

Comment ajouter des éléments de traversée à Java HashSet

Diagramme de classes HashSet
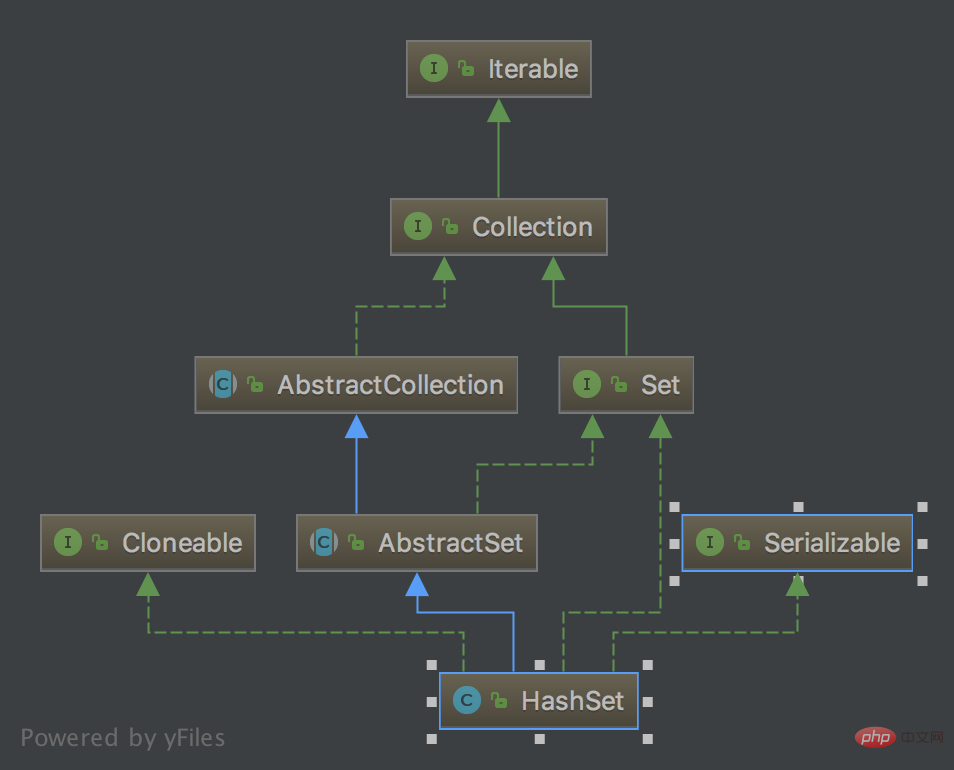
Description simple de HashSet
1.HashSet implémente l'interface SetHashSet 实现了 Set 接口
2.HashSet 底层实际上是由 HashMap 实现的
public HashSet() {
map = new HashMap<>();
}3.可以存放 null,但是只能有一个 null
4.HashSet 不保证元素是有序的(即不保证存放元素的顺序和取出元素的顺序一致),取决于 hash 后,再确定索引的结果
5.不能有重复的元素
HashSet 底层机制说明
HashSet 底层是 HashMap,HashMap 底层是 数组 + 链表 + 红黑树
模拟数组+链表的结构
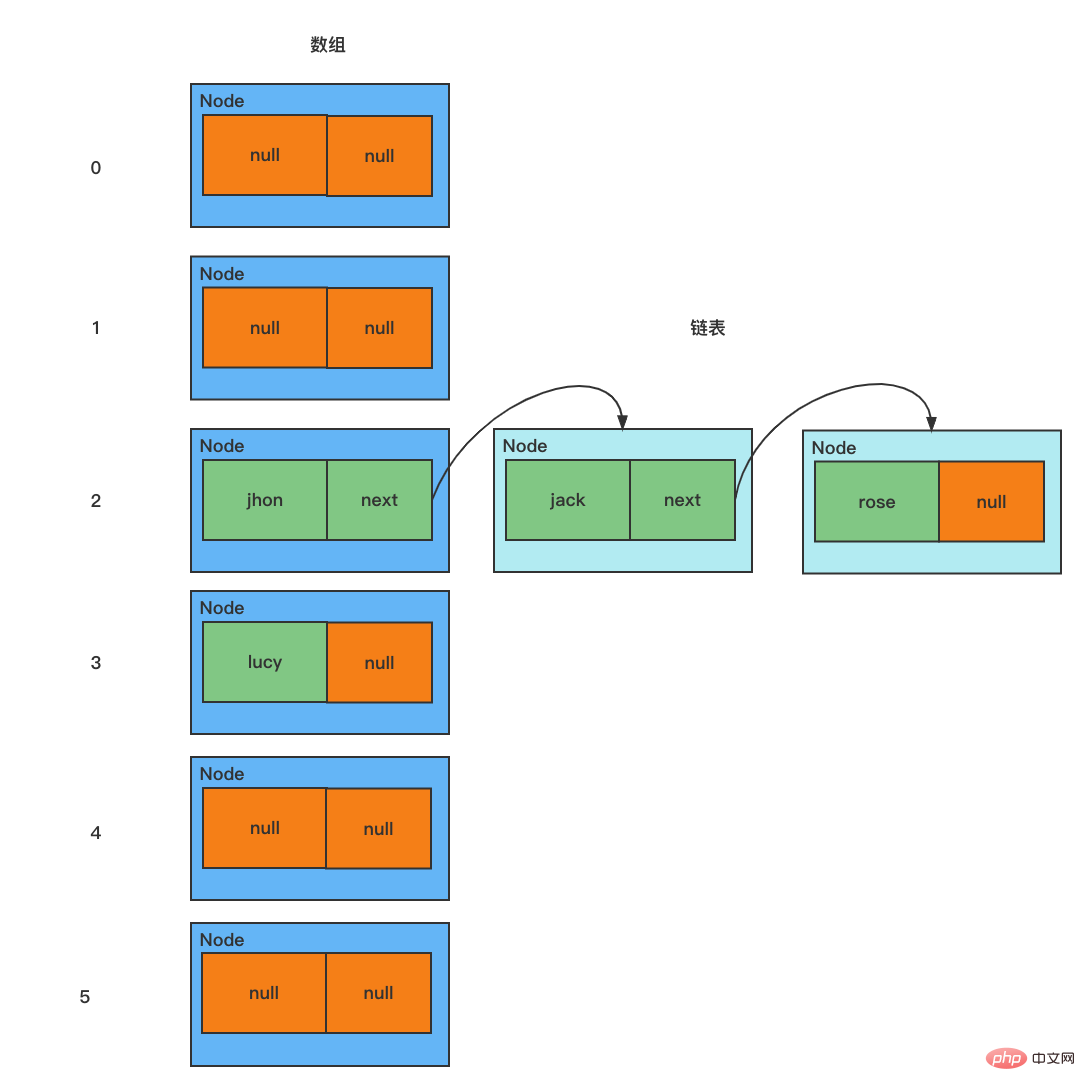
/**
* 模拟 HashSet 数组+链表的结构
*/
public class HashSetStructureMain {
public static void main(String[] args) {
// 模拟一个 HashSet(HashMap) 的底层结构
// 1. 创建一个数组,数组的类型为 Node[]
// 2. 有些地方直接把 Node[] 数组称为 表
Node[] table = new Node[16];
System.out.println(table);
// 3. 创建节点
Node john = new Node("john", null);
table[2] = jhon; // 把节点 john 放在数组索引为 2 的位置
Node jack = new Node("jack", null);
jhon.next = jack; // 将 jack 挂载到 jhon 的后面
Node rose = new Node("rose", null);
jack.next = rose; // 将 rose 挂载到 jack 的后面
Node lucy = new Node("lucy", null);
table[3] = lucy; // 将 lucy 放在数组索引为 3 的位置
System.out.println(table);
}
}
// 节点类 存储数据,可以指向下一个节点,从而形成链表
class Node{
Object item; // 存放数据
Node next; // 指向下一个节点
public Node(Object item, Node next){
this.item = item;
this.next = next;
}
}HashSet 添加元素底层机制
HashSet 添加元素的底层实现
1.HashSet 底层是 HashMap
2.当添加一个元素时,会先得到 待添加元素的 hash 值,然后将其转换成一个 索引值
3.查询存储数据表(Node 数组) table,看当前 待添加元素 所对应的 索引值 的位置是否已经存放了 其它元素
4.如果当前 索引值 所对应的的位置不存在 其它元素,就将当前 待添加元素 放到这个 索引值 所对应的的位置
5.如果当前 索引值 所对应的位置存在 其它元素,就调用 待添加元素.equals(已存在元素) 比较,结果为 true,则放弃添加;结果为 false,则将 待添加元素 放到 已存在元素 的后面(已存在元素.next = 待添加元素)
HashSet 扩容机制
1.HashSet 的底层是 HashMap,第一次添加元素时,table 数组扩容到 cap = 16,threshold(临界值) = cap * loadFactor(加载因子 0.75) = 12
2.如果 table 数组使用到了临界值 12,就会扩容到 cap * 2 = 32,新的临界值就是 32 * 0.75 = 24,以此类推
3.在 Java8 中,如果一条链表上的元素个数 到达 TREEIFY_THRESHOLD(默认是 8),并且 table 的大小 >= MIN_TREEIFY_CAPACITY(默认是 64),就会进行 树化(红黑树)
4.判断是否扩容是根据 ++size > threshold,即是否扩容,是根据 HashMap 所存的元素个数(size)是否超过临界值,而不是根据 table.length() 是否超过临界值
HashSet 添加元素源码
/**
* HashSet 源码分析
*/
public class HashSetSourceMain {
public static void main(String[] args) {
HashSet hashSet = new HashSet();
hashSet.add("java");
hashSet.add("php");
hashSet.add("java");
System.out.println("set = " + hashSet);
// 源码分析
// 1. 执行 HashSet()
/**
* public HashSet() { // HashSet 底层是 HashMap
* map = new HashMap<>();
* }
*/
// 2. 执行 add()
/**
* public boolean add(E e) { // e == "java"
* // HashSet 的 add() 方法其实是调用 HashMap 的 put()方法
* return map.put(e, PRESENT)==null; // (static) PRESENT = new Object(); 用于占位
