

Prévision des ventes à l'aide de LSTM (code Python)


Nous rencontrons souvent des scénarios qui nécessitent des prédictions, tels que la prévision des ventes de marques et la prévision des ventes de produits.
Aujourd'hui, j'aimerais partager avec vous un code complet et une explication détaillée de l'utilisation de LSTM pour la prédiction de séries chronologiques de bout en bout.
Commençons par comprendre deux sujets :
- Qu'est-ce que l'analyse de séries chronologiques ?
- Qu'est-ce que le LSTM ?
Analyse des séries chronologiques : les séries chronologiques représentent une série de données basées sur l'ordre chronologique. Cela peut être des secondes, des minutes, des heures, des jours, des semaines, des mois, des années. Les données futures dépendront de leur valeur précédente.
Dans les cas du monde réel, nous avons principalement deux types d'analyse de séries chronologiques :
- Séries temporelles univariées
- Séries temporelles multivariées
Pour les données de séries chronologiques univariées, nous utiliserons une seule colonne pour faire des prédictions.
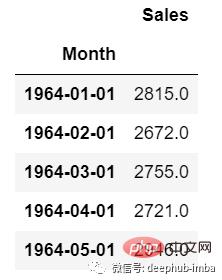
Comme nous pouvons le voir, il n'y a qu'une seule colonne donc la valeur future à venir ne dépendra que de sa valeur précédente.
Mais dans le cas de données de séries chronologiques multivariées, il y aura différents types de valeurs de caractéristiques et les données cibles dépendront de ces caractéristiques.
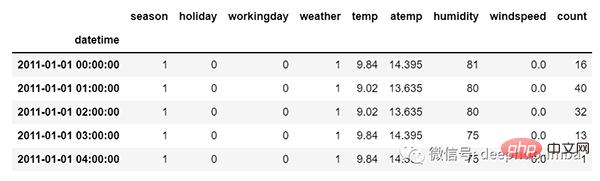
Comme vous pouvez le voir sur l'image, il y aura plusieurs colonnes dans la variable multivariée pour prédire la valeur cible. ("count" dans l'image ci-dessus est la valeur cible)
Dans les données ci-dessus, le nombre dépend non seulement de sa valeur précédente, mais dépend également d'autres caractéristiques. Par conséquent, pour prédire la valeur de comptage à venir, nous devons considérer toutes les colonnes, y compris la colonne cible, pour faire une prédiction pour la valeur cible.
Une chose doit être rappelée lors de l'analyse de séries chronologiques multivariées, nous devons prédire la cible actuelle en utilisant plusieurs fonctionnalités, comprenons à travers un exemple :
Au moment de la formation, si nous utilisons 5 colonnes [feature1 , feature2, feature3, feature4, target] pour entraîner le modèle, nous devons fournir 4 colonnes [feature1, feature2, feature3, feature4] pour le prochain jour de prédiction.
LSTM
Nous n'allons pas discuter du LSTM en détail dans cet article. Je ne fournis donc que quelques descriptions simples. Si vous ne savez pas grand-chose sur LSTM, vous pouvez vous référer à nos articles précédents.
LSTM est essentiellement un réseau neuronal récurrent capable de gérer les dépendances à long terme.
Supposons que vous regardiez un film. Ainsi, quand quelque chose se passe dans le film, vous savez déjà ce qui s’est passé auparavant et vous comprenez que quelque chose de nouveau se produit à cause de ce qui s’est passé dans le passé. Les RNN fonctionnent de la même manière, ils se souviennent des informations passées et les utilisent pour traiter les entrées actuelles. Le problème avec les RNN est qu’ils ne peuvent pas se souvenir des dépendances à long terme en raison de la disparition des gradients. Lstm a donc été conçu pour éviter les problèmes de dépendance à long terme.
Maintenant, nous avons discuté de la partie prévision des séries chronologiques et théorie LSTM. Commençons à coder.
Importons d'abord les bibliothèques nécessaires pour faire des prédictions :
import numpy as np import pandas as pd from matplotlib import pyplot as plt from tensorflow.keras.models import Sequential from tensorflow.keras.layers import LSTM from tensorflow.keras.layers import Dense, Dropout from sklearn.preprocessing import MinMaxScaler from keras.wrappers.scikit_learn import KerasRegressor from sklearn.model_selection import GridSearchCV
Chargez les données et vérifions le résultat :
df=pd.read_csv("train.csv",parse_dates=["Date"],index_col=[0])
df.head()
df.tail()
Prenons maintenant un moment pour regarder les données : Le fichier csv contient Données Google Stock du 25/01/2001 au 29/09/2021, les données sont basées sur la fréquence des jours.
