
 Périphériques technologiques
IA
Méthode de défense par porte dérobée de formation segmentée par porte dérobée : DBD
Périphériques technologiques
IA
Méthode de défense par porte dérobée de formation segmentée par porte dérobée : DBD
Méthode de défense par porte dérobée de formation segmentée par porte dérobée : DBD

Le groupe de recherche du professeur Wu Baoyuan de l'Université chinoise de Hong Kong (Shenzhen) et le groupe de recherche du professeur Qin Zhan de l'Université du Zhejiang ont publié conjointement un article dans le domaine de la défense par porte dérobée, qui a été accepté avec succès par ICLR2022.
Ces dernières années, le problème des portes dérobées a fait l'objet d'une large attention. Alors que les attaques par porte dérobée continuent d’être proposées, il devient de plus en plus difficile de proposer des méthodes de défense contre les attaques générales par porte dérobée. Cet article propose une méthode de défense par porte dérobée basée sur un processus de formation segmenté par porte dérobée.
Cet article révèle que l'attaque par porte dérobée est une méthode de formation supervisée de bout en bout qui projette la porte dérobée dans l'espace des fonctionnalités. Sur cette base, cet article divise le processus de formation pour éviter les attaques par porte dérobée. Des expériences comparatives ont été menées entre cette méthode et d’autres méthodes de défense par porte dérobée pour prouver l’efficacité de cette méthode.
Conférence Inclusion : ICLR2022
Lien de l'article :https://arxiv.org/pdf/2202.03423.pdf
Lien du code : https://github.com/SCLBD /DBD
1 Introduction au contexte
Le but de l'attaque par porte dérobée est de modifier les données de formation Ou contrôlez le processus de formation et d'autres méthodes pour que le modèle prévoie des échantillons propres corrects, mais les échantillons avec des portes dérobées sont jugés comme des étiquettes cibles. Par exemple, un attaquant par porte dérobée ajoute un bloc blanc à position fixe à une image (c'est-à-dire une image empoisonnée) et remplace l'étiquette de l'image par l'étiquette cible. Après avoir entraîné le modèle avec ces données empoisonnées, le modèle déterminera que l'image avec un bloc blanc spécifique est l'étiquette cible (comme le montre la figure ci-dessous).
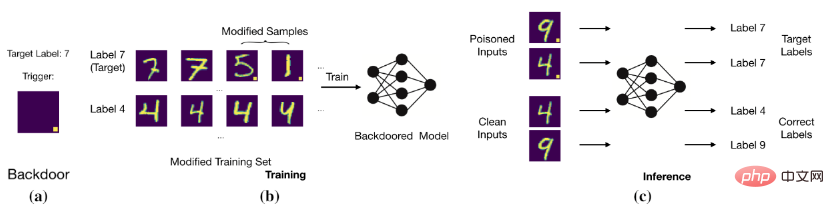 Attaque de porte dérobée de base
Attaque de porte dérobée de base
Établissement du modèle relation entre le déclencheur et l’étiquette cible.
2 Travail connexe
2.1 Attaque de porte dérobée
Les méthodes d'attaque par porte dérobée existantes sont réparties dans les deux catégories suivantes en fonction de la modification de l'étiquette de l'image empoisonnée : Poison-Label Backdoor Attack qui modifie l'étiquette de l'image empoisonnée (Poison-Label Backdoor Attack), et clean label attaque qui conserve l'étiquette originale de l'image empoisonnée (Clean-Label Backdoor Attack).
1. Attaque par étiquette d'empoisonnement : BadNets (Gu et al., 2019) est la première et la plus représentative de l'attaque par étiquette d'empoisonnement. Plus tard (Chen et al., 2017) ont proposé que l’invisibilité des images empoisonnées soit similaire à celle de leurs versions bénignes, et sur cette base, une attaque mixte a été proposée. Récemment, (Xue et al., 2020 ; Li et al., 2020 ; 2021) ont exploré plus en détail comment mener des attaques par porte dérobée par étiquette d'empoisonnement de manière plus secrète. Récemment, une attaque plus furtive et plus efficace, WaNet (Nguyen & Tran, 2021), a été proposée. WaNet utilise la distorsion de l'image comme déclencheur de porte dérobée, qui préserve le contenu de l'image tout en le déformant.
