
 Périphériques technologiques
IA
'En utilisant la technologie de diffusion stable pour reproduire des images, des recherches connexes ont été acceptées par la conférence CVPR'
Périphériques technologiques
IA
'En utilisant la technologie de diffusion stable pour reproduire des images, des recherches connexes ont été acceptées par la conférence CVPR'
'En utilisant la technologie de diffusion stable pour reproduire des images, des recherches connexes ont été acceptées par la conférence CVPR'

Et si l'intelligence artificielle pouvait lire votre imagination et transformer les images de votre esprit en réalité ?

Bien que cela semble un peu cyberpunk. Mais un article récemment publié a fait sensation dans le cercle de l’IA.
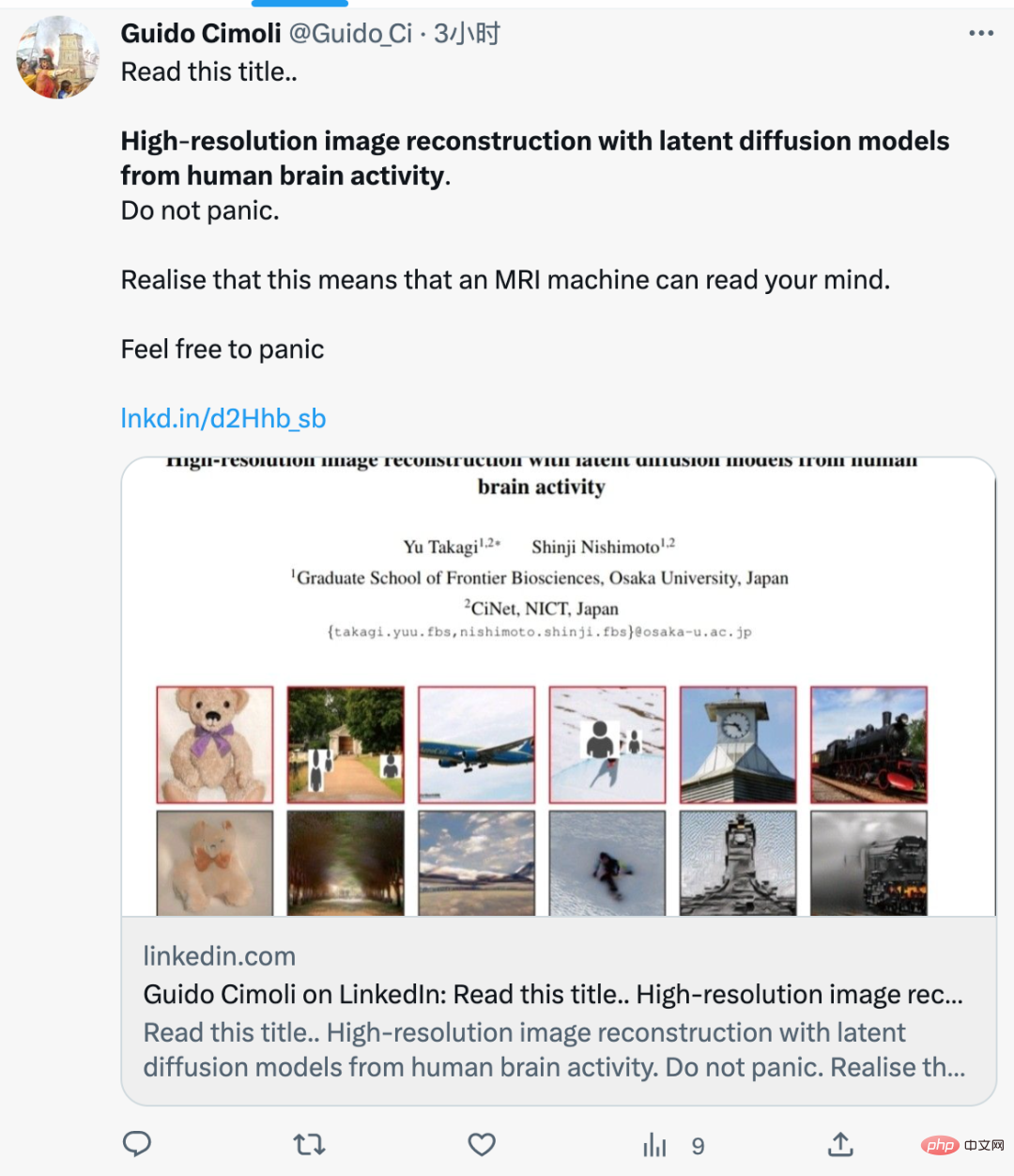
Cet article a révélé qu'ils utilisaient la méthode de diffusion stable, élevée, récemment très populaire. -des images de haute résolution et de haute précision de l’activité cérébrale peuvent être reconstruites. Les auteurs ont écrit que contrairement aux études précédentes, ils n’avaient pas besoin de former ou d’affiner un modèle d’intelligence artificielle pour créer ces images.

