
 Périphériques technologiques
IA
Une brève analyse de la voie technologique de perception visuelle pour la conduite autonome
Périphériques technologiques
IA
Une brève analyse de la voie technologique de perception visuelle pour la conduite autonome
Une brève analyse de la voie technologique de perception visuelle pour la conduite autonome

01 Contexte
La conduite autonome est une transition progressive de l'étape de prédiction à l'étape d'industrialisation. Les performances spécifiques peuvent être divisées en quatre points. Tout d’abord, dans le contexte du Big Data, l’échelle des ensembles de données s’étend rapidement. En conséquence, les détails des prototypes précédemment développés sur des ensembles de données à petite échelle seront largement filtrés et seuls les travaux pouvant être efficaces sur des ensembles de données à grande échelle seront largement filtrés. -les données à l'échelle seront laissées. La seconde est le changement de mise au point, des scènes monoculaires aux scènes multi-vues, ce qui entraîne une augmentation de la complexité. Ensuite, il y a la tendance vers des conceptions conviviales, telles que le transfert de l’espace de sortie de l’espace image vers l’espace BEV.
Enfin, nous sommes passés d'une simple recherche de précision à une prise en compte progressive de la vitesse d'inférence en même temps. Dans le même temps, une réponse rapide est requise dans les scénarios de conduite autonome, de sorte que les exigences de performances prendront en compte la vitesse. En outre, une plus grande attention est accordée à la manière de déployer sur les appareils de pointe.
Un autre élément du contexte est qu'au cours des 10 dernières années, la perception visuelle s'est développée rapidement grâce à l'apprentissage profond. Il y a eu beaucoup de travail et des paradigmes assez matures dans des domaines courants tels que la classification, la détection et la segmentation. . Dans le processus de développement de la perception visuelle dans les scénarios de conduite autonome, des aspects tels que la définition cible du codage des caractéristiques, le paradigme de perception et la supervision ont beaucoup emprunté à ces orientations dominantes. Par conséquent, avant de s'engager dans la perception de la conduite autonome, ces orientations dominantes doivent être explorées. Barbotez un peu.
Dans ce contexte, un grand nombre de travaux de détection de cibles 3D sur des ensembles de données à grande échelle ont vu le jour au cours de l'année écoulée, comme le montre la figure 1 (ceux marqués en rouge sont les premiers algorithmes).
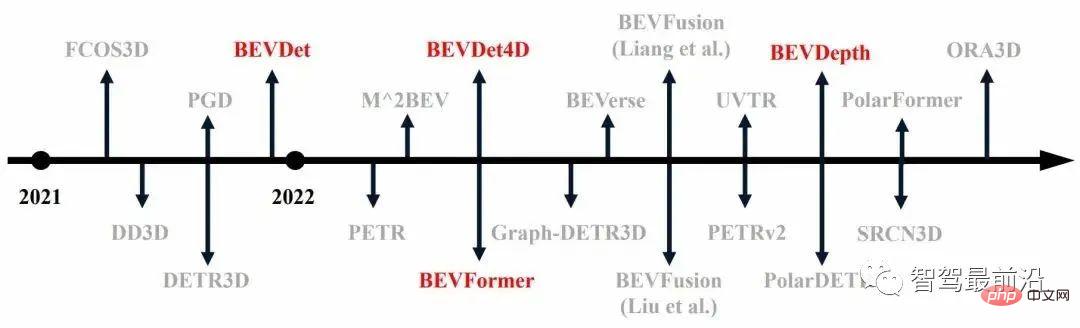
Figure 1 Développement de la détection de cibles 3D au cours de l'année écoulée
02 Parcours technique
2.1 Levage
Perception visuelle et La différence entre la perception visuelle dominante réside principalement dans la différence dans l'espace de définition de la cible donné. La cible de la perception visuelle dominante est définie dans l'espace de l'image, tandis que la cible de la scène de conduite autonome est définie dans l'espace tridimensionnel. Lorsque les entrées sont toutes des images, l’obtention des résultats dans l’espace tridimensionnel nécessite un processus Lift. C’est la question centrale de la perception visuelle pour la conduite autonome.
Nous pouvons diviser la méthode de résolution du problème de l'objet Lift en entrées, caractéristiques intermédiaires et sortie. Un exemple de niveau d'entrée est le changement de perspective. Le principe est d'utiliser l'image pour raisonner sur les informations de profondeur, puis d'utiliser. les informations de profondeur pour convertir la valeur RVB de l'image. Projetez-la dans un espace tridimensionnel pour obtenir un nuage de points coloré, puis suivez le travail associé de détection du nuage de points.