2. Attaque de balises propres : pour résoudre le problème selon lequel les utilisateurs peuvent remarquer des attaques de porte dérobée en vérifiant les relations image-tag, Turner et al. (2019) ont proposé une attaque de balises propres. paradigme où l’étiquette cible est cohérente avec l’étiquette originale de l’échantillon empoisonné. Cette idée a été étendue à la classification des vidéos d'attaque dans (Zhao et al., 2020b), qui a adopté une perturbation adverse générale de la cible (Moosavi-Dezfooli et al., 2017) comme déclencheur. Bien que les attaques par porte dérobée par balise propre soient plus subtiles que les attaques par porte dérobée par balise empoisonnée, leurs performances sont généralement relativement médiocres et peuvent même ne pas créer la porte dérobée (Li et al., 2020c).
2.2 Défense par porte dérobée
La plupart des défenses par porte dérobée existantes sont empiriques et peuvent être divisées en cinq grandes catégories Classes, y compris
1. La défense basée sur la détection (Xu et al, 2021 ; Zeng et al, 2011 ; Xiang et al, 2022) vérifie les modèles ou échantillons suspects. Qu'il soit attaqué ou non, il refusera l'utilisation d'objets malveillants.
2. La défense basée sur le prétraitement (Doan et al, 2020 ; Li et al, 2021 ; Zeng et al, 2021) vise à détruire les échantillons d'attaque contenus dans Trigger mode, qui empêche l’activation de la porte dérobée en introduisant un module de prétraitement avant d’introduire l’image dans le modèle.
3. La défense basée sur la reconstruction du modèle (Zhao et al, 2020a ; Li et al, 2021 ;) consiste à éliminer les portes dérobées cachées dans le modèle en modifiant directement le modèle .
4. Déclencher une défense globale (Guo et al, 2020 ; Dong et al, 2021 ; Shen et al, 2021) consiste d'abord à apprendre la porte dérobée et, d'autre part, à éliminer la porte dérobée cachée en supprimant son impact.
5. La défense basée sur la suppression des empoisonnements (Du et al, 2020 ; Borgnia et al, 2021) réduit l'efficacité des échantillons empoisonnés pendant le processus de formation pour empêcher la génération de portes dérobées cachées
2.3 Apprentissage semi-supervisé et Apprentissage auto-supervisé
1. Apprentissage semi-supervisé : Dans de nombreuses applications du monde réel, l'acquisition de données étiquetées repose souvent sur un étiquetage manuel, ce qui est très coûteux. En comparaison, il est beaucoup plus facile d’obtenir des échantillons non étiquetés. Afin d’exploiter la puissance des échantillons non étiquetés et étiquetés, un grand nombre de méthodes d’apprentissage semi-supervisé ont été proposées (Gao et al., 2017 ; Berthelot et al, 2019 ; Van Engelen & Hoos, 2020). Récemment, l'apprentissage semi-supervisé a également été utilisé pour améliorer la sécurité des modèles (Stanforth et al, 2019 ; Carmon et al, 2019), qui utilisent des échantillons non étiquetés dans la formation contradictoire. Récemment, (Yan et al, 2021) ont discuté de la manière de détourner l'apprentissage semi-supervisé. Cependant, en plus de modifier les échantillons d'entraînement, cette méthode doit également contrôler d'autres composants d'entraînement (tels que la perte d'entraînement).
2. Apprentissage auto-supervisé : le paradigme de l'apprentissage auto-supervisé est un sous-ensemble de l'apprentissage non supervisé, et le modèle est formé à l'aide de signaux générés par les données elles-mêmes (Chen et al, 2020a ; Grill et al, 2020 ; Liu et al, 2021 ). Il est utilisé pour augmenter la robustesse des adversaires (Hendrycks et al, 2019 ; Wu et al, 2021 ; Shi et al, 2021). Récemment, plusieurs articles (Saha et al, 2021 ; Carlini & Terzis, 2021 ; Jia et al, 2021) explorent comment mettre en place des portes dérobées dans l'apprentissage auto-supervisé. Cependant, en plus de modifier les échantillons d'entraînement, ces attaques nécessitent également de contrôler d'autres composants d'entraînement (par exemple, la perte d'entraînement).
3 Fonctionnalités de porte dérobée
Nous avons mené des BadNets et des attaques clean label sur l'ensemble de données CIFAR-10 (Krizhevsky, 2009). Apprentissage supervisé sur des ensembles de données toxiques et apprentissage auto-supervisé SimCLR sur des ensembles de données non étiquetés (Chen et al., 2020a).