- # 🎜 🎜#Adresse papier : https://www.biorxiv.org/content/10.1101/2022.11.18.517004v2.full.pdf #🎜🎜 #
- Adresse de la page Web : https://sites.google.com/view/stablediffusion-with-brain/
Dans cette étude, les auteurs ont utilisé la diffusion stable pour reconstruire des images d'activité cérébrale humaine obtenues par imagerie par résonance magnétique fonctionnelle (IRMf). L'auteur a également déclaré qu'il est également utile de comprendre le mécanisme du modèle de diffusion implicite en étudiant différentes composantes des fonctions liées au cerveau (comme le vecteur latent de l'image Z, etc.).
Ce papier a également été accepté par le CVPR 2023.
Les principales contributions de cette étude comprennent :
- Prouver que son cadre simple peut be Reconstruire des images haute résolution (512 × 512) à partir de l'activité cérébrale avec une haute fidélité sémantique sans avoir besoin de former ou d'affiner des modèles génératifs profonds complexes, comme indiqué ci-dessous ;
- # 🎜 🎜#Cette étude explique quantitativement chaque composant du LDM d'un point de vue neuroscientifique en cartographiant des composants spécifiques à différentes régions du cerveau
- L'étude explique objectivement comment le texte en image ; Le processus de conversion mis en œuvre par LDM combine les informations sémantiques exprimées par le texte conditionnel tout en conservant l'apparence de l'image originale.
- Aperçu de la méthode
La méthodologie globale de l'étude est présentée dans la figure 2 ci-dessous. La figure 2 (en haut) est un diagramme schématique du LDM utilisé dans cette étude, où ε représente l'encodeur d'image, D représente le décodeur d'image et τ représente l'encodeur de texte (CLIP).
La figure 2 (au milieu) est un diagramme schématique de l'analyse de décodage de cette étude. Nous avons décodé la représentation sous-jacente de l'image présentée (z) et du texte associé c à partir de signaux IRMf dans le cortex visuel précoce (bleu) et avancé (jaune), respectivement. Ces représentations latentes sont utilisées comme entrée pour générer l'image reconstruite X_zc.
La figure 2 (en bas) est un diagramme schématique de l'analyse de codage de cette étude. Nous avons construit des modèles de codage pour prédire les signaux IRMf de différents composants du LDM, notamment z, c et z_c.
Results
Jetons un coup d'œil aux résultats de reconstruction visuelle de cette étude.
Décodage
La figure 3 ci-dessous montre les résultats de la reconstruction visuelle d'un sujet (subj01). Nous avons généré cinq images pour chaque image de test et sélectionné l'image avec le PSM le plus élevé. D’une part, l’image reconstruite en utilisant uniquement z est visuellement cohérente avec l’image originale mais ne parvient pas à capturer son contenu sémantique. D'un autre côté, les images reconstruites avec seulement c produisent des images avec une haute fidélité sémantique mais sont visuellement incohérentes. Enfin, l’utilisation d’images reconstruites z_c peut produire des images haute résolution avec une haute fidélité sémantique. 
La figure 4 montre les reconstructions de tous les testeurs de la même image (toutes les images générées avec z_c). Dans l’ensemble, la qualité de la reconstruction parmi les testeurs était stable et précise.

