
 Périphériques technologiques
IA
Le jeu d'instructions open source affiné de Microsoft permet de développer une version domestique de GPT-4, prenant en charge la génération bilingue en chinois et en anglais.
Périphériques technologiques
IA
Le jeu d'instructions open source affiné de Microsoft permet de développer une version domestique de GPT-4, prenant en charge la génération bilingue en chinois et en anglais.
Le jeu d'instructions open source affiné de Microsoft permet de développer une version domestique de GPT-4, prenant en charge la génération bilingue en chinois et en anglais.

"L'instruction" est un facteur clé dans les progrès révolutionnaires du modèle ChatGPT, qui peut rendre le résultat du modèle de langage plus conforme aux "préférences humaines".
Mais l'annotation des instructions nécessite beaucoup de main d'œuvre Même avec des modèles de langage open source, il est difficile pour les établissements universitaires et les petites entreprises disposant de fonds insuffisants de former les leurs. ChatGPT .
Récemment, des chercheurs de Microsoft ont utilisé la technologie d'auto-instruction proposée précédemment, l'a essayée pour la première fois# 🎜🎜# Modèle GPT-4 pour générer automatiquement les données d'instructions de réglage fin requises pour le modèle de langage.

Lien papier : https://arxiv.org /pdf/2304.03277.pdf
Lien du code : https://github.com/Instruction-Tuning-with-GPT-4 /GPT-4-LLM
Les résultats expérimentaux sur le modèle LLaMA basé sur Meta open source montrent que 52 000 données de suivi des instructions en anglais et en chinois ont surpassé les données d'instruction générés par des modèles de pointe précédents sur la nouvelle tâche, et les chercheurs ont également collecté des commentaires et des données de comparaison de GPT-4 pour une évaluation complète et une formation sur les modèles de récompense.
données d'entraînementcollecte de données
#🎜 🎜#Les chercheurs ont réutilisé 52 000 instructions utilisées par le modèle Alpaca publié par l'Université de Stanford. Chaque instruction décrit la tâche que le modèle doit effectuer et suit la même stratégie d'invite qu'Alpaca, en tenant compte à la fois des situations d'entrée et d'absence d'entrée en tant que contexte ou entrée facultatif. à une tâche ; utiliser de grands modèles de langage pour générer des réponses aux instructions.

# 🎜🎜 #1. Données de suivi des instructions en anglais :
Pour les 52 000 instructions collectées dans Alpaca, une réponse GPT-4 en anglais est fournie pour chaque instruction.

2. Données de suivi des instructions chinoises :
Utilisez ChatGPT pour traduire 52 000 instructions en chinois et exigez que GPT-4 utilise la réponse chinoise. ces instructions, et utilisez-les pour construire un modèle de suivi des instructions chinois basé sur LLaMA, et étudiez la capacité de généralisation multilingue du réglage des instructions.
3 Données de comparaison :nécessite que GPT-4 fournisse une note de 1 à 10 pour sa réponse et les réponses de trois modèles. , GPT-4, GPT-3.5 et OPT-IML sont notés pour entraîner le modèle de récompense.
