
 Périphériques technologiques
IA
DAMO-YOLO : un framework de détection de cible efficace qui prend en compte à la fois la vitesse et la précision
Périphériques technologiques
IA
DAMO-YOLO : un framework de détection de cible efficace qui prend en compte à la fois la vitesse et la précision
DAMO-YOLO : un framework de détection de cible efficace qui prend en compte à la fois la vitesse et la précision


1. Introduction à la détection de cible
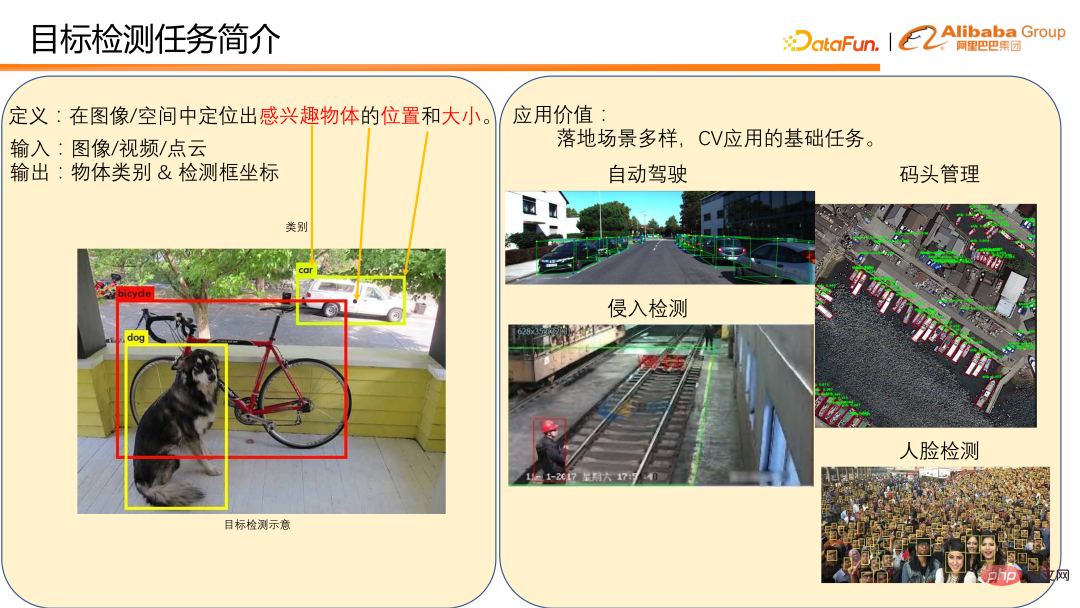
La définition de la détection de cible est de localiser la position et la taille d'un objet d'intérêt dans une image/un espace.
Généralement, saisissez des images, des vidéos ou des nuages de points, et affichez la catégorie d'objet et les coordonnées du cadre de détection. L'image en bas à gauche est un exemple de détection d'objet sur une image. Il existe de nombreux scénarios d'application pour la détection de cibles, tels que la détection de véhicules et de piétons dans des scénarios de conduite autonome et la détection d'accostage dans la gestion des quais. Ces deux éléments sont des applications directes à la détection d’objets. La détection de cibles est également une tâche de base pour de nombreuses applications CV, telles que la détection d'intrusion et la reconnaissance faciale utilisées dans les usines. Celles-ci nécessitent la détection des piétons et la détection des visages comme base pour accomplir la tâche de détection. On peut voir que la détection de cibles a de nombreuses applications importantes dans la vie quotidienne, et sa position dans la mise en œuvre du CV est également très importante, c'est donc un domaine très compétitif.
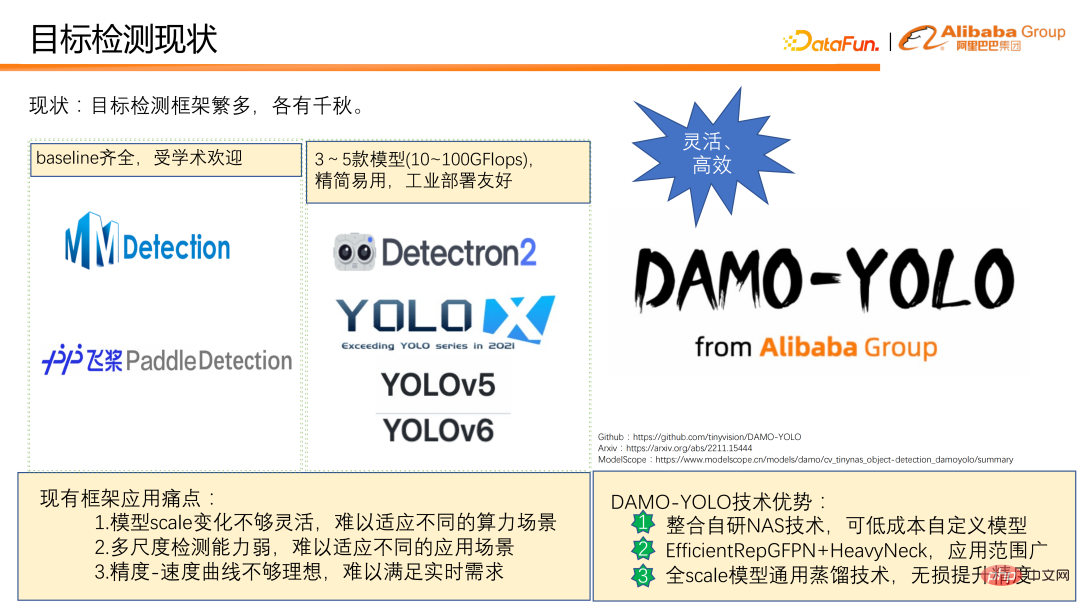
Il existe actuellement de nombreux frameworks de détection de cibles avec leurs propres caractéristiques. Sur la base de notre expérience accumulée dans l'utilisation réelle, nous avons constaté que le cadre de détection actuel présente toujours les problèmes suivants dans l'application pratique :
① Les changements d'échelle du modèle ne sont pas assez flexibles et difficiles à adapter aux différents scénarios de puissance de calcul. . Par exemple, le cadre de détection de la série YOLO ne fournit généralement que la quantité de calcul de 3 à 5 modèles, allant d'une douzaine à plus d'une centaine de Flops, ce qui rend difficile la couverture de différents scénarios de puissance de calcul.
② La capacité de détection multi-échelle est faible, en particulier les performances de détection des petits objets sont médiocres, ce qui rend les scénarios d'application du modèle très limités. Par exemple, dans les scénarios de détection de drones, leurs effets ne sont souvent pas idéaux.
③ La courbe vitesse/précision n'est pas assez idéale, et vitesse et précision sont difficiles à concilier en même temps.
En réponse à la situation ci-dessus, nous avons conçu et open source DAMO-YOLO. DAMO-YOLO se concentre principalement sur la mise en œuvre industrielle. Par rapport à d'autres frameworks de détection de cibles, il présente trois avantages techniques évidents :
① Il intègre la technologie NAS auto-développée et peut personnaliser les modèles à faible coût, permettant aux utilisateurs d'utiliser pleinement la puissance de calcul de la puce.
② La combinaison des paradigmes de conception de modèles RepGFPN et Heavyneck efficaces peut considérablement améliorer les capacités de détection multi-échelles du modèle et élargir la portée de l'application du modèle.
③ Propose une technologie de distillation universelle à grande échelle qui peut améliorer sans douleur la précision des petits, moyens et grands modèles.
