
 Périphériques technologiques
IA
Le stock mondial de données linguistiques de haute qualité est rare et ne peut être ignoré
Périphériques technologiques
IA
Le stock mondial de données linguistiques de haute qualité est rare et ne peut être ignoré
Le stock mondial de données linguistiques de haute qualité est rare et ne peut être ignoré

En tant que l'un des trois éléments de l'intelligence artificielle, les données jouent un rôle important.
Mais avez-vous déjà pensé à : Et si un jour, toutes les données du monde s'épuisaient ?
En fait, la personne qui a posé cette question n'a certainement aucun problème mental, car ce jour pourrait vraiment arriver bientôt ! ! !
Récemment, le chercheur Pablo Villalobos et d'autres ont publié un article intitulé"Allons-nous manquer de données ?" L'article « Analyse des limites de la mise à l'échelle des ensembles de données dans l'apprentissage automatique » a été publié sur arXiv.
Sur la base d'une analyse précédente des tendances de la taille des ensembles de données, ils ont prédit la croissance de la taille des ensembles de données dans les domaines du langage et de la vision, et ont estimé la tendance de développement du stock total de données non étiquetées disponibles au cours des prochaines décennies.
Leurs recherches montrent que les données linguistiques de haute qualité seront épuisées dès 2026 ! En conséquence, la vitesse de développement de l’apprentissage automatique ralentira également. Ce n'est vraiment pas optimiste.
Deux méthodes sont utilisées ensemble, mais les résultats ne sont pas optimistes
L'équipe de recherche de cet article est composée de 11 chercheurs et 3 consultants, avec des membres du monde entier, déterminés à réduire l'écart entre le développement de la technologie de l'IA et Stratégie d'IA et fourniture Fournir des conseils aux principaux décideurs en matière de sécurité de l'IA.

Chinchilla est un nouveau modèle d'optimisation informatique prédictive proposé par des chercheurs de DeepMind.
En fait, lors d'expériences sur Chinchilla auparavant, un chercheur a souligné un jour que "les données d'entraînement deviendront bientôt un goulot d'étranglement dans l'expansion de grands modèles de langage".
Ils ont donc analysé la croissance de la taille des ensembles de données d'apprentissage automatique pour le traitement du langage naturel et la vision par ordinateur, et ont utilisé deux méthodes pour extrapoler : en utilisant les taux de croissance historiques et en calculant des estimations optimales des budgets de calcul pour les prévisions futures. Taille de l'ensemble de données.
Avant cela, ils ont collecté des données sur les tendances des entrées d'apprentissage automatique, y compris certaines données de formation, et ont également étudié la croissance de l'utilisation des données en estimant le stock total de données non étiquetées disponibles sur Internet au cours des prochaines décennies.
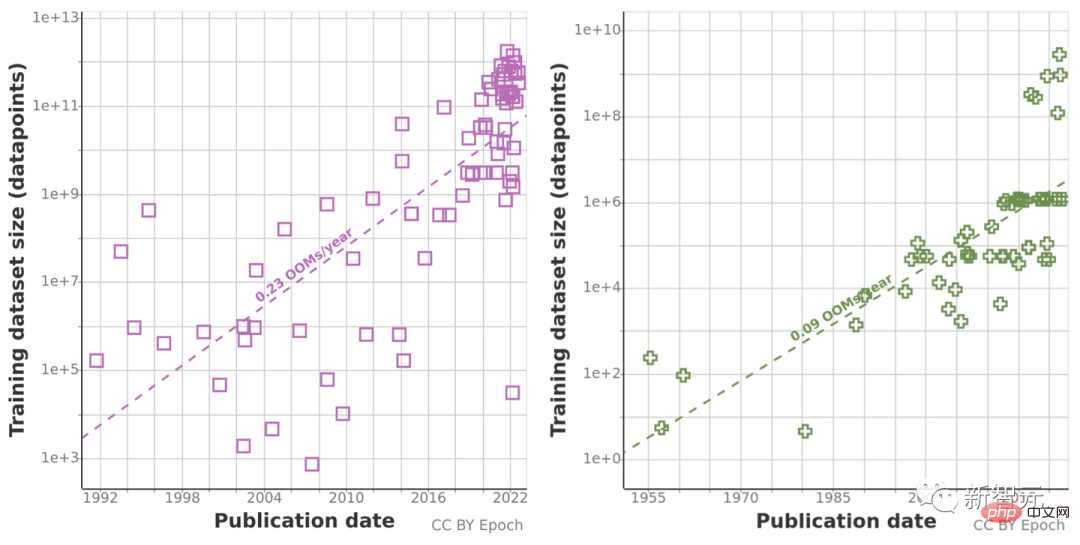
Étant donné que les tendances de prédiction historiques peuvent être « trompeuses » en raison de la croissance anormale du volume de calcul au cours de la dernière décennie, l'équipe de recherche a également utilisé la loi d'échelle de Chinchilla pour estimer la taille de l'ensemble de données au cours des prochaines années afin de améliorer la précision des résultats de calcul du sexe.