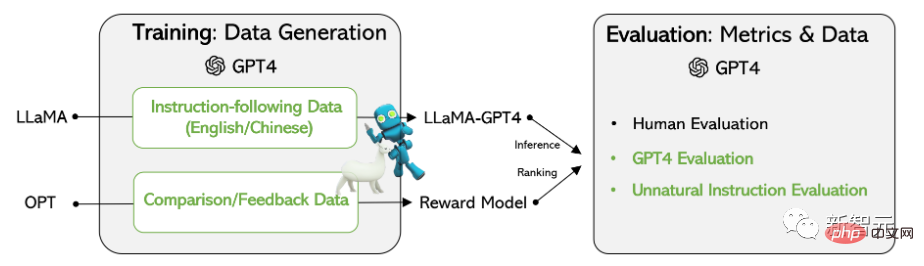
Statistiques
Les chercheurs ont comparé les ensembles de réponses de sortie en anglais de GPT-4 et GPT-3.5 : pour chaque sortie, le verbe racine et le nom d'objet direct ont été extraits, sur chaque ensemble de sorties, la fréquence des paires verbe-nom uniques a été calculée. Les 25 paires verbe-nom les plus fréquentes 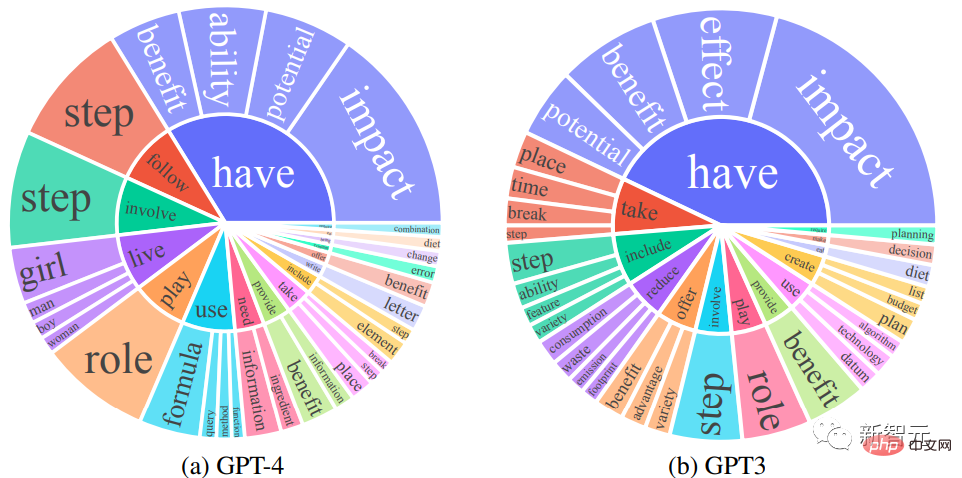
Sortie Comparaison de la distribution de fréquence de la longueur de la séquence
On peut voir que GPT-4 a tendance à générer des séquences plus longues que GPT-3.5. Le phénomène de longue traîne des données GPT-3.5 dans Alpaca est plus évident que la distribution de sortie. de GPT-4. Il se peut que l'ensemble de données Alpaca implique un processus de collecte de données itératif qui supprime les instances d'instructions similaires à chaque itération, ce qui n'est pas disponible dans la génération de données unique actuelle.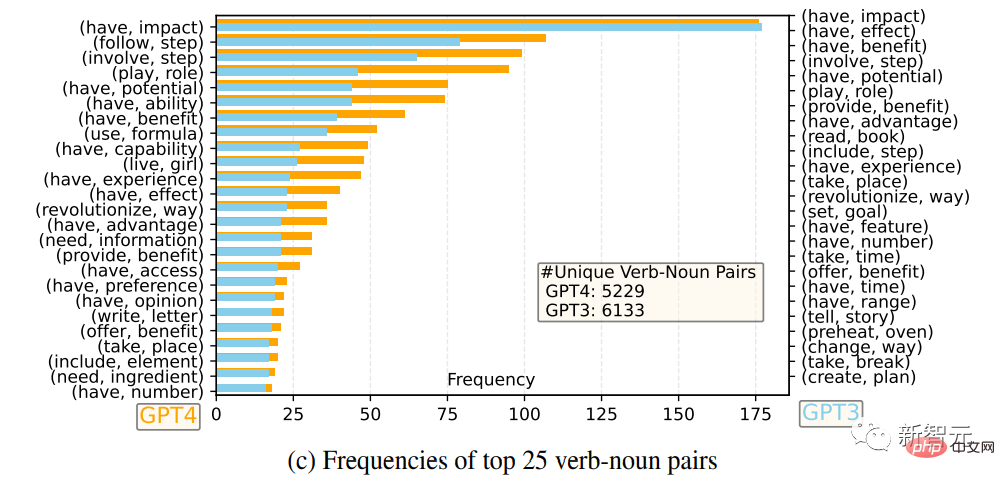
Modèle de langage de réglage des instructions
Réglage d'auto-instruction
Deux modèles ont été utilisés pour étudier la qualité des données de GPT-4 et les propriétés de généralisation multilingue des LLM adaptés aux instructions dans une langue.
