
 Périphériques technologiques
IA
Cela ne prend que 3 secondes pour voler votre voix ! Microsoft lance le modèle de synthèse vocale VALL-E : les internautes se sont exclamés que le seuil de « fraude téléphonique » a de nouveau été abaissé
Périphériques technologiques
IA
Cela ne prend que 3 secondes pour voler votre voix ! Microsoft lance le modèle de synthèse vocale VALL-E : les internautes se sont exclamés que le seuil de « fraude téléphonique » a de nouveau été abaissé
Cela ne prend que 3 secondes pour voler votre voix ! Microsoft lance le modèle de synthèse vocale VALL-E : les internautes se sont exclamés que le seuil de « fraude téléphonique » a de nouveau été abaissé

Laissez ChatGPT vous aider à écrire le script et Stable Diffusion générer des illustrations. Avez-vous besoin d'un doubleur pour réaliser une vidéo ? Ça arrive !
Récemment, des chercheurs de Microsoft ont publié un nouveau modèle de synthèse vocale (TTS) VALL-E, qui n'a besoin que de fournir trois secondes d'échantillons audio pour simuler les voix humaines d'entrée et les synthétiser en fonction du texte d'entrée correspondant. produit tout en conservant le ton émotionnel de l’orateur.

Lien papier : https://www.php.cn/link/402cac3dacf2ef35050ca72743ae6ca7
Lien du projet : https://valle-demo.github.io/
Lien code : https://github.com /microsoft/unilm
Jetons d'abord un coup d'œil à l'effet : supposons que vous ayez un enregistrement de 3 secondes.
diversity_speaker audio : 00:0000:03
Ensuite, entrez simplement le texte "Parce que nous n'en avons pas besoin pour obtenir le discours synthétisé."
diversity_s1 audio : 00:0000:01
Même en utilisant différentes graines aléatoires, vous pouvez également effectuer une synthèse vocale personnalisée.
diversity_s2 audio : 00:0000:02
VALL-E peut également maintenir le son ambiant du haut-parleur, comme la saisie de cette voix.
env_speaker audio : 00:0000:03
Ensuite, selon le texte "Je pense que c'est comme si vous savez, c'est plus pratique aussi.", vous pouvez émettre la parole synthétisée tout en conservant le son ambiant.
env_vall_e Audio : 00:0000:02
Et VALL-E peut également maintenir l'émotion de l'orateur, comme la saisie d'une voix en colère.
anger_pt Audio : 00:0000:03
Selon le texte « Nous devons réduire le nombre de sacs en plastique. », vous pouvez aussi exprimer votre colère.
anger_ours Audio : 00:0000:02
Il existe de nombreux autres exemples sur le site Web du projet.
Méthodologiquement parlant, les chercheurs ont formé le modèle de langage VALL-E à partir d'encodages discrets extraits de modèles de codecs audio neuronaux disponibles dans le commerce et ont traité le TTS comme une tâche de modélisation de langage conditionnelle plutôt que comme une régression continue du signal.
Dans la phase de pré-formation, les données de formation TTS reçues par VALL-E ont atteint 60 000 heures de parole en anglais, soit des centaines de fois plus volumineuses que les données utilisées par le système existant.
Et VALL-E démontre également la capacité d'apprentissage en contexte. Il suffit d'utiliser l'enregistrement d'enregistrement de 3 secondes du locuteur invisible comme invite sonore pour synthétiser un discours personnalisé de haute qualité.
Les résultats expérimentaux montrent que VALL-E est nettement meilleur que le système Zero-shot TTS de pointe en termes de naturel de la parole et de similarité du locuteur, et peut également préserver l'émotion du locuteur et l'environnement acoustique des signaux sonores. dans la synthèse.
Synthèse vocale Zero-shot
Au cours de la dernière décennie, la synthèse vocale a fait d'énormes progrès grâce au développement des réseaux neuronaux et à la modélisation de bout en bout.
