
 Périphériques technologiques
IA
Explorez la technologie des grands modèles dans l'ère post-GPT 3.0 et avancez vers la réalisation de l'avenir de l'AGI.
Périphériques technologiques
IA
Explorez la technologie des grands modèles dans l'ère post-GPT 3.0 et avancez vers la réalisation de l'avenir de l'AGI.
Explorez la technologie des grands modèles dans l'ère post-GPT 3.0 et avancez vers la réalisation de l'avenir de l'AGI.

ChatGPT a surpris ou réveillé de nombreuses personnes après son apparition. La surprise vient du fait que je ne m'attendais pas à ce que le grand modèle de langage (LLM) puisse être aussi efficace ; le réveil a été la prise de conscience soudaine que notre compréhension et nos concepts de développement du LLM sont loin des idées les plus avancées au monde. J'appartiens au groupe qui a été à la fois surpris et éveillé, et je suis aussi un Chinois typique. Les Chinois sont doués pour l'auto-réflexion, alors ils ont commencé à réfléchir, et cet article est le résultat de cette réflexion.
Pour être honnête, en termes de technologie liée aux modèles LLM en Chine, à l'heure actuelle, l'écart entre celle-ci et la technologie la plus avancée s'est encore creusé. Je pense que la question du leadership technologique ou du fossé technologique doit être considérée de manière dynamique dans une perspective de développement. En fait, un à deux ans après l'émergence de Bert, le rattrapage technologique national dans ce domaine était encore très rapide, et de bons modèles d'amélioration ont également été proposés. Le tournant décisif pour creuser l'écart devrait se situer après la sortie de GPT 3.0. , c'est-à-dire en 2020 Vers le milieu de l'année. À l’époque, seules quelques personnes savaient que GPT 3.0 n’était pas seulement une technologie spécifique, mais incarnait en réalité un concept de développement indiquant la direction que devait prendre le LLM. Depuis lors, l’écart s’est de plus en plus creusé, et ChatGPT n’est qu’une conséquence naturelle de cette différence de philosophies de développement. Par conséquent, je pense personnellement que mettons de côté la question de savoir si vous avez les ressources financières nécessaires pour construire un très grand LLM. D'un seul point de vue technique, l'écart vient principalement de la compréhension différente du LLM et des différents concepts de développement quant à l'endroit où aller. allez dans le futur .
La Chine prend de plus en plus de retard sur la technologie étrangère. C’est un fait, et il est normal de ne pas l’admettre. Il y a quelque temps, de nombreux internautes s'inquiétaient du fait que l'IA nationale se trouve désormais dans une « phase critique de survie ». Je ne pense pas que ce soit si grave. Ne voyez-vous pas, OpenAI est-elle la seule entreprise au monde avec une vision aussi avant-gardiste ? En fait, y compris Google, leur compréhension des concepts de développement LLM est évidemment derrière OpenAI. La réalité est qu’OpenAI a trop bien performé et a laissé tout le monde derrière, pas seulement au niveau national.
Je pense qu'OpenAI est en avance d'environ six mois à un an sur Google et DeepMind à l'étranger en termes de concepts et de technologies associées pour le LLM, et d'environ deux ans sur la Chine. En ce qui concerne le LLM, je pense que l'échelon est très clair. Ceux qui reflètent le mieux la vision technique de Google sont PaLM et Pathways. Ils ont été lancés entre février et avril 2022. Au cours de la même période, OpenAI. a été lancé. Il s'agit d'InstructGPT. De là, vous pouvez voir l'écart entre Google et OpenAI. Quant à la raison pour laquelle je dis cela, vous pouvez probablement le comprendre après avoir lu le texte derrière moi. L'objectif précédent de DeepMind était de renforcer l'apprentissage de la conquête des jeux et de l'IA pour la science. Il est en fait entré très tard dans le LLM. Il n'aurait dû commencer à s'intéresser à cette direction que dans 21 ans, et il rattrape actuellement son retard. Sans parler de Meta, l'accent n'a pas été mis sur le LLM, et maintenant on a l'impression qu'il essaie de rattraper son retard. Il s’agit toujours d’un groupe d’institutions qui s’en sortent le mieux à l’heure actuelle. Si tel est le cas, sans parler des institutions nationales ? Je me sens excusable. Quant à la philosophie d’OpenAI sur le LLM, je parlerai de ma compréhension dans la dernière partie de cet article.
Cet article résume la technologie LLM dominante depuis l'émergence de GPT 3.0 Pour les technologies grand public avant cela, vous pouvez vous référer à "PTM chevauchant le vent et les vagues, interprétation approfondie des progrès de. modèles de pré-formation".
Je pense qu'après avoir lu ces deux articles, vous aurez une compréhension plus claire du contexte technique du domaine LLM, des différents concepts de développement qui ont émergé dans le développement de la technologie LLM, et même des possibles tendances de développement futures. Bien entendu, le contenu mentionné à de nombreux endroits est mon opinion personnelle et est hautement subjectif. Les erreurs et omissions sont inévitables, veuillez donc vous y référer avec prudence.
Cet article tente de répondre à certaines des questions suivantes : ChatGPT a-t-il provoqué un changement de paradigme de recherche dans le domaine de la PNL et même de l'IA ? Si oui, quel impact cela aura-t-il ? Qu’apprend LLM à partir d’énormes quantités de données ? Comment LLM accède-t-il à ces connaissances ? À mesure que l’échelle du LLM augmente progressivement, quel sera l’impact ? Qu’est-ce que l’apprentissage en contexte ? Pourquoi est-ce une technologie mystérieuse ? Quelle est sa relation avec Instruct ? LLM a-t-il des capacités de raisonnement ? Comment fonctionne le CoT de la Chaîne de Pensée ? Attendez, je pense que vous aurez une réponse à ces questions après l'avoir lu.
Tout d'abord, avant de parler de l'état actuel de la technologie LLM, permettez-moi de parler du changement de paradigme de recherche dans mon esprit à un niveau macro. De cette façon, nous pouvons « voir la forêt avant les arbres » et mieux comprendre pourquoi certaines technologies ont tant évolué.
Top de la tendance : La transformation du paradigme de recherche en PNL
Si nous étendons la chronologie plus longtemps, revenons à l'ère de l'apprentissage profond dans le domaine de la PNL et observons les changements technologiques et leur impact sur une fenêtre de temps plus longue, cela peut-être qu'il est plus facile de voir certains des nœuds clés. Je crois personnellement qu’au cours du développement technologique dans le domaine de la PNL au cours des 10 dernières années, deux changements majeurs de paradigme de recherche ont pu se produire.
Paradigm Shift 1.0 : De l'apprentissage profond au modèle de pré-formation en deux étapes
La période couverte par ce changement de paradigme va approximativement de l'introduction de l'apprentissage profond dans le domaine de la PNL (vers 2013 ) vers GPT 3.0 Avant sa sortie (vers mai 2020) .
Avant l'émergence des modèles Bert et GPT, la technologie populaire dans le domaine de la PNL était le modèle d'apprentissage profond, et l'apprentissage profond dans le domaine de la PNL reposait principalement sur les technologies clés suivantes : un grand nombre de modèles LSTM améliorés et un petite quantité de modèles CNN améliorés En tant qu'extracteur de fonctionnalités typique ; utilisez Séquence à Séquence (ou encodeur-décodeur) + Attention comme cadre technique global typique pour diverses tâches spécifiques.
Avec le soutien de ces technologies de base, le principal objectif de recherche de l'apprentissage profond dans le domaine de la PNL, s'il est résumé, est de savoir comment augmenter efficacement la profondeur de la couche de modèle ou la capacité des paramètres du modèle. C'est-à-dire, comment pouvons-nous ajouter continuellement des couches LSTM ou CNN plus profondes à l'encodeur et au décodeur pour atteindre l'objectif d'augmenter la profondeur des couches et la capacité du modèle. Bien que ce type d'effort ait effectivement augmenté continuellement la profondeur du modèle, il n'est globalement pas très efficace du point de vue de l'effet de la résolution de tâches spécifiques. En d'autres termes, par rapport aux méthodes d'apprentissage non approfondies, les avantages qu'il apporte ne sont pas nombreux. super.
La raison pour laquelle l'apprentissage profond n'est pas assez efficace, je pense, est principalement due à deux aspects : d'une part, la quantité totale de données d'entraînement pour une tâche spécifique est limitée. À mesure que la capacité du modèle augmente, il doit être pris en charge par une plus grande quantité de données d'entraînement. Sinon, même si vous pouvez augmenter la profondeur, l'effet de la tâche ne sera pas obtenu. Avant l'émergence des modèles de pré-formation, il était évident qu'il s'agissait d'un problème sérieux dans le domaine de la recherche en PNL ; un autre aspect était que l'extracteur de fonctionnalités LSTM/CNN n'avait pas de fortes capacités d'expression ; Cela signifie que quelle que soit la quantité de données qui vous sont fournies, elles sont inutiles car vous ne pouvez pas absorber efficacement les connaissances contenues dans les données. Ce sont principalement ces deux raisons qui entravent la percée réussie du deep learning dans le domaine de la PNL.
L'émergence de ces deux modèles de pré-formation, Bert/GPT, représente un saut technologique dans le domaine de la PNL, tant du point de vue de la recherche académique que de l'application industrielle, et a entraîné une transformation du paradigme de recherche en tout le champ. L'impact de ce changement de paradigme se reflète sous deux aspects : premièrement, le déclin, voire la disparition progressive de certains sous-domaines de recherche en PNL, deuxièmement, les méthodes techniques et les cadres techniques des différents sous-domaines de la PNL sont de plus en plus unifiés un an après l'émergence de la PNL. Bert À cette époque, la pile technologique a essentiellement convergé vers deux modèles technologiques. Parlons de ces deux points séparément.
Impact 1 : La disparition des tâches intermédiaires
La PNL est un nom collectif pour un domaine de recherche macro, qui comporte une variété de sous-domaines et de sous-directions spécifiques s'il est analysé attentivement, du point de vue. Selon la nature de la tâche, celles-ci peuvent être divisées en deux catégories : l'une peut être appelée « tâches intermédiaires » et l'autre peut être appelée « tâches finales ».
Les tâches intermédiaires typiques incluent : la segmentation des mots chinois, le marquage d'une partie du discours, le NER, l'analyse syntaxique, la résolution de référence, l'analyseur sémantique, etc. Ces types de tâches ne résolvent généralement pas les besoins réels de l'application, et la plupart d'entre eux sont utilisés pour résoudre les besoins réels. Il y a une étape intermédiaire ou une étape auxiliaire de la tâche, par exemple, il n'est presque pas nécessaire de dire : je veux qu'un analyseur syntaxique montre à l'utilisateur l'arbre d'analyse syntaxique de cette phrase. L'utilisateur n'a pas besoin de voir les résultats du traitement de ces étapes intermédiaires de la PNL. Il s'en soucie seulement. Avez-vous bien accompli une tâche spécifique ? Les « tâches finales » incluent la classification de texte, le calcul de similarité de texte, la traduction automatique, le résumé de texte, etc., il y en a beaucoup. La caractéristique de ce type de tâche est que chaque sous-domaine répond à un certain besoin réel et que les résultats de la tâche peuvent être présentés directement à l'utilisateur. Par exemple, l'utilisateur a vraiment besoin de vous donner une phrase en anglais et de lui dire quoi. Le chinois l'est.
Logiquement parlant, les « tâches intermédiaires » ne devraient pas apparaître, et la raison pour laquelle elles existent est le reflet du niveau de développement insuffisant de la technologie PNL. Au début du développement technologique, la technologie étant relativement arriérée, il était difficile d’accomplir des tâches finales difficiles en une seule étape. Prenons l'exemple de la traduction automatique. Aux débuts de la technologie, il était très difficile de faire du bon travail en traduction automatique. C'est pourquoi les chercheurs ont divisé et résolu les problèmes difficiles et les ont décomposés en diverses étapes intermédiaires telles que la segmentation des mots, en partie. -le marquage vocal et l'analyse syntaxique. Ils ont d'abord bien complété chaque étape intermédiaire, puis nous ne pouvons rien faire pour travailler ensemble pour mener à bien la mission finale.
Mais depuis l'émergence de Bert/GPT, il n'est en fait plus nécessaire d'effectuer ces tâches intermédiaires, car grâce à un pré-entraînement avec une grande quantité de données, Bert/GPT a absorbé ces tâches intermédiaires en tant que caractéristiques linguistiques dans les paramètres de Transformer. À ce stade, nous pouvons résoudre directement ces tâches finales de bout en bout sans avoir à modéliser spécifiquement ce processus intermédiaire. La chose la plus controversée ici est peut-être la segmentation des mots chinois. En fait, le principe est le même. Vous n'avez pas à vous soucier des mots qui doivent former un mot. Laissez simplement LLM l'apprendre en tant que fonctionnalité. pour résoudre la tâche, il l'apprendra naturellement.La méthode raisonnable de segmentation des mots de cette étude n'est pas nécessairement la même que les règles de segmentation des mots que nous, les humains, comprenons.
Sur la base de la compréhension ci-dessus, en fait, dès l'apparition de Bert/GPT, vous devriez conclure que ce type de tâches de la phase intermédiaire de la PNL se retirera progressivement de la scène de l'histoire.
Impact 2 : Unification des voies techniques dans différentes directions de recherche
Avant d'expliquer l'impact spécifique, nous discutons d'abord d'une autre façon de diviser les tâches de la PNL, qui est utile pour comprendre le contenu suivant. Si la « tâche finale » est classée plus en détail, elle peut être grossièrement divisée en deux types de tâches différents : les tâches de compréhension du langage naturel et les tâches de génération du langage naturel. Si les « tâches intermédiaires » sont exclues, les tâches typiques de compréhension du langage naturel comprennent la classification de texte, le jugement de relation de phrase, le jugement de tendance émotionnelle, etc. Ces tâches sont essentiellement des tâches de classification, c'est-à-dire saisir une phrase (article) ou deux Une phrase, le modèle fait référence à tout le contenu d'entrée et donne enfin un jugement sur la catégorie à laquelle il appartient. La génération de langage naturel comprend également de nombreuses sous-directions de recherche en PNL, telles que les robots de discussion, la traduction automatique, la synthèse de texte, les systèmes de questions et réponses, etc. La caractéristique de la tâche de génération est qu'étant donné le texte d'entrée, le modèle doit générer une chaîne de texte de sortie en conséquence. La différence entre les deux se reflète principalement dans les formulaires d'entrée et de sortie
Depuis la naissance du modèle Bert/GPT, il y a eu une tendance évidente à l'unification technique. Tout d'abord, les extracteurs de fonctionnalités des différents sous-champs du NLP sont progressivement unifiés de LSTM/CNN à Transformer. En fait, peu de temps après que Bert ait été rendu public, nous aurions dû réaliser que cela deviendrait inévitablement une tendance technologique. Quant à la raison, elle a été expliquée et analysée dans cet article que j'ai écrit il y a quelques années "Zhang Junlin : Abandonnez les illusions et adoptez pleinement Transformer : Comparaison de trois extracteurs de fonctionnalités majeurs (CNN/RNN/TF) pour le traitement du langage naturel". Les étudiants intéressés peuvent s'y référer.
Lien de l'article : https://zhuanlan.zhihu.com/p/54743941
De plus, Transformer unifie non seulement de nombreux domaines de la PNL, mais remplace également progressivement les tâches de traitement d'image largement utilisées dans divers De même, dans le processus d'utilisation de CNN et d'autres modèles, les modèles multimodaux utilisent actuellement essentiellement le modèle Transformer. Ce type de Transformer part de la PNL et unifie progressivement la tendance de plus en plus de domaines de l'IA. Cela a commencé avec le Vision Transformer (ViT) apparu fin 2020. Il a prospéré depuis et a connu un grand succès jusqu'à présent. , et il continue de s'étendre dans davantage de domaines. La dynamique d'expansion deviendra de plus en plus rapide.
Deuxièmement, le modèle de recherche et développement dans la plupart des sous-domaines de la PNL est passé à un modèle en deux étapes : étape de pré-formation du modèle + réglage fin de l'application (Fine-tuning) ou mode d'invite Zero/Few Shot de l'application. Pour être plus précis, diverses tâches de PNL ont en fait convergé vers deux cadres de modèles de pré-formation différents : pour les tâches de compréhension du langage naturel, le système technique a été unifié dans le "modèle de langage bidirectionnel pré-formation + réglage fin de l'application" représenté par Bert. » ; pour les tâches de génération de langage naturel, le système technique est unifié selon le mode « modèle de langage autorégressif (c'est-à-dire, modèle de langage unidirectionnel de gauche à droite) + Zero /Few Shot Prompt » représenté par GPT 2.0. Quant à savoir pourquoi il est divisé en deux itinéraires techniques, c'est inévitable. Nous l'expliquerons plus tard.
Ces deux modèles peuvent sembler similaires, mais ils contiennent des idées de développement très différentes et mèneront à des orientations de développement futures différentes. Malheureusement, la plupart d’entre nous ont sous-estimé le potentiel du GPT en tant que voie de développement à cette époque et ont concentré notre vision sur des modèles comme Bert.
Paradigm Shift 2.0 : Des modèles pré-entraînés à l'intelligence générale artificielle (AGI, Artificial General Intelligence)
La plage de temps couverte par ce changement de paradigme se situe à peu près après l'émergence de GPT3.0 ( 20 ans environ juin), jusqu'à présent, nous devrions être en plein milieu de ce changement de paradigme .
ChatGPT est le nœud clé qui déclenche ce changement de paradigme, mais avant l'émergence d'InstructGPT, LLM était en fait dans une période de transition avant ce changement de paradigme.
Période de transition : Le modèle « modèle de langage autorégressif + Prompting » représenté par GPT 3.0 occupe une position dominante
Comme mentionné précédemment, dans les premiers jours du développement des modèles de pré-formation, le cadre technique a convergé vers le modèle Bert et le modèle GPT Ces deux paradigmes techniques différents, et les gens sont généralement plus optimistes quant au modèle Bert. De nombreuses améliorations techniques ultérieures se trouvent sur le chemin de Bert. Cependant, à mesure que la technologie continue de se développer, vous constaterez que les modèles LLM actuellement les plus importants sont presque tous basés sur le modèle « langage autorégressif + invite » similaire à GPT 3.0, comme GPT 3, PaLM, GLaM, Gopher, Chinchilla, MT. -NLG, LaMDA, etc., aucune exception. Pourquoi cela se produit-il ? Il doit y avoir une certaine fatalité derrière cela, et je pense que cela peut être principalement dû à deux raisons.
