
 Périphériques technologiques
IA
La recherche montre que l'apprentissage entrelacé pondéré basé sur la similarité peut résoudre efficacement le problème de « l'amnésie » dans l'apprentissage profond
Périphériques technologiques
IA
La recherche montre que l'apprentissage entrelacé pondéré basé sur la similarité peut résoudre efficacement le problème de « l'amnésie » dans l'apprentissage profond
La recherche montre que l'apprentissage entrelacé pondéré basé sur la similarité peut résoudre efficacement le problème de « l'amnésie » dans l'apprentissage profond

Contrairement aux humains, les réseaux de neurones artificiels oublient rapidement les informations précédemment apprises lorsqu'ils apprennent de nouvelles choses et doivent être recyclés en entrelaçant les anciennes et les nouvelles informations. Cependant, entrelacer toutes les anciennes informations prend beaucoup de temps et peut ne pas être nécessaire. Il peut suffire d'entrelacer uniquement les anciennes informations qui sont substantiellement similaires aux nouvelles informations.
Récemment, les Actes de la National Academy of Sciences (PNAS) ont publié un article intitulé « Apprendre dans les réseaux neuronaux profonds et les cerveaux avec un apprentissage entrelacé pondéré par similarité », publié par l'équipe de Bruce McNaughton, membre du Royal Société du Canada et neuroscientifique bien connu. Leurs travaux ont révélé qu'en effectuant un entraînement par entrelacement pondéré par similarité d'informations anciennes avec de nouvelles informations, les réseaux profonds peuvent rapidement apprendre de nouvelles choses, réduisant non seulement les taux d'oubli, mais utilisant également beaucoup moins de données.
Les auteurs émettent également l'hypothèse qu'un entrelacement pondéré par similarité peut être obtenu dans le cerveau en suivant les trajectoires d'excitabilité en cours des neurones récemment actifs et la dynamique des attracteurs neurodynamiques. Ces découvertes pourraient conduire à de nouveaux progrès dans les domaines des neurosciences et de l’apprentissage automatique.
Contexte de recherche
Comprendre comment le cerveau apprend tout au long de la vie reste un défi à long terme.
Dans les réseaux de neurones artificiels (ANN), l'intégration trop rapide de nouvelles informations peut produire des interférences catastrophiques, où les connaissances précédemment acquises sont soudainement perdues. La théorie des systèmes d'apprentissage complémentaires (CLST) suggère que de nouveaux souvenirs peuvent être progressivement intégrés dans le néocortex en les entrelaçant avec les connaissances existantes.
CLST affirme que le cerveau s'appuie sur des systèmes d'apprentissage complémentaires : l'hippocampe (HC) pour l'acquisition rapide de nouveaux souvenirs, et le néocortex (NC) pour l'intégration progressive de nouvelles données dans des connaissances structurées sans contexte. Pendant les « périodes hors ligne », comme pendant le sommeil et le repos éveillé calme, le HC déclenche la relecture d'expériences récentes dans le NC, tandis que le NC récupère et entrelace spontanément les représentations des catégories existantes. La relecture entrelacée permet un ajustement incrémentiel des poids synaptiques NC par descente de gradient pour créer des représentations de catégories indépendantes du contexte qui intègrent avec élégance de nouveaux souvenirs et surmontent les interférences catastrophiques. De nombreuses études ont utilisé avec succès la relecture entrelacée pour parvenir à un apprentissage continu des réseaux neuronaux.
Cependant, lors de l'application du CLST dans la pratique, deux problèmes importants doivent être résolus. Premièrement, comment un entrelacement complet d’informations peut-il se produire lorsque le cerveau ne peut pas accéder à toutes les anciennes données ? Une solution possible est la « pseudo-répétition », dans laquelle une entrée aléatoire peut déclencher une lecture générative de représentations internes sans accès explicite aux exemples appris précédemment. La dynamique de type attracteur peut permettre au cerveau d'effectuer une « pseudo-répétition », mais le contenu de la « pseudo-répétition » n'a pas encore été clarifié. La deuxième question est donc de savoir si, après chaque nouvelle activité d’apprentissage, le cerveau dispose de suffisamment de temps pour entrelacer toutes les informations précédemment apprises.
L'algorithme d'apprentissage entrelacé pondéré par similarité (SWIL) est considéré comme une solution au deuxième problème, suggérant que seul l'entrelacement d'anciennes informations présentant une similarité de représentation substantielle avec les nouvelles informations peut être suffisant. Des études comportementales empiriques montrent que de nouvelles informations hautement cohérentes peuvent être rapidement intégrées dans des connaissances structurées NC avec peu d'interférences. Cela suggère que la vitesse à laquelle les nouvelles informations sont intégrées dépend de leur cohérence avec les connaissances antérieures. Inspirés par ce résultat comportemental et en réexaminant les distributions d'interférence catastrophique obtenues précédemment entre les catégories, McClelland et al. ""), chaque époque utilise moins de 2,5 fois la quantité de données pour apprendre de nouvelles informations, obtenant les mêmes performances que la formation du réseau sur toutes les données. Cependant, les chercheurs n’ont pas trouvé d’effets similaires lors de l’utilisation d’ensembles de données plus complexes, ce qui soulève des inquiétudes quant à l’évolutivité de l’algorithme.
Des expériences montrent que les réseaux neuronaux artificiels non linéaires profonds peuvent apprendre de nouvelles informations en entrelaçant uniquement des sous-ensembles d'informations anciennes qui partagent une grande similitude de représentation avec les nouvelles informations. En utilisant l'algorithme SWIL, l'ANN est capable d'apprendre rapidement de nouvelles informations avec un niveau de précision similaire et un minimum d'interférences, tout en utilisant une très petite quantité d'informations anciennes présentées à chaque époque, ce qui signifie une utilisation élevée des données et un apprentissage rapide.
Dans le même temps, SWIL peut également être appliqué au cadre d'apprentissage séquentiel. De plus, l’apprentissage d’une nouvelle catégorie peut grandement améliorer l’utilisation des données. Si les anciennes informations présentent très peu de similitudes avec les catégories précédemment apprises, alors la quantité d’informations anciennes présentées sera beaucoup plus petite, ce qui est probablement le cas réel de l’apprentissage humain.
Enfin, les auteurs proposent un modèle théorique de la façon dont SWIL est mis en œuvre dans le cerveau, avec un biais d'excitabilité proportionnel au chevauchement de nouvelles informations.
Modèle dynamique DNN appliqué à l'ensemble de données de classification d'images
Les expériences de McClelland et al. montrent que dans un réseau linéaire profond avec une couche cachée, SWIL peut apprendre une nouvelle catégorie, similaire à l'apprentissage entièrement entrelacé (Fully Interleaved Learning). (FIL), qui entrelace toute l'ancienne catégorie avec la nouvelle catégorie, mais utilise 40 % de données en moins.
Cependant, le réseau a été formé sur un ensemble de données très simple avec seulement deux catégories d'hyperonymes, ce qui soulève des questions sur l'évolutivité de l'algorithme.
Explorez d'abord comment différentes catégories d'apprentissage évoluent dans un réseau neuronal linéaire profond avec une couche cachée pour un ensemble de données plus complexe (comme Fashion-MNIST). Après avoir supprimé les catégories « botte » et « sac », le modèle a atteint une précision de test de 87 % sur les huit catégories restantes. L'équipe d'auteur a ensuite recyclé le modèle pour apprendre la (nouvelle) classe "boot" dans deux conditions différentes, chacune répétée 10 fois :
- Focused Learning (FoL) ), c'est-à-dire uniquement nouveau " les classes "boot" sont présentées ;
- Apprentissage entièrement entrelacé (FIL), c'est-à-dire que toutes les catégories (nouvelles catégories + catégories précédemment apprises) sont présentées avec une probabilité égale. Dans les deux cas, un total de 180 images sont présentées par époque, avec des images identiques à chaque époque.
