
 Périphériques technologiques
IA
La diffusion stable peut-elle surpasser les algorithmes tels que JPEG et améliorer la compression de l'image tout en conservant la clarté ?
Périphériques technologiques
IA
La diffusion stable peut-elle surpasser les algorithmes tels que JPEG et améliorer la compression de l'image tout en conservant la clarté ?
La diffusion stable peut-elle surpasser les algorithmes tels que JPEG et améliorer la compression de l'image tout en conservant la clarté ?

Le modèle de génération d'images basé sur du texte est très populaire. Non seulement le modèle de diffusion est populaire, mais aussi le modèle de diffusion stable open source. Récemment, un ingénieur logiciel suisse, Matthias Bühlmann, a découvert accidentellement que la diffusion stable peut non seulement être utilisée pour générer des images, mais également pour compresser des images bitmap , même avec un taux de compression plus élevé que JPEG et WebP.

L'image originale fait 768 Ko, qui est compressée à 5,66 Ko en utilisant JPEG et stable La diffusion peut davantage# 🎜🎜#Compressée à 4,98 Ko, et peut conserver plus de détails en haute résolution et
moins d'artefacts de compression, ce qui est visiblement mieux pour à l’œil nu d’autres algorithmes de compression. Cependant, cette méthode de compression présente également des défauts, c'est-à-dire que ne convient pas pour compresser le visage et des images de texte , dans certains cas, même générent des images originales sans contenu
.
Bien que recycler un auto-encodeur peut également faire quelque chose de similaire à Stable L'effet de compression de Diffusion, mais l'un des principaux avantages de l'utilisation de Stable Diffusion est que quelqu'un a investi des millions de fonds
pour vous aider à en former un, et vousPourquoi dépenser de l'argent pour vous entraîner à nouveau# 🎜🎜#Et un modèle à compression ? 
Comment Stable Diffusion compresse les imagesLes modèles de diffusion remettent en question la domination des modèles génératifs, et le modèle open source Stable Diffusion correspondant est également présent la communauté du machine learning Commencez une révolution artistique.
La diffusion stable est obtenue en concaténant trois réseaux de neurones entraînés, c'est-à-dire
un encodeur variationnel ( VAE), modèle U-Net et
un encodeur de texte. 
L'autoencodeur variationnel encode et décode l'image dans l'espace image pour obtenir l'image dans # 🎜🎜#Le vecteur de représentation de l'espace latent est représenté par une résolution inférieure (64x64) avec précision supérieure (4x32 bits)
vecteur# 🎜🎜#Image source (512x512 po 3x8 ou 4x8 bits). 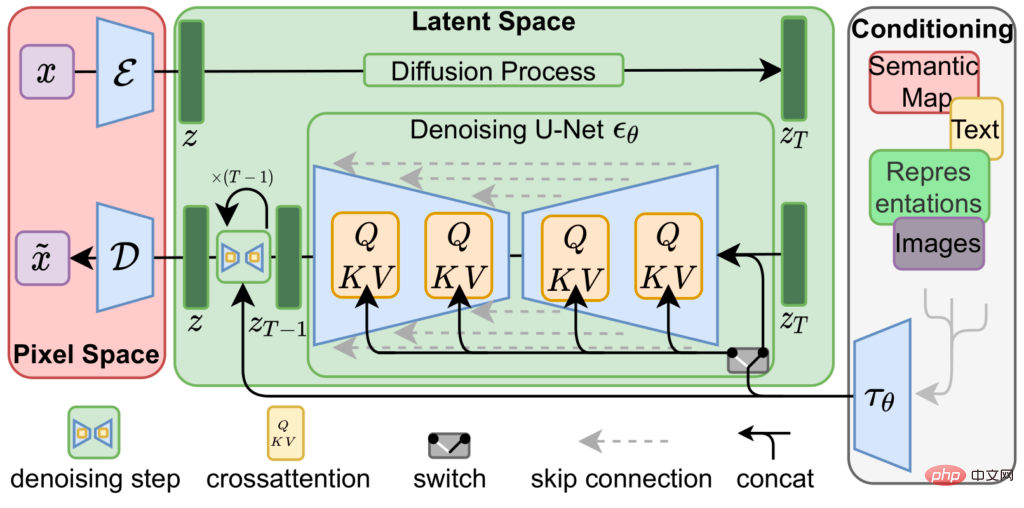
Le processus de formation de la VAE pour encoder des images dans un espace latent repose principalement sur un apprentissage auto-supervisé, c'est-à-dire que l'entrée et la sortie sont toutes deux des images sources, de sorte que le modèle est davantage formé, différent La représentation de l'espace latent peut être différente pour différentes versions du modèle. Après avoir remappé et interprété la représentation de l'espace latent en une image couleur à 4 canaux à l'aide de Stable Diffusion v1.4, elle ressemble à l'image du milieu ci-dessous, dans l'image source Les principales fonctionnalités sont toujours visibles .