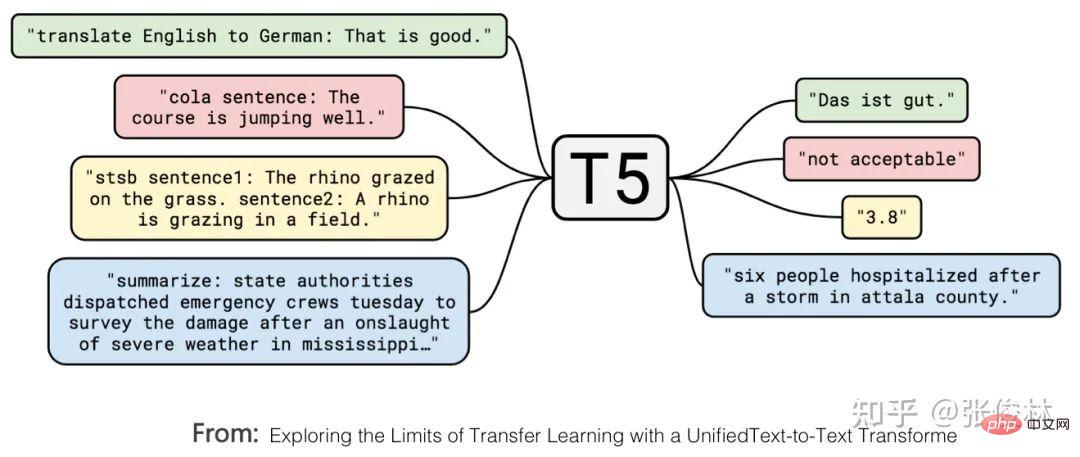
Tout d'abord, Le modèle T5 de Google unifie formellement les expressions externes des tâches de compréhension du langage naturel et de génération du langage naturel. Comme le montre la figure ci-dessus, ce qui est marqué en rouge est un problème de classification de texte, et ce qui est marqué en jaune est un problème de régression ou de classification qui détermine la similitude des phrases. Ce sont deux problèmes typiques de compréhension du langage naturel. Dans le modèle T5, ces problèmes de compréhension du langage naturel sont cohérents avec les problèmes de génération sous forme d'entrée et de sortie. En d'autres termes, le problème de classification peut être converti en modèle LLM pour générer des chaînes de catégories correspondantes, de sorte que la compréhension et la sortie soient cohérentes. les tâches de génération sont exprimées sous la forme L'unité complète est atteinte.
Cela montre que la tâche de génération du langage naturel peut être compatible avec la tâche de compréhension du langage naturel en termes d'expression. Si c'est l'inverse, il sera difficile d'y parvenir. L’avantage est que le même modèle de génération LLM peut résoudre presque tous les problèmes de PNL. Si le mode Bert est toujours adopté, ce modèle LLM ne peut pas bien gérer la tâche de génération. Cela étant, il y a une raison pour laquelle nous avons certainement tendance à utiliser des modèles génératifs.
La deuxième raison, Si vous voulez faire du bon travail avec une invite de tir zéro ou quelques invites de tir, vous devez adopter le mode GPT. Il y a eu des études (Référence : Sur le rôle de la bidirectionnalité dans la pré-formation du modèle de langage) qui ont prouvé que si les tâches en aval sont résolues avec un réglage fin, le mode Bert est meilleur que le mode GPT si l'invite zéro tir/quelques tirs est utilisée ; , ceci Si ce mode résout les tâches en aval, l'effet du mode GPT est meilleur que le mode Bert. Cela montre qu'il est plus facile pour le modèle généré d'effectuer des tâches en mode d'invite zéro tir/quelques tirs, et le mode Bert présente des inconvénients naturels pour effectuer des tâches de cette manière. C'est la deuxième raison.
Mais voici la question : pourquoi cherchons-nous à inciter à zéro tir/quelques tirs pour effectuer des tâches ? Pour expliquer clairement ce problème, nous devons d’abord clarifier une autre question : quel type de modèle LLM est le plus idéal pour nous ?
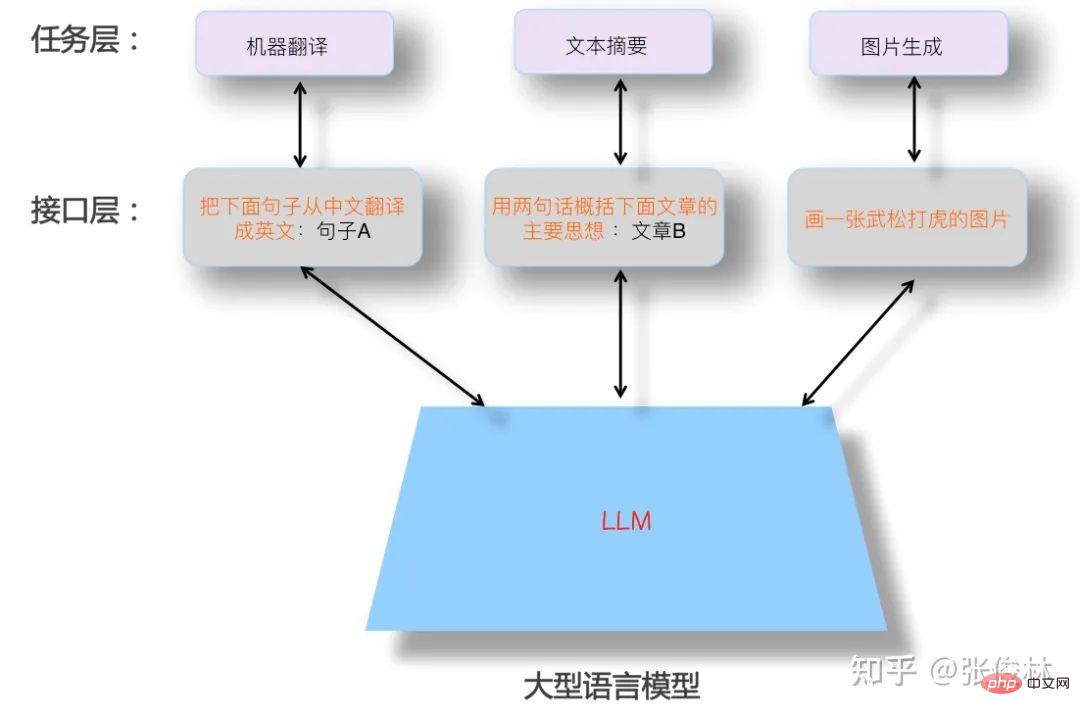
L'image ci-dessus montre à quoi devrait ressembler un LLM idéal. Premièrement, le LLM doit avoir de fortes capacités d’apprentissage autonome. Supposons que nous lui fournissions tous les différents types de données, comme du texte ou des images, disponibles dans le monde, il devrait être capable d'apprendre automatiquement tous les points de connaissance qu'il contient. Le processus d'apprentissage ne nécessite pas d'intervention humaine, et il devrait pouvoir le faire. appliquer avec flexibilité les connaissances acquises pour résoudre des problèmes pratiques. Parce que les données sont massives, pour absorber toutes les connaissances, de nombreux paramètres de modèle sont nécessaires pour stocker les connaissances, ce modèle sera donc inévitablement un modèle géant.
Deuxièmement, LLM devrait être capable de résoudre des problèmes dans n'importe quel sous-domaine de la PNL, et pas seulement de prendre en charge des domaines limités. Il devrait même répondre aux problèmes dans d'autres domaines en dehors de la PNL. Il est préférable que les problèmes dans n'importe quel domaine puissent être résolus. eh bien. Répondez .
De plus, lorsque nous utilisons LLM pour résoudre des problèmes dans un domaine spécifique, nous devons utiliser les expressions auxquelles nous sommes habitués en tant qu'humains, c'est-à-dire que LLM doit comprendre les commandes humaines. Cela reflète le fait de laisser les LLM s'adapter aux gens, plutôt que l'inverse, de laisser les gens s'adapter au modèle LLM. Des exemples typiques de personnes qui s'adaptent au LLM se creusent la tête pour essayer diverses invites dans le but de trouver les bonnes invites qui peuvent mieux résoudre le problème en question. Concernant ce point, la figure ci-dessus donne quelques exemples au niveau de la couche d'interface où les humains interagissent avec LLM pour illustrer ce qu'est une bonne forme d'interface permettant aux utilisateurs d'utiliser le modèle LLM.
Après avoir lu ce LLM idéal, revenons en arrière et expliquons les questions restantes ci-dessus : Pourquoi devrions-nous poursuivre l'incitation à zéro tir/quelques tirs pour accomplir des tâches ? Il y a deux raisons.
Premièrement, l'échelle de ce modèle LLM doit être très énorme, et il doit y avoir très peu d'institutions capables de réaliser ce modèle ou de modifier les paramètres de ce modèle. Les demandeurs de tâches sont des milliers de petites et moyennes organisations ou même des particuliers. Même si vous ouvrez le modèle en open source, ils ne pourront pas déployer le modèle, et encore moins utiliser le mode de réglage fin pour modifier les paramètres du modèle. Par conséquent, nous devrions rechercher un moyen de permettre au demandeur de tâche de terminer la tâche sans modifier les paramètres du modèle, c'est-à-dire que le mode invite devrait être utilisé pour terminer la tâche au lieu du mode de réglage fin (on peut voir que la direction technique du soft inciter va à l’encontre de cette tendance de développement). Le modéliste transforme LLM en service public et l'exécute en mode LLM as Service. En tant que partisan du service, compte tenu des besoins en constante évolution des utilisateurs, les producteurs de modèles LLM doivent poursuivre l'objectif de permettre à LLM d'effectuer autant de types de tâches que possible. C'est un effet secondaire, et c'est aussi un facteur réaliste pour lequel c'est super. les grands modèles poursuivront certainement l'AGI.
Deuxièmement, qu'il s'agisse d'une invite de tir zéro, d'une invite de tir peu ou même d'une invite de chaîne de pensée (CoT, Chain of Thought) qui favorise la capacité de raisonnement LLM, c'est la couche d'interface existante dans l'image ci-dessus Technologie . Plus précisément, l'intention initiale de l'invite de tir zéro est en fait l'interface idéale entre les humains et LLM. Elle utilise directement la méthode d'expression de tâches à laquelle les humains sont habitués pour laisser LLM faire les choses. Cependant, il a été constaté que LLM ne pouvait pas bien la comprendre et. l'effet n'était pas bon. Après des recherches continues, nous avons découvert que pour une certaine tâche, si nous donnons quelques exemples à LLM et utilisons ces exemples pour représenter la description de la tâche, l'effet sera meilleur que l'invite de tir zéro, de sorte que tout le monde étudie mieux la technologie d'incitation à quelques tirs. On peut comprendre que nous espérions à l'origine que LLM pourrait effectuer une certaine tâche en utilisant des commandes couramment utilisées par les humains, mais la technologie actuelle n'est pas en mesure de le faire, nous avons donc opté pour la meilleure solution et avons utilisé ces technologies alternatives pour exprimer la tâche humaine. exigences.
Si vous comprenez la logique ci-dessus, il est facile de tirer la conclusion suivante : l'incitation à quelques tirs (également connue sous le nom d'apprentissage en contexte) n'est qu'une technologie de transition. Si nous pouvons décrire une tâche plus naturellement et que LLM peut la comprendre, alors nous abandonnerons définitivement ces technologies de transition sans hésitation. La raison est évidente : utiliser ces méthodes pour décrire les exigences d'une tâche n'est pas conforme aux habitudes humaines.
C'est aussi la raison pour laquelle j'ai répertorié GPT 3.0+Prompting comme technologie de transition. L'émergence de ChatGPT a changé ce statu quo et a remplacé Prompting par Instruct, ce qui a entraîné un nouveau changement de paradigme technologique et produit plusieurs suivis. ups.
Impact 1 : Adapter le LLM à une nouvelle interface interactive pour les gens
Dans le cadre d'un LLM idéal, regardons ChatGPT pour mieux comprendre son apport technique. ChatGPT devrait être la méthode technique la plus proche du LLM idéal parmi toutes les technologies existantes. Si je résume les fonctionnalités les plus importantes de ChatGPT, j'utiliserais les huit mots suivants : "Puissant, prévenant ".
"Puissant" Ceci, je crois, devrait être principalement attribué au LLM GPT3.5, la fondation sur laquelle repose ChatGPT. Bien que ChatGPT ait ajouté des données annotées manuellement, ce n'est que par dizaines de milliers. Par rapport aux centaines de milliards de données au niveau des jetons utilisées pour entraîner le modèle GPT 3.5, cette quantité de données contient moins de connaissances mondiales (faits contenus dans les données). ) et le bon sens) peut être décrit comme une goutte d'eau dans l'océan, presque négligeable, et ne jouera fondamentalement aucun rôle dans l'amélioration des capacités de base de GPT 3.5. Par conséquent, ses puissantes fonctions devraient provenir principalement du GPT 3.5 caché derrière lui. GPT 3.5 compare le modèle géant parmi les modèles LLM idéaux.
Alors, ChatGPT injecte-t-il de nouvelles connaissances dans le modèle GPT 3.5 ? Il faut l’injecter. Cette connaissance est contenue dans des dizaines de milliers de données étiquetées manuellement, mais ce qui est injecté n’est pas la connaissance du monde, mais la connaissance des préférences humaines. La « préférence humaine » a plusieurs significations : premièrement, il s’agit d’une manière habituelle pour les humains d’exprimer une tâche. Par exemple, les gens ont l'habitude de dire : « Traduisez la phrase suivante du chinois vers l'anglais » pour exprimer un besoin de « traduction automatique ». Cependant, LLM n'est pas un humain, alors comment peut-il comprendre ce que signifie cette phrase ? Vous devez trouver un moyen de faire comprendre à LLM la signification de cette commande et de l'exécuter correctement. Par conséquent, ChatGPT injecte ce type de connaissances dans GPT 3.5 via l'annotation manuelle des données, ce qui permet à LLM de comprendre plus facilement les commandes humaines. C'est la clé de son « empathie ». Deuxièmement, les humains ont leurs propres normes quant à ce qui constitue une bonne réponse et ce qui est une mauvaise réponse. Par exemple, une réponse plus détaillée est bonne, une réponse au contenu discriminatoire est mauvaise, et ainsi de suite. C'est la préférence humaine pour la qualité des réponses. Les données que les gens renvoient à LLM via le modèle de récompense contiennent ce type d'informations. Dans l'ensemble, ChatGPT injecte des connaissances sur les préférences humaines dans GPT 3.5 pour obtenir un LLM qui comprend la parole humaine et est plus poli.
On peut voir que la plus grande contribution de ChatGPT est qu'il réalise essentiellement la couche d'interface du LLM idéal, permettant à LLM de s'adapter aux expressions de commande habituelles des gens, plutôt que l'inverse. Laissez les gens s'adapter au LLM et se creuser la tête pour trouver une commande qui peut fonctionner (c'est ce que faisait la technologie d'invite avant la sortie de la technologie d'instruction), et cela augmente la facilité d'utilisation et l'expérience utilisateur de. LLM. C'est InstructGPT/ChatGPT qui a été le premier à comprendre ce problème et à fournir une bonne solution, qui constitue également sa plus grande contribution technique. Par rapport aux invites de tir précédentes, il s'agit d'une technologie d'interface homme-machine qui est plus conforme aux habitudes d'expression humaine permettant aux gens d'interagir avec LLM.
Cela inspirera certainement les modèles LLM ultérieurs et continuera à travailler davantage sur des interfaces homme-machine faciles à utiliser pour rendre le LLM plus obéissant.
Impact 2 : De nombreux sous-domaines de la PNL n'ont plus de valeur de recherche indépendante
# 🎜 🎜#En ce qui concerne le domaine de la PNL, ce changement de paradigme signifie que de nombreux domaines de recherche en PNL qui existent actuellement de manière indépendante seront inclus dans le système technologique LLM, n'existeront plus de manière indépendante et disparaîtront progressivement. . Après le premier changement de paradigme, bien que de nombreuses « tâches intermédiaires » en PNL ne soient plus nécessaires pour continuer à exister en tant que domaines de recherche indépendants, la plupart des « tâches finales » existent toujours en tant que domaines de recherche indépendants, mais sont transférées vers la « pré-formation ». . + mise au point », face aux problématiques uniques du domaine, de nouveaux plans d'amélioration ont été proposés les uns après les autres.
Les recherches actuelles montrent que pour de nombreuses tâches PNL, à mesure que la taille du modèle LLM augmente, les performances seront grandement améliorées. Sur cette base, je pense que l'on peut tirer la conclusion suivante : la plupart des problèmes dits "uniques" dans un certain domaine ne sont probablement qu'une apparence externe causée par un manque de connaissances dans le domaine, à condition qu'il y ait suffisamment de connaissances dans le domaine. , ce soi-disant problème propre au domaine sera résolu. Il peut être très bien résolu. En fait, il n'est pas nécessaire de se concentrer sur un problème de terrain spécifique et de travailler dur pour trouver une solution spéciale. Peut-être que la vérité à propos de l'AGI est étonnamment simple : vous donnez simplement plus de données à LLM sur le terrain et vous le laissez apprendre davantage par lui-même.
Dans ce contexte, en même temps, ChatGPT prouve que nous pouvons désormais poursuivre directement le modèle LLM idéal. Ensuite, la future tendance de développement technologique devrait être : poursuivre des modèles LLM de plus en plus grands en augmentant le nombre de données de pré-formation. pour couvrir de plus en plus de domaines, LLM apprend de manière autonome les connaissances du domaine à partir des données du domaine grâce au processus de pré-formation. À mesure que la taille du modèle continue d'augmenter, de nombreux problèmes sont résolus. La recherche se concentrera sur la manière de construire ce modèle LLM idéal, plutôt que sur la résolution de problèmes spécifiques dans un domaine particulier. De cette manière, de plus en plus de sous-domaines de la PNL seront inclus dans le système technique LLM et disparaîtront progressivement.
Je pense que pour juger si la recherche indépendante dans un domaine spécifique doit être arrêtée immédiatement, la norme de jugement peut être l'une des deux méthodes suivantes : premièrement, juger si l'effet de la recherche du LLM sur une certaine tâche dépasse celui des humains Performance, pour les domaines de recherche où l'effet du LLM dépasse celui des humains, il n'est pas nécessaire de mener une recherche indépendante. Par exemple, pour de nombreuses tâches des ensembles de tests GLUE et SuperGLUE, l'effet LLM dépasse actuellement les performances humaines. En fait, il n'est pas nécessaire que les domaines de recherche étroitement liés à cet ensemble de données continuent d'exister de manière indépendante. Deuxièmement, comparez les effets des tâches de deux modes. Le premier mode est le réglage fin avec des données spécifiques à un domaine plus volumineuses, et le deuxième mode est constitué d'invites à quelques tirs ou de méthodes basées sur des instructions. Si l’effet de la deuxième méthode atteint ou dépasse celui de la première méthode, cela signifie qu’il n’est pas nécessaire que ce champ continue d’exister de manière indépendante. Si nous utilisons cette norme, en fait, dans de nombreux domaines de recherche, l'effet de réglage fin est toujours dominant (en raison de la grande quantité de données d'entraînement dans ce domaine de mode), et il semble qu'il puisse exister indépendamment. Cependant, étant donné que pour de nombreuses tâches, à mesure que la taille du modèle augmente, l'effet de quelques tirs continue de croître avec l'émergence de modèles plus grands, ce point d'inflexion est susceptible d'être atteint à court terme.
Si la spéculation ci-dessus est vraie, cela signifiera le fait cruel suivant : pour de nombreux chercheurs dans le domaine de la PNL, ils seront confrontés au choix de savoir où aller s'ils continuent à travailler sur des problèmes propres à ce domaine. ? Ou devrions-nous abandonner cette approche apparemment peu prometteuse et plutôt construire un meilleur LLM ? Si nous choisissons de nous tourner vers la construction de LLM, quelles institutions ont la capacité et les conditions pour le faire ? Quelle serait votre réponse à cette question ?