Ci-dessous, nous analyserons plus en détail DAMO-YOLO à partir de la valeur de 3 avantages techniques.
2. Valeur technique DAMO-YOLO
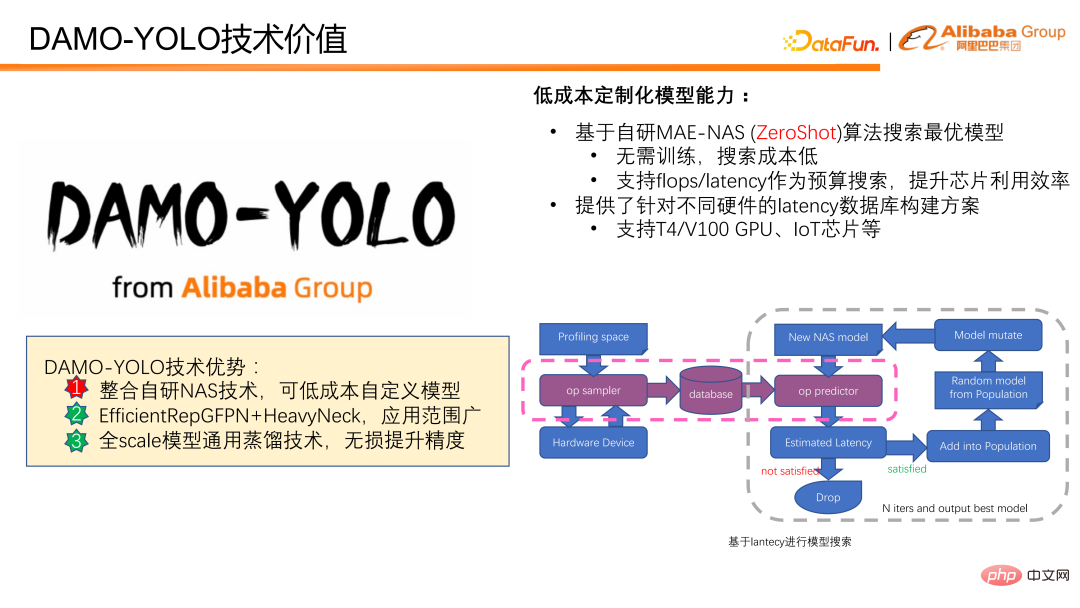
DAMO-YOLO réalise une personnalisation de modèle à faible coût et est basé sur l'algorithme MAE-NAS auto-développé. Les modèles peuvent être personnalisés à faible coût en fonction de la latence ou du budget FLOPS. Il peut fournir des scores d'évaluation de modèle sans avoir besoin de formation sur le modèle ou de participation à des données réelles, et le coût de recherche de modèle est faible. Le ciblage des FLOPS peut exploiter pleinement la puissance de calcul de la puce. La recherche avec retard car le budget est très adaptée à divers scénarios qui ont des exigences strictes en matière de retard. Nous fournissons également des solutions de construction de bases de données qui prennent en charge différents scénarios de retard matériel, facilitant ainsi la recherche pour chacun en utilisant le retard comme objectif.
La figure suivante montre comment utiliser le délai pour la recherche de modèle. Tout d'abord, échantillonnez la puce cible ou le dispositif cible pour obtenir les retards de tous les opérateurs possibles, puis prédisez le retard du modèle en fonction des données de retard. Si l'ampleur prévue du modèle atteint l'objectif prédéfini, le modèle entrera dans les mises à jour ultérieures du modèle et dans les calculs de scores. Enfin, après mise à jour itérative, le modèle optimal répondant aux contraintes de délai est obtenu.
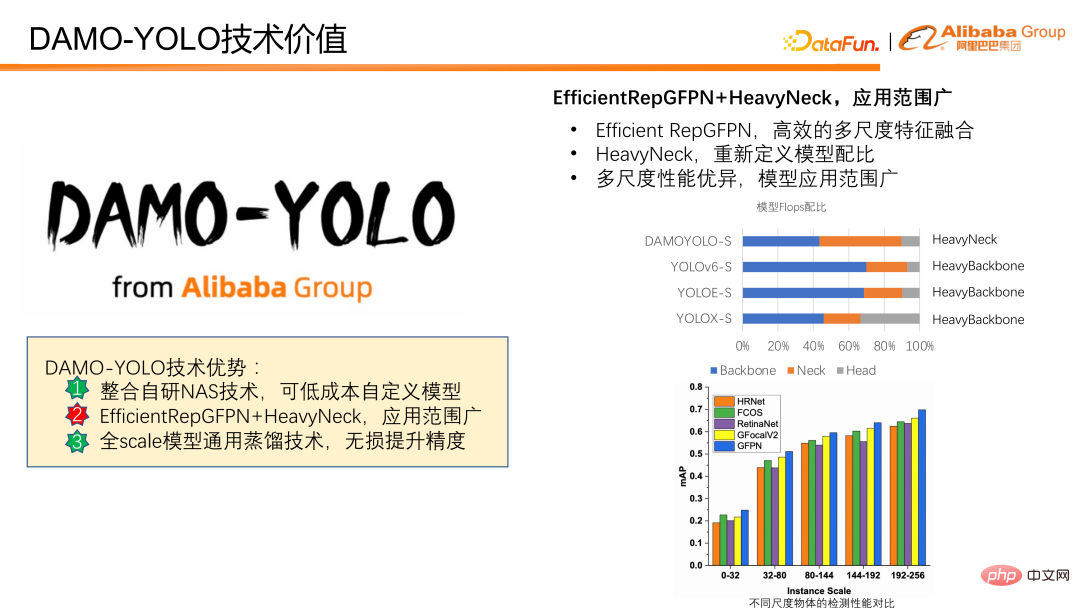
Ensuite, nous présenterons comment améliorer la capacité de détection multi-échelle du modèle. DAMO-YOLO combine le RepGFPN efficace proposé et le HeavyNeck innovant, qui améliore considérablement les capacités de détection multi-échelles. Un RepGFPN efficace peut réaliser efficacement une fusion de fonctionnalités à plusieurs échelles. Le paradigme HeavyNeck fait référence à l'allocation d'un grand nombre de FLOPS du modèle à la couche de fusion de fonctionnalités. Tels que le tableau de ratio modèle FLOPS. En prenant DAMO-YOLO-S comme exemple, la quantité de calcul du cou représente près de la moitié de l'ensemble du modèle, ce qui est très différent des autres modèles qui placent principalement la quantité de calcul sur la colonne vertébrale.