[Vous pouvez convertir la fréquence en "B" [jour ouvrable] ou "D" si vous le souhaitez, puisque nous n'utiliserons pas de dates, je la garde telle quelle. ]
Ici, nous essayons de prédire la valeur future de la colonne "Open", donc "Open" est la colonne cible ici.
Jetons un coup d'œil à la forme des données :
df.shape (5203,5)
Faisons maintenant la répartition train-test. Ici, nous ne pouvons pas mélanger les données car elles doivent être séquentielles dans des séries chronologiques.
test_split=round(len(df)*0.20) df_for_training=df[:-1041] df_for_testing=df[-1041:] print(df_for_training.shape) print(df_for_testing.shape) (4162, 5) (1041, 5)
Vous pouvez remarquer que la plage de données est très large et qu'elles ne sont pas mises à l'échelle dans la même plage, donc pour éviter les erreurs de prédiction, mettons d'abord à l'échelle les données à l'aide de MinMaxScaler. (Vous pouvez également utiliser StandardScaler)
scaler = MinMaxScaler(feature_range=(0,1)) df_for_training_scaled = scaler.fit_transform(df_for_training) df_for_testing_scaled=scaler.transform(df_for_testing) df_for_training_scaled

Divisez les données en X et Y, c'est la partie la plus importante, lisez chaque étape correctement.
def createXY(dataset,n_past): dataX = [] dataY = [] for i in range(n_past, len(dataset)): dataX.append(dataset[i - n_past:i, 0:dataset.shape[1]]) dataY.append(dataset[i,0]) return np.array(dataX),np.array(dataY) trainX,trainY=createXY(df_for_training_scaled,30) testX,testY=createXY(df_for_testing_scaled,30)
Voyons ce qui est fait dans le code ci-dessus :
N_past est le nombre d'étapes que nous examinerons dans le passé pour prédire la prochaine valeur cible.
Utiliser 30 ici signifie que les 30 dernières valeurs (toutes les caractéristiques, y compris la colonne cible) seront utilisées pour prédire la 31ème valeur cible.
因此,在trainX中我们会有所有的特征值,而在trainY中我们只有目标值。
让我们分解for循环的每一部分:
对于训练,dataset = df_for_training_scaled, n_past=30
当i= 30:
data_X.addend (df_for_training_scaled[i - n_past:i, 0:df_for_training.shape[1]])
从n_past开始的范围是30,所以第一次数据范围将是-[30 - 30,30,0:5] 相当于 [0:30,0:5]
因此在dataX列表中,df_for_training_scaled[0:30,0:5]数组将第一次出现。
现在, dataY.append(df_for_training_scaled[i,0])
i = 30,所以它将只取第30行开始的open(因为在预测中,我们只需要open列,所以列范围仅为0,表示open列)。
第一次在dataY列表中存储df_for_training_scaled[30,0]值。
所以包含5列的前30行存储在dataX中,只有open列的第31行存储在dataY中。然后我们将dataX和dataY列表转换为数组,它们以数组格式在LSTM中进行训练。
我们来看看形状。
print("trainX Shape-- ",trainX.shape)
print("trainY Shape-- ",trainY.shape)
(4132, 30, 5)
(4132,)