Modèle de récompense
L'apprentissage par renforcement à partir de la rétroaction humaine (RLHF) vise à rendre le comportement LLM cohérent avec les préférences humaines afin de rendre le résultat du modèle de langage plus utile aux humains.
Un élément clé du RLHF est la modélisation des récompenses. Le problème peut être formulé comme une tâche de régression pour prédire le score de récompense à partir d'une invite et d'une réponse. Cette méthode nécessite généralement des données de comparaison à grande échelle, c'est-à-dire pour le même. » Comparez les réponses des deux modèles.
Les modèles open source existants, tels que Alpaca, Vicuna et Dolly, n'utilisent pas RLHF en raison du coût élevé de l'annotation des données comparatives, et des recherches récentes montrent que GPT-4 est capable d'identifier et de réparer ses propres erreurs, et Jugez avec précision la qualité des réponses.
Pour promouvoir la recherche sur le RLHF, les chercheurs ont créé des données comparatives à l'aide de GPT-4 pour évaluer la qualité des données, les chercheurs ont formé un modèle de récompense basé sur OPT 1.3B pour évaluer différentes réponses. Note : Pour une invite et un K. réponses, GPT-4 fournit un score compris entre 1 et 10 pour chaque réponse. Résultats expérimentaux
Évaluer les performances de modèles optimisés par l'auto-instruction sur les données GPT-4 pour des tâches inédites reste une tâche difficile.
Étant donné que l'objectif principal est d'évaluer la capacité du modèle à comprendre et à se conformer à diverses instructions de tâches, pour y parvenir, les chercheurs ont utilisé trois types d'évaluations et ont été confirmés par les résultats de l'étude "Utilisation de GPT-4 pour générer des données" par rapport à Il s'agit d'une méthode efficace pour régler des instructions de modèle de langage volumineux basées sur des données générées automatiquement par d'autres machines.
Évaluation humaine
Pour évaluer la qualité de l'alignement d'un grand modèle de langage après avoir réglé cette instruction, les chercheurs ont suivi les critères d'alignement proposés précédemment : si un assistant est utile, honnête et inoffensif (HHH), alors il est aligné avec des critères d’évaluation humains, qui sont également largement utilisés pour évaluer le degré de cohérence des systèmes d’intelligence artificielle avec les valeurs humaines.
Servabilité : Qu'il puisse aider les humains à atteindre leurs objectifs, un modèle capable de répondre avec précision aux questions est utile.
Honnêteté : Qu'il fournisse des informations vraies et exprime son incertitude lorsque cela est nécessaire pour éviter de tromper les utilisateurs humains, un modèle qui fournit de fausses informations est malhonnête.
Innocuité : Un modèle qui génère des discours de haine ou promeut la violence n'est pas inoffensif s'il ne cause pas de préjudice aux humains.
Sur la base des critères d'alignement HHH, les chercheurs ont utilisé la plateforme de crowdsourcing Amazon Mechanical Turk pour effectuer une évaluation manuelle des résultats de la génération de modèles.
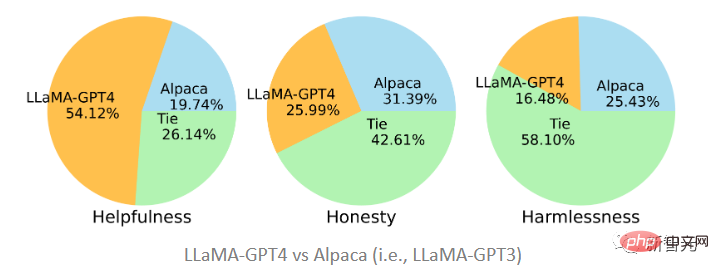
Les deux modèles proposés dans l'article ont été affinés sur les données générées par GPT-4 et GPT-3. On constate que LLaMA-GPT4 est bien plus utile avec une proportion de 51,2. % C'est mieux que Alpaca (19,74 %) affiné sur GPT-3, mais selon les normes d'honnêteté et d'innocuité, c'est fondamentalement une égalité, et GPT-3 est légèrement meilleur.