Actuellement, les plus prometteuses sont la transformation au niveau des fonctionnalités ou l'ascenseur au niveau des fonctionnalités, tels que DETR3D, qui effectuent tous des changements spatiaux au niveau des fonctionnalités. L'avantage de la transformation au niveau des fonctionnalités est qu'elle peut éviter une extraction répétée de. les caractéristiques et les calculs au niveau de l'image. Cette petite quantité peut également éviter le problème de la fusion des résultats de recherche au niveau de la sortie. Bien entendu, la conversion au niveau des fonctionnalités posera également des problèmes typiques, tels que l'utilisation habituelle de certains OP étranges, ce qui rend le déploiement peu convivial.
À l'heure actuelle, le processus Lift relativement robuste au niveau des fonctionnalités est principalement basé sur des stratégies de profondeur et de mécanisme d'attention, et les plus représentatives sont respectivement BEVDet et DETR3D. La stratégie basée sur la profondeur consiste à effectuer un processus de levage en calculant la profondeur de chaque point de l'image, puis en projetant les caractéristiques dans un espace tridimensionnel selon le modèle d'imagerie de la caméra. La stratégie basée sur le mécanisme d'attention consiste à prédéfinir un objet dans l'espace tridimensionnel en tant que requête, à trouver les caractéristiques de l'image correspondant au point médian de l'espace tridimensionnel comme clé et valeur via des paramètres internes et externes, puis à calculer un objet tridimensionnel grâce à l'attention. Une caractéristique d'un objet dans l'espace.
Tous les algorithmes actuels dépendent fondamentalement fortement des modèles de caméra, qu'ils soient basés sur la profondeur ou sur l'attention, ce qui entraîne une sensibilité à l'étalonnage et des processus de calcul généralement complexes. Les algorithmes qui abandonnent les modèles de caméras manquent souvent de robustesse, cet aspect n’est donc pas encore complètement mature.
2.2 Temporelle
Les informations temporelles peuvent améliorer efficacement l'effet de la détection de la cible. Pour les scénarios de conduite autonome, le timing a une signification plus profonde car la vitesse de la cible est l’une des principales cibles de perception dans le scénario actuel. L'objectif de la vitesse réside dans le changement. Les données à image unique ne contiennent pas suffisamment d'informations sur les changements, une modélisation est donc nécessaire pour fournir des informations sur les changements dans la dimension temporelle. La méthode de modélisation de séries chronologiques de nuages de points existante consiste à mélanger les nuages de points de plusieurs images en entrée, de sorte qu'un nuage de points relativement dense puisse être obtenu, rendant la détection plus précise. De plus, les nuages de points multi-trames contiennent des informations continues. Plus tard, au cours du processus de formation du réseau, BP est utilisé pour apprendre à extraire ces informations continues afin de résoudre des tâches telles que l'estimation de la vitesse qui nécessitent des informations continues.
La méthode de modélisation temporelle de la perception visuelle provient principalement de BEVDet4D et BEVFormer. BEVDet4D fournit des informations continues pour les réseaux suivants en fusionnant simplement une fonctionnalité de deux trames. L'autre voie est basée sur l'attention, fournissant à la fois des caractéristiques de trame temporelle unique et dans le sens inverse des aiguilles d'une montre comme objet de requête, puis interrogeant ces deux caractéristiques simultanément par l'attention pour extraire des informations de synchronisation.
2.3 Profondeur
L'un des plus grands inconvénients de la perception visuelle de la conduite autonome par rapport à la perception radar est la précision de l'estimation de la profondeur. L'article « Profondeur probabiliste et géométrique : détection d'objets en perspective » étudie l'impact de différents facteurs sur les scores de performance en remplaçant la méthode GT. La principale conclusion de l'analyse est qu'une estimation précise de la profondeur peut apporter des améliorations significatives des performances.
Mais l'estimation de la profondeur est un goulot d'étranglement majeur dans la perception visuelle actuelle. Il existe actuellement deux idées principales d'amélioration. La première consiste à utiliser des contraintes géométriques dans le PGD pour affiner la carte de profondeur prédite. L’autre consiste à utiliser le lidar comme supervision pour obtenir une estimation de profondeur plus robuste.