print("testX Shape-- ",testX.shape)
print("testY Shape-- ",testY.shape)
(1011, 30, 5)
(1011,)4132 是 trainX 中可用的数组总数,每个数组共有 30 行和 5 列, 在每个数组的 trainY 中,我们都有下一个目标值来训练模型。
让我们看一下包含来自 trainX 的 (30,5) 数据的数组之一 和 trainX 数组的 trainY 值:
print("trainX[0]-- n",trainX[0])
print("trainY[0]-- ",trainY[0])
如果查看 trainX[1] 值,会发现到它与 trainX[0] 中的数据相同(第一列除外),因为我们将看到前 30 个来预测第 31 列,在第一次预测之后它会自动移动 到第 2 列并取下一个 30 值来预测下一个目标值。
让我们用一种简单的格式来解释这一切:
trainX — — →trainY [0 : 30,0:5] → [30,0] [1:31, 0:5] → [31,0] [2:32,0:5] →[32,0]
像这样,每个数据都将保存在 trainX 和 trainY 中。
现在让我们训练模型,我使用 girdsearchCV 进行一些超参数调整以找到基础模型。
def build_model(optimizer):
grid_model = Sequential()
grid_model.add(LSTM(50,return_sequences=True,input_shape=(30,5)))
grid_model.add(LSTM(50))
grid_model.add(Dropout(0.2))
grid_model.add(Dense(1))
grid_model.compile(loss = 'mse',optimizer = optimizer)
return grid_modelgrid_model = KerasRegressor(build_fn=build_model,verbose=1,validation_data=(testX,testY))
parameters = {'batch_size' : [16,20],
'epochs' : [8,10],
'optimizer' : ['adam','Adadelta'] }
grid_search = GridSearchCV(estimator = grid_model,
param_grid = parameters,
cv = 2)如果你想为你的模型做更多的超参数调整,也可以添加更多的层。但是如果数据集非常大建议增加 LSTM 模型中的时期和单位。
在第一个 LSTM 层中看到输入形状为 (30,5)。它来自 trainX 形状。
(trainX.shape[1],trainX.shape[2]) → (30,5)
现在让我们将模型拟合到 trainX 和 trainY 数据中。
grid_search = grid_search.fit(trainX,trainY)
由于进行了超参数搜索,所以这将需要一些时间来运行。
你可以看到损失会像这样减少:
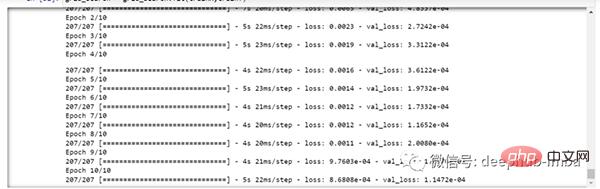
现在让我们检查模型的最佳参数。
grid_search.best_params_
{‘batch_size’: 20, ‘epochs’: 10, ‘optimizer’: ‘adam’}将最佳模型保存在 my_model 变量中。
my_model=grid_search.best_estimator_.model
现在可以用测试数据集测试模型。
prediction=my_model.predict(testX)
print("predictionn", prediction)
print("nPrediction Shape-",prediction.shape)
testY 和 prediction 的长度是一样的。现在可以将 testY 与预测进行比较。
但是我们一开始就对数据进行了缩放,所以首先我们必须做一些逆缩放过程。
scaler.inverse_transform(prediction)
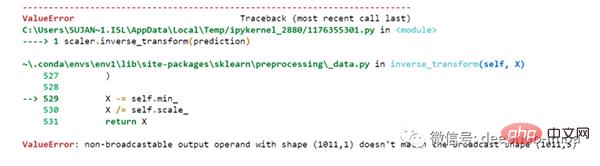
报错了,这是因为在缩放数据时,我们每行有 5 列,现在我们只有 1 列是目标列。
所以我们必须改变形状来使用 inverse_transform:
prediction_copies_array = np.repeat(prediction,5, axis=-1)

5 列值是相似的,它只是将单个预测列复制了 4 次。所以现在我们有 5 列相同的值 。
prediction_copies_array.shape (1011,5)
这样就可以使用 inverse_transform 函数。
pred=scaler.inverse_transform(np.reshape(prediction_copies_array,(len(prediction),5)))[:,0]
但是逆变换后的第一列是我们需要的,所以我们在最后使用了 → [:,0]。
现在将这个 pred 值与 testY 进行比较,但是 testY 也是按比例缩放的,也需要使用与上述相同的代码进行逆变换。
original_copies_array = np.repeat(testY,5, axis=-1) original=scaler.inverse_transform(np.reshape(original_copies_array,(len(testY),5)))[:,0]
现在让我们看一下预测值和原始值:
print("Pred Values-- " ,pred)