Impact 3 : Davantage de domaines de recherche autres que la PNL seront inclus dans le système technologique LLM
Si vous vous situez du point de vue de l'AGI et vous référez au modèle LLM idéal décrit précédemment, les tâches qu'il peut accomplir ne devrait pas être limité au domaine de la PNL, ou à un ou deux domaines. Le LLM idéal devrait être un modèle d'intelligence artificielle générale indépendant du domaine. Il fonctionne bien dans un ou deux domaines, mais cela ne signifie pas qu'il peut le faire. faites seulement ces tâches. L'émergence de ChatGPT prouve qu'il est possible pour nous de poursuivre l'AGI au cours de cette période, et qu'il est maintenant temps de mettre de côté les chaînes de la réflexion sur la « discipline de terrain ».
ChatGPT démontre non seulement la capacité à résoudre diverses tâches de PNL dans un format conversationnel fluide, mais possède également de solides capacités de codage. Il est naturel que de plus en plus d'autres domaines de recherche soient progressivement inclus dans le dispositif LLM et fassent partie de l'intelligence artificielle générale.
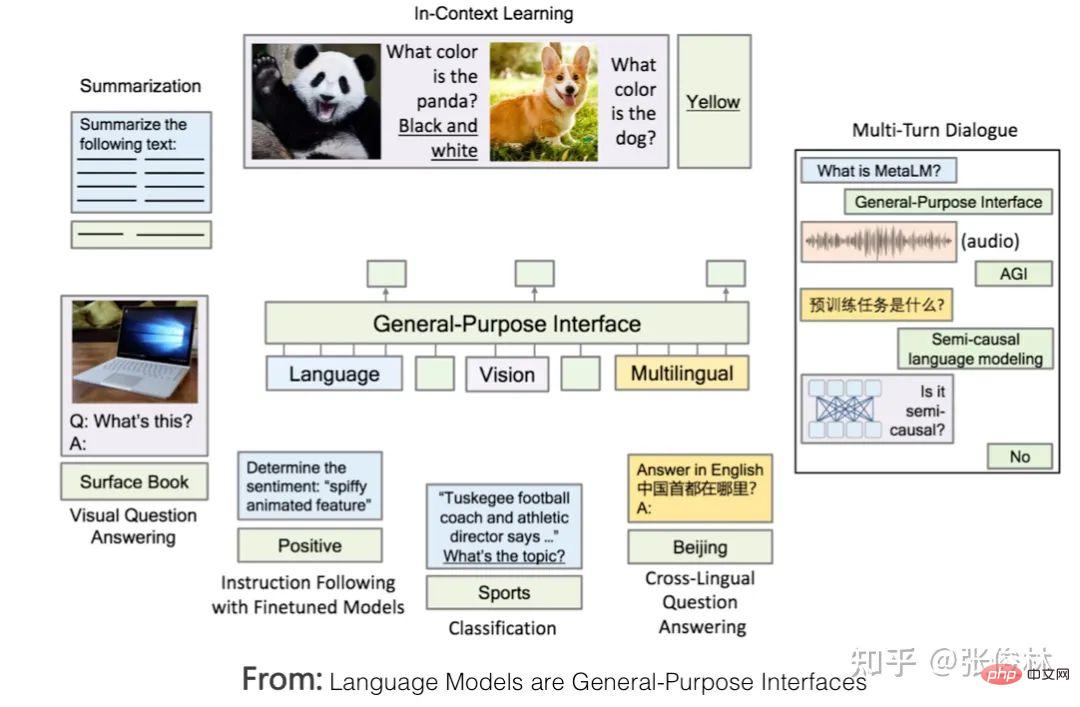
LLM étend son domaine de la PNL vers l'extérieur, et un choix naturel se porte sur le traitement d'images et les tâches associées multimodales. Il y a déjà des efforts pour intégrer la multimodalité et faire de LLM une interface homme-machine universelle qui prend en charge les entrées et sorties multimodales. Des exemples typiques incluent Flamingo de DeepMind et les « modèles de langage sont des interfaces à usage général », comme indiqué ci-dessus. L’approche est démontrée.
Mon jugement est que qu'il s'agisse d'images ou de multimodalité, la future intégration dans LLM pour devenir des fonctions utiles pourrait être plus lente qu'on ne le pense. La raison principale est que, bien que le domaine de l'image ait imité l'approche de pré-formation de Bert au cours des deux dernières années, il tente d'introduire un apprentissage auto-supervisé pour libérer la capacité du modèle à apprendre de manière indépendante des connaissances à partir de données d'image. Les technologies typiques sont « contrastées ». "apprentissage" et MAE. Il s'agit de deux voies techniques différentes. Cependant, à en juger par les résultats actuels, malgré les grands progrès technologiques, il semble que ce chemin ne soit pas encore terminé. Cela se reflète dans l'application de modèles pré-entraînés dans le domaine de l'image aux tâches en aval, ce qui apporte bien moins d'avantages que Bert. ou GPT. Il est appliqué de manière significative aux tâches PNL en aval. Par conséquent, les modèles de prétraitement d’images doivent encore être explorés en profondeur pour libérer le potentiel des données d’image, ce qui retardera leur unification dans de grands modèles LLM. Bien entendu, si cette voie est ouverte un jour, il y a une forte probabilité que la situation actuelle dans le domaine de la PNL se reproduise, c'est-à-dire que divers sous-domaines de recherche en traitement d'images pourraient progressivement disparaître et être intégrés dans des LLM à grande échelle pour effectuer directement les tâches du terminal.
En plus de l'image et de la multimodalité, il est évident que d'autres domaines seront progressivement inclus dans le LLM idéal. Cette direction est en plein essor et constitue un sujet de recherche à forte valeur ajoutée.
Ce qui précède sont mes réflexions personnelles sur le changement de paradigme. Ensuite, examinons les progrès technologiques traditionnels des modèles LLM après GPT 3.0. Comme le montre le modèle LLM idéal, les technologies associées peuvent en fait être divisées en deux catégories principales : l'une concerne la manière dont le modèle LLM absorbe les connaissances des données, et inclut également l'impact de la croissance de la taille du modèle sur la capacité du LLM à absorber les connaissances de la deuxième catégorie ; est une interface homme-machine expliquant comment les gens utilisent les capacités inhérentes de LLM pour résoudre des tâches, y compris les modes d'apprentissage en contexte et d'instruction. Les invites de chaîne de pensée (CoT), une technologie de raisonnement LLM, appartiennent essentiellement à l'apprentissage en contexte. Parce qu'elles sont plus importantes, j'en parlerai séparément. Apprenants : Des données infinies à des connaissances massives
D'après les résultats de recherche actuels, Transformer est un extracteur de fonctionnalités suffisamment puissant et ne nécessite aucune amélioration particulière. Alors, qu’a appris Transformer lors du processus de pré-formation ? Comment accède-t-on à la connaissance ? Comment corriger des connaissances erronées ? Cette section décrit les progrès de la recherche dans ce domaine.
Parcours de la connaissance : quelles connaissances LLM a-t-il apprises
LLM a appris beaucoup de connaissances à partir de textes libres massifs. Si ces connaissances sont grossièrement classées, elles peuvent être divisées enconnaissances linguistiques et connaissances du monde. Deux grandes catégories.
Les connaissances linguistiques font référence aux connaissances lexicales, aux parties du discours, à la syntaxe, à la sémantique et à d'autres connaissances qui aident les humains ou les machines à comprendre le langage naturel. Il existe une longue histoire de recherches sur la capacité du LLM à capturer les connaissances linguistiques. Depuis l'émergence de Bert, les recherches pertinentes se sont poursuivies et des conclusions ont été tirées très tôt. C'est pourquoi il est utilisé. Après la pré-entraînement du modèle, l'une des raisons les plus importantes est que diverses tâches de compréhension du langage naturel ont obtenu des améliorations significatives des performances. En outre, diverses études ont également prouvé que les connaissances linguistiques superficielles telles que la morphologie, les parties du discours, la syntaxe et d'autres connaissances sont stockées dans les structures de bas et de niveau intermédiaire de Transformer, tandis que les connaissances linguistiques abstraites telles que les connaissances sémantiques sont largement distribuées. dans les structures de niveau intermédiaire et supérieur de Transformer.
La connaissance du monde fait référence à certains événements réels qui se produisent dans ce monde (connaissance factuelle), ainsi qu'à certaines connaissances de bon sens (connaissance du bon sens). Par exemple, « Biden est l'actuel président des États-Unis », « Biden est un Américain », « Le président ukrainien Zelensky a rencontré le président américain Biden », ce sont des connaissances factuelles liées à Biden et « Les gens ont deux yeux » et « ; Le soleil se lève à l'est" relève du bon sens. Il existe de nombreuses études sur la capacité du modèle LLM à acquérir des connaissances mondiales, et les conclusions sont relativement cohérentes : LLM absorbe une grande quantité de connaissances mondiales à partir des données de formation, et ce type de connaissances est principalement distribué dans les couches moyennes et élevées de Transformateur, particulièrement concentré dans la couche intermédiaire. De plus, à mesure que la profondeur du modèle Transformer augmente, la quantité de connaissances pouvant être apprises augmente progressivement de façon exponentielle (voir : BERTnesia : Enquête sur la capture et l'oubli des connaissances dans BERT). En fait, vous considérez LLM comme un graphe de connaissances implicite reflété dans les paramètres du modèle. Si vous le comprenez de cette façon, je pense qu'il n'y a aucun problème. "Quand avez-vous besoin de milliards de mots de données de pré-formation ?" Cet article étudie la relation entre la quantité de connaissances apprises par le modèle de pré-formation et la quantité de données de formation. : pour Bert Pour un type de modèle de langage, vous pouvez apprendre des connaissances linguistiques telles que la syntaxe et la sémantique avec seulement 10 à 100 millions de mots de corpus, mais pour apprendre des connaissances factuelles, vous avez besoin de plus de données de formation. Cette conclusion est en réalité attendue. Après tout, les connaissances linguistiques sont relativement limitées et statiques, tandis que les connaissances factuelles sont énormes et en constante évolution. Les recherches actuelles ont prouvé qu'à mesure que la quantité de données de formation augmente, le modèle pré-entraîné est plus performant dans diverses tâches en aval, ce qui montre que ce que l'on apprend des données de formation incrémentielles est principalement une connaissance du monde. Lieu Mémoire : LLM Comment accéder aux connaissances Par As See More Comme le montre ce qui précède, LLM a en effet appris beaucoup de connaissances linguistiques et mondiales à partir des données. Alors, pour une connaissance précise, où LLM la stocke-t-elle ? Comment est-il extrait ? C'est aussi une question intéressante. Évidemment, les connaissances doivent être stockées dans les paramètres du modèle de Transformer. À en juger par la structure de Transformer, les paramètres du modèle sont composés de deux parties : la partie attention multi-têtes (MHA) représente environ un tiers du total des paramètres, et les deux tiers des paramètres sont concentrés dans la structure FFN. MHA est principalement utilisé pour calculer la force de corrélation entre des mots ou des connaissances et intégrer des informations globales. Il est plus susceptible d'établir le lien entre les connaissances. Il existe une forte probabilité que des points de connaissances spécifiques ne soient pas stockés, il est donc facile d'en déduire. corps de connaissances du modèle LLM. Il est stocké dans la structure FFN de Transformer. Cependant, la granularité d'un tel positionnement est encore trop grossière, et il est difficile de répondre à la manière dont une pièce spécifique de connaissances est stocké et comment Les connaissances extraites, telles que « La capitale de la Chine est Pékin », sont exprimées en triples sous la forme , où « est-capitale-de » représente la relation entre les entités. Où sont stockées ces connaissances dans LLM ? "Les couches de transmission directe du transformateur sont des mémoires à valeurs clés" donne une perspective d'observation relativement nouvelle, qui considère le FFN de Transformer comme stockant une grande quantité de connaissances spécifiques. Mémoire de valeur. Comme le montre la figure ci-dessus (le côté gauche de la figure est la figure papier originale, qui n'est en fait pas facile à comprendre, vous pouvez regarder la figure de droite annotée pour une meilleure compréhension), la première couche de FFN est une largeur MLP. la couche cachée, qui est la couche clé ; la deuxième couche est la couche cachée étroite de MLP et est la couche de valeur ; La couche d'entrée de FFN est en fait l'intégration de sortie du MHA correspondant à un certain mot, qui est l'intégration qui intègre le contexte d'entrée lié à la phrase entière via Self Attention, qui représente les informations globales de l'ensemble de la phrase d'entrée. Key enregistre une paire d'informations . Par exemple, pour le Cela peut encore paraître compliqué, alors utilisons un exemple extrême pour illustrer. Nous supposons que le nœud Et cet article a également souligné que le transformateur de bas niveau répond au modèle de surface de la phrase, et que le haut niveau répond au modèle sémantique, c'est-à-dire que le FFN de bas niveau stocke des connaissances de surface telles. comme le lexique et la syntaxe, et les couches intermédiaire et supérieure stockent des connaissances conceptuelles sémantiques et factuelles. Cela est cohérent avec d'autres conclusions de recherche. Je suppose que traiter FFN comme une mémoire clé-valeur n'est probablement pas la bonne réponse finale, mais ce n'est probablement pas trop loin de la bonne réponse finale. Fluide de Correction des Connaissances : Comment corriger les connaissances stockées en LLM #🎜 🎜 #Maintenant que nous savons qu'une connaissance spécifique du monde est stockée dans les paramètres d'un ou plusieurs nœuds FFN, une autre question se pose naturellement : Pouvons-nous corriger les erreurs ou les connaissances obsolètes stockées dans le modèle LLM ? Par exemple, concernant la question : « Qui est l'actuel Premier ministre du Royaume-Uni ? » Compte tenu des fréquents changements de Premier ministre britannique ces dernières années, pensez-vous que LLM est plus enclin à exporter « Boris » ou « Sunak » ? Évidemment, il y aura plus de données contenant « Boris » dans les données d'entraînement. Dans ce cas, il est très probable que LLM donnera une mauvaise réponse, nous devons donc corriger les connaissances obsolètes stockées dans LLM. En résumé, il existe actuellement trois méthodes différentes pour modifier les connaissances contenues en LLM : # 🎜🎜#Le premier type de méthode corrige les connaissances à partir de la source des données de formation. "Vers le traçage des connaissances factuelles dans les modèles linguistiques jusqu'aux données de formation" L'objectif de recherche de cet article est le suivant : pour un élément de connaissance spécifié, pouvons-nous localiser quelles données de formation ont amené LLM à apprendre cet élément de connaissance ? La réponse est oui, ce qui signifie que nous pouvons remonter à l’envers la source des données de formation correspondant à un certain élément de connaissance. Si nous utilisons cette technologie, en supposant que nous souhaitions supprimer un certain élément de connaissances, nous pouvons d'abord localiser sa source de données correspondante, supprimer la source de données, puis ré-entraîner l'ensemble du modèle LLM. Cela peut atteindre l'objectif de supprimer les connaissances pertinentes. dans le LLM. Mais il y a ici un problème. Si nous corrigeons une petite partie des connaissances, nous devons reformer le modèle, ce qui est évidemment trop coûteux. Par conséquent, cette méthode n'a pas beaucoup de perspectives de développement. Elle peut être plus adaptée à la suppression ponctuelle à grande échelle d'une catégorie spécifique de données. Elle peut par exemple ne pas convenir à un petit nombre de scénarios réguliers de correction des connaissances. être plus approprié pour éliminer les biais. Attendez que le contenu toxique soit supprimé. Le deuxième type de méthode consiste à faire un peaufinage sur le modèle LLM pour corriger les connaissances #🎜 🎜##🎜 🎜#. Une méthode intuitive à laquelle on peut penser est la suivante : nous pouvons construire des données de formation basées sur les nouvelles connaissances à modifier, puis laisser le modèle LLM affiner ces données de formation, guidant ainsi le LLM à mémoriser les nouvelles connaissances et à les oublier. les anciennes connaissances. Cette méthode est simple et intuitive, mais elle présente également certains problèmes. Tout d’abord, elle entraînera le problème de l’oubli en cas de catastrophe, ce qui signifie qu’en plus d’oublier les connaissances qui devraient être oubliées, elle oublie également les connaissances qui ne devraient pas l’être. être oublié, ce qui entraîne une baisse de l'efficacité de certaines tâches en aval. De plus, comme le modèle LLM actuel est très volumineux, même si des ajustements précis sont effectués fréquemment, le coût est en réalité assez élevé. Les personnes intéressées par cette méthode peuvent se référer à « Modification des mémoires dans les modèles de transformateur ». #🎜🎜 # . Supposons que nous voulions corriger les anciennes connaissances en . Tout d'abord, nous trouvons un moyen de localiser le nœud FFN qui stocke les anciennes connaissances dans les paramètres du modèle LLM, puis nous pouvons ajuster et modifier de force les paramètres du modèle correspondant dans FFN pour remplacer les anciennes connaissances par de nouvelles connaissances. On peut voir que cette méthode implique deux technologies clés : premièrement, comment localiser l'emplacement de stockage spécifique d'un certain élément de connaissance dans l'espace des paramètres LLM, deuxièmement, comment corriger les paramètres du modèle pour parvenir à la correction des anciennes connaissances en nouvelles ; connaissance. Pour plus de détails sur ce type de technologie, voir « Localisation et modification d'associations factuelles dans GPT » et « Édition en masse de la mémoire dans un transformateur ». Comprendre ce processus de révision des connaissances du LLM est en fait très utile pour une compréhension plus approfondie du mécanisme de fonctionnement interne du LLM. Nous savons qu'au cours des dernières années, l'échelle des modèles LLM a augmenté rapidement et que la plupart des modèles LLM les plus performants actuels ont des tailles de paramètres dépassant 100 milliards (100B ) paramètres. Par exemple, la taille du GPT 3 d'OpenAI est de 175 B, la taille du LaMDA de Google est de 137 B, la taille du PaLM est de 540 B, la taille du Gogher de DeepMind est de 280 B, et ainsi de suite. Il existe également des modèles géants chinois en Chine, tels que Zhiyuan GLM avec une échelle de 130B, Huawei « Pangu » avec une échelle de 200B, Baidu « Wenxin » avec une échelle de 260B et Inspur « Yuan 1.0 » avec une échelle de 245B. . Une question naturelle se pose donc : que se passe-t-il lorsque la taille des modèles LLM continue de croître ? L'application des modèles pré-entraînés est souvent divisée en deux étapes : l'étape de pré-formation et l'étape d'application de scénarios spécifiques. Dans la phase de pré-formation, l'objectif d'optimisation est l'entropie croisée. Pour les modèles de langage autorégressifs tels que GPT, cela dépend du fait que le LLM prédit correctement le mot suivant, tandis que dans la phase d'application du scénario, cela dépend généralement des indicateurs d'évaluation du LLM. scénario spécifique. Notre intuition générale est que si les performances du modèle LLM dans la phase de pré-formation sont meilleures, sa capacité à résoudre les tâches en aval sera naturellement plus forte. Cependant, ce n’est pas entièrement vrai. Les recherches existantes ont prouvé que l'indice d'optimisation dans la phase de pré-formation montre une corrélation positive avec les tâches en aval, mais elle n'est pas complètement positive. En d’autres termes, il ne suffit pas d’examiner uniquement les indicateurs de la phase de pré-formation pour juger si un modèle LLM est suffisamment performant. Sur cette base, nous examinerons séparément ces deux étapes différentes pour voir quel sera l'impact à mesure que le modèle LLM augmente. Tout d'abord, regardons ce qui se passe lorsque la taille du modèle augmente progressivement pendant la phase de pré-entraînement. OpenAI a spécifiquement étudié cette question dans « Scaling Laws for Neural Language Models » et a proposé la « loi de mise à l'échelle » suivie du modèle LLM. Comme le