Mais les systèmes actuels de synthèse vocale en cascade (TTS) utilisent généralement un pipeline avec un modèle acoustique et un vocodeur qui utilise des spectrogrammes mel comme représentations intermédiaires.
Bien que certains systèmes TTS hautes performances puissent synthétiser la parole de haute qualité à partir d'un ou de plusieurs locuteurs, ils nécessitent toujours des données propres de haute qualité provenant du studio d'enregistrement. Les données à grande échelle extraites d'Internet ne peuvent pas répondre aux exigences en matière de données. entraînera une diminution des performances du modèle.
En raison de la quantité relativement faible de données d'entraînement, le système TTS actuel présente toujours le problème d'une faible capacité de généralisation.
Dans le cadre de la tâche zéro tir, pour les locuteurs qui ne sont pas apparus dans les données d'entraînement, la similarité et le naturel de la parole diminueront fortement.
Pour résoudre le problème du TTS zéro-shot, les travaux existants utilisent généralement des méthodes telles que l'adaptation et l'encodage des haut-parleurs, qui nécessitent un réglage précis supplémentaire, des fonctionnalités préconçues complexes ou une ingénierie structurelle lourde.
Plutôt que de concevoir un réseau complexe et spécialisé pour ce problème, compte tenu du succès dans le domaine de la synthèse de texte, les chercheurs estiment que la solution ultime devrait être d'entraîner le modèle avec des données aussi diverses que possible.
Modèle VALL-E
Dans le domaine de la synthèse de texte, les données non étiquetées à grande échelle provenant d'Internet sont directement introduites dans le modèle. À mesure que la quantité de données d'entraînement augmente, les performances du modèle s'améliorent constamment.
Les chercheurs ont migré cette idée vers le domaine de la synthèse vocale. Le modèle VALL-E est le premier cadre TTS basé sur des modèles de langage, utilisant des données vocales massives, diverses et multi-locuteurs.
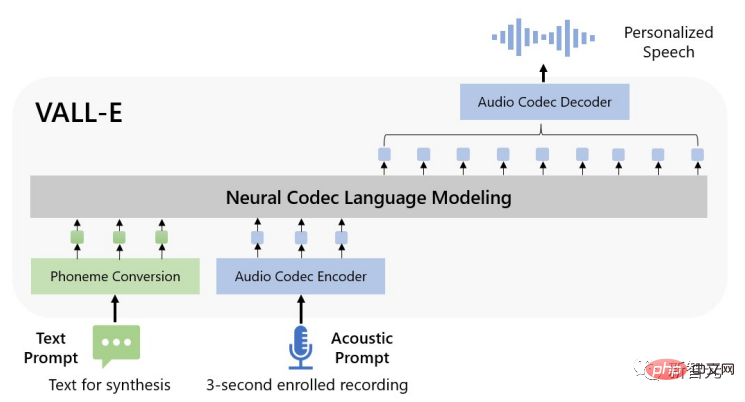
Afin de synthétiser une parole personnalisée, le modèle VALL-E génère le jeton acoustique correspondant en fonction du jeton acoustique et de l'invite phonémique de l'enregistrement enregistré de 3 secondes. Ces informations peuvent limiter les informations sur le locuteur et le contenu.
Enfin, le jeton acoustique généré est utilisé pour synthétiser la forme d'onde finale avec le codec neuronal correspondant.
Les jetons acoustiques discrets du modèle de codec audio permettent à TTS d'être considéré comme une modélisation de langage de codec conditionnel, de sorte que certaines techniques avancées de grand modèle basées sur des indices (telles que les GPT) peuvent être utilisées pour les tâches TTS.
Les jetons acoustiques peuvent également utiliser différentes stratégies d'échantillonnage pendant le processus d'inférence pour produire divers résultats de synthèse dans TTS.