* }
*/
// 3. 执行 put()
// hash(key) 得到 key(待存元素) 对应的hash值,并不等于 hashcode()
// 算法是 h = key.hashCode()) ^ (h >>> 16
/**
* public V put(K key, V value) {
* return putVal(hash(key), key, value, false, true);
* }
*/
// 4. 执行 putVal()
// 定义的辅助变量:Node<K,V>[] tab; Node<K,V> p; int n, i;
// table 是 HashMap 的一个属性,初始化为 null;transient Node<K,V>[] table;
// resize() 方法,为 table 数组指定容量
// p = tab[i = (n - 1) & hash] 计算 key的hash值所对应的 table 中的索引位置,将索引位置对应的 Node 赋给 p
/**
* final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
* boolean evict) {
* Node<K,V>[] tab; Node<K,V> p; int n, i; // 辅助变量
* // table 就是 HashMap 的一个属性,类型是 Node[]
* // if 语句表示如果当前 table 是 null,或者 table.length == 0
* // 就是 table 第一次扩容,容量为 16
* if ((tab = table) == null || (n = tab.length) == 0)
* n = (tab = resize()).length;
* // 1. 根据 key,得到 hash 去计算key应该存放到 table 的哪个索引位置
* // 2. 并且把这个位置的索引值赋给 i;索引值对应的元素,赋给 p
* // 3. 判断 p 是否为 null
* // 3.1 如果 p 为 null,表示还没有存放过元素,就创建一个Node(key="java",value=PRESENT),并把这个元素放到 i 的索引位置
* // tab[i] = newNode(hash, key, value, null);
* if ((p = tab[i = (n - 1) & hash]) == null)
* tab[i] = newNode(hash, key, value, null);
* else {
* Node<K,V> e; K k; // 辅助变量
* // 如果当前索引位置对应的链表的第一个元素和待添加的元素的 hash值一样
* // 并且满足下面两个条件之一:
* // 1. 待添加的 key 与 p 所指向的 Node 节点的key 是同一个对象
* // 2. 待添加的 key.equals(p 指向的 Node 节点的 key) == true
* // 就认为当前待添加的元素是重复元素,添加失败
* if (p.hash == hash &&
* ((k = p.key) == key || (key != null && key.equals(k))))
* e = p;
* // 判断 当前 p 是不是一颗红黑树
* // 如果是一颗红黑树,就调用 putTreeVal,来进行添加
* else if (p instanceof TreeNode)
* e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
* else {
* // 如果 当前索引位置已经形成一个 链表,就使用 for 循环比较
* // 将待添加元素依次和链表上的每个元素进行比较
* // 1. 比较过程中如果出现待添加元素和链表中的元素有相同的,比较结束,出现重复元素,添加失败
* // 2. 如果比较到链表最后一个元素,链表中都没出现与待添加元素相同的,就把当前待添加元素放到该链表最后的位置
* // 注意:在把待添加元素添加到链表后,立即判断 该链表是否已经到达 8 个节点
* // 如果到达,就调用 treeifyBin() 对当前这个链表进行数化(转成红黑树)
* // 注意:在转成红黑树前,还要进行判断
* // if (tab == null || (n = tab.length) < MIN_TREEIFY_CAPACITY)
* // resize();
* // 如果上面条件成立,先对 table 进行扩容
* // 如果上面条件不成立,才转成红黑树
* for (int binCount = 0; ; ++binCount) {
* if ((e = p.next) == null) {
* p.next = newNode(hash, key, value, null);
* if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
* treeifyBin(tab, hash);
* break;
* }
* if (e.hash == hash &&
* ((k = e.key) == key || (key != null && key.equals(k))))
* break;
* p = e;
* }
* }
* // e 不为 null ,说明添加失败
* if (e != null) { // existing mapping for key
* V oldValue = e.value;
* if (!onlyIfAbsent || oldValue == null)