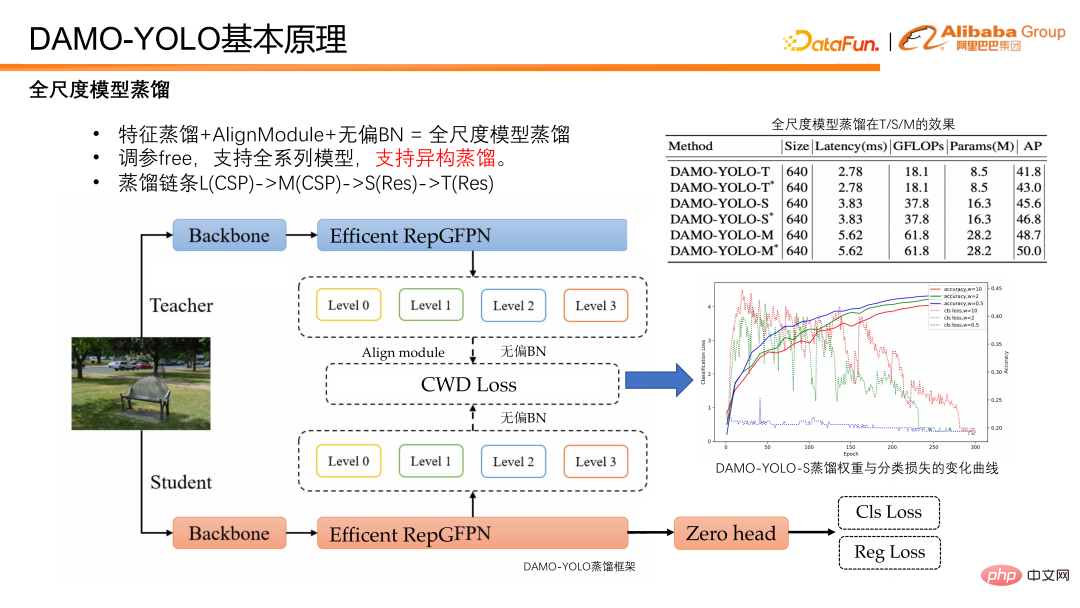
Enfin, le modèle de distillation est introduit. La distillation fait référence au transfert des connaissances d'un grand modèle vers un petit modèle, améliorant ainsi les performances du petit modèle sans encourir le fardeau du raisonnement. La distillation sur modèle est un outil puissant pour améliorer l’efficacité des modèles de détection, mais l’exploration dans le monde universitaire et industriel se limite principalement aux grands modèles, et il existe un manque de solutions de distillation pour les petits modèles. DAMO-YOLO propose un ensemble de distillations communes aux modèles toutes échelles. Cette solution peut non seulement apporter des améliorations significatives aux modèles à grande échelle, mais présente également une grande robustesse. Elle utilise également des poids dynamiques sans avoir besoin d'ajuster les paramètres, et la distillation peut être effectuée avec des scripts en un seul clic. En outre, ce schéma est également robuste à la distillation hétérogène, ce qui revêt une grande importance pour le modèle personnalisé à faible coût mentionné ci-dessus. Dans le modèle NAS, la similarité structurelle entre le petit modèle et le grand modèle obtenu par recherche n'est pas garantie. S'il existe une distillation hétérogène et robuste, les avantages du NAS et de la distillation peuvent être pleinement exploités. La figure ci-dessous montre nos performances en matière de distillation. On peut constater que peu importe le modèle T, le modèle S ou le modèle M, il y a une amélioration stable après distillation.

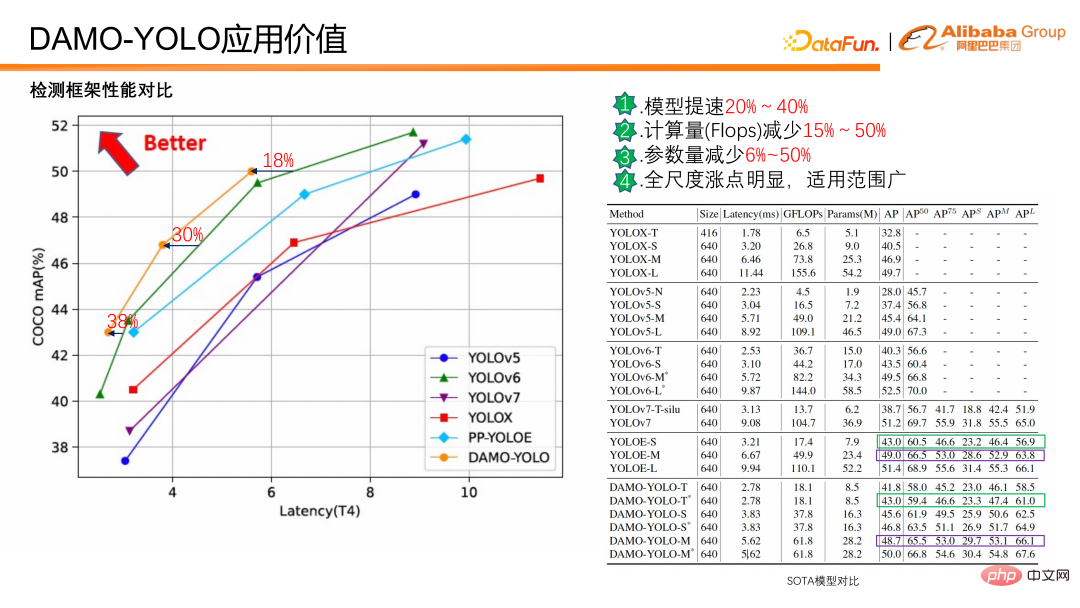
Sur la base de la valeur technique ci-dessus, quelle valeur de l'application peut être convertie ? Ce qui suit présentera la comparaison entre DAMO-YOLO et d'autres cadres de détection SOTA actuels.
DAMO-YOLO Par rapport au SOTA actuel, la vitesse du modèle est 20 à 40 % plus rapide avec la même précision, la quantité de calcul est réduite de 15 à 50 % et les paramètres sont réduits de 6 % -50 % L'augmentation à grande échelle est évidente et elle est applicable à une large gamme. De plus, des améliorations évidentes sont constatées aussi bien sur les petits que sur les grands objets.
Comme le montre la comparaison des données ci-dessus, DAMO-YOLO est rapide, a de faibles flops et dispose d'une large gamme d'applications, il peut également personnaliser des modèles en fonction de la puissance de calcul pour améliorer l'efficacité d'utilisation des puces ;
Des modèles pertinents ont été lancés sur ModelScope. L'inférence et la formation peuvent être effectuées en configurant trois à cinq lignes de code. Vous pouvez expérimenter son utilisation. Si vous avez des questions ou des commentaires pendant l'utilisation, veuillez laisser un message. la zone de commentaires.
Ensuite, nous nous concentrerons sur les 3 avantages techniques de DAMO-YOLO et présenterons les principes qui le sous-tendent pour aider chacun à mieux comprendre et utiliser DAMO-YOLO.
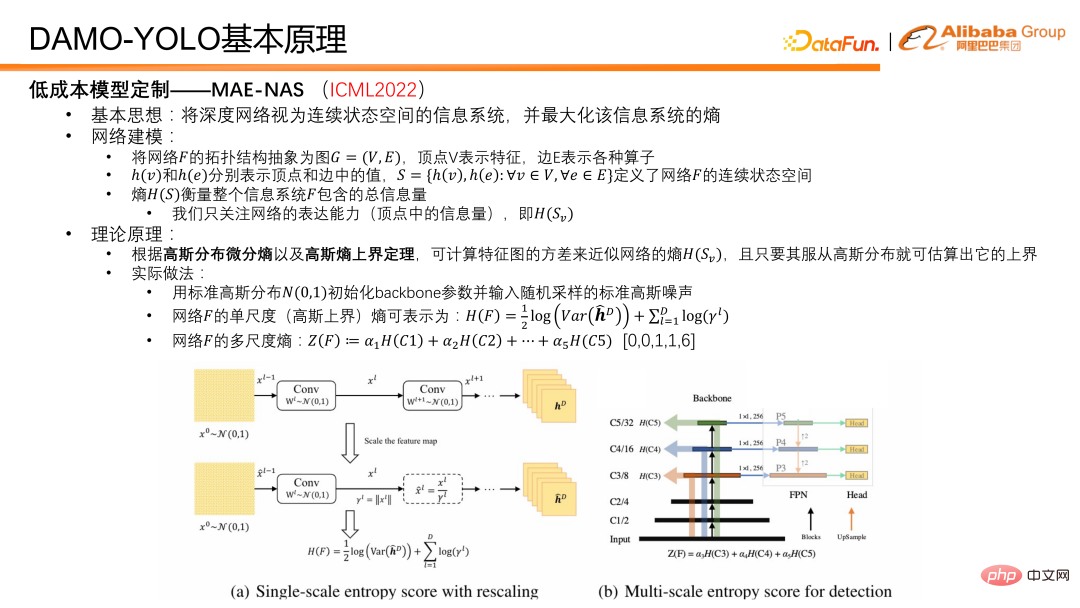
4. Introduction au principe de DAMO-YOLOTout d'abord, nous introduisons la technologie clé de la capacité de personnalisation de modèles à faible coût MAE-NAS. Son idée de base est de considérer un réseau profond comme un système d'information avec un espace d'état continu et de trouver l'entropie qui peut maximiser le système d'information.
