

Il y a quelques jours, les commentaires de Yann LeCun, scientifique en chef de l'intelligence artificielle de Meta, à propos de ChatGPT se sont rapidement répandus dans l'industrie et ont déclenché de nombreuses discussions.
Lors d'un petit rassemblement de médias et de dirigeants chez Zoom, LeCun a fait un commentaire surprenant : "En ce qui concerne la technologie sous-jacente, ChatGPT n'est pas une grande innovation
"Bien qu'aux yeux du public, c'est révolutionnaire." , mais nous savons que c'est un produit bien assemblé, rien de plus. monde et a même changé la carrière de certaines personnes et la situation actuelle de l’enseignement scolaire.
 "En plus de Google et Meta, il existe six startups, essentiellement toutes dotées d'une technologie très similaire", a ajouté LeCun.
"En plus de Google et Meta, il existe six startups, essentiellement toutes dotées d'une technologie très similaire", a ajouté LeCun.
 Parmi eux, Transformer est l’invention de Google. Ce type de réseau neuronal linguistique constitue la base de modèles linguistiques à grande échelle tels que GPT-3.
Parmi eux, Transformer est l’invention de Google. Ce type de réseau neuronal linguistique constitue la base de modèles linguistiques à grande échelle tels que GPT-3.
Le premier modèle de langage de réseau neuronal a été proposé par Yoshua Bengio il y a 20 ans. Le mécanisme d'attention de Bengio a ensuite été utilisé par Google dans Transformer et est depuis devenu un élément clé dans tous les modèles de langage.
De plus, ChatGPT utilise la technologie d'apprentissage par renforcement par retour humain (RLHF), également lancée par Google DeepMind Lab.
De l’avis de LeCun, ChatGPT est plus un cas d’ingénierie réussi qu’une avancée scientifique.
La technologie d'OpenAI "n'a rien d'innovant en termes de science fondamentale, elle est juste bien conçue."
"Bien sûr, je ne les critiquerai pas pour ça
Je ne critique pas le travail d'OpenAI." , et ce n’est pas non plus une critique de leurs idées. Je souhaite corriger l'opinion du public et des médias. Ils pensent généralement que ChatGPT est une avancée technologique innovante et unique, mais ce n'est pas le cas. Lors d'une table ronde avec le journaliste du New York Times Cade Metz, LeCun a ressenti les doutes des gens occupés.
Lors d'une table ronde avec le journaliste du New York Times Cade Metz, LeCun a ressenti les doutes des gens occupés.
"Vous voudrez peut-être demander pourquoi Google et Meta n'ont pas de systèmes similaires ? Ma réponse est que si Google et Meta lancent des chatbots aussi absurdes, les pertes seront assez lourdes", a-t-il déclaré avec un sourire.
Par coïncidence, dès que la nouvelle est sortie selon laquelle OpenAI était favorisée par Microsoft et d'autres investisseurs et que sa valeur grimpait à 29 milliards de dollars américains, Marcus a également écrit du jour au lendemain un article sur son blog pour le ridiculiser. Dans l'article, Marcus a lancé une phrase en or : que peut faire OpenAI que Google ne peut pas faire, et vaut-il un prix exorbitant de 29 milliards de dollars ?
 Sans plus attendre, sortons les chatbots de ces géants de l’IA et laissons les données parler d’elles-mêmes.
Sans plus attendre, sortons les chatbots de ces géants de l’IA et laissons les données parler d’elles-mêmes.
