
 Périphériques technologiques
IA
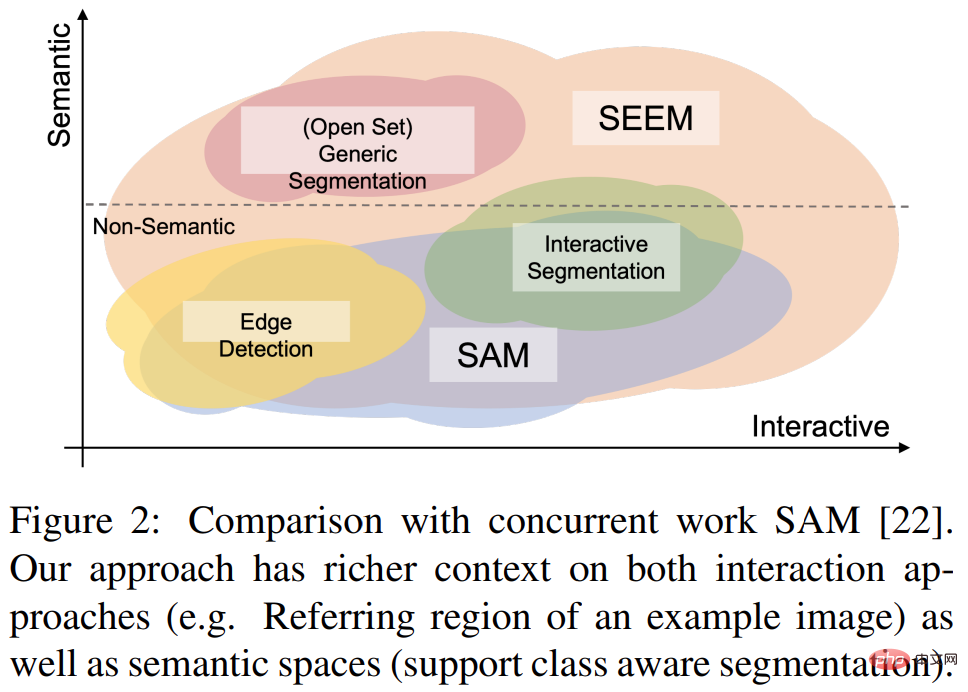
SEEM, un modèle de segmentation universel créé par une équipe chinoise, porte la segmentation ponctuelle à un nouveau niveau
Périphériques technologiques
IA
SEEM, un modèle de segmentation universel créé par une équipe chinoise, porte la segmentation ponctuelle à un nouveau niveau
SEEM, un modèle de segmentation universel créé par une équipe chinoise, porte la segmentation ponctuelle à un nouveau niveau

Au début du mois, Meta a publié le modèle d'IA « Segment Anything » - Segment Anything Model (SAM). SAM est considéré comme un modèle de base universel pour la segmentation d'images. Il apprend les concepts généraux sur les objets et peut générer des masques pour n'importe quel objet dans n'importe quelle image ou vidéo, y compris les objets et les types d'images qui n'ont pas été rencontrés au cours du processus de formation. Cette capacité de « migration sans échantillon » est étonnante, et certains disent même que le domaine CV a inauguré un « moment GPT-3 ».
Récemment, un nouveau document "Segment Everything Everywhere All at Once" a de nouveau attiré l'attention. Dans cet article, plusieurs chercheurs chinois de l’Université du Wisconsin-Madison, de Microsoft et de l’Université des sciences et technologies de Hong Kong ont proposé un nouveau modèle d’interaction basé sur des invites, SEEM. SEEM peut segmenter tout le contenu d'une image ou d'une vidéo à la fois et identifier des catégories d'objets en fonction de diverses entrées modales fournies par l'utilisateur (y compris le texte, les images, les graffitis, etc.). Le projet est open source et une adresse d'essai est fournie à tous.