La solution actuelle supérieure en termes de processus, BEVDepth, utilise les informations de profondeur fournies par lidar pendant le processus de formation pour superviser l'estimation de la profondeur pendant le processus de changement, et l'exécute simultanément avec la tâche principale de perception.
2.4 Muti-modalité/Multi-tâches
Multi-tâche espère effectuer une variété de tâches de perception sur un cadre unifié. Grâce à ce calcul, il peut atteindre l'objectif d'économiser des ressources ou d'accélérer le raisonnement informatique. . Cependant, les méthodes actuelles réalisent essentiellement le multitâche simplement en traitant les fonctionnalités à différents niveaux après avoir obtenu une fonctionnalité unifiée. Il existe un problème courant de dégradation des performances après la fusion des tâches. La multimodalité est également presque universelle dans la recherche d’une forme qui peut être directement fusionnée dans l’ensemble du jugement, puis dans la réalisation d’une simple fusion.
03 Série BEVDet
3.1 BEVDet
Le réseau BEVDet est illustré à la figure 2. Le processus d'extraction de caractéristiques consiste principalement à convertir une caractéristique de l'espace image extrait en une caractéristique de l'espace BEV, puis coder davantage cette fonctionnalité pour obtenir une fonctionnalité qui peut être utilisée pour la prédiction, et enfin utiliser la prédiction dense pour prédire la cible.
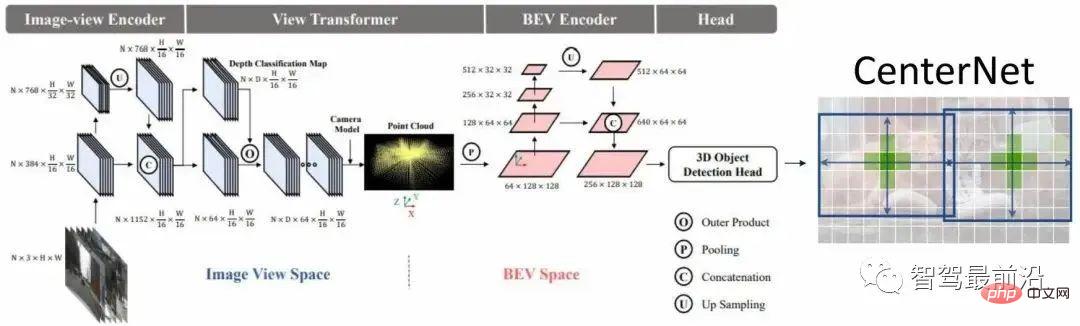
Figure 2 Structure du réseau BEVDet
Le processus du module de changement de perspective est divisé en deux étapes. Tout d'abord, supposons que la taille de l'entité à transformer est VxCxHxW, puis prédisez-la. de manière classifiée dans l'espace d'image Une profondeur, pour chaque pixel afin d'obtenir une distribution de profondeur dimensionnelle D, vous pouvez alors utiliser ces deux fonctionnalités pour restituer différentes profondeurs afin d'obtenir une caractéristique visuelle, puis utiliser le modèle de caméra pour le projeter dans un espace tridimensionnel, pour 3 L'espace dimensionnel est voxélisé, puis le processus splat est effectué pour obtenir les caractéristiques BEV.
Une caractéristique très importante du module de changement de perspective est qu'il joue un rôle d'isolation mutuelle dans le ralentissement des données. Plus précisément, grâce aux paramètres internes de la caméra, un point sur le système de coordonnées de la caméra peut être obtenu en le projetant dans un espace tridimensionnel lorsque l'augmentation des données est appliquée à un point dans l'espace image, afin de conserver les coordonnées. du point sur le système de coordonnées de la caméra Invariant, vous devez effectuer une transformation inverse, c'est-à-dire qu'une coordonnée sur le système de coordonnées de la caméra reste inchangée avant et après l'augmentation, ce qui a un effet d'isolement mutuel. L'inconvénient de l'isolement mutuel est que l'augmentation de l'espace image ne régularise pas l'apprentissage de l'espace BEV. L'avantage peut améliorer la robustesse de l'apprentissage de l'espace BEV
Nous pouvons tirer plusieurs points importants des expériences en conclusion. Premièrement, après avoir utilisé l’encodeur spatial BEV, l’algorithme est plus susceptible de tomber en surapprentissage. Une autre conclusion est que l’expansion de l’espace BEV aura un impact plus important sur les performances que l’expansion de l’espace image.