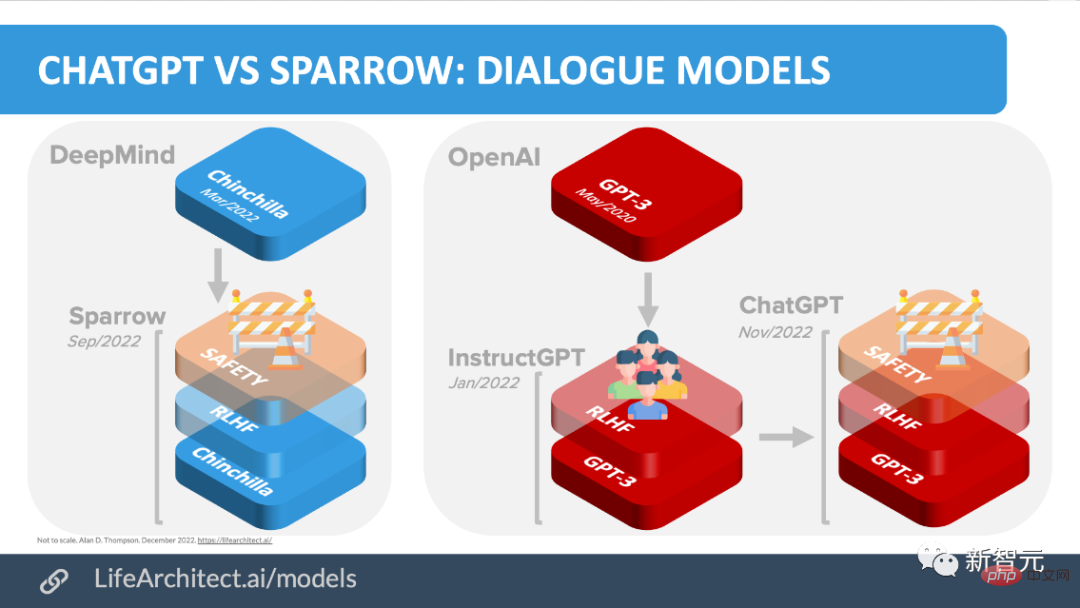
ChatGPT n'est pas le premier chatbot IA basé sur un modèle de langage, il a de nombreux « prédécesseurs ».
Avant OpenAI, Meta, Google, DeepMind, etc. ont tous publié leurs propres chatbots, tels que BlenderBot de Meta, LaMDA de Google et Sparrow de DeepMind.
Certaines équipes ont également annoncé leurs propres plans de chatbot open source. Par exemple, Open-Assistant de LAION.
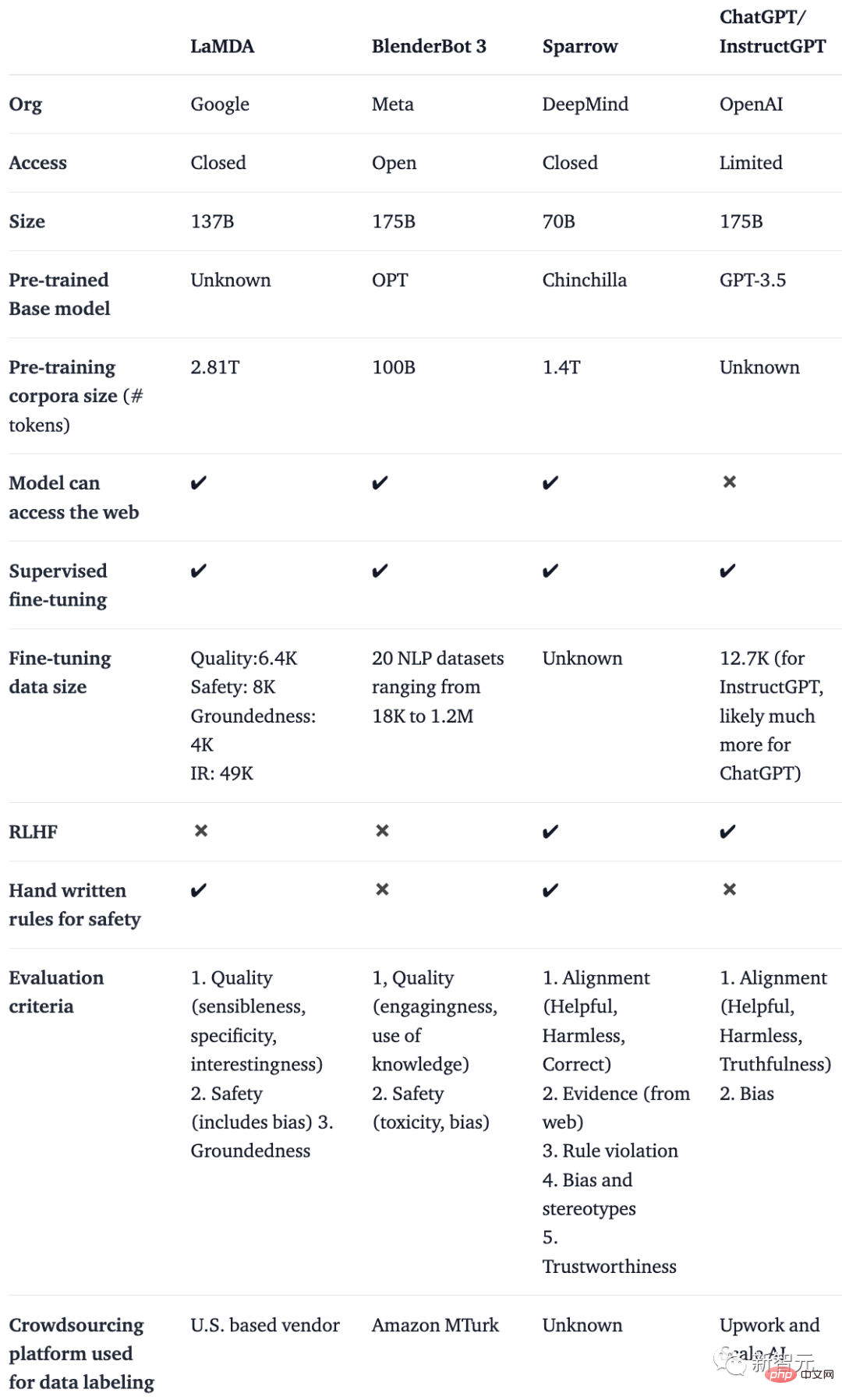
Dans un blog de Huggingface, plusieurs auteurs ont étudié des articles importants sur les thèmes RLHF, SFT, IFT et CoT (ce sont tous des mots-clés de ChatGPT), les ont classés et résumés.Ils ont créé un tableau comparant les chatbots IA tels que BlenderBot, LaMDA, Sparrow et InstructGPT sur la base de détails tels que l'accès public, les données de formation, l'architecture du modèle et la direction de l'évaluation.
