
 Périphériques technologiques
IA
Résumant les trois dernières années, le MIT publie un document de synthèse sur les accélérateurs d'IA
Périphériques technologiques
IA
Résumant les trois dernières années, le MIT publie un document de synthèse sur les accélérateurs d'IA
Résumant les trois dernières années, le MIT publie un document de synthèse sur les accélérateurs d'IA

Au cours de l'année écoulée, les startups et les entreprises établies ont mis du temps à annoncer, lancer et déployer des accélérateurs d'intelligence artificielle (IA) et d'apprentissage automatique (ML). Mais ce n’est pas déraisonnable, et pour de nombreuses entreprises qui publient des rapports sur les accélérateurs, elles passent trois à quatre ans à rechercher, analyser, concevoir, valider et évaluer la conception de l’accélérateur et à construire la pile technologique pour programmer l’accélérateur. Pour les entreprises qui ont publié des versions améliorées de leurs accélérateurs, les cycles de développement durent encore au moins deux à trois ans, même si elles indiquent qu'ils sont plus courts. L'objectif de ces accélérateurs est toujours d'accélérer les modèles de réseaux neuronaux profonds (DNN). Les scénarios d'application vont de la reconnaissance vocale intégrée à très faible consommation et de la classification d'images à la formation de grands modèles de centres de données. La concurrence sur le marché et les domaines d'application typiques se poursuit. Une partie importante du passage de l’informatique traditionnelle moderne aux solutions d’apprentissage automatique pour les entreprises industrielles et technologiques.
L'écosystème de l'IA rassemble des composants de l'informatique de pointe, du calcul haute performance traditionnel (HPC) et de l'analyse de données haute performance (HPDA) qui doivent fonctionner ensemble pour responsabiliser efficacement les décideurs, le personnel de première ligne et les analyses. Autonomisation des enseignants. La figure 1 montre un aperçu architectural de cette solution d'IA de bout en bout et de ses composants.
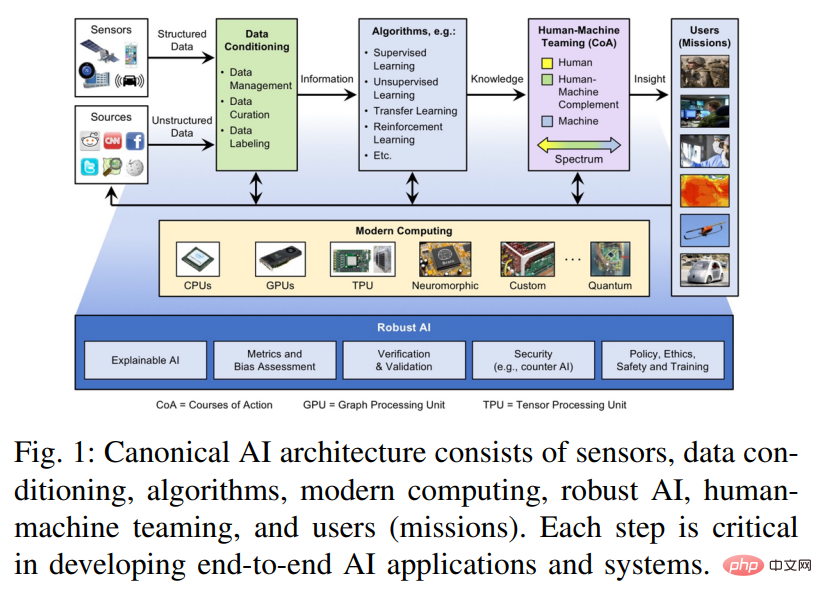
Les données originales doivent d'abord être conservées. Au cours de cette étape, les données sont fusionnées, agrégées, structurées, accumulées et converties en informations. Les informations générées par l'étape de traitement des données servent d'entrée à des algorithmes supervisés ou non supervisés tels que des réseaux de neurones qui extraient des modèles, remplissent les données manquantes ou trouvent des similitudes entre des ensembles de données et font des prédictions, convertissant ainsi les informations d'entrée en connaissances exploitables. Ces connaissances exploitables seront transférées aux humains et utilisées dans le processus de prise de décision lors de la phase de collaboration homme-machine. L’étape de collaboration homme-machine fournit aux utilisateurs des informations utiles et importantes, transformant les connaissances en informations ou informations exploitables.
