
 développement back-end
Tutoriel Python
Comment résoudre le problème du pool de threads de ThreadPoolExecutor de Python
développement back-end
Tutoriel Python
Comment résoudre le problème du pool de threads de ThreadPoolExecutor de Python
Comment résoudre le problème du pool de threads de ThreadPoolExecutor de Python

Concept
Il existe déjà un module threading dans Python , pourquoi avons-nous besoin d'un pool de threads ? Python中已经有了threading模块,为什么还需要线程池呢,线程池又是什么东西呢?
以爬虫为例,需要控制同时爬取的线程数,例子中创建了20个线程,而同时只允许3个线程在运行,但是20个线程都需要创建和销毁,线程的创建是需要消耗系统资源的,有没有更好的方案呢?
其实只需要三个线程就行了,每个线程各分配一个任务,剩下的任务排队等待,当某个线程完成了任务的时候,排队任务就可以安排给这个线程继续执行。
这就是线程池的思想(当然没这么简单),但是自己编写线程池很难写的比较完美,还需要考虑复杂情况下的线程同步,很容易发生死锁。
从Python3.2开始,标准库为我们提供了concurrent.futures模块,它提供了ThreadPoolExecutor和ProcessPoolExecutor两个类,实现了对threading和multiprocessing的进一步抽象(这里主要关注线程池),不仅可以帮我们自动调度线程,还可以做到:
主线程可以获取某一个线程(或者任务的)的状态,以及返回值。
当一个线程完成的时候,主线程能够立即知道。
让多线程和多进程的编码接口一致。
实例
简单使用
from concurrent.futures import ThreadPoolExecutor
import time
# 参数times用来模拟网络请求的时间
def get_html(times):
time.sleep(times)
print("get page {}s finished".format(times))
return times
executor = ThreadPoolExecutor(max_workers=2)
# 通过submit函数提交执行的函数到线程池中,submit函数立即返回,不阻塞
task1 = executor.submit(get_html, (3))
task2 = executor.submit(get_html, (2))
# done方法用于判定某个任务是否完成
print(task1.done())
# cancel方法用于取消某个任务,该任务没有放入线程池中才能取消成功
print(task2.cancel())
time.sleep(4)
print(task1.done())
# result方法可以获取task的执行结果
print(task1.result())
# 执行结果
# False # 表明task1未执行完成
# False # 表明task2取消失败,因为已经放入了线程池中
# get page 2s finished
# get page 3s finished
# True # 由于在get page 3s finished之后才打印,所以此时task1必然完成了
# 3 # 得到task1的任务返回值ThreadPoolExecutor构造实例的时候,传入max_workers参数来设置线程池中最多能同时运行的线程数目。
使用submit函数来提交线程需要执行的任务(函数名和参数)到线程池中,并返回该任务的句柄(类似于文件、画图),注意submit()不是阻塞的,而是立即返回。
通过submit函数返回的任务句柄,能够使用done()方法判断该任务是否结束。上面的例子可以看出,由于任务有2s的延时,在task1提交后立刻判断,task1还未完成,而在延时4s之后判断,task1就完成了。
使用cancel()方法可以取消提交的任务,如果任务已经在线程池中运行了,就取消不了。这个例子中,线程池的大小设置为2,任务已经在运行了,所以取消失败。如果改变线程池的大小为1,那么先提交的是task1,task2还在排队等候,这是时候就可以成功取消。
使用result()方法可以获取任务的返回值。查看内部代码,发现这个方法是阻塞的。
as_completed
上面虽然提供了判断任务是否结束的方法,但是不能在主线程中一直判断啊。
有时候我们是得知某个任务结束了,就去获取结果,而不是一直判断每个任务有没有结束。
这是就可以使用as_completed方法一次取出所有任务的结果。
from concurrent.futures import ThreadPoolExecutor, as_completed
import time
# 参数times用来模拟网络请求的时间
def get_html(times):
time.sleep(times)
print("get page {}s finished".format(times))
return times
executor = ThreadPoolExecutor(max_workers=2)
urls = [3, 2, 4] # 并不是真的url
all_task = [executor.submit(get_html, (url)) for url in urls]
for future in as_completed(all_task):
data = future.result()
print("in main: get page {}s success".format(data))
# 执行结果
# get page 2s finished
# in main: get page 2s success
# get page 3s finished
# in main: get page 3s success
# get page 4s finished
# in main: get page 4s successas_completed()方法是一个生成器,在没有任务完成的时候,会阻塞,在有某个任务完成的时候,会yield这个任务,就能执行for循环下面的语句,然后继续阻塞住,循环到所有的任务结束。
从结果也可以看出,先完成的任务会先通知主线程。
map
除了上面的as_completed方法,还可以使用executor.map方法,但是有一点不同。
from concurrent.futures import ThreadPoolExecutor
import time
# 参数times用来模拟网络请求的时间
def get_html(times):
time.sleep(times)
print("get page {}s finished".format(times))
return times
executor = ThreadPoolExecutor(max_workers=2)
urls = [3, 2, 4] # 并不是真的url
for data in executor.map(get_html, urls):
print("in main: get page {}s success".format(data))