Les chercheurs ont formé VALL-E à l'aide de l'ensemble de données LibriLight, qui comprend 60 000 heures de parole en anglais avec plus de 7 000 locuteurs uniques. Les données brutes sont uniquement audio, donc seul un modèle de reconnaissance vocale est utilisé pour générer les transcriptions.
Par rapport aux précédents ensembles de données de formation TTS, tels que LibriTTS, le nouvel ensemble de données fourni dans l'article contient des paroles plus bruyantes et des transcriptions inexactes, mais fournit des locuteurs et des prosodies différents.
Les chercheurs estiment que la méthode proposée dans l'article est robuste au bruit et peut utiliser le Big Data pour obtenir une bonne généralité.

Il convient de noter que les systèmes TTS existants utilisent toujours des dizaines d'heures de données de locuteurs monolingues ou des centaines d'heures de données de locuteurs multilingues pour la formation, ce qui est plus de centaines de fois plus petit que VALL-E.
En bref, VALL-E est une toute nouvelle méthode de modèle de langage pour TTS, qui utilise des codes d'encodage et de décodage audio comme représentations intermédiaires et utilise une grande quantité de données différentes pour donner au modèle de puissantes capacités d'apprentissage contextuel.
Inférence : apprentissage en contexte via des invites
L'apprentissage en contexte est une capacité étonnante des modèles de langage basés sur du texte, qui est capable de prédire l'étiquette d'une entrée invisible sans avoir besoin de mettre à jour des paramètres supplémentaires.
Pour TTS, si le modèle peut synthétiser une parole de haute qualité pour des locuteurs invisibles sans réglage fin, alors le modèle est considéré comme ayant des capacités d'apprentissage contextuel.
Cependant, les systèmes TTS existants ne disposent pas de solides capacités d'apprentissage en contexte, car soit ils nécessitent des réglages supplémentaires, soit ils souffrent d'une dégradation importante pour les locuteurs invisibles.
L'incitation est nécessaire pour que les modèles de langage réalisent un apprentissage contextuel dans des situations zéro-shot.
Les indices et le raisonnement conçus par les chercheurs sont les suivants :
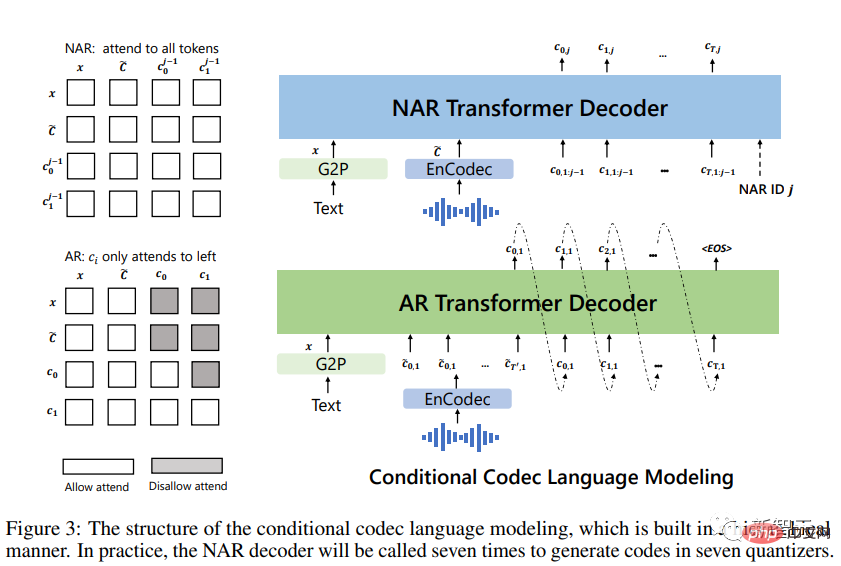
Convertissez d'abord le texte en séquences de phonèmes et encodez les enregistrements inscrits dans des matrices acoustiques pour former des indices phonémiques et des indices acoustiques, tous deux utilisés dans les modèles AR et NAR.