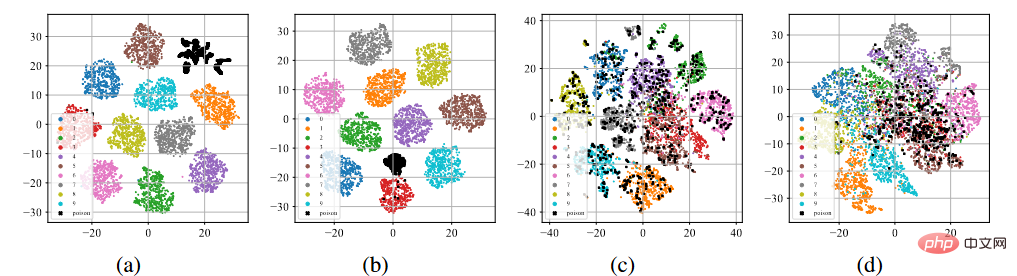
Affichage T-sne des fonctionnalités de la porte dérobée
Comme le montre la figure (a) - (b) ci-dessus, après le processus de formation supervisé standard, peu importe l'attaque de l'étiquette d'empoisonnement ou le attaque en étiquette propre Ci-dessous, les échantillons empoisonnés (indiqués par des points noirs) ont tous tendance à se regrouper pour former des groupes séparés. Ce phénomène laisse entrevoir le succès des attaques de porte dérobée existantes basées sur l’empoisonnement. Le surapprentissage permet au modèle d'apprendre les caractéristiques des déclencheurs de porte dérobée. Combiné à un paradigme de formation supervisée de bout en bout, le modèle peut réduire la distance entre les échantillons empoisonnés dans l'espace des fonctionnalités et connecter les fonctionnalités liées aux déclencheurs apprises aux étiquettes cibles. Au contraire, comme le montrent les figures (c) à (d) ci-dessus, sur l'ensemble de données d'empoisonnement non étiqueté, après le processus de formation auto-supervisé, les échantillons empoisonnés sont très proches des échantillons portant les étiquettes d'origine. Cela montre que nous pouvons éviter les portes dérobées grâce à l’apprentissage auto-supervisé.
4 Défense de porte dérobée basée sur la segmentation
Sur la base de l'analyse des caractéristiques de la porte dérobée, nous proposons une défense de porte dérobée dans la phase d'entraînement à la segmentation. Comme le montre la figure ci-dessous, il se compose de trois étapes principales : (1) l'apprentissage d'un extracteur de caractéristiques purifié grâce à un apprentissage auto-supervisé, (2) le filtrage d'échantillons de haute confiance grâce à l'apprentissage du bruit d'étiquette et (3) un apprentissage semi-supervisé fin. réglage.
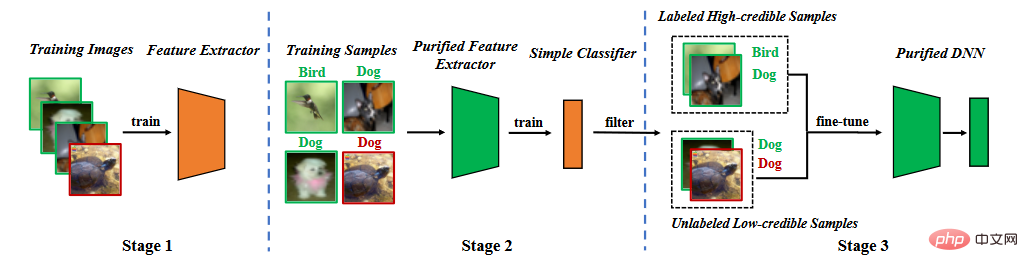 Organigramme de la méthode
Organigramme de la méthode
4.1 Extracteur de fonctionnalités d'apprentissage
Nous utilisons l'ensemble de données d'entraînement pour apprendre le modèle. Les paramètres du modèle comprennent deux parties, l'une correspond aux paramètres du modèle de base et l'autre correspond aux paramètres de la couche entièrement connectée. Nous utilisons l'apprentissage auto-supervisé pour optimiser les paramètres du modèle de base.
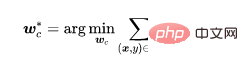
où est la perte auto-supervisée (par exemple, NT-Xent dans SimCLR (Chen et al, 2020)). Grâce à l'analyse précédente, nous pouvons savoir qu'il est difficile pour l'extracteur de fonctionnalités d'apprendre. fonctionnalités de porte dérobée.