print("nOriginal Values-- " ,original)
最后绘制一个图来对比我们的 pred 和原始数据。
plt.plot(original, color = 'red', label = 'Real Stock Price')
plt.plot(pred, color = 'blue', label = 'Predicted Stock Price')
plt.title('Stock Price Prediction')
plt.xlabel('Time')
plt.ylabel('Google Stock Price')
plt.legend()
plt.show()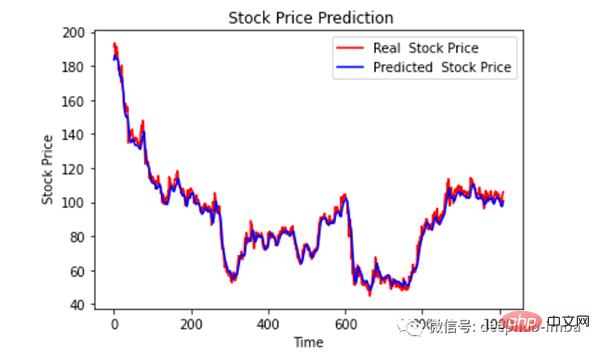
看样子还不错,到目前为止,我们训练了模型并用测试值检查了该模型。现在让我们预测一些未来值。
从主 df 数据集中获取我们在开始时加载的最后 30 个值[为什么是 30?因为这是我们想要的过去值的数量,来预测第 31 个值]
df_30_days_past=df.iloc[-30:,:] df_30_days_past.tail()
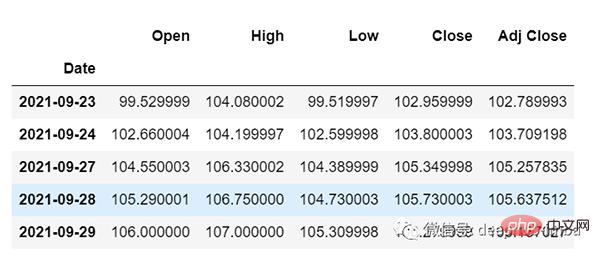
可以看到有包括目标列(“Open”)在内的所有列。现在让我们预测未来的 30 个值。
在多元时间序列预测中,需要通过使用不同的特征来预测单列,所以在进行预测时我们需要使用特征值(目标列除外)来进行即将到来的预测。
这里我们需要“High”、“Low”、“Close”、“Adj Close”列的即将到来的 30 个值来对“Open”列进行预测。
df_30_days_future=pd.read_csv("test.csv",parse_dates=["Date"],index_col=[0])
df_30_days_future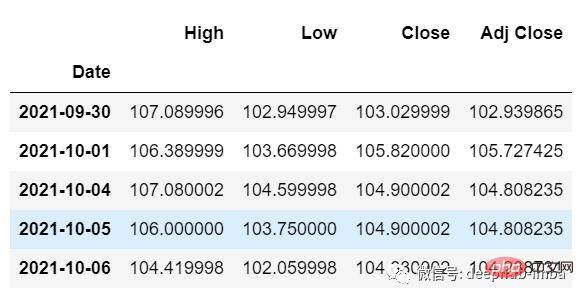
剔除“Open”列后,使用模型进行预测之前还需要做以下的操作:
缩放数据,因为删除了‘Open’列,在缩放它之前,添加一个所有值都为“0”的Open列。
缩放后,将未来数据中的“Open”列值替换为“nan”
现在附加 30 天旧值和 30 天新值(其中最后 30 个“打开”值是 nan)
df_30_days_future["Open"]=0 df_30_days_future=df_30_days_future[["Open","High","Low","Close","Adj Close"]] old_scaled_array=scaler.transform(df_30_days_past) new_scaled_array=scaler.transform(df_30_days_future) new_scaled_df=pd.DataFrame(new_scaled_array) new_scaled_df.iloc[:,0]=np.nan full_df=pd.concat([pd.DataFrame(old_scaled_array),new_scaled_df]).reset_index().drop(["index"],axis=1)
full_df 形状是 (60,5),最后第一列有 30 个 nan 值。
要进行预测必须再次使用 for 循环,我们在拆分 trainX 和 trainY 中的数据时所做的。但是这次我们只有 X,没有 Y 值。
full_df_scaled_array=full_df.values all_data=[] time_step=30 for i in range(time_step,len(full_df_scaled_array)): data_x=[] data_x.append( full_df_scaled_array[i-time_step :i , 0:full_df_scaled_array.shape[1]]) data_x=np.array(data_x) prediction=my_model.predict(data_x) all_data.append(prediction) full_df.iloc[i,0]=prediction
对于第一个预测,有之前的 30 个值,当 for 循环第一次运行时它会检查前 30 个值并预测第 31 个“Open”数据。
当第二个 for 循环将尝试运行时,它将跳过第一行并尝试获取下 30 个值 [1:31] 。这里会报错错误因为Open列最后一行是 “nan”,所以需要每次都用预测替换“nan”。
最后还需要对预测进行逆变换:
new_array=np.array(all_data) new_array=new_array.reshape(-1,1) prediction_copies_array = np.repeat(new_array,5, axis=-1) y_pred_future_30_days = scaler.inverse_transform(np.reshape(prediction_copies_array,(len(new_array),5)))[:,0] print(y_pred_future_30_days)
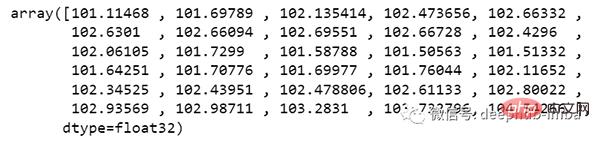
这样一个完整的流程就已经跑通了。
如果你想看完整的代码,可以在这里查看:
https://www.php.cn/link/dd95829de39fe21f384685c07a1628d8
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Comment les plumes PS contrôlent-elles la douceur de la transition?
