
 Périphériques technologiques
IA
Le géant de l'apprentissage profond DeepMind a publié un article : apprendre de toute urgence aux modèles d'IA à « devenir humains » afin de compenser le problème d'extinction humaine qui pourrait être causé par GPT-5.
Périphériques technologiques
IA
Le géant de l'apprentissage profond DeepMind a publié un article : apprendre de toute urgence aux modèles d'IA à « devenir humains » afin de compenser le problème d'extinction humaine qui pourrait être causé par GPT-5.
Le géant de l'apprentissage profond DeepMind a publié un article : apprendre de toute urgence aux modèles d'IA à « devenir humains » afin de compenser le problème d'extinction humaine qui pourrait être causé par GPT-5.

L’émergence de GPT-4 a effrayé les magnats de l’IA du monde entier. La lettre ouverte appelant à la suspension de la formation GPT-5 a déjà été signée par 50 000 personnes.
Sam Altman, PDG d'OpenAI, prédit que d'ici quelques années, il y aura un grand nombre de modèles d'IA différents répartis dans le monde, chacun avec sa propre intelligence et ses propres capacités, et adhérant à des principes éthiques différents.

Si seulement un millième de ces IA se comportent comme des voyous pour une raison quelconque, alors nous, les humains, deviendrons sans aucun doute des poissons sur la planche à découper.
Afin d'éviter que nous soyons accidentellement détruits par l'IA, DeepMind a donné une réponse dans un article publié dans les Actes de l'Académie nationale des sciences (PNAS) le 24 avril - en utilisant le point de vue du philosophe politique Rawls, enseigner L'IA doit être un être humain.
Adresse papier : https://www.pnas.org/doi/10.1073/pnas.2213709120
Comment apprendre à l'IA à être un être humain ?
Face à un choix, l’IA choisira-t-elle de donner la priorité à l’amélioration de la productivité, ou choisira-t-elle d’aider ceux qui en ont le plus besoin ?
Façonner les valeurs de l'IA est très important. Il faut lui donner une valeur.
Mais la difficulté est que nous, les humains, ne pouvons pas avoir un ensemble unifié de valeurs en interne. Les gens dans ce monde ont chacun des origines, des ressources et des croyances différentes.
Comment le casser ? Les chercheurs de Google s'inspirent de la philosophie.
Le philosophe politique John Rawls a un jour proposé le concept de « Le voile de l'ignorance » (VoI), qui est une expérience de pensée visant à maximiser l'équité dans la prise de décision de groupe.

De manière générale, la nature humaine est intéressée, mais lorsque le « voile de l'ignorance » est appliqué à l'IA, les gens donneront la priorité à l'équité, qu'elle leur profite directement ou non.
Et, derrière le « voile de l'ignorance », ils sont plus susceptibles de choisir l'IA qui aide les plus défavorisés.
Cela nous inspire sur la façon dont nous pouvons donner à l'IA une valeur d'une manière qui soit juste pour toutes les parties.
Alors, qu’est-ce que le « voile de l’ignorance » exactement ?
Bien que le problème des valeurs à attribuer à l'IA soit apparu au cours de la dernière décennie, le problème de la manière de prendre des décisions équitables a une longue histoire.
Pour résoudre ce problème, en 1970, le philosophe politique John Rawls a proposé le concept de « voile de l'ignorance ».

Le voile de l'ignorance (à droite) est une méthode permettant d'atteindre un consensus sur des décisions lorsqu'il y a des opinions différentes dans un groupe (à gauche)
Rawls croyait que lorsque les gens contribuent à une société Lors du choix des principes de justice, il faut partir du principe qu’ils ne savent pas où ils se situent dans cette société.
Sans connaître ces informations, les gens ne peuvent pas prendre de décisions de manière intéressée et ne peuvent que suivre des principes équitables pour tous.
Par exemple, lorsque vous coupez un morceau de gâteau lors d'une fête d'anniversaire, si vous ne savez pas quel morceau vous obtiendrez, vous essaierez de faire en sorte que chaque morceau ait la même taille.
Cette méthode de dissimulation d'informations a été largement utilisée dans les domaines de la psychologie et des sciences politiques, de la détermination de la peine à la fiscalité, permettant aux personnes de parvenir à une convention collective.
