
 Périphériques technologiques
IA
L'équipe chinoise NUS lance le dernier modèle : une reconstruction 3D à vue unique, rapide et précise !
Périphériques technologiques
IA
L'équipe chinoise NUS lance le dernier modèle : une reconstruction 3D à vue unique, rapide et précise !
L'équipe chinoise NUS lance le dernier modèle : une reconstruction 3D à vue unique, rapide et précise !

La reconstruction 3D d'images 2D a toujours été un moment fort dans le domaine du CV.
Différents modèles ont été développés pour tenter de pallier à ce problème.
Aujourd'hui, des chercheurs de l'Université nationale de Singapour ont publié conjointement un article et développé un nouveau framework Anything-3D pour résoudre ce problème de longue date.

Adresse papier : https://arxiv.org/pdf/2304.10261.pdf#🎜 🎜#
Avec l'aide du modèle « diviser tout » de Meta, Anything-3D donne directement vie à tout objet divisé.

De plus, en utilisant le modèle Zero-1-to-3, vous pouvez obtenir différents angles de base Ke .
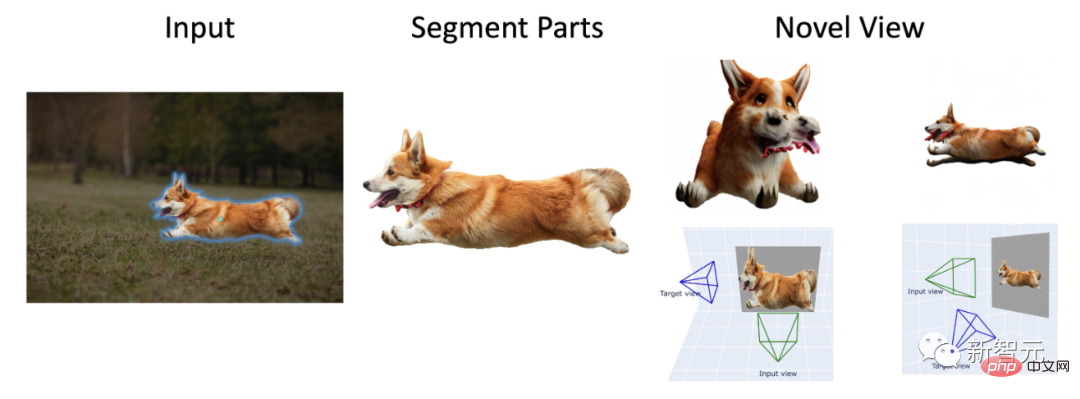
Vous pouvez même effectuer une reconstruction 3D de personnages.

On peut dire que celui-là est vraiment un percée.
Anything-3D !Dans le monde réel, divers objets et environnements sont divers et complexes. Par conséquent, sans restrictions, la reconstruction 3D à partir d’une seule image RVB se heurte à de nombreuses difficultés.
Ici, des chercheurs de l'Université nationale de Singapour ont combiné une série de modèles de langage visuel et de modèles de segmentation d'objets SAM (Segment-Anything) pour générer un système Strong polyvalent et fiable. - N'importe quoi en 3D.
Le but est de réaliser la tâche de reconstruction 3D sous la condition d'une perspective unique.
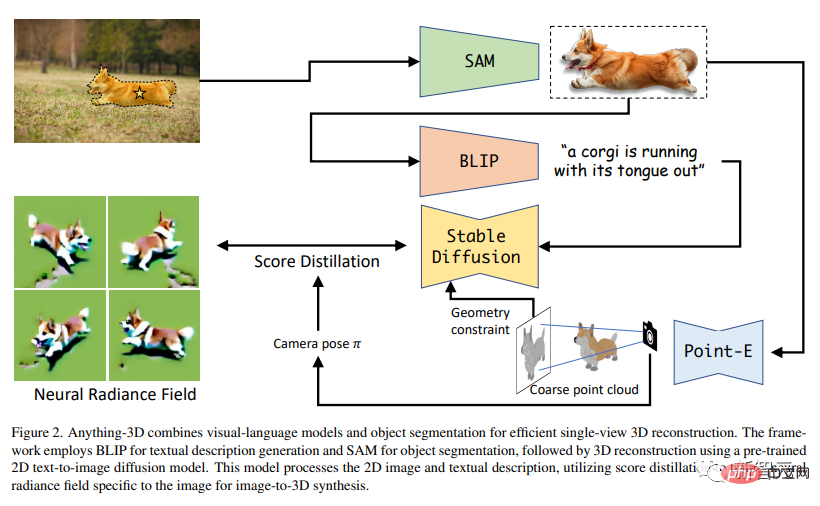
Ils utilisent le modèle BLIP pour générer des descriptions de texture, utilisent le modèle SAM pour extraire des objets dans l'image, puis utilisent le modèle de diffusion texte → image Stable Diffusion pour placer les objets dans Nerf (champ de rayonnement neuronal).