L'idée de la modélisation de réseau est la suivante : résumer la structure topologique du réseau F dans un graphe G=(V,E), où le sommet V représente l'entité et l'arête E représente divers opérateurs. Sur cette base, h(v) et h(e) peuvent être utilisés pour représenter les valeurs respectivement dans les sommets et les arêtes, et un tel ensemble S peut être généré, qui définit l'espace d'état continu du réseau et l'entropie de l'ensemble S peut représenter la quantité totale d'informations dans le réseau ou le système d'information F. La quantité d'informations sur les sommets mesure la capacité d'expression du réseau, et la quantité d'informations sur les arêtes est également l'entropie des arêtes, qui mesure la complexité du réseau. Pour la tâche de détection d'objets DAMO-YOLO, notre principale préoccupation est de maximiser la capacité d'expression du réseau. Dans les applications pratiques, seule l’entropie des fonctionnalités du réseau est concernée. Selon l'entropie différentielle de distribution gaussienne et le théorème de la limite supérieure de l'entropie gaussienne, nous utilisons la variance de la carte des caractéristiques pour approximer la limite supérieure de l'entropie des caractéristiques du réseau.
En fonctionnement réel, nous initialisons d'abord les poids du réseau fédérateur avec une distribution gaussienne standard, et utilisons une image de bruit gaussienne standard comme entrée. Une fois le bruit gaussien introduit dans le réseau pour le passage direct, plusieurs caractéristiques peuvent être obtenues. Ensuite, l'entropie à échelle unique, c'est-à-dire la variance de chaque caractéristique d'échelle, est calculée, puis l'entropie à plusieurs échelles est obtenue par pondération. Dans le processus de pondération, des coefficients a priori sont utilisés pour équilibrer les capacités d'expression des caractéristiques à différentes échelles. Ce paramètre est généralement défini sur [0,0,1,1,6]. La raison pour laquelle cela est défini est la suivante : Dans le modèle de détection, les caractéristiques générales sont divisées en cinq étapes, soit cinq résolutions différentes, de 1/2 à 1/32. Afin de maintenir une utilisation efficace des fonctionnalités, nous utilisons uniquement les trois dernières étapes. Donc en fait, les deux premières étapes ne participent pas à la prédiction du modèle, elles sont donc 0 et 0. Pour les trois autres, nous avons mené des expériences approfondies et constaté que 1, 1 et 6 constituent un meilleur rapport modèle.
Sur la base des principes de base ci-dessus, nous pouvons utiliser l'entropie multi-échelle du réseau comme proxy de performance et utiliser l'algorithme de purification comme cadre de base pour rechercher la structure du réseau, qui constitue un MAE-NAS complet. Le NAS présente de nombreux avantages. Tout d'abord, il prend en charge plusieurs restrictions de budget d'inférence et peut utiliser les FLOPS, la quantité de paramètres, la latence et le numéro de couche réseau pour effectuer une recherche de modèle. Deuxièmement, il prend également en charge un très grand nombre de variations dans les structures de réseau à granularité fine. Étant donné que des algorithmes évolutifs sont utilisés ici pour effectuer des recherches de réseau, plus les variantes de structures de réseau sont prises en charge, plus le degré de personnalisation et de flexibilité lors de la recherche est élevé. De plus, afin de permettre aux utilisateurs de personnaliser le processus de recherche, nous proposons des didacticiels officiels. Enfin, et surtout, MAE-NAS est zéro-short, c'est-à-dire que sa recherche ne nécessite aucune participation réelle aux données et ne nécessite aucune formation réelle du modèle. Il recherche pendant des dizaines de minutes sur le CPU et peut produire un résultat réseau optimal sous les contraintes actuelles.
Dans DAMO-YOLO, nous utilisons MAE-NAS pour rechercher le réseau fédérateur du modèle T/S/M avec différents délais comme cibles de recherche ; nous emballons l'infrastructure du réseau fédérateur recherché et utilisons ResStyle pour les petits modèles, les grands modèles utilisent CSPStyle.
Comme le montre le tableau ci-dessous, CSP-Darknet est un réseau conçu manuellement utilisant la structure CSP, et a également réalisé des applications généralisées dans YOLO v 5/V6. Nous avons utilisé MAE-NAS pour générer une structure de base, et après l'avoir empaquetée avec CSP, nous avons constaté que le modèle était considérablement amélioré en termes de vitesse et de précision. De plus, vous pouvez voir le formulaire MAE-ResNet sur des petits modèles, qui auront une plus grande précision. Il y a un net avantage à utiliser la structure CPS sur les grands modèles, qui peuvent atteindre 48,7.

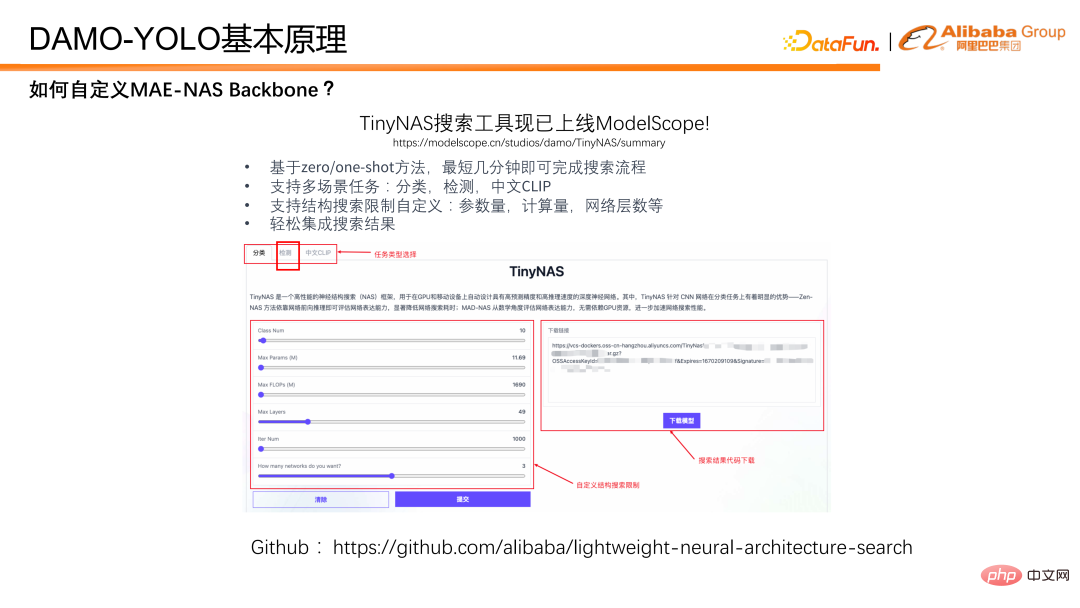
Comment utiliser MAE-NAS pour effectuer une recherche dans le backbone ? Nous présentons ici notre boîte à outils TinyNAS, qui est déjà en ligne dans ModelScope. Vous pouvez facilement obtenir le modèle souhaité grâce à une configuration visuelle sur la page Web. Dans le même temps, MAE-NAS est également disponible en open source sur github. Les étudiants intéressés peuvent rechercher le modèle souhaité avec une plus grande liberté sur la base du code open source.