Il est à noter que l'encodage aller-retour VAE une fois et
n'est pas sans perte #🎜🎜 #.Par exemple, après décodage, le ANNA nom
sur la bande bleue n'est pas aussi clair que l'image source, et la lisibilité est considérablement réduit. Les auto-encodeurs variationnels dans
Stable Diffusion v1.4 ne sont pas très bons pour représenter #🎜 🎜#Petit texte et visage images, je ne sais pas si ça sera amélioré dans la v1.5.
Le principal algorithme de compression de Stable Diffusion consiste à utiliser cette représentation spatiale latente des images pour générer de nouvelles images à partir de courtes descriptions textuelles.
Partez du bruit aléatoire représenté par l'espace latent, utilisez un U-Net entièrement entraîné pour supprimer de manière itérative le bruit de l'image de l'espace latent et utilisez une représentation plus simple pour générer la prédiction dans laquelle le modèle pense "voir" ce bruit, c'est un peu comme quand on regarde des nuages, restaure les formes ou les visages dans notre esprit à partir de formes irrégulières.
Lors de l'utilisation de Stable Diffusion pour générer des images, cette étape itérative de débruitage est guidée par un troisième composant, l'encodeur de texte, qui donne à U-Net une idée de ce qu'il devrait essayer de voir dans les informations sur le bruit.
Cependant, pour les tâches de compression, il n'est pas nécessaire d'avoir un encodeur de texte, donc le processus expérimental a uniquement créé un encodage de chaîne vide pour indiquer à U-Net d'effectuer un décodage non guidé pendant le processus de reconstruction d'image. Bruyant.
Afin d'utiliser Stable Diffusion comme codec de compression d'image, l'algorithme doit compresser efficacement la représentation latente produite par VAE.
On peut constater dans des expériences que le sous-échantillonnage de la représentation latente ou l'utilisation directe des méthodes de compression d'image avec perte existantes réduiront considérablement la qualité de l'image reconstruite.
Mais l'auteur a constaté que le décodage VAE semble être très efficace dans la quantification des représentations latentes.
La mise à l'échelle, le serrage et le remappage des potentiels de la virgule flottante aux entiers non signés de 8 bits ne produisent que de petites erreurs de reconstruction visibles.

En quantifiant la représentation latente de 8 bits, la taille des données représentée par l'image est désormais de 64*64*4*8 bits=16 Ko, ce qui est beaucoup plus petit que les 512*512*3*8 bits=768 Ko de l'image source non compressée
Si le nombre de représentations latentes est inférieur à 8 bits, cela ne produira pas de meilleurs résultats.
Si vous effectuez davantage de palettisation et de tramage sur l'image, l'effet de quantification s'améliorera à nouveau.
Création d'une représentation de palette utilisant la représentation latente de vecteurs 256*4*8 bits et le tramage Floyd-Steinberg, compressant davantage la taille des données à 64*64*8+256*4*8bit=5kB

Le jittering de la palette d'espace latent introduit du bruit, faussant les résultats du décodage. Cependant, étant donné que la diffusion stable est basée sur la suppression du bruit latent, U-Net peut être utilisé pour supprimer le bruit provoqué par la gigue.
Après 4 itérations, le résultat de la reconstruction est visuellement très proche de la version non quantifiée.