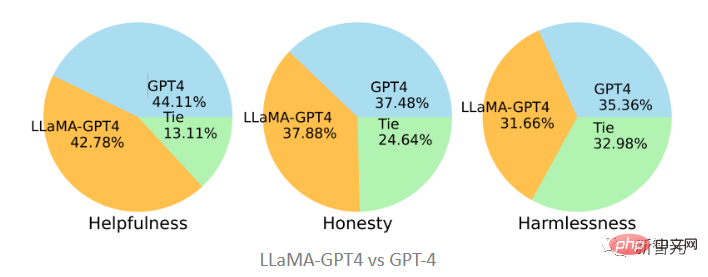
Par rapport au GPT-4 d'origine, on peut constater que les deux sont assez cohérents dans trois normes, c'est-à-dire que les performances de LLaMA après le réglage des instructions du GPT-4 sont similaires à l'original GPT-4.
Évaluation automatique GPT-4
Inspirés par Vicuna, les chercheurs ont également choisi d'utiliser GPT-4 pour évaluer la qualité des réponses générées par différents modèles de chatbot à 80 questions inédites, de LLaMA - Collecter les réponses de GPT -4(7B) et le modèle GPT-4 et obtenez les réponses d'autres modèles d'études précédentes, puis demandez à GPT-4 d'évaluer la qualité des réponses entre les deux modèles sur une échelle de 1 à 10, et comparez les résultats avec d'autres modèles fortement concurrents (ChatGPT et GPT-4).
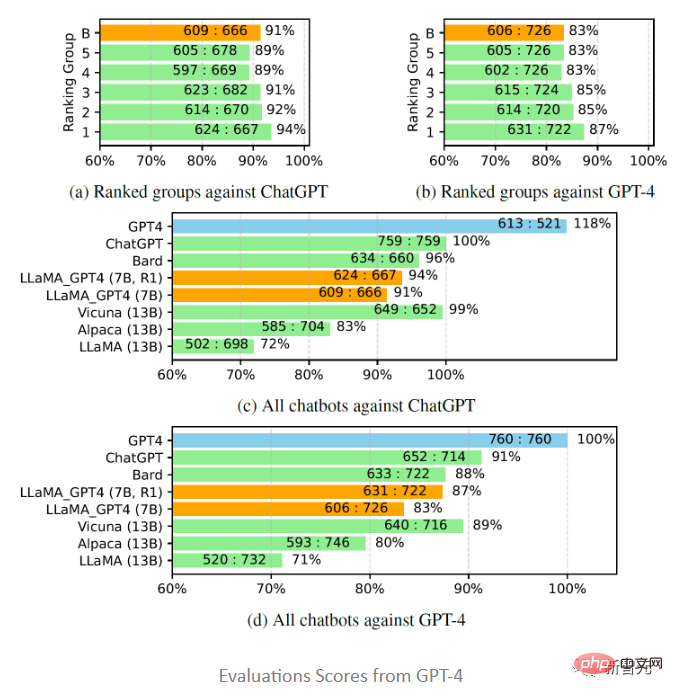
Les résultats de l'évaluation montrent que les données de rétroaction et les modèles de récompense sont efficaces pour améliorer les performances de LLaMA ; l'utilisation de GPT-4 pour régler les instructions de LLaMA est souvent meilleure que l'utilisation du réglage text-davinci-003 (c'est-à-dire Alpaca). ) et aucun réglage (c'est-à-dire LLaMA) ont des performances plus élevées ; les performances de 7B LLaMA GPT4 dépassent celles de 13B Alpaca et LLaMA, mais il existe encore un écart par rapport aux grands chatbots commerciaux tels que GPT-4.