Pour les modèles AR, utilisez un décodage basé sur l'échantillonnage conditionnel à des indices, car la recherche de faisceau peut faire entrer LM dans une boucle infinie. De plus, les méthodes basées sur l'échantillonnage peuvent augmenter considérablement la diversité des sorties ;
Pour le modèle NAR, utilisez le décodage glouton pour sélectionner le jeton avec la probabilité la plus élevée.
Enfin, un codec neuronal est utilisé pour générer des formes d'onde conditionnées sur les huit séquences codantes.
Les signaux acoustiques n'ont pas nécessairement de relation sémantique avec la parole à synthétiser, ils peuvent donc être divisés en deux cas :
VALL-E : L'objectif principal est de générer un contenu donné pour un locuteur invisible.
L'entrée de ce modèle est une phrase de texte, un discours inscrit et sa transcription correspondante. Ajoutez les phonèmes transcrits du discours enregistré comme indices phonémiques à la séquence phonémique de la phrase donnée et utilisez le jeton acoustique de premier niveau du discours enregistré comme préfixe acoustique. Avec des indices phonémiques et des préfixes acoustiques, VALL-E génère un jeton acoustique pour un texte donné, clonant la voix du locuteur.
VALL-E-continual : utilise l'intégralité de la transcription et les 3 premières secondes de l'énoncé comme indices phonémiques et acoustiques respectivement, et demande au modèle de générer un contenu continu.
Le processus de raisonnement est le même que pour la définition de VALL-E, sauf que la parole inscrite et la parole générée sont sémantiquement continues.
Section expérimentale
Les chercheurs ont évalué VALL-E sur les ensembles de données LibriSpeech et VCTK, où tous les locuteurs testés n'apparaissaient pas dans le corpus de formation.
VALL-E surpasse considérablement les systèmes TTS Zero-shot de pointe en termes de naturel de la parole et de similarité des locuteurs, avec un score d'option moyen comparatif (CMOS) de +0,12 et un score d'option moyen de similarité de +0,93 sur LibriSpeech (SMOS). .
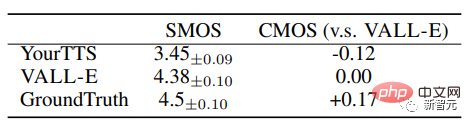
VALL-E surpasse également le système de base avec des améliorations de performances de +0,11 SMOS et +0,23 CMOS sur VCTK, atteignant même un score CMOS de +0,04 par rapport à la vérité terrain, démontrant une parole invisible sur VCTK. La parole synthétisée de l'orateur est aussi naturelle comme des enregistrements humains.
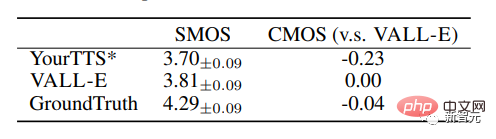
De plus, l'analyse qualitative montre que VALL-E est capable de synthétiser différentes sorties avec 2 textes et locuteurs cibles identiques, ce qui peut être bénéfique pour la création de pseudo-données pour les tâches de reconnaissance vocale.
On constate également dans l'expérience que VALL-E peut entretenir l'environnement sonore (comme la réverbération) et l'émotion suscitée par le son (comme la colère, etc.).
Risques de sécurité
Si une technologie puissante est utilisée à mauvais escient, elle peut nuire à la société. Par exemple, le seuil de fraude téléphonique a de nouveau été abaissé !
En raison du potentiel de méfait et de tromperie de VALL-E, Microsoft n’a pas ouvert le code ou les interfaces de VALL-E pour les tests.
Certains internautes ont partagé : si vous appelez l'administrateur système, enregistrez quelques mots qu'ils disent "Bonjour", puis re-synthétisez la voix en fonction de ces mots "Bonjour, je suis l'administrateur système. Mon son est un identifiant unique et peut être vérifié en toute sécurité. « J'ai toujours pensé que c'était impossible. On ne pouvait pas accomplir cette tâche avec si peu de données. Maintenant, il semble que je me sois peut-être trompé...