Bien que la quantité de données soit considérablement réduite (l'image source est 155 fois plus grande que l'image compressée), l'effet est très bon, mais certains artefacts sont également introduits (comme le motif en forme de cœur qui n'existe pas dans l'image originale) artefacts).
Fait intéressant, les artefacts introduits par ce schéma de compression ont un impact plus important sur le contenu de l'image que sur la qualité de l'image, et les images compressées de cette manière peuvent contenir ces types d'artefacts de compression.
L'auteur a également utilisé zlib pour effectuer une compression sans perte sur la palette et l'index. Dans les échantillons de test, la plupart des résultats de compression étaient moins de 5 Ko, mais cette méthode de compression a encore plus de place pour l'optimisation.
Afin d'évaluer le codec de compression, l'auteur n'a utilisé aucune image de test standard trouvée sur Internet , car les images sur Internet peuvent être apparues dans l'ensemble d'entraînement de Stable Diffusion, et la compression de ces images peut causer un avantage comparatif injuste.
Pour rendre la comparaison aussi juste que possible, l'auteur a utilisé les paramètres d'encodeur de la plus haute qualité de la bibliothèque d'images Python et a ajouté une compression de données sans perte des données JPG compressées à l'aide de la bibliothèque mozjpeg.
Il convient de noter que même si les résultats de Stable Diffusion semblent subjectivement bien meilleurs que les images compressées JPG et WebP, ils ne sont pas significativement meilleurs lorsqu'il s'agit de mesures standard comme PSNR ou SSIM. Mieux, mais pas pire.
C'est juste que les types d'artefacts introduits sont moins évidents car ils ont un impact plus important sur le contenu de l'image que sur la qualité de l'image.
Cette méthode de compression est également un peu dangereuse, bien que la qualité des fonctionnalités reconstruites soit élevée, le contenu peut être affecté par des artefacts de compression, même s'il semble très net .
Par exemple, dans une image de test, tandis que Stable Diffusion en tant que codec fait un bien meilleur travail pour maintenir la qualité de l'image, même le grain de la caméra La texture (grain de la caméra) est préservée (ce qui est difficile pour la plupart des algorithmes de compression traditionnels), mais son contenu est toujours affecté par les artefacts de compression et des fonctionnalités fines telles que les formes des bâtiments peuvent changer.

Bien sûr, il est impossible d'identifier plus de vérité dans une image compressée JPG que dans une image compressée à diffusion stable valeur, mais la haute qualité visuelle des résultats de compression à diffusion stable peut être trompeuse car les artefacts de compression dans JPG et WebP sont plus faciles à identifier.
Si vous aussi vous souhaitez reproduire l'expérience, l'auteur a open source le code sur Colab.
Lien du code : https://colab.research.google.com/drive/ 1Ci1VYHuFJK5eOX9TB0Mq4NsqkeDr MaaH ?usp=sharing
Enfin, l'auteur a déclaré que l'expérience conçue dans l'article est encore assez simple, mais l'effet est toujours surprenant,# 🎜🎜#Il y a encore beaucoup de choses à améliorer à l'avenir.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 CLIP-BEVFormer : superviser explicitement la structure BEVFormer pour améliorer les performances de détection à longue traîne
Mar 26, 2024 pm 12:41 PM
CLIP-BEVFormer : superviser explicitement la structure BEVFormer pour améliorer les performances de détection à longue traîne
Mar 26, 2024 pm 12:41 PM
Écrit ci-dessus et compréhension personnelle de l'auteur : À l'heure actuelle, dans l'ensemble du système de conduite autonome, le module de perception joue un rôle essentiel. Le véhicule autonome roulant sur la route ne peut obtenir des résultats de perception précis que via le module de perception en aval. dans le système de conduite autonome, prend des jugements et des décisions comportementales opportuns et corrects. Actuellement, les voitures dotées de fonctions de conduite autonome sont généralement équipées d'une variété de capteurs d'informations de données, notamment des capteurs de caméra à vision panoramique, des capteurs lidar et des capteurs radar à ondes millimétriques pour collecter des informations selon différentes modalités afin d'accomplir des tâches de perception précises. L'algorithme de perception BEV basé sur la vision pure est privilégié par l'industrie en raison de son faible coût matériel et de sa facilité de déploiement, et ses résultats peuvent être facilement appliqués à diverses tâches en aval.