Apr 06, 2025 pm 07:33 PM
Comment les plumes PS contrôlent-elles la douceur de la transition?
Apr 06, 2025 pm 07:33 PM
La clé du contrôle des plumes est de comprendre sa nature progressive. Le PS lui-même ne fournit pas la possibilité de contrôler directement la courbe de gradient, mais vous pouvez ajuster de manière flexible le rayon et la douceur du gradient par plusieurs plumes, des masques correspondants et des sélections fines pour obtenir un effet de transition naturel.
 Comment utiliser MySQL après l'installation
Apr 08, 2025 am 11:48 AM
Comment utiliser MySQL après l'installation
Apr 08, 2025 am 11:48 AM
L'article présente le fonctionnement de la base de données MySQL. Tout d'abord, vous devez installer un client MySQL, tel que MySQLWorkBench ou le client de ligne de commande. 1. Utilisez la commande MySQL-UROot-P pour vous connecter au serveur et connecter avec le mot de passe du compte racine; 2. Utilisez Createdatabase pour créer une base de données et utilisez Sélectionner une base de données; 3. Utilisez CreateTable pour créer une table, définissez des champs et des types de données; 4. Utilisez InsertInto pour insérer des données, remettre en question les données, mettre à jour les données par mise à jour et supprimer les données par Supprimer. Ce n'est qu'en maîtrisant ces étapes, en apprenant à faire face à des problèmes courants et à l'optimisation des performances de la base de données que vous pouvez utiliser efficacement MySQL.
 MySQL doit-il payer
Apr 08, 2025 pm 05:36 PM
MySQL doit-il payer
Apr 08, 2025 pm 05:36 PM
MySQL a une version communautaire gratuite et une version d'entreprise payante. La version communautaire peut être utilisée et modifiée gratuitement, mais le support est limité et convient aux applications avec des exigences de stabilité faibles et des capacités techniques solides. L'Enterprise Edition fournit une prise en charge commerciale complète pour les applications qui nécessitent une base de données stable, fiable et haute performance et disposées à payer pour le soutien. Les facteurs pris en compte lors du choix d'une version comprennent la criticité des applications, la budgétisation et les compétences techniques. Il n'y a pas d'option parfaite, seulement l'option la plus appropriée, et vous devez choisir soigneusement en fonction de la situation spécifique.
 Comment configurer des plumes de PS?
Apr 06, 2025 pm 07:36 PM
Comment configurer des plumes de PS?
Apr 06, 2025 pm 07:36 PM
La plume PS est un effet flou du bord de l'image, qui est réalisé par la moyenne pondérée des pixels dans la zone de bord. Le réglage du rayon de la plume peut contrôler le degré de flou, et plus la valeur est grande, plus elle est floue. Le réglage flexible du rayon peut optimiser l'effet en fonction des images et des besoins. Par exemple, l'utilisation d'un rayon plus petit pour maintenir les détails lors du traitement des photos des caractères et l'utilisation d'un rayon plus grand pour créer une sensation brumeuse lorsque le traitement de l'art fonctionne. Cependant, il convient de noter que trop grand, le rayon peut facilement perdre des détails de bord, et trop petit, l'effet ne sera pas évident. L'effet de plumes est affecté par la résolution de l'image et doit être ajusté en fonction de la compréhension de l'image et de la saisie de l'effet.