Ensuite, nous présenterons comment DAMO-YOLO améliore les capacités de détection multi-échelles. Il repose sur la fusion de différentes fonctionnalités du réseau. Dans les réseaux de détection précédents, la profondeur des caractéristiques à différentes échelles varie considérablement. Par exemple, les fonctionnalités à grande résolution sont utilisées pour détecter de petits objets, mais leur profondeur est faible, ce qui affectera les performances de détection des petits objets.
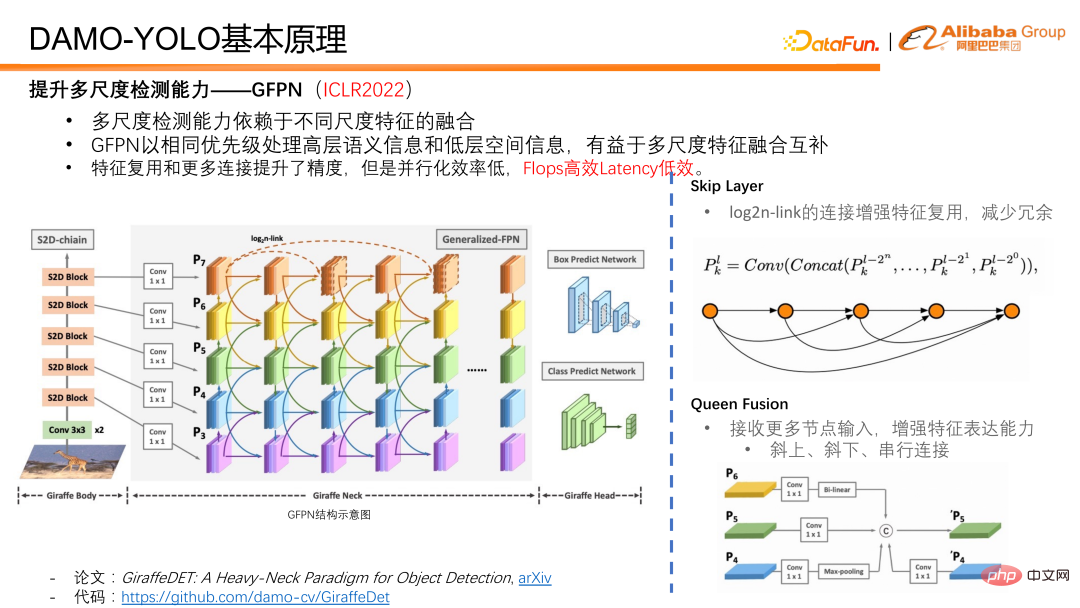
Un travail que nous avons proposé à l'ICLR2022 - GFPN, traite simultanément des informations sémantiques de haut niveau et des informations spatiales de bas niveau avec la même priorité, et est très convivial pour la fusion et la complémentation de fonctionnalités multi-échelles. Dans la conception de GFPN, nous avons d'abord introduit une couche de saut afin de permettre à GFPN d'être conçu plus en profondeur. Nous utilisons un lien log2n pour réutiliser les fonctionnalités et réduire la redondance.
Queen fusion consiste à augmenter la fusion interactive de caractéristiques de différentes échelles et de caractéristiques de différentes profondeurs. En plus de recevoir des caractéristiques d'échelle différentes en diagonale au-dessus et en dessous de lui, chaque nœud de Queen Fusion reçoit également des caractéristiques d'échelle différentes à la même profondeur de caractéristiques, ce qui augmente considérablement la quantité d'informations lors de la fusion de caractéristiques et favorise les informations multi-échelles à la même profondeur. fusion activée.
Bien que la réutilisation des fonctionnalités de GFPN et la conception de connexion unique aient apporté des améliorations dans la précision du modèle. Étant donné que notre couche de saut et notre fusion Queen apportent des opérations de fusion sur des nœuds de fonctionnalités multi-échelles, ainsi que des opérations de suréchantillonnage et de sous-échantillonnage, elles augmentent considérablement le temps d'inférence et rendent difficile la satisfaction des exigences de mise en œuvre de l'industrie. Donc en fait, GFPN est une structure FLOPS efficace, mais inefficace en termes de retard. Compte tenu de certaines lacunes du GFPN, nous avons analysé et attribué les raisons comme suit :
① Tout d'abord, les fonctionnalités de différentes échelles partagent en fait le nombre de canaux, ce qui présente beaucoup de redondance des fonctionnalités et de la configuration du réseau. n'est pas assez souple.
② Deuxièmement, il existe des connexions de suréchantillonnage et de sous-échantillonnage dans la fonction Queen, et les opérateurs de suréchantillonnage et de sous-échantillonnage prennent beaucoup plus de temps.
③ Troisièmement, lorsque les nœuds sont empilés, les connexions série avec la même profondeur de fonctionnalités réduisent l'efficacité parallèle du GPU, et la croissance du chemin série provoquée par chaque pile est très significative.
Pour résoudre ces problèmes, nous avons effectué les optimisations correspondantes et proposé Efficient RepGFPN.
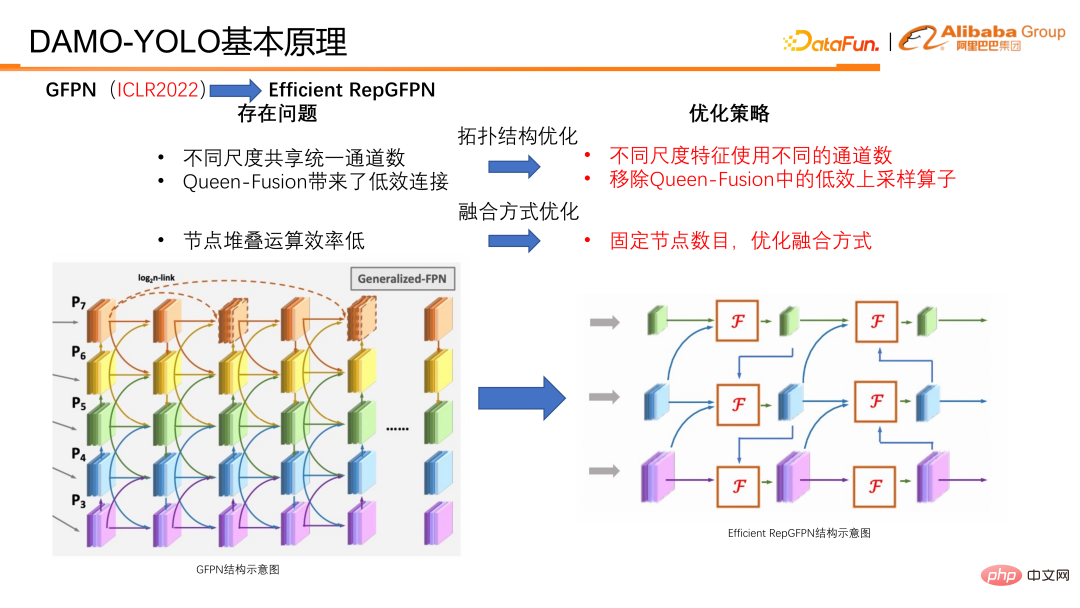
En optimisation, elle est principalement divisée en deux catégories, l'une est l'optimisation de la structure topologique et l'autre est l'optimisation de la méthode de fusion.