 Implémentation d'algorithmes d'apprentissage automatique en C++ : défis et solutions courants
Jun 03, 2024 pm 01:25 PM
Implémentation d'algorithmes d'apprentissage automatique en C++ : défis et solutions courants
Jun 03, 2024 pm 01:25 PM
Les défis courants rencontrés par les algorithmes d'apprentissage automatique en C++ incluent la gestion de la mémoire, le multithread, l'optimisation des performances et la maintenabilité. Les solutions incluent l'utilisation de pointeurs intelligents, de bibliothèques de threads modernes, d'instructions SIMD et de bibliothèques tierces, ainsi que le respect des directives de style de codage et l'utilisation d'outils d'automatisation. Des cas pratiques montrent comment utiliser la bibliothèque Eigen pour implémenter des algorithmes de régression linéaire, gérer efficacement la mémoire et utiliser des opérations matricielles hautes performances.
 Explorez les principes sous-jacents et la sélection d'algorithmes de la fonction de tri C++
Apr 02, 2024 pm 05:36 PM
Explorez les principes sous-jacents et la sélection d'algorithmes de la fonction de tri C++
Apr 02, 2024 pm 05:36 PM
La couche inférieure de la fonction de tri C++ utilise le tri par fusion, sa complexité est O(nlogn) et propose différents choix d'algorithmes de tri, notamment le tri rapide, le tri par tas et le tri stable.
 L'intelligence artificielle peut-elle prédire la criminalité ? Explorez les capacités de CrimeGPT
Mar 22, 2024 pm 10:10 PM
L'intelligence artificielle peut-elle prédire la criminalité ? Explorez les capacités de CrimeGPT
Mar 22, 2024 pm 10:10 PM
La convergence de l’intelligence artificielle (IA) et des forces de l’ordre ouvre de nouvelles possibilités en matière de prévention et de détection de la criminalité. Les capacités prédictives de l’intelligence artificielle sont largement utilisées dans des systèmes tels que CrimeGPT (Crime Prediction Technology) pour prédire les activités criminelles. Cet article explore le potentiel de l’intelligence artificielle dans la prédiction de la criminalité, ses applications actuelles, les défis auxquels elle est confrontée et les éventuelles implications éthiques de cette technologie. Intelligence artificielle et prédiction de la criminalité : les bases CrimeGPT utilise des algorithmes d'apprentissage automatique pour analyser de grands ensembles de données, identifiant des modèles qui peuvent prédire où et quand les crimes sont susceptibles de se produire. Ces ensembles de données comprennent des statistiques historiques sur la criminalité, des informations démographiques, des indicateurs économiques, des tendances météorologiques, etc. En identifiant les tendances qui pourraient échapper aux analystes humains, l'intelligence artificielle peut donner du pouvoir aux forces de l'ordre.
