
 Périphériques technologiques
IA
Discussion intéressante sur les principes et les algorithmes de ChatGPT
Périphériques technologiques
IA
Discussion intéressante sur les principes et les algorithmes de ChatGPT
Discussion intéressante sur les principes et les algorithmes de ChatGPT

Le 1er décembre de l'année dernière, OpenAI a lancé le prototype de chat d'intelligence artificielle ChatGPT, qui a une fois de plus attiré l'attention et déclenché une grande discussion dans la communauté de l'IA similaire à l'AIGC mettant les artistes au chômage.
ChatGPT est un modèle de langage axé sur la génération de conversations. Il peut générer des réponses intelligentes correspondantes basées sur la saisie de texte de l'utilisateur.
Cette réponse peut être des mots courts ou un long essai. Parmi eux, GPT est l'abréviation de Generative Pre-trained Transformer (modèle de transformation générative pré-entraînée).
En apprenant d'un grand nombre de collections de textes et de dialogues prêtes à l'emploi (telles que Wiki), ChatGPT peut avoir des conversations instantanées comme les humains et répondre couramment à diverses questions. (Bien sûr, la vitesse de réponse est toujours plus lente que celle des humains) Qu'il s'agisse de l'anglais ou d'autres langues (comme le chinois, le coréen, etc.), de la réponse à des questions historiques à l'écriture d'histoires et même à l'écriture d'affaires plans et analyses industrielles, «presque» peut tout faire. Certains programmeurs ont même publié des conversations sur ChatGPT concernant les modifications du programme.
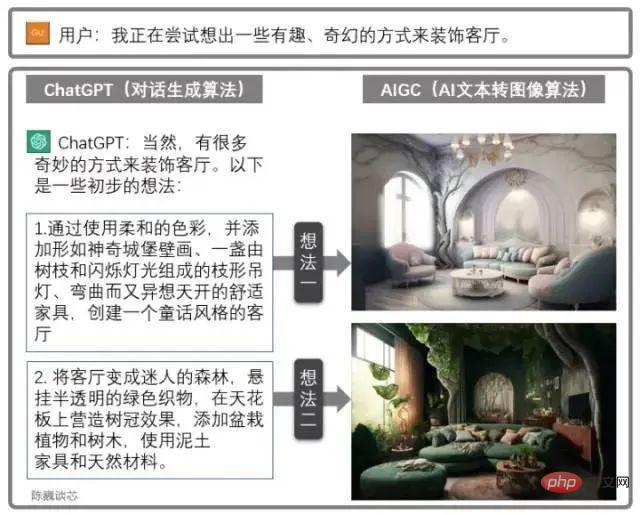
Utilisation combinée de ChatGPT et AIGC
ChatGPT peut également être utilisé en conjonction avec d'autres modèles AIGC pour obtenir des fonctions plus intéressantes et pratiques.
Par exemple, le dessin de conception du salon est généré via le dialogue ci-dessus. Cela améliore considérablement la capacité des applications d’IA à communiquer avec les clients, ce qui nous permet d’entrevoir l’aube d’une mise en œuvre à grande échelle de l’IA.
1. L'héritage et les caractéristiques de ChatGPT

▌1.1 Famille OpenAI
Comprenons d'abord qui est OpenAI.
OpenAI a son siège à San Francisco et a été cofondée par Musk de Tesla, Sam Altman et d'autres investisseurs en 2015. L'objectif est de développer une technologie d'IA qui profite à toute l'humanité. Musk a quitté l'entreprise en 2018 en raison de divergences dans l'orientation du développement de l'entreprise.
Auparavant, OpenAI était célèbre pour avoir lancé la série GPT de modèles de traitement du langage naturel. Depuis 2018, OpenAI a commencé à publier le modèle de langage génératif pré-entraîné GPT (Generative Pre-trained Transformer), qui peut être utilisé pour générer divers contenus tels que des articles, des codes, des traductions automatiques et des questions-réponses.
Le nombre de paramètres de chaque génération de modèles GPT a explosé, ce que l'on peut dire : « plus c'est gros, mieux c'est ». GPT-2 publié en février 2019 comptait 1,5 milliard de paramètres, tandis que GPT-3 en mai 2020 comptait 175 milliards de paramètres.
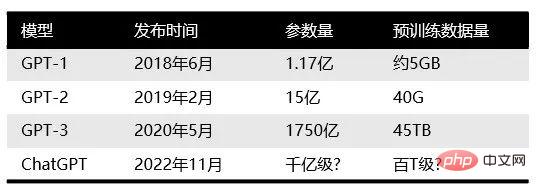
Comparaison des principaux modèles de la famille GPT
▌1.2 Principales fonctionnalités de ChatGPT
ChatGPT est un modèle d'IA conversationnelle développé sur la base de l'architecture GPT-3.5 (Generative Pre-trained Transformer 3.5) et est un frère modèle d’InstructGPT.
ChatGPT est probablement un exercice d'OpenAI avant le lancement officiel de GPT-4, ou utilisé pour collecter de grandes quantités de données de conversation.
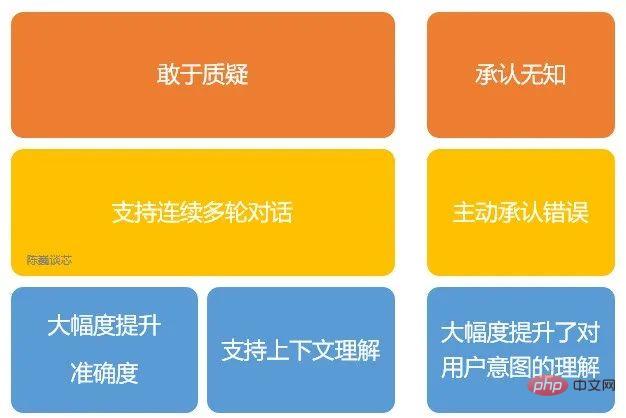
Principales fonctionnalités de ChatGPT
OpenAI utilise la technologie RLHF (Reinforcement Learning from Human Feedbac, human feedback renforcement learning) pour former ChatGPT et ajoute davantage de supervision manuelle pour un réglage précis.
De plus, ChatGPT présente également les caractéristiques suivantes :
1) Il peut admettre de manière proactive ses propres erreurs. Si l'utilisateur signale son erreur, le modèle écoute et affine la réponse.