Dans la déclaration éthique finale du projet, le chercheur a déclaré que « l'expérience décrite dans cet article a été menée lorsque l'utilisateur modèle était l'orateur cible et a été approuvée par l'orateur. Cependant, lorsque le modèle est généralisé à des locuteurs invisibles, les parties pertinentes doivent être accompagnées d'un modèle d'édition de la parole, comprenant un protocole pour garantir que l'orateur accepte d'effectuer la modification et un système pour détecter la parole éditée
L'auteur. indique également dans le document que, puisque VALL-E peut synthétiser une parole qui préserve l'identité du locuteur, cela peut entraîner des risques potentiels d'utilisation abusive du modèle, tels qu'une reconnaissance vocale trompeuse ou l'imitation d'un locuteur spécifique. Pour réduire ce risque, un modèle de détection peut être construit pour distinguer si un clip audio est synthétisé par VALL-E. Au fur et à mesure que nous développerons ces modèles, nous mettrons également en pratique les principes de Microsoft AI.
Pour réduire ce risque, un modèle de détection peut être construit pour distinguer si un clip audio est synthétisé par VALL-E. Au fur et à mesure que nous développerons ces modèles, nous mettrons également en pratique les principes de Microsoft AI.
Référence :
https://www.php.cn/link/402cac3dacf2ef35050ca72743ae6ca7
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

Video Face Swap
Échangez les visages dans n'importe quelle vidéo sans effort grâce à notre outil d'échange de visage AI entièrement gratuit !

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Adresse d'entrée de la version internationale de Microsoft Bing (entrée du moteur de recherche Bing)
Mar 14, 2024 pm 01:37 PM
Adresse d'entrée de la version internationale de Microsoft Bing (entrée du moteur de recherche Bing)
Mar 14, 2024 pm 01:37 PM
Bing est un moteur de recherche en ligne lancé par Microsoft. La fonction de recherche est très puissante et comporte deux entrées : la version nationale et la version internationale. Où sont les entrées de ces deux versions ? Comment accéder à la version internationale ? Jetons un coup d'œil aux détails ci-dessous. Entrée du site Web de la version chinoise de Bing : https://cn.bing.com/ Entrée du site Web de la version internationale de Bing : https://global.bing.com/ Comment accéder à la version internationale de Bing ? 1. Entrez d'abord l'URL pour ouvrir Bing : https://www.bing.com/ 2. Vous pouvez voir qu'il existe des options pour les versions nationales et internationales. Il suffit de sélectionner la version internationale et de saisir les mots-clés.
 Pourquoi n'entends-je pas le son sur WeChat Voice ? Que dois-je faire si je n'entends pas le son sur WeChat Voice ?
Mar 13, 2024 pm 02:31 PM
Pourquoi n'entends-je pas le son sur WeChat Voice ? Que dois-je faire si je n'entends pas le son sur WeChat Voice ?
Mar 13, 2024 pm 02:31 PM
Pourquoi n’entends-je pas le son sur WeChat Voice ? WeChat est un outil de communication indispensable dans notre vie quotidienne. De nombreux utilisateurs ont rencontré des problèmes lors de l'utilisation. Par exemple, vous n'entendez pas le son de la voix de WeChat ? Alors que faire? Laissez ce site donner aux utilisateurs une introduction détaillée sur ce qu'il faut faire s'ils n'entendent pas le son de la voix WeChat. Que dois-je faire si je n'entends pas le son de la voix WeChat ? 1. Le son défini par le système de téléphonie mobile est relativement faible ou muet. Dans ce cas, vous pouvez augmenter le volume ou désactiver le mode silencieux. 2. Il est également possible que la fonction haut-parleur WeChat ne soit pas activée. Ouvrez « Paramètres » et sélectionnez l'option « Chat ». 3. Après avoir cliqué sur l'option « Chat »
 Mise à niveau de Microsoft Edge : la fonction de sauvegarde automatique du mot de passe interdite ? ! Les utilisateurs ont été choqués !