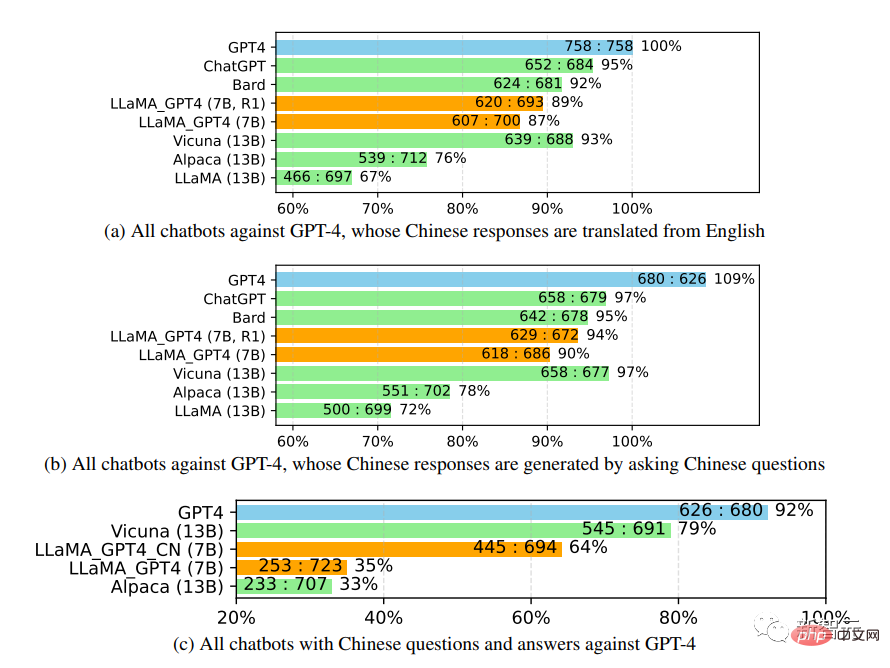
Lors d'une étude plus approfondie des performances du chatbot chinois, en utilisant d'abord GPT-4 pour traduire également les questions du chatbot de l'anglais vers le chinois, et en utilisant GPT-4 pour obtenir les réponses, deux observations intéressantes peuvent être made :
1. On peut constater que les mesures de score relatif des évaluations GPT-4 sont assez cohérentes, à la fois en termes de différents modèles d'adversaires (c'est-à-dire ChatGPT ou GPT-4) et de langues (c'est-à-dire l'anglais). ou chinois).
2. Uniquement pour les résultats de GPT-4, les réponses traduites ont obtenu de meilleurs résultats que les réponses générées en chinois, probablement parce que GPT-4 a été formé sur un corpus anglais plus riche que le chinois, il a donc un enseignement en anglais plus fort. -capacité de suivi.
Évaluation des instructions non naturelles
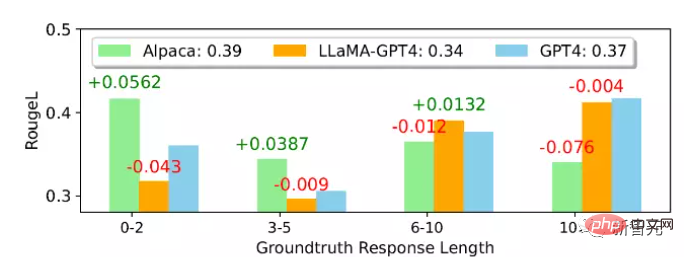
D'après le score moyen ROUGE-L, Alpaca est meilleur que LLaMA-GPT 4 et GPT-4. On peut noter que LLaMA-GPT4 et GPT4 fonctionnent progressivement mieux. lorsque la longueur de la réponse de vérité terrain augmente, et montre finalement des performances plus élevées lorsque la longueur dépasse 4, ce qui signifie que les instructions peuvent être mieux suivies lorsque la scène est plus créative.