* e.value = value;
* afterNodeAccess(e);
* return oldValue;
* }
* }
* ++modCount;
* // 扩容:说明判断 table 是否扩容不是看 table 的length
* // 而是看 整个 HashMap 的 size(即已存元素个数)
* if (++size > threshold)
* resize();
* afterNodeInsertion(evict);
* return null;
* }
*/
}
}HashSet 遍历元素底层机制
HashSet 遍历元素底层机制
1.HashSet 的底层是 HashMap,HashSet 的迭代器也是借由 HashMap 来实现的
2.HashSet.iterator() 实际上是去调用 HashMap 的 KeySet().iterator()
public Iterator<E> iterator() {
return map.keySet().iterator();
}3.KeySet() 方法返回一个 KeySet 对象,而 KeySet 是 HashMap 的一个内部类
public Set<K> keySet() {
Set<K> ks = keySet;
if (ks == null) {
ks = new KeySet();
keySet = ks;
}
return ks;
}4.KeySet().iterator() 方法返回一个 KeyIterator 对象,KeyIterator 是 HashMap 的一个内部类
public final Iterator<K> iterator() { return new KeyIterator(); }5.KeyIterator 继承了 HashIterator(HashMap的内部类) 类,并实现了 Iterator 接口,即 KeyIterator、HashIterator 才是真正实现 迭代器 的类
final class KeyIterator extends HashIterator
implements Iterator<K> {
public final K next() { return nextNode().key; }
}6.当执行完 Iterator iterator = HashSet.iterator; 之后,此时的 iterator 对象中已经存储了一个元素节点
怎么做到的?
回到第 4 步,
2.KeySet().iterator()方法返回一个KeyIteratorHashSetLa couche inférieure est en fait Il est implémenté parHashMap🎜🎜3. Il peut stocker/** * Node<K,V> next; // next entry to return * Node<K,V> current; // current entry * int expectedModCount; // for fast-fail * int index; // current slot * HashIterator() { * expectedModCount = modCount; * Node<K,V>[] t = table; * current = next = null; * index = 0; * if (t != null && size > 0) { // advance to first entry * do {} while (index < t.length && (next = t[index++]) == null); * } * } */Copier après la connexionCopier après la connexionnull, mais il ne peut y en avoir qu'un seulnull🎜🎜4.< code>HashSet< /code> ne garantit pas que les éléments sont dans l'ordre (c'est-à-dire qu'il ne garantit pas que l'ordre dans lequel les éléments sont stockés est le même que l'ordre dans lequel les éléments sont supprimés). de l'index est déterminé après lehash🎜🎜5. Il ne peut pas y avoir de doublons. Élément 🎜🎜HashSet description du mécanisme sous-jacent🎜🎜HashSetLa couche inférieure estHashMap. >, et la couche inférieure deHashMapest tableau + liste chaînée + arbre rouge-noir< /strong>🎜Simuler la structure d'un tableau + liste chaînée
🎜< img src="https://img.php.cn/upload/article/000/887/227/168265824976128.png" alt="Comment ajouter des éléments de traversée à Java HashSet" />🎜🎜Le mécanisme sous-jacent de HashSet ajout d'éléments🎜public final boolean hasNext() { return next != null; }Copier après la connexionCopier après la connexionL'implémentation sous-jacente de l'ajout d'éléments HashSet
