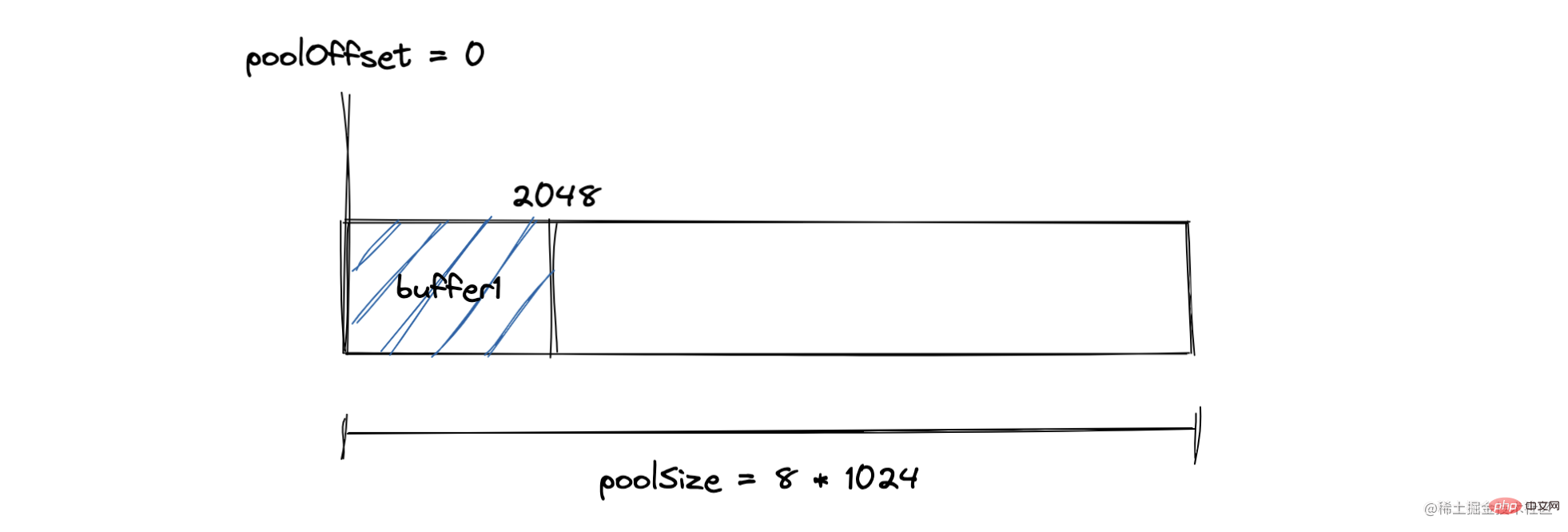 S'il y a un tampon dépassant 8 Ko, il ira directement à la fonction creatUnsafeBuffer et allouera une unité de dalle qui sera exclusivement occupée par ce grand objet Buffer. Le mécanisme d'allocation d'allocation est comme indiqué dans la figure. Le mécanisme de Buffer est tel qu'illustré dans la figure. En utilisant le codage de caractères, les instances de Buffer et les chaînes JavaScript peuvent être converties les unes vers les autres
S'il y a un tampon dépassant 8 Ko, il ira directement à la fonction creatUnsafeBuffer et allouera une unité de dalle qui sera exclusivement occupée par ce grand objet Buffer. Le mécanisme d'allocation d'allocation est comme indiqué dans la figure. Le mécanisme de Buffer est tel qu'illustré dans la figure. En utilisant le codage de caractères, les instances de Buffer et les chaînes JavaScript peuvent être converties les unes vers les autres
.
Node prend actuellement en charge huit méthodes d'encodage : utf8, ucs2, utf16le, latin1, ascii, base64, hex et base64Url Implémentation spécifique