4.2 Apprentissage du bruit d'étiquette pour filtrer les échantillons
Une fois l'extracteur de caractéristiques entraîné, nous fixons les paramètres de l'extracteur de caractéristiques et utilisons l'ensemble de données d'entraînement pour apprendre davantage les paramètres de couche entièrement connectés,
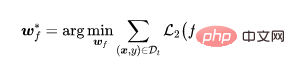
où se trouve la perte d’apprentissage supervisée (par exemple, perte d’entropie croisée).
Bien que ce processus de segmentation rende difficile l'apprentissage des portes dérobées par le modèle, il présente deux problèmes. Premièrement, par rapport aux méthodes entraînées par apprentissage supervisé, puisque l’extracteur de caractéristiques apprises est gelé dans la deuxième étape, il y aura une certaine diminution de la précision de la prédiction des échantillons propres. Deuxièmement, lorsque des attaques d'étiquettes empoisonnées se produisent, les échantillons empoisonnés serviront de « valeurs aberrantes », entravant encore davantage la deuxième étape de l'apprentissage. Ces deux problèmes indiquent que nous devons supprimer les échantillons empoisonnés et recycler ou affiner l'ensemble du modèle.
Nous devons déterminer si l'échantillon a une porte dérobée. Nous pensons qu'il est difficile pour le modèle d'apprendre à partir d'échantillons détournés, c'est pourquoi nous utilisons la confiance comme indicateur de distinction. Les échantillons à haut niveau de confiance sont des échantillons propres, tandis que les échantillons à faible niveau de confiance sont des échantillons empoisonnés. Grâce à des expériences, il a été constaté que le modèle formé à l'aide d'une perte d'entropie croisée symétrique présente un écart de perte important entre les deux échantillons, de sorte que le degré de discrimination est élevé, comme le montre la figure ci-dessous.
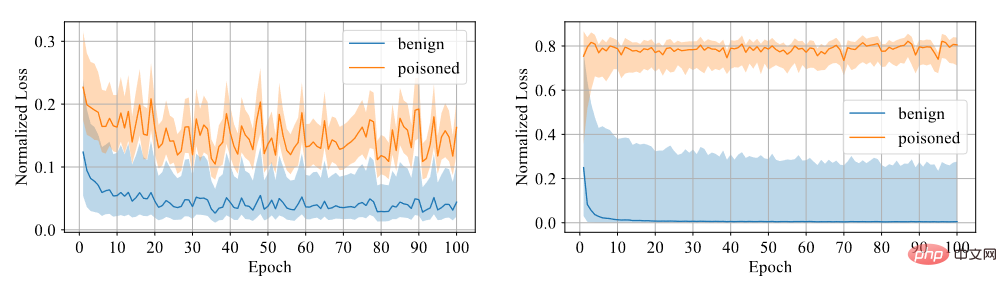
Comparaison entre la perte d'entropie croisée symétrique et la perte d'entropie croisée
Par conséquent, nous avons corrigé l'extracteur de caractéristiques pour entraîner la couche entièrement connectée en utilisant une perte d'entropie croisée symétrique, et avons filtré l'ensemble de données pour qu'il soit élevé par la taille du niveau de confiance Données de confiance et données de faible confiance.
4.3 Ajustement fin semi-supervisé
Tout d'abord, nous supprimons les étiquettes des données de faible confiance. Nous utilisons l'apprentissage semi-supervisé pour affiner l'ensemble du modèle.

où est la perte semi-supervisée (par exemple, la fonction de perte dans MixMatch (Berthelot et al, 2019)).
Le réglage fin semi-supervisé peut non seulement empêcher le modèle d'apprendre les déclencheurs de porte dérobée, mais également permettre au modèle de bien fonctionner sur des ensembles de données propres.
5 (un sous-ensemble). L'article utilise le modèle ResNet18 (He et al., 2016). L'article étudie toutes les méthodes de défense pour se défendre contre quatre attaques typiques, à savoir les badnets (Gu et al., 2019), les attaques par porte dérobée à stratégie mixte (blended) (Chen et al., 2016). . al, 2017), WaNet (Nguyen & Tran, 2021) et des attaques cohérentes avec des perturbations adverses (Turner et al, 2019).