🎜1.HashSetLa couche inférieure estHashMap</ code>🎜🎜2. obtiendra d'abord la valeur <strong>de hachagede l'élément à ajouter, puis la convertira en une valeur d'index🎜🎜3 Interrogera la table de données de stockage (tableau de nœuds)table pour voir si la position de la valeur d'index correspondant à l'élément actuel à ajouter a été Stocke les autres éléments🎜 🎜4. Si la position correspondant à la valeur d'index actuelle n'existe pas d'autres éléments, l'attente actuelle ajoute l'élément à la position correspondant à la valeur d'index 🎜🎜5. S'il y a d'autres éléments à la position correspondant à la valeur d'index strong> actuelle, appelez Element. à ajouter.equals (élément existant)pour comparer, si le résultat esttrue, alors abandonnez l'ajout ; le résultat estfalse, Puis mettez Élément à ajouter après Élément existant (Existing element.next = Élément à ajouter)🎜Mécanisme d'expansion HashSet
🎜1 . La couche inférieure deHashSetestHashMapLorsqu'un élément est ajouté pour la première fois, le tableautableest étendu àcap. = 16,seuil(valeur critique) = cap * loadFactor (facteur de chargement 0,75) = 12🎜🎜2 Si le tableautableutilise la valeur critique 12. , Il sera étendu àcap * 2 = 32, et la nouvelle valeur critique est32 * 0,75 = 24, et ainsi de suite🎜🎜3 En Java8, si un. liste chaînée Le nombre d'éléments portéeTREEIFY_THRESHOLD(la valeur par défaut est 8) et la taille de latable>=MIN_TREEIFY_CAPACITY</code > (la valeur par défaut est 64), ce sera <strong>Arbre (arbre rouge-noir)</strong>🎜🎜4. Déterminer s'il faut développer est basé sur le <code>++seuil de taille, qui est défini. c'est-à-dire que l'expansion dépend du fait que le nombre d'éléments (size) stockés dansHashMapdépasse la valeur critique n'est pas basé sur le fait quetable.length()dépasse la valeur critique🎜HashSet ajoute le code source de l'élément
🎜HashSet traverse le mécanisme sous-jacent des éléments🎜/** * HashSet 源码分析 */ public class HashSetSourceMain { public static void main(String[] args) { HashSet hashSet = new HashSet(); hashSet.add("java"); hashSet.add("php"); hashSet.add("java"); System.out.println("set = " + hashSet); // HashSet 迭代器实现原理 // HashSet 底层是 HashMap,HashMap 底层是 数组 + 链表 + 红黑树 // HashSet 本身没有实现迭代器,而是借由 HashMap 来实现的 // 1. hashSet.iterator() 实际上是去调用 HashMap 的 keySet().iterator() /** * public Iteratoriterator() { * return map.keySet().iterator(); * } */ // 2. KeySet() 