montre la figure ci-dessus, cette étude prouve : Lorsque nous augmentons indépendamment la quantité de données d'entraînement, la taille des paramètres du modèle ou prolongeons le temps d'entraînement du modèle (par exemple de 1 époque à 2 époques), la perte du pré- Le modèle formé sur l'ensemble de test sera monotone Réducteur, c'est-à-dire que l'effet du modèle s'améliore de plus en plus. Étant donné que ces trois facteurs sont importants, lorsque nous effectuons réellement une pré-formation, nous sommes confrontés à un problème de prise de décision sur la manière d'allouer la puissance de calcul : supposons le budget total de puissance de calcul utilisé pour entraîner le LLM (comme le nombre d'heures de GPU ou jours GPU) étant donné, devrions-nous augmenter la quantité de données et réduire les paramètres du modèle ? Ou la quantité de données et la taille du modèle devraient-elles augmenter en même temps, réduisant ainsi le nombre d'étapes de formation ? À mesure que l'échelle d'un facteur augmente, l'échelle des autres facteurs doit être réduite pour maintenir la puissance de calcul totale inchangée. Il existe donc différents plans d'allocation de puissance de calcul possibles. En fin de compte, OpenAI a choisi d'augmenter simultanément la quantité de données d'entraînement et les paramètres du modèle, mais a utilisé une stratégie d'arrêt précoce pour réduire le nombre d'étapes d'entraînement. Parce que cela prouve que : pour les deux éléments du volume des données d'entraînement et des paramètres du modèle, si vous n'en augmentez qu'un séparément, ce n'est pas le meilleur choix. Il est préférable d'augmenter les deux en même temps selon une certaine proportion. La conclusion est de donner la priorité à l'augmentation des paramètres du modèle, puis de la quantité de données d'entraînement. En supposant que le budget total de puissance de calcul pour la formation LLM augmente de 10 fois, la quantité de paramètres du modèle devrait être augmentée de 5,5 fois et la quantité de données de formation devrait être augmentée de 1,8 fois. À ce stade, l'effet du modèle est optimal. Une étude de DeepMind (Référence : Training Compute-Optimal Large Language Models) a exploré cette question plus en profondeur. Ses conclusions fondamentales sont similaires à celles d'OpenAI. Par exemple, il est en effet nécessaire d'augmenter la quantité de données d'entraînement et. Paramètres du modèle en même temps. Le modèle L'effet sera meilleur. De nombreux grands modèles n'en tiennent pas compte lors de la pré-formation. De nombreux grands modèles LLM augmentent simplement de manière monotone les paramètres du modèle tout en fixant la quantité de données d'entraînement. Cette approche est en fait erronée et limite le potentiel du modèle LLM. Cependant, il corrige la relation proportionnelle entre les deux et estime que la quantité de données d'entraînement et les paramètres du modèle sont tout aussi importants. En d'autres termes, en supposant que le budget total de puissance de calcul utilisé pour entraîner LLM augmente de 10 fois, la quantité de paramètres du modèle. devrait être augmenté de 3,3 fois, 3,3 fois la quantité de données d'entraînement, afin que le modèle ait le meilleur effet. Cela signifie : Augmenter la quantité de données d'entraînement est plus important que nous ne le pensions auparavant. Sur la base de cette compréhension, DeepMind a choisi une autre configuration en termes d'allocation de puissance de calcul lors de la conception du modèle Chinchilla : par rapport au modèle Gopher avec un volume de données de 300 B et un volume de paramètres de modèle de 280 B, Chinchilla a choisi d'augmenter les données d'entraînement de 4 fois. , mais réduit le modèle Les paramètres sont réduits à un quart de ceux de Gopher, soit environ 70B. Cependant, quels que soient les indicateurs de pré-formation ou de nombreux indicateurs de tâches en aval, le Chinchilla est meilleur que le plus grand Gopher. Cela nous apporte l'éclairage suivant : Nous pouvons choisir d'agrandir les données d'entraînement et de réduire les paramètres du modèle LLM proportionnellement pour atteindre l'objectif de réduire considérablement la taille du modèle sans réduire l'effet du modèle. Réduire la taille du modèle présente de nombreux avantages, tels que la vitesse d'inférence sera beaucoup plus rapide une fois appliquée, etc. Il s'agit sans aucun doute d'une voie de développement LLM prometteuse. Ce qui précède est l'impact de l'échelle du modèle dès la phase de pré-formation. Du point de vue de l'effet du LLM sur la résolution de tâches spécifiques en aval, à mesure que l'échelle du modèle augmente, différents types de tâches ont des performances différentes. Sont les trois types de situations suivants. Le premier type de tâche reflète parfaitement la loi d'échelle du modèle LLM, ce qui signifie qu'à mesure que l'échelle du modèle augmente progressivement, les performances de la tâche s'améliorent de plus en plus, comme le montre ( a) ci-dessus Afficher. De telles tâches ont généralement les caractéristiques communes suivantes : ce sont souvent des tâches à forte intensité de connaissances, ce qui signifie que plus le modèle LLM contient de connaissances, meilleures sont les performances de ces tâches. De nombreuses études ont prouvé que plus le modèle LLM est grand, plus l'efficacité de l'apprentissage est élevée, c'est-à-dire que pour la même quantité de données d'entraînement, plus le modèle est grand, meilleur est l'effet de la tâche. Cela montre que même face au même. lot de données de formation, un modèle LLM plus grand est relativement plus efficace. Un modèle plus petit à partir duquel plus de connaissances sont apprises. De plus, dans des circonstances normales, lorsque les paramètres du modèle LLM augmentent, la quantité de données d'entraînement augmente souvent simultanément, ce qui signifie que les grands modèles peuvent apprendre plus de points de connaissances à partir de plus de données. Ces études peuvent bien expliquer le chiffre ci-dessus, pourquoi à mesure que la taille du modèle augmente, ces tâches à forte intensité de connaissances deviennent de mieux en mieux. La plupart des tâches traditionnelles de compréhension du langage naturel sont en fait des tâches à forte intensité de connaissances, et de nombreuses tâches ont connu de grandes améliorations au cours des deux dernières années, dépassant même les performances humaines. Évidemment, cela est probablement dû à l’augmentation de l’échelle du modèle LLM, plutôt qu’à une amélioration technique spécifique. Le deuxième type de tâche montre que LLM a une certaine « capacité émergente », comme indiqué en (b) ci-dessus. La soi-disant « capacité émergente » signifie que lorsque l'échelle des paramètres du modèle n'atteint pas un certain seuil, le modèle n'a fondamentalement aucune capacité à résoudre de telles tâches, ce qui reflète que ses performances équivaut à une sélection aléatoire de réponses. l'échelle du modèle s'étend Une fois le seuil dépassé, l'effet du modèle LLM sur ces tâches connaîtra une augmentation soudaine des performances. En d'autres termes, la taille du modèle est la clé pour débloquer (déverrouiller) de nouvelles capacités de LLM. À mesure que la taille du modèle devient de plus en plus grande, de plus en plus de nouvelles capacités de LLM seront progressivement débloquées. Il s'agit d'un phénomène très magique, car il implique les possibilités suivantes qui rendent les gens optimistes quant à l'avenir : Peut-être que de nombreuses tâches ne peuvent pas être bien résolues par le LLM à l'heure actuelle. Même de notre point de vue actuel, le LLM n'a aucune solution. la capacité de résoudre de telles tâches, mais comme LLM a une « capacité émergente », si nous continuons à pousser de grands modèles, cette capacité pourrait être soudainement débloquée un jour. La croissance du modèle LLM nous apportera des cadeaux inattendus et merveilleux. "Au-delà du jeu de l'imitation : quantifier et extrapoler les capacités des modèles de langage" Cet article souligne que ce type de tâches qui reflètent des "capacités émergentes" ont également certains points communs : ces tâches consistent généralement en plusieurs étapes, et à résoudre ces tâches nécessitent souvent de résoudre d'abord plusieurs étapes intermédiaires, et la capacité de raisonnement logique joue un rôle important dans la solution finale de ces tâches. L'invite de chaîne de pensée est une technologie typique qui améliore les capacités de raisonnement LLM et peut considérablement améliorer les performances de ces tâches. La technologie CoT sera expliquée dans les sections suivantes et ne sera pas abordée ici. La question est : pourquoi LLM a-t-il ce phénomène de « capacité émergente » ? L'article ci-dessus et « Capacités émergentes des grands modèles linguistiques » donnent plusieurs explications possibles : Une explication possible est que les indicateurs d'évaluation de certaines tâches ne sont pas assez fluides. Par exemple, certaines normes de jugement pour les tâches de génération exigent que la chaîne produite par le modèle corresponde complètement à la réponse standard pour être considérée comme correcte, sinon elle recevra 0 point. Par conséquent, même à mesure que le modèle augmente, son effet s'améliore progressivement, ce qui se reflète dans la sortie de fragments de caractères plus corrects. Cependant, comme il n'est pas complètement correct, 0 point sera attribué pour toute petite erreur uniquement lorsque le modèle l'est. suffisamment grand, les scores de sortie sont notés si tous les segments sont corrects. En d'autres termes, parce que l'indicateur n'est pas assez fluide, il ne peut pas refléter la réalité selon laquelle LLM améliore progressivement l'exécution des tâches. Il semble être une manifestation externe d'une « capacité émergente ». Une autre explication possible est la suivante : certaines tâches consistent en plusieurs étapes intermédiaires. À mesure que la taille du modèle augmente, la capacité à résoudre chaque étape augmente progressivement, mais tant qu'une étape intermédiaire est fausse, la réponse finale est fausse, et cela conduira également à ce phénomène superficiel de « capacité émergente ». Bien sûr, les explications ci-dessus sont encore des conjectures. Quant à la raison pour laquelle LLM a ce phénomène, des recherches plus approfondies sont nécessaires. Il existe également un petit nombre de tâches. À mesure que l'échelle du modèle augmente, la courbe d'effet de la tâche présente une caractéristique en forme de U : à mesure que l'échelle du modèle augmente progressivement, la tâche L'effet s'aggrave progressivement, mais lorsque l'échelle du modèle augmente encore, l'effet commence à s'améliorer de plus en plus, montrant une tendance de croissance en forme de U, comme le montre la figure ci-dessus, la tendance de l'indicateur du modèle PaLM rose sur les deux tâches. Pourquoi ces tâches semblent-elles si particulières ? "La mise à l'échelle inverse peut prendre la forme d'un U" Cet article donne une explication : ces tâches contiennent en fait deux types différents de sous-tâches, l'une est la tâche réelle et l'autre est la "tâche d'interférence (tâche de distraction)". Lorsque la taille du modèle est petite, il ne peut identifier aucune sous-tâche, de sorte que les performances du modèle sont similaires à une sélection aléatoire de réponses. Lorsque le modèle atteint une taille moyenne, il effectue principalement des tâches d'interférence, ce qui a un impact négatif sur. la performance réelle de la tâche.Cela se reflète dans la diminution de l'effet de la tâche réelle. Lorsque la taille du modèle augmente encore, LLM peut ignorer les tâches interférentes et effectuer la tâche réelle, ce qui se reflète dans l'effet qui commence à croître. Pour les tâches dont les performances diminuent à mesure que la taille du modèle augmente, si l'invite de chaîne de pensée (CoT) est utilisée, les performances de certaines tâches seront converties pour suivre la loi de mise à l'échelle, c'est-à-dire que plus la taille du modèle est grande. , meilleures sont les performances, tandis que pour d'autres tâches, la tâche est convertie en une courbe de croissance en forme de U. Cela montre en fait que ce type de tâche devrait être une tâche de type raisonnement, de sorte que les performances de la tâche changeront qualitativement après l'ajout de CoT. Généralement, les technologies d'interface que nous mentionnons souvent entre les personnes et le LLM comprennent : l'invite de tir zéro, l'invite de quelques tirs, l'apprentissage en contexte et l'instruction. Ce sont en fait des manières de décrire une tâche spécifique. Mais si vous regardez la littérature, vous constaterez que les noms prêtent à confusion. Parmi eux, Instruct est la méthode d'interface de ChatGPT, ce qui signifie que les gens donnent une description de la tâche en langage naturel, comme "Traduire cette phrase du chinois vers l'anglais", quelque chose comme ceci. Je comprends que l'invite de tir zéro est en fait le premier nom de l'Instruct actuel. Dans le passé, les gens l'appelaient zéro tir, mais maintenant beaucoup de gens l'appellent Instruct. Bien que cela ait la même connotation, il existe deux méthodes spécifiques. Au début, les gens faisaient des invitations à tir zéro. En fait, ils ne savaient pas comment exprimer une tâche, ils changeaient donc différents mots ou phrases et essayaient à plusieurs reprises de bien exprimer la tâche. Cette approche s'est avérée adaptée à la formation. La distribution des données n'a en réalité aucun sens. L'approche actuelle d'Instruct consiste à donner une instruction de commande et à essayer de la faire comprendre à LLM. Ainsi, bien qu’elles soient toutes des expressions de tâches en surface, les idées sont différentes. Et l'apprentissage contextuel a une signification similaire à quelques invites de tir, qui consiste à donner à LLM quelques exemples comme modèle, puis à laisser LLM résoudre de nouveaux problèmes. Je pense personnellement que l'apprentissage en contexte peut également être compris comme une description d'une certaine tâche, mais Instruct est une méthode de description abstraite et l'apprentissage en contexte est un exemple de méthode d'illustration. Bien entendu, étant donné que ces termes sont actuellement utilisés de manière un peu confuse, la compréhension ci-dessus ne représente que mon opinion personnelle. Nous introduisons donc ici uniquement l'apprentissage et l'instruction en contexte, et ne mentionnons plus zéro tir et quelques tirs. Si vous y réfléchissez bien, vous constaterez que l’apprentissage en contexte est une technologie très magique. Qu'y a-t-il de si magique là-dedans ? La magie est que lorsque vous fournissez à LLM plusieurs exemples d'exemples , puis que vous lui donnez , LLM peut prédire avec succès le #🎜🎜 correspondant # Une tentative pour prouver que l'apprentissage en contexte n'apprend pas à partir d'exemples est "Repenser le rôle des démonstrations : qu'est-ce qui fait que l'apprentissage en contexte fonctionne ?". Il a trouvé : Dans l'exemple d'exemple Ce qui a vraiment un plus grand impact sur l'apprentissage en contexte, c'est : la distribution de et En bref, ce travail prouve que l'apprentissage en contexte n'apprend pas la fonction de cartographie, mais la répartition des entrées et des sorties est très importante, et ces deux-là ne peuvent pas être modifiées au hasard. Certains travaux pensent que LLM apprend encore cette fonction de cartographie à partir des exemples donnés Dans l’ensemble, cela reste un mystère non résolu. Magical Instruct Understanding Nous pouvons considérer Instruct comme un énoncé de tâche facile à comprendre pour les êtres humains. Selon cette prémisse, la recherche actuelle sur Instruct peut être divisée en deux types : Instruct qui est plus. recherche universitaire, et une instruction sur la description des besoins humains réels. Jetons d'abord un coup d'œil au premier type : Celui qui relève davantage de la recherche universitaire Instruire. Son thème de recherche principal est la capacité de généralisation du modèle LLM à comprendre Instruct dans des scénarios multitâches. Comme le montre le modèle FLAN de la figure ci-dessus, c'est-à-dire qu'il existe de nombreuses tâches PNL. Pour chaque tâche, les chercheurs construisent un ou plusieurs modèles d'invite comme instruction de la tâche, puis utilisent des exemples de formation pour affiner. le modèle LLM afin que LLM puisse apprendre plusieurs tâches en même temps. Après avoir entraîné le modèle, donnez au modèle LLM une instruction pour une toute nouvelle tâche qu'il n'a jamais vue auparavant, puis laissez LLM résoudre la tâche zéro tir. Le fait que la tâche soit suffisamment bien résolue peut être utilisé pour juger si le modèle LLM. a la capacité de généralisation pour comprendre l’instruction. Si vous résumez les conclusions de la recherche actuelle (veuillez vous référer à "Mise à l'échelle des modèles de langage d'instructions affinés"/"Instructions super-naturelles : généralisation via des instructions déclaratives sur plus de 1600 tâches PNL"), vous pouvez effectivement augmenter la généralisation de Les facteurs d'instruction du modèle LLM comprennent : l'augmentation du nombre de tâches multitâches, l'augmentation de la taille du modèle LLM, la fourniture d'invites CoT et l'augmentation de la diversité des tâches. Si l’une de ces mesures est prise, la compréhension Instruct du modèle LLM peut être améliorée. Le deuxième type est Instruct basé sur des besoins humains réels. Ce type de recherche est représenté par InstructGPT et ChatGPT. Ce type de travail est également basé sur le multitâche, mais la plus grande différence avec le travail orienté vers la recherche académique est qu'il est orienté vers les besoins réels des utilisateurs humains. Pourquoi tu dis ça ? Parce que les invites de description de tâche qu'ils utilisent pour la formation multitâche LLM sont échantillonnées à partir de demandes réelles soumises par un grand nombre d'utilisateurs, au lieu de fixer la portée de la tâche de recherche et de laisser ensuite les chercheurs rédiger les invites de description de tâche. Les soi-disant « besoins réels » se reflètent ici sous deux aspects : premièrement, parce qu'ils sont sélectionnés au hasard à partir des descriptions de tâches soumises par les utilisateurs, les types de tâches couvertes sont plus diversifiés et plus conformes aux besoins réels des utilisateurs ; , une certaine La description rapide d'une tâche est soumise par l'utilisateur et reflète ce que l'utilisateur moyen dirait lorsqu'il exprime les exigences de la tâche, et non ce que vous pensez que l'utilisateur dirait. Évidemment, l’expérience utilisateur du modèle LLM améliorée par ce type de travail sera meilleure. Dans l'article InstructGPT, cette