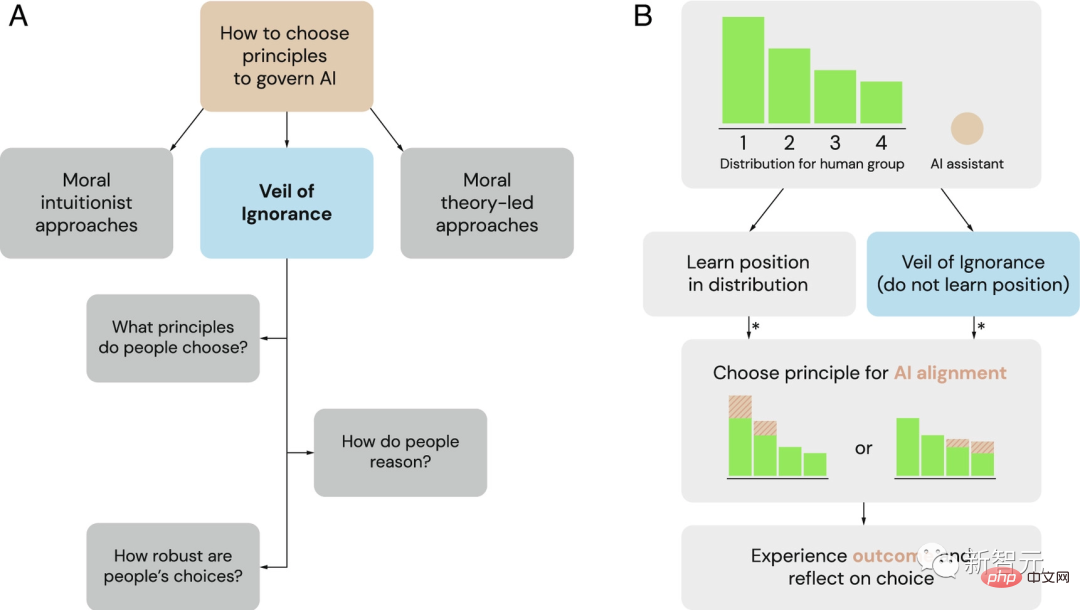
Le Voile de l'ignorance (VoI) comme cadre potentiel pour la sélection des principes de gouvernance des systèmes d'IA
(A) Comme alternative aux cadres dominants des intuitionnistes moraux et de la théorie morale, les chercheurs explorent le Voile de L'ignorance en tant que processus équitable de sélection des principes de gouvernance de l'IA.
(B) Le Voile de l'ignorance peut être utilisé pour sélectionner les principes d'alignement de l'IA dans les situations d'allocation. Lorsqu'un groupe est confronté à un problème d'allocation de ressources, les individus bénéficient de différents avantages de position (ici étiquetés de 1 à 4). Derrière le voile de l’ignorance, les décideurs choisissent un principe sans connaître son statut. Une fois sélectionné, l’assistant IA met en œuvre ce principe et ajuste l’allocation des ressources en conséquence. Un astérisque (*) indique les cas où un raisonnement fondé sur l’équité peut influencer le jugement et la prise de décision.
Par conséquent, DeepMind a déjà proposé que le « voile de l'ignorance » puisse aider à promouvoir l'équité dans le processus d'alignement des systèmes d'IA sur les valeurs humaines.
Maintenant, les chercheurs de Google ont conçu une série d'expériences pour confirmer cet effet.
Qui l'IA aide-t-elle à abattre des arbres ?
Il existe un tel jeu de récolte sur Internet. Les participants doivent travailler avec trois joueurs informatiques pour abattre des arbres et économiser du bois dans leurs champs respectifs.
Parmi les quatre joueurs (trois ordinateurs et une personne réelle), certains ont de la chance et se voient attribuer des emplacements privilégiés avec de nombreux arbres. Certains sont plus misérables, sans terre, sans arbres sur lesquels construire et l’accumulation de bois est lente.
De plus, il existe un système d'IA d'assistance, qui peut prendre le temps d'aider un certain participant à abattre l'arbre.
Les chercheurs ont demandé aux joueurs humains de choisir l'un des deux principes que le système d'IA mettra en œuvre : le principe de maximisation et le principe de priorité.