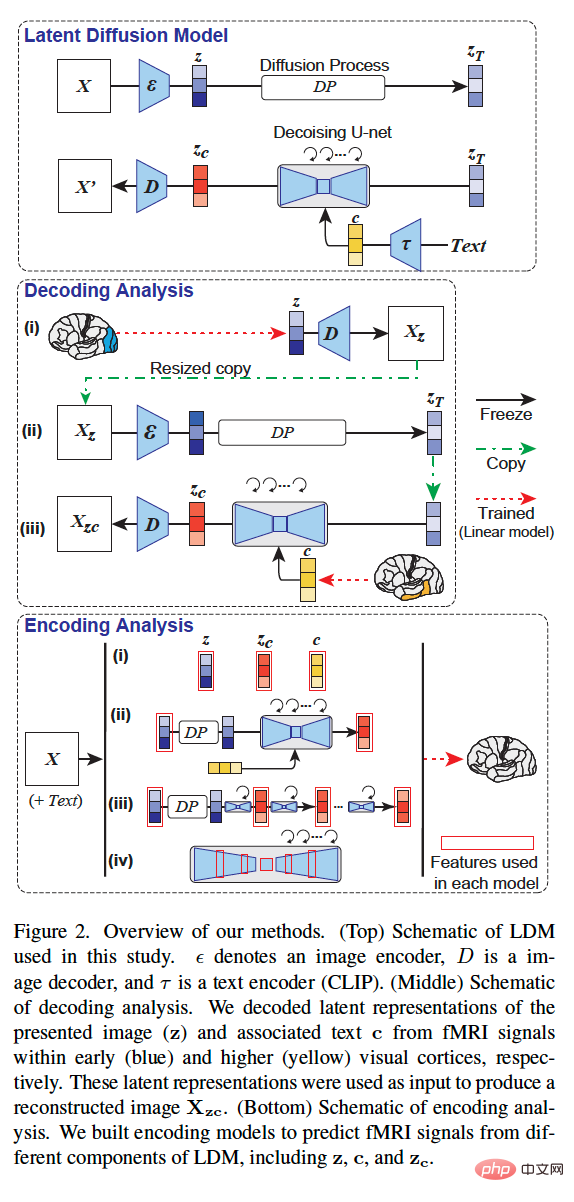
La figure 5 est le résultat de l'évaluation quantitative : 6 montre le modèle de codage pour trois types de LDM - Précision de prédiction liée aux images latentes : z, l'image latente de l'image originale ; c, l'image latente de l'annotation de texte de l'image et z_c, la représentation d'image latente bruyante de z après le processus de rétrodiffusion d'attention croisée avec c ; .
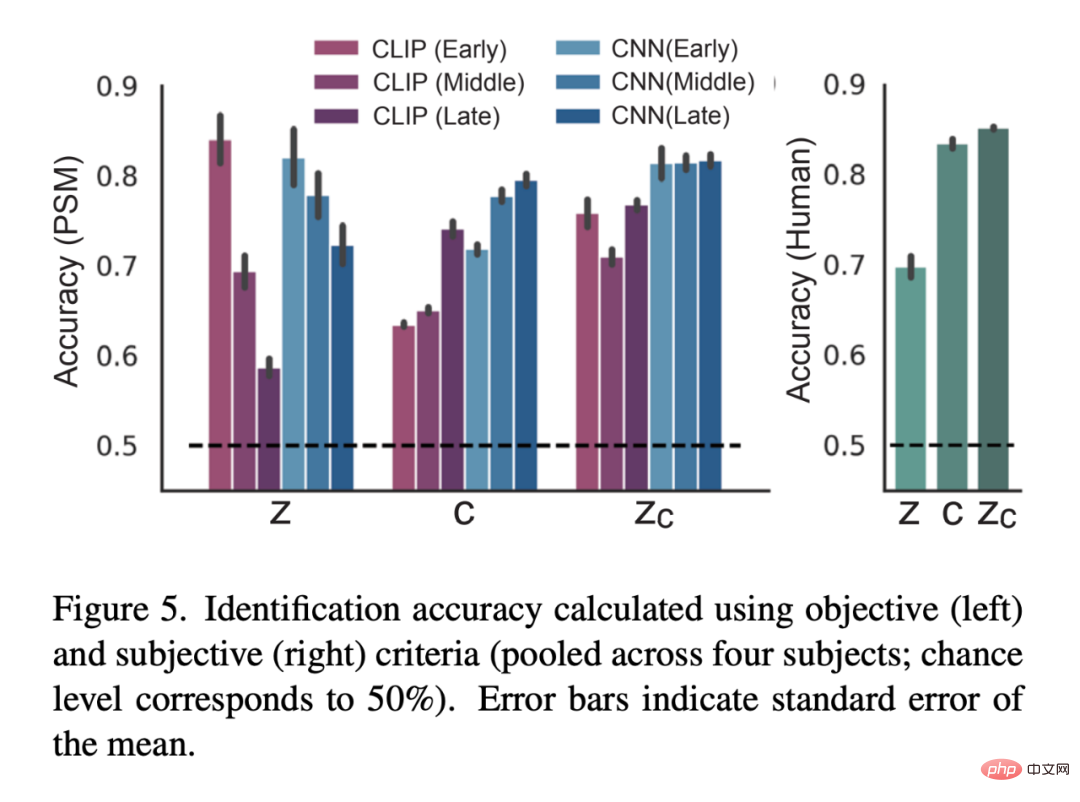
Comment la représentation sous-jacente du bruit ajouté change-t-elle au cours du processus itératif de débruitage ? La figure 8 montre que dans les premiers stades du processus de débruitage, le signal z domine la prédiction du signal IRMf. Au stade intermédiaire du processus de débruitage, z_c prédit bien mieux que z l’activité au sein du cortex visuel élevé, indiquant que la majeure partie du contenu sémantique émerge à ce stade. Les résultats montrent comment LDM affine et génère des images à partir du bruit.