Lien papier : https://arxiv.org/pdf/2304.06718.pdf
Lien du projet : https://github.com/UX-Decoder/Segment-Everything -Everywhere-All-At-Once
Adresse d'essai : https://huggingface.co/spaces/xdecoder/SEEM
Cette étude a vérifié les performances de SEEM dans diverses tâches de segmentation grâce à l'efficacité d'expériences complètes sur. Même si SEEM n’a pas la capacité de comprendre les intentions des utilisateurs, il présente de fortes capacités de généralisation car il apprend à écrire différents types d’invites dans un espace de représentation unifié. De plus, SEEM peut gérer efficacement plusieurs séries d’interactions grâce à un décodeur d’invite léger.
Regardons d'abord l'effet de segmentation :
Segment "Optimus Prime" dans la photo Transformers :

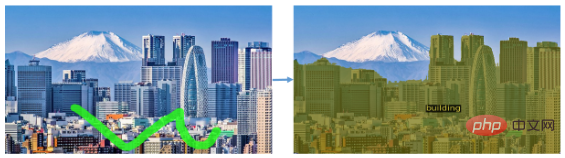
Il peut également segmenter un type d'objet, tel comme segmenter tous les bâtiments dans une image de paysage :
SEEM peut également facilement segmenter des objets en mouvement dans la vidéo :

Cet effet de segmentation peut être considéré comme très fluide . Jetons un coup d’œil à l’approche proposée dans cette étude.
Présentation de la méthode
Cette recherche vise à proposer une interface générale pour la segmentation d'images à l'aide d'invites multimodales. Afin d'atteindre cet objectif, ils ont proposé une nouvelle solution contenant 4 attributs, dont la polyvalence, la compositionnalité, l'interactivité et la conscience sémantique, dont
1) Polyvalence Cette recherche propose d'encoder des éléments hétérogènes tels que des points, des masques, des textes, des boîtes de détection (boîtes) et même la région de référence d'une autre image dans la même invite sémantique visuelle commune dans l'espace.
2) La compositionnalité écrit des requêtes à la volée pour le raisonnement en apprenant un espace sémantique visuel commun d'invites visuelles et textuelles. SEEM peut gérer n’importe quelle combinaison d’invites de saisie.
3) Interactivité : Cette étude introduit la conservation des informations de l'historique des conversations en combinant des invites de mémoire apprenables et une attention croisée guidée par des masques.
4) Conscience sémantique : utilisez un encodeur de texte pour encoder les requêtes de texte et masquer les étiquettes, fournissant ainsi une sémantique ouverte pour tous les résultats de segmentation de sortie.

En termes d'architecture, SEEM suit une architecture simple d'encodeur-décodeur Transformer et ajoute un encodeur de texte supplémentaire. Dans SEEM, le processus de décodage est similaire au LLM génératif, mais avec des entrées et des sorties multimodales. Toutes les requêtes sont renvoyées au décodeur sous forme d'invites, et les encodeurs d'images et de texte sont utilisés comme encodeurs d'invites pour coder tous les types de requêtes.