Le réseau a été testé sur un total de 9 000 images inédites, où l'ensemble de données de test était composé de 1 000 images par classe, sans "sac" inclus " catégorie. La formation s'arrête lorsque les performances du réseau atteignent l'asymptote.
Comme prévu, FoL a provoqué des interférences dans l'ancienne catégorie, tandis que FIL a surmonté cela (Figure 1, colonne 2). Comme mentionné ci-dessus, l'interférence de FoL avec les anciennes données varie selon la catégorie, ce qui faisait partie de l'inspiration originale de SWIL et suggère une relation de similarité hiérarchique entre la nouvelle catégorie « démarrage » et l'ancienne catégorie. Par exemple, le rappel des « baskets » (« baskets ») et des « sandales » (« sandales ») diminue plus rapidement que celui des « pantalons » (« pantalons ») (Figure 1, colonne 2), peut-être en raison de l'intégration de nouveau La classe "boot" modifie sélectivement les poids synaptiques représentant les classes "sneaker" et "sandales", provoquant davantage d'interférences.
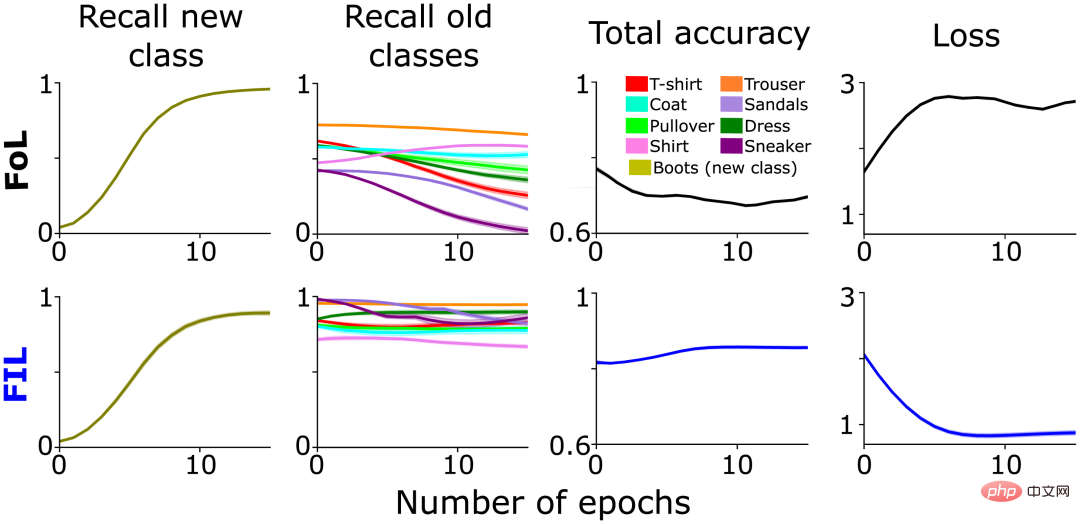
Figure 1 : Un réseau pré-entraîné apprend de nouvelles « Analyse comparative des performances de démarrage" : FoL (en haut) et FIL (en bas). De gauche à droite, rappel pour prédire les nouvelles classes « de démarrage » (olive), rappel pour les classes existantes (tracées dans différentes couleurs), précision globale (un score élevé signifie une faible erreur) et perte d'entropie croisée (une mesure globale de l'erreur) La courbe est fonction du nombre d'époques sur l'ensemble de données de test conservé.
Calculez la similarité entre les différentes catégories
Lorsque FoL apprend de nouvelles catégories, les performances de classification sur d'anciennes catégories similaires seront considérablement réduites.
La relation entre la similarité des attributs multi-catégories et l'apprentissage a déjà été explorée et montré que les réseaux linéaires profonds peuvent rapidement acquérir des attributs cohérents connus. En revanche, l’ajout de nouvelles branches d’attributs incohérents à une hiérarchie de catégories existante nécessite un apprentissage lent, progressif et échelonné.
Dans le travail actuel, l'équipe d'auteurs utilise la méthode proposée pour calculer la similarité au niveau des fonctionnalités. En bref, la similarité cosinusoïdale est calculée entre les vecteurs d'activation moyens par classe des classes existantes et nouvelles dans la couche cachée cible (généralement l'avant-dernière couche). La figure 2A montre la matrice de similarité calculée par l'équipe d'auteurs sur la base de l'avant-dernière fonction d'activation de couche du réseau pré-entraîné pour la nouvelle catégorie « boot » et l'ancienne catégorie basée sur l'ensemble de données Fashion MNIST.
La similitude entre les catégories est cohérente avec notre perception visuelle des objets. Par exemple, dans le diagramme de regroupement hiérarchique (Figure 2B), nous pouvons observer la relation entre la classe « boot » et les classes « sneaker » et « sandale », ainsi que la relation entre « chemise » (« chemise ») et « t-shirt » (« chemise »). La matrice de similarité (figure 2A) correspond exactement à la matrice de confusion (figure 2C). Plus la similarité est élevée, plus il est facile de confondre, par exemple, la catégorie « chemise » se confond facilement avec les catégories « T-shirt », « pull » et « veste », ce qui montre que la mesure de similarité prédit la dynamique d'apprentissage. du réseau neuronal.
Dans le graphique des résultats FoL de la section précédente (Figure 1), il existe une courbe de similarité de classe similaire dans la courbe de rappel de l'ancienne catégorie. Par rapport aux différentes anciennes catégories (« pantalons », etc.), FoL oublie rapidement les anciennes catégories similaires (« baskets » et « sandales ») lors de l'apprentissage de la nouvelle catégorie « bottes ».
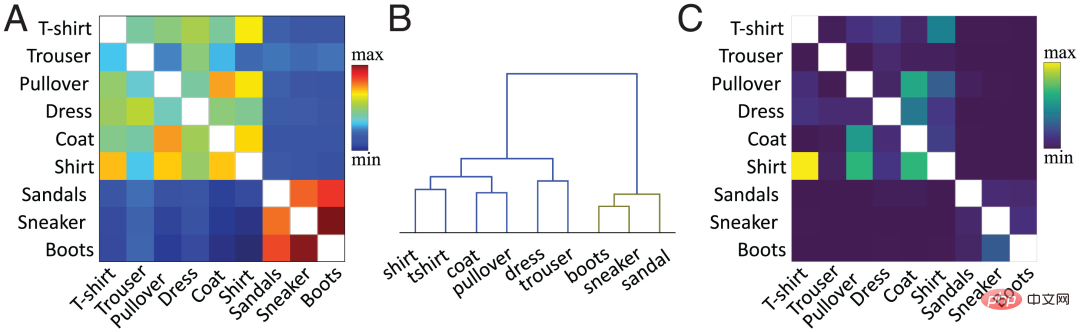
Figure 2 : (A) Le compte à rebours de l'équipe auteur selon le pré See More -réseau formé Fonction d'activation de la deuxième couche, matrice de similarité calculée des classes existantes et des nouvelles classes "de démarrage", où les valeurs diagonales (les similitudes pour la même classe sont tracées en blanc) sont supprimées. (B) Regroupement hiérarchique de la matrice de similarité dans A. (C) La matrice de confusion générée par l'algorithme FIL après l'entraînement pour apprendre la classe "boot". Valeurs diagonales supprimées pour plus de clarté.
Un réseau neuronal linéaire profond permet un apprentissage rapide et efficace de nouvelles choses
Ensuite sur les deux premières conditions Sur cette base, 3 nouvelles conditions ont été ajoutées pour étudier la nouvelle dynamique d'apprentissage de la classification, dans laquelle chaque condition était répétée 10 fois :
- FoL (total n=6 000 images/époque) ;
- FIL (total n=54 000 images/époque, 6 000 images/classe)
- Partial Interleaved Learning (PIL) utilise un petit sous-ensemble d'images (total n=) ; 350 images/époque, environ 39 images/classe), les images de chaque catégorie (nouvelle catégorie + catégorie existante) sont présentées avec une probabilité égale
- SWIL, chaque époque utilise et PIL recycle avec le même nombre total d'images, mais pondère les images existantes ; catégoriser les images en fonction de la similitude avec la (nouvelle) catégorie "boot" ;
- Equally Weighted Interleaved Learning (EqWIL), en utilisant le même numéro que SWIL. Les images de classe "boot" sont recyclées, mais avec les mêmes poids pour les images de classe existantes ( Figure 3A).