En fin de compte, les chercheurs ont utilisé une série de modèles probabilistes pour estimer l'inventaire total des données de langue anglaise et d'image au cours des prochaines années et ont comparé les prédictions de la taille de l'ensemble de données d'entraînement et l'inventaire total des données. ci-dessous.
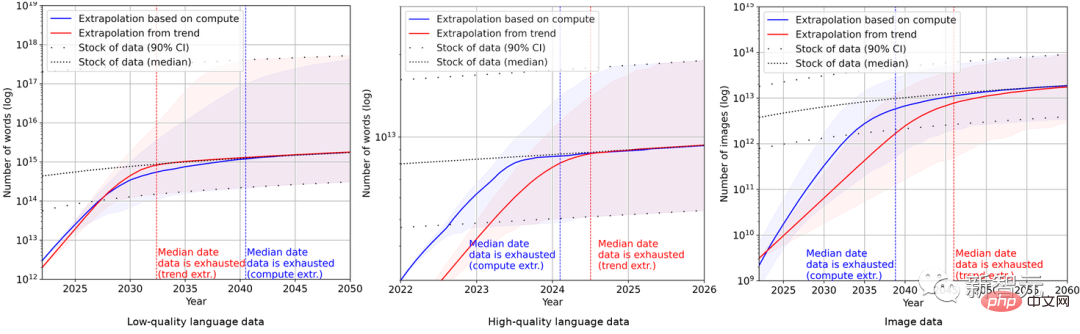
Cela montre que le taux de croissance de l'ensemble de données sera beaucoup plus rapide que le stock de données.
Par conséquent, si la tendance actuelle se poursuit, il sera inévitable que le stock de données soit épuisé. Le tableau ci-dessous montre le nombre médian d’années jusqu’à l’épuisement à chaque intersection de la courbe de prévision.
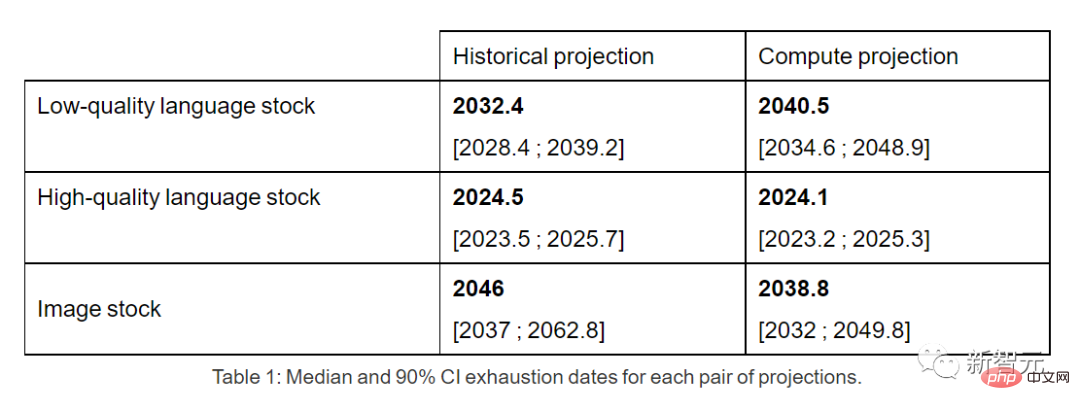
Les inventaires de données linguistiques de haute qualité pourraient être épuisés d'ici 2026 au plus tôt.
En revanche, les données linguistiques et les données d’images de mauvaise qualité s’en sortent légèrement mieux : les premières seront épuisées entre 2030 et 2050, et les secondes entre 2030 et 2060.
À la fin de l'article, l'équipe de recherche a conclu que si l'efficacité des données n'est pas significativement améliorée ou si de nouvelles sources de données sont disponibles, les modèles d'apprentissage automatique qui s'appuient actuellement sur d'énormes ensembles de données en constante expansion sont probables. avoir une tendance à la croissance va ralentir.
Internautes : C'est irrationnel de s'inquiéter, Efficient Zero le saura
Cependant, dans la zone de commentaires de cet article, la plupart des internautes Je pense qu'il est irrationnel de s'inquiéter de l'auteur.