# 执行结果
# get page 2s finished
# get page 3s finished
# in main: get page 3s success
# in main: get page 2s success
# get page 4s finished
# in main: get page 4s success使用map方法,无需提前使用submit方法,map方法与python标准库中的map含义相同,都是将序列中的每个元素都执行同一个函数。
上面的代码就是对urls的每个元素都执行get_html函数,并分配各线程池。可以看到执行结果与上面的as_completed方法的结果不同,输出顺序和urls列表的顺序相同,就算2s的任务先执行完成,也会先打印出3s的任务先完成,再打印2s的任务完成。
wait
wait方法可以让主线程阻塞,直到满足设定的要求。
from concurrent.futures import ThreadPoolExecutor, wait, ALL_COMPLETED, FIRST_COMPLETED
import time
# 参数times用来模拟网络请求的时间
def get_html(times):
time.sleep(times)
print("get page {}s finished".format(times))
return times
executor = ThreadPoolExecutor(max_workers=2)
urls = [3, 2, 4] # 并不是真的url
all_task = [executor.submit(get_html, (url)) for url in urls]
wait(all_task, return_when=ALL_COMPLETED)
print("main")
# 执行结果
# get page 2s finished
# get page 3s finished
# get page 4s finished
# mainwait方法接收3个参数,等待的任务序列、超时时间以及等待条件。
等待条件return_when默认为ALL_COMPLETED,表明要等待所有的任务都结束。
可以看到运行结果中,确实是所有任务都完成了,主线程才打印出main。
等待条件还可以设置为FIRST_COMPLETED,表示第一个任务完成就停止等待。
源码分析
cocurrent.future模块中的future En prenant un robot comme exemple, vous devez contrôler le nombre de threads analysés en même temps. Dans l'exemple, 20 threads sont créés et seuls 3 threads sont autorisés à s'exécuter en même temps. , mais les 20 threads doivent être créés et détruits. La création de threads nécessite des ressources système. Existe-t-il une meilleure solution ?
Python3.2, la bibliothèque standard nous fournit le module concurrent.futures, qui fournit ThreadPoolExecutor et ProcessPoolExecutor sont deux classes qui implémentent une abstraction plus poussée du threading et du multiprocessing (l'objectif principal ici est le pool de threads), ce qui peut non seulement aider nous planifions automatiquement Les threads peuvent également faire : #🎜🎜#- #🎜🎜#Le thread principal peut obtenir le statut d'un certain thread (ou tâche) et la valeur de retour . #🎜🎜#
- #🎜🎜#Lorsqu'un fil de discussion se termine, le fil de discussion principal peut le savoir immédiatement. #🎜🎜#
- #🎜🎜#Rendre cohérente l'interface de codage multi-threading et multi-processus. #🎜🎜# #🎜🎜##🎜🎜#Instance#🎜🎜#
Utilisation simple
rrreee#🎜🎜#ThreadPoolExecutor Lors de la construction d'une instance, transmettez le paramètre max_workers pour définir le thread pool Nombre maximum de threads pouvant s'exécuter simultanément. #🎜🎜##🎜🎜#Utilisez la fonction submit pour soumettre la tâche (nom de la fonction et paramètres) que le thread doit effectuer au pool de threads et renvoyez le handle de la tâche (similaire aux fichiers et aux dessins). submit() ne bloque pas, mais renvoie immédiatement. #🎜🎜##🎜🎜#À l'aide du handle de tâche renvoyé par la fonction submit, vous pouvez utiliser la méthode done() pour déterminer si la tâche est terminée. Comme le montre l'exemple ci-dessus, puisque la tâche a un délai de 2 s, il est jugé immédiatement après la soumission de la tâche 1 que la tâche 1 n'est pas terminée, mais après un délai de 4 s, il est jugé que la tâche 1 est terminée. #🎜🎜##🎜🎜#Utilisez la méthode Cancel() pour annuler la tâche soumise. Si la tâche est déjà en cours d'exécution dans le pool de threads, elle ne peut pas être annulée. Dans cet exemple, la taille du pool de threads est définie sur 2 et la tâche est déjà en cours d'exécution, l'annulation échoue donc. Si vous modifiez la taille du pool de threads