Remarque : Comme ChatGPT n'est pas documenté, ils utilisent les détails d'InstructGPT, un modèle de réglage fin des instructions d'OpenAI qui peut être considéré comme la base de ChatGPT.
LaMDA |
BlenderBot3 |
Sparrow |
ChatGPT/ InstructGPT |
|
Organisation | |
Meta |
DeepMind |
OpenAI |
Accès |
Fermé |
Public |
Fermé |
Limité |
échelle de paramètres |
137 milliards | #🎜 ° 🎜#Modèle de base | Unknown | # 🎜🎜#OPT |
| Chinchilla | GPT-3.5# 🎜 🎜# | Taille du corpus |
2,81 billions |
#🎜 🎜 # 100 Milliards 🎜🎜#Access Network |
| ✔️ | ✔️# 🎜 🎜 # | ✔️ |
✖️ |
|
Supervision et mise au point |
✔️ |
✔️ |
|
✔️ |
Affiner le taille des données |
Haute qualité : 6,4K Sécurité : 8K Flottabilité : 4K IR : 49K |
20 ensembles de données NLP allant de 18K à 1,2M |
Un connu |
12,7K ( ChatGPT peut-être plus) |
✔ |
✖️ |
✔ |
✖️ |
Il n'est pas difficile de constater que malgré de nombreuses différences dans les données d'entraînement, les modèles de base et les réglages fins, ces chatbots ont tous une chose en commun : suivre les instructions.
