

La plateforme d'apprentissage automatique Alibaba Cloud PAI a collaboré avec l'équipe du professeur Gao Ming de l'Université normale de Chine orientale pour publier le modèle SASA de Transformer d'attention sparse sensible à la structure au SIGIR2022. performances de longues séquences de code, effets et performances. Étant donné que la complexité du module d'auto-attention augmente de façon exponentielle avec la longueur de la séquence, la plupart des modèles de langage pré-entraînés basés sur la programmation (PPLM) utilisent la troncature de séquence pour traiter les séquences de code. La méthode SASA économise le calcul de l'attention personnelle et combine les caractéristiques structurelles du code, améliorant ainsi les performances des tâches à séquence longue et réduisant la mémoire et la complexité de calcul.
Article : Tingting Liu, Chengyu Wang, Cen Chen, Ming Gao et Aoying Zhou. Comprendre les langages de programmation longs avec une attention sparse sensible à la structure
La figure suivante montre le cadre global de SASA. :

Parmi eux, SASA comprend principalement deux étapes : l'étape de prétraitement et l'étape de formation Sparse Transformer. Au cours de l'étape de prétraitement, les matrices d'interaction entre deux jetons sont obtenues, l'une est la matrice de fréquence top-k et l'autre est la matrice de modèle AST. La matrice de fréquence Top-k utilise un modèle de langage pré-entraîné pour apprendre la fréquence d'interaction d'attention entre les jetons du corpus CodeSearchNet. La matrice de modèles AST est un arbre de syntaxe abstraite (AST) qui analyse le code. sur la relation de connexion de l'arbre syntaxique Informations interactives entre les jetons. La phase de formation Sparse Transformer utilise Transformer Encoder comme cadre de base, remplace l'auto-attention complète par une auto-attention clairsemée sensible à la structure et effectue des calculs d'attention entre des paires de jetons conformes à des modèles spécifiques, réduisant ainsi la complexité de calcul.
SASA sparse attention comprend les quatre modules suivants au total :
Afin de s'adapter aux caractéristiques de calcul parallèle du matériel moderne, nous divisons la séquence en plusieurs blocs au lieu de calculer en unités symboliques. Chaque bloc de requête comporte

blocs de fenêtre coulissante et

blocs globaux. et
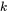
les blocs top-k et AST calculent l'attention. La complexité informatique globale est

b est la taille du bloc.
Chaque modèle d'attention clairsemé correspond à une matrice d'attention. En prenant comme exemple l'attention par fenêtre glissante, le calcul de la matrice d'attention est :

Pseudo-code ASA :

Nous utilisons quatre ensembles de données de tâches fournis par CodeXGLUE[1] pour l'évaluation, à savoir la détection de clone de code, la détection de défauts, la recherche de code et le résumé de code. Nous avons extrait les données dont la longueur de séquence est supérieure à 512 pour former un ensemble de données de séquence longue. Les résultats expérimentaux sont les suivants : Les performances sur cet ensemble de données dépassent largement toutes les lignes de base. Parmi eux, Roberta-base[2], CodeBERT[3] et GraphCodeBERT[4] utilisent la troncature pour traiter de longues séquences, ce qui fera perdre une partie des informations contextuelles. Longformer[5] et BigBird[6] sont des méthodes utilisées pour traiter de longues séquences dans le traitement du langage naturel, mais elles ne prennent pas en compte les caractéristiques structurelles du code et le transfert direct vers la tâche de code n'est pas efficace.
Afin de vérifier l'effet des modules d'attention clairsemée top-k et d'attention clairsemée AST, nous avons mené des expériences d'ablation sur les ensembles de données BigCloneBench et Defect Detection. Les résultats sont les suivants : 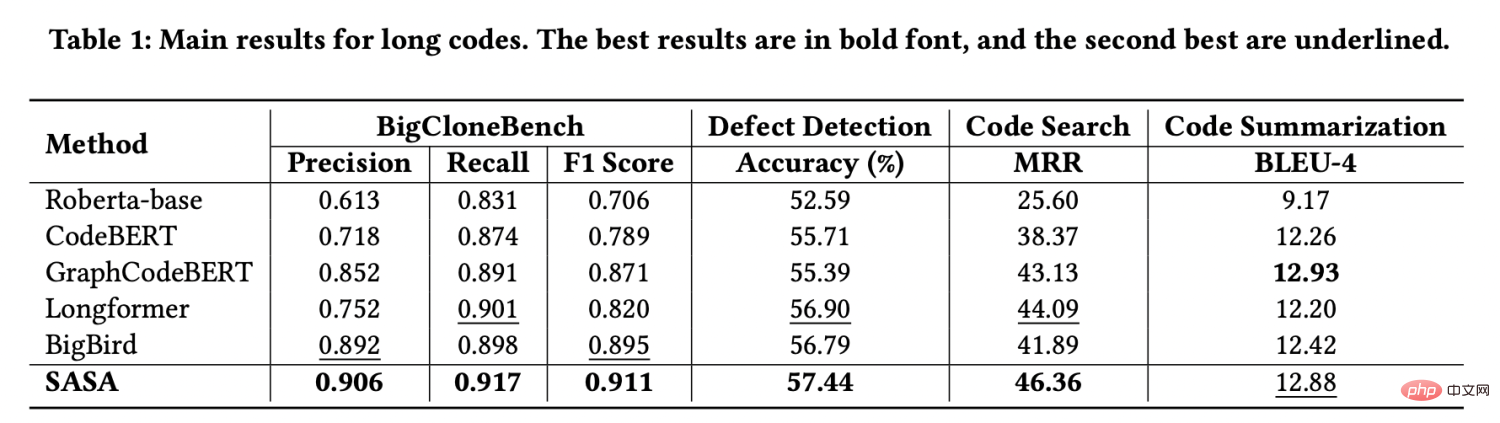 .
.
sparse attention module non seulement améliore les performances des tâches de code long, mais réduit également considérablement l'utilisation de la mémoire vidéo sous le même appareil, SASA peut définir une taille de lot plus grande, tandis que le modèle -attention est confronté au problème du manque de mémoire. L'utilisation spécifique de la mémoire est la suivante :

SASA, en tant que module d'attention clairsemé. , peuvent être migrés vers D'autres modèles pré-entraînés basés sur Transformer sont utilisés pour traiter des tâches de traitement du langage naturel à séquence longue. Ils seront intégrés dans le framework open source EasyNLP (https://github.com/alibaba/EasyNLP) et contribués à. la communauté open source.
Lien papier :  https://arxiv.org/abs/2205.13730
https://arxiv.org/abs/2205.13730
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
















![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