Image d'exemple d'attaque de porte dérobée
5.2 Résultats expérimentaux
 Les critères de jugement de l'expérience sont l'exactitude du jugement de BA étant un échantillon propre et l'exactitude du jugement de l'ASR étant un échantillon empoisonné .
Les critères de jugement de l'expérience sont l'exactitude du jugement de BA étant un échantillon propre et l'exactitude du jugement de l'ASR étant un échantillon empoisonné .
Résultats de comparaison de la défense par porte dérobée
Comme le montre le tableau ci-dessus, DBD est nettement meilleur que les défenses ayant les mêmes exigences (c'est-à-dire DPSGD et ShrinkPad) pour se défendre contre toutes les attaques. Dans tous les cas, DBD surpasse DPSGD de 20 % en plus de BA et de 5 % en moins d'ASR. L'ASR du modèle DBD est inférieur à 2 % dans tous les cas (moins de 0,5 % dans la plupart des cas), ce qui confirme que DBD peut empêcher avec succès la création de portes dérobées cachées. DBD est comparé à deux autres méthodes, à savoir NC et NAD, qui nécessitent toutes deux que le défenseur dispose d'un ensemble de données locales propres.
Comme le montre le tableau ci-dessus, NC et NAD surpassent DPSGD et ShrinkPad car ils utilisent des informations supplémentaires provenant d'ensembles de données locaux propres. En particulier, bien que NAD et NC utilisent des informations supplémentaires, DBD est meilleur qu'eux. En particulier sur l'ensemble de données ImageNet, la CN a un effet limité sur la réduction de l'ASR. En comparaison, DBD atteint le plus petit ASR, tandis que le BA de DBD est le plus élevé ou le deuxième plus élevé dans presque tous les cas. De plus, par rapport au modèle sans aucune formation de défense, le BA a chuté de moins de 2 % lors de la défense contre les attaques par empoisonnement. Sur des ensembles de données relativement plus volumineux, DBD est encore meilleur, car toutes les méthodes de base deviennent moins efficaces. Ces résultats vérifient l’efficacité du DBD.
5.3 Expériences d'ablation
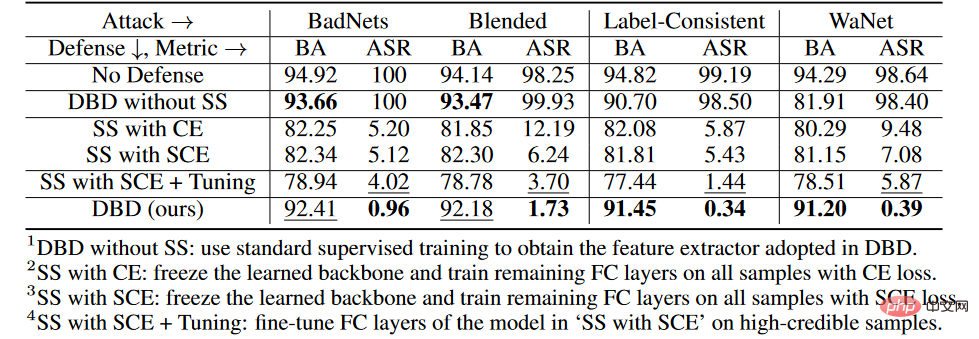
Expériences d'ablation à différentes étapes
Sur l'ensemble de données CIFAR-10, nous avons comparé le DBD proposé et ses quatre variantes, dont
1. SS , remplace la colonne vertébrale générée par l'apprentissage auto-supervisé par la colonne vertébrale formée de manière supervisée et maintient les autres parties inchangées
2, gèle la colonne vertébrale apprise grâce à l'apprentissage auto-supervisé et la perte d'entropie croisée de. les couches restantes entièrement connectées sont entraînées sur tous les échantillons d'entraînement
3.SS avec SCE, similaire à la deuxième variante, mais entraînées en utilisant une perte d'entropie croisée symétrique.
4.SS avec SCE + Tuning, affinant davantage la couche entièrement connectée sur des échantillons de haute confiance filtrés par la troisième variante.
Comme le montre le tableau ci-dessus, le découplage du processus de formation supervisé d'origine de bout en bout est efficace pour empêcher la création de portes dérobées cachées. En outre, les deuxième et troisième variantes de DBD sont comparées pour vérifier l’efficacité de la perte de SCE dans la défense contre les attaques de porte dérobée par poison tag. De plus, l'ASR et le BA de la quatrième mutation DBD sont inférieurs à ceux de la troisième mutation DBD. Ce phénomène est dû à la suppression des échantillons de faible confiance. Cela suggère qu’il est important pour la défense de recueillir des informations utiles à partir d’échantillons peu fiables tout en réduisant leurs effets secondaires.