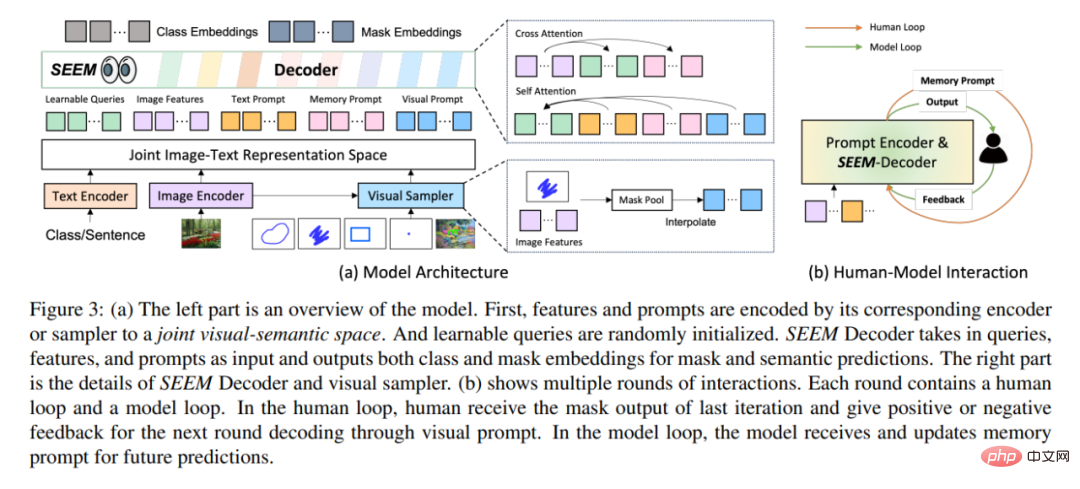
Plus précisément, cette étude encode toutes les requêtes (telles que les points, les cases et les masques) en invites visuelles, tout en utilisant un encodeur de texte pour convertir les requêtes de texte en invites de texte, telles que les invites visuelles et textuelles à maintenir l’alignement. Cinq types différents d'invites peuvent tous être mappés dans l'espace sémantique visuel commun, et les invites utilisateur invisibles peuvent être traitées grâce à une adaptation sans tir. En s'entraînant sur différentes tâches de segmentation, le modèle a la capacité de gérer diverses invites. De plus, différents types d’invites peuvent s’entraider en matière d’attention croisée. En fin de compte, les modèles SEEM peuvent utiliser diverses invites pour obtenir des résultats de segmentation supérieurs.
En plus de ses fortes capacités de généralisation, SEEM est également très efficace en fonctionnement. Les chercheurs ont utilisé des invites comme entrée dans le décodeur, de sorte que SEEM n’a dû exécuter l’extracteur de fonctionnalités qu’une seule fois au début, au cours de plusieurs cycles d’interactions avec des humains. À chaque itération, exécutez simplement à nouveau un décodeur léger avec une nouvelle invite. Par conséquent, lors du déploiement du modèle, l'extracteur de fonctionnalités avec un grand nombre de paramètres et une lourde charge d'exécution peut être exécuté sur le serveur, tandis que seul le décodeur relativement léger est exécuté sur la machine de l'utilisateur pour atténuer le problème de latence du réseau lors de plusieurs appels à distance.
Comme le montre la figure 3(b) ci-dessus, dans plusieurs cycles d'interaction, chaque interaction contient une boucle manuelle et une boucle modèle. Dans la boucle artificielle, l'humain reçoit la sortie du masque de l'itération précédente et donne un retour positif ou négatif pour le prochain cycle de décodage via des invites visuelles. Pendant la boucle du modèle, le modèle reçoit et met à jour les invites de mémoire pour les prédictions futures.
Résultats expérimentaux
Cette étude a comparé expérimentalement le modèle SEEM avec le modèle de segmentation interactif SOTA, et les résultats sont présentés dans le tableau 1 ci-dessous.
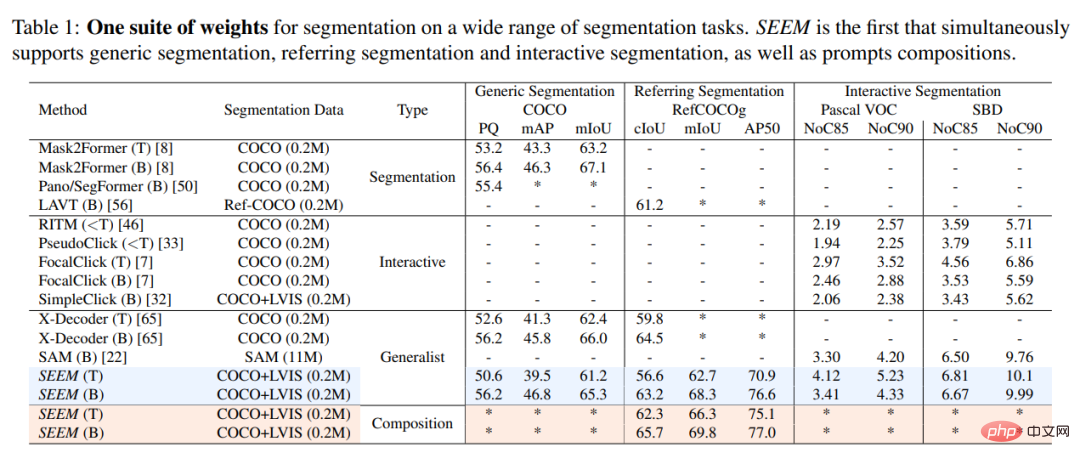
En tant que modèle général, SEEM atteint des performances comparables à celles de RITM, SimpleClick et d'autres modèles, et est très proche des performances de SAM, tandis que les données segmentées utilisées pour la formation par SAM sont 50 fois supérieures à celles de SEMBLER .