En termes d'optimisation de la structure topologique, Efficient RepGFPN utilise différents numéros de canal pour différentes fonctionnalités d'échelle, afin de pouvoir contrôler de manière flexible les capacités d'expression des fonctionnalités de haut niveau et des fonctionnalités de bas niveau sous les contraintes de calculs légers. Dans le cas des FLOPS et de l'approximation des délais, une configuration flexible permet d'obtenir la meilleure précision et la meilleure efficacité en termes de vitesse. En outre, nous avons également effectué une analyse d'efficacité sur une connexion dans la fusion reine et avons constaté que l'opérateur de suréchantillonnage a une charge énorme, mais que l'amélioration de la précision est faible, ce qui est bien inférieur à l'avantage de l'opérateur de sous-échantillonnage. Nous avons donc supprimé la connexion de suréchantillonnage dans la fusion reine. Comme on peut le voir dans le tableau, les graduations en diagonale vers le bas sont en fait un suréchantillonnage, et les graduations en diagonale vers le haut sont un sous-échantillonnage. Vous pouvez le comparer avec l'image de gauche. Les petites résolutions deviennent progressivement des résolutions plus grandes vers le bas, et les connexions en bas à droite. représenter Le but est de suréchantillonner les fonctionnalités à petite résolution, de les connecter aux fonctionnalités à grande résolution, et de les fusionner en fonctionnalités à grande résolution. La conclusion finale est que l'opérateur de sous-échantillonnage a des rendements plus élevés, tandis que l'opérateur de suréchantillonnage a des rendements très faibles. Nous avons donc supprimé la connexion de suréchantillonnage dans la fonctionnalité Queen pour améliorer l'efficacité de l'ensemble du GFPN.
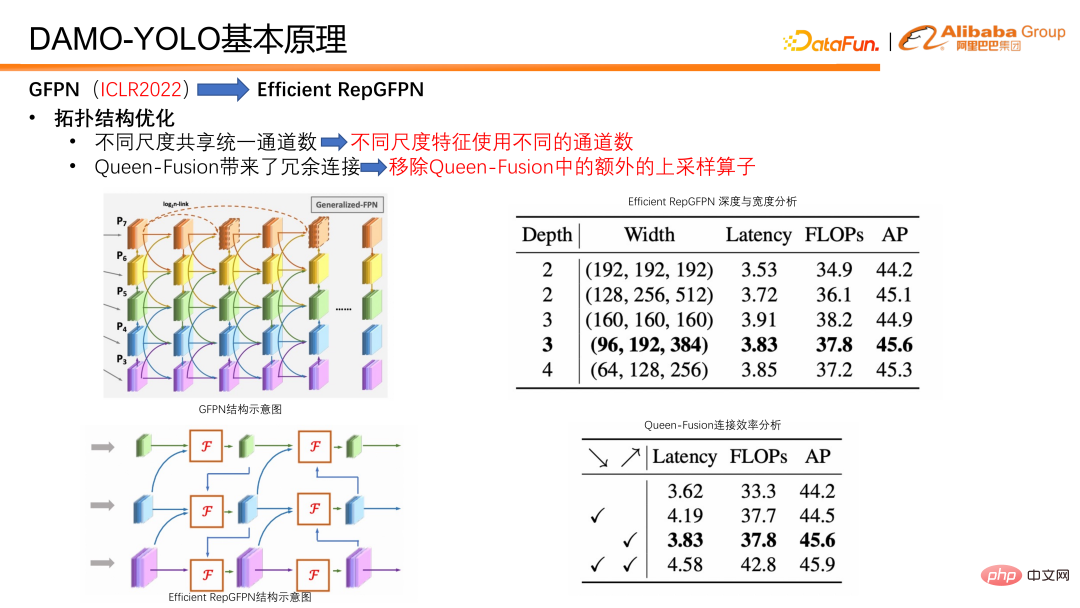
Nous avons également procédé à quelques optimisations en termes de méthodes d'intégration. Premièrement, le nombre de nœuds de fusion est fixe, de sorte que seules deux fusions sont effectuées dans chaque modèle, au lieu d'empiler continuellement les fusions pour créer un GFPN plus profond comme auparavant. Cela évite la réduction de l'efficacité parallèle provoquée par la croissance continue des liaisons série. De plus, nous avons spécialement conçu un bloc de fusion pour la fusion de fonctionnalités. Dans le bloc fusionon, nous introduisons des technologies telles qu'un mécanisme de paramétrage lourd et une connexion d'agrégation multicouche pour améliorer encore l'effet de fusion.
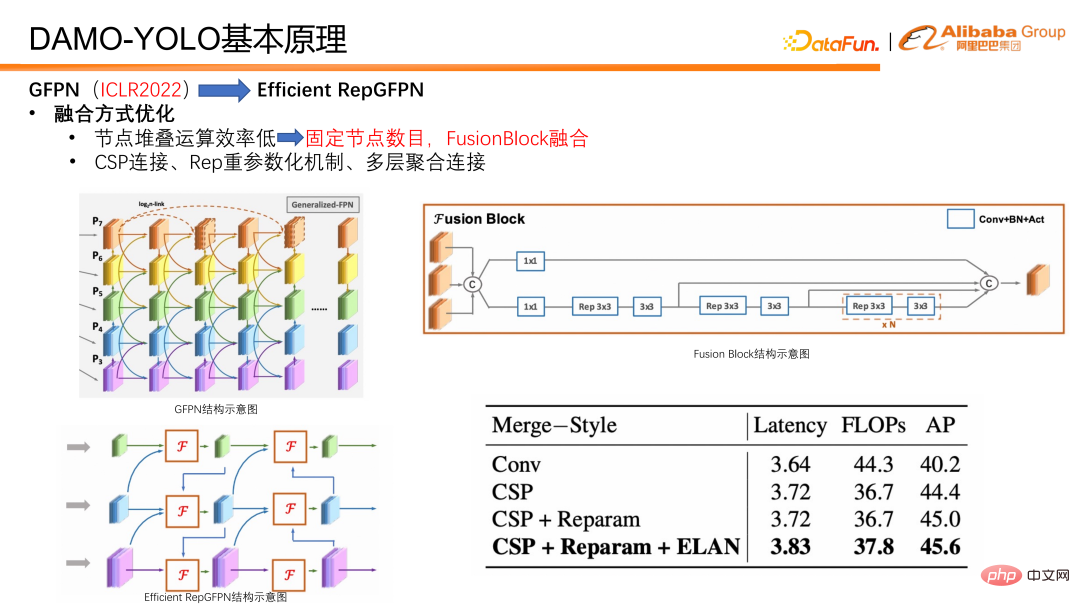
En plus du cou, la tête de détection Head est également une partie importante du modèle de détection. Il prend les caractéristiques produites par Neck en entrée et est responsable de la sortie des résultats de régression et de classification. Nous avons conçu des expériences pour vérifier le compromis entre Efficient RepGFPN et Head, et avons constaté que lorsque la latence du modèle est strictement contrôlée, plus Efficient RepGFPN est profond, mieux c'est. Par conséquent, dans la conception du réseau, le montant du calcul est principalement alloué à Efficient RepGFPN, tandis qu'une seule couche de projection linéaire est réservée dans la partie Head pour les tâches de classification et de régression. Nous appelons la tête qui n'a qu'une seule couche de classification et une couche de cartographie non linéaire de régression ZeroHead. Un modèle de conception qui alloue cette charge de calcul principalement à Neck est appelé le paradigme Heavyneck.