方法返回一个 KeySet 对象,而 KeySet 是 HashMap 的一个内部类 /** * public Set keySet() { * Set ks = keySet; * if (ks == null) { * ks = new KeySet(); * keySet = ks; * } * return ks; * } */ // 3. KeySet().iterator() 方法返回一个 KeyIterator 对象,KeyIterator 是 HashMap的一个内部类 /** * public final Iterator<K> iterator() { return new KeyIterator(); } */ // 4. KeyIterator 继承了 HashIterator(HashMap的内部类) 类,并实现了 Iterator 接口 // 即 KeyIterator、HashIterator 才是真正实现 迭代器的类 /** * final class KeyIterator extends HashIterator * implements Iterator { * public final K next() { return nextNode().key; } * } */ // 5. 当执行完 Iterator iterator = hashSet.iterator(); 后 // 此时的 iterator 对象中已经存储了一个元素节点 // 怎么做到的? // 回到第 3 步,KeySet().iterator() 方法返回一个 KeyIterator 对象 // new KeyIterator() 调用 KeyIterator 的无参构造器 // 在这之前,会先调用 KeyIterator 父类 HashIterator 的无参构造器 // 因此分析 HashIterator 的无参构造器就知道发生了什么 /** * Node Copier après la connexionCopier après la connexionHashSet traverse le mécanisme sous-jacent des éléments
🎜1. Le mécanisme deHashSetestHashMap, l'itérateur deHashSetest également implémenté parHashMap🎜🎜2. HashSet.iterator() appelle en fait leKeySet().iterator()🎜rrreee🎜3 deHashMap.KeySet()La méthode renvoie un objetKeySet, etKeySetest une classe interne deHashMap🎜rrreee🎜4. ) renvoie un objetKeyIterator,KeyIteratorest une classe interne deHashMap🎜rrreee🎜5.KeyIteratorcode> hérite de la classeHashIterator(classe interne deHashMap) et implémente l'interfaceIterator, c'est-à-direKeyIteratoretHashIteratorsont les véritables implémentations de la classe🎜rrreee🎜6 de Iterator. Après avoir exécutéIterator iterator = HashSet.iterator;, un élément a été stocké dans l'objetiteratorà ce moment-là Node 🎜- 🎜Comment faire ? 🎜
- 🎜Retournez à l'étape 4, la méthode
KeySet().iterator()renvoie un objetKeyIterator🎜 new KeyIterator()调用KeyIterator的无参构造器在这之前,会先调用其父类
HashIterator的无参构造器因此,分析
HashIterator的无参构造器就知道发生了什么
/** * Node<K,V> next; // next entry to return * Node<K,V> current; // current entry * int expectedModCount; // for fast-fail * int index; // current slot * HashIterator() { * expectedModCount = modCount; * Node<K,V>[] t = table; * current = next = null; * index = 0; * if (t != null && size > 0) { // advance to first entry * do {} while (index < t.length && (next = t[index++]) == null); * } * } */Copier après la connexionCopier après la connexionnext、current、index都是HashIterator的属性Node<K,V>[] t = table;先把Node数组talbe赋给tcurrent = next = null;current、next都置为nullindex = 0;index置为0do {} while (index < t.length && (next = t[index++]) == null);这个do-while会在table中遍历Node结点一旦