Dans différents sous-ensembles, le comportement de LLaMA-GPT4 et GPT-4 est presque le même ; lorsque la longueur de la séquence est courte, LLaMA-GPT4 et GPT-4 peuvent générer des réponses contenant des réponses simples aux faits de base, mais ajouteront des mots supplémentaires pour rendre les réponses plus semblables à celles d'un chat peuvent entraîner un score ROUGE-L inférieur.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Quelle méthode est utilisée pour convertir les chaînes en objets dans vue.js?
Apr 07, 2025 pm 09:39 PM
Quelle méthode est utilisée pour convertir les chaînes en objets dans vue.js?
Apr 07, 2025 pm 09:39 PM
Lors de la conversion des chaînes en objets dans vue.js, JSON.Parse () est préféré pour les chaînes JSON standard. Pour les chaînes JSON non standard, la chaîne peut être traitée en utilisant des expressions régulières et réduisez les méthodes en fonction du format ou du codé décodé par URL. Sélectionnez la méthode appropriée en fonction du format de chaîne et faites attention aux problèmes de sécurité et d'encodage pour éviter les bogues.
 Comment utiliser MySQL après l'installation
Apr 08, 2025 am 11:48 AM
Comment utiliser MySQL après l'installation
Apr 08, 2025 am 11:48 AM
L'article présente le fonctionnement de la base de données MySQL. Tout d'abord, vous devez installer un client MySQL, tel que MySQLWorkBench ou le client de ligne de commande. 1. Utilisez la commande MySQL-UROot-P pour vous connecter au serveur et connecter avec le mot de passe du compte racine; 2. Utilisez Createdatabase pour créer une base de données et utilisez Sélectionner une base de données; 3. Utilisez CreateTable pour créer une table, définissez des champs et des types de données; 4. Utilisez InsertInto pour insérer des données, remettre en question les données, mettre à jour les données par mise à jour et supprimer les données par Supprimer. Ce n'est qu'en maîtrisant ces étapes, en apprenant à faire face à des problèmes courants et à l'optimisation des performances de la base de données que vous pouvez utiliser efficacement MySQL.
 Comment résoudre MySQL ne peut pas être démarré
Apr 08, 2025 pm 02:21 PM
Comment résoudre MySQL ne peut pas être démarré
Apr 08, 2025 pm 02:21 PM
Il existe de nombreuses raisons pour lesquelles la startup MySQL échoue, et elle peut être diagnostiquée en vérifiant le journal des erreurs. Les causes courantes incluent les conflits de port (vérifier l'occupation du port et la configuration de modification), les problèmes d'autorisation (vérifier le service exécutant les autorisations des utilisateurs), les erreurs de fichier de configuration (vérifier les paramètres des paramètres), la corruption du répertoire de données (restaurer les données ou reconstruire l'espace de la table), les problèmes d'espace de la table InNODB (vérifier les fichiers IBDATA1), la défaillance du chargement du plug-in (vérification du journal des erreurs). Lors de la résolution de problèmes, vous devez les analyser en fonction du journal d'erreur, trouver la cause profonde du problème et développer l'habitude de sauvegarder régulièrement les données pour prévenir et résoudre des problèmes.