à 1, alors la tâche 1 est soumise en premier et la tâche 2 est toujours en attente dans la file d'attente. À ce stade, elle peut être annulée avec succès. #🎜🎜##🎜🎜#Utilisez la méthode result() pour obtenir la valeur de retour de la tâche. En examinant le code interne, nous avons constaté que cette méthode est bloquante. #🎜🎜##🎜🎜#as_completed#🎜🎜##🎜🎜#Bien que ce qui précède fournisse une méthode pour déterminer si la tâche est terminée, elle ne peut pas toujours être déterminée dans le fil de discussion principal. #🎜🎜##🎜🎜# Parfois, lorsque nous savons qu'une tâche est terminée, nous obtenons le résultat au lieu de constamment juger si chaque tâche est terminée. #🎜🎜##🎜🎜#C'est le résultat de l'utilisation de la méthodeas_completed pour récupérer toutes les tâches en même temps. #🎜🎜#rrreee#🎜🎜#La méthode as_completed() est un générateur. Lorsqu'aucune tâche n'est terminée, elle se bloque Lorsqu'une certaine tâche est terminée, elle rendCette tâche peut exécuter l'instruction sous la boucle for, puis continuer à bloquer jusqu'à ce que toutes les tâches soient terminées. #🎜🎜##🎜🎜# Il ressort également des résultats que les #🎜🎜# tâches terminées en premier seront notifiées au fil de discussion principal #🎜🎜# en premier. #🎜🎜#<h4 id="map">map</h4>#🎜🎜#En plus de la méthode <code>as_completed ci-dessus, vous pouvez également utiliser la méthode executor.map, mais là il y a une petite différence. #🎜🎜#rrreee#🎜🎜#Utilisez la méthode map sans utiliser la méthode submit au préalable. La méthode map est la même que <. code>pythonmap dans la bibliothèque standard a la même signification, qui est d'exécuter la même fonction sur chaque élément de la séquence. #🎜🎜##🎜🎜#Le code ci-dessus consiste à exécuter la fonction get_html pour chaque élément des urls et à allouer chaque pool de threads. Vous pouvez voir que le résultat de l'exécution est différent du résultat de la méthode as_completed ci-dessus #🎜🎜#L'ordre de sortie est le même que l'ordre des #🎜🎜#urlscode>#🎜🎜#list#🎜 🎜#, même si la tâche 2s est exécutée en premier, la tâche 3s sera imprimée en premier puis la tâche 2s sera imprimée. #🎜🎜#<h4 id="wait">wait</h4>#🎜🎜#La méthode <code>wait permet au thread principal de se bloquer jusqu'à ce que les exigences définies soient remplies. #🎜🎜#rrreee#🎜🎜#La méthode wait reçoit 3 paramètres, la séquence de tâches en attente, le délai d'attente et les conditions d'attente. #🎜🎜##🎜🎜#La condition d'attente return_when est par défaut ALL_COMPLETED, indiquant que vous souhaitez attendre la fin de toutes les tâches. #🎜🎜##🎜🎜#Vous pouvez voir à partir des résultats en cours d'exécution que toutes les tâches sont effectivement terminées avant que le thread principal n'imprime main. #🎜🎜##🎜🎜#La condition d'attente peut également être définie sur FIRST_COMPLETED, ce qui signifie que l'attente s'arrêtera lorsque la première tâche sera terminée. #🎜🎜##🎜🎜#Analyse du code source#🎜🎜##🎜🎜#cocurrent.futureLe futur dans le module signifie objet futur, qui peut être compris comme #🎜🎜#Une opération réalisée dans le futur#🎜🎜#, qui est la base de la programmation asynchrone. #🎜🎜#Après le pool de threads submit(), l'objet futur est renvoyé. La tâche n'est pas terminée une fois renvoyée, mais le sera dans le futur. submit()之后,返回的就是这个future对象,返回的时候任务并没有完成,但会在将来完成。
也可以称之为task的返回容器,这个里面会存储task的结果和状态。
那ThreadPoolExecutor内部是如何操作这个对象的呢?