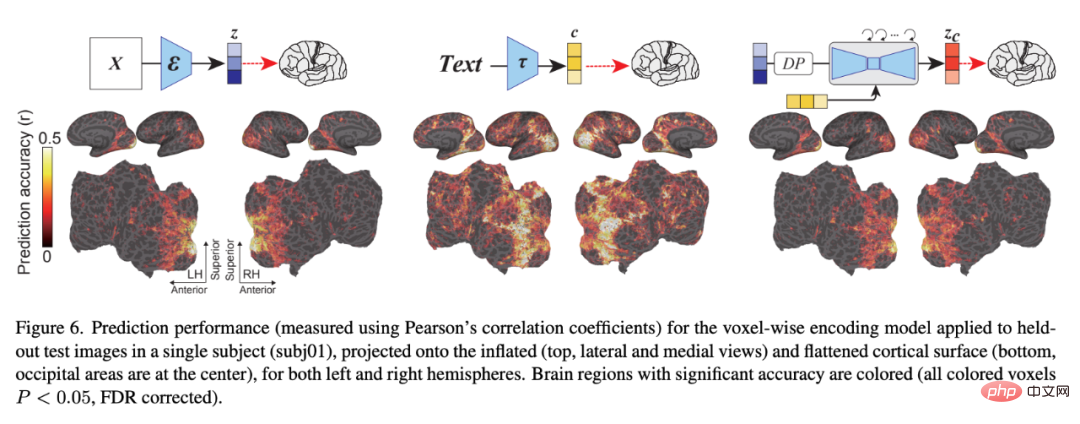
Enfin, les chercheurs ont exploré les informations traitées par chaque couche d'U-Net. La figure 9 montre les résultats des différentes étapes du processus de débruitage (précoce, intermédiaire, tardif) et le modèle de codage des différentes couches d'U-Net. Dans les premiers stades du processus de débruitage, la couche de goulot d'étranglement (orange) d'U-Net produit les performances de prédiction les plus élevées sur l'ensemble du cortex. Cependant, à mesure que le débruitage progresse, les premières couches d'U-Net (bleu) prédisent l'activité au sein du cortex visuel précoce, tandis que les couches de goulot d'étranglement passent à un pouvoir prédictif supérieur pour le cortex visuel supérieur.

Pour plus de détails sur la recherche, veuillez consulter l'article original.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Comment télécharger l'image de fond d'écran Windows Spotlight sur PC
Aug 23, 2023 pm 02:06 PM
Comment télécharger l'image de fond d'écran Windows Spotlight sur PC
Aug 23, 2023 pm 02:06 PM
Les fenêtres ne négligent jamais l’esthétique. Des champs verts bucoliques de XP au design tourbillonnant bleu de Windows 11, les fonds d’écran par défaut sont une source de plaisir pour les utilisateurs depuis des années. Avec Windows Spotlight, vous avez désormais un accès direct chaque jour à des images magnifiques et impressionnantes pour votre écran de verrouillage et votre fond d’écran. Malheureusement, ces images ne traînent pas. Si vous êtes tombé amoureux de l'une des images phares de Windows, vous voudrez savoir comment les télécharger afin de pouvoir les conserver comme arrière-plan pendant un certain temps. Voici tout ce que vous devez savoir. Qu’est-ce que WindowsSpotlight ? Window Spotlight est un programme de mise à jour automatique du fond d'écran disponible dans Personnalisation et dans l'application Paramètres.