L'équipe d'auteur a utilisé le même ensemble de données de test mentionné ci-dessus (un total de n = 9 000 images). La formation est arrêtée lorsque les performances du réseau neuronal atteignent l'asymptote dans chaque condition. Bien que moins de données de formation soient utilisées par époque, la précision de la prédiction de la nouvelle classe « boot » prend plus de temps pour atteindre l'asymptote, et PIL a un rappel inférieur à celui de FIL (H = 7,27, P
Pour SWIL, le calcul de similarité est utilisé pour déterminer la proportion d'images d'anciennes catégories existantes à entrelacer. Sur cette base, l’équipe d’auteurs tire au hasard des images d’entrée avec des probabilités pondérées de chaque ancienne catégorie. Par rapport aux autres catégories, les catégories « baskets » et « sandales » sont les plus similaires, ce qui entraîne une proportion plus élevée d'entrelacements (Figure 3A).
Selon le dendrogramme (Figure 2B), l'équipe d'auteurs se réfère aux classes « baskets » et « sandales » comme d'anciennes classes similaires, et le reste comme d'anciennes classes différentes. Le rappel de nouvelle classe (colonne 1 de la figure 3B et colonne « Nouvelle classe » du tableau 1), la précision totale et la perte de PIL (H = 5,44, P0,05) sont comparables à FIL. L'apprentissage de la nouvelle classe « boot » dans EqWIL (H = 10,99, P
L'équipe de l'auteur utilise les deux méthodes suivantes pour comparer SWIL et FIL :
- Rapport de mémoire, qui est le rapport du nombre d'images stockées dans FIL et SWIL, indiquant une réduction de la quantité de données stockées ; Rapport d'accélération, qui est le rapport entre FIL et SWIL. Le rapport du nombre total de contenus présentés dans SWIL pour atteindre une précision saturée pour le rappel d'une nouvelle catégorie, indiquant une réduction du temps nécessaire pour apprendre une nouvelle catégorie.
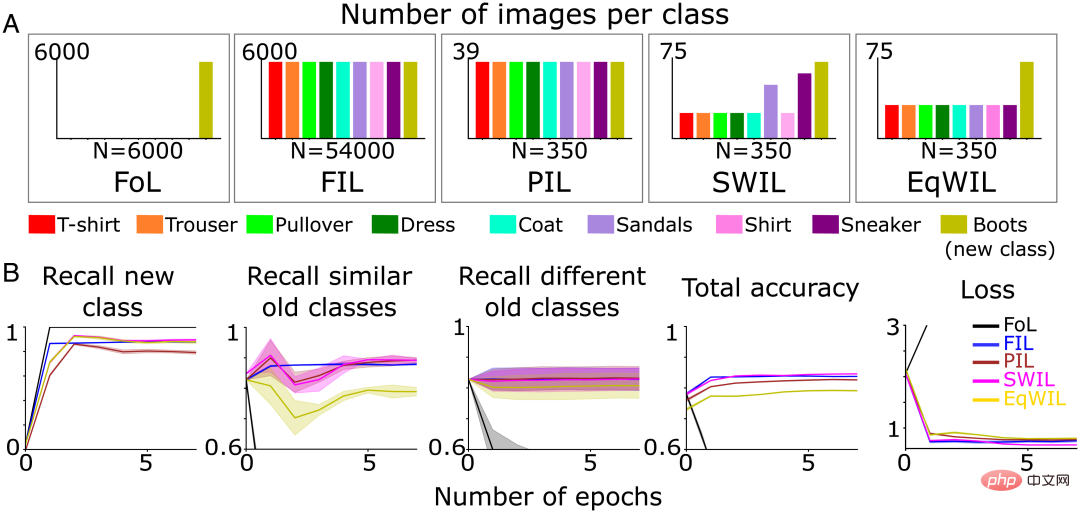
Figure 3 (A) L'équipe d'auteurs a pré-entraîné le réseau neuronal pour apprendre la nouvelle classe "boot" (vert olive) dans cinq conditions d'apprentissage différentes jusqu'à ce que la performance plafonne : 1) FoL (total n = 6 000 images/époque ); 2) FIL (total n = 54 000 images/époque) ; 3) PIL (total n = 350 images/époque) et 5) EqWIL ; (total n = 350 images/époque). (B) FoL (noir), FIL (bleu), PIL (marron), SWIL (magenta) et EqWIL (or) prédisent de nouvelles catégories, d'anciennes catégories similaires (« baskets » et « sandales ») et d'anciennes catégories différentes. Taux de rappel, la précision totale de la prédiction de toutes les catégories et la perte d'entropie croisée sur l'ensemble de données de test, où l'abscisse est le nombre d'époques.
Utilisation de SWIL pour apprendre de nouvelles catégories dans CNN basées sur CIFAR10 Ensuite, pour tester si SWIL peut fonctionner dans des environnements plus complexes, l'équipe d'auteur a formé un CNN non linéaire à 6 couches avec une couche de sortie entièrement connectée (Figure 4A) pour identifier les images des 8 catégories différentes restantes (sauf « chat » et « voiture ») dans l'ensemble de données CIFAR10. Ils ont également recyclé le modèle pour apprendre la classe « chat » dans 5 conditions d'entraînement différentes définies précédemment (FoL, FIL, PIL, SWIL et EqWIL). La figure 4C montre la répartition des images dans chaque catégorie sous 5 conditions. Le nombre total d'images par époque était de 2 400 pour les conditions SWIL, PIL et EqWIL, tandis que le nombre total d'images par époque était de 45 000 et 5 000 pour FIL et FoL respectivement. L'équipe de l'auteur a formé le réseau séparément pour chaque situation jusqu'à ce que les performances se stabilisent. Ils ont testé le modèle sur un total de 9000 images inédites (1000 images/classe, hors classe "voiture"). La figure 4B est la matrice de similarité calculée par l'équipe de l'auteur sur la base de l'ensemble de données CIFAR10. La classe « chat » s’apparente davantage à la classe « chien », tandis que les autres classes d’animaux appartiennent à la même branche (Figure 4B à gauche).D'après l'arborescence (Figure 4B), les catégories « camion » (« camion »), « navire » (« navire ») et « avion » (« avion ») sont appelées différentes anciennes catégories, à l'exception du « chat ». " catégorie Les catégories d'animaux restantes sont appelées anciennes catégories similaires. Pour FoL, le modèle apprend la nouvelle classe "cat" mais oublie l'ancienne classe. Semblable aux résultats de l'ensemble de données Fashion-MNIST, il existe des gradients d'interférence à la fois dans la classe « chien » (la plus similaire à la classe « chat ») et dans la classe « camion » (la moins similaire à la classe « chat »). ), parmi lesquels la classe « chien » oublié a le taux d'oubli le plus élevé, tandis que la catégorie « camion » a le taux d'oubli le plus faible.