(next = t[index++]) == null不成立 时,就说明找到了一个table中的Node结点将这个节点赋给
next,并退出当前do-while循环此时
Iterator iterator = HashSet.iterator;就执行完了当前
iterator的运行类型其实是HashIterator,而HashIterator的next中存储着从table中遍历出来的一个Node结点
7.执行
iterator.hasNext此时的
next存储着一个Node,所以并不为null,返回truepublic final boolean hasNext() { return next != null; }Copier après la connexionCopier après la connexion8.执行
iterator.next()I.
Node<K,V> e = next;把当前存储着Node结点的next赋值给了eII.
(next = (current = e).next) == null判断当前结点的下一个结点是否为null(a). 如果当前结点的下一个结点为
null,就执行do {} while (index < t.length && (next = t[index++]) == null);,在table数组中遍历,寻找table数组中的下一个Node并赋值给next(b). 如果当前结点的下一个结点不为
null,就将当前结点的下一个结点赋值给next,并且此刻不会去table数组中遍历下一个Node结点
III.将找到的结点
e返回IV.之后每次执行
iterator.next()都像 (a)、(b) 那样去判断遍历,直到遍历完成HashSet 遍历元素源码
/** * HashSet 源码分析 */ public class HashSetSourceMain { public static void main(String[] args) { HashSet hashSet = new HashSet(); hashSet.add("java"); hashSet.add("php"); hashSet.add("java"); System.out.println("set = " + hashSet); // HashSet 迭代器实现原理 // HashSet 底层是 HashMap,HashMap 底层是 数组 + 链表 + 红黑树 // HashSet 本身没有实现迭代器,而是借由 HashMap 来实现的 // 1. hashSet.iterator() 实际上是去调用 HashMap 的 keySet().iterator() /** * public Iteratoriterator() { * return map.keySet().iterator(); * } */ // 2. KeySet() 方法返回一个 KeySet 对象,而 KeySet 是 HashMap 的一个内部类 /** * public Set keySet() { * Set ks = keySet; * if (ks == null) { * ks = new KeySet(); * keySet = ks; * } * return ks; * } */ // 3. KeySet().iterator() 方法返回一个 KeyIterator 对象,KeyIterator 是 HashMap的一个内部类 /** * public final Iterator<K> iterator() { return new KeyIterator(); } */ // 4. KeyIterator 继承了 HashIterator(HashMap的内部类) 类,并实现了 Iterator 接口 // 即 KeyIterator、HashIterator 才是真正实现 迭代器的类 /** * final class KeyIterator extends HashIterator * implements Iterator { * public final K next() { return nextNode().key; } * } */ // 5. 当执行完 Iterator iterator = hashSet.iterator(); 后 // 此时的 iterator 对象中已经存储了一个元素节点 // 怎么做到的? // 回到第 3 步,KeySet().iterator() 方法返回一个 KeyIterator 对象 // new KeyIterator() 调用 KeyIterator 的无参构造器 // 在这之前,会先调用 KeyIterator 父类 HashIterator 的无参构造器 // 因此分析 HashIterator 的无参构造器就知道发生了什么 /** * Node Copier après la connexionCopier après la connexionCe qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Nombre parfait en Java
Aug 30, 2024 pm 04:28 PM
Nombre parfait en Java
Aug 30, 2024 pm 04:28 PM
Guide du nombre parfait en Java. Nous discutons ici de la définition, comment vérifier le nombre parfait en Java ?, des exemples d'implémentation de code.