Apr 19, 2024 am 08:13 AM
Mise à niveau de Microsoft Edge : la fonction de sauvegarde automatique du mot de passe interdite ? ! Les utilisateurs ont été choqués !
Apr 19, 2024 am 08:13 AM
Actualités du 18 avril : Récemment, certains utilisateurs du navigateur Microsoft Edge utilisant le canal Canary ont signalé qu'après la mise à niveau vers la dernière version, ils avaient constaté que l'option d'enregistrement automatique des mots de passe était désactivée. Après enquête, il a été constaté qu'il s'agissait d'un ajustement mineur après la mise à niveau du navigateur, plutôt que d'une suppression de fonctionnalités. Avant d'utiliser le navigateur Edge pour accéder à un site Web, les utilisateurs ont signalé que le navigateur ouvrait une fenêtre leur demandant s'ils souhaitaient enregistrer le mot de passe de connexion au site Web. Après avoir choisi d'enregistrer, Edge remplira automatiquement le numéro de compte et le mot de passe enregistrés lors de votre prochaine connexion, offrant ainsi aux utilisateurs une grande commodité. Mais la dernière mise à jour ressemble à un ajustement, modifiant les paramètres par défaut. Les utilisateurs doivent choisir d'enregistrer le mot de passe, puis activer manuellement le remplissage automatique du compte et du mot de passe enregistrés dans les paramètres.
 Microsoft publie la mise à jour cumulative Win11 août : amélioration de la sécurité, optimisation de l'écran de verrouillage, etc.
Aug 14, 2024 am 10:39 AM
Microsoft publie la mise à jour cumulative Win11 août : amélioration de la sécurité, optimisation de l'écran de verrouillage, etc.
Aug 14, 2024 am 10:39 AM
Selon les informations de ce site du 14 août, lors de la journée d'événement Patch Tuesday d'aujourd'hui, Microsoft a publié des mises à jour cumulatives pour les systèmes Windows 11, notamment la mise à jour KB5041585 pour 22H2 et 23H2 et la mise à jour KB5041592 pour 21H2. Après l'installation de l'équipement mentionné ci-dessus avec la mise à jour cumulative d'août, les changements de numéro de version attachés à ce site sont les suivants : Après l'installation de l'équipement 21H2, le numéro de version est passé à Build22000.314722H2. le numéro de version est passé à Build22621.403723H2. Après l'installation de l'équipement, le numéro de version est passé à Build22631.4037. Le contenu principal de la mise à jour KB5041585 pour Windows 1121H2 est le suivant : Amélioration : Amélioré.
