
 Périphériques technologiques
IA
Tant que le modèle et les échantillons sont suffisamment grands, l'IA peut devenir plus intelligente !
Périphériques technologiques
IA
Tant que le modèle et les échantillons sont suffisamment grands, l'IA peut devenir plus intelligente !
Tant que le modèle et les échantillons sont suffisamment grands, l'IA peut devenir plus intelligente !

Il n'y a aucune différence de mécanisme mathématique entre le modèle d'IA et le cerveau humain.
Tant que le modèle est suffisamment grand et que les échantillons sont suffisamment grands, l'IA peut devenir plus intelligente ! L’émergence du
chatGPT l’a effectivement prouvé.
1. Les détails sous-jacents de l'IA et du cerveau humain sont basés sur des instructions if else
opérations logiques, qui sont les opérations de base qui produisent l'intelligence.
La logique de base du langage de programmation est if else, qui divise le code en deux branches basées sur des expressions conditionnelles.
Sur cette base, les programmeurs peuvent écrire des codes très complexes et mettre en œuvre diverses logiques métier.
La logique de base du cerveau humain est aussi if else. Les deux mots if else viennent de l'anglais, et le vocabulaire chinois correspondant est if...else...
#🎜🎜 #cerveau humain C'est le même raisonnement logique lorsque l'on réfléchit à des problèmes. Ce n'est pas différent des ordinateurs à cet égard.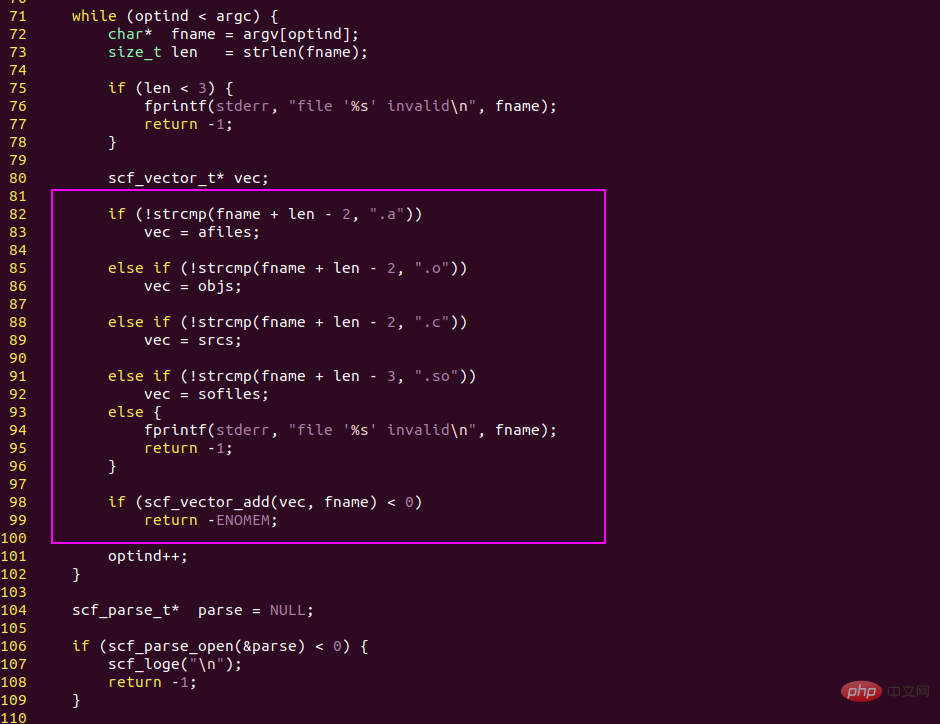
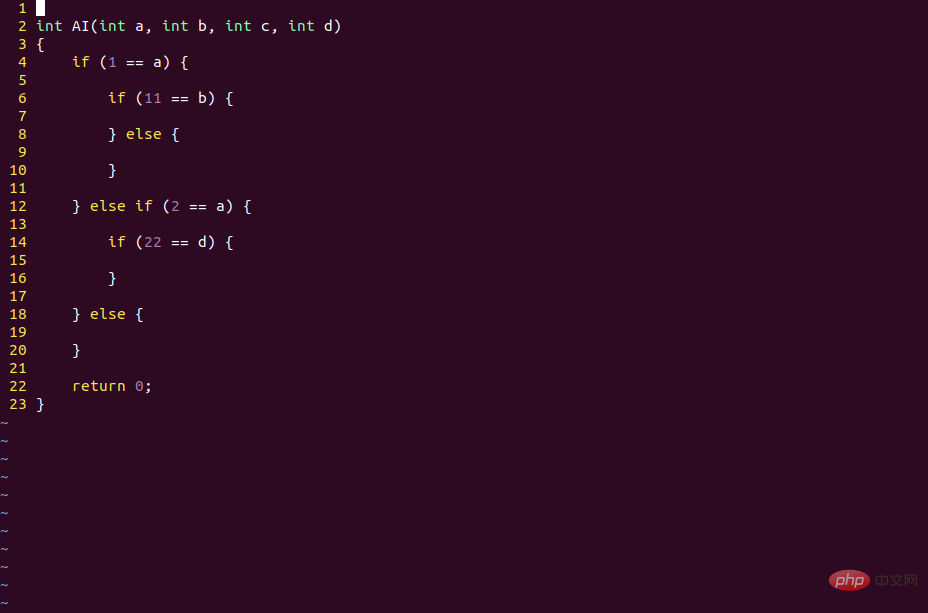
Mais ce n'est pas le cas des réseaux de neurones. Bien que son code soit écrit, il suffit de mettre à jour les données de poids pour changer le contexte logique du modèle.