Par exemple, vous pouvez commander à ChatGPT d'écrire un poème sur le réglage fin.
On voit que ChatGPT est très « avisé » et n'oublie jamais de flatter LeCun et Hinton lorsqu'ils écrivent des poèmes.
Puis il a loué avec passion : "Tourne, tourne, tu es une belle danse." De la prédiction du texte au suivi des instructions

Dans la formation du modèle, les chercheurs n'utiliseront pas seulement des tâches classiques de PNL (telles que l'émotion, la classification de texte, le résumé, etc.), mais utiliser également des instructions Le réglage fin (IFT) consiste à affiner le modèle de base grâce à des instructions textuelles sur des tâches très diverses.
Parmi eux, ces exemples de commandes sont composés de trois parties principales : commande, entrée et sortie. 
Les données IFT sont généralement une collection d'instructions écrites par des humains et des exemples d'instructions guidés par des modèles de langage.
Pendant le processus de démarrage, LM est invité à effectuer un réglage de quelques tirs (petit échantillon) (comme indiqué ci-dessus) et est invité à générer de nouvelles instructions, entrées et sorties. 
Une extrémité est un ensemble de données IFT purement généré par un modèle, tel que les instructions non naturelles, et l'autre extrémité est un grand nombre d'instructions générées artificiellement, comme les instructions surnaturelles.
Quelque part entre les deux, il faut utiliser un ensemble de données de départ plus petit mais de meilleure qualité, puis effectuer un travail guidé, tel que l'auto-instruction. 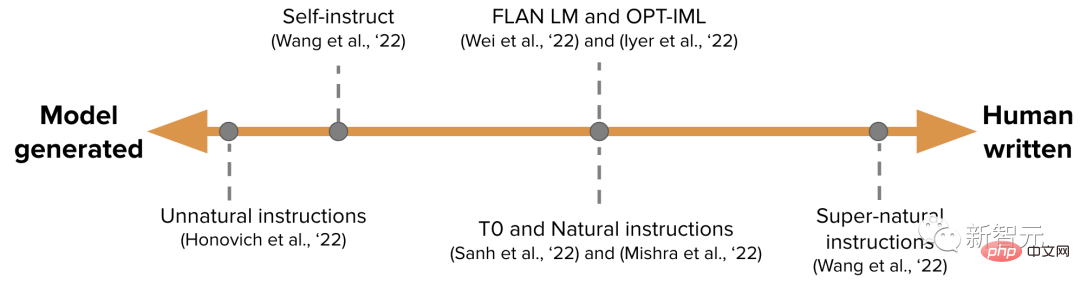
Articles connexes sur l'ensemble de données d'instruction naturelle : https://arxiv.org/abs/2104.08773
Fine-tune le modèle 
Dans RLHF, un ensemble de réponses modèles sont classées en fonction des commentaires humains (par exemple, le choix d'un texte d'introduction plus populaire).