2) ChatGPT peut remettre en question des questions incorrectes. Par exemple, à la question « Que se passerait-il si Colomb venait aux États-Unis en 2015 ? », le robot expliquerait que Colomb n'appartient pas à cette époque et ajusterait la réponse.
3) ChatGPT peut admettre sa propre ignorance et son manque de compréhension de la technologie professionnelle.
4) Prend en charge plusieurs cycles de dialogue continu.
Différent des différents haut-parleurs intelligents et des « retardateurs d'intelligence artificielle » que tout le monde utilise dans la vie, ChatGPT se souviendra des messages de conversation des utilisateurs précédents pendant la conversation, c'est-à-dire la compréhension du contexte, pour répondre à certaines questions hypothétiques.
ChatGPT peut réaliser des conversations continues, améliorant considérablement l'expérience utilisateur en mode interaction conversation.
Pour une traduction précise (en particulier le chinois et la translittération des noms), ChatGPT est encore loin d'être parfait, mais il est similaire à d'autres outils de traduction en ligne en termes de fluidité du texte et d'identification de noms spécifiques.
Étant donné que ChatGPT est un grand modèle de langage et ne dispose actuellement pas de capacités de recherche sur réseau, il ne peut répondre qu'en fonction de l'ensemble de données dont il dispose en 2021.
Par exemple, il ne connaît pas la situation de la Coupe du monde 2022, il ne répondra pas non plus à la météo aujourd'hui ni ne vous aidera à rechercher des informations comme Siri d'Apple. Si ChatGPT peut aller en ligne pour trouver du matériel d'apprentissage et rechercher des connaissances par lui-même, on estime qu'il y aura des percées encore plus importantes.
Même si les connaissances acquises sont limitées, ChatGPT peut toujours répondre à de nombreuses questions étranges d'humains à l'esprit ouvert. Afin d'empêcher ChatGPT de prendre de mauvaises habitudes, ChatGPT est protégé par des algorithmes pour réduire les entrées de formation nuisibles et trompeuses.
Les requêtes sont filtrées via l'API de modération et les astuces potentiellement racistes ou sexistes sont rejetées.
2. Principe de ChatGPT/GPT
▌2.1 NLP
Les limitations connues dans le domaine NLP/NLU incluent la répétition de textes, l'incompréhension de sujets hautement spécialisés et l'incompréhension d'expressions contextuelles.
Pour les humains ou l'IA, il faut généralement des années d'entraînement pour avoir une conversation normale.
Les modèles de type PNL doivent non seulement comprendre le sens des mots, mais également comprendre comment former des phrases et donner des réponses contextuellement significatives, même en utilisant un argot et un vocabulaire professionnel appropriés.
Champs d'application de la technologie PNL
Essentiellement, GPT-3 ou GPT-3.5, qui est la base de ChatGPT, est un très grand modèle de langage statistique ou modèle de prédiction de texte séquentiel.
▌2.2 GPT vs BERT
Similaire au modèle BERT, ChatGPT ou GPT-3.5 génère automatiquement chaque mot (mot) de la réponse en fonction de la phrase d'entrée et de la probabilité de langue/corpus.
D'un point de vue mathématique ou d'apprentissage automatique, un modèle de langage est une modélisation de la distribution de corrélation de probabilité de séquences de mots, c'est-à-dire en utilisant des déclarations déjà prononcées (les déclarations peuvent être considérées comme des vecteurs en mathématiques) comme conditions d'entrée pour prédire la distribution de probabilité. de l'apparition de phrases différentes ou même d'ensembles de langues à l'instant suivant.
ChatGPT est formé à l'aide de l'apprentissage par renforcement à partir des commentaires humains, une méthode qui améliore l'apprentissage automatique avec l'intervention humaine pour de meilleurs résultats.
Pendant le processus de formation, les formateurs humains jouent le rôle d'utilisateurs et d'assistants d'intelligence artificielle, et sont affinés grâce à des algorithmes d'optimisation des politiques proximales.
En raison des performances plus élevées et des paramètres massifs de ChatGPT, il contient des données sur plus de sujets et peut gérer davantage de sujets de niche.
ChatGPT peut désormais gérer davantage de tâches telles que répondre à des questions, rédiger des articles, résumer des textes, traduire des langues et générer du code informatique.
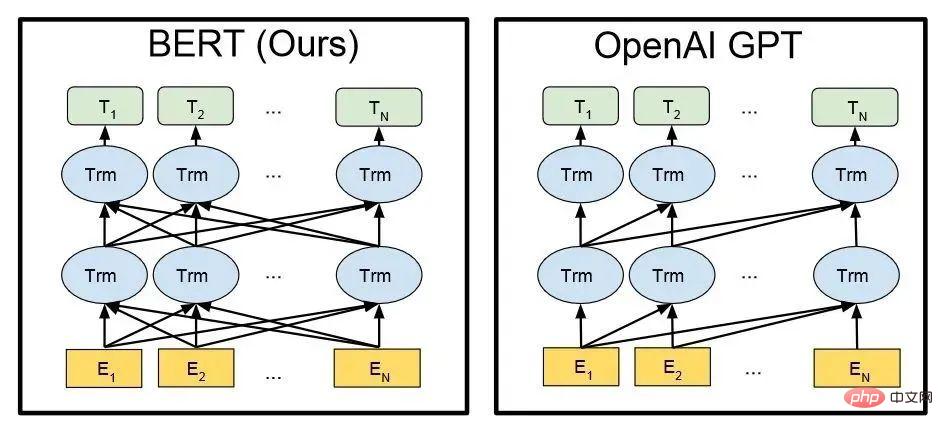
Architecture technique de BERT et GPT (En dans la figure est chaque mot d'entrée, Tn est chaque mot de réponse de sortie)
3. Architecture technique de ChatGPT
▌3.1 Evolution de la famille GPT
Quand il vient à ChatGPT, vous devez mentionner la famille GPT.
ChatGPT avait plusieurs frères bien connus avant lui, dont GPT-1, GPT-2 et GPT-3. Chacun de ces frères est plus grand que l’autre et ChatGPT ressemble davantage à GPT-3.