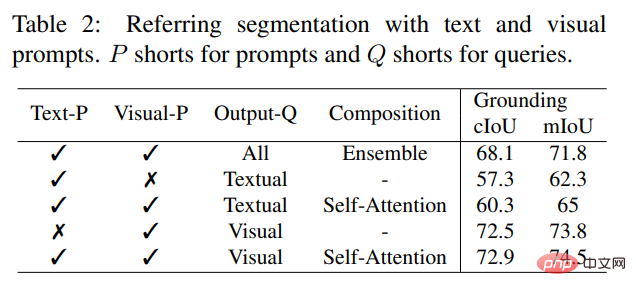
Contrairement aux modèles interactifs existants, SEEM est la première interface universelle qui prend en charge non seulement les tâches de segmentation classiques, mais également divers types de saisie utilisateur, notamment le texte, les points, les gribouillages, les cases et les images, offrant ainsi de puissantes combinaisons de fonctions. Comme le montre le tableau 2 ci-dessous, en ajoutant des invites combinables, SEEM a considérablement amélioré les performances de segmentation dans cIoU, mIoU et d'autres indicateurs.
Jetons un coup d'œil aux résultats de visualisation de la segmentation d'images interactive. Les utilisateurs n'ont qu'à dessiner un point ou simplement griffonner, et SEEM peut fournir de très bons résultats de segmentation

Vous pouvez également saisir du texte et laisser SEEM effectuer la segmentation d'image

Vous pouvez également saisir directement l'image de référence et indiquer la zone de référence, segmenter d'autres images et trouver des objets cohérents avec la zone de référence :

Ce projet peut déjà être essayé en ligne pour les personnes intéressées lecteurs, allez-y et essayez-le.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Le modèle MoE open source le plus puissant au monde est ici, avec des capacités chinoises comparables à celles du GPT-4, et le prix ne représente que près d'un pour cent de celui du GPT-4-Turbo.
May 07, 2024 pm 04:13 PM
Le modèle MoE open source le plus puissant au monde est ici, avec des capacités chinoises comparables à celles du GPT-4, et le prix ne représente que près d'un pour cent de celui du GPT-4-Turbo.
May 07, 2024 pm 04:13 PM
Imaginez un modèle d'intelligence artificielle qui non seulement a la capacité de surpasser l'informatique traditionnelle, mais qui permet également d'obtenir des performances plus efficaces à moindre coût. Ce n'est pas de la science-fiction, DeepSeek-V2[1], le modèle MoE open source le plus puissant au monde est ici. DeepSeek-V2 est un puissant mélange de modèle de langage d'experts (MoE) présentant les caractéristiques d'une formation économique et d'une inférence efficace. Il est constitué de 236B paramètres, dont 21B servent à activer chaque marqueur. Par rapport à DeepSeek67B, DeepSeek-V2 offre des performances plus élevées, tout en économisant 42,5 % des coûts de formation, en réduisant le cache KV de 93,3 % et en augmentant le débit de génération maximal à 5,76 fois. DeepSeek est une entreprise explorant l'intelligence artificielle générale
 Bonjour, Atlas électrique ! Le robot Boston Dynamics revient à la vie, des mouvements étranges à 180 degrés effraient Musk
Apr 18, 2024 pm 07:58 PM
Bonjour, Atlas électrique ! Le robot Boston Dynamics revient à la vie, des mouvements étranges à 180 degrés effraient Musk
Apr 18, 2024 pm 07:58 PM