Comme le montre la figure 4D, l'algorithme FIL surmonte les interférences catastrophiques lors de l'apprentissage de la nouvelle classe « chat ». Pour l'algorithme PIL, le modèle utilise 18,75 fois la quantité de données à chaque époque pour apprendre la nouvelle classe « chat », mais le taux de rappel de la classe « chat » est supérieur à celui de FIL (H=5,72, P0,05 ; voir Tableau 2 et Figure 4D). SWIL a un taux de rappel plus élevé pour la nouvelle classe « chat » que PIL (H=7,89, P
FIL, PIL, SWIL et EqWIL ont des performances similaires dans la prédiction de différentes anciennes catégories (H=0,6, P>0,05). SWI intègre mieux la nouvelle classe « cat » que PIL et aide à surmonter les interférences d’observation dans EqWIL. Par rapport à FIL, l'utilisation de SWIL pour apprendre de nouvelles catégories est plus rapide, rapport d'accélération = 31,25x (45 000 × 10/(2 400 × 6)), tout en utilisant moins de données (rapport de mémoire = 18,75x). Ces résultats démontrent que SWIL peut apprendre efficacement de nouvelles catégories de choses, même sur des CNN non linéaires et des ensembles de données plus réalistes.
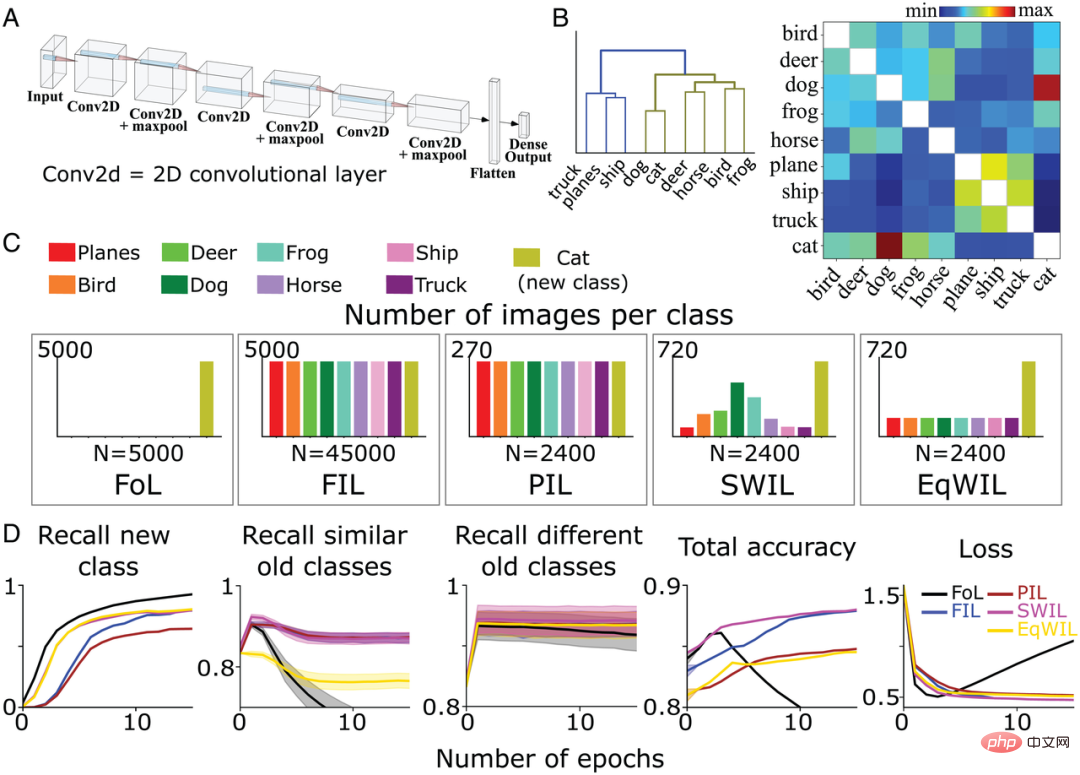
Figure 4 : (A) L'équipe d'auteurs utilise un CNN non linéaire à 6 couches avec une couche de sortie entièrement connectée pour apprendre 8 catégories de choses dans l'ensemble de données CIFAR10. (B) La matrice de similarité (à droite) est calculée par l'équipe d'auteurs sur la base de la fonction d'activation de la dernière couche convolutive après présentation de la nouvelle classe « chat ». L'application du regroupement hiérarchique à la matrice de similarité (à gauche) montre le regroupement des deux catégories d'hyperonymes Animaux (vert olive) et Véhicules (bleu) dans un dendrogramme. (C) L'équipe d'auteurs a pré-entraîné CNN pour apprendre la nouvelle classe « chat » (vert olive) dans 5 conditions différentes jusqu'à ce que les performances se stabilisent : 1) FoL (total n = 5 000 images/époque 2) FIL (total n) ; = 45 000 images/époque) ; 3) PIL (total n = 2 400 images/époque) ; 4) SWIL (total n = 2 400 images/époque) ; Chaque condition a été répétée 10 fois. (D) FoL (noir), FIL (bleu), PIL (marron), SWIL (magenta) et EqWIL (or) prédisent de nouvelles classes, d'anciennes classes similaires (autres classes d'animaux dans l'ensemble de données CIFAR10) et différentes anciennes classes (Le rappel taux de "avion", "navire" et "camion"), la précision de prédiction totale de toutes les catégories et la perte d'entropie croisée sur l'ensemble de données de test, où l'abscisse est le nombre d'époques.
L'impact de la cohérence du nouveau contenu avec les anciennes catégories sur le temps d'apprentissage et les données requises
Si un nouveau contenu peut être ajouté à une catégorie précédemment apprise sans nécessiter de modifications majeures du réseau, on dit que les deux être cohérent. Sur la base de ce cadre, l'apprentissage de nouvelles catégories qui interfèrent avec moins de catégories existantes (cohérence élevée) peut être plus facilement intégré au réseau que l'apprentissage de nouvelles catégories qui interfèrent avec plusieurs catégories existantes (cohérence faible).
Pour tester l'inférence ci-dessus, l'équipe d'auteurs a utilisé le CNN pré-entraîné de la section précédente pour apprendre une nouvelle catégorie « voiture » dans les 5 conditions d'apprentissage décrites précédemment. La figure 5A montre la matrice de similarité de la catégorie « voiture ». Par rapport aux autres catégories existantes, « voiture » et « camion », « navire » et « avion » se trouvent sous le même nœud de niveau, ce qui indique qu'ils sont plus similaires. Pour une confirmation supplémentaire, l’équipe d’auteurs a effectué une analyse de visualisation de réduction de dimensionnalité t-SNE sur la couche d’activation utilisée pour le calcul de similarité (Figure 5B). L'étude a révélé que la classe « voiture » chevauchait de manière significative avec d'autres classes de véhicules (« camion », « bateau » et « avion »), tandis que la classe « chat » chevauchait d'autres classes d'animaux (« chien », « grenouille », "cheval" ("cheval"), "oiseau" ("oiseau") et "cerf" ("cerf")) se chevauchent.
Conformément aux attentes de l'équipe de l'auteur, FoL produira des interférences catastrophiques lors de l'apprentissage de la catégorie « voiture », et interfère davantage avec les anciennes catégories similaires. Ceci est surmonté en utilisant FIL (Figure 5D). Pour PIL, SWIL et EqWIL, il existe un total de n = 2 000 images par époque (Figure 5C). Grâce à l'algorithme SWIL, le modèle peut apprendre de nouvelles catégories de « voitures » avec une précision similaire à FIL (H=0,79, P>0,05), avec une interférence minimale avec les catégories existantes (y compris les catégories similaires et différentes). Comme le montre la colonne 2 de la figure 5D, en utilisant EqWIL, le modèle apprend la nouvelle classe « voiture » de la même manière que SWIL, mais avec un degré d'interférence plus élevé avec d'autres catégories similaires (par exemple, « camion ») (H = 53,81). , P
Par rapport à FIL, SWIL peut apprendre de nouveaux contenus plus rapidement, taux d'accélération = 48,75x (45 000 × 12/(2 000 × 6)), et les besoins en mémoire sont réduits, taux de mémoire = 22,5x. Par rapport à « chat » (48,75x contre 31,25x), « voiture » peut apprendre plus rapidement en entrelaçant moins de classes (telles que « camion », « bateau » et « avion »), tandis que « chat » a plus de nombreuses catégories (telles que car "chien", "grenouille", "cheval", "grenouille" et "cerf") se chevauchent. Ces expériences de simulation montrent que la quantité de données sur les anciennes catégories nécessaire au croisement et à l'apprentissage accéléré de nouvelles catégories dépend de la cohérence des nouvelles informations avec les connaissances antérieures.