 Algorithme de détection amélioré : pour la détection de cibles dans des images de télédétection optique haute résolution
Jun 06, 2024 pm 12:33 PM
Algorithme de détection amélioré : pour la détection de cibles dans des images de télédétection optique haute résolution
Jun 06, 2024 pm 12:33 PM
01Aperçu des perspectives Actuellement, il est difficile d'atteindre un équilibre approprié entre efficacité de détection et résultats de détection. Nous avons développé un algorithme YOLOv5 amélioré pour la détection de cibles dans des images de télédétection optique haute résolution, en utilisant des pyramides de caractéristiques multicouches, des stratégies de têtes de détection multiples et des modules d'attention hybrides pour améliorer l'effet du réseau de détection de cibles dans les images de télédétection optique. Selon l'ensemble de données SIMD, le mAP du nouvel algorithme est 2,2 % meilleur que YOLOv5 et 8,48 % meilleur que YOLOX, permettant ainsi d'obtenir un meilleur équilibre entre les résultats de détection et la vitesse. 02 Contexte et motivation Avec le développement rapide de la technologie de télédétection, les images de télédétection optique à haute résolution ont été utilisées pour décrire de nombreux objets à la surface de la Terre, notamment des avions, des voitures, des bâtiments, etc. Détection d'objets dans l'interprétation d'images de télédétection
 Comment éditer des photos sur iPhone avec iOS 17
Nov 30, 2023 pm 11:39 PM
Comment éditer des photos sur iPhone avec iOS 17
Nov 30, 2023 pm 11:39 PM
La photographie mobile a fondamentalement changé la façon dont nous capturons et partageons les moments de la vie. L’avènement des smartphones, notamment de l’iPhone, a joué un rôle clé dans cette évolution. Connu pour sa technologie d'appareil photo avancée et ses fonctionnalités d'édition conviviales, l'iPhone est devenu le premier choix des photographes amateurs et expérimentés. Le lancement d’iOS 17 marque une étape importante dans ce voyage. La dernière mise à jour d'Apple apporte un ensemble amélioré de fonctionnalités de retouche photo, offrant aux utilisateurs une boîte à outils plus puissante pour transformer leurs instantanés quotidiens en images visuellement attrayantes et artistiquement riches. Ce développement technologique simplifie non seulement le processus photographique, mais ouvre également de nouvelles voies d'expression créative, permettant aux utilisateurs d'injecter sans effort une touche professionnelle à leurs photos.
 Application d'algorithmes dans la construction de 58 plateformes de portraits
May 09, 2024 am 09:01 AM
Application d'algorithmes dans la construction de 58 plateformes de portraits
May 09, 2024 am 09:01 AM
1. Contexte de la construction de la plateforme 58 Portraits Tout d'abord, je voudrais partager avec vous le contexte de la construction de la plateforme 58 Portraits. 1. La pensée traditionnelle de la plate-forme de profilage traditionnelle ne suffit plus. La création d'une plate-forme de profilage des utilisateurs s'appuie sur des capacités de modélisation d'entrepôt de données pour intégrer les données de plusieurs secteurs d'activité afin de créer des portraits d'utilisateurs précis. Elle nécessite également l'exploration de données pour comprendre le comportement et les intérêts des utilisateurs. et besoins, et fournir des capacités côté algorithmes ; enfin, il doit également disposer de capacités de plate-forme de données pour stocker, interroger et partager efficacement les données de profil utilisateur et fournir des services de profil. La principale différence entre une plate-forme de profilage d'entreprise auto-construite et une plate-forme de profilage de middle-office est que la plate-forme de profilage auto-construite dessert un seul secteur d'activité et peut être personnalisée à la demande. La plate-forme de mid-office dessert plusieurs secteurs d'activité et est complexe ; modélisation et offre des fonctionnalités plus générales. 2.58 Portraits d'utilisateurs de l'arrière-plan de la construction du portrait sur la plate-forme médiane 58
 Ajoutez SOTA en temps réel et montez en flèche ! FastOcc : un algorithme Occ plus rapide et convivial pour le déploiement est là !
Mar 14, 2024 pm 11:50 PM
Ajoutez SOTA en temps réel et montez en flèche ! FastOcc : un algorithme Occ plus rapide et convivial pour le déploiement est là !
Mar 14, 2024 pm 11:50 PM
Écrit ci-dessus & La compréhension personnelle de l'auteur est que dans le système de conduite autonome, la tâche de perception est un élément crucial de l'ensemble du système de conduite autonome. L'objectif principal de la tâche de perception est de permettre aux véhicules autonomes de comprendre et de percevoir les éléments environnementaux environnants, tels que les véhicules circulant sur la route, les piétons au bord de la route, les obstacles rencontrés lors de la conduite, les panneaux de signalisation sur la route, etc., aidant ainsi en aval modules Prendre des décisions et des actions correctes et raisonnables. Un véhicule doté de capacités de conduite autonome est généralement équipé de différents types de capteurs de collecte d'informations, tels que des capteurs de caméra à vision panoramique, des capteurs lidar, des capteurs radar à ondes millimétriques, etc., pour garantir que le véhicule autonome peut percevoir et comprendre avec précision l'environnement environnant. éléments , permettant aux véhicules autonomes de prendre les bonnes décisions pendant la conduite autonome. Tête