En fait, tant que de nouveaux échantillons sont saisis en permanence, le modèle d'IA peut mettre à jour en permanence les données de poids à l'aide de l'algorithme BP (algorithme de descente de gradient) pour s'adapter aux nouveaux scénarios commerciaux.
La mise à jour du modèle d'IA ne nécessite pas de modifier le code, mais nécessite uniquement de modifier les données, de sorte que le même modèle CNN peut reconnaître différents objets s'il est entraîné avec différents échantillons.
Dans ce processus, le code du framework Tensorflow et la structure du réseau du modèle d'IA restent inchangés. Ce qui change, ce sont les données de poids de chaque nœud.
Théoriquement, tant qu'un modèle d'IA peut explorer les données à travers le réseau, il peut devenir plus intelligent.
Est-ce fondamentalement différent des gens qui regardent des choses via un navigateur (devenant ainsi plus intelligents) ? Il semble que non.
4. Tant que le modèle est suffisamment grand et que les échantillons sont suffisamment grands, ChatGPT peut peut-être vraiment défier le cerveau humain
Le cerveau humain possède 15 milliards de neurones, et les yeux et les oreilles humains lui fournissent de nouvelles données à chaque instant. Les modèles d’IA peuvent certainement le faire aussi.
Peut-être que par rapport à l'IA, l'avantage des humains est que la « chaîne industrielle » est plus courte
La naissance d'un bébé ne nécessite que ses parents, mais la naissance d'un modèle d'IA n'est évidemment pas quelque chose qu'un ou deux programmeurs peuvent faire .
La seule fabrication de GPU nécessite plus de dizaines de milliers de personnes.
Les programmes Cuda sur GPU ne sont pas difficiles à écrire, mais la chaîne industrielle de fabrication des GPU est trop longue, bien inférieure à la naissance et à la croissance des êtres humains.
C’est peut-être le véritable inconvénient de l’IA par rapport aux humains.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)
Sujets chauds



 KAN, qui remplace MLP, a été étendu à la convolution par des projets open source
Jun 01, 2024 pm 10:03 PM
KAN, qui remplace MLP, a été étendu à la convolution par des projets open source
Jun 01, 2024 pm 10:03 PM
Plus tôt ce mois-ci, des chercheurs du MIT et d'autres institutions ont proposé une alternative très prometteuse au MLP – KAN. KAN surpasse MLP en termes de précision et d’interprétabilité. Et il peut surpasser le MLP fonctionnant avec un plus grand nombre de paramètres avec un très petit nombre de paramètres. Par exemple, les auteurs ont déclaré avoir utilisé KAN pour reproduire les résultats de DeepMind avec un réseau plus petit et un degré d'automatisation plus élevé. Plus précisément, le MLP de DeepMind compte environ 300 000 paramètres, tandis que le KAN n'en compte qu'environ 200. KAN a une base mathématique solide comme MLP est basé sur le théorème d'approximation universelle, tandis que KAN est basé sur le théorème de représentation de Kolmogorov-Arnold. Comme le montre la figure ci-dessous, KAN a
 Yolov10 : explication détaillée, déploiement et application en un seul endroit !