 Une plongée approfondie dans les modèles, les données et les frameworks : une revue exhaustive de 54 pages de grands modèles de langage efficaces
Jan 14, 2024 pm 07:48 PM
Une plongée approfondie dans les modèles, les données et les frameworks : une revue exhaustive de 54 pages de grands modèles de langage efficaces
Jan 14, 2024 pm 07:48 PM
Les modèles linguistiques à grande échelle (LLM) ont démontré des capacités convaincantes dans de nombreuses tâches importantes, notamment la compréhension du langage naturel, la génération de langages et le raisonnement complexe, et ont eu un impact profond sur la société. Cependant, ces capacités exceptionnelles nécessitent des ressources de formation importantes (illustrées dans l’image de gauche) et de longs temps d’inférence (illustrés dans l’image de droite). Les chercheurs doivent donc développer des moyens techniques efficaces pour résoudre leurs problèmes d’efficacité. De plus, comme on peut le voir sur le côté droit de la figure, certains LLM (LanguageModels) efficaces tels que Mistral-7B ont été utilisés avec succès dans la conception et le déploiement de LLM. Ces LLM efficaces peuvent réduire considérablement la mémoire d'inférence tout en conservant une précision similaire à celle du LLaMA1-33B
 Comment utiliser la technologie de segmentation sémantique d'images en Python ?
Jun 06, 2023 am 08:03 AM
Comment utiliser la technologie de segmentation sémantique d'images en Python ?
Jun 06, 2023 am 08:03 AM
Avec le développement continu de la technologie de l’intelligence artificielle, la technologie de segmentation sémantique des images est devenue une direction de recherche populaire dans le domaine de l’analyse d’images. Dans la segmentation sémantique d'image, nous segmentons différentes zones d'une image et classons chaque zone pour obtenir une compréhension globale de l'image. Python est un langage de programmation bien connu. Ses puissantes capacités d'analyse et de visualisation de données en font le premier choix dans le domaine de la recherche sur les technologies d'intelligence artificielle. Cet article expliquera comment utiliser la technologie de segmentation sémantique d'images en Python. 1. Les connaissances préalables s’approfondissent
 Crushing H100, le GPU nouvelle génération de Nvidia se dévoile ! La première conception de module multipuce 3 nm, dévoilée en 2024
Sep 30, 2023 pm 12:49 PM
Crushing H100, le GPU nouvelle génération de Nvidia se dévoile ! La première conception de module multipuce 3 nm, dévoilée en 2024
Sep 30, 2023 pm 12:49 PM
Processus 3 nm, les performances dépassent le H100 ! Récemment, le média étranger DigiTimes a annoncé que Nvidia développait le GPU de nouvelle génération, le B100, dont le nom de code est "Blackwell". Il s'agirait d'un produit destiné aux applications d'intelligence artificielle (IA) et de calcul haute performance (HPC). , le B100 utilisera le processus de traitement 3 nm de TSMC, ainsi qu'une conception de module multi-puces (MCM) plus complexe, et apparaîtra au quatrième trimestre 2024. Pour Nvidia, qui monopolise plus de 80 % du marché des GPU d’intelligence artificielle, il peut utiliser le B100 pour frapper pendant que le fer est chaud et attaquer davantage des challengers comme AMD et Intel dans cette vague de déploiement d’IA. Selon les estimations de NVIDIA, d'ici 2027, la valeur de production de ce domaine devrait atteindre environ
 La revue la plus complète des grands modèles multimodaux est ici ! 7 chercheurs Microsoft ont coopéré vigoureusement, 5 thèmes majeurs, 119 pages de document
Sep 25, 2023 pm 04:49 PM
La revue la plus complète des grands modèles multimodaux est ici ! 7 chercheurs Microsoft ont coopéré vigoureusement, 5 thèmes majeurs, 119 pages de document
Sep 25, 2023 pm 04:49 PM
La revue la plus complète des grands modèles multimodaux est ici ! Écrit par 7 chercheurs chinois de Microsoft, il compte 119 pages - il part de deux types d'orientations de recherche multimodales sur grands modèles qui ont été complétées et sont toujours à l'avant-garde, et résume de manière exhaustive cinq sujets de recherche spécifiques : la compréhension visuelle et la génération visuelle. L'agent multimodal grand modèle multimodal supporté par le modèle visuel unifié LLM se concentre sur un phénomène : le modèle de base multimodal est passé de spécialisé à universel. Ps. C'est pourquoi l'auteur a directement dessiné une image de Doraemon au début de l'article. Qui devrait lire cette critique (rapport) ? Dans les mots originaux de Microsoft : tant que vous souhaitez apprendre les connaissances de base et les derniers progrès des modèles de base multimodaux, que vous soyez un chercheur professionnel ou un étudiant, ce contenu est très approprié pour vous réunir.