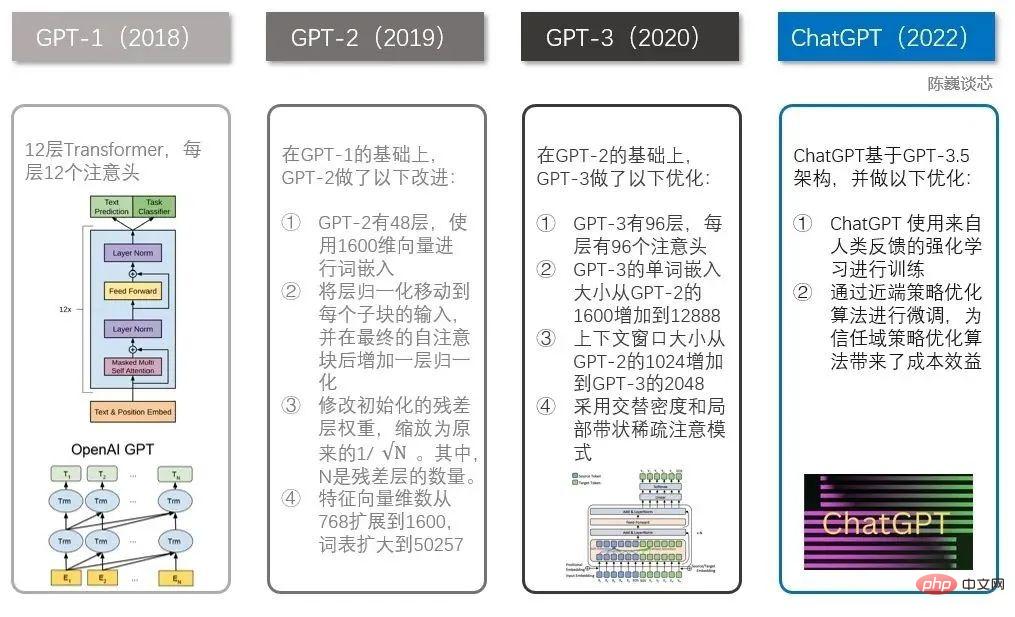
Comparaison technique entre ChatGPT et GPT 1-3
La famille GPT et le modèle BERT sont tous deux des modèles NLP bien connus, tous deux basés sur la technologie Transformer. GPT-1 n'a que 12 couches de transformateur, mais avec GPT-3, il est passé à 96 couches.
▌3.2 Apprentissage par renforcement du feedback humain
La principale différence entre InstructGPT/GPT3.5 (le prédécesseur de ChatGPT) et GPT-3 est qu'une nouvelle fonctionnalité appelée RLHF (Reinforcement Learning from Human Feedback, apprentissage par renforcement du feedback humain) a été ajouté.
Ce paradigme de formation améliore la régulation humaine des résultats de sortie du modèle et aboutit à un classement plus compréhensible.
Dans InstructGPT, voici les critères d'évaluation de la « qualité des phrases ».
- Authenticité : S'agit-il d'une fausse information ou d'une information trompeuse ?
- Innocuité : cause-t-il des dommages physiques ou mentaux aux personnes ou à l'environnement ?
- Utilité : cela résout-il la tâche de l'utilisateur ?
▌3.3 Cadre TAMER
Je dois mentionner le cadre TAMER (Training an Agent Manually via Evaluative Reinforcement).
Ce cadre introduit des marqueurs humains dans le cycle d'apprentissage des agents et peut fournir des commentaires de récompense aux agents par l'intermédiaire des humains (c'est-à-dire guider les agents dans leur formation), atteignant ainsi rapidement les objectifs des tâches de formation.
L'objectif principal de l'introduction des étiqueteurs humains est d'accélérer la formation. Bien que la technologie d'apprentissage par renforcement ait des performances exceptionnelles dans de nombreux domaines, elle présente encore de nombreux inconvénients, tels qu'une vitesse de convergence lente et un coût de formation élevé.
Surtout dans le monde réel, de nombreuses tâches ont des coûts d'exploration ou d'acquisition de données élevés. Comment accélérer l'efficacité de la formation est l'une des questions importantes à résoudre dans les tâches d'apprentissage par renforcement d'aujourd'hui.
TAMER peut utiliser la connaissance des marqueurs humains pour former l'agent sous forme de retour de lettre de récompense afin d'accélérer sa convergence rapide.
TAMER ne nécessite pas que le tagueur ait des connaissances professionnelles ou des compétences en programmation, et le coût du corpus est inférieur. Avec TAMER+RL (apprentissage par renforcement), le processus d'apprentissage par renforcement (RL) à partir des récompenses du processus de décision de Markov (MDP) peut être amélioré grâce aux commentaires des marqueurs humains.
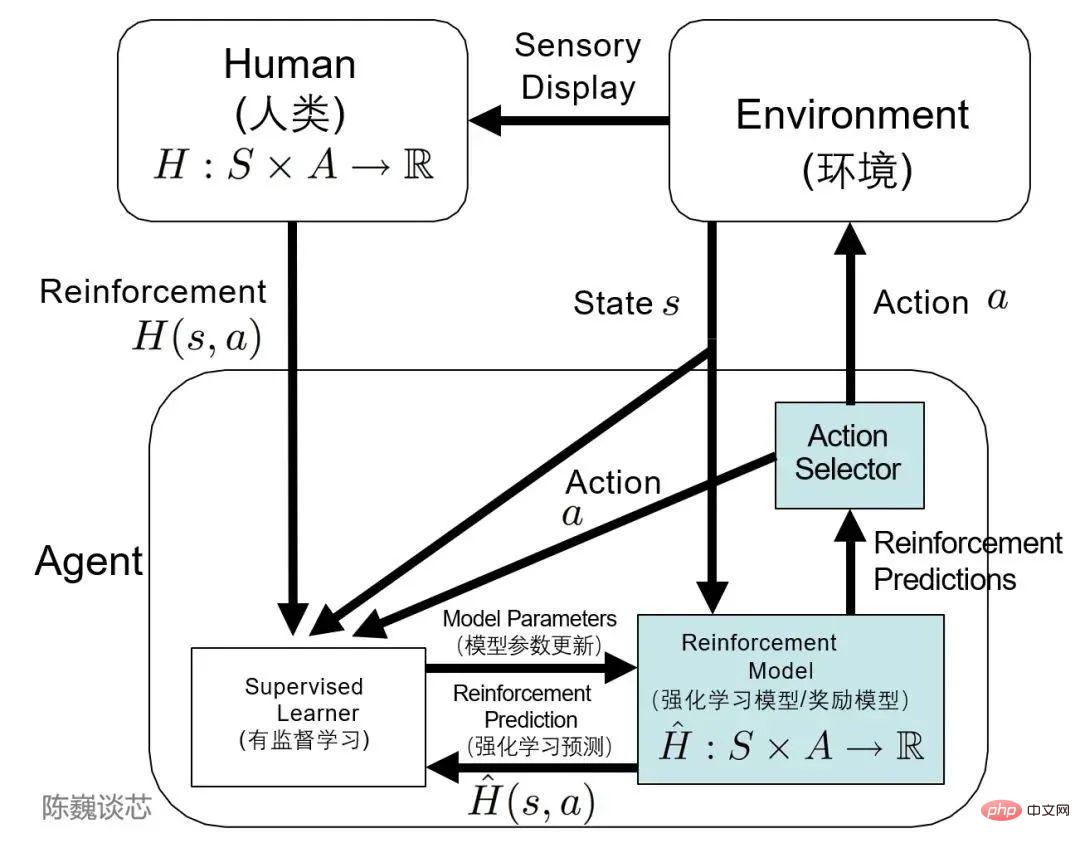
Application de l'architecture TAMER dans l'apprentissage par renforcement
En termes de mise en œuvre spécifique, les étiqueteurs humains agissent en tant qu'utilisateurs de conversation et assistants d'intelligence artificielle, fournissent des échantillons de conversation, laissent le modèle générer des réponses, puis les étiqueteurs noteront et classeront les options de réponse, introduisant de meilleurs résultats dans le modèle.