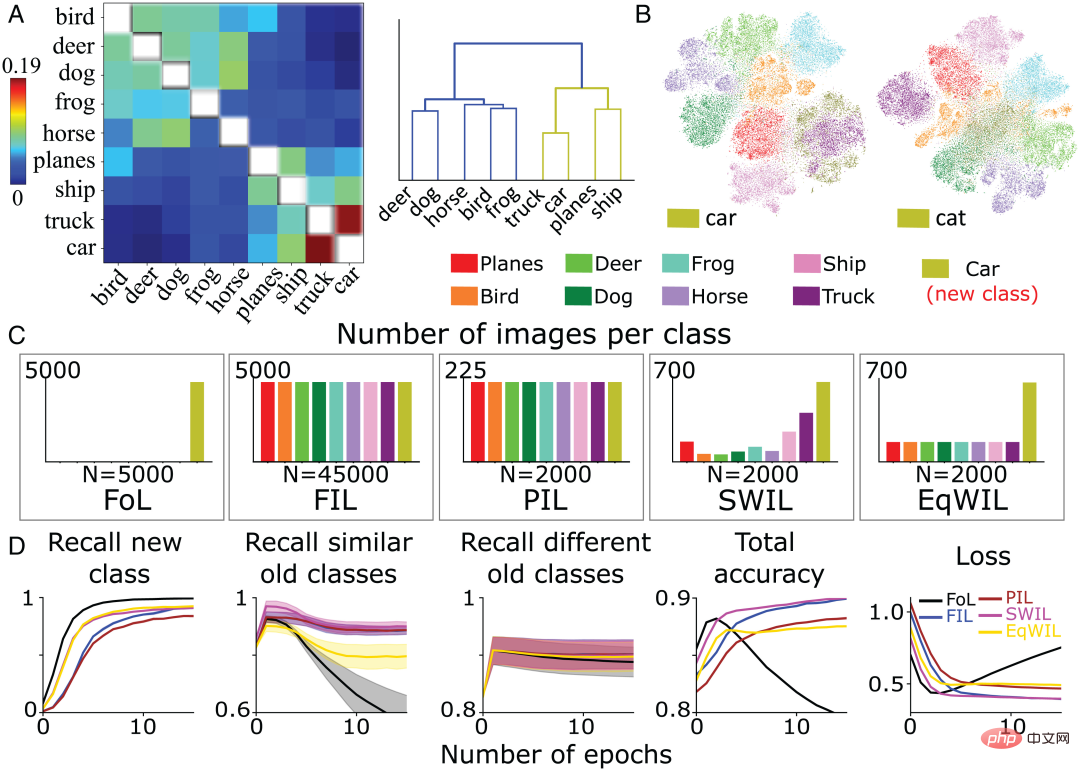
Figure 5 : (A) L'équipe de l'auteur a calculé la matrice de similarité (à gauche) sur la base de l'avant-dernière fonction d'activation de couche et a effectué un regroupement hiérarchique de la matrice de similarité après avoir présenté la nouvelle catégorie « voiture ». photo du résultat final (à droite). (B) Le modèle apprend respectivement de nouvelles catégories « voiture » et « chat ». Une fois que la dernière couche convolutive a passé la fonction d'activation, l'équipe d'auteur effectue la visualisation des résultats de réduction de dimensionnalité t-SNE. (C) L'équipe d'auteurs a pré-entraîné CNN pour apprendre la nouvelle classe « voiture » (vert olive) dans 5 conditions différentes jusqu'à ce que les performances se stabilisent : 1) FoL (total n = 5 000 images/époque 2) FIL (total n) ; = 45 000 images/époque) ; 3) PIL (total n = 2 000 images/époque) ; 4) SWIL (total n = 2 000 images/époque) ; (D) FoL (noir), FIL (bleu), PIL (marron), SWIL (magenta) et EqWIL (or) prédisent de nouvelles catégories, d'anciennes catégories similaires (« avion », « navire » et « camion ») et le rappel le taux de différentes anciennes catégories (autres catégories d'animaux dans l'ensemble de données CIFAR10), la précision totale de la prédiction de toutes les catégories et la perte d'entropie croisée sur l'ensemble de données de test, où l'abscisse est le nombre d'époques. Chaque graphique montre la moyenne de 10 répétitions et la zone ombrée est de ± 1 SEM.
Utilisation de SWIL pour l'apprentissage de séquences
Ensuite, l'équipe d'auteurs a testé si un nouveau contenu présenté sous forme de sérialisation (cadre d'apprentissage de séquence) pouvait être appris à l'aide de SWIL. À cette fin, ils ont adopté le modèle CNN entraîné de la figure 4 pour apprendre la classe « chat » (tâche 1) dans l'ensemble de données CIFAR10 dans les conditions FIL et SWIL, formés uniquement sur les 9 catégories restantes de CIFAR10, puis formés sur chaque condition. Entraînez ensuite le modèle pour apprendre la nouvelle classe « voiture » (tâche 2). La première colonne de la figure 6 montre la répartition du nombre d'images dans d'autres catégories lors de l'apprentissage de la catégorie « voiture » dans les conditions SWIL (un total de n = 2500 images/époque). Notez que la prédiction de la classe « chat » entraîne également un apprentissage croisé de la nouvelle classe « voiture ». Étant donné que les performances du modèle sont meilleures dans les conditions FIL, SWIL n'a comparé les résultats qu'avec FIL.
Comme le montre la figure 6, la capacité de SWIL à prédire les nouvelles et anciennes catégories est équivalente à celle de FIL (H=14,3, P>0,05). Le modèle utilise l'algorithme SWIL pour apprendre plus rapidement de nouvelles catégories de « voitures », avec un taux d'accélération de 45x (50 000 × 20/(2 500 × 8)), et l'empreinte mémoire de chaque époque est 20 fois inférieure à celle de FIL. Lorsque le modèle apprend les catégories « chat » et « voiture », le nombre d'images utilisées par époque dans la condition SWIL (le taux de mémoire et le taux d'accélération sont respectivement de 18,75x et 20x) est inférieur à la totalité des données utilisées par époque dans la condition FIL. conditions définies (taux de mémoire et taux d'accélération de 31,25x et 45x respectivement) tout en apprenant rapidement de nouvelles catégories. En élargissant cette idée, à mesure que le nombre de catégories apprises continue d'augmenter, l'équipe d'auteurs s'attend à ce que le temps d'apprentissage et le stockage des données du modèle soient réduits de façon exponentielle, lui permettant d'apprendre de nouvelles catégories plus efficacement, reflétant peut-être ce qui se passe lorsque le cerveau humain apprend réellement.
Les résultats expérimentaux montrent que SWIL peut intégrer plusieurs nouvelles classes dans le cadre d'apprentissage séquentiel, permettant au réseau neuronal de continuer à apprendre sans interférence.
