

sql中 in , not in , exists , not exists效率分析_MySQL

in和exists执行时,in是先执行子查询中的查询,然后再执行主查询。而exists查询它是先执行主查询,即外层表的查询,然后再执行子查询。
exists 和 in 在执行时效率单从执行时间来说差不多,exists要稍微优于in。在使用时一般应该是用exists而不用in
如果子查询得出的结果集记录较少,主查询中的表较大且又有索引时应该用in,反之如果外层的主查询记录较少,子查询中的表大,又有索引时使用exists。IN时不对NULL进行处理。
not exists 和 not in 比较时,not exists 的效率比较高。
为了说明测试结果,我把emp1表中的数据到了315392条。emp2中删除只有2条件数据。测试的依据是执行的时间来说明的。
emp1中的数据记录情况。
SQL> select count(*) from emp1;
COUNT(*)
----------
315392
emp2中的数据记录情况:
SQL> select count(*) from emp2;
COUNT(*)
----------
2
1、 执行exists查询,要求在emp1中查询出所有存在于emp2的数据总数
SQL> select count(*) from emp1 where exists ( select null from emp2 where emp1.ename = emp2.ename);
COUNT(*)
----------
45056
执行次数十次,最大的一次为0.125S
2、 使用not exists查询出所在不在emp2中的数据总数
SQL> select count(*) from emp1 where not exists ( select null from emp2 where emp1.ename = emp2.ename);
COUNT(*)
----------
270336
执行次数十次,最大的一次为0.141S
3、执行in 查询,要求在emp1中查询出所有存在于emp2的数据总数
SQL> select count(*) from emp1 where ename in ( select ename from emp2);
COUNT(*)
----------
45056
执行十次,最大的一次为0.141S
4、使用not in查询出所在不在emp2中的数据总数
SQL> select count(*) from emp1 where ename not in ( select ename from emp2 );
COUNT(*)
----------
270336
执行十次,最长一次为0.328S
5、使用in查询,调用外层与子查询的位置,要求查询出存在于emp2中,且存在于emp1中的数据记录数
SQL> select count(*) from emp2 where ename in (select ename from emp1 );
COUNT(*)
----------
2
执行次数十次,最长的一次为0.047S
6、使用exists查询,调用外层与子查询的位置,要求查询出存在于emp2中,且存在于emp1中的数据记录数
SQL> select count(*) from emp2 where ename in (select ename from emp1 );
COUNT(*)
----------
2
执行次数十次,最长的一次为0.047S
综上所述:在使用in 和 exists时,个人觉得,效率差不多。而在not in 和 not exists比较时,not exists的效率要比not in的效率要高。
当使用in时,子查询where条件不受外层的影响,自动优化会转成exist语句,它的效率和exist一样。(没有验证)
如select * from t1 where f1 in (select f1 from t2 where t2.fx='x') 这时,认为in 和 exists效率一样。
IN适合于外表大而内表小的情况;EXISTS适合于外表小而内表大的情况。

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

Video Face Swap
Échangez les visages dans n'importe quelle vidéo sans effort grâce à notre outil d'échange de visage AI entièrement gratuit !