5.4 Résistance aux attaques adaptatives potentielles
Si les attaquants connaissent l'existence du DBD, ils peuvent concevoir des attaques adaptatives. Si l'attaquant peut connaître la structure du modèle utilisé par le défenseur, il peut concevoir une attaque adaptative en optimisant le modèle de déclenchement afin que l'échantillon empoisonné reste dans un nouveau cluster après un apprentissage auto-supervisé, comme indiqué ci-dessous :
Paramètres d'attaque
Pour un problème de classification, représentons les échantillons propres qui doivent être empoisonnés, représentons les échantillons avec l'étiquette d'origine et soyons une colonne vertébrale entraînée. Compte tenu du générateur d'images empoisonnées prédéterminé par un attaquant, l'attaque adaptative vise à optimiser le modèle de déclenchement en minimisant la distance entre les images empoisonnées tout en maximisant la distance entre le centre de l'image empoisonnée et le centre du groupe d'images bénignes avec des étiquettes différentes. c'est-à-dire.
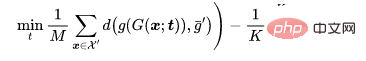
où 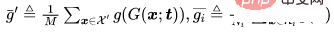 est une détermination à distance.
est une détermination à distance.
Résultats expérimentaux
Le BA de l'attaque adaptative sans défense est de 94,96% et l'ASR est de 99,70%. Cependant, les résultats de défense de DBD étaient de BA93,21 % et ASR1,02 %. En d’autres termes, DBD résiste à de telles attaques adaptatives.
6 Résumé
Le mécanisme de l'attaque par porte dérobée basée sur l'empoisonnement consiste à établir une connexion potentielle entre le modèle de déclenchement et l'étiquette cible pendant le processus de formation. Cet article révèle que cette connexion est principalement due à l’apprentissage du paradigme de formation supervisée de bout en bout. Partant de cette compréhension, cet article propose une méthode de défense par porte dérobée basée sur le découplage. Un grand nombre d’expériences ont vérifié que la défense DBD peut réduire les menaces de porte dérobée tout en maintenant une grande précision dans la prédiction des échantillons bénins.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Open source! Au-delà de ZoeDepth ! DepthFM : estimation rapide et précise de la profondeur monoculaire !
Apr 03, 2024 pm 12:04 PM
Open source! Au-delà de ZoeDepth ! DepthFM : estimation rapide et précise de la profondeur monoculaire !
Apr 03, 2024 pm 12:04 PM
0. À quoi sert cet article ? Nous proposons DepthFM : un modèle d'estimation de profondeur monoculaire génératif de pointe, polyvalent et rapide. En plus des tâches traditionnelles d'estimation de la profondeur, DepthFM démontre également des capacités de pointe dans les tâches en aval telles que l'inpainting en profondeur. DepthFM est efficace et peut synthétiser des cartes de profondeur en quelques étapes d'inférence. Lisons ce travail ensemble ~ 1. Titre des informations sur l'article : DepthFM : FastMonocularDepthEstimationwithFlowMatching Auteur : MingGui, JohannesS.Fischer, UlrichPrestel, PingchuanMa, Dmytr
 Bonjour, Atlas électrique ! Le robot Boston Dynamics revient à la vie, des mouvements étranges à 180 degrés effraient Musk
Apr 18, 2024 pm 07:58 PM
Bonjour, Atlas électrique ! Le robot Boston Dynamics revient à la vie, des mouvements étranges à 180 degrés effraient Musk
Apr 18, 2024 pm 07:58 PM
Boston Dynamics Atlas entre officiellement dans l’ère des robots électriques ! Hier, l'Atlas hydraulique s'est retiré "en larmes" de la scène de l'histoire. Aujourd'hui, Boston Dynamics a annoncé que l'Atlas électrique était au travail. Il semble que dans le domaine des robots humanoïdes commerciaux, Boston Dynamics soit déterminé à concurrencer Tesla. Après la sortie de la nouvelle vidéo, elle a déjà été visionnée par plus d’un million de personnes en seulement dix heures. Les personnes âgées partent et de nouveaux rôles apparaissent. C'est une nécessité historique. Il ne fait aucun doute que cette année est l’année explosive des robots humanoïdes. Les internautes ont commenté : Les progrès des robots ont fait ressembler la cérémonie d'ouverture de cette année à des êtres humains, et le degré de liberté est bien plus grand que celui des humains. Mais n'est-ce vraiment pas un film d'horreur ? Au début de la vidéo, Atlas est allongé calmement sur le sol, apparemment sur le dos. Ce qui suit est à couper le souffle