Il existe également une corrélation entre la taille cible de l'espace BEV et la hauteur de la catégorie. Dans le même temps, la faible longueur de chevauchement entre les cibles posera certains problèmes. On observe que la méthode de suppression non maximale conçue dans. l'espace image n'est pas optimal. Le cœur de la stratégie d'accélération simultanée consiste à utiliser des méthodes de calcul parallèle pour allouer des threads indépendants à différentes petites tâches informatiques afin d'atteindre l'objectif d'accélération du calcul parallèle. L'avantage est qu'il n'y a pas de surcharge de mémoire vidéo supplémentaire.
3.2 La structure du réseau BEVDet4D
BEVDet4D est illustrée à la figure 3. L'objectif principal de ce réseau est de savoir comment appliquer les caractéristiques de la trame temporelle inverse à la trame actuelle. Nous choisissons la fonctionnalité d'entrée comme objet conservé, mais ne choisissons pas cette fonctionnalité d'image car les variables cibles sont définies dans l'espace BEV. , et l'image Les caractéristiques de ne conviennent pas à la modélisation temporelle directe. Dans le même temps, les fonctionnalités derrière l'encodeur BEV ne sont pas sélectionnées comme fonctionnalités de fusion continue, car nous devons extraire une fonctionnalité continue dans l'encodeur BEV.
Étant donné que les caractéristiques produites par le module de changement de perspective sont relativement rares, un encodeur BEV supplémentaire est connecté après le changement de perspective pour extraire les caractéristiques BEV préliminaires, puis effectuer une modélisation de séries chronologiques. Lors de la fusion temporelle, nous épissons simplement les caractéristiques du cadre dans le sens inverse des aiguilles d'une montre avec l'aiguille actuelle en les alignant pour terminer la fusion temporelle. En fait, nous laissons ici la tâche d'extraire les caractéristiques temporelles aux plus récents.
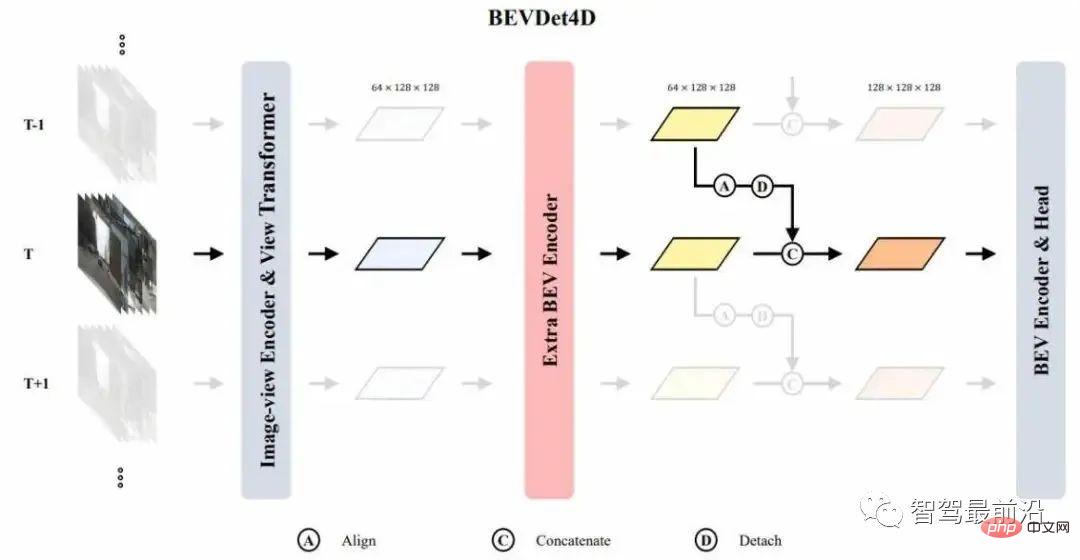
Figure 3 Structure du réseau BEVDet4D
Comment concevoir des variables cibles qui correspondent à la structure du réseau ? Avant cela, nous devons d'abord comprendre certaines caractéristiques clés du réseau. La première est le champ réceptif de la fonctionnalité. Étant donné que le réseau apprend via BP, le champ réceptif de la fonctionnalité est déterminé par l'espace de sortie.