Boston Dynamics Atlas entre officiellement dans l’ère des robots électriques ! Hier, l'Atlas hydraulique s'est retiré "en larmes" de la scène de l'histoire. Aujourd'hui, Boston Dynamics a annoncé que l'Atlas électrique était au travail. Il semble que dans le domaine des robots humanoïdes commerciaux, Boston Dynamics soit déterminé à concurrencer Tesla. Après la sortie de la nouvelle vidéo, elle a déjà été visionnée par plus d’un million de personnes en seulement dix heures. Les personnes âgées partent et de nouveaux rôles apparaissent. C'est une nécessité historique. Il ne fait aucun doute que cette année est l’année explosive des robots humanoïdes. Les internautes ont commenté : Les progrès des robots ont fait ressembler la cérémonie d'ouverture de cette année à des êtres humains, et le degré de liberté est bien plus grand que celui des humains. Mais n'est-ce vraiment pas un film d'horreur ? Au début de la vidéo, Atlas est allongé calmement sur le sol, apparemment sur le dos. Ce qui suit est à couper le souffle
 KAN, qui remplace MLP, a été étendu à la convolution par des projets open source
Jun 01, 2024 pm 10:03 PM
KAN, qui remplace MLP, a été étendu à la convolution par des projets open source
Jun 01, 2024 pm 10:03 PM
Plus tôt ce mois-ci, des chercheurs du MIT et d'autres institutions ont proposé une alternative très prometteuse au MLP – KAN. KAN surpasse MLP en termes de précision et d’interprétabilité. Et il peut surpasser le MLP fonctionnant avec un plus grand nombre de paramètres avec un très petit nombre de paramètres. Par exemple, les auteurs ont déclaré avoir utilisé KAN pour reproduire les résultats de DeepMind avec un réseau plus petit et un degré d'automatisation plus élevé. Plus précisément, le MLP de DeepMind compte environ 300 000 paramètres, tandis que le KAN n'en compte qu'environ 200. KAN a une base mathématique solide comme MLP est basé sur le théorème d'approximation universelle, tandis que KAN est basé sur le théorème de représentation de Kolmogorov-Arnold. Comme le montre la figure ci-dessous, KAN a
 L'IA bouleverse la recherche mathématique ! Le lauréat de la médaille Fields et mathématicien sino-américain a dirigé 11 articles les mieux classés | Aimé par Terence Tao
Apr 09, 2024 am 11:52 AM
L'IA bouleverse la recherche mathématique ! Le lauréat de la médaille Fields et mathématicien sino-américain a dirigé 11 articles les mieux classés | Aimé par Terence Tao
Apr 09, 2024 am 11:52 AM
L’IA change effectivement les mathématiques. Récemment, Tao Zhexuan, qui a prêté une attention particulière à cette question, a transmis le dernier numéro du « Bulletin de l'American Mathematical Society » (Bulletin de l'American Mathematical Society). En se concentrant sur le thème « Les machines changeront-elles les mathématiques ? », de nombreux mathématiciens ont exprimé leurs opinions. L'ensemble du processus a été plein d'étincelles, intense et passionnant. L'auteur dispose d'une équipe solide, comprenant Akshay Venkatesh, lauréat de la médaille Fields, le mathématicien chinois Zheng Lejun, l'informaticien de l'Université de New York Ernest Davis et de nombreux autres universitaires bien connus du secteur. Le monde de l’IA a radicalement changé. Vous savez, bon nombre de ces articles ont été soumis il y a un an.