La structure finale du modèle de DAMO-YOLO est présentée dans la figure ci-dessous.
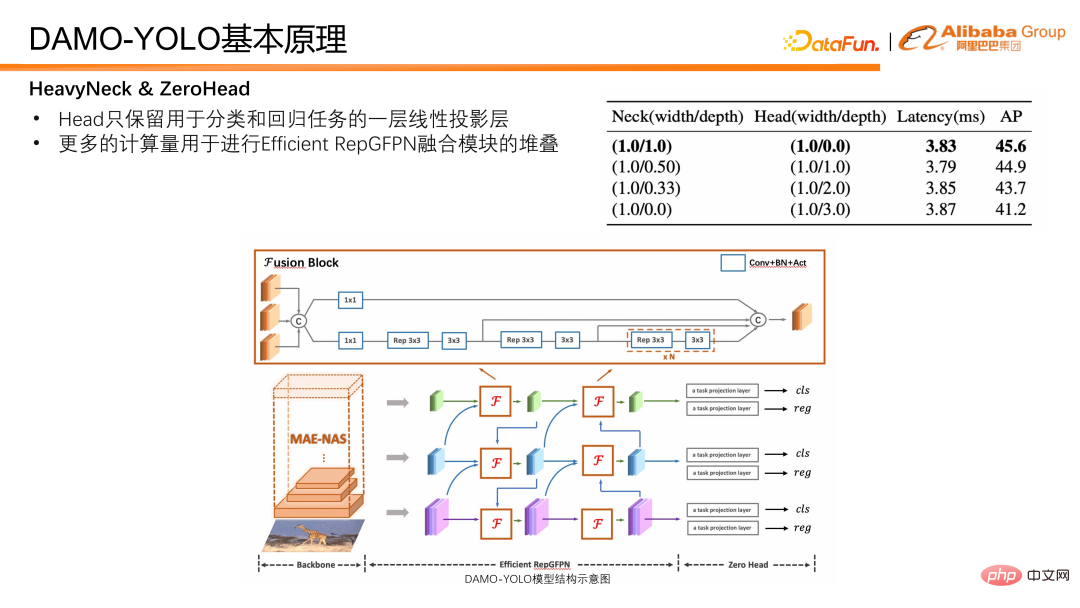
Ci-dessus sont quelques réflexions sur la conception de modèles. Enfin, introduisons le schéma de distillation.
DAMO-YOLO reprend les fonctionnalités de sortie d'Efficient RepGFPN pour la distillation. La fonction étudiant passera d’abord par le module align pour aligner son numéro de canal sur celui de l’enseignant. Afin de supprimer le biais du modèle lui-même, les caractéristiques de l'étudiant et de l'enseignant sont normalisées par un BN impartial, puis la perte de distillation est calculée. Lors de la distillation, nous avons observé qu'une perte excessive entraverait la convergence de la branche de classification propre à l'étudiant. Nous avons donc choisi d'utiliser un poids dynamique qui décroît avec l'entraînement. D’après les résultats expérimentaux, le poids de distillation uniforme dynamique est robuste aux modèles T/S/M.
La chaîne de distillation de DAMO-YOLO est, L distillation M, M distillation S. Il convient de mentionner que lorsque M distille S, M utilise un emballage CSP, tandis que S utilise un emballage Res. Structurellement parlant, M et S sont des isomères. Cependant, lors de l'utilisation du schéma de distillation DAMO-YOLO, M distille S, il peut également y avoir une amélioration de 1,2 points après distillation, indiquant que notre schéma de distillation est également robuste à l'isomérie. En résumé, le schéma de distillation de DAMO-YOLO a des paramètres libres, prend en charge une gamme complète de modèles et est hétérogène et robuste.
Enfin, résumons DAMO-YOLO. DAMO-YOLO combine la technologie MAE-NAS pour permettre une personnalisation de modèle à faible coût et utilise pleinement la puissance de calcul de la puce. Associé aux paradigmes Efficient RepGFPN et Heavyneck, il améliore les capacités de détection multi-échelles et dispose d'une large gamme d'applications de modèles avec la gamme complète. Schéma de distillation à grande échelle, il peut améliorer encore l'efficacité du modèle.

Le modèle DAMO-YOLO a été lancé sur ModelScope et est open source sur github. Tout le monde est invité à l'essayer.
5. Plan de développement de DAMO-YOLODAMO-YOLO vient de sortir, et il reste encore de nombreux domaines qui doivent être améliorés et optimisés. Nous prévoyons d'améliorer les outils de déploiement et de prendre en charge ModelScope à court terme. En outre, d'autres exemples d'application seront fournis sur la base des solutions championnes de la compétition au sein du groupe, telles que la détection de petites cibles par drone et la détection de cibles rotatives. Il est également prévu de lancer davantage de modèles d'exemple, notamment le modèle Nano pour l'appareil et le modèle Large pour le cloud. Enfin, j’espère que tout le monde y prêtera attention et fournira des commentaires positifs.

Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 CLIP-BEVFormer : superviser explicitement la structure BEVFormer pour améliorer les performances de détection à longue traîne
Mar 26, 2024 pm 12:41 PM
CLIP-BEVFormer : superviser explicitement la structure BEVFormer pour améliorer les performances de détection à longue traîne
Mar 26, 2024 pm 12:41 PM
Écrit ci-dessus et compréhension personnelle de l'auteur : À l'heure actuelle, dans l'ensemble du système de conduite autonome, le module de perception joue un rôle essentiel. Le véhicule autonome roulant sur la route ne peut obtenir des résultats de perception précis que via le module de perception en aval. dans le système de conduite autonome, prend des jugements et des décisions comportementales opportuns et corrects. Actuellement, les voitures dotées de fonctions de conduite autonome sont généralement équipées d'une variété de capteurs d'informations de données, notamment des capteurs de caméra à vision panoramique, des capteurs lidar et des capteurs radar à ondes millimétriques pour collecter des informations selon différentes modalités afin d'accomplir des tâches de perception précises. L'algorithme de perception BEV basé sur la vision pure est privilégié par l'industrie en raison de son faible coût matériel et de sa facilité de déploiement, et ses résultats peuvent être facilement appliqués à diverses tâches en aval.
 Implémentation d'algorithmes d'apprentissage automatique en C++ : défis et solutions courants
Jun 03, 2024 pm 01:25 PM
Implémentation d'algorithmes d'apprentissage automatique en C++ : défis et solutions courants
Jun 03, 2024 pm 01:25 PM
Les défis courants rencontrés par les algorithmes d'apprentissage automatique en C++ incluent la gestion de la mémoire, le multithread, l'optimisation des performances et la maintenabilité. Les solutions incluent l'utilisation de pointeurs intelligents, de bibliothèques de threads modernes, d'instructions SIMD et de bibliothèques tierces, ainsi que le respect des directives de style de codage et l'utilisation d'outils d'automatisation. Des cas pratiques montrent comment utiliser la bibliothèque Eigen pour implémenter des algorithmes de régression linéaire, gérer efficacement la mémoire et utiliser des opérations matricielles hautes performances.