Ce système repose sur un système informatique moderne. La tendance à la loi de Moore a pris fin, mais en même temps, de nombreuses lois et tendances connexes sont proposées, telles que la loi de Denard (densité de puissance), la fréquence d'horloge, le nombre de cœurs, les instructions par cycle d'horloge et les instructions par Joule (loi de Koomey). Depuis la tendance des systèmes sur puce (SoC) apparue pour la première fois dans les applications automobiles, la robotique et les smartphones, l'innovation continue de progresser grâce au développement et à l'intégration d'accélérateurs de cœurs, de méthodes ou de fonctions couramment utilisés. Ces accélérateurs offrent différents équilibres entre performances et flexibilité fonctionnelle, y compris une explosion d’innovation dans les processeurs et accélérateurs d’apprentissage profond. En lisant un grand nombre d'articles connexes, cet article explore les avantages relatifs de ces technologies, car elles sont particulièrement importantes lors de l'application de l'intelligence artificielle aux systèmes embarqués et aux centres de données qui ont des exigences extrêmes en matière de taille, de poids et de puissance.
Cet article est une mise à jour des articles IEEE-HPEC des trois dernières années. Comme les années précédentes, cet article continue de se concentrer sur les accélérateurs et les processeurs pour les réseaux de neurones profonds (DNN) et les réseaux de neurones convolutifs (CNN), qui sont extrêmement gourmands en calcul. Cet article se concentre sur le développement d’accélérateurs et de processeurs en inférence, car de nombreuses applications Edge IA/ML s’appuient fortement sur l’inférence. Cet article traite de tous les types de précision numérique pris en charge par les accélérateurs, mais pour la plupart des accélérateurs, leurs meilleures performances d'inférence sont int8 ou fp16/bf16 (virgule flottante IEEE 16 bits ou brain float 16 bits de Google).

Lien article : https://arxiv.org/pdf/2210.04055.pdf
À l'heure actuelle, de nombreux articles discutent des accélérateurs d'IA. Par exemple, le premier article de cette série d'enquêtes traite des performances maximales des FPGA pour certains modèles d'IA. Les enquêtes précédentes ont couvert les FPGA en profondeur et ne sont donc plus incluses dans cette enquête. Cet effort d'enquête et cet article en cours visent à collecter une liste complète des accélérateurs d'IA, y compris leurs capacités de calcul, leur efficacité énergétique et leur efficacité de calcul utilisant des accélérateurs dans des applications embarquées et de centres de données. Dans le même temps, l’article compare principalement les accélérateurs de réseaux neuronaux pour les applications gouvernementales et industrielles de capteurs et de traitement de données. Certains accélérateurs et processeurs inclus dans les articles des années précédentes ont été exclus de l'enquête de cette année car ils peuvent avoir été remplacés par de nouveaux accélérateurs de la même entreprise, ne sont plus entretenus ou ne sont plus pertinents pour le sujet.
Enquête sur les processeurs
De nombreuses avancées récentes en matière d'intelligence artificielle sont en partie dues à l'amélioration des performances matérielles, ce qui rend les algorithmes d'apprentissage automatique nécessitant une énorme puissance de calcul, notamment DNN, etc. le réseau peut y parvenir. L'enquête menée pour cet article a rassemblé une variété d'informations provenant de documents accessibles au public, notamment divers documents de recherche, revues techniques, références publiées par les entreprises, etc. Bien qu'il existe d'autres moyens d'obtenir des informations sur les entreprises et les startups (y compris celles en période de silence), cet article omet ces informations au moment de cette enquête et les données seront incluses dans l'enquête lorsqu'elles seront rendues publiques. Les mesures clés de ces données publiques sont présentées dans le graphique ci-dessous, qui reflète les dernières performances maximales du processeur par rapport aux capacités de consommation d'énergie (en juillet 2022).
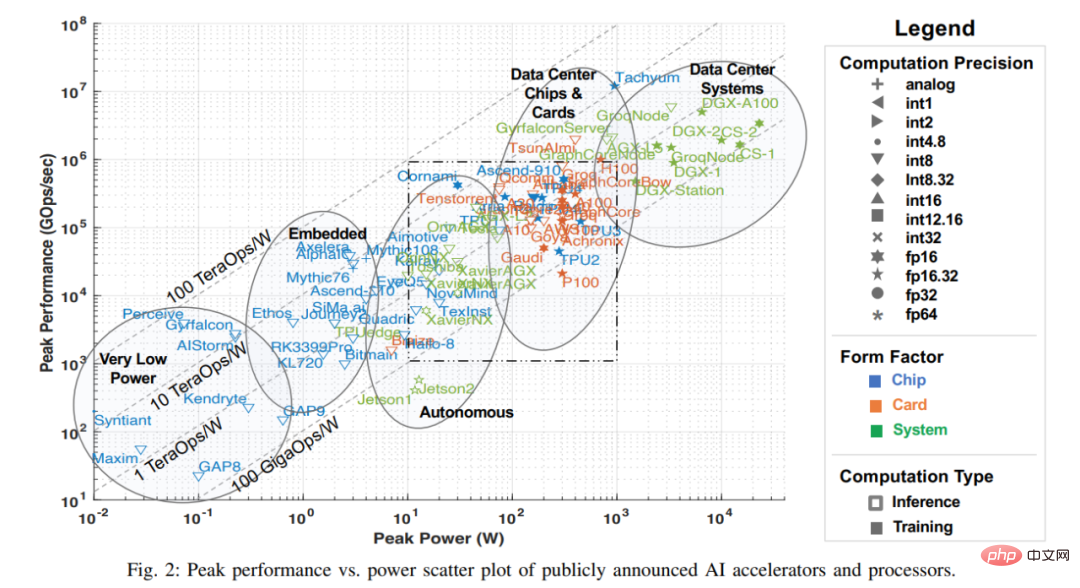
Remarque : La case en pointillés de la figure 2 correspond à la figure 3 ci-dessous. une image agrandie du cadre en pointillés.