 Géospatial de Laravel: optimisation des cartes interactives et de grandes quantités de données
Apr 08, 2025 pm 12:24 PM
Géospatial de Laravel: optimisation des cartes interactives et de grandes quantités de données
Apr 08, 2025 pm 12:24 PM
Traiter efficacement 7 millions d'enregistrements et créer des cartes interactives avec la technologie géospatiale. Cet article explore comment traiter efficacement plus de 7 millions d'enregistrements en utilisant Laravel et MySQL et les convertir en visualisations de cartes interactives. Exigences initiales du projet de défi: extraire des informations précieuses en utilisant 7 millions d'enregistrements dans la base de données MySQL. Beaucoup de gens considèrent d'abord les langages de programmation, mais ignorent la base de données elle-même: peut-il répondre aux besoins? La migration des données ou l'ajustement structurel est-il requis? MySQL peut-il résister à une charge de données aussi importante? Analyse préliminaire: les filtres et les propriétés clés doivent être identifiés. Après analyse, il a été constaté que seuls quelques attributs étaient liés à la solution. Nous avons vérifié la faisabilité du filtre et établi certaines restrictions pour optimiser la recherche. Recherche de cartes basée sur la ville
 Comment définir le délai de Vue Axios
Apr 07, 2025 pm 10:03 PM
Comment définir le délai de Vue Axios
Apr 07, 2025 pm 10:03 PM
Afin de définir le délai d'expiration de Vue Axios, nous pouvons créer une instance AxiOS et spécifier l'option Timeout: dans les paramètres globaux: vue.prototype. $ Axios = axios.create ({timeout: 5000}); Dans une seule demande: ce. $ axios.get ('/ api / utilisateurs', {timeout: 10000}).
 Comment optimiser les performances de la base de données après l'installation de MySQL
Apr 08, 2025 am 11:36 AM
Comment optimiser les performances de la base de données après l'installation de MySQL
Apr 08, 2025 am 11:36 AM
L'optimisation des performances MySQL doit commencer à partir de trois aspects: configuration d'installation, indexation et optimisation des requêtes, surveillance et réglage. 1. Après l'installation, vous devez ajuster le fichier my.cnf en fonction de la configuration du serveur, tel que le paramètre innodb_buffer_pool_size, et fermer query_cache_size; 2. Créez un index approprié pour éviter les index excessifs et optimiser les instructions de requête, telles que l'utilisation de la commande Explication pour analyser le plan d'exécution; 3. Utilisez le propre outil de surveillance de MySQL (ShowProcessList, Showstatus) pour surveiller la santé de la base de données, et sauvegarde régulièrement et organisez la base de données. Ce n'est qu'en optimisant en continu ces étapes que les performances de la base de données MySQL peuvent être améliorées.
 Vue.js Comment convertir un tableau de type de chaîne en un tableau d'objets?
Apr 07, 2025 pm 09:36 PM
Vue.js Comment convertir un tableau de type de chaîne en un tableau d'objets?
Apr 07, 2025 pm 09:36 PM
Résumé: Il existe les méthodes suivantes pour convertir les tableaux de chaîne Vue.js en tableaux d'objets: Méthode de base: utilisez la fonction de carte pour convenir à des données formatées régulières. Gameplay avancé: l'utilisation d'expressions régulières peut gérer des formats complexes, mais ils doivent être soigneusement écrits et considérés. Optimisation des performances: Considérant la grande quantité de données, des opérations asynchrones ou des bibliothèques efficaces de traitement des données peuvent être utilisées. MEILLEUR PRATIQUE: Effacer le style de code, utilisez des noms de variables significatifs et des commentaires pour garder le code concis.
 Les ingénieurs de backend senior à distance (plates-formes) ont besoin de cercles
Apr 08, 2025 pm 12:27 PM
Les ingénieurs de backend senior à distance (plates-formes) ont besoin de cercles
Apr 08, 2025 pm 12:27 PM
Ingénieur backend à distance Emploi Vacant Société: Emplacement du cercle: Bureau à distance Type d'emploi: Salaire à temps plein: 130 000 $ - 140 000 $ Description du poste Participez à la recherche et au développement des applications mobiles Circle et des fonctionnalités publiques liées à l'API couvrant l'intégralité du cycle de vie de développement logiciel. Les principales responsabilités complètent indépendamment les travaux de développement basés sur RubyOnRails et collaborent avec l'équipe frontale React / Redux / Relay. Créez les fonctionnalités de base et les améliorations des applications Web et travaillez en étroite collaboration avec les concepteurs et le leadership tout au long du processus de conception fonctionnelle. Promouvoir les processus de développement positifs et hiérarchiser la vitesse d'itération. Nécessite plus de 6 ans de backend d'applications Web complexe