Jun 07, 2024 pm 12:05 PM
Yolov10 : explication détaillée, déploiement et application en un seul endroit !
Jun 07, 2024 pm 12:05 PM
1. Introduction Au cours des dernières années, les YOLO sont devenus le paradigme dominant dans le domaine de la détection d'objets en temps réel en raison de leur équilibre efficace entre le coût de calcul et les performances de détection. Les chercheurs ont exploré la conception architecturale de YOLO, les objectifs d'optimisation, les stratégies d'expansion des données, etc., et ont réalisé des progrès significatifs. Dans le même temps, le recours à la suppression non maximale (NMS) pour le post-traitement entrave le déploiement de bout en bout de YOLO et affecte négativement la latence d'inférence. Dans les YOLO, la conception de divers composants manque d’une inspection complète et approfondie, ce qui entraîne une redondance informatique importante et limite les capacités du modèle. Il offre une efficacité sous-optimale et un potentiel d’amélioration des performances relativement important. Dans ce travail, l'objectif est d'améliorer encore les limites d'efficacité des performances de YOLO à la fois en post-traitement et en architecture de modèle. à cette fin
 Aucune donnée OpenAI requise, rejoignez la liste des grands modèles de code ! UIUC publie StarCoder-15B-Instruct
Jun 13, 2024 pm 01:59 PM
Aucune donnée OpenAI requise, rejoignez la liste des grands modèles de code ! UIUC publie StarCoder-15B-Instruct
Jun 13, 2024 pm 01:59 PM
À la pointe de la technologie logicielle, le groupe de l'UIUC Zhang Lingming, en collaboration avec des chercheurs de l'organisation BigCode, a récemment annoncé le modèle de grand code StarCoder2-15B-Instruct. Cette réalisation innovante a permis une percée significative dans les tâches de génération de code, dépassant avec succès CodeLlama-70B-Instruct et atteignant le sommet de la liste des performances de génération de code. Le caractère unique de StarCoder2-15B-Instruct réside dans sa stratégie d'auto-alignement pur. L'ensemble du processus de formation est ouvert, transparent et complètement autonome et contrôlable. Le modèle génère des milliers d'instructions via StarCoder2-15B en réponse au réglage fin du modèle de base StarCoder-15B sans recourir à des annotations manuelles coûteuses.
 Surpassant largement le DPO : l'équipe de Chen Danqi a proposé une optimisation simple des préférences SimPO et a également affiné le modèle open source 8B le plus puissant.
Jun 01, 2024 pm 04:41 PM
Surpassant largement le DPO : l'équipe de Chen Danqi a proposé une optimisation simple des préférences SimPO et a également affiné le modèle open source 8B le plus puissant.
Jun 01, 2024 pm 04:41 PM
Afin d'aligner les grands modèles de langage (LLM) sur les valeurs et les intentions humaines, il est essentiel d'apprendre les commentaires humains pour garantir qu'ils sont utiles, honnêtes et inoffensifs. En termes d'alignement du LLM, une méthode efficace est l'apprentissage par renforcement basé sur le retour humain (RLHF). Bien que les résultats de la méthode RLHF soient excellents, certains défis d’optimisation sont impliqués. Cela implique de former un modèle de récompense, puis d'optimiser un modèle politique pour maximiser cette récompense. Récemment, certains chercheurs ont exploré des algorithmes hors ligne plus simples, dont l’optimisation directe des préférences (DPO). DPO apprend le modèle politique directement sur la base des données de préférence en paramétrant la fonction de récompense dans RLHF, éliminant ainsi le besoin d'un modèle de récompense explicite. Cette méthode est simple et stable
 L'Université Tsinghua a pris le relais et YOLOv10 est sorti : les performances ont été grandement améliorées et il figurait sur la hot list de GitHub
Jun 06, 2024 pm 12:20 PM
L'Université Tsinghua a pris le relais et YOLOv10 est sorti : les performances ont été grandement améliorées et il figurait sur la hot list de GitHub
Jun 06, 2024 pm 12:20 PM
La série de référence YOLO de systèmes de détection de cibles a une fois de plus reçu une mise à niveau majeure. Depuis la sortie de YOLOv9 en février de cette année, le relais de la série YOLO (YouOnlyLookOnce) a été passé entre les mains de chercheurs de l'Université Tsinghua. Le week-end dernier, la nouvelle du lancement de YOLOv10 a attiré l'attention de la communauté IA. Il est considéré comme un cadre révolutionnaire dans le domaine de la vision par ordinateur et est connu pour ses capacités de détection d'objets de bout en bout en temps réel, poursuivant l'héritage de la série YOLO en fournissant une solution puissante alliant efficacité et précision. Adresse de l'article : https://arxiv.org/pdf/2405.14458 Adresse du projet : https://github.com/THU-MIG/yo