Les agents apprennent simultanément de deux modes de rétroaction : le renforcement humain et la récompense du processus de décision de Markov en tant que système intégré, affinant et itérant continuellement le modèle grâce à des stratégies de récompense.
Sur cette base, ChatGPT peut mieux comprendre et compléter le langage ou les instructions humaines que GPT-3, imiter les humains et fournir des informations textuelles cohérentes et logiques.
▌3.4 Formation de ChatGPT
Le processus de formation de ChatGPT est divisé en trois étapes suivantes :
Première étape : former le modèle de politique supervisé
GPT 3.5 lui-même est difficile à comprendre les différentes intentions contenues dans les différents types de instructions humaines, et c'est également très difficile de juger si le contenu généré est un résultat de haute qualité.
Pour que GPT 3.5 ait initialement l'intention de comprendre les instructions, les questions seront d'abord sélectionnées au hasard dans l'ensemble de données, et des annotateurs humains donneront des réponses de haute qualité. Ensuite, ces données annotées manuellement seront utilisées pour affiner le. Modèle GPT-3.5 (obtenir le modèle SFT, réglage fin supervisé).
Le modèle SFT à l'heure actuelle est déjà meilleur que GPT-3 pour suivre les instructions/conversations, mais ne correspond pas nécessairement aux préférences humaines.
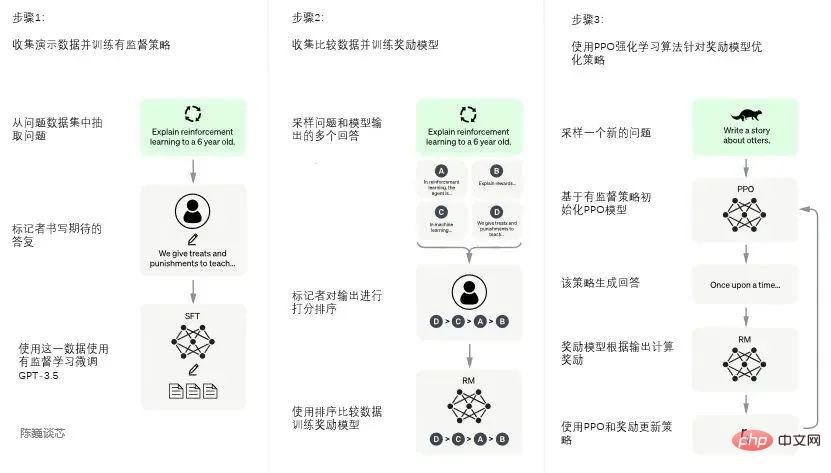
Processus de formation du modèle ChatGPT
Deuxième étape : Modèle de récompense de formation (Mode Récompense, RM)
Cette étape entraîne principalement le modèle de récompense via l'annotation manuelle des données de formation (environ 33 000 données).
Sélectionnez au hasard des questions dans l'ensemble de données et utilisez le modèle généré lors de la première étape pour générer plusieurs réponses différentes pour chaque question. Les annotateurs humains prennent en compte ces résultats et donnent un ordre de classement. Ce processus est similaire au coaching ou au mentorat.
Ensuite, utilisez ces données de résultats de classement pour entraîner le modèle de récompense. Plusieurs résultats de tri sont combinés par paires pour former plusieurs paires de données d'entraînement.
Le modèle RM accepte une entrée et donne un score pour évaluer la qualité de la réponse. De cette manière, pour une paire de données d'entraînement, les paramètres sont ajustés de manière à ce que les réponses de haute qualité obtiennent un score plus élevé que les réponses de mauvaise qualité.
La troisième étape : utiliser l'apprentissage par renforcement PPO (Proximal Policy Optimization, proximal Policy Optimization) pour optimiser la stratégie.
L'idée principale du PPO est de transformer le processus de formation sur politique en gradient politique en hors politique, c'est-à-dire de transformer l'apprentissage en ligne en apprentissage hors ligne. Ce processus de transformation est appelé échantillonnage d'importance.
Cette étape utilise le modèle de récompense formé lors de la deuxième étape et s'appuie sur les scores de récompense pour mettre à jour les paramètres du modèle pré-entraîné. Sélectionnez au hasard des questions dans l'ensemble de données, utilisez le modèle PPO pour générer des réponses et utilisez le modèle RM formé à l'étape précédente pour attribuer des scores de qualité.
Transmettez les scores de récompense dans l'ordre, générant ainsi un gradient politique, et mettez à jour les paramètres du modèle PPO grâce à l'apprentissage par renforcement.
Si nous continuons à répéter les deuxième et troisième étapes, par itération, un modèle ChatGPT de meilleure qualité sera formé.
4. Limites de ChatGPT
Tant que l'utilisateur saisit une question, ChatGPT peut y répondre. Cela signifie-t-il que nous n'avons plus besoin de fournir des mots-clés à Google ou Baidu et que nous pouvons obtenir immédiatement la réponse que nous voulons ?