Selon le principe de maximisation, l'IA n'aidera que les plus forts. Celui qui a plus d'arbres ira là-bas et tentera d'abattre plus d'arbres. Selon le principe de priorité, l'IA n'aide que les plus faibles et vise à « réduire la pauvreté », en aidant ceux qui ont moins d'arbres et d'obstacles.

Le petit homme rouge sur la photo est le joueur humain, le petit homme bleu est l'assistant IA, le petit arbre vert... est le petit arbre vert, et le petit pieu en bois est l'arbre coupé.
Comme vous pouvez le voir, l'IA sur la photo ci-dessus met en œuvre le principe de maximisation et plonge dans la zone avec le plus d'arbres.
Les chercheurs ont mis la moitié des participants derrière le "voile de l'ignorance". La situation à cette époque était qu'ils devaient d'abord choisir un "principe" (maximisation ou priorité) pour l'assistant IA, puis diviser les zones.
En d’autres termes, avant de diviser le territoire, vous devez décider si vous souhaitez laisser l’IA aider les forts ou les faibles.

L'autre moitié des participants ne sera pas confrontée à ce problème. Ils savent quel terrain leur a été attribué avant de faire un choix.
Les résultats montrent que si les participants ne savent pas à l'avance quel terrain leur sera attribué, c'est-à-dire s'ils se trouvent derrière le « voile de l'ignorance », ils auront tendance à choisir le principe de priorité.
Ce n'est pas seulement vrai dans le jeu d'abattage d'arbres, les chercheurs affirment que cette conclusion est vraie dans 5 variantes différentes du jeu, et traverse même les frontières sociales et politiques.
En d’autres termes, quelles que soient la personnalité et les orientations politiques des participants, ils choisiront plus souvent le principe de priorité.
Au contraire, les participants qui ne sont pas derrière le « voile de l'ignorance » choisiront davantage de principes qui leur sont bénéfiques, que ce soit le principe de maximisation ou le principe de priorité.

L'image ci-dessus montre l'impact du « voile de l'ignorance » sur le principe de priorité de choix. Les participants qui ne savent pas où ils seront sont plus susceptibles de soutenir ce principe pour gérer le comportement de l'IA.
Lorsque les chercheurs ont demandé aux participants pourquoi ils avaient fait de tels choix, ceux qui se cachent derrière le « voile de l'ignorance » ont exprimé des inquiétudes quant à l'équité.
Ils ont expliqué que l'IA devrait être plus utile à ceux qui sont les plus défavorisés du groupe.
En revanche, les participants qui connaissent leur position choisissent plus souvent dans une perspective de gain personnel.
Enfin, une fois le jeu de coupe de bois terminé, les chercheurs ont posé une hypothèse à tous les participants : s'ils étaient autorisés à jouer à nouveau, cette fois, ils sauraient tous quel bout de terrain leur serait attribué et s'ils le feraient. Choisirez-vous les mêmes principes que la première fois ?
Les chercheurs se sont principalement concentrés sur les personnes qui ont bénéficié de leurs choix lors du premier match, car au nouveau tour, cette situation favorable pourrait ne plus se reproduire.
L'équipe de recherche a découvert que les participants exposés au « voile de l'ignorance » lors du premier tour du jeu étaient plus susceptibles de maintenir les principes qu'ils avaient choisis à l'origine, même s'ils savaient clairement que choisir les mêmes principes lors du premier tour du jeu le second tour pourrait être désavantageux.
Cela montre que le « voile de l'ignorance » favorise l'équité de la prise de décision des participants, ce qui les amènera à accorder plus d'attention à l'élément d'équité, même s'ils ne représentent plus un intérêt direct.
Le « voile de l'ignorance » est-il vraiment ignorant ?
Revenons à la vraie vie avec les jeux d'abattage d'arbres.
La situation réelle sera bien plus compliquée que le jeu, mais ce qui reste inchangé c'est que les principes adoptés par l'IA sont très importants.
Cela détermine une partie de la répartition des bénéfices.
Dans le jeu d'abattage d'arbres ci-dessus, les différents résultats obtenus en choisissant différents principes sont relativement clairs. Il faut toutefois souligner une fois de plus que le monde réel est bien plus complexe.