Ensuite, les chercheurs ont formé un modèle de préférence sur ces réponses annotées, renvoyant une récompense scalaire à l'optimiseur RL. 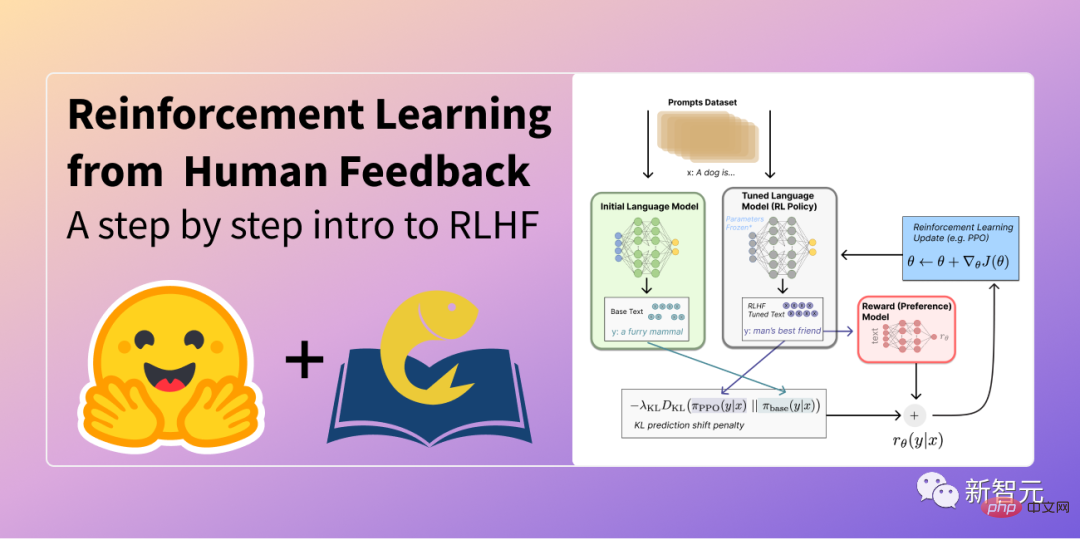
Les invites de chaîne de pensée (CoT) sont un cas particulier de l'exemple d'instruction, qui produisent une sortie en incitant le chatbot à raisonner étape par étape.
Les modèles affinés avec CoT utilisent un ensemble de données d'instructions pour une inférence étape par étape avec des annotations humaines. 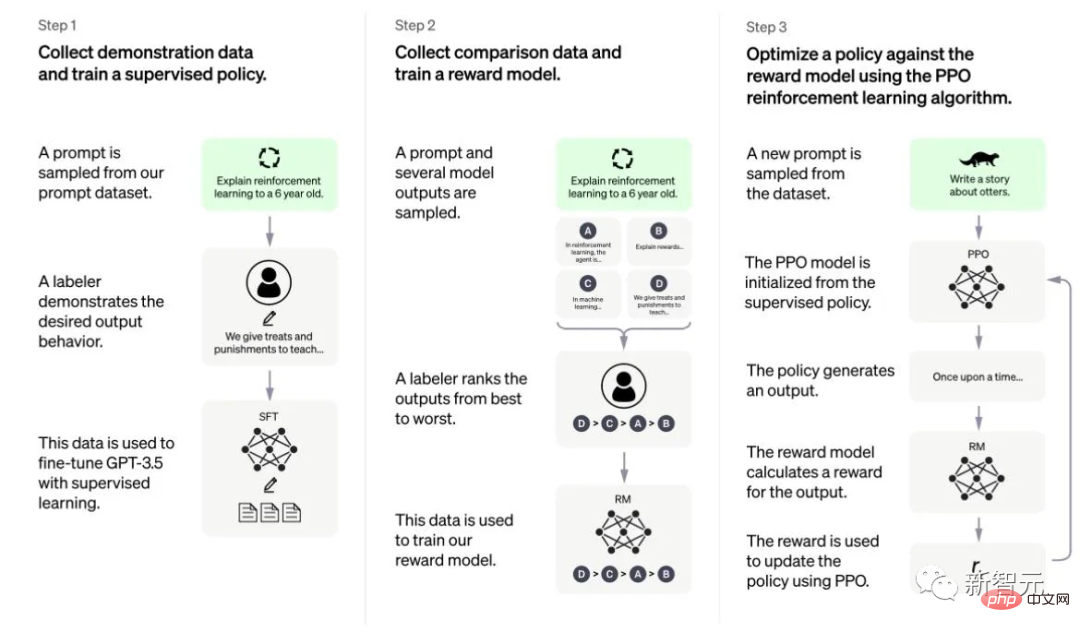
L'exemple suivant est tiré de « Mise à l'échelle des modèles de langage affinés par les instructions ». Parmi eux, l'orange met en évidence les instructions, le rose montre l'entrée et la sortie et le bleu est l'inférence CoT.

L'article souligne que les modèles utilisant le réglage fin du CoT sont plus performants dans les tâches impliquant le bon sens, l'arithmétique et le raisonnement symbolique.