下面简单介绍ThreadPoolExecutor的部分代码:
1.init方法
init方法中主要重要的就是任务队列和线程集合,在其他方法中需要使用到。

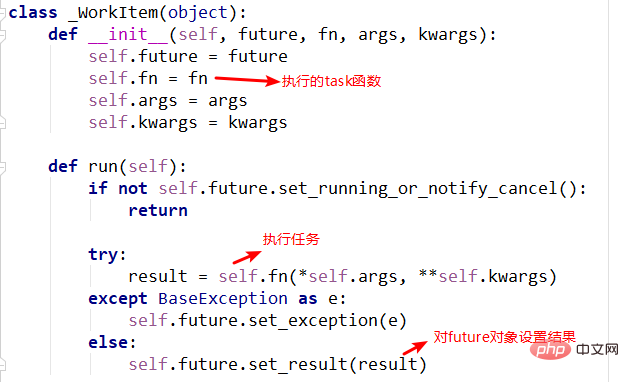
2.submit方法
submit中有两个重要的对象,_base.Future()和_WorkItem()对象,_WorkItem()对象负责运行任务和对future对象进行设置,最后会将future对象返回,可以看到整个过程是立即返回的,没有阻塞。
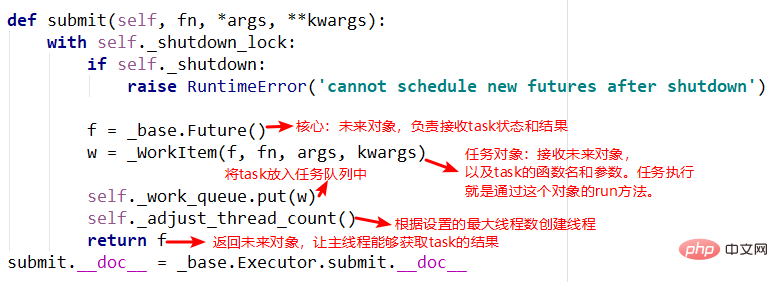
3.adjust_thread_count方法
这个方法的含义很好理解,主要是创建指定的线程数。但是实现上有点难以理解,比如线程执行函数中的weakref.ref,涉及到了弱引用等概念,留待以后理解。
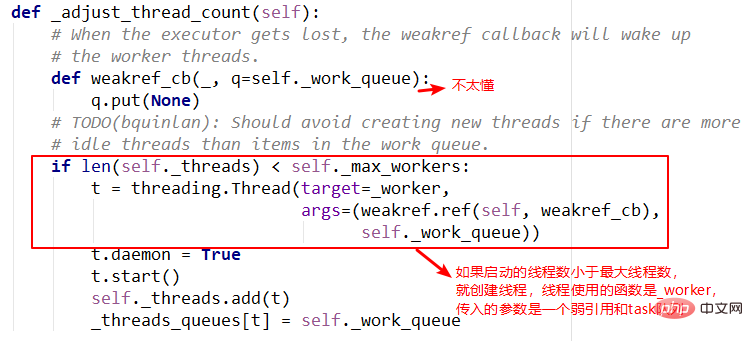
4._WorkItem对象
_WorkItem对象的职责就是执行任务和设置结果。这里面主要复杂的还是self.future.set_result(result) peut également être appelé le conteneur de retour de la tâche, qui stockera les résultats et le statut de task
 Alors, comment
Alors, comment ThreadPoolExecutor fait-il fonctionner cet objet en interne ?
Ce qui suit est une brève introduction à une partie du code de ThreadPoolExecutor :
Méthode 1.init La principale chose importante dans la méthode init est la file d'attente des tâches et la collection de threads, qui sont nécessaires dans d'autres méthodes Utilisé pour.