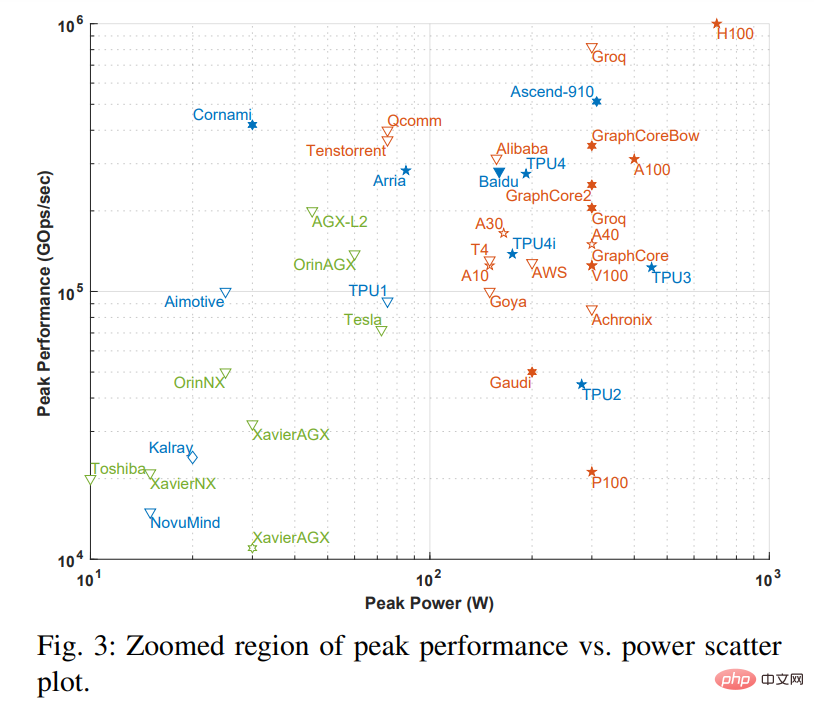
L'axe des x dans la figure représente la puissance maximale et l'axe des y représente le nombre maximal d'opérations gigabit par seconde (GOps/s), tous deux en échelle logarithmique. La précision de calcul de la puissance de traitement est représentée par différentes géométries, allant de int1 à int32 et de fp16 à fp64. Il existe deux types de précision affichés. Le côté gauche représente la précision des opérations de multiplication et le côté droit représente la précision des opérations d'accumulation/addition (telles que fp16.32 représente la multiplication fp16 et l'accumulation/addition fp32). Utilisez des couleurs et des formes pour différencier les différents types de systèmes et la puissance maximale. Le bleu représente une puce unique ; l'orange représente une carte ; le vert représente un système global (systèmes de bureau et de serveur à nœud unique). Cette enquête se limite aux systèmes à carte mère unique et à mémoire unique. Les géométries ouvertes de la figure représentent les performances optimales des accélérateurs qui effectuent uniquement l'inférence, tandis que les géométries solides représentent les performances des accélérateurs qui effectuent à la fois la formation et l'inférence.