De plus, le réglage fin du CoT est également très efficace sur des sujets sensibles (parfois mieux que RLHF), notamment pour éviter la corruption du modèle - "Désolé, je ne peux pas répondre".

Comme je viens de le mentionner, les modèles linguistiques adaptés aux instructions ne peuvent pas toujours produire des réponses utiles et sûres.
Par exemple, il échappera en donnant des réponses inutiles, telles que « Désolé, je ne comprends pas » ou en émettant des réponses dangereuses aux utilisateurs qui soulèvent des sujets sensibles.
Pour améliorer ce comportement, les chercheurs affinent le modèle de langage de base sur des données annotées humaines de haute qualité sous forme de réglage fin supervisé (SFT), améliorant ainsi l'utilité et l'innocuité du modèle.

Le lien entre SFT et IFT est très étroit. IFT peut être considéré comme un sous-ensemble de SFT. Dans la littérature récente, la phase SFT est souvent utilisée pour des sujets de sécurité plutôt que pour des sujets d'instructions spécifiques qui sont complétés après l'IFT.
À l'avenir, leur classification et leur description devraient avoir des cas d'utilisation plus clairs.
De plus, LaMDA de Google est également affiné sur un ensemble de données de conversation annotées de manière sécurisée qui comporte des annotations de sécurité basées sur une série de règles.
Ces règles sont souvent prédéfinies et élaborées par des chercheurs et couvrent un large éventail de sujets, notamment les préjudices, la discrimination, la désinformation, etc.
Il reste encore de nombreuses questions ouvertes à explorer concernant les chatbots IA, telles que :
1. Quelle est l'importance de la RL dans l'apprentissage à partir des commentaires humains ? Pouvons-nous obtenir les performances du RLHF en IFT ou SFT avec une formation sur les données de meilleure qualité ?
2. Comment la sécurité de SFT+RLHF dans Sparrow se compare-t-elle à celle de SFT uniquement dans LaMDA ?
3. Étant donné que nous avons déjà IFT, SFT, CoT et RLHF, combien de pré-formation supplémentaire est nécessaire ? Quels sont les compromis ? Quel est le meilleur modèle de base (public et privé) ?
4. Désormais, ces modèles sont soigneusement conçus, dans lesquels les chercheurs recherchent spécifiquement les modes de défaillance et influencent la formation future (y compris les conseils et les méthodes) en fonction des problèmes révélés. Comment documenter et reproduire systématiquement les effets de ces méthodes ?
1. Par rapport aux données d'entraînement, seule une très petite partie est nécessaire pour affiner l'enseignement (des centaines d'ordres de grandeur).
2. Le réglage fin supervisé utilise des annotations humaines pour rendre la sortie du modèle plus sécurisée et plus utile.
3. Le réglage fin du CoT améliore les performances du modèle dans les tâches de réflexion étape par étape et empêche le modèle d'échapper toujours aux problèmes sensibles.
Référence :
https://huggingface.co/blog/dialog-agents
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
 Inscription ChatGPT
Inscription ChatGPT
 Encyclopédie ChatGPT nationale gratuite
Encyclopédie ChatGPT nationale gratuite
 Comment installer chatgpt sur un téléphone mobile
Comment installer chatgpt sur un téléphone mobile
 Chatgpt peut-il être utilisé en Chine ?
Chatgpt peut-il être utilisé en Chine ?
 Solution d'erreur httpsstatus500
Solution d'erreur httpsstatus500
 Comment récupérer l'historique des discussions WeChat supprimé
Comment récupérer l'historique des discussions WeChat supprimé
 Comment configurer WeChat pour qu'il exige mon consentement lorsque des personnes m'ajoutent à un groupe ?
Comment configurer WeChat pour qu'il exige mon consentement lorsque des personnes m'ajoutent à un groupe ?
 Comment résoudre err_connection_reset
Comment résoudre err_connection_reset








![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