 Google est ravi : les performances de JAX surpassent Pytorch et TensorFlow ! Cela pourrait devenir le choix le plus rapide pour la formation à l'inférence GPU
Apr 01, 2024 pm 07:46 PM
Google est ravi : les performances de JAX surpassent Pytorch et TensorFlow ! Cela pourrait devenir le choix le plus rapide pour la formation à l'inférence GPU
Apr 01, 2024 pm 07:46 PM
Les performances de JAX, promu par Google, ont dépassé celles de Pytorch et TensorFlow lors de récents tests de référence, se classant au premier rang sur 7 indicateurs. Et le test n’a pas été fait sur le TPU présentant les meilleures performances JAX. Bien que parmi les développeurs, Pytorch soit toujours plus populaire que Tensorflow. Mais à l’avenir, des modèles plus volumineux seront peut-être formés et exécutés sur la base de la plate-forme JAX. Modèles Récemment, l'équipe Keras a comparé trois backends (TensorFlow, JAX, PyTorch) avec l'implémentation native de PyTorch et Keras2 avec TensorFlow. Premièrement, ils sélectionnent un ensemble de
 Nouveaux travaux sur la prédiction de séries chronologiques + grand modèle NLP : générer automatiquement des invites implicites pour la prédiction de séries chronologiques
Mar 18, 2024 am 09:20 AM
Nouveaux travaux sur la prédiction de séries chronologiques + grand modèle NLP : générer automatiquement des invites implicites pour la prédiction de séries chronologiques
Mar 18, 2024 am 09:20 AM
Aujourd'hui, j'aimerais partager un travail de recherche récent de l'Université du Connecticut qui propose une méthode pour aligner les données de séries chronologiques avec de grands modèles de traitement du langage naturel (NLP) sur l'espace latent afin d'améliorer les performances de prévision des séries chronologiques. La clé de cette méthode consiste à utiliser des indices spatiaux latents (invites) pour améliorer la précision des prévisions de séries chronologiques. Titre de l'article : S2IP-LLM : SemanticSpaceInformedPromptLearningwithLLMforTimeSeriesForecasting Adresse de téléchargement : https://arxiv.org/pdf/2403.05798v1.pdf 1. Modèle de fond de problème important
 Les robots Tesla travaillent dans les usines, Musk : Le degré de liberté des mains atteindra 22 cette année !
May 06, 2024 pm 04:13 PM
Les robots Tesla travaillent dans les usines, Musk : Le degré de liberté des mains atteindra 22 cette année !
May 06, 2024 pm 04:13 PM
La dernière vidéo du robot Optimus de Tesla est sortie, et il peut déjà fonctionner en usine. À vitesse normale, il trie les batteries (les batteries 4680 de Tesla) comme ceci : Le responsable a également publié à quoi cela ressemble à une vitesse 20 fois supérieure - sur un petit "poste de travail", en sélectionnant et en sélectionnant et en sélectionnant : Cette fois, il est publié L'un des points forts de la vidéo est qu'Optimus réalise ce travail en usine, de manière totalement autonome, sans intervention humaine tout au long du processus. Et du point de vue d'Optimus, il peut également récupérer et placer la batterie tordue, en se concentrant sur la correction automatique des erreurs : concernant la main d'Optimus, le scientifique de NVIDIA Jim Fan a donné une évaluation élevée : la main d'Optimus est l'un des robots à cinq doigts du monde. le plus adroit. Ses mains ne sont pas seulement tactiles
 DualBEV : dépassant largement BEVFormer et BEVDet4D, ouvrez le livre !
Mar 21, 2024 pm 05:21 PM
DualBEV : dépassant largement BEVFormer et BEVDet4D, ouvrez le livre !
Mar 21, 2024 pm 05:21 PM
Cet article explore le problème de la détection précise d'objets sous différents angles de vue (tels que la perspective et la vue à vol d'oiseau) dans la conduite autonome, en particulier comment transformer efficacement les caractéristiques de l'espace en perspective (PV) en vue à vol d'oiseau (BEV). implémenté via le module Visual Transformation (VT). Les méthodes existantes sont globalement divisées en deux stratégies : la conversion 2D en 3D et la conversion 3D en 2D. Les méthodes 2D vers 3D améliorent les caractéristiques 2D denses en prédisant les probabilités de profondeur, mais l'incertitude inhérente aux prévisions de profondeur, en particulier dans les régions éloignées, peut introduire des inexactitudes. Alors que les méthodes 3D vers 2D utilisent généralement des requêtes 3D pour échantillonner des fonctionnalités 2D et apprendre les poids d'attention de la correspondance entre les fonctionnalités 3D et 2D via un transformateur, ce qui augmente le temps de calcul et de déploiement.