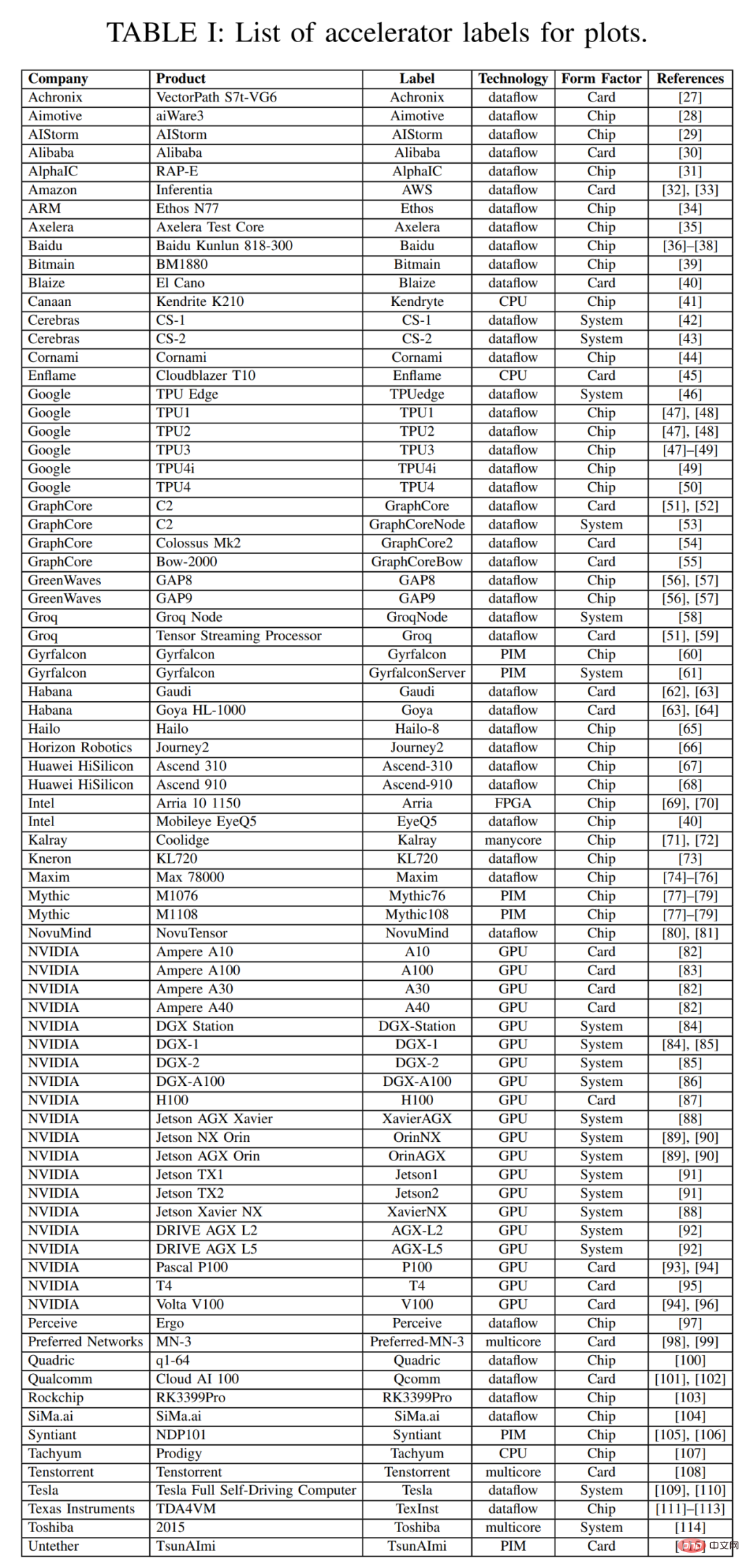
Dans cette enquête, cet article commence par un nuage de points de données d'enquête au cours des trois dernières années. Cet article résume certaines métadonnées importantes pour l'accélérateur, la carte et le système global dans le tableau 1 ci-dessous, y compris les étiquettes pour chaque point de la figure 2, avec de nombreux points tirés de l'enquête de l'année dernière. La plupart des colonnes et entrées du tableau 1 sont précises et claires. Mais deux éléments technologiques ne le sont probablement pas : Dataflow et PIM. Les processeurs de type Dataflow sont des processeurs personnalisés pour l'inférence et la formation de réseaux neuronaux. Étant donné que la formation des réseaux neuronaux et les calculs d'inférence sont construits de manière entièrement déterministe, ils conviennent au traitement des flux de données, où les calculs, les accès à la mémoire et les communications inter-ALU sont programmés explicitement/statiquement ou placés et acheminés vers le matériel de calcul. Les accélérateurs Processor in Memory (PIM) intègrent des éléments de traitement à la technologie de mémoire. Parmi ces accélérateurs PIM figurent ceux basés sur une technologie informatique analogique qui augmente les circuits de mémoire flash avec des fonctions analogiques de multiplication-ajout sur place. Vous pouvez vous référer aux matériaux des accélérateurs Mythic et Gyrfalcon pour plus de détails sur cette technologie innovante.
Cet article classe raisonnablement les accélérateurs en fonction de leurs applications attendues. La figure 1 utilise des ovales pour identifier cinq catégories d'accélérateurs. Correspondance basée sur les performances et la consommation d'énergie : très faible consommation d'énergie, très petits capteurs de traitement de la parole ; caméras embarquées, petits drones et robots ; conduite autonome et robots autonomes ; puces et cartes pour les centres de données ;
Les performances, les fonctionnalités et autres indicateurs de la plupart des accélérateurs n'ont pas changé. Vous pouvez vous référer aux articles des deux dernières années pour obtenir des informations pertinentes. Les accélérateurs suivants n'ont pas été inclus dans les articles précédents.