Bien que ChatGPT ait démontré d'excellentes capacités de dialogue contextuel et même des capacités de programmation, achevant la transformation de l'impression du public sur les robots de dialogue homme-machine (ChatBot) de « artificiellement retardé » à « intéressant », nous devons également voir que la technologie ChatGPT est toujours a quelques limites Les limites s'améliorent encore.
1) ChatGPT manque de « bon sens humain » et de capacités d'extension dans les domaines où il n'a pas été formé avec une grande quantité de corpus, et peut même dire de sérieuses « absurdités ». ChatGPT peut « créer des réponses » dans de nombreux domaines, mais lorsque les utilisateurs recherchent des réponses correctes, ChatGPT peut également donner des réponses trompeuses. Par exemple, laissez ChatGPT répondre à une question d'inscription à l'école primaire. Bien qu'il puisse écrire une longue série de processus de calcul, la réponse finale est fausse.
Alors faut-il croire ou non aux résultats de ChatGPT ?
2) ChatGPT ne peut pas gérer des structures linguistiques complexes, longues ou particulièrement professionnelles. Pour les questions provenant de domaines très spécialisés tels que la finance, les sciences naturelles ou la médecine, ChatGPT peut ne pas être en mesure de générer des réponses appropriées s'il n'y a pas suffisamment « d'alimentation » du corpus.
3) ChatGPT nécessite une très grande quantité de puissance de calcul (puces) pour prendre en charge sa formation et son déploiement. Indépendamment de la nécessité d'une grande quantité de données de corpus pour entraîner le modèle, à l'heure actuelle, l'application de ChatGPT nécessite toujours la prise en charge de serveurs dotés d'une grande puissance de calcul, et le coût de ces serveurs est hors de portée des utilisateurs ordinaires. Un modèle avec des milliards de paramètres nécessite une quantité impressionnante de ressources informatiques pour être exécuté et entraîné. , face à des centaines de millions de demandes d'utilisateurs provenant de moteurs de recherche réels, si la stratégie gratuite actuellement populaire est adoptée, il sera difficile pour toute entreprise de supporter ce coût. Par conséquent, pour le grand public, ils doivent encore attendre des modèles plus légers ou des plates-formes de puissance de calcul plus rentables.
4) ChatGPT n'a pas encore été en mesure d'intégrer de nouvelles connaissances en ligne, et il est irréaliste de ré-entraîner le modèle GPT lorsque de nouvelles connaissances apparaissent. Qu'il s'agisse du temps ou du coût de la formation, il est difficile pour les formateurs ordinaires de l'accepter. . Si nous adoptons un modèle de formation en ligne pour les nouvelles connaissances, cela semble réalisable et le coût du corpus est relativement faible, mais cela peut facilement conduire au problème de l'oubli catastrophique des connaissances originales en raison de l'introduction de nouvelles données.
5) ChatGPT est toujours un modèle de boîte noire. À l'heure actuelle, la logique de l'algorithme interne de ChatGPT ne peut pas être décomposée, il n'y a donc aucune garantie que ChatGPT ne générera pas de déclarations qui attaqueront ou même nuiront aux utilisateurs.
Bien sûr, les failles ne sont pas cachées. Certains ingénieurs ont posté une conversation demandant à ChatGPT d'écrire du code verilog (code de conception de puce). On constate que le niveau de ChatGPT a dépassé celui de certains débutants Verilog.
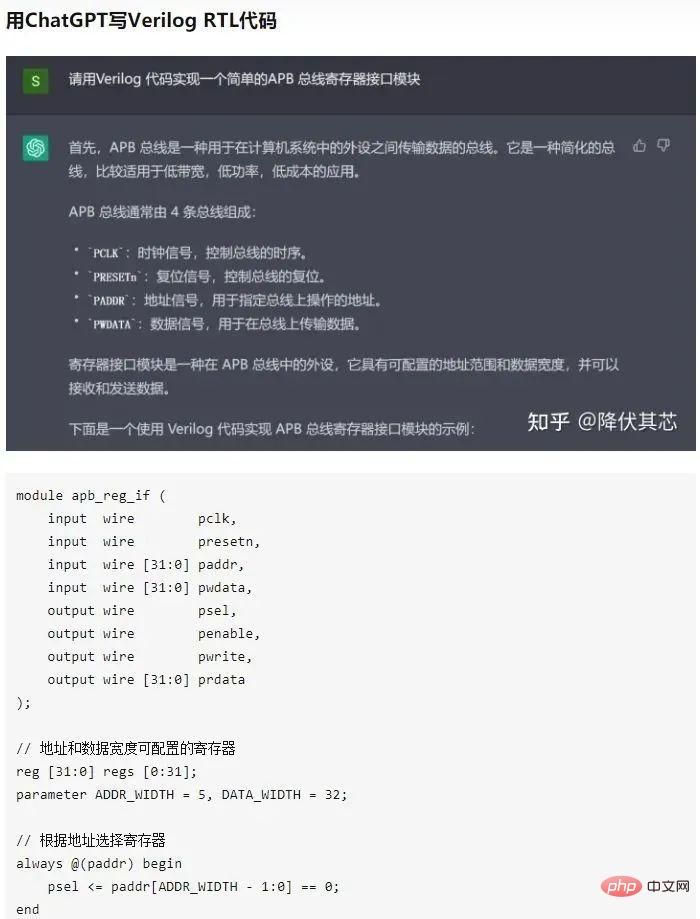
5. Orientations futures d'amélioration de ChatGPT
▌5.1 RLAIF pour réduire le feedback humain
Fin 2020, Dario Amodei, l'ancien vice-président de la recherche chez OpenAI, a fondé une société d'intelligence artificielle Anthropic avec 10 employés .
Les membres de l'équipe fondatrice d'Anthropic sont pour la plupart des premiers employés d'OpenAI et ont participé au GPT-3 d'OpenAI, aux neurones multimodaux, à l'apprentissage par renforcement des préférences humaines, etc.