 Générateur de nombres aléatoires en Java
Aug 30, 2024 pm 04:27 PM
Générateur de nombres aléatoires en Java
Aug 30, 2024 pm 04:27 PM
Guide du générateur de nombres aléatoires en Java. Nous discutons ici des fonctions en Java avec des exemples et de deux générateurs différents avec d'autres exemples.
 Weka en Java
Aug 30, 2024 pm 04:28 PM
Weka en Java
Aug 30, 2024 pm 04:28 PM
Guide de Weka en Java. Nous discutons ici de l'introduction, de la façon d'utiliser Weka Java, du type de plate-forme et des avantages avec des exemples.
 Numéro de Smith en Java
Aug 30, 2024 pm 04:28 PM
Numéro de Smith en Java
Aug 30, 2024 pm 04:28 PM
Guide du nombre de Smith en Java. Nous discutons ici de la définition, comment vérifier le numéro Smith en Java ? exemple avec implémentation de code.
 Questions d'entretien chez Java Spring
Aug 30, 2024 pm 04:29 PM
Questions d'entretien chez Java Spring
Aug 30, 2024 pm 04:29 PM
Dans cet article, nous avons conservé les questions d'entretien Java Spring les plus posées avec leurs réponses détaillées. Pour que vous puissiez réussir l'interview.
 Break or Return of Java 8 Stream Forach?
Feb 07, 2025 pm 12:09 PM
Break or Return of Java 8 Stream Forach?
Feb 07, 2025 pm 12:09 PM
Java 8 présente l'API Stream, fournissant un moyen puissant et expressif de traiter les collections de données. Cependant, une question courante lors de l'utilisation du flux est: comment se casser ou revenir d'une opération FOREAK? Les boucles traditionnelles permettent une interruption ou un retour précoce, mais la méthode Foreach de Stream ne prend pas directement en charge cette méthode. Cet article expliquera les raisons et explorera des méthodes alternatives pour la mise en œuvre de terminaison prématurée dans les systèmes de traitement de flux. Lire plus approfondie: Améliorations de l'API Java Stream Comprendre le flux Forach La méthode foreach est une opération terminale qui effectue une opération sur chaque élément du flux. Son intention de conception est
 Horodatage à ce jour en Java
Aug 30, 2024 pm 04:28 PM
Horodatage à ce jour en Java
Aug 30, 2024 pm 04:28 PM
Guide de TimeStamp to Date en Java. Ici, nous discutons également de l'introduction et de la façon de convertir l'horodatage en date en Java avec des exemples.
 Créer l'avenir : programmation Java pour les débutants absolus
Oct 13, 2024 pm 01:32 PM
Créer l'avenir : programmation Java pour les débutants absolus
Oct 13, 2024 pm 01:32 PM
Java est un langage de programmation populaire qui peut être appris aussi bien par les développeurs débutants que par les développeurs expérimentés. Ce didacticiel commence par les concepts de base et progresse vers des sujets avancés. Après avoir installé le kit de développement Java, vous pouvez vous entraîner à la programmation en créant un simple programme « Hello, World ! ». Une fois que vous avez compris le code, utilisez l'invite de commande pour compiler et exécuter le programme, et « Hello, World ! » s'affichera sur la console. L'apprentissage de Java commence votre parcours de programmation et, à mesure que votre maîtrise s'approfondit, vous pouvez créer des applications plus complexes.