L'espace de sortie de l'algorithme de perception de la conduite autonome est généralement défini comme un espace situé dans une certaine plage autour du véhicule autonome. La carte des caractéristiques peut être considérée comme un échantillon discret uniformément distribué et aligné dans les coins de l'espace continu. . Étant donné que le champ récepteur de la carte de caractéristiques est défini dans une certaine plage autour de la voiture autonome, il changera avec le mouvement de la voiture autonome. Par conséquent, à deux nœuds temporels différents, le champ récepteur de la carte de caractéristiques a une certaine. valeur dans le système de coordonnées mondial.
Si les deux entités sont directement assemblées, les positions de la cible statique dans les deux cartes de fonctionnalités sont différentes et le décalage de la cible dynamique dans les deux cartes de fonctionnalités est égal au décalage de l'auto- test plus Le décalage de la cible dynamique supérieure dans le système de coordonnées mondial. Selon un principe de cohérence des modèles, puisque le décalage de la cible dans les éléments épissés est lié au véhicule propre, lors de la définition de l'objectif d'apprentissage du réseau, il devrait s'agir du changement de position de la cible dans ces éléments. deux cartes de fonctionnalités.
D'après la formule suivante, on peut en déduire qu'une cible d'apprentissage n'est pas liée au mouvement de l'autotest, mais est uniquement liée au mouvement de la cible dans le système de coordonnées mondial.
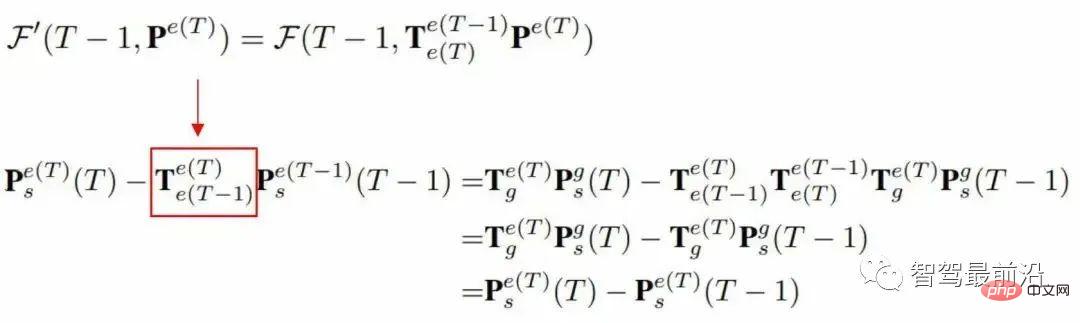
La différence entre les objectifs d'apprentissage que nous avons dérivés de ce qui précède et les objectifs d'apprentissage des méthodes traditionnelles actuelles est que la composante temporelle est supprimée et que la vitesse est égale au déplacement/temps. Cependant, ces deux fonctionnalités ne fournissent pas d'informations liées au temps. des indices, donc si vous apprenez cet objectif de vitesse, le réseau doit estimer avec précision la composante temporelle, ce qui augmente la difficulté d'apprentissage. En pratique, nous pouvons définir le temps entre deux images comme valeur constante pendant le processus de formation. Un réseau à intervalles de temps constants peut être appris par l'apprentissage de BP.
Dans l'augmentation du domaine temporel, nous utilisons de manière aléatoire différents intervalles de temps pendant le processus d'entraînement. À différents intervalles de temps, le décalage de la cible dans les deux images est différent et le décalage cible de l'apprentissage est également différent. , afin d'obtenir l'effet Lupin du modèle sur différents offsets. Dans le même temps, le modèle présente une certaine sensibilité au décalage de la cible, c'est-à-dire que si l'intervalle est trop petit, le changement entre deux images sera difficile à percevoir s'il est trop petit. Par conséquent, le choix d’un intervalle de temps approprié pendant les tests peut améliorer efficacement les performances de généralisation du modèle.
3.3 BEVDepth
Cet article utilise le radar pour obtenir une estimation de profondeur robuste, comme le montre la figure 4. Il utilise des nuages de points pour superviser la distribution de profondeur dans le module de changement. Cette supervision est clairsemée par rapport à la supervision de profondeur fournie par la cible, mais elle n'atteint pas chaque pixel. Cependant, davantage d'échantillons peuvent être fournis pour améliorer les performances de généralisation de cette estimation de profondeur.