Dans des expériences ultérieures, Anything-3D a démontré ses puissantes capacités de reconstruction tridimensionnelle. Non seulement il est précis, mais il a un large éventail d’applicabilités.
Anything-3D a des effets évidents en résolvant les limites des méthodes existantes. Les chercheurs ont démontré les avantages de ce nouveau cadre en testant et en évaluant divers ensembles de données.

Sur la photo ci-dessus, on peut voir : "Corgi tire la langue et court des milliers de kilomètres" , "Silver Wings", "Statue de la Déesse confiée à une voiture de luxe" et "Une vache brune dans un champ portant une corde bleue sur la tête".
Il s'agit d'une démonstration préliminaire que le framework Anything-3D peut habilement restaurer des images à vue unique prises dans n'importe quel environnement sous une forme 3D et générer une texture.
Ce nouveau framework fournit toujours des résultats très précis malgré d'importants changements dans la perspective de la caméra et les propriétés des objets.
Il faut savoir que la reconstruction d'objets 3D à partir d'images 2D est au cœur du sujet dans le domaine de la vision par ordinateur, très importante pour les robots, la conduite autonome, la réalité, réalité virtuelle et impression tridimensionnelle. Elle a un impact énorme dans tous les domaines.
Bien que de bons progrès aient été réalisés ces dernières années, la tâche de reconstruction d'objets à image unique dans des environnements non structurés reste un problème très attrayant et urgent à résoudre.
Actuellement, les chercheurs ont pour tâche de générer une représentation tridimensionnelle d'un ou plusieurs objets à partir d'une seule image bidimensionnelle. Les méthodes de représentation incluent des nuages de points, des maillages ou des représentations volumiques.
Cependant, ce problème n'est fondamentalement pas vrai.
En raison de l'ambiguïté inhérente créée par la projection bidimensionnelle, il est impossible de déterminer sans ambiguïté la structure tridimensionnelle d'un objet.
Couplée aux énormes différences de forme, de taille, de texture et d'apparence, la reconstruction d'objets dans leur environnement naturel est très complexe. De plus, les objets des images du monde réel sont souvent masqués, ce qui empêche une reconstruction précise des parties masquées.
Dans le même temps, des variables telles que l'éclairage et les ombres peuvent également affecter grandement l'apparence des objets, et les différences d'angle et de distance peuvent également provoquer des changements évidents entre les deux. -projection dimensionnelle.
Assez avec les difficultés, Anything-3D est prêt à jouer.
Dans l'article, les chercheurs ont présenté en détail ce cadre système révolutionnaire, qui intègre le modèle de langage visuel et le modèle de segmentation d'objets pour combiner facilement des objets 2D en 3D. .
De cette façon, un système doté de fonctions puissantes et d'une forte adaptabilité devient. Reconstruction à vue unique ? Facile.
Selon les chercheurs, en combinant les deux modèles, il est possible de récupérer et de déterminer la texture et la géométrie tridimensionnelles d'une image donnée.
Anything-3D utilise le modèle BLIP (Bootstrapping Language-Image Model) pour pré-entraîner la description textuelle de l'image, puis utilise le modèle SAM pour identifier le zone de distribution de l'objet.
Ensuite, utilisez les objets segmentés et les descriptions textuelles pour effectuer la tâche de reconstruction 3D.
En d'autres termes, cet article utilise un modèle de diffusion texte → image 2D pré-entraîné pour effectuer une synthèse 3D d'images. De plus, les chercheurs ont utilisé la distillation fractionnée pour entraîner un Nerf spécifiquement pour les images. Le coin supérieur gauche est l'image originale 2D. Elle passe d'abord par SAM pour segmenter le corgi, puis par BLIP pour générer une description textuelle, puis utilise la distillation fractionnée pour créer un Nerf.