Sur Reddit, un internaute nommé ktpr a déclaré :
"A quoi sert l'auto-supervision apprentissage ? Qu'est-ce qui ne va pas ? Si la tâche est bien spécifiée, elle peut même être combinée pour augmenter la taille de l'ensemble de données. Les internautes étaient encore plus méchants. Il a dit sans détour :
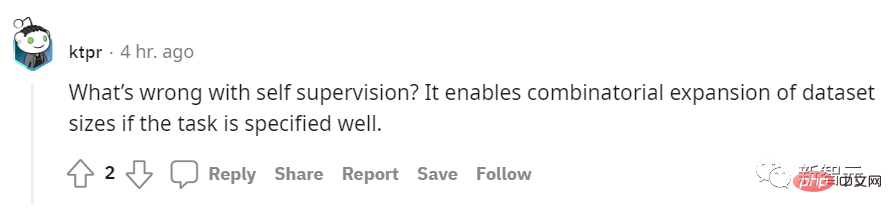 "Vous ne comprenez même pas Efficient Zero ? Je pense que l'auteur a sérieusement perdu le contact avec son temps." #
"Vous ne comprenez même pas Efficient Zero ? Je pense que l'auteur a sérieusement perdu le contact avec son temps." #
Efficient Zero est un algorithme d'apprentissage par renforcement capable d'échantillonner efficacement, proposé par le Dr Gao Yang de l'Université Tsinghua.
Dans le cas d'un volume de données limité, Efficient Zero résout dans une certaine mesure le problème de performance de l'apprentissage par renforcement et a été vérifié sur l'Atari Game, un benchmark de test universel pour les algorithmes.
Sur le blog de l'équipe d'auteurs de ce journal, même eux-mêmes ont dit franchement :
# 🎜🎜#"Toutes nos conclusions sont basées sur l'hypothèse irréaliste selon laquelle les tendances actuelles en matière d'utilisation et de production de données d'apprentissage automatique se poursuivront et qu'il n'y aura pas d'amélioration significative de l'efficacité des données." #
"Un modèle plus fiable devrait prendre en compte l'amélioration de l'efficacité des données d'apprentissage automatique, l'utilisation de données synthétiques et d'autres facteurs algorithmiques et économiques." 🎜#
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Comment définir le niveau de journal Debian Apache
Apr 13, 2025 am 08:33 AM
Comment définir le niveau de journal Debian Apache
Apr 13, 2025 am 08:33 AM
Cet article décrit comment ajuster le niveau de journalisation du serveur Apacheweb dans le système Debian. En modifiant le fichier de configuration, vous pouvez contrôler le niveau verbeux des informations de journal enregistrées par Apache. Méthode 1: Modifiez le fichier de configuration principal pour localiser le fichier de configuration: le fichier de configuration d'Apache2.x est généralement situé dans le répertoire / etc / apache2 /. Le nom de fichier peut être apache2.conf ou httpd.conf, selon votre méthode d'installation. Modifier le fichier de configuration: Ouvrez le fichier de configuration avec les autorisations racine à l'aide d'un éditeur de texte (comme Nano): Sutonano / etc / apache2 / apache2.conf
 Comment optimiser les performances de Debian Readdir
Apr 13, 2025 am 08:48 AM
Comment optimiser les performances de Debian Readdir
Apr 13, 2025 am 08:48 AM
Dans Debian Systems, les appels du système ReadDir sont utilisés pour lire le contenu des répertoires. Si ses performances ne sont pas bonnes, essayez la stratégie d'optimisation suivante: simplifiez le nombre de fichiers d'annuaire: divisez les grands répertoires en plusieurs petits répertoires autant que possible, en réduisant le nombre d'éléments traités par appel ReadDir. Activer la mise en cache de contenu du répertoire: construire un mécanisme de cache, mettre à jour le cache régulièrement ou lorsque le contenu du répertoire change et réduire les appels fréquents à Readdir. Les caches de mémoire (telles que Memcached ou Redis) ou les caches locales (telles que les fichiers ou les bases de données) peuvent être prises en compte. Adoptez une structure de données efficace: si vous implémentez vous-même la traversée du répertoire, sélectionnez des structures de données plus efficaces (telles que les tables de hachage au lieu de la recherche linéaire) pour stocker et accéder aux informations du répertoire
 Comment implémenter le tri des fichiers par Debian Readdir
Apr 13, 2025 am 09:06 AM
Comment implémenter le tri des fichiers par Debian Readdir
Apr 13, 2025 am 09:06 AM