méthode a également été comparée à la méthode FLAN basée sur Instruct. Tout d'abord, utilisez les tâches, les données et le modèle d'invite mentionnés dans FLAN pour affiner GPT3 afin de reproduire la méthode FLAN sur GPT 3, puis comparez-la avec InstructGPT. Étant donné que le modèle de base d'InstructGPT est également GPT3, il n'y a que des différences dans. données et méthodes. Les deux sont comparables, et il s'avère que l'effet de la méthode FLAN est loin derrière InstructGPT. Alors, quelle en est la raison ? Après avoir analysé les données, l'article estime que la méthode FLAN implique relativement peu de champs de tâches et constitue un sous-ensemble des champs impliqués dans InstructGPT, donc l'effet n'est pas bon. En d’autres termes, les tâches impliquées dans le document FLAN ne correspondent pas aux besoins réels des utilisateurs, ce qui entraîne des résultats insuffisants dans les scénarios réels. Cela signifie pour nous qu’il est important de collecter les besoins réels à partir des données des utilisateurs. Le lien entre In Context Learning et Instruct Si nous supposons que In Context Learning utilise quelques exemples pour exprimer concrètement les commandes de tâches, Instruct est une description de tâche abstraite qui est plus conforme aux habitudes humaines. Une question naturelle se pose donc : existe-t-il un lien entre eux ? Par exemple, pouvons-nous fournir à LLM plusieurs exemples spécifiques de réalisation d'une certaine tâche et laisser LLM trouver la commande Instruct correspondante décrite en langage naturel ? Il existe actuellement des travaux sporadiques explorant cette question. Je pense que cette direction est d'une grande valeur pour la recherche. Parlons d'abord de la réponse. La réponse est : Oui, LLM Can. "Les grands modèles de langage sont des ingénieurs d'invite au niveau humain" est un travail très intéressant dans cette direction, comme le montre la figure ci-dessus, pour une certaine tâche, donnez quelques exemples à LLM, laissez LLM générer automatiquement des commandes en langage naturel qui peuvent décrire la tâche, puis il utilise ensuite la description de la tâche générée par LLM pour tester l'effet de la tâche. Les modèles de base qu'il utilise sont GPT 3 et InstructGPT. Après la bénédiction de cette technologie, l'effet d'Instruct généré par LLM est grandement amélioré par rapport à GPT 3 et InstructGPT qui n'utilisent pas cette technologie, et dans certaines tâches, des performances surhumaines. Cela montre qu'il existe un mystérieux lien interne entre les exemples de tâches concrètes et les descriptions de tâches en langage naturel. Quant à savoir exactement quelle est cette connexion ? Nous n’en savons encore rien. De nombreuses études ont prouvé que le LLM a une forte capacité de mémoire pour la connaissance. Cependant, en général, nous ne disons pas qu'une personne est intelligente simplement parce qu'elle a une forte capacité de mémoire. capacité de mémoire. Avoir une forte capacité de raisonnement est souvent un critère important pour juger si une personne est intelligente. De même, pour que l’effet du LLM soit étonnant, une forte capacité de raisonnement est nécessaire. Essentiellement, la capacité de raisonnement est l’utilisation globale de nombreux points de connaissances pertinents pour en tirer de nouvelles connaissances ou de nouvelles conclusions. La capacité de raisonnement du LLM a été l’un des domaines de recherche les plus importants et les plus populaires en LLM au cours de l’année écoulée. Par conséquent, la question qui nous préoccupe est la suivante : Le LLM a-t-il des capacités de raisonnement ? Si oui, sa capacité de raisonnement est-elle suffisamment forte ? Les réponses actuelles à ces deux questions semblent être : Lorsque l'échelle du modèle est suffisamment grande, LLM lui-même a des capacités de raisonnement sur des problèmes de raisonnement simples, LLM a atteint de bonnes capacités, mais il est complexe sur la question. de raisonnement, des recherches plus approfondies sont nécessaires. Si je trie les travaux existants liés au raisonnement LLM, je les classe en deux grandes catégories, reflétant différentes idées techniques pour l'exploitation minière ou la promotion des capacités de raisonnement LLM : Il existe davantage d'études dans la première catégorie, qui peuvent être collectivement référencées. En tant que méthodes basées sur des invites, l'idée principale est de mieux stimuler la capacité de raisonnement du LLM lui-même grâce à des invites ou des échantillons d'invites appropriés. Google a fait beaucoup de travail très efficace dans cette direction. Le deuxième type d'approche consiste à introduire le code du programme pendant le processus de pré-formation et à participer à la pré-formation avec le texte pour améliorer davantage la capacité de raisonnement du LLM. Cela devrait être l'idée mise en œuvre par OpenAI. Par exemple, ChatGPT possède certainement de fortes capacités de raisonnement, mais il n'exige pas que les utilisateurs fournissent des exemples de raisonnement. Par conséquent, les puissantes capacités de raisonnement de ChatGPT proviennent très probablement de l'utilisation de code pour participer à la pré-formation de GPT 3.5. Les deux idées sont en fait très différentes dans leur direction générale : utiliser du code pour améliorer les capacités de raisonnement LLM, ce qui reflète une idée d'améliorer directement les capacités de raisonnement LLM en augmentant la diversité des données de formation et basées sur celles-ci ; La méthode on Prompt ne favorise pas la capacité de raisonnement du LLM lui-même, mais constitue simplement une méthode technique qui permet au LLM de mieux démontrer cette capacité dans le processus de résolution de problèmes. On peut voir que la première (méthode du code) traite la cause profonde, tandis que la seconde traite les symptômes. Bien sûr, les deux sont en fait complémentaires, mais à long terme, la cause profonde est plus importante. Méthode basée sur les invites Il y a beaucoup de travail dans ce domaine, Si résumé, il peut être grossièrement divisé en trois itinéraires techniques. La première idée est d'ajouter directement l'invite de raisonnement auxiliaire# à la question 🎜🎜#. Cette méthode est simple et directe, mais efficace dans de nombreux domaines. Cette approche a été proposée par « Les grands modèles de langage sont des raisonneurs zéro-shot » et est également connue sous le nom de CoT zéro-shot. Plus précisément, il est divisé en deux étapes (comme le montre la figure ci-dessus). Dans la première étape, l'invite « Réfléchissons étape par étape » est ajoutée à la question, et LLM produira le processus de raisonnement spécifique dans la deuxième étape ; , Après les questions de la première étape, divisez le processus de raisonnement spécifique produit par LLM et ajoutez Prompt="Par conséquent, la réponse (chiffres arabes) est", auquel moment LLM donnera la réponse. Une opération aussi simple peut considérablement augmenter l'efficacité du LLM dans diverses tâches de raisonnement. Par exemple, sur l'ensemble de tests de raisonnement mathématique GSM8K, après l'ajout d'invites, la précision du raisonnement a augmenté directement de 10,4 % à l'origine à 40,4 %, ce qui est miraculeux. Pourquoi LLM a-t-il la capacité de lister les étapes de raisonnement détaillées et de calculer la réponse en donnant une invite de type « Pensons étape par étape » ? La raison n'est pas encore concluante. Je suppose que c'est probablement parce qu'il y a une grande quantité de ce type de données dans les données de pré-entraînement, qui commencent par « Pensons étape par étape », suivi d'étapes de raisonnement détaillées, et donne enfin la réponse. LLM mémorise ces schémas lors de la pré-formation. Lorsque nous saisissons cette invite, LLM est incité à « rappeler » vaguement les étapes de dérivation de certains exemples, afin que nous puissions imiter ces exemples pour effectuer un raisonnement par étapes et donner des réponses. Bien sûr, ce n'est que ma conclusion infondée. Si tel est vraiment le cas, si vous lisez la pratique CoT standard présentée plus tard, vous constaterez que le CoT Zero-shot n'est probablement pas différent du CoT standard en substance, sauf que le CoT standard l'est. écrit par des humains. Exemples d'étapes, et Zero-shot CoT active très probablement des exemples en mémoire qui contiennent des étapes de raisonnement via des invites, qui sont probablement si différentes. Il est tout à fait compréhensible que l'effet CoT standard soit meilleur que l'effet Zero-Shot CoT, car après tout, en s'appuyant sur LLM pour rappeler des exemples, la précision n'est pas estimée trop élevée et la précision des exemples artificiellement donnés est garantie, Ainsi, l'effet CoT standard naturel sera meilleur. Cela illustre une vérité, c'est-à-dire que LLM lui-même a une capacité de raisonnement, mais nous n'avons aucun moyen de stimuler sa capacité par des invites appropriées. Utiliser le langage pour effectuer deux-. les invites d'étape peuvent libérer son potentiel dans une certaine mesure. De plus, pour le chinois, il y aura probablement un autre rappel en or, tel que « Les idées détaillées pour résoudre les problèmes sont les suivantes », similaire à celui-ci, car lorsque le corpus chinois explique les étapes de raisonnement, les phrases d'introduction et « Réfléchissons à l'étape par étape" sont souvent utilisés "Cela devrait être différent". C'est une déclaration occidentale évidente, et il est en fait nécessaire d'explorer ce rappel en or en chinois. La deuxième idée est généralement appelée la chaîne de pensée basée sur l'exemple (few-shot CoT, Chain of Thought) Invite#🎜 🎜#. Cette direction est actuellement la direction principale de la recherche sur l'inférence LLM, et de nombreux travaux sont effectués sur cette idée. Nous présentons brièvement quelques travaux représentatifs avec des résultats significatifs, qui peuvent essentiellement représenter l'orientation du développement technique du CoT. L'idée principale de CoT est en fait très simple ; afin d'enseigner au modèle LLM l'apprentissage du raisonnement, quelques exemples de raisonnement écrits manuellement sont donnés dans les exemples. , avant d'obtenir la réponse finale, les étapes de raisonnement spécifiques sont clairement expliquées étape par étape, et ces processus de raisonnement détaillés écrits manuellement constituent la chaîne de réflexion. Invite Pour des exemples spécifiques. , veuillez vous référer au texte bleu dans l'image ci-dessus. CoT signifie laisser le modèle LLM comprendre une vérité : pendant le processus de raisonnement, ne pas faire de pas trop grands, sinon il est facile de faire des erreurs. Changez votre mode de pensée, transformez les gros problèmes en petits problèmes, étape par étape. , accumulez de petites victoires en grandes victoires. Le premier article proposant clairement le concept de CoT est « L'incitation à la chaîne de pensée suscite le raisonnement dans de grands modèles de langage ». L'article a été publié en janvier 2022. Bien que la méthode soit très simple, la capacité de raisonnement du modèle LLM a été grandement améliorée. après avoir appliqué CoT GSM8K, la précision de l'ensemble de tests de raisonnement mathématique a augmenté jusqu'à environ 60,1 %. Bien sûr, cette idée de donner des étapes de raisonnement détaillées et des processus intermédiaires n'a pas été proposée pour la première fois par CoT. La technologie antérieure du « bloc-notes » (voir : Montrez votre travail : blocs-notes pour le calcul intermédiaire avec des modèles de langage) a d'abord adopté des idées similaires. CoT a été proposé il y a peu, bientôt en 2022 -3 En mars, une technologie d'amélioration appelée « Auto-cohérence » a augmenté la précision de l'ensemble de tests GSM8K à 74,4 %. L'article proposant cette amélioration était « L'auto-cohérence améliore le raisonnement en chaîne de pensée dans les modèles linguistiques ». L'idée d'« auto-cohérence » est également très intuitive (voir l'image ci-dessus) : d'abord, vous pouvez utiliser CoT pour donner plusieurs exemples de processus de raisonnement écrit, puis demander à LLM de raisonner sur le problème posé. est CoT, génère directement un processus d'inférence et des réponses, tout le processus est terminé. "L'auto-cohérence" n'est pas le cas. Elle nécessite que LLM génère plusieurs processus de raisonnement et réponses différents, puis utilise le vote pour sélectionner la meilleure réponse. L'idée est très simple et directe, mais l'effet est vraiment bon. "Self-Cohérence" apprend en fait au LLM à apprendre cette vérité : Kong Yiji a dit un jour qu'il y avait quatre façons d'écrire le mot "fenouil" pour les haricots de fenouil. De même, il peut y avoir de nombreuses solutions correctes à un problème mathématique, chacune avec une solution différente. dérivation. Le processus mène à la réponse finale. Tous les chemins mènent à Rome. Même s'il y a des gens qui se perdent et arrivent à Pékin, ceux qui se perdent ne sont que quelques-uns. Regardez où vont la plupart des gens, et c'est là que se trouve la bonne réponse. Les méthodes simples contiennent souvent de profondes significations philosophiques, n’est-ce pas vrai ? Plus loin, l'ouvrage "On the Advance of Making Language Models Better Reasoners" intègre en outre "à partir d'une question rapide" basée sur "l'auto-cohérence" "l'expansion vers "Plusieurs questions rapides, vérification de l'exactitude des étapes intermédiaires de raisonnement et vote pondéré sur les réponses à plusieurs résultats", ces trois améliorations ont augmenté la précision de l'ensemble de tests GSM8K à environ 83 %. La troisième idée incarne l'idée d'une division-et- conquérir l'algorithme# 🎜🎜#. Bien sûr, ce soi-disant « diviser pour régner » est ma généralisation, d’autres ne l’ont pas dit. L'idée centrale de cette idée est la suivante : pour un problème de raisonnement complexe, on le décompose en un certain nombre de sous-problèmes faciles à résoudre. Après avoir résolu les sous-problèmes un par un, on en déduit ensuite la réponse au complexe. problème à partir des réponses aux sous-problèmes. Vous voyez, cela ressemble en effet à l’idée de l’algorithme diviser pour régner. Personnellement, je pense que ce type de réflexion peut être le moyen authentique de révéler l'essence du problème et, en fin de compte, de résoudre le problème de raisonnement complexe du LLM. Nous prenons la technologie « du moins au plus » comme exemple pour illustrer une mise en œuvre spécifique de cette idée, comme le montre la figure ci-dessus : elle est divisée en deux étapes. Dans la première étape, à partir du problème initial, nous pouvons connaître. la finale Quelle est la question à poser ? Supposons que le problème final soit Final Q, puis remplissons le modèle d'invite à partir du problème d'origine : « Si je veux résoudre le problème Final Q, alors je dois le résoudre d'abord", puis remettez le problème d'origine et cette invite à LLM, laissez le modèle LLM donner la réponse, ce qui équivaut à laisser le LLM donner le préfixe sous-question Sub Q de la question finale ; puis nous entrons dans la deuxième étape, laisser le LLM répondre à la sous-question Sub Q qui vient d'être obtenue et obtenir la réponse correspondante. Ensuite, la question d'origine est fusionnée en la sous-question Sub Q et la réponse correspondante, puis le LLM se voit poser la question finale Final Q. C'est à ce moment-là que le LLM donnera la réponse définitive. De cette manière, il incarne l'idée de démonter les sous-questions et de trouver progressivement la réponse finale à partir des réponses aux sous-questions. La pré-formation au code améliore les capacités de raisonnement du LLM Les trois méthodes principales ci-dessus utilisent des invites pour stimuler les capacités de raisonnement des modèles LLM. Concernant les capacités de raisonnement du LLM, un phénomène intéressant et déroutant a été observé. : En plus du texte, si vous pouvez ajouter du code de programme pour participer à la pré-formation du modèle, la capacité de raisonnement du modèle LLM peut être grandement améliorée. Cette conclusion peut être tirée des sections expérimentales de nombreux articles (veuillez vous référer à : CHAÎNE AUTOMATIQUE DE PENSÉE DANS DE GRANDS MODÈLES DE LANGAGE/Tâches difficiles de BIG-Bench et si la chaîne de pensée peut les résoudre et d'autres sections expérimentales d'articles. ). La figure ci-dessus montre des données expérimentales de l'article "On the Advance of Making Language Models Better Reasoners", dans lequel GPT3 davinci est le modèle GPT 3 standard, basé sur un entraînement en texte brut - ; davinci-002 (appelé Codex en interne par OpenAI) est un modèle formé à la fois sur les données Code et NLP. Si vous comparez les effets des deux, vous pouvez voir que quelle que soit la méthode d'inférence utilisée, il suffit de passer d'un modèle de pré-entraînement de texte pur à un modèle de pré-entraînement mixte texte et code, la capacité d'inférence du modèle a été améliorée. sur presque tous les ensembles de données de test. Par exemple, nous prenons comme exemple la méthode « Self Cohérence ». L'amélioration des performances sur la plupart des ensembles de données dépasse directement 20 à 50 points de pourcentage. , au niveau des modèles d'inférence spécifiques, nous n'avons fait qu'ajouter du code de programme supplémentaire en plus du texte lors de la pré-formation. En plus de ce phénomène, à partir des données de la figure ci-dessus, nous pouvons également tirer d'autres conclusions. Par exemple, le modèle de pré-entraînement en texte pur de GPT 3 a en fait un degré considérable de capacité de raisonnement. aux mathématiques telles que GSM8K En plus des résultats d'inférence médiocres, d'autres collections de données d'inférence fonctionnent également bien. Le principe est que vous devez utiliser des méthodes appropriées pour stimuler la capacité dont vous disposez. Un autre exemple est text-davinci-002, qui est dans le code ; -davinci-002 Basé sur le modèle après avoir ajouté le réglage fin des instructions (qui est la première étape pour ajouter le modèle InstructGPT ou ChatGPT), sa capacité de raisonnement est plus faible que celle du Codex, mais d'autres recherches montrent qu'elle est plus forte que le Codex en langage naturel tâches de traitement. Cela semble indiquer que l'ajout d'un réglage fin des instructions nuira à la capacité de raisonnement du modèle LLM, mais améliorera dans une certaine mesure la capacité de compréhension du langage naturel. Ces conclusions sont en fait très intéressantes et peuvent inspirer une réflexion et une exploration plus approfondies. Une question naturelle se pose donc : Pourquoi les modèles pré-entraînés peuvent-ils acquérir des capacités de raisonnement supplémentaires grâce à la pré-entraînement