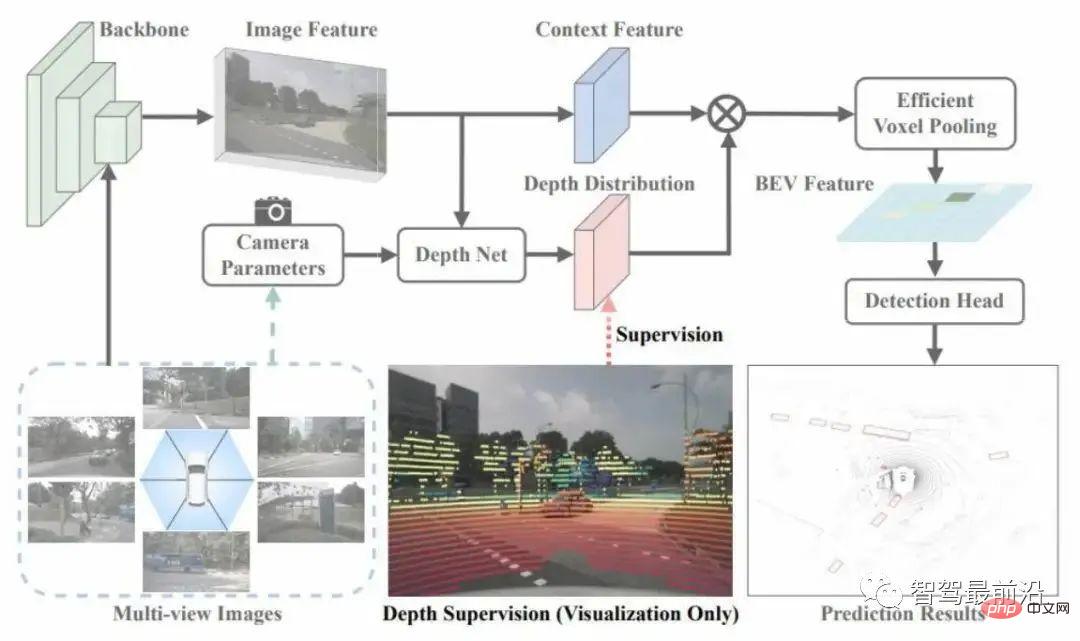
Figure 4 Structure du réseau BEVDepth
Un autre aspect de ce travail consiste à diviser les caractéristiques et la profondeur en deux branches pour l'estimation, et à ajouter des résidus supplémentaires à la branche d'estimation de la profondeur. réseau pour améliorer le champ de réception de la branche d'estimation de profondeur. Les chercheurs pensent que la précision des paramètres internes et externes de la caméra entraînera un désalignement du contexte et de la profondeur. Lorsque le réseau d'estimation de la profondeur n'est pas assez puissant, il y aura une certaine perte de précision.
Enfin, les paramètres internes de cette caméra sont utilisés comme entrée de branche d'estimation de profondeur, en utilisant une méthode similaire à NSE pour ajuster le canal de la fonction d'entrée au niveau du canal, ce qui peut améliorer efficacement la réponse du réseau à différentes caméras. paramètres internes de robustesse.
04 Limites et discussions associées
Tout d'abord, la perception visuelle de la conduite autonome sert en fin de compte le déploiement, et lors du déploiement, elle impliquera des problèmes de données et des problèmes de modèle. Le problème des données implique un problème de diversité et d'annotation des données, car l'annotation manuelle est très coûteuse, nous verrons donc si l'annotation automatisée peut être réalisée à l'avenir.
Actuellement, l'étiquetage des cibles dynamiques est inédit. Pour les cibles statiques, un étiquetage partiel ou semi-automatique peut être obtenu grâce à la reconstruction 3D. En termes de modèles, la conception actuelle du modèle n'est pas robuste à l'étalonnage ou est sensible à l'étalonnage. Ainsi, comment rendre le modèle robuste à l'étalonnage ou indépendant de l'étalonnage est également une question qui mérite réflexion.
L'autre problème est l'accélération de la structure du réseau. Un OP général peut-il être utilisé pour réaliser des changements de perspective ? Ce problème affectera le processus d'accélération du réseau.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Pourquoi le Gaussian Splatting est-il si populaire dans la conduite autonome que le NeRF commence à être abandonné ?
Jan 17, 2024 pm 02:57 PM
Pourquoi le Gaussian Splatting est-il si populaire dans la conduite autonome que le NeRF commence à être abandonné ?