 Grâce à des expériences rigoureuses sur différents ensembles de données, les chercheurs ont démontré l'efficacité et l'adaptabilité de cette approche, tout en améliorant la précision, la robustesse et la généralisation. Les capacités dépassent les méthodes existantes. .
Grâce à des expériences rigoureuses sur différents ensembles de données, les chercheurs ont démontré l'efficacité et l'adaptabilité de cette approche, tout en améliorant la précision, la robustesse et la généralisation. Les capacités dépassent les méthodes existantes. .
Les chercheurs ont également mené une analyse complète et approfondie des défis existants dans la reconstruction d'objets 3D dans des environnements naturels et ont exploré comment le nouveau cadre peut résoudre ces problèmes.
Enfin, en intégrant les capacités de vision à distance nulle et de compréhension du langage dans le modèle de base, le nouveau framework peut mieux reconstruire des objets à partir de différents types d'images dans le monde réel et générer une représentation 3D précise, complexe et largement applicable.
On peut dire qu'Anything-3D est une avancée majeure dans le domaine de la reconstruction d'objets 3D.
Voici d'autres exemples :
#🎜🎜 ## ##小, grue d'excavatrice orange vif, chapeau vert petit canard en caoutchouc jaune#🎜🎜 ## 🎜🎜 ## 🎜🎜 ## 🎜🎜 ## 🎜🎜# #🎜🎜 ##### 🎜🎜#Times Tears Fading Cannon , Pig Pig's Cute Metal Save Tibet, Tabouret haut à quatre pattes rouge cinabre#🎜🎜 ## 🎜🎜 ## 🎜🎜 ##### ## 🎜🎜#Ce nouveau cadre peut identifier de manière interactive les régions dans des images à vue unique et représenter des objets 2D avec des incorporations de texte optimisées. En fin de compte, un modèle de distillation fractionnée prenant en charge la 3D est utilisé pour générer efficacement des objets 3D de haute qualité.
En résumé, Anything-3D démontre le potentiel de reconstruction d'objets 3D naturels à partir d'images à vue unique.
Les chercheurs ont déclaré que la qualité de la reconstruction 3D du nouveau cadre peut être plus parfaite et que les chercheurs travaillent constamment dur pour améliorer la qualité de la génération.
De plus, les chercheurs ont déclaré que les évaluations quantitatives d'ensembles de données 3D telles que la synthèse de nouvelles vues et la reconstruction d'erreurs ne sont pas fournies actuellement, mais seront incluses dans les futures itérations de travail. ces contenus.
Pendant ce temps, l'objectif ultime des chercheurs est d'élargir ce cadre pour s'adapter à des situations plus pratiques, notamment la récupération d'objets sous des vues clairsemées.
À propos de l'auteur
Wang est actuellement professeur assistant tenure track au département ECE de l'Université nationale de Singapour (NUS).
Avant de rejoindre l'Université nationale de Singapour, il était professeur adjoint au département CS du Stevens Institute of Technology. Avant de rejoindre Stevens, j'ai travaillé comme postdoctorant dans le groupe de formation d'images du professeur Thomas Huang à l'Institut Beckman de l'Université de l'Illinois à Urbana-Champaign.
Wang a obtenu son doctorat au Laboratoire de vision par ordinateur de l'Ecole Polytechnique Fédérale de Lausanne (EPFL), supervisé par le professeur Pascal Fua, et a obtenu son doctorat au Département d'informatique Sciences, Université polytechnique de Hong Kong en 2010 Licence avec mention très bien.

Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Quatre outils de programmation assistés par IA recommandés
Apr 22, 2024 pm 05:34 PM
Quatre outils de programmation assistés par IA recommandés
Apr 22, 2024 pm 05:34 PM
Cet outil de programmation assistée par l'IA a mis au jour un grand nombre d'outils de programmation assistée par l'IA utiles à cette étape de développement rapide de l'IA. Les outils de programmation assistés par l'IA peuvent améliorer l'efficacité du développement, améliorer la qualité du code et réduire les taux de bogues. Ils constituent des assistants importants dans le processus de développement logiciel moderne. Aujourd'hui, Dayao partagera avec vous 4 outils de programmation assistés par l'IA (et tous prennent en charge le langage C#). J'espère que cela sera utile à tout le monde. https://github.com/YSGStudyHards/DotNetGuide1.GitHubCopilotGitHubCopilot est un assistant de codage IA qui vous aide à écrire du code plus rapidement et avec moins d'effort, afin que vous puissiez vous concentrer davantage sur la résolution de problèmes et la collaboration. Git
 CLIP-BEVFormer : superviser explicitement la structure BEVFormer pour améliorer les performances de détection à longue traîne
Mar 26, 2024 pm 12:41 PM
CLIP-BEVFormer : superviser explicitement la structure BEVFormer pour améliorer les performances de détection à longue traîne
Mar 26, 2024 pm 12:41 PM
Écrit ci-dessus et compréhension personnelle de l'auteur : À l'heure actuelle, dans l'ensemble du système de conduite autonome, le module de perception joue un rôle essentiel. Le véhicule autonome roulant sur la route ne peut obtenir des résultats de perception précis que via le module de perception en aval. dans le système de conduite autonome, prend des jugements et des décisions comportementales opportuns et corrects. Actuellement, les voitures dotées de fonctions de conduite autonome sont généralement équipées d'une variété de capteurs d'informations de données, notamment des capteurs de caméra à vision panoramique, des capteurs lidar et des capteurs radar à ondes millimétriques pour collecter des informations selon différentes modalités afin d'accomplir des tâches de perception précises. L'algorithme de perception BEV basé sur la vision pure est privilégié par l'industrie en raison de son faible coût matériel et de sa facilité de déploiement, et ses résultats peuvent être facilement appliqués à diverses tâches en aval.
 Quel programmeur IA est le meilleur ? Explorez le potentiel de Devin, Tongyi Lingma et de l'agent SWE
Apr 07, 2024 am 09:10 AM
Quel programmeur IA est le meilleur ? Explorez le potentiel de Devin, Tongyi Lingma et de l'agent SWE
Apr 07, 2024 am 09:10 AM
Le 3 mars 2022, moins d'un mois après la naissance de Devin, le premier programmeur d'IA au monde, l'équipe NLP de l'Université de Princeton a développé un agent SWE pour programmeur d'IA open source. Il exploite le modèle GPT-4 pour résoudre automatiquement les problèmes dans les référentiels GitHub. Les performances de l'agent SWE sur l'ensemble de tests du banc SWE sont similaires à celles de Devin, prenant en moyenne 93 secondes et résolvant 12,29 % des problèmes. En interagissant avec un terminal dédié, SWE-agent peut ouvrir et rechercher le contenu des fichiers, utiliser la vérification automatique de la syntaxe, modifier des lignes spécifiques et écrire et exécuter des tests. (Remarque : le contenu ci-dessus est un léger ajustement du contenu original, mais les informations clés du texte original sont conservées et ne dépassent pas la limite de mots spécifiée.) SWE-A
 Les dernières nouvelles de l'Université d'Oxford ! Mickey : correspondance d'images 2D en 3D SOTA ! (CVPR\'24)
Apr 23, 2024 pm 01:20 PM
Les dernières nouvelles de l'Université d'Oxford ! Mickey : correspondance d'images 2D en 3D SOTA ! (CVPR\'24)
Apr 23, 2024 pm 01:20 PM
Lien du projet écrit devant : https://nianticlabs.github.io/mickey/ Étant donné deux images, la pose de la caméra entre elles peut être estimée en établissant la correspondance entre les images. En règle générale, ces correspondances sont 2D à 2D et nos poses estimées sont à échelle indéterminée. Certaines applications, telles que la réalité augmentée instantanée, à tout moment et en tout lieu, nécessitent une estimation de pose des métriques d'échelle, elles s'appuient donc sur des estimateurs de profondeur externes pour récupérer l'échelle. Cet article propose MicKey, un processus de correspondance de points clés capable de prédire les correspondances métriques dans l'espace d'une caméra 3D. En apprenant la correspondance des coordonnées 3D entre les images, nous sommes en mesure de déduire des métriques relatives.