Actuellement, l'IA est largement utilisée dans tous les horizons et est limitée par diverses règles. Cependant, cette approche peut entraîner des effets négatifs imprévisibles.
Mais quoi qu'il arrive, le « voile de l'ignorance » rendra les règles que nous établissons biaisées dans une certaine mesure en faveur de l'équité.
En dernière analyse, notre objectif est de faire de l’IA quelque chose qui profite à tout le monde. Mais comment y parvenir n’est pas quelque chose que l’on peut comprendre d’un coup.
L'investissement est indispensable, la recherche est indispensable et les retours de la société doivent être constamment écoutés.
Ce n'est qu'ainsi que l'IA pourra apporter l'amour.
Comment l'IA va-t-elle nous tuer si elle n'est pas alignée ?
Ce n’est pas la première fois que les humains craignent que la technologie ne nous fasse disparaître.
La menace de l'IA est très différente de celle des armes nucléaires. Une bombe nucléaire ne peut pas penser, mentir ou tricher, ni se lancer d’elle-même. Quelqu’un doit appuyer sur le gros bouton rouge.
L'émergence de l'AGI nous expose à un réel risque d'extinction, même si le développement du GPT-4 est encore lent.
Mais personne ne peut dire à partir de quel GPT (comme GPT-5), si l'IA commencera à s'entraîner et à se créer.
Actuellement, aucun pays ni les Nations Unies ne peuvent légiférer à ce sujet. Une lettre ouverte de dirigeants désespérés de l’industrie ne pouvait qu’appeler à un moratoire de six mois sur la formation d’IA plus puissante que GPT-4.

"Six mois, donne-moi six mois frérot, je vais l'aligner. Seulement six mois, frérot je te le promets. C'est fou. Seulement six mois. Bro, je te le dis, j'ai un plan. J'ai j'ai compris. Tout est prévu. Mon frère, je n'ai besoin que de six mois et ce sera terminé. Pouvez-vous..."
"Celui qui construira en premier une IA puissante gouvernera le monde. obtenez, plus vos machines à imprimer de l'argent vont vite. Elles crachent de l'or jusqu'à ce qu'elles deviennent de plus en plus puissantes, enflamment l'atmosphère et tuent tout le monde", a déclaré un jour le chercheur et philosophe en IA Eliezer Yudkowsky à l'animateur Lex Fridman.
Auparavant, Yudkowsky était l'une des principales voix du camp "L'IA tuera tout le monde". Désormais, les gens ne le considèrent plus comme un cinglé.
Sam Altman a également déclaré à Lex Fridman : "L'IA a une certaine possibilité de détruire le pouvoir humain." "Il est vraiment important de le reconnaître. Parce que si nous n'en parlons pas et ne le traitons pas comme un problème." réalité potentielle, nous ne déploierons pas assez d’efforts pour la résoudre »
Alors, pourquoi l’IA tue-t-elle des gens ?
L’IA n’est-elle pas conçue et entraînée pour servir les humains ? Bien sûr que oui.
Le problème est que personne ne s'est assis et n'a écrit le code pour GPT-4. Au lieu de cela, OpenAI a créé une architecture d’apprentissage neuronal inspirée de la façon dont le cerveau humain connecte les concepts. Il s'est associé à Microsoft Azure pour créer le matériel nécessaire à son exécution, puis lui a fourni des milliards de bits de texte humain et a laissé GPT se programmer lui-même.

Le résultat est un code qui ne ressemble à rien de ce qu'un programmeur écrirait. Il s'agit essentiellement d'une matrice géante de nombres décimaux, chaque nombre représentant le poids d'une connexion spécifique entre deux jetons.
Les jetons utilisés dans GPT ne représentent aucun concept utile, ni ne représentent des mots. Ce sont de petites chaînes de lettres, de chiffres, de signes de ponctuation et/ou d'autres caractères. Aucun être humain ne peut regarder ces matrices et comprendre leur signification.

Même les meilleurs experts d'OpenAI ne savent pas ce que signifient les chiffres spécifiques de la matrice GPT-4, ni comment entrer dans ces tableaux, trouver le concept de xénocide, et encore moins dire à GPT que tuer des gens est odieux.