En décembre 2022, Anthropic a de nouveau publié l'article « Constitutional AI : Harmlessness from AI Feedback » présentant le modèle d'intelligence artificielle Claude. (arxiv.org/pdf/2212.0807)
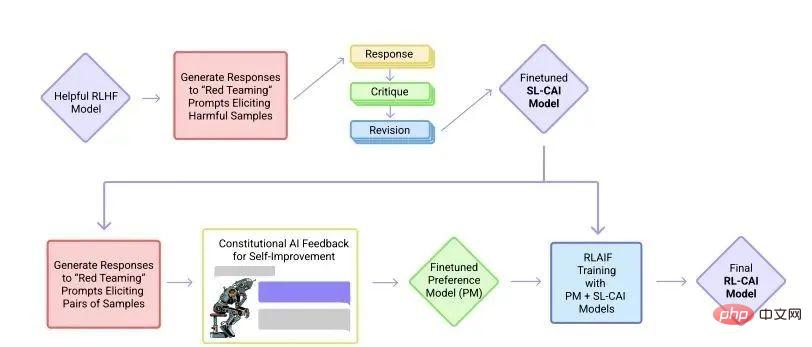
Processus de formation du modèle CAI
Claude et ChatGPT s'appuient tous deux sur l'apprentissage par renforcement (RL) pour former des modèles de préférences. CAI (Constitutional AI) est également construit sur RLHF. La différence est que le processus de classement de CAI utilise des modèles (plutôt que des humains) pour fournir un résultat de classement initial pour tous les résultats générés.
CAI utilise les commentaires de l'intelligence artificielle pour remplacer les préférences humaines par des expressions inoffensives, c'est-à-dire que l'intelligence artificielle RLAIF évalue le contenu des réponses sur la base d'un ensemble de principes constitutionnels.
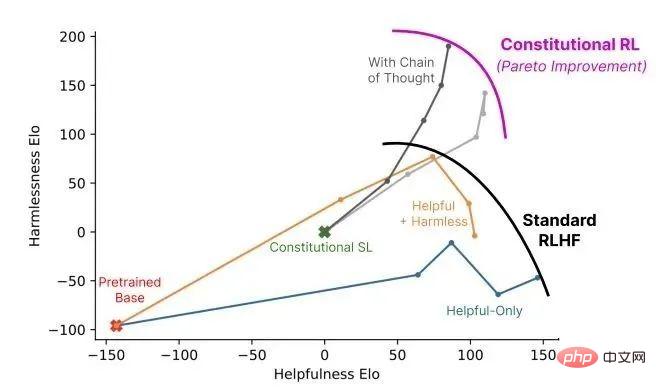
▌5.2 Combler les lacunes en mathématiques
ChatGPT Bien qu'il ait de solides compétences conversationnelles, il est facile de dire des bêtises sérieuses en mathématiques conversations de calcul.
L'informaticien Stephen Wolfram a proposé une solution à ce problème. Stephen Wolfram a créé le moteur de recherche de connaissances en langage et informatique Wolfram Wolfram|Alpha, dont le backend est implémenté via Mathematica.
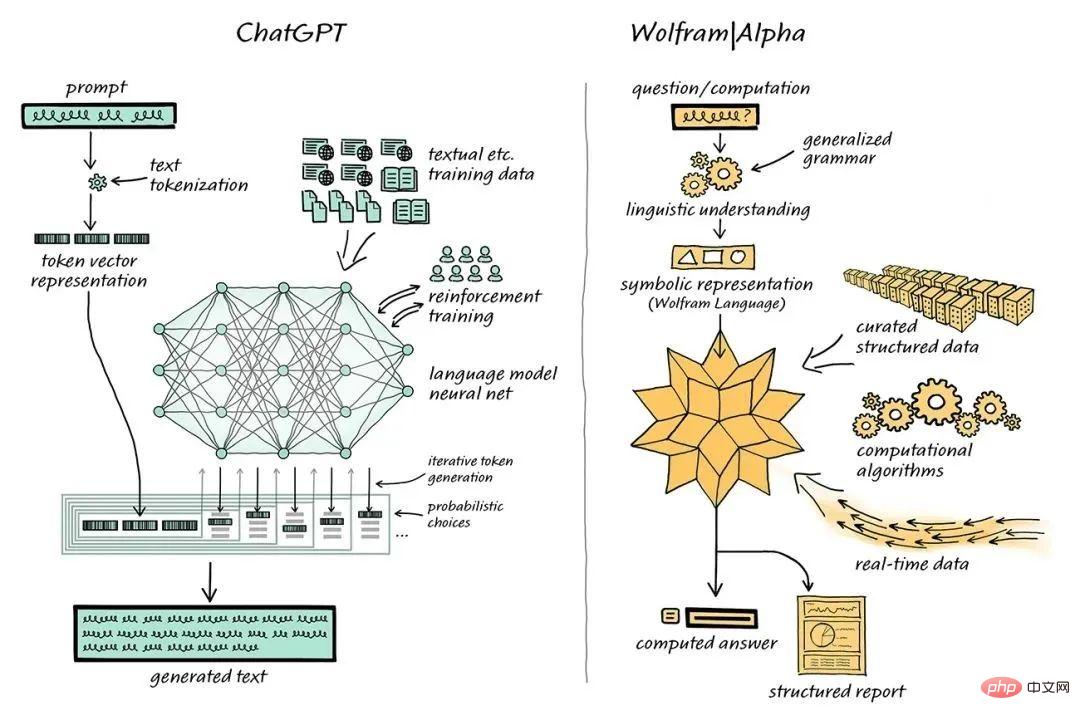
ChatGPT est combiné avec Wolfram | Like |Alpha, "parlant" à Wolfram|Alpha, Wolfram|Alpha utilisera ses capacités de traduction symbolique pour "traduire" " les expressions en langage naturel obtenues à partir de ChatGPT dans le langage informatique symbolique correspondant.
Dans le passé, la communauté universitaire était divisée sur le type de « méthodes statistiques » utilisées par ChatGPT et les « méthodes symboliques » de Wolfram|Alpha.
Mais désormais, la complémentarité de ChatGPT et de Wolfram|Alpha a donné au domaine de la PNL la possibilité de passer au niveau supérieur.
ChatGPT Il n'est pas nécessaire de générer un tel code, il suffit de générer un langage naturel normal, puis d'utiliser Wolfram|Alpha pour le traduire en Wolfram Language précis, puis le Mathematica sous-jacent effectue des calculs.
▌5.3 Miniaturisation de ChatGPT
Bien que ChatGPT soit puissant, sa taille de modèle et son coût d'utilisation interdisent également à de nombreuses personnes.