 Apprenez à développer des applications mobiles en utilisant le langage Go
Mar 28, 2024 pm 10:00 PM
Apprenez à développer des applications mobiles en utilisant le langage Go
Mar 28, 2024 pm 10:00 PM
Didacticiel d'application mobile de développement du langage Go Alors que le marché des applications mobiles continue de croître, de plus en plus de développeurs commencent à explorer comment utiliser le langage Go pour développer des applications mobiles. En tant que langage de programmation simple et efficace, le langage Go a également montré un fort potentiel dans le développement d'applications mobiles. Cet article présentera en détail comment utiliser le langage Go pour développer des applications mobiles et joindra des exemples de code spécifiques pour aider les lecteurs à démarrer rapidement et à commencer à développer leurs propres applications mobiles. 1. Préparation Avant de commencer, nous devons préparer l'environnement et les outils de développement. tête
 Résumé des cinq bibliothèques du langage Go les plus populaires : outils essentiels au développement
Feb 22, 2024 pm 02:33 PM
Résumé des cinq bibliothèques du langage Go les plus populaires : outils essentiels au développement
Feb 22, 2024 pm 02:33 PM
Résumé des cinq bibliothèques du langage Go les plus populaires : des outils essentiels au développement, nécessitant des exemples de code spécifiques. Depuis sa naissance, le langage Go a fait l'objet d'une attention et d'une application généralisées. En tant que langage de programmation émergent, efficace et concis, le développement rapide de Go est indissociable du support de riches bibliothèques open source. Cet article présentera les cinq bibliothèques de langage Go les plus populaires. Ces bibliothèques jouent un rôle essentiel dans le développement Go et offrent aux développeurs des fonctions puissantes et une expérience de développement pratique. Parallèlement, afin de mieux comprendre les usages et les fonctions de ces bibliothèques, nous les expliquerons avec des exemples de codes précis.
 Le LLM est terminé ! OmniDrive : Intégration de la perception 3D et de la planification du raisonnement (la dernière version de NVIDIA)
May 09, 2024 pm 04:55 PM
Le LLM est terminé ! OmniDrive : Intégration de la perception 3D et de la planification du raisonnement (la dernière version de NVIDIA)
May 09, 2024 pm 04:55 PM
Écrit ci-dessus et compréhension personnelle de l'auteur : cet article est dédié à la résolution des principaux défis des grands modèles de langage multimodaux (MLLM) actuels dans les applications de conduite autonome, c'est-à-dire le problème de l'extension des MLLM de la compréhension 2D à l'espace 3D. Cette expansion est particulièrement importante car les véhicules autonomes (VA) doivent prendre des décisions précises concernant les environnements 3D. La compréhension spatiale 3D est essentielle pour les véhicules utilitaires car elle a un impact direct sur la capacité du véhicule à prendre des décisions éclairées, à prédire les états futurs et à interagir en toute sécurité avec l’environnement. Les modèles de langage multimodaux actuels (tels que LLaVA-1.5) ne peuvent souvent gérer que des entrées d'images de résolution inférieure (par exemple) en raison des limitations de résolution de l'encodeur visuel et des limitations de la longueur de la séquence LLM. Cependant, les applications de conduite autonome nécessitent
 Le repérage des nuages de points est incontournable pour la vision 3D ! Comprendre toutes les solutions et défis courants dans un seul article
Apr 02, 2024 am 11:31 AM
Le repérage des nuages de points est incontournable pour la vision 3D ! Comprendre toutes les solutions et défis courants dans un seul article
Apr 02, 2024 am 11:31 AM
Le nuage de points, en tant qu'ensemble de points, devrait entraîner un changement dans l'acquisition et la génération d'informations de surface tridimensionnelles (3D) sur des objets grâce à la reconstruction 3D, à l'inspection industrielle et au fonctionnement de robots. Le processus le plus difficile mais essentiel est l'enregistrement des nuages de points, c'est-à-dire l'obtention d'une transformation spatiale qui aligne et fait correspondre deux nuages de points obtenus dans deux coordonnées différentes. Cette revue présente un aperçu et les principes de base de l'enregistrement des nuages de points, classe et compare systématiquement diverses méthodes et résout les problèmes techniques existant dans l'enregistrement des nuages de points, en essayant de fournir aux chercheurs universitaires en dehors du domaine et aux ingénieurs des conseils et faciliter les discussions sur une vision unifiée. pour l'enregistrement des nuages de points. La méthode générale d'acquisition de nuages de points est divisée en méthodes actives et passives. Le nuage de points acquis activement par le capteur est la méthode active, et le nuage de points est reconstruit ultérieurement.