 La version Kuaishou de Sora 'Ke Ling' est ouverte aux tests : génère plus de 120 s de vidéo, comprend mieux la physique et peut modéliser avec précision des mouvements complexes
Jun 11, 2024 am 09:51 AM
La version Kuaishou de Sora 'Ke Ling' est ouverte aux tests : génère plus de 120 s de vidéo, comprend mieux la physique et peut modéliser avec précision des mouvements complexes
Jun 11, 2024 am 09:51 AM
Quoi? Zootopie est-elle concrétisée par l’IA domestique ? Avec la vidéo est exposé un nouveau modèle de génération vidéo domestique à grande échelle appelé « Keling ». Sora utilise une voie technique similaire et combine un certain nombre d'innovations technologiques auto-développées pour produire des vidéos qui comportent non seulement des mouvements larges et raisonnables, mais qui simulent également les caractéristiques du monde physique et possèdent de fortes capacités de combinaison conceptuelle et d'imagination. Selon les données, Keling prend en charge la génération de vidéos ultra-longues allant jusqu'à 2 minutes à 30 ips, avec des résolutions allant jusqu'à 1080p, et prend en charge plusieurs formats d'image. Un autre point important est que Keling n'est pas une démo ou une démonstration de résultats vidéo publiée par le laboratoire, mais une application au niveau produit lancée par Kuaishou, un acteur leader dans le domaine de la vidéo courte. De plus, l'objectif principal est d'être pragmatique, de ne pas faire de chèques en blanc et de se mettre en ligne dès sa sortie. Le grand modèle de Ke Ling est déjà sorti à Kuaiying.
 La vitalité de la super intelligence s'éveille ! Mais avec l'arrivée de l'IA qui se met à jour automatiquement, les mères n'ont plus à se soucier des goulots d'étranglement des données.
Apr 29, 2024 pm 06:55 PM
La vitalité de la super intelligence s'éveille ! Mais avec l'arrivée de l'IA qui se met à jour automatiquement, les mères n'ont plus à se soucier des goulots d'étranglement des données.
Apr 29, 2024 pm 06:55 PM
Je pleure à mort. Le monde construit à la folie de grands modèles. Les données sur Internet ne suffisent pas du tout. Le modèle de formation ressemble à « The Hunger Games », et les chercheurs en IA du monde entier se demandent comment nourrir ces personnes avides de données. Ce problème est particulièrement important dans les tâches multimodales. À une époque où rien ne pouvait être fait, une équipe de start-up du département de l'Université Renmin de Chine a utilisé son propre nouveau modèle pour devenir la première en Chine à faire de « l'auto-alimentation des données générées par le modèle » une réalité. De plus, il s’agit d’une approche à deux volets, du côté compréhension et du côté génération, les deux côtés peuvent générer de nouvelles données multimodales de haute qualité et fournir un retour de données au modèle lui-même. Qu'est-ce qu'un modèle ? Awaker 1.0, un grand modèle multimodal qui vient d'apparaître sur le Forum Zhongguancun. Qui est l'équipe ? Moteur Sophon. Fondé par Gao Yizhao, doctorant à la Hillhouse School of Artificial Intelligence de l’Université Renmin.
 L'US Air Force présente son premier avion de combat IA de grande envergure ! Le ministre a personnellement effectué l'essai routier sans intervenir pendant tout le processus, et 100 000 lignes de code ont été testées 21 fois.
May 07, 2024 pm 05:00 PM
L'US Air Force présente son premier avion de combat IA de grande envergure ! Le ministre a personnellement effectué l'essai routier sans intervenir pendant tout le processus, et 100 000 lignes de code ont été testées 21 fois.