 Quel impact la plume de PS a-t-elle sur la qualité de l'image?
Apr 06, 2025 pm 07:21 PM
Quel impact la plume de PS a-t-elle sur la qualité de l'image?
Apr 06, 2025 pm 07:21 PM
Les plumes de PS peuvent entraîner une perte de détails d'image, une saturation des couleurs réduite et une augmentation du bruit. Pour réduire l'impact, il est recommandé d'utiliser un rayon de plumes plus petit, de copier la couche puis de plume, et de comparer soigneusement la qualité d'image avant et après les plumes. De plus, les plumes ne conviennent pas à tous les cas, et parfois les outils tels que les masques conviennent plus à la gestion des bords de l'image.
 Comment optimiser les performances de la base de données après l'installation de MySQL
Apr 08, 2025 am 11:36 AM
Comment optimiser les performances de la base de données après l'installation de MySQL
Apr 08, 2025 am 11:36 AM
L'optimisation des performances MySQL doit commencer à partir de trois aspects: configuration d'installation, indexation et optimisation des requêtes, surveillance et réglage. 1. Après l'installation, vous devez ajuster le fichier my.cnf en fonction de la configuration du serveur, tel que le paramètre innodb_buffer_pool_size, et fermer query_cache_size; 2. Créez un index approprié pour éviter les index excessifs et optimiser les instructions de requête, telles que l'utilisation de la commande Explication pour analyser le plan d'exécution; 3. Utilisez le propre outil de surveillance de MySQL (ShowProcessList, Showstatus) pour surveiller la santé de la base de données, et sauvegarde régulièrement et organisez la base de données. Ce n'est qu'en optimisant en continu ces étapes que les performances de la base de données MySQL peuvent être améliorées.
 Comment optimiser les performances MySQL pour les applications de haute charge?
Apr 08, 2025 pm 06:03 PM
Comment optimiser les performances MySQL pour les applications de haute charge?
Apr 08, 2025 pm 06:03 PM
Guide d'optimisation des performances de la base de données MySQL dans les applications à forte intensité de ressources, la base de données MySQL joue un rôle crucial et est responsable de la gestion des transactions massives. Cependant, à mesure que l'échelle de l'application se développe, les goulots d'étranglement des performances de la base de données deviennent souvent une contrainte. Cet article explorera une série de stratégies efficaces d'optimisation des performances MySQL pour garantir que votre application reste efficace et réactive dans des charges élevées. Nous combinerons des cas réels pour expliquer les technologies clés approfondies telles que l'indexation, l'optimisation des requêtes, la conception de la base de données et la mise en cache. 1. La conception de l'architecture de la base de données et l'architecture optimisée de la base de données sont la pierre angulaire de l'optimisation des performances MySQL. Voici quelques principes de base: sélectionner le bon type de données et sélectionner le plus petit type de données qui répond aux besoins peut non seulement économiser un espace de stockage, mais également améliorer la vitesse de traitement des données.
 Solution d'erreur d'installation MySQL
Apr 08, 2025 am 10:48 AM
Solution d'erreur d'installation MySQL
Apr 08, 2025 am 10:48 AM
Raisons et solutions courantes pour l'échec de l'installation MySQL: 1. Nom d'utilisateur ou mot de passe incorrect, ou le service MySQL n'est pas démarré, vous devez vérifier le nom d'utilisateur et le mot de passe et démarrer le service; 2. Conflits portuaires, vous devez modifier le port d'écoute MySQL ou fermer le programme qui occupe le port 3306; 3. La bibliothèque de dépendances est manquante, vous devez utiliser le gestionnaire de package système pour installer la bibliothèque de dépendances nécessaires; 4. Autorisations insuffisantes, vous devez utiliser les droits de Sudo ou d'administrateur pour exécuter l'installateur; 5. Fichier de configuration incorrect, vous devez vérifier le fichier de configuration My.cnf pour vous assurer que la configuration est correcte. Ce n'est qu'en travaillant régulièrement et soigneusement que MySQL peut être installé en douceur.