 Explorez les principes sous-jacents et la sélection d'algorithmes de la fonction de tri C++
Apr 02, 2024 pm 05:36 PM
Explorez les principes sous-jacents et la sélection d'algorithmes de la fonction de tri C++
Apr 02, 2024 pm 05:36 PM
La couche inférieure de la fonction de tri C++ utilise le tri par fusion, sa complexité est O(nlogn) et propose différents choix d'algorithmes de tri, notamment le tri rapide, le tri par tas et le tri stable.
 L'intelligence artificielle peut-elle prédire la criminalité ? Explorez les capacités de CrimeGPT
Mar 22, 2024 pm 10:10 PM
L'intelligence artificielle peut-elle prédire la criminalité ? Explorez les capacités de CrimeGPT
Mar 22, 2024 pm 10:10 PM
La convergence de l’intelligence artificielle (IA) et des forces de l’ordre ouvre de nouvelles possibilités en matière de prévention et de détection de la criminalité. Les capacités prédictives de l’intelligence artificielle sont largement utilisées dans des systèmes tels que CrimeGPT (Crime Prediction Technology) pour prédire les activités criminelles. Cet article explore le potentiel de l’intelligence artificielle dans la prédiction de la criminalité, ses applications actuelles, les défis auxquels elle est confrontée et les éventuelles implications éthiques de cette technologie. Intelligence artificielle et prédiction de la criminalité : les bases CrimeGPT utilise des algorithmes d'apprentissage automatique pour analyser de grands ensembles de données, identifiant des modèles qui peuvent prédire où et quand les crimes sont susceptibles de se produire. Ces ensembles de données comprennent des statistiques historiques sur la criminalité, des informations démographiques, des indicateurs économiques, des tendances météorologiques, etc. En identifiant les tendances qui pourraient échapper aux analystes humains, l'intelligence artificielle peut donner du pouvoir aux forces de l'ordre.
 Algorithme de détection amélioré : pour la détection de cibles dans des images de télédétection optique haute résolution
Jun 06, 2024 pm 12:33 PM
Algorithme de détection amélioré : pour la détection de cibles dans des images de télédétection optique haute résolution
Jun 06, 2024 pm 12:33 PM
01Aperçu des perspectives Actuellement, il est difficile d'atteindre un équilibre approprié entre efficacité de détection et résultats de détection. Nous avons développé un algorithme YOLOv5 amélioré pour la détection de cibles dans des images de télédétection optique haute résolution, en utilisant des pyramides de caractéristiques multicouches, des stratégies de têtes de détection multiples et des modules d'attention hybrides pour améliorer l'effet du réseau de détection de cibles dans les images de télédétection optique. Selon l'ensemble de données SIMD, le mAP du nouvel algorithme est 2,2 % meilleur que YOLOv5 et 8,48 % meilleur que YOLOX, permettant ainsi d'obtenir un meilleur équilibre entre les résultats de détection et la vitesse. 02 Contexte et motivation Avec le développement rapide de la technologie de télédétection, les images de télédétection optique à haute résolution ont été utilisées pour décrire de nombreux objets à la surface de la Terre, notamment des avions, des voitures, des bâtiments, etc. Détection d'objets dans l'interprétation d'images de télédétection
 Pratique et réflexion sur la plateforme multimodale de grands modèles Jiuzhang Yunji DataCanvas
Oct 20, 2023 am 08:45 AM
Pratique et réflexion sur la plateforme multimodale de grands modèles Jiuzhang Yunji DataCanvas
Oct 20, 2023 am 08:45 AM
1. Le développement historique des grands modèles multimodaux. La photo ci-dessus est le premier atelier sur l'intelligence artificielle organisé au Dartmouth College aux États-Unis en 1956. Cette conférence est également considérée comme le coup d'envoi du développement de l'intelligence artificielle. pionniers de la logique symbolique (à l'exception du neurobiologiste Peter Milner au milieu du premier rang). Cependant, cette théorie de la logique symbolique n’a pas pu être réalisée avant longtemps et a même marqué le début du premier hiver de l’IA dans les années 1980 et 1990. Il a fallu attendre la récente mise en œuvre de grands modèles de langage pour découvrir que les réseaux de neurones portent réellement cette pensée logique. Les travaux du neurobiologiste Peter Milner ont inspiré le développement ultérieur des réseaux de neurones artificiels, et c'est pour cette raison qu'il a été invité à y participer. dans ce projet.
 Application d'algorithmes dans la construction de 58 plateformes de portraits
May 09, 2024 am 09:01 AM
Application d'algorithmes dans la construction de 58 plateformes de portraits
May 09, 2024 am 09:01 AM
1. Contexte de la construction de la plateforme 58 Portraits Tout d'abord, je voudrais partager avec vous le contexte de la construction de la plateforme 58 Portraits. 1. La pensée traditionnelle de la plate-forme de profilage traditionnelle ne suffit plus. La création d'une plate-forme de profilage des utilisateurs s'appuie sur des capacités de modélisation d'entrepôt de données pour intégrer les données de plusieurs secteurs d'activité afin de créer des portraits d'utilisateurs précis. Elle nécessite également l'exploration de données pour comprendre le comportement et les intérêts des utilisateurs. et besoins, et fournir des capacités côté algorithmes ; enfin, il doit également disposer de capacités de plate-forme de données pour stocker, interroger et partager efficacement les données de profil utilisateur et fournir des services de profil. La principale différence entre une plate-forme de profilage d'entreprise auto-construite et une plate-forme de profilage de middle-office est que la plate-forme de profilage auto-construite dessert un seul secteur d'activité et peut être personnalisée à la demande. La plate-forme de mid-office dessert plusieurs secteurs d'activité et est complexe ; modélisation et offre des fonctionnalités plus générales. 2.58 Portraits d'utilisateurs de l'arrière-plan de la construction du portrait sur la plate-forme médiane 58
 Ajoutez SOTA en temps réel et montez en flèche ! FastOcc : un algorithme Occ plus rapide et convivial pour le déploiement est là !
Mar 14, 2024 pm 11:50 PM
Ajoutez SOTA en temps réel et montez en flèche ! FastOcc : un algorithme Occ plus rapide et convivial pour le déploiement est là !
Mar 14, 2024 pm 11:50 PM
Écrit ci-dessus & La compréhension personnelle de l'auteur est que dans le système de conduite autonome, la tâche de perception est un élément crucial de l'ensemble du système de conduite autonome. L'objectif principal de la tâche de perception est de permettre aux véhicules autonomes de comprendre et de percevoir les éléments environnementaux environnants, tels que les véhicules circulant sur la route, les piétons au bord de la route, les obstacles rencontrés lors de la conduite, les panneaux de signalisation sur la route, etc., aidant ainsi en aval modules Prendre des décisions et des actions correctes et raisonnables. Un véhicule doté de capacités de conduite autonome est généralement équipé de différents types de capteurs de collecte d'informations, tels que des capteurs de caméra à vision panoramique, des capteurs lidar, des capteurs radar à ondes millimétriques, etc., pour garantir que le véhicule autonome peut percevoir et comprendre avec précision l'environnement environnant. éléments , permettant aux véhicules autonomes de prendre les bonnes décisions pendant la conduite autonome. Tête