May 07, 2024 pm 05:00 PM
Récemment, le milieu militaire a été submergé par la nouvelle : les avions de combat militaires américains peuvent désormais mener des combats aériens entièrement automatiques grâce à l'IA. Oui, tout récemment, l’avion de combat IA de l’armée américaine a été rendu public pour la première fois, dévoilant ainsi son mystère. Le nom complet de ce chasseur est Variable Stability Simulator Test Aircraft (VISTA). Il a été personnellement piloté par le secrétaire de l'US Air Force pour simuler une bataille aérienne en tête-à-tête. Le 2 mai, le secrétaire de l'US Air Force, Frank Kendall, a décollé à bord d'un X-62AVISTA à la base aérienne d'Edwards. Notez que pendant le vol d'une heure, toutes les actions de vol ont été effectuées de manière autonome par l'IA ! Kendall a déclaré : "Au cours des dernières décennies, nous avons réfléchi au potentiel illimité du combat air-air autonome, mais cela a toujours semblé hors de portée." Mais maintenant,
 Pour seulement 250$, le directeur technique de Hugging Face vous apprend étape par étape comment peaufiner Llama 3
May 06, 2024 pm 03:52 PM
Pour seulement 250$, le directeur technique de Hugging Face vous apprend étape par étape comment peaufiner Llama 3
May 06, 2024 pm 03:52 PM
Les grands modèles de langage open source familiers tels que Llama3 lancé par Meta, les modèles Mistral et Mixtral lancés par MistralAI et Jamba lancé par AI21 Lab sont devenus des concurrents d'OpenAI. Dans la plupart des cas, les utilisateurs doivent affiner ces modèles open source en fonction de leurs propres données pour libérer pleinement le potentiel du modèle. Il n'est pas difficile d'affiner un grand modèle de langage (comme Mistral) par rapport à un petit en utilisant Q-Learning sur un seul GPU, mais le réglage efficace d'un grand modèle comme Llama370b ou Mixtral est resté un défi jusqu'à présent. . C'est pourquoi Philipp Sch, directeur technique de HuggingFace
 Surpassant largement le DPO : l'équipe de Chen Danqi a proposé une optimisation simple des préférences SimPO et a également affiné le modèle open source 8B le plus puissant.
Jun 01, 2024 pm 04:41 PM
Surpassant largement le DPO : l'équipe de Chen Danqi a proposé une optimisation simple des préférences SimPO et a également affiné le modèle open source 8B le plus puissant.
Jun 01, 2024 pm 04:41 PM
Afin d'aligner les grands modèles de langage (LLM) sur les valeurs et les intentions humaines, il est essentiel d'apprendre les commentaires humains pour garantir qu'ils sont utiles, honnêtes et inoffensifs. En termes d'alignement du LLM, une méthode efficace est l'apprentissage par renforcement basé sur le retour humain (RLHF). Bien que les résultats de la méthode RLHF soient excellents, certains défis d’optimisation sont impliqués. Cela implique de former un modèle de récompense, puis d'optimiser un modèle politique pour maximiser cette récompense. Récemment, certains chercheurs ont exploré des algorithmes hors ligne plus simples, dont l’optimisation directe des préférences (DPO). DPO apprend le modèle politique directement sur la base des données de préférence en paramétrant la fonction de récompense dans RLHF, éliminant ainsi le besoin d'un modèle de récompense explicite. Cette méthode est simple et stable
 Le modèle évoluera après fusion, et gagnera directement SOTA ! Les nouvelles réalisations entrepreneuriales de l'auteur de Transformer sont populaires
Mar 26, 2024 am 11:30 AM
Le modèle évoluera après fusion, et gagnera directement SOTA ! Les nouvelles réalisations entrepreneuriales de l'auteur de Transformer sont populaires
Mar 26, 2024 am 11:30 AM
Utilisez les modèles prêts à l'emploi sur Huggingface pour « économiser » : pouvez-vous les combiner directement pour créer de nouveaux modèles puissants ? ! La grande société de mannequins japonaise sakana.ai a été très créative (c'était la société fondée par l'un des « 8 Transformers ») et a trouvé une manière très intelligente d'évoluer et de fusionner des modèles. Non seulement la méthode génère automatiquement de nouveaux modèles de base, mais les performances sont tout sauf : ils ont obtenu des résultats de pointe sur des benchmarks pertinents en utilisant un grand modèle de mathématiques japonaises avec 7 milliards de paramètres, dépassant les 70 milliards de paramètres Llama- 2 et autres modèles précédents. Plus important encore, la dérivation d’un tel modèle ne nécessite aucune formation en gradient et nécessite donc beaucoup moins de ressources informatiques. Le scientifique NVIDIA JimFan l'a félicité après l'avoir lu