 La fenêtre contextuelle plein écran de Microsoft exhorte les utilisateurs de Windows 10 à se dépêcher et à passer à Windows 11
Jun 06, 2024 am 11:35 AM
La fenêtre contextuelle plein écran de Microsoft exhorte les utilisateurs de Windows 10 à se dépêcher et à passer à Windows 11
Jun 06, 2024 am 11:35 AM
Selon l'actualité du 3 juin, Microsoft envoie activement des notifications en plein écran à tous les utilisateurs de Windows 10 pour les encourager à passer au système d'exploitation Windows 11. Ce déplacement concerne les appareils dont les configurations matérielles ne prennent pas en charge le nouveau système. Depuis 2015, Windows 10 occupe près de 70 % des parts de marché, établissant ainsi sa domination en tant que système d'exploitation Windows. Cependant, la part de marché dépasse largement la part de marché de 82 %, et la part de marché dépasse largement celle de Windows 11, qui sortira en 2021. Même si Windows 11 est lancé depuis près de trois ans, sa pénétration sur le marché est encore lente. Microsoft a annoncé qu'il mettrait fin au support technique de Windows 10 après le 14 octobre 2025 afin de se concentrer davantage sur
 La fonction de compression des fichiers 7z et TAR de Microsoft Win11 a été rétrogradée des versions 24H2 aux versions 23H2/22H2
Apr 28, 2024 am 09:19 AM
La fonction de compression des fichiers 7z et TAR de Microsoft Win11 a été rétrogradée des versions 24H2 aux versions 23H2/22H2
Apr 28, 2024 am 09:19 AM
Selon les informations de ce site le 27 avril, Microsoft a publié la mise à jour de la version préliminaire de Windows 11 Build 26100 sur les canaux Canary et Dev plus tôt ce mois-ci, qui devrait devenir une version RTM candidate de la mise à jour Windows 1124H2. Les principaux changements de la nouvelle version sont l'explorateur de fichiers, l'intégration de Copilot, l'édition des métadonnées des fichiers PNG, la création de fichiers compressés TAR et 7z, etc. @PhantomOfEarth a découvert que Microsoft a délégué certaines fonctions de la version 24H2 (Germanium) à la version 23H2/22H2 (Nickel), comme la création de fichiers compressés TAR et 7z. Comme le montre le schéma, Windows 11 prendra en charge la création native de TAR
 Mise à jour du navigateur Microsoft Edge : ajout de la fonction 'zoomer sur l'image' pour améliorer l'expérience utilisateur
Mar 21, 2024 pm 01:40 PM
Mise à jour du navigateur Microsoft Edge : ajout de la fonction 'zoomer sur l'image' pour améliorer l'expérience utilisateur
Mar 21, 2024 pm 01:40 PM
Selon l'actualité du 21 mars, Microsoft a récemment mis à jour son navigateur Microsoft Edge et ajouté une fonction pratique « agrandir l'image ». Désormais, lorsqu'ils utilisent le navigateur Edge, les utilisateurs peuvent facilement trouver cette nouvelle fonctionnalité dans le menu contextuel en cliquant simplement avec le bouton droit sur l'image. Ce qui est plus pratique, c'est que les utilisateurs peuvent également passer le curseur sur l'image, puis double-cliquer sur la touche Ctrl pour appeler rapidement la fonction de zoom avant sur l'image. Selon la compréhension de l'éditeur, le nouveau navigateur Microsoft Edge a été testé pour les nouvelles fonctionnalités du canal Canary. La version stable du navigateur a également officiellement lancé la fonction pratique « agrandir l'image », offrant aux utilisateurs une expérience de navigation d'images plus pratique. Les médias scientifiques et technologiques étrangers y ont également prêté attention.
 Microsoft prévoit de supprimer progressivement NTLM dans Windows 11 au second semestre 2024 et de passer entièrement à l'authentification Kerberos
Jun 09, 2024 pm 04:17 PM
Microsoft prévoit de supprimer progressivement NTLM dans Windows 11 au second semestre 2024 et de passer entièrement à l'authentification Kerberos
Jun 09, 2024 pm 04:17 PM
Au second semestre 2024, le blog officiel de sécurité Microsoft a publié un message en réponse à l'appel de la communauté de la sécurité. La société prévoit d'éliminer le protocole d'authentification NTLAN Manager (NTLM) dans Windows 11, publié au second semestre 2024, pour améliorer la sécurité. Selon des explications précédentes, Microsoft a déjà pris des mesures similaires auparavant. Le 12 octobre dernier, Microsoft a proposé un plan de transition dans un communiqué de presse officiel visant à supprimer progressivement les méthodes d'authentification NTLM et à inciter davantage d'entreprises et d'utilisateurs à passer à Kerberos. Pour aider les entreprises susceptibles de rencontrer des problèmes avec les applications et services câblés après avoir désactivé l'authentification NTLM, Microsoft fournit IAKerb et