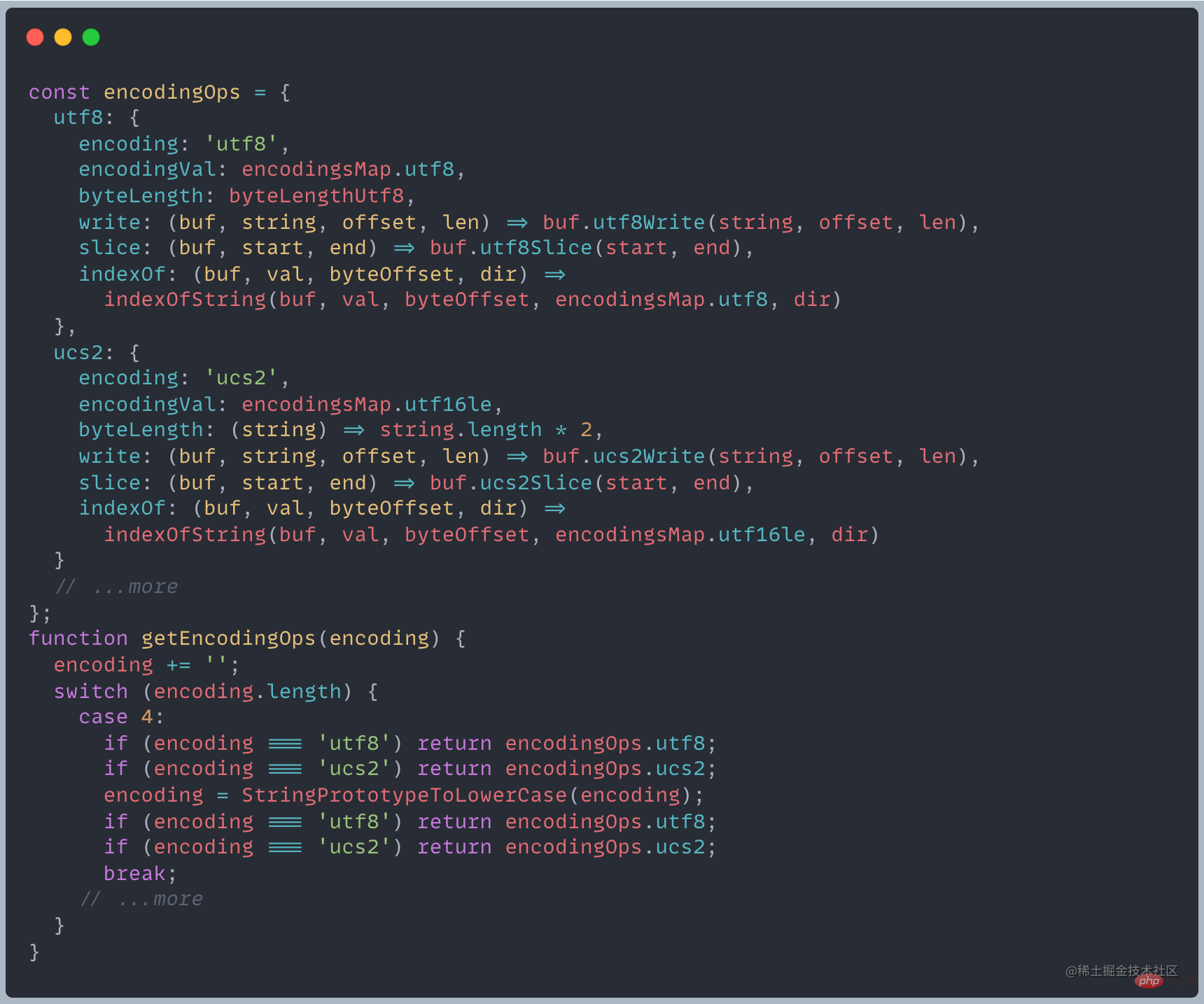
Une série d'API sera implémentée pour chaque schéma d'encodage différent. différents résultats renvoyés. Node.js renverra différents objets en fonction de l'encodage entrant
Principalement via la méthode Buffer.from mentionnée ci-dessus, l'encodage par défaut La méthode est utf-8
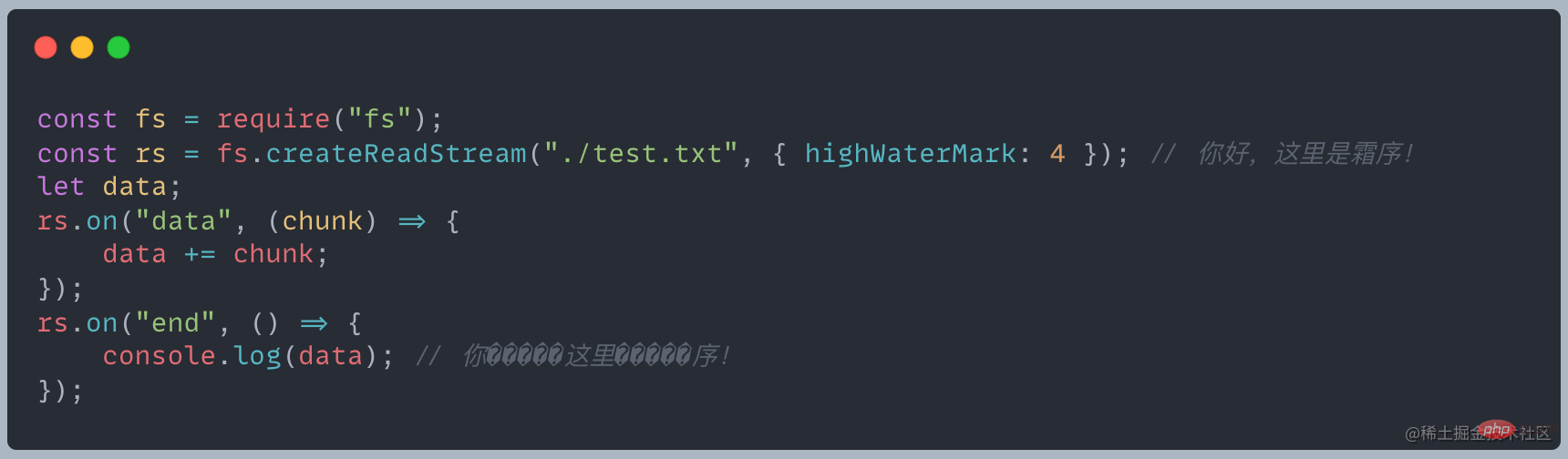
Pourquoi y a-t-il des caractères tronqués ? Comment résoudre ce problème ?
En termes de lecture, la longueur de chaque lecture est de 4 et la sortie du bloc est la suivante

Pourdata += chunk等价于data = data.toString + chunk.toString
Puisqu'un caractère chinois occupe trois octets, le quatrième du premier bloc Les octets s'afficheront des caractères tronqués, et les premier et deuxième octets du deuxième morceau ne peuvent pas former de texte, etc., donc des caractères tronqués apparaîtront. Pour plus de connaissances sur les nœuds, veuillez visiter :
tutoriel NodejsCe qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!



















![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