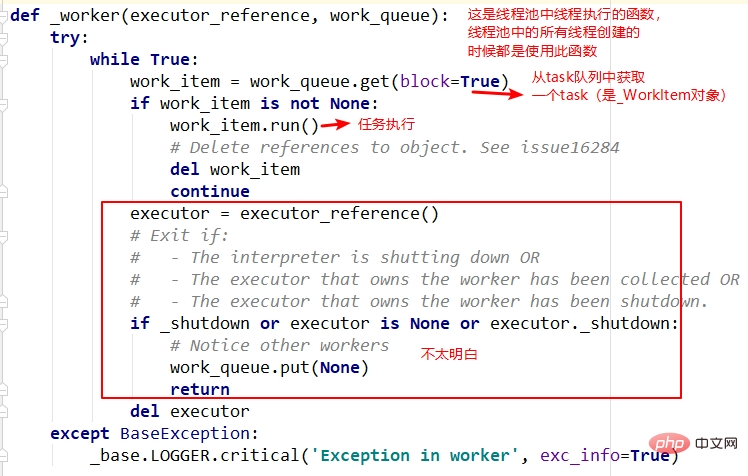
submit, les objets _base.Future() et _WorkItem(), _WorkItem () L'objet est responsable de l'exécution des tâches et de la définition de l'objet future. Enfin, l'objet future sera renvoyé. Vous pouvez voir que l'ensemble du processus est renvoyé. immédiatement sans bloquer. 🎜🎜🎜🎜3 Méthode .adjust_thread_count 🎜🎜La signification de cette méthode est facile à comprendre, elle crée principalement le nombre de threads spécifié. Cependant, l'implémentation est un peu difficile à comprendre.Par exemple, lowref.ref dans la fonction d'exécution de thread implique des concepts tels que les références faibles, qui seront compris plus tard. 🎜🎜🎜🎜4 ._WorkItem La responsabilité de l'objet 🎜🎜_WorkItem est d'effectuer des tâches et de définir des résultats. La principale complexité ici est self.future.set_result(result)🎜. 🎜🎜🎜🎜🎜🎜5. Fonction d'exécution de thread--_worker🎜🎜Il s'agit de l'entrée de fonction spécifiée lorsque le pool de threads crée un thread. Il retire principalement 🎜task🎜 de la file d'attente et l'exécute, mais le premier paramètre du. la fonction n'est pas encore très claire. Laissez ça pour plus tard. 🎜🎜🎜🎜
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 PHP et Python: exemples de code et comparaison
Apr 15, 2025 am 12:07 AM
PHP et Python: exemples de code et comparaison
Apr 15, 2025 am 12:07 AM
PHP et Python ont leurs propres avantages et inconvénients, et le choix dépend des besoins du projet et des préférences personnelles. 1.Php convient au développement rapide et à la maintenance des applications Web à grande échelle. 2. Python domine le domaine de la science des données et de l'apprentissage automatique.
 Comment est la prise en charge du GPU pour Pytorch sur Centos
Apr 14, 2025 pm 06:48 PM
Comment est la prise en charge du GPU pour Pytorch sur Centos
Apr 14, 2025 pm 06:48 PM
Activer l'accélération du GPU Pytorch sur le système CentOS nécessite l'installation de versions CUDA, CUDNN et GPU de Pytorch. Les étapes suivantes vous guideront tout au long du processus: CUDA et CUDNN Installation détermineront la compatibilité de la version CUDA: utilisez la commande NVIDIA-SMI pour afficher la version CUDA prise en charge par votre carte graphique NVIDIA. Par exemple, votre carte graphique MX450 peut prendre en charge CUDA11.1 ou plus. Téléchargez et installez Cudatoolkit: visitez le site officiel de Nvidiacudatoolkit et téléchargez et installez la version correspondante selon la version CUDA la plus élevée prise en charge par votre carte graphique. Installez la bibliothèque CUDNN:
 Explication détaillée du principe docker
Apr 14, 2025 pm 11:57 PM
Explication détaillée du principe docker
Apr 14, 2025 pm 11:57 PM
Docker utilise les fonctionnalités du noyau Linux pour fournir un environnement de fonctionnement d'application efficace et isolé. Son principe de travail est le suivant: 1. Le miroir est utilisé comme modèle en lecture seule, qui contient tout ce dont vous avez besoin pour exécuter l'application; 2. Le Système de fichiers Union (UnionFS) empile plusieurs systèmes de fichiers, ne stockant que les différences, l'économie d'espace et l'accélération; 3. Le démon gère les miroirs et les conteneurs, et le client les utilise pour l'interaction; 4. Les espaces de noms et les CGROUP implémentent l'isolement des conteneurs et les limitations de ressources; 5. Modes de réseau multiples prennent en charge l'interconnexion du conteneur. Ce n'est qu'en comprenant ces concepts principaux que vous pouvez mieux utiliser Docker.