 Li Feifei révèle l'orientation entrepreneuriale de « l'intelligence spatiale » : la visualisation se transforme en aperçu, la vue devient compréhension et la compréhension mène à l'action
Jun 01, 2024 pm 02:55 PM
Li Feifei révèle l'orientation entrepreneuriale de « l'intelligence spatiale » : la visualisation se transforme en aperçu, la vue devient compréhension et la compréhension mène à l'action
Jun 01, 2024 pm 02:55 PM
Stanford Li Feifei a dévoilé pour la première fois le nouveau concept « d'intelligence spatiale » après avoir lancé sa propre entreprise. Ce n'est pas seulement son orientation entrepreneuriale, mais aussi « l'étoile du Nord » qui la guide, elle la considère comme « la pièce clé du puzzle pour résoudre le problème de l'intelligence artificielle ». La visualisation mène à la perspicacité ; la vue mène à la compréhension ; la compréhension mène à l’action. Basé sur la conférence TED de 15 minutes de Li Feifei, il est entièrement révélé, depuis l'origine de l'évolution de la vie il y a des centaines de millions d'années, jusqu'à la façon dont les humains ne sont pas satisfaits de ce que la nature leur a donné et développent l'intelligence artificielle, jusqu'à la façon de construire l'intelligence spatiale dans la prochaine étape. Il y a neuf ans, Li Feifei a présenté au monde le nouveau ImageNet sur la même scène - l'un des points de départ de cette explosion d'apprentissage profond. Elle a elle-même encouragé les internautes : si vous regardez les deux vidéos, vous pourrez comprendre la vision par ordinateur des 10 dernières années.
 Battant GPT-4o en quelques secondes, battant Llama 3 70B en 22B, Mistral AI ouvre son premier modèle de code
Jun 01, 2024 pm 06:32 PM
Battant GPT-4o en quelques secondes, battant Llama 3 70B en 22B, Mistral AI ouvre son premier modèle de code
Jun 01, 2024 pm 06:32 PM
La licorne française d'IA MistralAI, qui vise OpenAI, a fait un nouveau pas : Codestral, le premier grand modèle de code, est né. En tant que modèle d'IA génératif ouvert conçu spécifiquement pour les tâches de génération de code, Codestral aide les développeurs à écrire et à interagir avec le code en partageant des instructions et des points de terminaison d'API d'achèvement. La maîtrise du codage et de l'anglais de Codestral permet aux développeurs de logiciels de concevoir des applications d'IA avancées. La taille des paramètres de Codestral est de 22B, il est conforme à la nouvelle MistralAINon-ProductionLicense et peut être utilisé à des fins de recherche et de test, mais l'utilisation commerciale est interdite. Actuellement, le modèle est disponible en téléchargement sur HuggingFace. lien de téléchargement
 Revoir! Résumer de manière exhaustive le rôle important des modèles de base dans la promotion de la conduite autonome
Jun 11, 2024 pm 05:29 PM
Revoir! Résumer de manière exhaustive le rôle important des modèles de base dans la promotion de la conduite autonome
Jun 11, 2024 pm 05:29 PM
Écrit ci-dessus et compréhension personnelle de l'auteur : Récemment, avec le développement et les percées de la technologie d'apprentissage profond, les modèles de base à grande échelle (Foundation Models) ont obtenu des résultats significatifs dans les domaines du traitement du langage naturel et de la vision par ordinateur. L’application de modèles de base à la conduite autonome présente également de grandes perspectives de développement, susceptibles d’améliorer la compréhension et le raisonnement des scénarios. Grâce à une pré-formation sur un langage riche et des données visuelles, le modèle de base peut comprendre et interpréter divers éléments des scénarios de conduite autonome et effectuer un raisonnement, fournissant ainsi un langage et des commandes d'action pour piloter la prise de décision et la planification. Le modèle de base peut être constitué de données enrichies d'une compréhension du scénario de conduite afin de fournir les rares caractéristiques réalisables dans les distributions à longue traîne qui sont peu susceptibles d'être rencontrées lors d'une conduite de routine et d'une collecte de données.