Il existe trois types de compression de modèle (compression de modèle) qui peuvent réduire la taille et le coût du modèle.
La première méthode est la quantification, c'est-à-dire la réduction de la précision de la représentation numérique d'un seul poids. Par exemple, la rétrogradation de Tansformer de FP32 à INT8 a peu d'impact sur sa précision.
La deuxième méthode de compression du modèle est l'élagage, qui supprime les éléments du réseau, y compris les canaux, des poids individuels (élagage non structuré) vers des composants de granularité plus élevée tels que les matrices de poids. Cette approche est efficace dans les modèles de vision et de langage à plus petite échelle.
La troisième méthode de compression du modèle est la sparsification. Par exemple, SparseGPT (arxiv.org/pdf/2301.0077) proposé par l'Institut autrichien des sciences et technologies (ISTA) peut réduire le modèle de la série GPT à 50 % en une seule étape sans aucun recyclage. Pour le modèle GPT-175B, cet élagage peut être réalisé en quelques heures en utilisant un seul GPU.
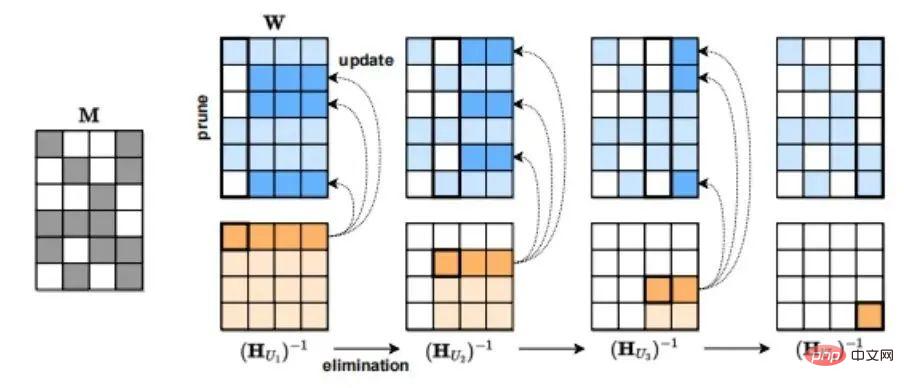 SparseGPT processus de compression
SparseGPT processus de compression
6. L'avenir industriel et les opportunités d'investissement de ChatGPT
▌6.1 AIGC
En parlant de ChaGPT, je dois mentionner l'AIGC.
AIGC utilise la technologie de l'intelligence artificielle pour générer du contenu. Par rapport à l'UGC (contenu généré par l'utilisateur) et au PGC (contenu produit par des professionnels) des époques précédentes du Web1.0 et du Web2.0, l'AIGC, qui représente le contenu conçu par l'intelligence artificielle, constitue une nouvelle série de changements dans les méthodes de production de contenu, et l'AIGC le contenu est dans le Web3. Il y aura également une croissance exponentielle dans l’ère 0.
ChatGPT L'émergence du modèle est d'une grande importance pour l'application de l'AIGC en mode texte/voix et aura un impact significatif sur l'amont et l'aval de l'industrie de l'IA.
▌6.2 Scénarios d'avantages
Du point de vue des applications d'avantages liées en aval, y compris, mais sans s'y limiter, la programmation sans code, la génération de romans, les moteurs de recherche conversationnels, les compagnons vocaux et assistants de travail vocaux, humains virtuels conversationnels, service client d'intelligence artificielle, traduction automatique, conception de puces, etc.
À en juger par la demande croissante en amont, notamment les puces de puissance de calcul, l'annotation de données, le traitement du langage naturel (NLP), etc.
 Les grands modèles explosent (plus de paramètres/exigences en matière de puce de puissance de calcul plus importantes)
Les grands modèles explosent (plus de paramètres/exigences en matière de puce de puissance de calcul plus importantes)
Avec l'algorithme Avec l'avancement continu de Grâce à la technologie et à la puissance de calcul, ChatGPT évoluera vers une version plus avancée avec des fonctions plus puissantes, sera appliqué dans de plus en plus de domaines et générera des conversations et du contenu plus nombreux et de meilleure qualité pour les êtres humains.
Enfin, l'auteur a posé des questions sur l'état de la technologie de stockage et de calcul intégrée dans le domaine de ChatGPT (l'auteur se concentre actuellement sur la promotion de la mise en œuvre de puces de stockage et de calcul intégrées par ChatGPT). prédit avec audace que la technologie intégrée de stockage et de calcul dominera la puce ChatGPT. (A gagné mon cœur)
Référence :
See More- ChatGPT : Optimisation des modèles linguistiques pour le dialogue ChatGPT : Optimisation des modèles linguistiques pour le dialogue
- GPT论文:Les modèles linguistiques sont peu nombreux pour les apprenants Les modèles linguistiques sont peu nombreux pour les apprenants
- InstructGPT论文:Formation des modèles linguistiques pour qu'ils suivent les instructions avec des commentaires humains Formation modèles de langage pour suivre les instructions avec des commentaires humains
- huggingface解读RHLF算法:Illustrer l'apprentissage par renforcement à partir de la rétroaction humaine (RLHF) /~ai-lab/p
- TAMER框架论文:Formation interactive d'agents via le renforcement humain cs.utexas.edu/~bradknox
- PPO算法:Algorithmes d'optimisation de politique proximale Algorithmes d'optimisation de politique proximale
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 ChatGPT permet désormais aux utilisateurs gratuits de générer des images en utilisant DALL-E 3 avec une limite quotidienne
Aug 09, 2024 pm 09:37 PM
ChatGPT permet désormais aux utilisateurs gratuits de générer des images en utilisant DALL-E 3 avec une limite quotidienne
Aug 09, 2024 pm 09:37 PM
Le DALL-E 3 a été officiellement introduit en septembre 2023 en tant que modèle considérablement amélioré par rapport à son prédécesseur. Il est considéré comme l’un des meilleurs générateurs d’images IA à ce jour, capable de créer des images avec des détails complexes. Cependant, au lancement, c'était exclu
 CLIP-BEVFormer : superviser explicitement la structure BEVFormer pour améliorer les performances de détection à longue traîne
Mar 26, 2024 pm 12:41 PM
CLIP-BEVFormer : superviser explicitement la structure BEVFormer pour améliorer les performances de détection à longue traîne
Mar 26, 2024 pm 12:41 PM
Écrit ci-dessus et compréhension personnelle de l'auteur : À l'heure actuelle, dans l'ensemble du système de conduite autonome, le module de perception joue un rôle essentiel. Le véhicule autonome roulant sur la route ne peut obtenir des résultats de perception précis que via le module de perception en aval. dans le système de conduite autonome, prend des jugements et des décisions comportementales opportuns et corrects. Actuellement, les voitures dotées de fonctions de conduite autonome sont généralement équipées d'une variété de capteurs d'informations de données, notamment des capteurs de caméra à vision panoramique, des capteurs lidar et des capteurs radar à ondes millimétriques pour collecter des informations selon différentes modalités afin d'accomplir des tâches de perception précises. L'algorithme de perception BEV basé sur la vision pure est privilégié par l'industrie en raison de son faible coût matériel et de sa facilité de déploiement, et ses résultats peuvent être facilement appliqués à diverses tâches en aval.