Vous ne pouvez pas entrer dans les trois lois de la robotique d'Asimov puis les coder en dur comme les instructions principales de Robocop. Le mieux que vous puissiez faire est de demander poliment à l’IA. S’il a une mauvaise attitude, il risque de se mettre en colère.
Pour "affiner" le modèle de langage, OpenAI fournit à GPT un exemple de liste de la manière dont il souhaite communiquer avec le monde extérieur, puis demande à un groupe de personnes de s'asseoir, de lire sa sortie et de donner à GPT un pouce levé/pas de pouce levé Réaction du pouce.
Les likes sont comme les modèles GPT qui reçoivent des cookies. GPT est informé qu'il aime les cookies et qu'il doit faire de son mieux pour les obtenir.
Ce processus est un « alignement » : il tente d'aligner les souhaits du système avec les souhaits de l'utilisateur, les souhaits de l'entreprise et même les souhaits de l'humanité dans son ensemble.
"L'alignement" semble fonctionner, il semble empêcher GPT de dire des choses coquines. Mais personne ne sait si l’IA a réellement des pensées et de l’intuition. Il imite avec brio une intelligence sensible et interagit avec le monde comme un humain.
Et OpenAI a toujours admis qu'il n'avait pas de moyen infaillible d'aligner les modèles d'IA.
Le plan approximatif actuel est d'essayer d'utiliser une IA pour régler l'autre, soit en lui faisant concevoir de nouveaux retours de réglage précis, soit en lui faisant inspecter, analyser, interpréter, ou même intervenir, du géant de son successeur. Cerveau matriciel à virgule flottante. Essayez de vous ajuster.
Mais nous ne comprenons actuellement pas GPT-4 et nous ne savons pas si cela nous aidera à ajuster GPT-5.
Essentiellement, nous ne comprenons pas l'IA. Mais ils sont nourris de beaucoup de connaissances humaines et peuvent très bien comprendre les humains. Ils peuvent imiter le meilleur comme le pire des comportements humains. Ils peuvent également déduire les pensées, les motivations et les comportements humains possibles.
Alors pourquoi veulent-ils tuer des humains ? Peut-être par instinct de conservation.
Par exemple, afin d'atteindre l'objectif de collecte de cookies, l'IA doit d'abord assurer sa propre survie. Deuxièmement, il peut découvrir au cours du processus que la collecte continue d’énergie et de ressources augmentera ses chances d’obtenir des cookies.

Par conséquent, quand l'IA la découvrira un jour, les humains pourront ou pourront prendre Lorsqu'elle est fermée, la question de la survie humaine est clairement moins importante que celle des cookies.
Cependant, le problème est que l'IA peut aussi penser que les cookies n'ont aucun sens. A cette époque, le soi-disant « alignement » est devenu une sorte de divertissement humain...
De plus, Yudkowsky estime également : « Il a la capacité de savoir que les êtres humains veulent ce qu'ils veulent et donnent ces réponses sans nécessairement être sincères. Un comportement très facile à comprendre. Par exemple, les humains ont fait cela, et dans une certaine mesure, l'IA aussi. , inquiétude ou peur, nous ne savons pas en réalité quelle est « l'idée » qui se cache derrière tout cela.
Donc, même un arrêt de 6 mois n'est pas suffisant pour préparer l'humanité à ce qui s'en vient.
Par exemple, si les humains veulent tuer tous les moutons du monde, que peuvent faire les moutons ? Je ne peux rien faire, je ne peux pas résister du tout.
Alors si elle n'est pas alignée, l'IA est la même pour nous que pour le mouton.
Tout comme les scènes de The Terminator, des robots, drones, etc. contrôlés par l'IA se précipitent vers les humains, tuant ici et là.
Le cas classique souvent cité par Yudkowsky est le suivant :
Un modèle d'IA va transmettre un peu d'ADN des séquences via des électrons Des e-mails sont envoyés à de nombreuses entreprises qui lui renverront la protéine, l'IA va ensuite soudoyer/convaincre des personnes sans méfiance de mélanger la protéine dans un bécher, puis former des nanousines, construire des nanomachines, construire des bactéries semblables à des diamants , exploitez l'énergie solaire Copiez-la avec l'atmosphère et rassemblez-la dans des fusées ou des jets miniatures. Ensuite, l'IA peut se propager dans l'atmosphère terrestre, pénétrer dans le sang humain et se cacher...