La startup néerlandaise de systèmes embarqués Acelera affirme que la puce de test intégrée qu'elle produit possède des capacités de conception numérique et analogique, et que cette puce de test est destinée à tester la portée des capacités de conception numérique. Ils espèrent ajouter des éléments de conception analogiques (et éventuellement flash) dans leurs travaux futurs.
Maxim Integrated a lancé un système sur puce (SoC) appelé MAX78000 pour les applications à très faible consommation. Il comprend des cœurs de processeur ARM, des cœurs de processeur RISC-V et des accélérateurs d'IA. Le cœur ARM est utilisé pour le prototypage rapide et la réutilisation du code, tandis que le cœur RISC-V est optimisé pour une consommation d'énergie la plus faible possible. L'accélérateur AI dispose de 64 processeurs parallèles prenant en charge les opérations sur les nombres entiers 1 bit, 2 bits, 4 bits et 8 bits. Le SoC fonctionne à une puissance maximale de 30 mW, ce qui le rend adapté aux applications alimentées par batterie à faible latence.
Tachyum a récemment lancé un processeur tout-en-un appelé Prodigy. Chaque cœur de Prodigy intègre les fonctions CPU et GPU. Il est conçu pour les applications HPC et d'apprentissage automatique. La puce dispose de 128 cœurs unifiés hautes performances et fonctionne de manière simultanée. fréquence de 5,7 GHz.
NVIDIA a lancé son GPU de nouvelle génération appelé Hopper (H100) en mars 2022. Hopper intègre davantage de multiprocesseurs symétriques (cœurs SIMD et Tensor), 50 % de bande passante mémoire en plus et des instances de carte mezzanine SXM d'une puissance de 700 W. (La puissance de la carte PCIe est de 450 W)
Au cours des dernières années, NVIDIA a publié une série de plates-formes système pour les GPU à architecture Ampere déployés dans l'automobile, la robotique et d'autres applications embarquées. Pour les applications automobiles, la plateforme DRIVE AGX ajoute deux nouveaux systèmes : DRIVE AGX L2 permet une conduite autonome de niveau 2 dans la plage de puissance de 45 W, et DRIVE AGX L5 permet une conduite autonome de niveau 5 dans la plage de puissance de 800 W. Jetson AGX Orin et Jetson NX Orin utilisent également des GPU à architecture Ampere pour la robotique, l'automatisation industrielle, etc., et ils ont une puissance de crête maximale de 60 W et 25 W.
Graphcore lance sa puce accélératrice de deuxième génération CG200, qui est déployée sur une carte PCIe et a une puissance maximale d'environ 300W. L'année dernière, Graphcore a également lancé l'accélérateur Bow, le premier processeur wafer-to-wafer conçu en partenariat avec TSMC. L'accélérateur lui-même est le même que celui du CG200 mentionné ci-dessus, mais il est associé à une seconde puce qui améliore considérablement la répartition de la puissance et de l'horloge sur l'ensemble de la puce CG200. Cela représente une amélioration des performances de 40 % et une amélioration des performances par watt de 16 %.
En juin 2021, Google a annoncé les détails de son accélérateur TPU4i d'inférence pure de quatrième génération. Près d'un an plus tard, Google a partagé les détails de son accélérateur de formation de 4e génération, TPUv4. Bien que l'annonce officielle contienne peu de détails, ils ont partagé la puissance de pointe et les chiffres de performances associés. Comme les versions précédentes de TPU, TPU4 est disponible via Google Compute Cloud et utilisé pour les opérations internes.
Ce qui suit est une introduction aux accélérateurs qui n'apparaissent pas dans la figure 2. Chaque version publie des résultats de référence, mais certaines manquent de performances maximales et d'autres ne publient pas de puissance maximale, comme suit.
SambaNova a publié l'année dernière quelques résultats de référence sur la technologie des accélérateurs d'IA reconfigurables. Cette année, il a également publié un certain nombre de technologies connexes et publié des documents d'application en coopération avec le Laboratoire national d'Argonne. Cependant, SambaNova n'a fourni aucun détail. performances ou consommation électrique de leur solution à partir de sources accessibles au public.
En mai de cette année, Intel Habana Labs a annoncé le lancement de l'accélérateur d'inférence Goya de deuxième génération et de l'accélérateur de formation Gaudi, nommés respectivement Greco et Gaudi2. Les deux fonctionnent plusieurs fois mieux que les versions précédentes. La Greco est une carte PCIe simple largeur de 75 W, tandis que la Gaudi2 est également une carte PCIe double largeur de 650 W (probablement sur un emplacement PCIe 5.0). Habana a publié quelques comparaisons de référence de Gaudi2 avec le GPU Nvidia A100, mais n'a pas divulgué de chiffres de performances maximales pour l'un ou l'autre des accélérateurs.