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)
Sujets chauds



 Comment activer ou désactiver le mode productivité pour une application ou un processus dans Windows 11
Apr 14, 2023 pm 09:46 PM
Comment activer ou désactiver le mode productivité pour une application ou un processus dans Windows 11
Apr 14, 2023 pm 09:46 PM
Le nouveau gestionnaire de tâches de Windows 11 22H2 est une aubaine pour les utilisateurs expérimentés. Il offre désormais une meilleure expérience d'interface utilisateur avec des données supplémentaires pour garder un œil sur vos processus, tâches, services et composants matériels en cours d'exécution. Si vous utilisez le nouveau Gestionnaire des tâches, vous avez peut-être remarqué le nouveau mode de productivité. qu'est-ce que c'est? Cela contribue-t-il à améliorer les performances des systèmes Windows 11 ? Découvrons-le ! Qu’est-ce que le mode productivité dans Windows 11 ? Le mode productivité est l'une des tâches du Gestionnaire des tâches
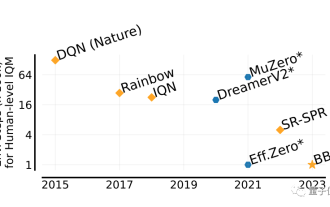 Il peut surpasser les humains en deux heures ! Le dernier speedrun IA de DeepMind exécute 26 jeux Atari
Jul 03, 2023 pm 08:57 PM
Il peut surpasser les humains en deux heures ! Le dernier speedrun IA de DeepMind exécute 26 jeux Atari
Jul 03, 2023 pm 08:57 PM
L’agent IA de DeepMind est de nouveau au travail ! Attention, ce type nommé BBF a maîtrisé 26 jeux Atari en seulement 2 heures. Son efficacité est équivalente à celle des humains, surpassant tous ses prédécesseurs. Vous savez, les agents d'IA ont toujours été efficaces pour résoudre des problèmes grâce à l'apprentissage par renforcement, mais le plus gros problème est que cette méthode est très inefficace et nécessite beaucoup de temps à explorer. Picture La avancée apportée par BBF se situe en termes d'efficacité. Pas étonnant que son nom complet puisse être appelé Bigger, Better ou Faster. De plus, il peut effectuer une formation sur une seule carte et les besoins en puissance de calcul sont également considérablement réduits. BBF a été proposé conjointement par Google DeepMind et l'Université de Montréal, et les données et le code sont actuellement open source. L'humain le plus élevé possible
 Guide pratique de développement à distance PyCharm : améliorer l'efficacité du développement
Feb 23, 2024 pm 01:30 PM
Guide pratique de développement à distance PyCharm : améliorer l'efficacité du développement
Feb 23, 2024 pm 01:30 PM
PyCharm est un puissant environnement de développement intégré (IDE) Python largement utilisé par les développeurs Python pour l'écriture de code, le débogage et la gestion de projets. Dans le processus de développement réel, la plupart des développeurs seront confrontés à différents problèmes, tels que comment améliorer l'efficacité du développement, comment collaborer avec les membres de l'équipe sur le développement, etc. Cet article présentera un guide pratique du développement à distance de PyCharm pour aider les développeurs à mieux utiliser PyCharm pour le développement à distance et à améliorer l'efficacité du travail. 1. Travail de préparation dans PyCh
 Déploiement privé de Stable Diffusion pour jouer avec le dessin IA
Mar 12, 2024 pm 05:49 PM
Déploiement privé de Stable Diffusion pour jouer avec le dessin IA
Mar 12, 2024 pm 05:49 PM
StableDiffusion est un modèle d'apprentissage profond open source. Sa fonction principale est de générer des images de haute qualité via des descriptions textuelles et prend en charge des fonctions telles que la génération de graphiques, la fusion de modèles et la formation de modèles. L'interface de fonctionnement du modèle est visible dans la figure ci-dessous. Comment générer une image. Ce qui suit est une introduction au processus de création d'une image d'un cerf buvant de l'eau. Lors de la génération d'une image, elle est divisée en mots d'invite et en mots d'invite négatifs. Lors de la saisie des mots d'invite, vous devez la décrire. clairement et essayez de décrire la scène, l’objet, le style et la couleur que vous souhaitez en détail. Par exemple, au lieu de simplement dire « le cerf boit de l'eau », il est écrit « un ruisseau, à côté d'arbres denses, et il y a des cerfs qui boivent de l'eau à côté du ruisseau ». Les mots d'invite négatifs vont dans la direction opposée. aucun bâtiment, aucune personne, aucun pont, aucune clôture et une description trop vague peuvent conduire à des résultats inexacts.
 Compétences en développement Java révélées : optimisation de l'efficacité du traitement des transactions de base de données
Nov 20, 2023 pm 03:13 PM
Compétences en développement Java révélées : optimisation de l'efficacité du traitement des transactions de base de données
Nov 20, 2023 pm 03:13 PM
Avec le développement rapide d’Internet, l’importance des bases de données est devenue de plus en plus importante. En tant que développeur Java, nous impliquons souvent des opérations de base de données. L'efficacité du traitement des transactions de base de données est directement liée aux performances et à la stabilité de l'ensemble du système. Cet article présentera certaines techniques couramment utilisées dans le développement Java pour optimiser l'efficacité du traitement des transactions de base de données afin d'aider les développeurs à améliorer les performances du système et la vitesse de réponse. Opérations d'insertion/mise à jour par lots Normalement, l'efficacité de l'insertion ou de la mise à jour d'un seul enregistrement dans la base de données en une seule fois est bien inférieure à celle des opérations par lots. Par conséquent, lors de l'exécution d'une insertion/mise à jour par lots
 Comment activer le mode d'économie d'énergie dans Microsoft Edge ?
Apr 20, 2023 pm 08:22 PM
Comment activer le mode d'économie d'énergie dans Microsoft Edge ?
Apr 20, 2023 pm 08:22 PM
Les navigateurs basés sur Chromium comme Edge utilisent beaucoup de ressources, mais vous pouvez activer le mode efficacité dans Microsoft Edge pour améliorer les performances. Le navigateur Web Microsoft Edge a parcouru un long chemin depuis ses humbles débuts. Récemment, Microsoft a ajouté un nouveau mode d'efficacité au navigateur, conçu pour améliorer les performances globales du navigateur sur PC. Le mode Efficacité permet de prolonger la durée de vie de la batterie et de réduire l’utilisation des ressources système. Par exemple, les navigateurs construits avec Chromium, tels que Google Chrome et Microsoft Edge, sont connus pour monopoliser les cycles de RAM et de processeur. Par conséquent, afin
 Maîtrisez Python pour améliorer l'efficacité du travail et la qualité de vie
Feb 18, 2024 pm 05:57 PM
Maîtrisez Python pour améliorer l'efficacité du travail et la qualité de vie
Feb 18, 2024 pm 05:57 PM
Titre : Python rend la vie plus pratique : maîtrisez ce langage pour améliorer l'efficacité du travail et la qualité de vie. En tant que langage de programmation puissant et facile à apprendre, Python devient de plus en plus populaire à l'ère numérique d'aujourd'hui. Non seulement pour écrire des programmes et effectuer des analyses de données, Python peut également jouer un rôle important dans notre vie quotidienne. La maîtrise de cette langue peut non seulement améliorer l'efficacité du travail, mais également améliorer la qualité de vie. Cet article utilisera des exemples de code spécifiques pour démontrer la large application de Python dans la vie et aider les lecteurs
 Masque de sous-réseau : rôle et impact sur l'efficacité de la communication réseau
Dec 26, 2023 pm 04:28 PM
Masque de sous-réseau : rôle et impact sur l'efficacité de la communication réseau
Dec 26, 2023 pm 04:28 PM
Le rôle du masque de sous-réseau et son impact sur l'efficacité de la communication réseau Introduction : Avec la popularité d'Internet, la communication réseau est devenue un élément indispensable de la société moderne. Dans le même temps, l'efficacité de la communication en réseau est également devenue l'un des centres d'attention des gens. Dans le processus de création et de gestion d'un réseau, le masque de sous-réseau est une option de configuration importante et basique, qui joue un rôle clé dans la communication réseau. Cet article présentera le rôle du masque de sous-réseau et son impact sur l'efficacité des communications réseau. 1. Définition et fonction du masque de sous-réseau Masque de sous-réseau (subnetmask)