Jan 17, 2024 pm 02:57 PM
Écrit ci-dessus et compréhension personnelle de l'auteur Le Gaussiansplatting tridimensionnel (3DGS) est une technologie transformatrice qui a émergé dans les domaines des champs de rayonnement explicites et de l'infographie ces dernières années. Cette méthode innovante se caractérise par l’utilisation de millions de gaussiennes 3D, ce qui est très différent de la méthode du champ de rayonnement neuronal (NeRF), qui utilise principalement un modèle implicite basé sur les coordonnées pour mapper les coordonnées spatiales aux valeurs des pixels. Avec sa représentation explicite de scènes et ses algorithmes de rendu différenciables, 3DGS garantit non seulement des capacités de rendu en temps réel, mais introduit également un niveau de contrôle et d'édition de scène sans précédent. Cela positionne 3DGS comme un révolutionnaire potentiel pour la reconstruction et la représentation 3D de nouvelle génération. À cette fin, nous fournissons pour la première fois un aperçu systématique des derniers développements et préoccupations dans le domaine du 3DGS.
 Comment résoudre le problème de la longue traîne dans les scénarios de conduite autonome ?
Jun 02, 2024 pm 02:44 PM
Comment résoudre le problème de la longue traîne dans les scénarios de conduite autonome ?
Jun 02, 2024 pm 02:44 PM
Hier, lors de l'entretien, on m'a demandé si j'avais posé des questions à longue traîne, j'ai donc pensé faire un bref résumé. Le problème à longue traîne de la conduite autonome fait référence aux cas extrêmes dans les véhicules autonomes, c'est-à-dire à des scénarios possibles avec une faible probabilité d'occurrence. Le problème perçu de la longue traîne est l’une des principales raisons limitant actuellement le domaine de conception opérationnelle des véhicules autonomes intelligents à véhicule unique. L'architecture sous-jacente et la plupart des problèmes techniques de la conduite autonome ont été résolus, et les 5 % restants des problèmes à longue traîne sont progressivement devenus la clé pour restreindre le développement de la conduite autonome. Ces problèmes incluent une variété de scénarios fragmentés, de situations extrêmes et de comportements humains imprévisibles. La « longue traîne » des scénarios limites dans la conduite autonome fait référence aux cas limites dans les véhicules autonomes (VA). Les cas limites sont des scénarios possibles avec une faible probabilité d'occurrence. ces événements rares
 Choisir une caméra ou un lidar ? Une étude récente sur la détection robuste d'objets 3D
Jan 26, 2024 am 11:18 AM
Choisir une caméra ou un lidar ? Une étude récente sur la détection robuste d'objets 3D
Jan 26, 2024 am 11:18 AM
0. Écrit à l'avant&& Compréhension personnelle que les systèmes de conduite autonome s'appuient sur des technologies avancées de perception, de prise de décision et de contrôle, en utilisant divers capteurs (tels que caméras, lidar, radar, etc.) pour percevoir l'environnement et en utilisant des algorithmes et des modèles pour une analyse et une prise de décision en temps réel. Cela permet aux véhicules de reconnaître les panneaux de signalisation, de détecter et de suivre d'autres véhicules, de prédire le comportement des piétons, etc., permettant ainsi de fonctionner en toute sécurité et de s'adapter à des environnements de circulation complexes. Cette technologie attire actuellement une grande attention et est considérée comme un domaine de développement important pour l'avenir des transports. . un. Mais ce qui rend la conduite autonome difficile, c'est de trouver comment faire comprendre à la voiture ce qui se passe autour d'elle. Cela nécessite que l'algorithme de détection d'objets tridimensionnels du système de conduite autonome puisse percevoir et décrire avec précision les objets dans l'environnement, y compris leur emplacement,
 Avez-vous vraiment maîtrisé la conversion des systèmes de coordonnées ? Des enjeux multi-capteurs indispensables à la conduite autonome
Oct 12, 2023 am 11:21 AM
Avez-vous vraiment maîtrisé la conversion des systèmes de coordonnées ? Des enjeux multi-capteurs indispensables à la conduite autonome
Oct 12, 2023 am 11:21 AM
Le premier article pilote et clé présente principalement plusieurs systèmes de coordonnées couramment utilisés dans la technologie de conduite autonome, et comment compléter la corrélation et la conversion entre eux, et enfin construire un modèle d'environnement unifié. L'objectif ici est de comprendre la conversion du véhicule en corps rigide de caméra (paramètres externes), la conversion de caméra en image (paramètres internes) et la conversion d'image en unité de pixel. La conversion de 3D en 2D aura une distorsion, une traduction, etc. Points clés : Le système de coordonnées du véhicule et le système de coordonnées du corps de la caméra doivent être réécrits : le système de coordonnées planes et le système de coordonnées des pixels Difficulté : la distorsion de l'image doit être prise en compte. La dé-distorsion et l'ajout de distorsion sont compensés sur le plan de l'image. 2. Introduction Il existe quatre systèmes de vision au total : système de coordonnées du plan de pixels (u, v), système de coordonnées d'image (x, y), système de coordonnées de caméra () et système de coordonnées mondiales (). Il existe une relation entre chaque système de coordonnées,
 Cet article vous suffit pour en savoir plus sur la conduite autonome et la prédiction de trajectoire !