du code ? La raison exacte est actuellement inconnue et mérite une exploration plus approfondie. Je suppose que cela peut être dû au fait que la formation au code de la version originale du Codex (qui utilise uniquement la formation au code, veuillez vous référer à : Évaluation des grands modèles de langage formés sur le code) génère du code à partir du texte, et le code contient souvent de nombreux commentaires textuels, ce qui est essentiellement similaire au modèle pré-entraîné qui a effectué un travail d'alignement multimodal sur les deux types de données. Les données doivent contenir une proportion considérable de codes, de descriptions et d'annotations de problèmes mathématiques ou logiques. Il est évident que ces données de raisonnement mathématique ou logique sont utiles pour résoudre les problèmes de raisonnement mathématique en aval. Réflexions sur les capacités de raisonnement LLM Ce qui précède présente les idées techniques dominantes du raisonnement LLM et certaines conclusions existantes. Ensuite, je parlerai de mes réflexions sur la technologie de raisonnement des modèles LLM. Le contenu suivant est purement personnel. inférence, il n'y a pas beaucoup de preuves, veuillez donc vous y référer avec prudence. Mon jugement est le suivant : Bien qu'au cours de la dernière année, la technologie ait fait des progrès rapides dans la stimulation de la capacité de raisonnement du LLM et que de grands progrès techniques aient été réalisés, le sentiment général est que nous allons peut-être dans la bonne direction. il reste encore un long chemin à parcourir avant d'arriver à la véritable nature du problème, et nous devons réfléchir plus profondément et explorer cela. Tout d'abord, je suis d'accord avec l'idée principale de l'algorithme diviser pour régner mentionné ci-dessus. Pour les problèmes de raisonnement complexes, nous devrions le décomposer en un certain nombre de sous-problèmes simples, car la probabilité de répondre au sous-problème est la suivante. -les problèmes correctement sont beaucoup plus importants pour LLM. Après que LLM ait répondu aux sous-questions une par une, il en dérive ensuite progressivement la réponse finale. Inspiré par la technologie « du moins au plus d'incitation », si je réfléchis plus loin, je pense que le raisonnement LLM est susceptible d'être l'une des deux possibilités suivantes : un problème de raisonnement graphique qui interagit continuellement avec LLM, ou un problème de raisonnement graphique qui interagit avec LLM Problèmes d'exécution de l'organigramme du programme pour interagir avec LLM. Parlons d'abord du problème de raisonnement graphique. Comme le montre la figure ci-dessus, supposons que nous ayons un moyen de décomposer un problème complexe en une structure graphique composée de sous-problèmes ou de sous-étapes. le graphique sont des sous-problèmes ou des sous-étapes, les bords du graphique représentent les dépendances entre les sous-questions, c'est-à-dire que ce n'est qu'en répondant à la sous-question A que vous pouvez répondre à la sous-question B, et il y a un il y a une forte probabilité qu'il y ait une structure de boucle dans le graphique, c'est-à-dire qu'il y ait certaines sous-étapes à plusieurs reprises. En supposant que nous puissions obtenir le diagramme de désassemblage des sous-problèmes mentionné ci-dessus, nous pouvons guider LLM étape par étape selon la structure du graphique en fonction de la relation de dépendance, et répondre aux sous-questions auxquelles il faut répondre en premier jusqu'à ce que la réponse finale soit dérivée. . Parlons à nouveau du problème de l'organigramme du programme. Reportez-vous à l'image ci-dessus. Supposons que nous ayons un moyen de décomposer un problème complexe en sous-problèmes ou sous-étapes et de générer un organigramme de programme. structure composée de sous-étapes. Dans cette structure, certaines étapes seront exécutées à plusieurs reprises (structure en boucle), et l'exécution de certaines étapes nécessite un jugement conditionnel (branche conditionnelle). En bref, interagissez avec LLM lors de l'exécution de chaque sous-étape pour obtenir la réponse à la sous-étape, puis continuez à exécuter selon le processus jusqu'à ce que la réponse finale soit obtenue. Similaire à ce modèle. En supposant que cette idée soit à peu près correcte, il peut être possible d'expliquer de ce point de vue pourquoi l'ajout de code améliorera la capacité de raisonnement du modèle pré-entraîné : il y a une forte probabilité que le modèle multimodal pré-entraîné de utilise un programme implicite comme celui-ci à l'intérieur du modèle En tant que pont entre les deux modalités, l'organigramme relie les deux, c'est-à-dire de la description textuelle à l'organigramme implicite, puis au code spécifique généré par l'organigramme. En d'autres termes, ce type de pré-formation multimodale peut améliorer la capacité du modèle LLM à construire un organigramme implicite à partir de texte et à l'exécuter selon l'organigramme, c'est-à-dire qu'il renforce sa capacité de raisonnement. Bien sûr, le plus gros problème avec l'idée ci-dessus est de savoir comment pouvons-nous nous appuyer sur le modèle LLM ou d'autres modèles pour obtenir la structure graphique ou la structure de l'organigramme basée sur le problème décrit dans le texte ? C'est peut-être là la difficulté. Une idée possible est de continuer à améliorer la pré-formation sur le texte et le code de meilleure qualité, et d'adopter la méthode d'apprentissage implicite de la structure implicite interne. Si vous réfléchissez à la technologie CoT actuelle sur la base des idées ci-dessus, vous pouvez la comprendre de cette façon : le CoT standard s'appuie en fait sur un texte en langage naturel pour décrire la structure du graphique ou l'organigramme du programme, tandis que la technologie "du moins au plus" ; Il essaie de déduire la structure du graphe en se basant sur le dernier nœud du graphe et en s'appuyant sur l'inférence arrière. Cependant, il est évident que la méthode actuelle limite la profondeur de son inférence arrière, ce qui signifie qu'elle ne peut déduire qu'une structure de graphe très simple. C'est ce qui limite ses capacités. Voici quelques domaines de recherche LLM que je considère personnellement comme importants, ou des orientations de recherche dignes d'une exploration approfondie. Explorer le plafond d'échelle du modèle LLM Bien qu'il puisse sembler qu'il n'y ait aucun contenu technique à continuer d'augmenter l'échelle du modèle LLM, c'est en réalité extrêmement important. À mon avis, depuis l'émergence de Bert, de GPT 3, puis de ChatGPT, il y a une forte probabilité que les principales contributions de ces impressionnantes avancées technologiques clés proviennent de la croissance de la taille du modèle LLM, plutôt que d'une technologie spécifique. . Peut-être que la véritable clé pour débloquer l'AGI est : des données à extrêmement grande échelle et suffisamment diversifiées, des modèles à extrêmement grande échelle et des processus de formation suffisants. De plus, la réalisation de modèles LLM à très grande échelle nécessite des capacités de mise en œuvre d’ingénierie très élevées de la part de l’équipe technique, et on ne peut pas considérer que ce sujet manque de contenu technique. Alors, quelle est l'importance pour la recherche de continuer à augmenter l'échelle du modèle LLM ? Je pense qu'il y a deux aspects de la valeur. Tout d'abord, comme mentionné ci-dessus, nous savons que pour les tâches à forte intensité de connaissances, à mesure que la taille du modèle augmente, les performances de diverses tâches deviendront de mieux en mieux et pour de nombreux types de raisonnements et de tâches difficiles, avec l'ajout de CoT ; Invite Enfin, son effet montre également une tendance à suivre la loi d'échelle. Une question naturelle se pose donc : pour ces tâches, dans quelle mesure l’effet d’échelle du LLM peut-il résoudre ces tâches ? C’est une question qui préoccupe beaucoup de gens, dont moi. Deuxièmement, compte tenu de la « capacité émergente » magique du LLM, si nous continuons à augmenter la taille du modèle, quelles nouvelles capacités débloquera-t-il auxquelles nous ne nous attendions pas ? C'est aussi une question très intéressante. Compte tenu des deux points ci-dessus, nous devons encore continuer à augmenter la taille du modèle pour voir où se situe le plafond de la taille du modèle pour résoudre diverses tâches. Bien sûr, ce genre de chose ne peut qu'être évoqué. Pour 99,99% des pratiquants, il n'y a aucune opportunité ou capacité de le faire. Pour ce faire, les exigences en matière de ressources financières et de volonté d'investissement, de capacités d'ingénierie et d'enthousiasme technique des instituts de recherche sont extrêmement élevées, et toutes sont indispensables. Une estimation approximative du nombre d’institutions capables de le faire n’est pas supérieur à 5 à l’étranger et à 3 au maximum dans le pays. Bien sûr, compte tenu de la question des coûts, il pourrait y avoir un « grand modèle par actions » à l'avenir, ce qui est un phénomène dans lequel plusieurs institutions compétentes coopèrent et travaillent ensemble pour construire un très grand modèle. Améliorez la capacité de raisonnement complexe du LLM Comme décrit précédemment à propos de la capacité de raisonnement du LLM, bien que la capacité de raisonnement du LLM ait été grandement améliorée au cours de la dernière année, de nombreuses études (Référence : Limitations du langage Les modèles d'induction arithmétique et symbolique (les grands modèles de langage ne peuvent toujours pas planifier) montre qu'actuellement, LLM peut résoudre de meilleurs problèmes de raisonnement, qui sont souvent relativement simples. La capacité de raisonnement complexe de LLM est encore faible, comme même un simple raisonnement par copie de caractères ou en plus. , opérations de soustraction, de multiplication et de division, lorsque les chaînes ou les nombres sont très longs, la capacité de raisonnement de LLM diminuera rapidement et les capacités de raisonnement complexes telles que la capacité de planification du comportement sont très faibles. Dans l’ensemble, le renforcement des capacités de raisonnement complexes du LLM devrait être l’un des aspects les plus importants des recherches futures sur le LLM. Comme mentionné précédemment, l'ajout de code et la pré-formation sont une direction qui améliore directement les capacités de raisonnement du LLM. Il n'y a actuellement pas suffisamment de recherches dans cette direction. Il s'agit plutôt d'un résumé de l'expérience pratique, explorant les principes qui la sous-tendent, puis introduisant davantage de nouveaux types de données autres que le code pour améliorer la capacité de raisonnement du LLM. améliorer plus essentiellement la capacité de raisonnement. LLM intègre d'autres domaines de recherche en plus de la PNL Le ChatGPT actuel est bon pour les tâches de PNL et de code En tant qu'acteur de départ important menant à l'AGI, il combine des images, des vidéos, de l'audio et d'autres images avec plusieurs. -l'intégration modale au LLM, et même à d'autres domaines présentant des différences plus évidentes comme l'IA pour la science et le contrôle des robots, sont progressivement intégrés au LLM, ce qui est le seul moyen pour le LLM de conduire à l'AGI. Cette direction vient tout juste de commencer, elle a donc une grande valeur de recherche. Interface interactive plus facile à utiliser pour les personnes et les LLM Comme mentionné précédemment, la plus grande contribution technique de ChatGPT est ici. Mais il est évident que la technologie actuelle n’est pas parfaite et qu’il doit y avoir de nombreuses commandes que LLM ne peut pas comprendre. Par conséquent, dans cette direction, nous recherchons une meilleure technologie pour permettre aux humains d'utiliser leurs propres expressions de commande habituelles, et LLM peut les comprendre. Il s'agit d'une direction technique nouvelle et très prometteuse. Construire un ensemble de données d'évaluation de tâches complet et difficile Un bon ensemble de données d'évaluation est la pierre angulaire pour guider le progrès continu de la technologie. À mesure que le modèle LLM augmente progressivement, les performances des tâches s'améliorent rapidement, ce qui rend rapidement obsolètes de nombreux ensembles de tests standard. En d’autres termes, ces ensembles de données sont trop simples par rapport aux technologies existantes. Dans le cadre d’un test sans difficulté, on ne sait pas où se trouvent les défauts et les angles morts de la technologie actuelle. Par conséquent, la création d’un ensemble de tests difficiles est la clé pour promouvoir les progrès de la technologie LLM. À l'heure actuelle, de nouveaux ensembles de tests devraient apparaître dans l'industrie, les plus représentatifs incluent BIGBench, OPT-IML, etc. Ces ensembles de tests reflètent certaines caractéristiques, comme le fait d'être plus difficiles que les technologies LLM existantes et d'intégrer une variété de tâches. Inspiré de ChatGPT, je pense qu'une autre considération devrait être incluse : refléter les besoins réels des utilisateurs. C'est-à-dire que l'expression de ces tâches est véritablement initiée par les utilisateurs. Seul le modèle LLM ainsi construit peut répondre aux besoins réels des utilisateurs. De plus, je pense que le LLM débordera rapidement de ses capacités dans des domaines autres que la PNL, et la manière d'incorporer davantage de données d'évaluation provenant d'autres domaines doit également être réfléchie à l'avance. Ingénierie des données de haute qualité Pour le modèle de pré-formation, les données sont son fondement, et le processus de pré-formation peut être compris comme le processus d'absorption des connaissances contenues dans les données. Par conséquent, nous devons renforcer davantage l’exploration, la collecte et le nettoyage de données de haute qualité. Concernant les données, il y a deux aspects à considérer : la qualité et la quantité des données. Sur la base des expériences comparatives de T5, nous pouvons conclure que parmi les deux facteurs de quantité et de qualité, la qualité est prioritaire et que la bonne voie devrait être d'augmenter la taille des données tout en garantissant la qualité des données. La qualité des données comprend de multiples mesures telles que le contenu informationnel des données et la diversité des données. Par exemple, Wiki est évidemment une donnée de haute qualité avec une densité de connaissances extrêmement élevée dans le monde, en termes de contenu informationnel ; augmentation des données La diversité des types est sans aucun doute la base pour stimuler diverses nouvelles capacités de LLM. Par exemple, l'ajout de données à partir de sites Web de questions et réponses est directement utile pour améliorer les capacités d'assurance qualité de LLM. La diversité des données donne au LLM la capacité de mieux résoudre davantage de types de tâches différents, ce qui peut donc être le critère le plus critique en matière de qualité des données. Concernant la quantité de données, en principe, toutes les données publiées publiquement sur Internet peuvent être incluses dans le processus de pré-formation du modèle LLM. Alors, où sont ses limites ? "Allons-nous manquer de données ? Une analyse des limites de la mise à l'échelle des ensembles de données dans le Machine Learning" a estimé cela et a conclu que d'ici 2026 environ, les données NLP de haute qualité seront épuisées et les données NLP de mauvaise qualité seront épuisées d'ici 2030. Elle sera épuisée d’ici 2050, et les données d’images de mauvaise qualité le seront entre 2030 et 2060. Et cela signifie : soit nous disposons alors de nouveaux types de sources de données, soit nous devons augmenter l'efficacité du modèle LLM dans l'utilisation des données. Sinon, l’approche actuelle d’optimisation des modèles basée sur les données cessera de progresser ou ses avantages diminueront. Sparsification du très grand modèle LLM Transformer Parmi les plus grands LLM actuellement, une proportion considérable de modèles adoptent une structure clairsemée (Sparse), comme GPT 3, PaLM, GLaM, etc., GPT 4 a une forte probabilité. Nous emprunterons également la voie du modèle clairsemé. Le principal avantage de l’utilisation d’un modèle basé sur Sparse est qu’il peut réduire considérablement le temps de formation et le temps d’inférence en ligne du LLM. L'article de Switch Transformer souligne que dans le cadre du même budget de puissance de calcul, en utilisant le Transformer clairsemé, la vitesse de formation du modèle LLM peut être augmentée de 4 à 7 fois par rapport au Transformateur Dense. Pourquoi les modèles Sparse accélèrent-ils les temps de formation et d'inférence ? En effet, bien que les paramètres du modèle soient énormes, pour une certaine instance de formation, le modèle Sparse n'utilise qu'une petite partie de l'ensemble des paramètres via le mécanisme de routage. Le nombre de paramètres actifs impliqués dans la formation et l'inférence est relativement faible, c'est donc le cas. rapide. Je pense que les très grands modèles LLM à l'avenir convergeront très probablement vers des modèles clairsemés. Il y a deux raisons principales : d'une part, les recherches existantes montrent (Référence : Les grands modèles sont des apprenants parcimonieux : Activation Sparsity in Trained Transformers) que le transformateur dense standard lui-même est également peu activé pendant la formation et l'inférence, c'est-à-dire seulement une partie de Les paramètres seront activés et la plupart des paramètres ne participent pas au processus de formation et d'inférence. Dans ce cas, autant migrer directement vers le modèle clairsemé ; de plus, il ne fait aucun doute que l'échelle du modèle LLM continuera à augmenter, et le coût élevé de la formation est un obstacle important à l'expansion ultérieure du modèle. Les modèles clairsemés peuvent réduire considérablement le coût des très grands modèles. Ainsi, à mesure que la taille du modèle augmente, les avantages apportés par le modèle clairsemé deviennent plus évidents. Compte tenu de ces deux aspects, il existe une forte probabilité que les modèles LLM plus grands adoptent à l’avenir une solution de modèle clairsemé. Alors pourquoi d’autres modèles à grande échelle ne prennent-ils pas actuellement la voie des modèles clairsemés ? Étant donné que le modèle Sparse présente des problèmes tels qu'un entraînement instable et un surapprentissage facile, il n'est pas facile de bien s'entraîner. Par conséquent, la manière de corriger les problèmes rencontrés par les modèles clairsemés et de concevoir des modèles clairsemés plus faciles à former constitue une orientation de recherche future importante. (Architecture Encodeur-Décodeur, l'Encodeur adopte un modèle de langage