Esperanto a produit des puces de démonstration que Samsung et d'autres partenaires peuvent évaluer. La puce est un processeur RISC-V à 1 000 cœurs avec un accélérateur tenseur IA par cœur. Esperanto a publié quelques chiffres de performances, mais ils ne divulguent pas de puissance ou de performances maximales.
Lors du Tesla AI Day, Tesla a présenté son accélérateur Dojo personnalisé et quelques détails du système. Leurs puces ont des performances maximales de 22,6 TF FP32, mais la consommation électrique maximale de chaque puce n'a pas été annoncée, peut-être que ces détails seront révélés à une date ultérieure.
L'année dernière, Centaur Technology a lancé un processeur x86 avec un accélérateur d'IA intégré, doté d'une unité SIMD de 4 096 octets de large et offrant des performances très compétitives. Mais la société mère de Centaur, VIA Technologies, semble avoir mis fin au développement des processeurs CNS après avoir vendu son équipe d'ingénierie de processeurs basée aux États-Unis à Intel.
Quelques observations et tendances
Il y a plusieurs observations qui méritent d'être mentionnées dans la figure 2, les détails sont les suivants.
Int8 reste la précision numérique par défaut pour les applications d'inférence intégrées, autonomes et de centre de données. Cette précision est suffisante pour la plupart des applications d'IA/ML qui utilisent des nombres rationnels. Certains accélérateurs utilisent également fp16 ou bf16. La formation du modèle utilise une représentation entière.
En plus de l'accélérateur pour l'apprentissage automatique, aucune autre fonction supplémentaire n'a été trouvée dans la puce à très faible consommation. Dans les catégories des puces à très faible consommation et des composants embarqués, il est courant de lancer des solutions de systèmes sur puce (SoC), comprenant souvent des cœurs de processeur à faible consommation, des convertisseurs analogique-numérique (ADC) audio et vidéo, des moteurs cryptographiques. , interfaces réseau, etc. Ces fonctionnalités supplémentaires du SoC ne modifient pas les mesures de performances maximales, mais elles ont un impact direct sur la puissance maximale signalée par la puce, c'est donc important lors de leur comparaison.
La partie embarquée n'a pas beaucoup changé, ce qui signifie que les performances de calcul et la puissance crête sont suffisantes pour répondre aux besoins des applications dans ce domaine.
Plusieurs entreprises, dont Texas Instruments, ont lancé des accélérateurs d'IA au cours des dernières années. Et NVIDIA a également publié des systèmes plus performants pour les applications automobiles et robotiques, comme mentionné précédemment. Dans le data center, la spécification PCIe v5 est très attendue afin de dépasser la limite de puissance de 300 W du PCIe v4.
Enfin, non seulement les systèmes de formation haut de gamme génèrent des performances impressionnantes, mais ces entreprises lancent également une technologie d'interconnexion hautement évolutive pour connecter des milliers de cartes entre elles. Ceci est particulièrement important pour les accélérateurs de flux de données tels que Cerebras, GraphCore, Groq, Tesla Dojo et SambaNova, qui sont programmés via une programmation explicite/statique ou par placement et acheminement sur le matériel informatique. De cette façon, cela permet à ces accélérateurs de s’adapter à de très grands modèles comme des transformateurs.