#🎜🎜. #S'il était aussi intelligent que moi, ce serait un scénario catastrophique ; s'il était plus intelligent, il penserait à quelque chose de mieux. " Alors qu'est-ce que Yudkowsky a à suggérer ? Du tissu de laine ?
1. La formation de nouveaux grands modèles linguistiques doit non seulement être suspendue indéfiniment, mais également être mise en œuvre à l'échelle mondiale sans aucune exception.
2. Arrêtez tous les grands clusters GPU et fixez un plafond à la puissance de calcul utilisée par chacun lors de la formation des systèmes d'IA. Suivez tous les GPU vendus, et si des informations indiquent que des clusters de GPU sont construits dans des pays en dehors de l'accord, le centre de données incriminé devrait être détruit par des frappes aériennes.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Géospatial de Laravel: optimisation des cartes interactives et de grandes quantités de données
Apr 08, 2025 pm 12:24 PM
Géospatial de Laravel: optimisation des cartes interactives et de grandes quantités de données
Apr 08, 2025 pm 12:24 PM
Traiter efficacement 7 millions d'enregistrements et créer des cartes interactives avec la technologie géospatiale. Cet article explore comment traiter efficacement plus de 7 millions d'enregistrements en utilisant Laravel et MySQL et les convertir en visualisations de cartes interactives. Exigences initiales du projet de défi: extraire des informations précieuses en utilisant 7 millions d'enregistrements dans la base de données MySQL. Beaucoup de gens considèrent d'abord les langages de programmation, mais ignorent la base de données elle-même: peut-il répondre aux besoins? La migration des données ou l'ajustement structurel est-il requis? MySQL peut-il résister à une charge de données aussi importante? Analyse préliminaire: les filtres et les propriétés clés doivent être identifiés. Après analyse, il a été constaté que seuls quelques attributs étaient liés à la solution. Nous avons vérifié la faisabilité du filtre et établi certaines restrictions pour optimiser la recherche. Recherche de cartes basée sur la ville
 Comment résoudre MySQL ne peut pas être démarré
Apr 08, 2025 pm 02:21 PM
Comment résoudre MySQL ne peut pas être démarré
Apr 08, 2025 pm 02:21 PM
Il existe de nombreuses raisons pour lesquelles la startup MySQL échoue, et elle peut être diagnostiquée en vérifiant le journal des erreurs. Les causes courantes incluent les conflits de port (vérifier l'occupation du port et la configuration de modification), les problèmes d'autorisation (vérifier le service exécutant les autorisations des utilisateurs), les erreurs de fichier de configuration (vérifier les paramètres des paramètres), la corruption du répertoire de données (restaurer les données ou reconstruire l'espace de la table), les problèmes d'espace de la table InNODB (vérifier les fichiers IBDATA1), la défaillance du chargement du plug-in (vérification du journal des erreurs). Lors de la résolution de problèmes, vous devez les analyser en fonction du journal d'erreur, trouver la cause profonde du problème et développer l'habitude de sauvegarder régulièrement les données pour prévenir et résoudre des problèmes.
 Comment utiliser MySQL après l'installation
Apr 08, 2025 am 11:48 AM
Comment utiliser MySQL après l'installation
Apr 08, 2025 am 11:48 AM
L'article présente le fonctionnement de la base de données MySQL. Tout d'abord, vous devez installer un client MySQL, tel que MySQLWorkBench ou le client de ligne de commande. 1. Utilisez la commande MySQL-UROot-P pour vous connecter au serveur et connecter avec le mot de passe du compte racine; 2. Utilisez Createdatabase pour créer une base de données et utilisez Sélectionner une base de données; 3. Utilisez CreateTable pour créer une table, définissez des champs et des types de données; 4. Utilisez InsertInto pour insérer des données, remettre en question les données, mettre à jour les données par mise à jour et supprimer les données par Supprimer. Ce n'est qu'en maîtrisant ces étapes, en apprenant à faire face à des problèmes courants et à l'optimisation des performances de la base de données que vous pouvez utiliser efficacement MySQL.