Dans Debian Systems, la fonction ReadDir est utilisée pour lire le contenu du répertoire, mais l'ordre dans lequel il revient n'est pas prédéfini. Pour trier les fichiers dans un répertoire, vous devez d'abord lire tous les fichiers, puis les trier à l'aide de la fonction QSORT. Le code suivant montre comment trier les fichiers de répertoire à l'aide de ReadDir et QSort dans Debian System: # include # include # include # include # include // Fonction de comparaison personnalisée, utilisée pour qsortintCompare (constvoid * a, constvoid * b) {returnstrcmp (* (
 Conseils de configuration du pare-feu Debian Mail Server
Apr 13, 2025 am 11:42 AM
Conseils de configuration du pare-feu Debian Mail Server
Apr 13, 2025 am 11:42 AM
La configuration du pare-feu d'un serveur de courrier Debian est une étape importante pour assurer la sécurité du serveur. Voici plusieurs méthodes de configuration de pare-feu couramment utilisées, y compris l'utilisation d'iptables et de pare-feu. Utilisez les iptables pour configurer le pare-feu pour installer iptables (sinon déjà installé): Sudoapt-getUpDaSuDoapt-getinstalliptableView Règles actuelles iptables: Sudoiptable-L Configuration
 Méthode d'installation du certificat de Debian Mail Server SSL
Apr 13, 2025 am 11:39 AM
Méthode d'installation du certificat de Debian Mail Server SSL
Apr 13, 2025 am 11:39 AM
Les étapes pour installer un certificat SSL sur le serveur de messagerie Debian sont les suivantes: 1. Installez d'abord la boîte à outils OpenSSL, assurez-vous que la boîte à outils OpenSSL est déjà installée sur votre système. Si ce n'est pas installé, vous pouvez utiliser la commande suivante pour installer: Sudoapt-getUpDaSuDoapt-getInstallOpenSSL2. Générer la clé privée et la demande de certificat Suivant, utilisez OpenSSL pour générer une clé privée RSA 2048 bits et une demande de certificat (RSE): OpenSS
 Comment Debian Readdir s'intègre à d'autres outils
Apr 13, 2025 am 09:42 AM
Comment Debian Readdir s'intègre à d'autres outils
Apr 13, 2025 am 09:42 AM
La fonction ReadDir dans le système Debian est un appel système utilisé pour lire le contenu des répertoires et est souvent utilisé dans la programmation C. Cet article expliquera comment intégrer ReadDir avec d'autres outils pour améliorer sa fonctionnalité. Méthode 1: combinant d'abord le programme de langue C et le pipeline, écrivez un programme C pour appeler la fonction readdir et sortir le résultat: # include # include # include # includeIntmain (intargc, char * argv []) {dir * dir; structDirent * entrée; if (argc! = 2) {
 Comment Debian OpenSSL empêche les attaques de l'homme au milieu
Apr 13, 2025 am 10:30 AM
Comment Debian OpenSSL empêche les attaques de l'homme au milieu
Apr 13, 2025 am 10:30 AM
Dans Debian Systems, OpenSSL est une bibliothèque importante pour le chiffrement, le décryptage et la gestion des certificats. Pour empêcher une attaque d'homme dans le milieu (MITM), les mesures suivantes peuvent être prises: utilisez HTTPS: assurez-vous que toutes les demandes de réseau utilisent le protocole HTTPS au lieu de HTTP. HTTPS utilise TLS (Protocole de sécurité de la couche de transport) pour chiffrer les données de communication pour garantir que les données ne sont pas volées ou falsifiées pendant la transmission. Vérifiez le certificat de serveur: vérifiez manuellement le certificat de serveur sur le client pour vous assurer qu'il est digne de confiance. Le serveur peut être vérifié manuellement via la méthode du délégué d'URLSession
 Comment faire Debian Hadoop Log Management
Apr 13, 2025 am 10:45 AM
Comment faire Debian Hadoop Log Management
Apr 13, 2025 am 10:45 AM
Gérer les journaux Hadoop sur Debian, vous pouvez suivre les étapes et les meilleures pratiques suivantes: l'agrégation de journal Activer l'agrégation de journaux: définir yarn.log-aggregation-inable à true dans le fichier yarn-site.xml pour activer l'agrégation de journaux. Configurer la stratégie de rétention du journal: Définissez Yarn.log-agregation.retain-secondes pour définir le temps de rétention du journal, tel que 172800 secondes (2 jours). Spécifiez le chemin de stockage des journaux: via yarn.n