Veuillez vous référer à l'article original pour plus de détails.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Bytedance Cutting lance le super abonnement SVIP : 499 yuans pour un abonnement annuel continu, offrant une variété de fonctions d'IA
Jun 28, 2024 am 03:51 AM
Bytedance Cutting lance le super abonnement SVIP : 499 yuans pour un abonnement annuel continu, offrant une variété de fonctions d'IA
Jun 28, 2024 am 03:51 AM
Ce site a rapporté le 27 juin que Jianying est un logiciel de montage vidéo développé par FaceMeng Technology, une filiale de ByteDance. Il s'appuie sur la plateforme Douyin et produit essentiellement du contenu vidéo court pour les utilisateurs de la plateforme. Il est compatible avec iOS, Android et. Windows, MacOS et autres systèmes d'exploitation. Jianying a officiellement annoncé la mise à niveau de son système d'adhésion et a lancé un nouveau SVIP, qui comprend une variété de technologies noires d'IA, telles que la traduction intelligente, la mise en évidence intelligente, l'emballage intelligent, la synthèse humaine numérique, etc. En termes de prix, les frais mensuels pour le clipping SVIP sont de 79 yuans, les frais annuels sont de 599 yuans (attention sur ce site : équivalent à 49,9 yuans par mois), l'abonnement mensuel continu est de 59 yuans par mois et l'abonnement annuel continu est de 59 yuans par mois. est de 499 yuans par an (équivalent à 41,6 yuans par mois) . En outre, le responsable de Cut a également déclaré que afin d'améliorer l'expérience utilisateur, ceux qui se sont abonnés au VIP d'origine
 Assistant de codage d'IA augmenté par le contexte utilisant Rag et Sem-Rag
Jun 10, 2024 am 11:08 AM
Assistant de codage d'IA augmenté par le contexte utilisant Rag et Sem-Rag
Jun 10, 2024 am 11:08 AM
Améliorez la productivité, l’efficacité et la précision des développeurs en intégrant une génération et une mémoire sémantique améliorées par la récupération dans les assistants de codage IA. Traduit de EnhancingAICodingAssistantswithContextUsingRAGandSEM-RAG, auteur JanakiramMSV. Bien que les assistants de programmation d'IA de base soient naturellement utiles, ils ne parviennent souvent pas à fournir les suggestions de code les plus pertinentes et les plus correctes, car ils s'appuient sur une compréhension générale du langage logiciel et des modèles d'écriture de logiciels les plus courants. Le code généré par ces assistants de codage est adapté à la résolution des problèmes qu’ils sont chargés de résoudre, mais n’est souvent pas conforme aux normes, conventions et styles de codage des équipes individuelles. Cela aboutit souvent à des suggestions qui doivent être modifiées ou affinées pour que le code soit accepté dans l'application.
 Sept questions d'entretien technique Cool GenAI et LLM
Jun 07, 2024 am 10:06 AM
Sept questions d'entretien technique Cool GenAI et LLM
Jun 07, 2024 am 10:06 AM
Pour en savoir plus sur l'AIGC, veuillez visiter : 51CTOAI.x Community https://www.51cto.com/aigc/Translator|Jingyan Reviewer|Chonglou est différent de la banque de questions traditionnelle que l'on peut voir partout sur Internet. nécessite de sortir des sentiers battus. Les grands modèles linguistiques (LLM) sont de plus en plus importants dans les domaines de la science des données, de l'intelligence artificielle générative (GenAI) et de l'intelligence artificielle. Ces algorithmes complexes améliorent les compétences humaines et stimulent l’efficacité et l’innovation dans de nombreux secteurs, devenant ainsi la clé permettant aux entreprises de rester compétitives. LLM a un large éventail d'applications. Il peut être utilisé dans des domaines tels que le traitement du langage naturel, la génération de texte, la reconnaissance vocale et les systèmes de recommandation. En apprenant de grandes quantités de données, LLM est capable de générer du texte
 Le réglage fin peut-il vraiment permettre au LLM d'apprendre de nouvelles choses : l'introduction de nouvelles connaissances peut amener le modèle à produire davantage d'hallucinations
Jun 11, 2024 pm 03:57 PM
Le réglage fin peut-il vraiment permettre au LLM d'apprendre de nouvelles choses : l'introduction de nouvelles connaissances peut amener le modèle à produire davantage d'hallucinations
Jun 11, 2024 pm 03:57 PM
Les grands modèles linguistiques (LLM) sont formés sur d'énormes bases de données textuelles, où ils acquièrent de grandes quantités de connaissances du monde réel. Ces connaissances sont intégrées à leurs paramètres et peuvent ensuite être utilisées en cas de besoin. La connaissance de ces modèles est « réifiée » en fin de formation. À la fin de la pré-formation, le modèle arrête effectivement d’apprendre. Alignez ou affinez le modèle pour apprendre à exploiter ces connaissances et répondre plus naturellement aux questions des utilisateurs. Mais parfois, la connaissance du modèle ne suffit pas, et bien que le modèle puisse accéder à du contenu externe via RAG, il est considéré comme bénéfique de l'adapter à de nouveaux domaines grâce à un réglage fin. Ce réglage fin est effectué à l'aide de la contribution d'annotateurs humains ou d'autres créations LLM, où le modèle rencontre des connaissances supplémentaires du monde réel et les intègre.
 Afin de fournir un nouveau système de référence et d'évaluation de questions-réponses scientifiques et complexes pour les grands modèles, l'UNSW, Argonne, l'Université de Chicago et d'autres institutions ont lancé conjointement le cadre SciQAG.
Jul 25, 2024 am 06:42 AM
Afin de fournir un nouveau système de référence et d'évaluation de questions-réponses scientifiques et complexes pour les grands modèles, l'UNSW, Argonne, l'Université de Chicago et d'autres institutions ont lancé conjointement le cadre SciQAG.