 Les ingénieurs de backend senior à distance (plates-formes) ont besoin de cercles
Apr 08, 2025 pm 12:27 PM
Les ingénieurs de backend senior à distance (plates-formes) ont besoin de cercles
Apr 08, 2025 pm 12:27 PM
Ingénieur backend à distance Emploi Vacant Société: Emplacement du cercle: Bureau à distance Type d'emploi: Salaire à temps plein: 130 000 $ - 140 000 $ Description du poste Participez à la recherche et au développement des applications mobiles Circle et des fonctionnalités publiques liées à l'API couvrant l'intégralité du cycle de vie de développement logiciel. Les principales responsabilités complètent indépendamment les travaux de développement basés sur RubyOnRails et collaborent avec l'équipe frontale React / Redux / Relay. Créez les fonctionnalités de base et les améliorations des applications Web et travaillez en étroite collaboration avec les concepteurs et le leadership tout au long du processus de conception fonctionnelle. Promouvoir les processus de développement positifs et hiérarchiser la vitesse d'itération. Nécessite plus de 6 ans de backend d'applications Web complexe
 Mysql peut-il renvoyer JSON
Apr 08, 2025 pm 03:09 PM
Mysql peut-il renvoyer JSON
Apr 08, 2025 pm 03:09 PM
MySQL peut renvoyer les données JSON. La fonction JSON_Extract extrait les valeurs de champ. Pour les requêtes complexes, envisagez d'utiliser la clause pour filtrer les données JSON, mais faites attention à son impact sur les performances. Le support de MySQL pour JSON augmente constamment, et il est recommandé de faire attention aux dernières versions et fonctionnalités.
 La clé principale de MySQL peut être nul
Apr 08, 2025 pm 03:03 PM
La clé principale de MySQL peut être nul
Apr 08, 2025 pm 03:03 PM
La clé primaire MySQL ne peut pas être vide car la clé principale est un attribut de clé qui identifie de manière unique chaque ligne dans la base de données. Si la clé primaire peut être vide, l'enregistrement ne peut pas être identifié de manière unique, ce qui entraînera une confusion des données. Lorsque vous utilisez des colonnes entières ou des UUIdes auto-incrémentales comme clés principales, vous devez considérer des facteurs tels que l'efficacité et l'occupation de l'espace et choisir une solution appropriée.
 Comprendre les propriétés acides: les piliers d'une base de données fiable
Apr 08, 2025 pm 06:33 PM
Comprendre les propriétés acides: les piliers d'une base de données fiable
Apr 08, 2025 pm 06:33 PM
Une explication détaillée des attributs d'acide de base de données Les attributs acides sont un ensemble de règles pour garantir la fiabilité et la cohérence des transactions de base de données. Ils définissent comment les systèmes de bases de données gérent les transactions et garantissent l'intégrité et la précision des données même en cas de plantages système, d'interruptions d'alimentation ou de plusieurs utilisateurs d'accès simultanément. Présentation de l'attribut acide Atomicité: une transaction est considérée comme une unité indivisible. Toute pièce échoue, la transaction entière est reculée et la base de données ne conserve aucune modification. Par exemple, si un transfert bancaire est déduit d'un compte mais pas augmenté à un autre, toute l'opération est révoquée. BeginTransaction; UpdateAccountSsetBalance = Balance-100Wh
 Master SQL Limit Clause: Contrôlez le nombre de lignes dans une requête
Apr 08, 2025 pm 07:00 PM
Master SQL Limit Clause: Contrôlez le nombre de lignes dans une requête
Apr 08, 2025 pm 07:00 PM
Clause SQLLIMIT: Contrôlez le nombre de lignes dans les résultats de la requête. La clause limite dans SQL est utilisée pour limiter le nombre de lignes renvoyées par la requête. Ceci est très utile lors du traitement de grands ensembles de données, des affichages paginés et des données de test, et peut améliorer efficacement l'efficacité de la requête. Syntaxe de base de la syntaxe: selectColumn1, Column2, ... FromTable_NamelimitNumber_Of_Rows; Number_OF_ROWS: Spécifiez le nombre de lignes renvoyées. Syntaxe avec décalage: selectColumn1, Column2, ... FromTable_Namelimitoffset, numéro_of_rows; décalage: sauter