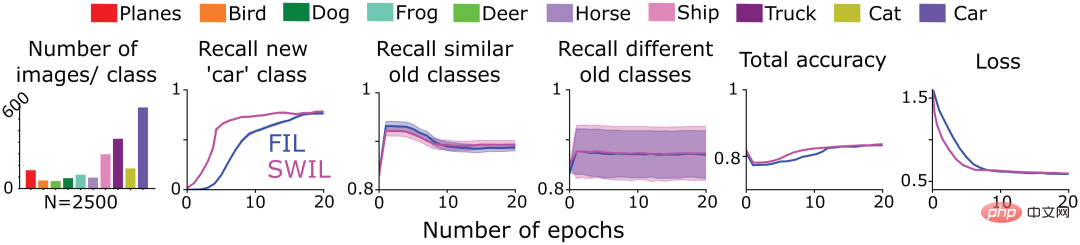
Figure 6 : L'équipe d'auteurs a formé un CNN à 6 couches pour apprendre la nouvelle classe « chat » (tâche 1), puis apprendre la classe « voiture » (tâche 2) jusqu'à ce que les performances convergent dans les deux cas suivants, Yu Stable : 1) FIL : contient toutes les anciennes catégories (dessinées dans des couleurs différentes) et les nouvelles catégories ("chat"/"voiture") présentées avec la même probabilité 2) SWIL : basé sur des images avec de nouvelles ; catégories ("chat"/"voiture") et utilisent proportionnellement d'anciens exemples de catégories. Incluez également la classe « chat » apprise dans la tâche 1 et pondérez-la en fonction de la similitude de la classe « voiture » apprise dans la tâche 2. La première sous-figure montre la distribution du nombre d'images utilisées à chaque époque. Les sous-figures restantes indiquent respectivement les taux de rappel de FIL (bleu) et de SWIL (magenta) dans la prédiction de nouvelles catégories, d'anciennes catégories similaires et d'anciennes catégories différentes, et dans la prédiction des nouvelles catégories. taux de rappel de toutes les catégories. La précision globale et la perte d'entropie croisée sur l'ensemble de données de test, où l'abscisse est le nombre d'époques.
Utilisez SWIL pour élargir la distance entre les catégories et réduire le temps d'apprentissage et le volume de données
L'équipe d'auteurs a finalement testé la généralisation de l'algorithme SWIL et vérifié s'il peut apprendre des ensembles de données incluant plus de catégories, et s'il est applicable aux architectures de réseau plus complexes.
Ils ont formé un modèle CNN complexe-VGG19 (19 couches au total) sur l'ensemble de données CIFAR100 (ensemble d'entraînement 500 images/classe, ensemble de test 100 images/classe) et ont appris 90 catégories. Le réseau est ensuite recyclé pour apprendre de nouvelles catégories. La figure 7A montre la matrice de similarité calculée par l'équipe de l'auteur sur la base de la fonction d'activation de l'avant-dernière couche basée sur l'ensemble de données CIFAR100. Comme le montre la figure 7B, la nouvelle classe « train » est compatible avec de nombreuses classes de transport existantes telles que « bus » (« bus »), « tramway » (« tramway ») et « tracteur » (« tracteur »), etc. ) sont très similaires.
Par rapport à FIL, SWIL peut apprendre de nouvelles choses plus rapidement (rapport d'accélération = 95,45x (45500×6/(1430×2))) et utiliser beaucoup moins de données (rapport de mémoire = 31,8x), et les performances sont fondamentalement le même (H = 8,21, P>0,05). Comme le montre la figure 7C, dans les conditions de PIL (H = 10,34, P
Dans le même temps, afin d'explorer si la grande distance entre les représentations de différentes catégories constitue une condition de base pour accélérer l'apprentissage des modèles, l'équipe d'auteur a en outre formé deux modèles de réseaux neuronaux :
- CNN à 6 couches (avec Le graphique 4 basé sur CIFAR10 est le même que la figure 5 );
- VGG11 (11 couches) apprend 90 catégories dans l'ensemble de données CIFAR100 et n'entraîne la nouvelle classe « train » que sous deux conditions : FIL et SWIL.
Comme le montre la figure 7B, pour les deux modèles de réseau ci-dessus, le chevauchement entre la nouvelle classe « train » et la catégorie transport est plus élevé, mais par rapport au modèle VGG19, la séparation de chaque catégorie est plus faible. Par rapport à FIL, la vitesse d'apprentissage de SWIL est à peu près linéaire avec l'augmentation du nombre de couches (pente = 0,84). Ce résultat montre qu’augmenter la distance de représentation entre les catégories peut accélérer l’apprentissage et réduire la charge mémoire.
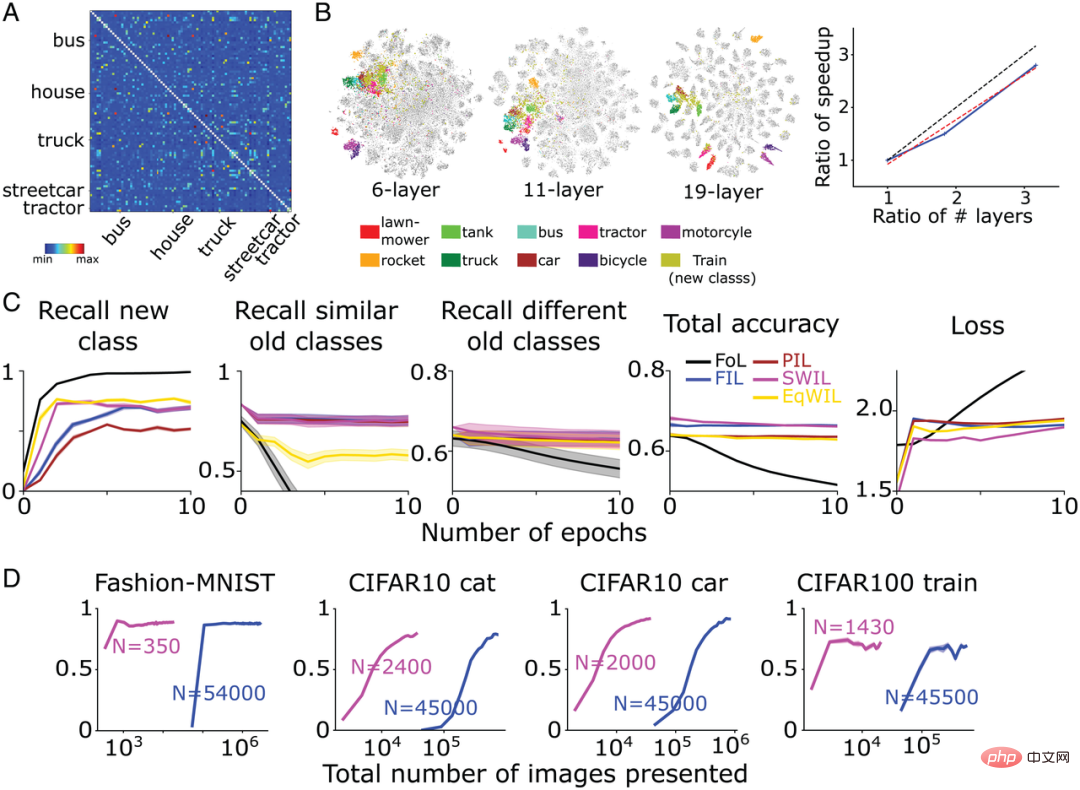
Figure 7 : (A) Après que VGG19 ait appris la nouvelle classe « train », la matrice de similarité calculée par l'équipe d'auteurs sur la base de l'avant-dernière fonction d'activation de couche. Les cinq catégories « camion », « tramway », « bus », « maison » et « tracteur » sont les plus proches du « train ». Excluez les éléments diagonaux de la matrice de similarité (similarité = 1). (B, à gauche) Résultats de visualisation de la réduction de dimensionnalité t-SNE de l’équipe d’auteurs pour les réseaux CNN, VGG11 et VGG19 à 6 couches après avoir passé l’avant-dernière couche de fonction d’activation. (B, à droite) L'axe vertical représente le rapport d'accélération (FIL/SWIL) et l'axe horizontal représente le rapport du nombre de couches de 3 réseaux différents par rapport au CNN à 6 couches. La ligne pointillée noire, la ligne pointillée rouge et la ligne continue bleue représentent respectivement la ligne standard avec une pente = 1, la ligne la mieux ajustée et les résultats de la simulation. (C) Situation d'apprentissage du modèle VGG19 : FoL (noir), FIL (bleu), PIL (marron), SWIL (magenta) et EqWIL (or) prédisent une nouvelle classe "train", une ancienne classe similaire (classe de transport) Et le rappel le taux de différentes anciennes catégories (à l'exception de la catégorie de transport), la précision totale de la prédiction de toutes les catégories et la perte d'entropie croisée sur l'ensemble de données de test, où l'abscisse est le numéro d'époque. Chaque graphique montre la moyenne de 10 répétitions et la zone ombrée est de ± 1 SEM. (D) De gauche à droite, le modèle prédit le rappel de la classe « boot » Fashion-MNIST (Fig. 3), de la classe « chat » CIFAR10 (Fig. 4), de la classe « voiture » CIFAR10 (Fig. 5) et Classe « train » CIFAR100 Taux en fonction du nombre total d'images (échelle log) utilisées par SWIL (magenta) et FIL (bleu). « N » représente le nombre total d'images utilisées à chaque époque dans chaque condition d'apprentissage (y compris les nouvelles et anciennes catégories).