Jul 25, 2024 am 06:42 AM
L'ensemble de données ScienceAI Question Answering (QA) joue un rôle essentiel dans la promotion de la recherche sur le traitement du langage naturel (NLP). Des ensembles de données d'assurance qualité de haute qualité peuvent non seulement être utilisés pour affiner les modèles, mais également évaluer efficacement les capacités des grands modèles linguistiques (LLM), en particulier la capacité à comprendre et à raisonner sur les connaissances scientifiques. Bien qu’il existe actuellement de nombreux ensembles de données scientifiques d’assurance qualité couvrant la médecine, la chimie, la biologie et d’autres domaines, ces ensembles de données présentent encore certaines lacunes. Premièrement, le formulaire de données est relativement simple, et la plupart sont des questions à choix multiples. Elles sont faciles à évaluer, mais limitent la plage de sélection des réponses du modèle et ne peuvent pas tester pleinement la capacité du modèle à répondre aux questions scientifiques. En revanche, les questions et réponses ouvertes
 Cinq écoles d'apprentissage automatique que vous ne connaissez pas
Jun 05, 2024 pm 08:51 PM
Cinq écoles d'apprentissage automatique que vous ne connaissez pas
Jun 05, 2024 pm 08:51 PM
L'apprentissage automatique est une branche importante de l'intelligence artificielle qui donne aux ordinateurs la possibilité d'apprendre à partir de données et d'améliorer leurs capacités sans être explicitement programmés. L'apprentissage automatique a un large éventail d'applications dans divers domaines, de la reconnaissance d'images et du traitement du langage naturel aux systèmes de recommandation et à la détection des fraudes, et il change notre façon de vivre. Il existe de nombreuses méthodes et théories différentes dans le domaine de l'apprentissage automatique, parmi lesquelles les cinq méthodes les plus influentes sont appelées les « Cinq écoles d'apprentissage automatique ». Les cinq grandes écoles sont l’école symbolique, l’école connexionniste, l’école évolutionniste, l’école bayésienne et l’école analogique. 1. Le symbolisme, également connu sous le nom de symbolisme, met l'accent sur l'utilisation de symboles pour le raisonnement logique et l'expression des connaissances. Cette école de pensée estime que l'apprentissage est un processus de déduction inversée, à travers les connaissances existantes.
 Les performances de SOTA, la méthode d'IA de prédiction d'affinité protéine-ligand multimodale de Xiamen, combinent pour la première fois des informations sur la surface moléculaire
Jul 17, 2024 pm 06:37 PM
Les performances de SOTA, la méthode d'IA de prédiction d'affinité protéine-ligand multimodale de Xiamen, combinent pour la première fois des informations sur la surface moléculaire
Jul 17, 2024 pm 06:37 PM
Editeur | KX Dans le domaine de la recherche et du développement de médicaments, il est crucial de prédire avec précision et efficacité l'affinité de liaison des protéines et des ligands pour le criblage et l'optimisation des médicaments. Cependant, les études actuelles ne prennent pas en compte le rôle important des informations sur la surface moléculaire dans les interactions protéine-ligand. Sur cette base, des chercheurs de l'Université de Xiamen ont proposé un nouveau cadre d'extraction de caractéristiques multimodales (MFE), qui combine pour la première fois des informations sur la surface des protéines, la structure et la séquence 3D, et utilise un mécanisme d'attention croisée pour comparer différentes modalités. alignement. Les résultats expérimentaux démontrent que cette méthode atteint des performances de pointe dans la prédiction des affinités de liaison protéine-ligand. De plus, les études d’ablation démontrent l’efficacité et la nécessité des informations sur la surface des protéines et de l’alignement des caractéristiques multimodales dans ce cadre. Les recherches connexes commencent par "S
 Préparant des marchés tels que l'IA, GlobalFoundries acquiert la technologie du nitrure de gallium de Tagore Technology et les équipes associées
Jul 15, 2024 pm 12:21 PM
Préparant des marchés tels que l'IA, GlobalFoundries acquiert la technologie du nitrure de gallium de Tagore Technology et les équipes associées
Jul 15, 2024 pm 12:21 PM
Selon les informations de ce site Web du 5 juillet, GlobalFoundries a publié un communiqué de presse le 1er juillet de cette année, annonçant l'acquisition de la technologie de nitrure de gallium (GaN) et du portefeuille de propriété intellectuelle de Tagore Technology, dans l'espoir d'élargir sa part de marché dans l'automobile et Internet. des objets et des domaines d'application des centres de données d'intelligence artificielle pour explorer une efficacité plus élevée et de meilleures performances. Alors que des technologies telles que l’intelligence artificielle générative (GenerativeAI) continuent de se développer dans le monde numérique, le nitrure de gallium (GaN) est devenu une solution clé pour une gestion durable et efficace de l’énergie, notamment dans les centres de données. Ce site Web citait l'annonce officielle selon laquelle, lors de cette acquisition, l'équipe d'ingénierie de Tagore Technology rejoindrait GF pour développer davantage la technologie du nitrure de gallium. g