 Comment entraîner le modèle Pytorch sur Centos
Apr 14, 2025 pm 03:03 PM
Comment entraîner le modèle Pytorch sur Centos
Apr 14, 2025 pm 03:03 PM
Une formation efficace des modèles Pytorch sur les systèmes CentOS nécessite des étapes, et cet article fournira des guides détaillés. 1. Préparation de l'environnement: Installation de Python et de dépendance: le système CentOS préinstalle généralement Python, mais la version peut être plus ancienne. Il est recommandé d'utiliser YUM ou DNF pour installer Python 3 et Mettez PIP: sudoyuMupDatePython3 (ou sudodnfupdatepython3), pip3install-upradepip. CUDA et CUDNN (accélération GPU): Si vous utilisez Nvidiagpu, vous devez installer Cudatool
 Python vs JavaScript: communauté, bibliothèques et ressources
Apr 15, 2025 am 12:16 AM
Python vs JavaScript: communauté, bibliothèques et ressources
Apr 15, 2025 am 12:16 AM
Python et JavaScript ont leurs propres avantages et inconvénients en termes de communauté, de bibliothèques et de ressources. 1) La communauté Python est amicale et adaptée aux débutants, mais les ressources de développement frontal ne sont pas aussi riches que JavaScript. 2) Python est puissant dans les bibliothèques de science des données et d'apprentissage automatique, tandis que JavaScript est meilleur dans les bibliothèques et les cadres de développement frontaux. 3) Les deux ont des ressources d'apprentissage riches, mais Python convient pour commencer par des documents officiels, tandis que JavaScript est meilleur avec MDNWEBDOCS. Le choix doit être basé sur les besoins du projet et les intérêts personnels.
 Comment choisir la version Pytorch sous Centos
Apr 14, 2025 pm 02:51 PM
Comment choisir la version Pytorch sous Centos
Apr 14, 2025 pm 02:51 PM
Lors de la sélection d'une version Pytorch sous CentOS, les facteurs clés suivants doivent être pris en compte: 1. CUDA Version Compatibilité GPU Prise en charge: si vous avez NVIDIA GPU et que vous souhaitez utiliser l'accélération GPU, vous devez choisir Pytorch qui prend en charge la version CUDA correspondante. Vous pouvez afficher la version CUDA prise en charge en exécutant la commande nvidia-SMI. Version CPU: Si vous n'avez pas de GPU ou que vous ne souhaitez pas utiliser de GPU, vous pouvez choisir une version CPU de Pytorch. 2. Version Python Pytorch
 Comment faire le prétraitement des données avec Pytorch sur CentOS
Apr 14, 2025 pm 02:15 PM
Comment faire le prétraitement des données avec Pytorch sur CentOS
Apr 14, 2025 pm 02:15 PM
Traitez efficacement les données Pytorch sur le système CentOS, les étapes suivantes sont requises: Installation de dépendance: Mettez d'abord à jour le système et installez Python3 et PIP: sudoyuMupdate-anduhuminstallpython3-ysudoyuminstallpython3-pip-y, téléchargez et installez Cudatoolkit et Cudnn à partir du site officiel de Nvidia selon votre version de Centos et GPU. Configuration de l'environnement virtuel (recommandé): utilisez conda pour créer et activer un nouvel environnement virtuel, par exemple: condacreate-n
 Comment installer nginx dans Centos
Apr 14, 2025 pm 08:06 PM
Comment installer nginx dans Centos
Apr 14, 2025 pm 08:06 PM
CENTOS L'installation de Nginx nécessite de suivre les étapes suivantes: Installation de dépendances telles que les outils de développement, le devet PCRE et l'OpenSSL. Téléchargez le package de code source Nginx, dézippez-le et compilez-le et installez-le, et spécifiez le chemin d'installation AS / USR / LOCAL / NGINX. Créez des utilisateurs et des groupes d'utilisateurs de Nginx et définissez les autorisations. Modifiez le fichier de configuration nginx.conf et configurez le port d'écoute et le nom de domaine / adresse IP. Démarrez le service Nginx. Les erreurs communes doivent être prêtées à prêter attention, telles que les problèmes de dépendance, les conflits de port et les erreurs de fichiers de configuration. L'optimisation des performances doit être ajustée en fonction de la situation spécifique, comme l'activation du cache et l'ajustement du nombre de processus de travail.