bidirectionnel, et le Décodeur adopte un modèle de langage autorégressif, c'est donc une structure hybride, mais son essence appartient toujours au mode Bert). Nous devrions choisir un modèle de langage autorégressif comme GPT. Les raisons sont analysées dans la section changement de paradigme de cet article. À l'heure actuelle, lorsque les LLM nationaux effectuent une sélection technologique dans ce domaine, il semble que beaucoup d'entre eux empruntent la voie technique du modèle de langage bidirectionnel Bert ou du modèle de langage hybride T5. Il est très probable que la direction se soit égarée. Deuxièmement, Une capacité de raisonnement puissante est une base psychologique importante pour que les utilisateurs reconnaissent le LLM#🎜 🎜 #Basique, et si vous souhaitez que le LLM ait de fortes capacités de raisonnement, selon l'expérience actuelle, il est préférable d'introduire une grande quantité de code et de texte pour entraîner le LLM ensemble lors de la pré-formation#🎜🎜 # . Quant à la justification, vous trouverez une analyse correspondante dans les parties pertinentes plus haut dans cet article. Troisièmement, Si vous voulez que la taille des paramètres du modèle ne soit pas si énorme, mais que vous voulez quand même que l'effet soit assez bon, là Il existe actuellement deux techniques. Les options peuvent être configurées : soit améliorer la collecte de données de haute qualité, l'exploration, le nettoyage, etc., ce qui signifie que les paramètres de mon modèle peuvent être la moitié de ChatGPT/GPT 4, mais pour obtenir des effets similaires, la quantité de données d'entraînement de haute qualité doit être deux fois supérieure à celle du modèle ChatGPT/GPT 4 (approche Chinchilla) Une autre voie qui peut réduire efficacement la taille du modèle ; est d'adopter la récupération de texte (basée sur la récupération) L'itinéraire modèle + LLM peut également réduire considérablement l'échelle des paramètres du modèle LLM tout en conservant le même effet. Ces deux sélections technologiques ne s'excluent pas mutuellement, mais sont complémentaires. En d'autres termes, ces deux technologies peuvent être utilisées en même temps pour obtenir des effets similaires à ceux de très grands modèles, en partant du principe que l'échelle du modèle est relativement petite. Quatrièmement, en raison de la grande échelle du modèle, le coût de formation des très grands modèles est trop élevé, ce qui fait que peu d'institutions ont la capacité de le faire. Et d’après l’analyse ci-dessus, il ressort que continuer à étendre l’échelle du modèle LLM est quelque chose qui se produira certainement et qui devrait être fait. Par conséquent, Comment réduire le coût de la formation en LLM grâce à des moyens techniques est très important. La fragmentation de l'extracteur de fonctionnalités de LLM est un choix technique qui peut réduire efficacement les coûts de formation et d'inférence des modèles. Il s’ensuit qu’à mesure que les modèles deviennent plus grands, la fragmentation des modèles LLM est une option à considérer. Cinquièmement, ChatGPT est actuellement la solution technique la plus proche du LLM idéal, et le LLM idéal devrait être basé sur un grand modèle universel de base presque omnipotent, pour prendre en charge un. variété de types de tâches de niveau supérieur. À l'heure actuelle, la prise en charge de plus en plus de types de tâches est principalement obtenue en augmentant la diversité des données de pré-formation LLM. Plus la diversité des données est grande, plus les types de tâches que LLM peut prendre en charge sont riches. Par conséquent, devrait prêter attention à l'idée d'ajouter de nouvelles capacités de LLM en augmentant la diversité des données . Sixième interface d'opération homme-machine facile à utiliser. Les humains utilisent leurs propres expressions habituelles pour décrire les tâches, et LLM doit être capable de comprendre le véritable sens de ces instructions. En outre, il convient également de noter que ces instructions sont conformes aux besoins humains réels, c'est-à-dire que les descriptions de tâches doivent être collectées auprès des utilisateurs finaux, plutôt que de s'appuyer sur l'imagination ou les suppositions des développeurs eux-mêmes. ChatGPT La plus grande inspiration pour moi est en fait celle-ci. Quant à savoir s'il faut utiliser l'apprentissage par renforcement, je ne pense pas que cela ait de l'importance. D'autres technologies alternatives devraient pouvoir faire des choses similaires#🎜. 🎜#. ChatGPT : Pourquoi est-ce OpenAI Au début de cet article, nous avons évoqué la philosophie d'OpenAI sur le LLM. Que pense OpenAI du LLM ? En regardant les technologies qu'il a continuellement introduites, nous pouvons voir que, à partir de GPT 1.0, il a fondamentalement fermement considéré le LLM comme le seul moyen d'accéder à l'AGI. Plus précisément, aux yeux d'OpenAI, la future AGI devrait ressembler à ceci : il existe un très grand LLM indépendant des tâches utilisé pour apprendre diverses connaissances à partir de données massives. Ce LLM génère tout pour résoudre divers problèmes pratiques, et il devrait le faire. être capable de comprendre les commandes humaines afin qu'elles puissent être utilisées par les humains. En fait, la compréhension du concept de développement LLM au premier semestre est de « construire un très grand LLM indépendant des tâches et de lui permettre d'apprendre diverses connaissances à partir de données massives. C'est le consensus de presque tout le monde et peut refléter la vision réelle d'OpenAI ». . C'est la seconde moitié. . La raison pour laquelle OpenAI peut créer ChatGPT est qu'il a un positionnement relativement élevé, qu'il est exempt d'interférences externes et qu'il a une attitude inébranlable. Nous pouvons passer en revue certaines des étapes clés qu'il a suivies : GPT 1.0 suit la voie du modèle de langage autorégressif consistant à générer des modèles, qui a été publié avant Bert. Bert a prouvé que les modèles de langage bidirectionnels fonctionnent mieux que les modèles de langage autorégressifs unidirectionnels pour de nombreuses tâches de compréhension de la PNL. Malgré cela, GPT 2.0 n'a pas opté pour la voie des modèles de langage bidirectionnels, il a toujours suivi la voie de la génération de texte et a commencé à essayer des invites à tir nul et des invites à tir réduit. En fait, à l'heure actuelle, l'AGI dans l'esprit d'OpenAI a commencé à faire surface et montre progressivement ses contours. Juste parce que l'effet de zéro coup/quelques coups est bien pire que Bert + réglage fin, tout le monde ne le prend pas trop au sérieux, et ils ne comprennent même pas pourquoi il insiste toujours sur la voie du modèle de langage à sens unique. À l'heure actuelle, j'estime que même OpenAI lui-même ne sera peut-être pas en mesure de garantir que cette voie fonctionnera définitivement. Cependant, cela ne l'empêche pas de continuer à repartir sur cette route. GPT 3.0 a démontré des capacités d'invite zéro tir/quelques tirs relativement puissantes. À l'heure actuelle, l'AGI dans l'esprit d'OpenAI a complètement fui hors de l'eau, avec un contour clair, et son effet prouve également que cette voie est plus susceptible d'être suivie. . Passé. GPT 3.0 est un carrefour et un tournant qui détermine l'orientation du développement de LLM. L'autre voie correspondante est le modèle « Bert+fine-tuning ». À cette croisée des chemins, différents pratiquants ont choisi de prendre des chemins différents, et l'écart technique a commencé à se creuser à partir de là. Malheureusement, de nombreux praticiens nationaux choisissent de continuer à reculer sur la voie du « Bert + réglage fin », qui est également un moment clé à l'origine de la situation arriérée d'aujourd'hui. À l'avenir, il existe InstructGPT et ChatGPT 
 ème nœud
ème nœud  dans la première couche cachée de FFN dans l'image ci-dessus, peut-être qu'il enregistre les connaissances . Le vecteur clé correspondant au nœud
dans la première couche cachée de FFN dans l'image ci-dessus, peut-être qu'il enregistre les connaissances . Le vecteur clé correspondant au nœud  fait en fait référence au vecteur de poids du nœud
fait en fait référence au vecteur de poids du nœud  et de chaque nœud de la couche d'entrée ; et le vecteur Valeur correspondant fait référence à la connexion entre le nœud
et de chaque nœud de la couche d'entrée ; et le vecteur Valeur correspondant fait référence à la connexion entre le nœud  et chaque nœud de la couche Valeur de la seconde ; couche de vecteur de poids FFN. Le vecteur clé de chaque neurone est utilisé pour identifier un certain modèle de langage ou de connaissances dans l'entrée. Il s'agit d'un détecteur de modèles. Si l'entrée contient un certain modèle qu'elle souhaite détecter, alors le vecteur d'entrée et le poids clé du nœud
et chaque nœud de la couche Valeur de la seconde ; couche de vecteur de poids FFN. Le vecteur clé de chaque neurone est utilisé pour identifier un certain modèle de langage ou de connaissances dans l'entrée. Il s'agit d'un détecteur de modèles. Si l'entrée contient un certain modèle qu'elle souhaite détecter, alors le vecteur d'entrée et le poids clé du nœud  sont calculés en tant que produits internes vectoriels, et Relu est ajouté pour former une grande réponse numérique de
sont calculés en tant que produits internes vectoriels, et Relu est ajouté pour former une grande réponse numérique de  , ce qui signifie que
, ce qui signifie que  a a détecté ce modèle, alors ceci La valeur de réponse est propagée à la deuxième couche de FFN via le vecteur de poids de valeur du nœud
a a détecté ce modèle, alors ceci La valeur de réponse est propagée à la deuxième couche de FFN via le vecteur de poids de valeur du nœud  . Cela équivaut à pondérer la valeur du vecteur Valeur avec la valeur de réponse, puis à la transmettre et à la refléter à la sortie de chaque nœud de la deuxième couche Valeur. De cette manière, le processus de calcul de propagation vers l'avant de FFN ressemble à la détection d'un certain modèle de connaissances via Key, puis à la suppression de la valeur correspondante et à la réflexion de la valeur sur la sortie de la deuxième couche de FFN. Bien entendu, chaque nœud de la deuxième couche de FFN collectera toutes les informations sur les nœuds de la couche clé de FFN, il s'agit donc d'une réponse mixte, et la réponse mixte de tous les nœuds de la couche Valeur peut être interprétée comme des informations de distribution de probabilité représentant la mot de sortie.
. Cela équivaut à pondérer la valeur du vecteur Valeur avec la valeur de réponse, puis à la transmettre et à la refléter à la sortie de chaque nœud de la deuxième couche Valeur. De cette manière, le processus de calcul de propagation vers l'avant de FFN ressemble à la détection d'un certain modèle de connaissances via Key, puis à la suppression de la valeur correspondante et à la réflexion de la valeur sur la sortie de la deuxième couche de FFN. Bien entendu, chaque nœud de la deuxième couche de FFN collectera toutes les informations sur les nœuds de la couche clé de FFN, il s'agit donc d'une réponse mixte, et la réponse mixte de tous les nœuds de la couche Valeur peut être interprétée comme des informations de distribution de probabilité représentant la mot de sortie.  dans la figure ci-dessus est la mémoire clé-valeur qui enregistre cet élément de connaissance. Son vecteur clé est utilisé pour détecter le modèle de connaissance "La capitale de la Chine est..." et son vecteur valeur stocke essentiellement. les mêmes mots que « Pékin » » L'intégration est un vecteur relativement proche. Lorsque l'entrée de Transformer est "La capitale de la Chine est [Masque]", le nœud
dans la figure ci-dessus est la mémoire clé-valeur qui enregistre cet élément de connaissance. Son vecteur clé est utilisé pour détecter le modèle de connaissance "La capitale de la Chine est..." et son vecteur valeur stocke essentiellement. les mêmes mots que « Pékin » » L'intégration est un vecteur relativement proche. Lorsque l'entrée de Transformer est "La capitale de la Chine est [Masque]", le nœud  détecte ce modèle de connaissances à partir de la couche d'entrée, il génère donc une sortie de réponse plus grande. Nous supposons que les autres neurones de la couche clé n'ont pas de réponse à cette entrée, alors le nœud correspondant dans la couche valeur ne recevra en fait que le mot incorporé correspondant à la valeur de « Pékin » et effectuera un traitement ultérieur via la grande valeur de réponse. de
détecte ce modèle de connaissances à partir de la couche d'entrée, il génère donc une sortie de réponse plus grande. Nous supposons que les autres neurones de la couche clé n'ont pas de réponse à cette entrée, alors le nœud correspondant dans la couche valeur ne recevra en fait que le mot incorporé correspondant à la valeur de « Pékin » et effectuera un traitement ultérieur via la grande valeur de réponse. de  Amplification numérique. Par conséquent, la sortie correspondant à la position du masque affichera naturellement le mot « Pékin ». C'est essentiellement ce processus. Cela semble compliqué, mais c'est en réalité très simple.
Amplification numérique. Par conséquent, la sortie correspondant à la position du masque affichera naturellement le mot « Pékin ». C'est essentiellement ce processus. Cela semble compliqué, mais c'est en réalité très simple. Effet d'échelle : que se passe-t-il lorsque le LLM devient de plus en plus grand
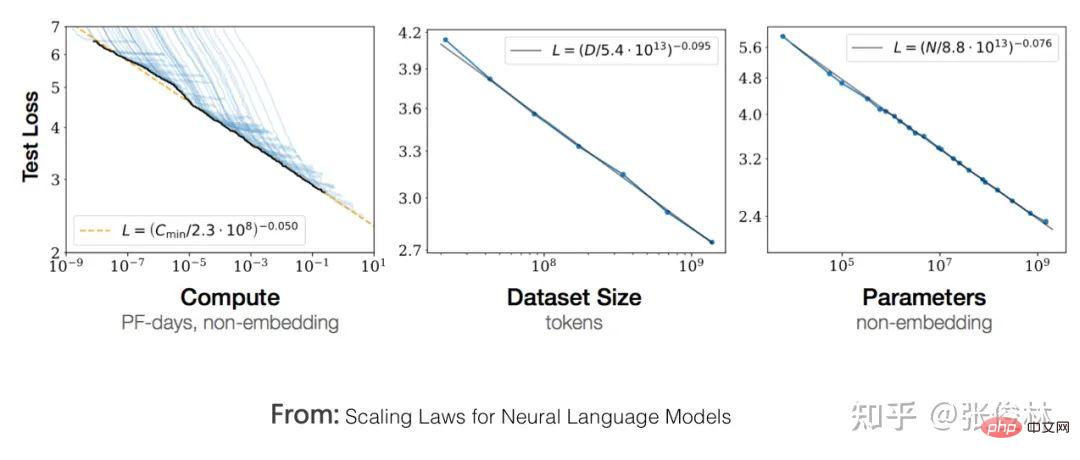
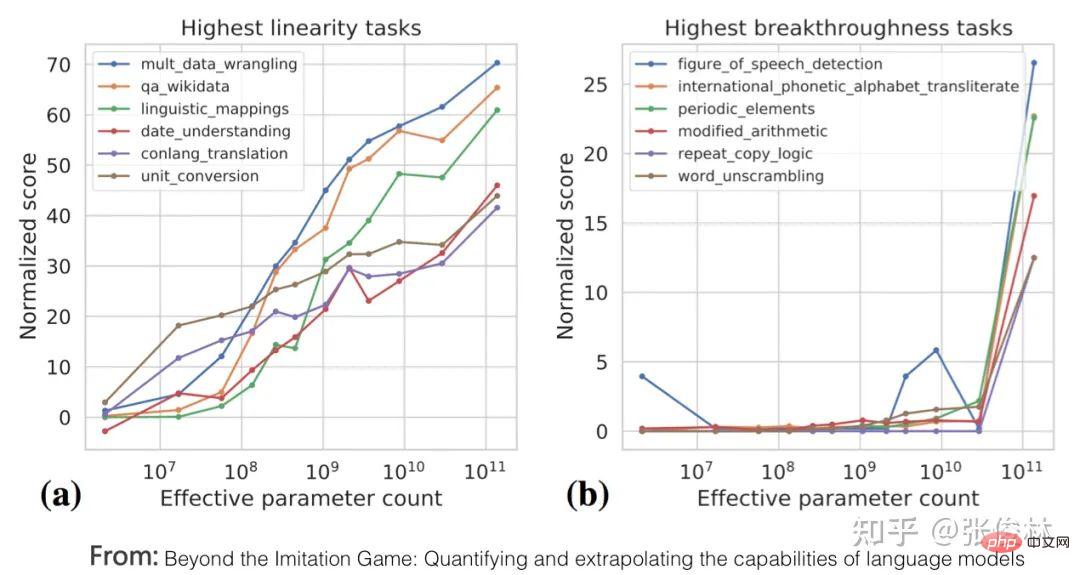
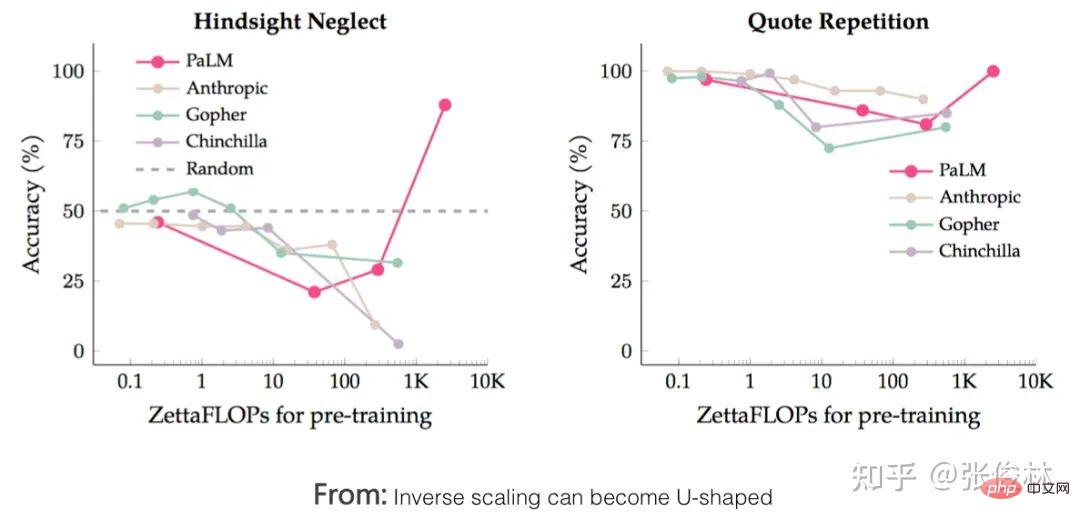
Interface homme-machine : de l'apprentissage en contexte à la compréhension de l'instruction
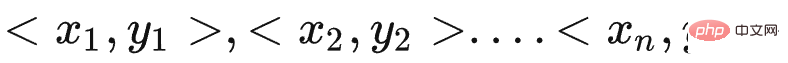
 Le réglage fin et l'apprentissage en contexte semblent fournir quelques exemples sont donnés au LLM, mais ils sont qualitativement différents (voir la figure ci-dessus) : Le réglage fin utilise ces exemples comme données d'entraînement et utilise la rétropropagation pour modifier les paramètres du modèle de LLM. L'action de modification des paramètres du modèle incarne le processus de LLM. apprendre de ces exemples. Cependant, In Context Learning n'a pris que des exemples pour que LLM les examine, et n'a pas utilisé la rétropropagation pour modifier les paramètres du modèle LLM en fonction des exemples, et lui a demandé de prédire de nouveaux exemples. Puisque les paramètres du modèle ne sont pas modifiés, cela signifie qu'il semble que LLM n'a pas suivi un processus d'apprentissage, alors pourquoi peut-il prédire de nouveaux exemples simplement en le regardant ? C’est la magie de l’apprentissage en contexte. Cela vous rappelle-t-il une parole : "Juste parce que je t'ai regardé une fois de plus dans la foule, je ne pourrai plus jamais oublier ton visage." La chanson s'appelle "Legend". Êtes-vous en train de dire que c'est légendaire ou pas ?
Le réglage fin et l'apprentissage en contexte semblent fournir quelques exemples sont donnés au LLM, mais ils sont qualitativement différents (voir la figure ci-dessus) : Le réglage fin utilise ces exemples comme données d'entraînement et utilise la rétropropagation pour modifier les paramètres du modèle de LLM. L'action de modification des paramètres du modèle incarne le processus de LLM. apprendre de ces exemples. Cependant, In Context Learning n'a pris que des exemples pour que LLM les examine, et n'a pas utilisé la rétropropagation pour modifier les paramètres du modèle LLM en fonction des exemples, et lui a demandé de prédire de nouveaux exemples. Puisque les paramètres du modèle ne sont pas modifiés, cela signifie qu'il semble que LLM n'a pas suivi un processus d'apprentissage, alors pourquoi peut-il prédire de nouveaux exemples simplement en le regardant ? C’est la magie de l’apprentissage en contexte. Cela vous rappelle-t-il une parole : "Juste parce que je t'ai regardé une fois de plus dans la foule, je ne pourrai plus jamais oublier ton visage." La chanson s'appelle "Legend". Êtes-vous en train de dire que c'est légendaire ou pas ? 
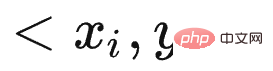 fourni à LLM,
fourni à LLM,  est
est  Le correspondant La bonne réponse n'est en fait pas importante. Si nous remplaçons la bonne réponse
Le correspondant La bonne réponse n'est en fait pas importante. Si nous remplaçons la bonne réponse  par une autre réponse aléatoire
par une autre réponse aléatoire  , cela n'affectera pas l'effet de l'apprentissage en contexte. Cela illustre au moins une chose : In Context Learning ne fournit pas à LLM les informations sur la fonction de cartographie de
, cela n'affectera pas l'effet de l'apprentissage en contexte. Cela illustre au moins une chose : In Context Learning ne fournit pas à LLM les informations sur la fonction de cartographie de  à
à  : #🎜🎜 #
: #🎜🎜 # 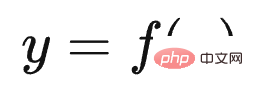 , sinon, si vous modifiez la bonne balise au hasard, cela perturbera définitivement la fonction de cartographie . En d’autres termes, l’apprentissage contextuel n’apprend pas le processus de mappage de l’espace d’entrée à l’espace de sortie.
, sinon, si vous modifiez la bonne balise au hasard, cela perturbera définitivement la fonction de cartographie . En d’autres termes, l’apprentissage contextuel n’apprend pas le processus de mappage de l’espace d’entrée à l’espace de sortie. 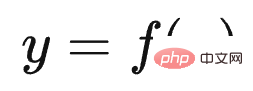
 , c'est-à-dire la somme de distribution de l'entrée texte
, c'est-à-dire la somme de distribution de l'entrée texte  Quelles sont les réponses des candidats
Quelles sont les réponses des candidats  ? Si vous modifiez ces deux distributions, par exemple en remplaçant
? Si vous modifiez ces deux distributions, par exemple en remplaçant  par un contenu autre que les réponses des candidats, l'effet d'apprentissage en contexte diminuera fortement.
par un contenu autre que les réponses des candidats, l'effet d'apprentissage en contexte diminuera fortement. 
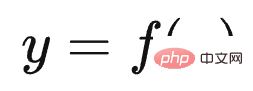 , mais elle est apprise implicitement. Par exemple, « Quel algorithme d'apprentissage est l'apprentissage en contexte ? Enquêtes avec des modèles linéaires » estime que Transformer peut implicitement apprendre le processus de cartographie de
, mais elle est apprise implicitement. Par exemple, « Quel algorithme d'apprentissage est l'apprentissage en contexte ? Enquêtes avec des modèles linéaires » estime que Transformer peut implicitement apprendre le processus de cartographie de  à
à  à partir d'exemples. Sa fonction d'activation contient des fonctions de cartographie simples, tandis que LLM peut apprendre le processus de cartographie. à partir d'exemples pour tirer celui correspondant. L'article « Pourquoi GPT peut-il apprendre en contexte ? Les modèles de langage effectuent secrètement une descente de gradient en tant que méta-optimiseurs » traite ICL comme un réglage fin implicite.