Si le réseau est formé sur davantage de classes qui ne se chevauchent pas et que la distance entre les représentations est plus grande, la vitesse sera-t-elle encore améliorée ?
À cette fin, l'équipe d'auteur a adopté un réseau linéaire profond (utilisé pour l'exemple Fashion-MNIST dans la figure 1-3) et l'a formé pour apprendre un réseau composé de 8 catégories Fashion-MNIST (hors « sacs » » et catégories « démarrage ») et les catégories 10 Digit-MNIST, puis entraînez le réseau à apprendre la nouvelle catégorie « démarrage ».
Conformément aux attentes de l'équipe auteur, « boot » s'apparente davantage aux anciennes catégories « sandales » et « sneaker », suivies du reste de la catégorie Fashion-MNIST (comprenant principalement des images de vêtements), et enfin de la Catégorie Digit-MNIST (incluant principalement des images numériques).
Sur cette base, l'équipe d'auteurs a d'abord entrelacé des échantillons d'anciennes catégories plus similaires, puis entrelacé des échantillons de catégories Fashion-MNIST et Digit-MNIST (un total de n = 350 images/époque). Les résultats expérimentaux montrent que, comme FIL, SWIL peut rapidement apprendre le contenu de nouvelles catégories sans interférence, mais utilise un sous-ensemble de données beaucoup plus petit, avec un taux de mémoire de 325,7x (114 000/350) et un taux d'accélération de 162,85x (228 000/228 000). /350). L'équipe d'auteurs a observé une accélération de 2,1x (162,85/77,1) dans les résultats actuels, avec une augmentation de 2,25x du nombre de catégories (18/8) par rapport à l'ensemble de données Fashion-MNIST.
Les résultats expérimentaux de cette section aident à déterminer que SWIL peut être appliqué à des ensembles de données plus complexes (CIFAR100) et à des modèles de réseaux neuronaux (VGG19), prouvant la généralisation de l'algorithme. Nous démontrons également que l'élargissement de la distance interne entre les catégories ou l'augmentation du nombre de catégories qui ne se chevauchent pas peuvent encore augmenter la vitesse d'apprentissage et réduire la charge mémoire.
Résumé
Les réseaux de neurones artificiels sont confrontés à des défis importants en matière d'apprentissage continu, présentant souvent des interférences catastrophiques. Pour surmonter ce problème, de nombreuses études ont eu recours à l'apprentissage entièrement entrelacé (FIL), dans lequel les contenus nouveaux et anciens font l'objet d'un apprentissage croisé pour former conjointement le réseau. FIL nécessite d'entrelacer toutes les informations existantes à chaque fois qu'il apprend de nouvelles informations, ce qui en fait un processus biologiquement invraisemblable et long. Récemment, certaines recherches ont montré que FIL n'était peut-être pas nécessaire et que seul l'entrelacement d'anciens contenus présentant une similitude de représentation substantielle avec le nouveau contenu, c'est-à-dire l'utilisation de la méthode d'apprentissage entrelacé pondéré par similarité (SWIL) peut obtenir le même effet d'apprentissage. Cependant, des inquiétudes ont été exprimées quant à l'évolutivité de SWIL.
Cet article étend l'algorithme SWIL et le teste sur la base de différents ensembles de données (Fashion-MNIST, CIFAR10 et CIFAR100) et de modèles de réseaux neuronaux (réseau linéaire profond et CNN). Dans toutes les conditions, l’apprentissage entrelacé pondéré par similarité (SWIL) et l’apprentissage entrelacé à pondération égale (EqWIL) ont obtenu de meilleurs résultats dans l’apprentissage de nouvelles catégories que l’apprentissage partiellement entrelacé (PIL). Ceci est conforme aux attentes de l’équipe d’auteurs, car SWIL et EqWIL augmentent la fréquence relative des nouvelles catégories par rapport aux anciennes catégories.
Cet article démontre également qu'une sélection minutieuse et un entrelacement de contenus similaires réduisent les interférences catastrophiques avec d'anciennes catégories similaires par rapport au sous-échantillonnage égal des catégories existantes (c'est-à-dire la méthode EqWIL). SWIL fonctionne de manière similaire à FIL dans la prédiction des catégories nouvelles et existantes, mais accélère considérablement l'apprentissage de nouveaux contenus (Figure 7D) tout en réduisant considérablement les données de formation requises. SWIL peut apprendre de nouvelles catégories dans un cadre d'apprentissage séquentiel, démontrant ainsi ses capacités de généralisation.
Enfin, si elle présente moins de chevauchement (distance plus grande) avec des catégories précédemment apprises qu'une nouvelle catégorie présentant des similitudes avec de nombreuses anciennes catégories, le temps d'intégration peut être raccourci et l'efficacité des données est plus élevée. Dans l’ensemble, les résultats expérimentaux suggèrent que le cerveau surmonte réellement l’une des principales faiblesses du modèle CLST original en réduisant le temps d’entraînement irréaliste.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 YOLO est immortel ! YOLOv9 est sorti : performances et vitesse SOTA~
Feb 26, 2024 am 11:31 AM
YOLO est immortel ! YOLOv9 est sorti : performances et vitesse SOTA~
Feb 26, 2024 am 11:31 AM
Les méthodes d'apprentissage profond d'aujourd'hui se concentrent sur la conception de la fonction objectif la plus appropriée afin que les résultats de prédiction du modèle soient les plus proches de la situation réelle. Dans le même temps, une architecture adaptée doit être conçue pour obtenir suffisamment d’informations pour la prédiction. Les méthodes existantes ignorent le fait que lorsque les données d’entrée subissent une extraction de caractéristiques couche par couche et une transformation spatiale, une grande quantité d’informations sera perdue. Cet article abordera des problèmes importants lors de la transmission de données via des réseaux profonds, à savoir les goulots d'étranglement de l'information et les fonctions réversibles. Sur cette base, le concept d'information de gradient programmable (PGI) est proposé pour faire face aux différents changements requis par les réseaux profonds pour atteindre des objectifs multiples. PGI peut fournir des informations d'entrée complètes pour la tâche cible afin de calculer la fonction objectif, obtenant ainsi des informations de gradient fiables pour mettre à jour les pondérations du réseau. De plus, un nouveau cadre de réseau léger est conçu
 Un aperçu des trois architectures de puces traditionnelles pour la conduite autonome dans un seul article
Apr 12, 2023 pm 12:07 PM
Un aperçu des trois architectures de puces traditionnelles pour la conduite autonome dans un seul article
Apr 12, 2023 pm 12:07 PM
Les puces IA actuelles sont principalement divisées en trois catégories : GPU, FPGA et ASIC. Les GPU et les FPGA sont des architectures de puces relativement matures à un stade précoce et sont des puces à usage général. ASIC est une puce personnalisée pour des scénarios d'IA spécifiques. L’industrie a confirmé que les processeurs ne sont pas adaptés au calcul de l’IA, mais qu’ils sont également essentiels dans les applications d’IA. Comparaison de l'architecture de la solution GPU entre le GPU et le CPU Le CPU suit l'architecture von Neumann, dont le cœur est le stockage des programmes/données et l'exécution séquentielle en série. Par conséquent, l'architecture du CPU nécessite une grande quantité d'espace pour placer l'unité de stockage (Cache) et l'unité de contrôle (Control). En revanche, l'unité de calcul (ALU) n'occupe qu'une petite partie, le CPU est donc performant à grande échelle. calcul parallèle.