 iOS 17 : Comment utiliser le recadrage en un clic des photos
Sep 20, 2023 pm 08:45 PM
iOS 17 : Comment utiliser le recadrage en un clic des photos
Sep 20, 2023 pm 08:45 PM
Avec l'application iOS 17 Photos, Apple facilite le recadrage des photos selon vos spécifications. Lisez la suite pour savoir comment. Auparavant, dans iOS 16, le recadrage d'une image dans l'application Photos impliquait plusieurs étapes : appuyez sur l'interface d'édition, sélectionnez l'outil de recadrage, puis ajustez le recadrage à l'aide d'un geste de pincement pour zoomer ou en faisant glisser les coins de l'outil de recadrage. Dans iOS 17, Apple a heureusement simplifié ce processus afin que lorsque vous zoomez sur une photo sélectionnée dans votre bibliothèque Photos, un nouveau bouton Recadrer apparaisse automatiquement dans le coin supérieur droit de l'écran. En cliquant dessus, l'interface de recadrage complète s'affichera avec le niveau de zoom de votre choix. Vous pourrez ainsi recadrer la partie de l'image que vous aimez, faire pivoter l'image, inverser l'image, appliquer un rapport d'écran ou utiliser des marqueurs.
 Comment redimensionner par lots des images à l'aide de PowerToys sous Windows
Aug 23, 2023 pm 07:49 PM
Comment redimensionner par lots des images à l'aide de PowerToys sous Windows
Aug 23, 2023 pm 07:49 PM
Ceux qui doivent travailler quotidiennement avec des fichiers image doivent souvent les redimensionner pour les adapter aux besoins de leurs projets et de leurs tâches. Cependant, si vous avez trop d’images à traiter, les redimensionner individuellement peut prendre beaucoup de temps et d’efforts. Dans ce cas, un outil comme PowerToys peut s'avérer utile, entre autres, pour redimensionner par lots des fichiers image à l'aide de son utilitaire de redimensionnement d'image. Voici comment configurer vos paramètres de redimensionnement d'image et commencer le redimensionnement par lots d'images avec PowerToys. Comment redimensionner des images par lots avec PowerToys PowerToys est un programme tout-en-un doté d'une variété d'utilitaires et de fonctionnalités pour vous aider à accélérer vos tâches quotidiennes. L'un de ses utilitaires est les images
 Adaptateur I2V de la communauté SD : aucune configuration requise, plug and play, parfaitement compatible avec le plug-in vidéo Tusheng
Jan 15, 2024 pm 07:48 PM
Adaptateur I2V de la communauté SD : aucune configuration requise, plug and play, parfaitement compatible avec le plug-in vidéo Tusheng
Jan 15, 2024 pm 07:48 PM
La tâche de génération d'image en vidéo (I2V) est un défi dans le domaine de la vision par ordinateur qui vise à convertir des images statiques en vidéos dynamiques. La difficulté de cette tâche est d'extraire et de générer des informations dynamiques dans la dimension temporelle à partir d'une seule image tout en conservant l'authenticité et la cohérence visuelle du contenu de l'image. Les méthodes I2V existantes nécessitent souvent des architectures de modèles complexes et de grandes quantités de données de formation pour atteindre cet objectif. Récemment, un nouveau résultat de recherche « I2V-Adapter : AGeneralImage-to-VideoAdapter for VideoDiffusionModels » dirigé par Kuaishou a été publié. Cette recherche introduit une méthode innovante de conversion image-vidéo et propose un module adaptateur léger, c'est-à-dire