à partir d'exemples. Sa fonction d'activation contient des fonctions de cartographie simples, tandis que LLM peut apprendre le processus de cartographie. à partir d'exemples pour tirer celui correspondant. L'article « Pourquoi GPT peut-il apprendre en contexte ? Les modèles de langage effectuent secrètement une descente de gradient en tant que méta-optimiseurs » traite ICL comme un réglage fin implicite. Lumière de la sagesse : Comment améliorer la capacité de raisonnement du LLM
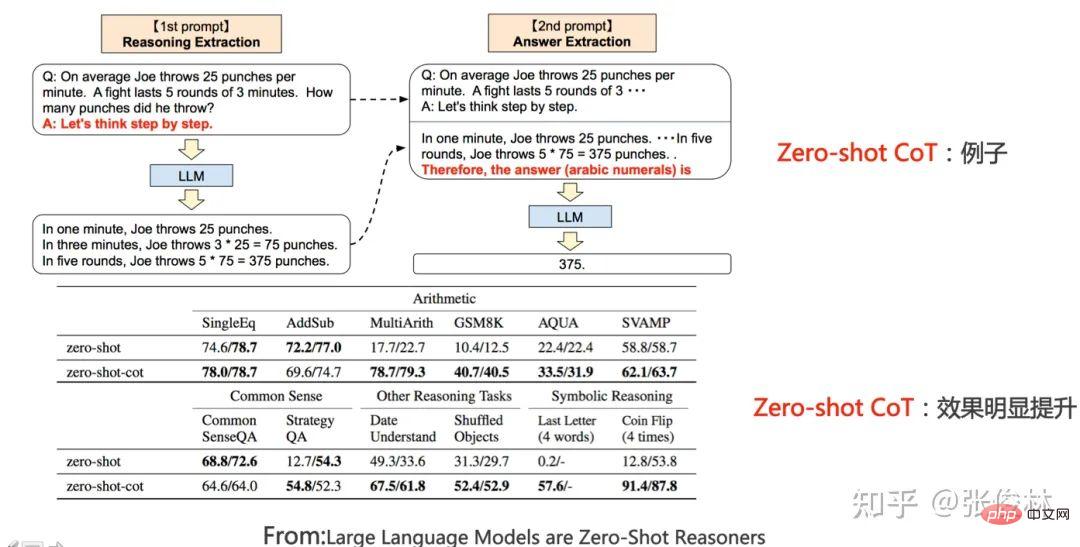
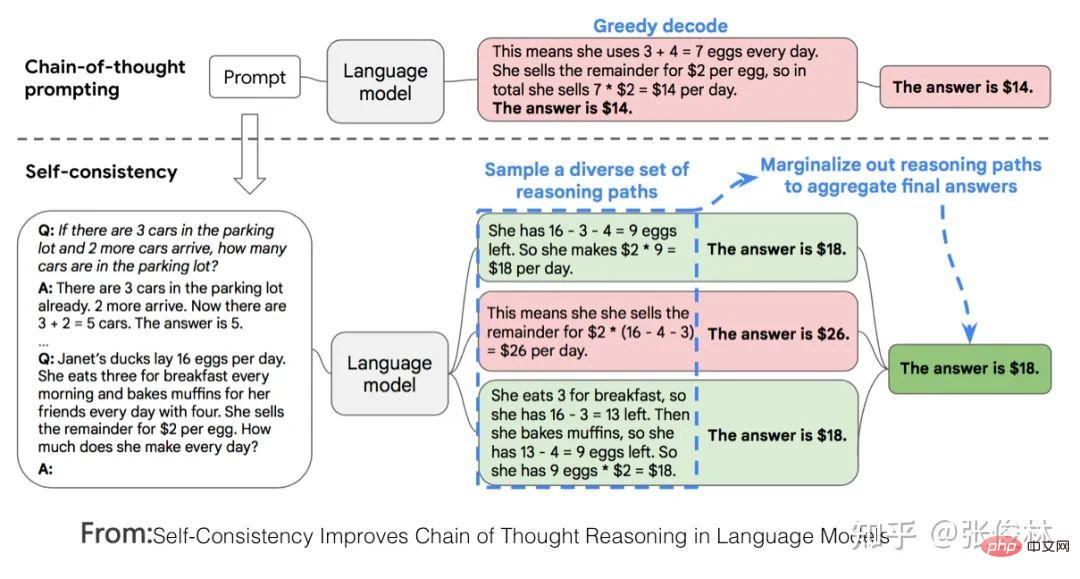
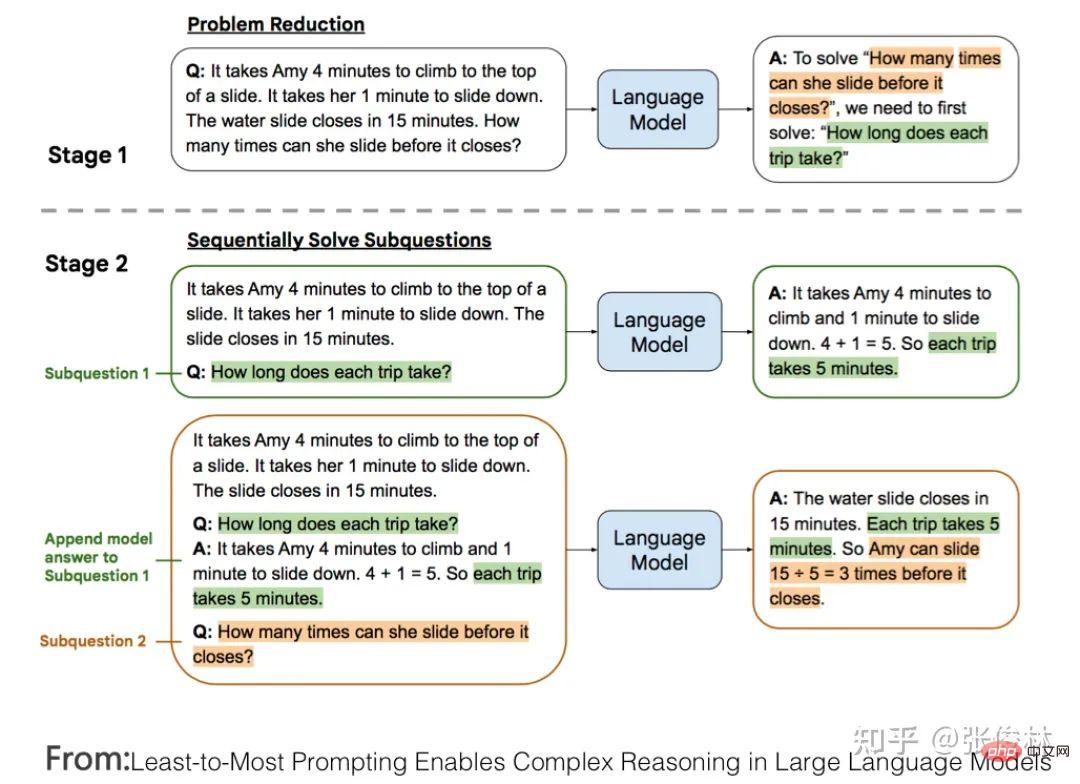
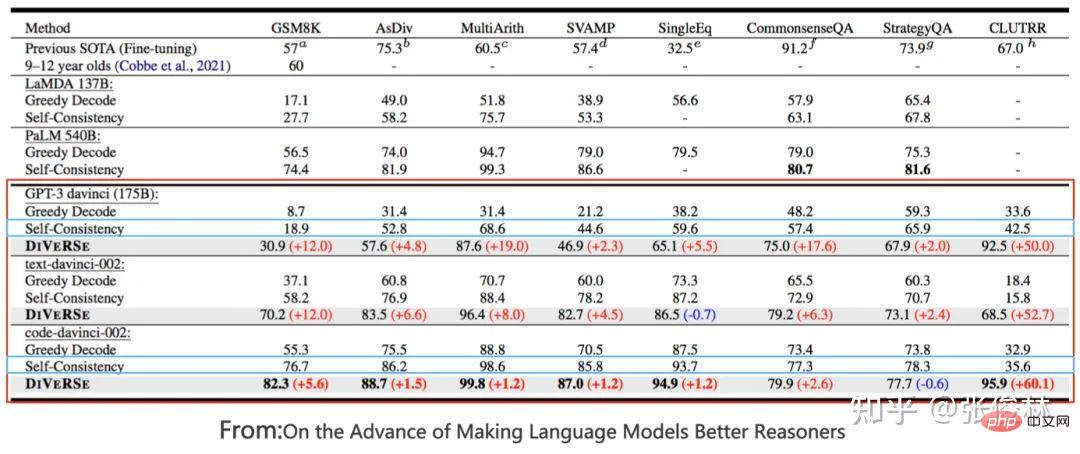
La route vers l'avenir : tendances de la recherche LLM et orientations clés dignes de recherche
Le chemin de l'apprentissage : à quoi devez-vous faire attention lors de la réplication de ChatGPT ? Conclusion de la recherche : lors de la sélection technologique, vous devez vous concentrer sur l'évaluation des problèmes suivants : Choix : GPT est un modèle de langage autorégressif, Bert est un modèle bidirectionnel. modèle de langage, et T5 est un modèle hybride
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Le modèle MoE open source le plus puissant au monde est ici, avec des capacités chinoises comparables à celles du GPT-4, et le prix ne représente que près d'un pour cent de celui du GPT-4-Turbo.
May 07, 2024 pm 04:13 PM
Le modèle MoE open source le plus puissant au monde est ici, avec des capacités chinoises comparables à celles du GPT-4, et le prix ne représente que près d'un pour cent de celui du GPT-4-Turbo.
May 07, 2024 pm 04:13 PM
Imaginez un modèle d'intelligence artificielle qui non seulement a la capacité de surpasser l'informatique traditionnelle, mais qui permet également d'obtenir des performances plus efficaces à moindre coût. Ce n'est pas de la science-fiction, DeepSeek-V2[1], le modèle MoE open source le plus puissant au monde est ici. DeepSeek-V2 est un puissant mélange de modèle de langage d'experts (MoE) présentant les caractéristiques d'une formation économique et d'une inférence efficace. Il est constitué de 236B paramètres, dont 21B servent à activer chaque marqueur. Par rapport à DeepSeek67B, DeepSeek-V2 offre des performances plus élevées, tout en économisant 42,5 % des coûts de formation, en réduisant le cache KV de 93,3 % et en augmentant le débit de génération maximal à 5,76 fois. DeepSeek est une entreprise explorant l'intelligence artificielle générale
 Bonjour, Atlas électrique ! Le robot Boston Dynamics revient à la vie, des mouvements étranges à 180 degrés effraient Musk
Apr 18, 2024 pm 07:58 PM
Bonjour, Atlas électrique ! Le robot Boston Dynamics revient à la vie, des mouvements étranges à 180 degrés effraient Musk
Apr 18, 2024 pm 07:58 PM
Boston Dynamics Atlas entre officiellement dans l’ère des robots électriques ! Hier, l'Atlas hydraulique s'est retiré "en larmes" de la scène de l'histoire. Aujourd'hui, Boston Dynamics a annoncé que l'Atlas électrique était au travail. Il semble que dans le domaine des robots humanoïdes commerciaux, Boston Dynamics soit déterminé à concurrencer Tesla. Après la sortie de la nouvelle vidéo, elle a déjà été visionnée par plus d’un million de personnes en seulement dix heures. Les personnes âgées partent et de nouveaux rôles apparaissent. C'est une nécessité historique. Il ne fait aucun doute que cette année est l’année explosive des robots humanoïdes. Les internautes ont commenté : Les progrès des robots ont fait ressembler la cérémonie d'ouverture de cette année à des êtres humains, et le degré de liberté est bien plus grand que celui des humains. Mais n'est-ce vraiment pas un film d'horreur ? Au début de la vidéo, Atlas est allongé calmement sur le sol, apparemment sur le dos. Ce qui suit est à couper le souffle
 KAN, qui remplace MLP, a été étendu à la convolution par des projets open source
Jun 01, 2024 pm 10:03 PM
KAN, qui remplace MLP, a été étendu à la convolution par des projets open source
Jun 01, 2024 pm 10:03 PM
Plus tôt ce mois-ci, des chercheurs du MIT et d'autres institutions ont proposé une alternative très prometteuse au MLP – KAN. KAN surpasse MLP en termes de précision et d’interprétabilité. Et il peut surpasser le MLP fonctionnant avec un plus grand nombre de paramètres avec un très petit nombre de paramètres. Par exemple, les auteurs ont déclaré avoir utilisé KAN pour reproduire les résultats de DeepMind avec un réseau plus petit et un degré d'automatisation plus élevé. Plus précisément, le MLP de DeepMind compte environ 300 000 paramètres, tandis que le KAN n'en compte qu'environ 200. KAN a une base mathématique solide comme MLP est basé sur le théorème d'approximation universelle, tandis que KAN est basé sur le théorème de représentation de Kolmogorov-Arnold. Comme le montre la figure ci-dessous, KAN a
 L'IA bouleverse la recherche mathématique ! Le lauréat de la médaille Fields et mathématicien sino-américain a dirigé 11 articles les mieux classés | Aimé par Terence Tao
Apr 09, 2024 am 11:52 AM
L'IA bouleverse la recherche mathématique ! Le lauréat de la médaille Fields et mathématicien sino-américain a dirigé 11 articles les mieux classés | Aimé par Terence Tao
Apr 09, 2024 am 11:52 AM
L’IA change effectivement les mathématiques. Récemment, Tao Zhexuan, qui a prêté une attention particulière à cette question, a transmis le dernier numéro du « Bulletin de l'American Mathematical Society » (Bulletin de l'American Mathematical Society). En se concentrant sur le thème « Les machines changeront-elles les mathématiques ? », de nombreux mathématiciens ont exprimé leurs opinions. L'ensemble du processus a été plein d'étincelles, intense et passionnant. L'auteur dispose d'une équipe solide, comprenant Akshay Venkatesh, lauréat de la médaille Fields, le mathématicien chinois Zheng Lejun, l'informaticien de l'Université de New York Ernest Davis et de nombreux autres universitaires bien connus du secteur. Le monde de l’IA a radicalement changé. Vous savez, bon nombre de ces articles ont été soumis il y a un an.
 Google est ravi : les performances de JAX surpassent Pytorch et TensorFlow ! Cela pourrait devenir le choix le plus rapide pour la formation à l'inférence GPU
Apr 01, 2024 pm 07:46 PM
Google est ravi : les performances de JAX surpassent Pytorch et TensorFlow ! Cela pourrait devenir le choix le plus rapide pour la formation à l'inférence GPU
Apr 01, 2024 pm 07:46 PM
Les performances de JAX, promu par Google, ont dépassé celles de Pytorch et TensorFlow lors de récents tests de référence, se classant au premier rang sur 7 indicateurs. Et le test n’a pas été fait sur le TPU présentant les meilleures performances JAX. Bien que parmi les développeurs, Pytorch soit toujours plus populaire que Tensorflow. Mais à l’avenir, des modèles plus volumineux seront peut-être formés et exécutés sur la base de la plate-forme JAX. Modèles Récemment, l'équipe Keras a comparé trois backends (TensorFlow, JAX, PyTorch) avec l'implémentation native de PyTorch et Keras2 avec TensorFlow. Premièrement, ils sélectionnent un ensemble de
 Les robots Tesla travaillent dans les usines, Musk : Le degré de liberté des mains atteindra 22 cette année !
May 06, 2024 pm 04:13 PM
Les robots Tesla travaillent dans les usines, Musk : Le degré de liberté des mains atteindra 22 cette année !
May 06, 2024 pm 04:13 PM
La dernière vidéo du robot Optimus de Tesla est sortie, et il peut déjà fonctionner en usine. À vitesse normale, il trie les batteries (les batteries 4680 de Tesla) comme ceci : Le responsable a également publié à quoi cela ressemble à une vitesse 20 fois supérieure - sur un petit "poste de travail", en sélectionnant et en sélectionnant et en sélectionnant : Cette fois, il est publié L'un des points forts de la vidéo est qu'Optimus réalise ce travail en usine, de manière totalement autonome, sans intervention humaine tout au long du processus. Et du point de vue d'Optimus, il peut également récupérer et placer la batterie tordue, en se concentrant sur la correction automatique des erreurs : concernant la main d'Optimus, le scientifique de NVIDIA Jim Fan a donné une évaluation élevée : la main d'Optimus est l'un des robots à cinq doigts du monde. le plus adroit. Ses mains ne sont pas seulement tactiles
 FisheyeDetNet : le premier algorithme de détection de cible basé sur une caméra fisheye
Apr 26, 2024 am 11:37 AM
FisheyeDetNet : le premier algorithme de détection de cible basé sur une caméra fisheye
Apr 26, 2024 am 11:37 AM
La détection de cibles est un problème relativement mature dans les systèmes de conduite autonome, parmi lesquels la détection des piétons est l'un des premiers algorithmes à être déployés. Des recherches très complètes ont été menées dans la plupart des articles. Cependant, la perception de la distance à l’aide de caméras fisheye pour une vue panoramique est relativement moins étudiée. En raison de la distorsion radiale importante, la représentation standard du cadre de délimitation est difficile à mettre en œuvre dans les caméras fisheye. Pour alléger la description ci-dessus, nous explorons les conceptions étendues de boîtes englobantes, d'ellipses et de polygones généraux dans des représentations polaires/angulaires et définissons une métrique de segmentation d'instance mIOU pour analyser ces représentations. Le modèle fisheyeDetNet proposé avec une forme polygonale surpasse les autres modèles et atteint simultanément 49,5 % de mAP sur l'ensemble de données de la caméra fisheye Valeo pour la conduite autonome.
 Une seule carte exécute Llama 70B plus rapidement que deux cartes, Microsoft vient de mettre le FP6 dans l'Open source A100 |
Apr 29, 2024 pm 04:55 PM
Une seule carte exécute Llama 70B plus rapidement que deux cartes, Microsoft vient de mettre le FP6 dans l'Open source A100 |
Apr 29, 2024 pm 04:55 PM
Le FP8 et la précision de quantification inférieure en virgule flottante ne sont plus le « brevet » du H100 ! Lao Huang voulait que tout le monde utilise INT8/INT4, et l'équipe Microsoft DeepSpeed a commencé à exécuter FP6 sur A100 sans le soutien officiel de NVIDIA. Les résultats des tests montrent que la quantification FP6 de la nouvelle méthode TC-FPx sur A100 est proche ou parfois plus rapide que celle de INT4, et a une précision supérieure à celle de cette dernière. En plus de cela, il existe également une prise en charge de bout en bout des grands modèles, qui ont été open source et intégrés dans des cadres d'inférence d'apprentissage profond tels que DeepSpeed. Ce résultat a également un effet immédiat sur l'accélération des grands modèles : dans ce cadre, en utilisant une seule carte pour exécuter Llama, le débit est 2,65 fois supérieur à celui des cartes doubles. un