 'Le propriétaire de Bilibili UP a créé avec succès le premier réseau neuronal au monde basé sur la pierre rouge, qui a fait sensation sur les réseaux sociaux et a été salué par Yann LeCun.'
May 07, 2023 pm 10:58 PM
'Le propriétaire de Bilibili UP a créé avec succès le premier réseau neuronal au monde basé sur la pierre rouge, qui a fait sensation sur les réseaux sociaux et a été salué par Yann LeCun.'
May 07, 2023 pm 10:58 PM
Dans Minecraft, la redstone est un élément très important. C'est un matériau unique dans le jeu. Les interrupteurs, les torches de redstone et les blocs de redstone peuvent fournir une énergie semblable à l'électricité aux fils ou aux objets. Les circuits Redstone peuvent être utilisés pour construire des structures permettant de contrôler ou d'activer d'autres machines. Ils peuvent eux-mêmes être conçus pour répondre à une activation manuelle par les joueurs, ou ils peuvent émettre des signaux à plusieurs reprises ou répondre à des changements provoqués par des non-joueurs, tels que le mouvement des créatures. et des objets. Chute, croissance des plantes, jour et nuit, et plus encore. Par conséquent, dans mon monde, Redstone peut contrôler de nombreux types de machines, allant des machines simples telles que les portes automatiques, les interrupteurs d'éclairage et les alimentations stroboscopiques, aux énormes ascenseurs, aux fermes automatiques, aux petites plates-formes de jeu et même aux machines intégrées aux jeux. Récemment, la station B UP principale @
 Multi-chemin, multi-domaine, tout compris ! Google AI publie le modèle général d'apprentissage multi-domaines MDL
May 28, 2023 pm 02:12 PM
Multi-chemin, multi-domaine, tout compris ! Google AI publie le modèle général d'apprentissage multi-domaines MDL
May 28, 2023 pm 02:12 PM
Les modèles d'apprentissage profond pour les tâches de vision (telles que la classification d'images) sont généralement formés de bout en bout avec des données provenant d'un seul domaine visuel (telles que des images naturelles ou des images générées par ordinateur). Généralement, une application qui effectue des tâches de vision pour plusieurs domaines doit créer plusieurs modèles pour chaque domaine distinct et les former indépendamment. Les données ne sont pas partagées entre différents domaines. Lors de l'inférence, chaque modèle gérera un domaine spécifique. Même s'ils sont orientés vers des domaines différents, certaines caractéristiques des premières couches entre ces modèles sont similaires, de sorte que la formation conjointe de ces modèles est plus efficace. Cela réduit la latence et la consommation d'énergie, ainsi que le coût de la mémoire lié au stockage de chaque paramètre du modèle. Cette approche est appelée apprentissage multidomaine (MDL). De plus, les modèles MDL peuvent également surpasser les modèles simples.
 1,3 ms prend 1,3 ms ! La dernière architecture de réseau neuronal mobile open source de Tsinghua, RepViT
Mar 11, 2024 pm 12:07 PM
1,3 ms prend 1,3 ms ! La dernière architecture de réseau neuronal mobile open source de Tsinghua, RepViT
Mar 11, 2024 pm 12:07 PM
Adresse papier : https://arxiv.org/abs/2307.09283 Adresse code : https://github.com/THU-MIG/RepViTRepViT fonctionne bien dans l'architecture ViT mobile et présente des avantages significatifs. Ensuite, nous explorons les contributions de cette étude. Il est mentionné dans l'article que les ViT légers fonctionnent généralement mieux que les CNN légers sur les tâches visuelles, principalement en raison de leur module d'auto-attention multi-têtes (MSHA) qui permet au modèle d'apprendre des représentations globales. Cependant, les différences architecturales entre les ViT légers et les CNN légers n'ont pas été entièrement étudiées. Dans cette étude, les auteurs ont intégré des ViT légers dans le système efficace.
 Afin de fournir un nouveau système de référence et d'évaluation de questions-réponses scientifiques et complexes pour les grands modèles, l'UNSW, Argonne, l'Université de Chicago et d'autres institutions ont lancé conjointement le cadre SciQAG.
Jul 25, 2024 am 06:42 AM
Afin de fournir un nouveau système de référence et d'évaluation de questions-réponses scientifiques et complexes pour les grands modèles, l'UNSW, Argonne, l'Université de Chicago et d'autres institutions ont lancé conjointement le cadre SciQAG.
Jul 25, 2024 am 06:42 AM
L'ensemble de données ScienceAI Question Answering (QA) joue un rôle essentiel dans la promotion de la recherche sur le traitement du langage naturel (NLP). Des ensembles de données d'assurance qualité de haute qualité peuvent non seulement être utilisés pour affiner les modèles, mais également évaluer efficacement les capacités des grands modèles linguistiques (LLM), en particulier la capacité à comprendre et à raisonner sur les connaissances scientifiques. Bien qu’il existe actuellement de nombreux ensembles de données scientifiques d’assurance qualité couvrant la médecine, la chimie, la biologie et d’autres domaines, ces ensembles de données présentent encore certaines lacunes. Premièrement, le formulaire de données est relativement simple, et la plupart sont des questions à choix multiples. Elles sont faciles à évaluer, mais limitent la plage de sélection des réponses du modèle et ne peuvent pas tester pleinement la capacité du modèle à répondre aux questions scientifiques. En revanche, les questions et réponses ouvertes
 Savez-vous que les programmeurs seront en déclin dans quelques années ?
Nov 08, 2023 am 11:17 AM
Savez-vous que les programmeurs seront en déclin dans quelques années ?
Nov 08, 2023 am 11:17 AM
Le magazine "ComputerWorld" a écrit un article disant que "la programmation disparaîtra d'ici 1960" parce qu'IBM a développé un nouveau langage FORTRAN, qui permet aux ingénieurs d'écrire les formules mathématiques dont ils ont besoin, puis de les soumettre à l'ordinateur pour que la programmation se termine. Picture Quelques années plus tard, nous avons entendu un nouveau dicton : tout homme d'affaires peut utiliser des termes commerciaux pour décrire ses problèmes et dire à l'ordinateur quoi faire. Grâce à ce langage de programmation appelé COBOL, les entreprises n'ont plus besoin de programmeurs. Plus tard, il est dit qu'IBM a développé un nouveau langage de programmation appelé RPG qui permet aux employés de remplir des formulaires et de générer des rapports, de sorte que la plupart des besoins de programmation de l'entreprise puissent être satisfaits grâce à lui.
 Implémentation d'OpenAI CLIP sur des ensembles de données personnalisés
Sep 14, 2023 am 11:57 AM
Implémentation d'OpenAI CLIP sur des ensembles de données personnalisés
Sep 14, 2023 am 11:57 AM
En janvier 2021, OpenAI a annoncé deux nouveaux modèles : DALL-E et CLIP. Les deux modèles sont des modèles multimodaux qui relient le texte et les images d’une manière ou d’une autre. Le nom complet de CLIP est Contrastive Language-Image Pre-training (ContrastiveLanguage-ImagePre-training), qui est une méthode de pré-formation basée sur des paires texte-image contrastées. Pourquoi introduire CLIP ? Parce que le StableDiffusion actuellement populaire n'est pas un modèle unique, mais se compose de plusieurs modèles. L'un des composants clés est l'encodeur de texte, qui est utilisé pour encoder la saisie de texte de l'utilisateur. Cet encodeur de texte est l'encodeur de texte CL dans le modèle CLIP.