 Implémentation d'algorithmes d'apprentissage automatique en C++ : défis et solutions courants
Jun 03, 2024 pm 01:25 PM
Implémentation d'algorithmes d'apprentissage automatique en C++ : défis et solutions courants
Jun 03, 2024 pm 01:25 PM
Les défis courants rencontrés par les algorithmes d'apprentissage automatique en C++ incluent la gestion de la mémoire, le multithread, l'optimisation des performances et la maintenabilité. Les solutions incluent l'utilisation de pointeurs intelligents, de bibliothèques de threads modernes, d'instructions SIMD et de bibliothèques tierces, ainsi que le respect des directives de style de codage et l'utilisation d'outils d'automatisation. Des cas pratiques montrent comment utiliser la bibliothèque Eigen pour implémenter des algorithmes de régression linéaire, gérer efficacement la mémoire et utiliser des opérations matricielles hautes performances.
 Analyse de la fonction et du principe de nohup
Mar 25, 2024 pm 03:24 PM
Analyse de la fonction et du principe de nohup
Mar 25, 2024 pm 03:24 PM
Analyse du rôle et du principe de nohup Dans les systèmes d'exploitation Unix et de type Unix, nohup est une commande couramment utilisée pour exécuter des commandes en arrière-plan. Même si l'utilisateur quitte la session en cours ou ferme la fenêtre du terminal, la commande peut. continuent toujours à être exécutés. Dans cet article, nous analyserons en détail la fonction et le principe de la commande nohup. 1. Le rôle de nohup : Exécuter des commandes en arrière-plan : Grâce à la commande nohup, nous pouvons laisser les commandes de longue durée continuer à s'exécuter en arrière-plan sans être affectées par la sortie de l'utilisateur de la session du terminal. Cela doit être exécuté
 Explorez les principes sous-jacents et la sélection d'algorithmes de la fonction de tri C++
Apr 02, 2024 pm 05:36 PM
Explorez les principes sous-jacents et la sélection d'algorithmes de la fonction de tri C++
Apr 02, 2024 pm 05:36 PM
La couche inférieure de la fonction de tri C++ utilise le tri par fusion, sa complexité est O(nlogn) et propose différents choix d'algorithmes de tri, notamment le tri rapide, le tri par tas et le tri stable.
 L'intelligence artificielle peut-elle prédire la criminalité ? Explorez les capacités de CrimeGPT
Mar 22, 2024 pm 10:10 PM
L'intelligence artificielle peut-elle prédire la criminalité ? Explorez les capacités de CrimeGPT
Mar 22, 2024 pm 10:10 PM
La convergence de l’intelligence artificielle (IA) et des forces de l’ordre ouvre de nouvelles possibilités en matière de prévention et de détection de la criminalité. Les capacités prédictives de l’intelligence artificielle sont largement utilisées dans des systèmes tels que CrimeGPT (Crime Prediction Technology) pour prédire les activités criminelles. Cet article explore le potentiel de l’intelligence artificielle dans la prédiction de la criminalité, ses applications actuelles, les défis auxquels elle est confrontée et les éventuelles implications éthiques de cette technologie. Intelligence artificielle et prédiction de la criminalité : les bases CrimeGPT utilise des algorithmes d'apprentissage automatique pour analyser de grands ensembles de données, identifiant des modèles qui peuvent prédire où et quand les crimes sont susceptibles de se produire. Ces ensembles de données comprennent des statistiques historiques sur la criminalité, des informations démographiques, des indicateurs économiques, des tendances météorologiques, etc. En identifiant les tendances qui pourraient échapper aux analystes humains, l'intelligence artificielle peut donner du pouvoir aux forces de l'ordre.
 Algorithme de détection amélioré : pour la détection de cibles dans des images de télédétection optique haute résolution
Jun 06, 2024 pm 12:33 PM
Algorithme de détection amélioré : pour la détection de cibles dans des images de télédétection optique haute résolution
Jun 06, 2024 pm 12:33 PM
01Aperçu des perspectives Actuellement, il est difficile d'atteindre un équilibre approprié entre efficacité de détection et résultats de détection. Nous avons développé un algorithme YOLOv5 amélioré pour la détection de cibles dans des images de télédétection optique haute résolution, en utilisant des pyramides de caractéristiques multicouches, des stratégies de têtes de détection multiples et des modules d'attention hybrides pour améliorer l'effet du réseau de détection de cibles dans les images de télédétection optique. Selon l'ensemble de données SIMD, le mAP du nouvel algorithme est 2,2 % meilleur que YOLOv5 et 8,48 % meilleur que YOLOX, permettant ainsi d'obtenir un meilleur équilibre entre les résultats de détection et la vitesse. 02 Contexte et motivation Avec le développement rapide de la technologie de télédétection, les images de télédétection optique à haute résolution ont été utilisées pour décrire de nombreux objets à la surface de la Terre, notamment des avions, des voitures, des bâtiments, etc. Détection d'objets dans l'interprétation d'images de télédétection
 SearchGPT : Open AI affronte Google avec son propre moteur de recherche IA
Jul 30, 2024 am 09:58 AM
SearchGPT : Open AI affronte Google avec son propre moteur de recherche IA
Jul 30, 2024 am 09:58 AM
L’Open AI fait enfin son incursion dans la recherche. La société de San Francisco a récemment annoncé un nouvel outil d'IA doté de capacités de recherche. Rapporté pour la première fois par The Information en février de cette année, le nouvel outil s'appelle à juste titre SearchGPT et propose un c