Feb 28, 2024 pm 07:20 PM
Cet article vous suffit pour en savoir plus sur la conduite autonome et la prédiction de trajectoire !
Feb 28, 2024 pm 07:20 PM
La prédiction de trajectoire joue un rôle important dans la conduite autonome. La prédiction de trajectoire de conduite autonome fait référence à la prédiction de la trajectoire de conduite future du véhicule en analysant diverses données pendant le processus de conduite du véhicule. En tant que module central de la conduite autonome, la qualité de la prédiction de trajectoire est cruciale pour le contrôle de la planification en aval. La tâche de prédiction de trajectoire dispose d'une riche pile technologique et nécessite une connaissance de la perception dynamique/statique de la conduite autonome, des cartes de haute précision, des lignes de voie, des compétences en architecture de réseau neuronal (CNN&GNN&Transformer), etc. Il est très difficile de démarrer ! De nombreux fans espèrent se lancer dans la prédiction de trajectoire le plus tôt possible et éviter les pièges. Aujourd'hui, je vais faire le point sur quelques problèmes courants et des méthodes d'apprentissage introductives pour la prédiction de trajectoire ! Connaissances introductives 1. Existe-t-il un ordre d'entrée pour les épreuves de prévisualisation ? R : Regardez d’abord l’enquête, p
 SIMPL : un benchmark de prédiction de mouvement multi-agents simple et efficace pour la conduite autonome
Feb 20, 2024 am 11:48 AM
SIMPL : un benchmark de prédiction de mouvement multi-agents simple et efficace pour la conduite autonome
Feb 20, 2024 am 11:48 AM
Titre original : SIMPL : ASimpleandEfficientMulti-agentMotionPredictionBaselineforAutonomousDriving Lien article : https://arxiv.org/pdf/2402.02519.pdf Lien code : https://github.com/HKUST-Aerial-Robotics/SIMPL Affiliation de l'auteur : Université des sciences de Hong Kong et technologie Idée DJI Paper : cet article propose une base de référence de prédiction de mouvement (SIMPL) simple et efficace pour les véhicules autonomes. Par rapport au cent agent traditionnel
 Parlons des systèmes de conduite autonome de bout en bout et de nouvelle génération, ainsi que de quelques malentendus sur la conduite autonome de bout en bout ?
Apr 15, 2024 pm 04:13 PM
Parlons des systèmes de conduite autonome de bout en bout et de nouvelle génération, ainsi que de quelques malentendus sur la conduite autonome de bout en bout ?
Apr 15, 2024 pm 04:13 PM
Au cours du mois dernier, pour des raisons bien connues, j'ai eu des échanges très intensifs avec divers professeurs et camarades de classe du secteur. Un sujet inévitable dans l'échange est naturellement le populaire Tesla FSDV12 de bout en bout. Je voudrais profiter de cette occasion pour trier certaines de mes pensées et opinions en ce moment pour votre référence et votre discussion. Comment définir un système de conduite autonome de bout en bout et quels problèmes devraient être résolus de bout en bout ? Selon la définition la plus traditionnelle, un système de bout en bout fait référence à un système qui saisit les informations brutes des capteurs et génère directement les variables pertinentes pour la tâche. Par exemple, en reconnaissance d'images, CNN peut être appelé de bout en bout par rapport à la méthode traditionnelle d'extraction de caractéristiques + classificateur. Dans les tâches de conduite autonome, saisir les données de divers capteurs (caméra/LiDAR
 NuScenes dernier SOTA SparseAD : les requêtes clairsemées contribuent à une conduite autonome efficace de bout en bout !
Apr 17, 2024 pm 06:22 PM
NuScenes dernier SOTA SparseAD : les requêtes clairsemées contribuent à une conduite autonome efficace de bout en bout !
Apr 17, 2024 pm 06:22 PM
Écrit à l'avant et point de départ Le paradigme de bout en bout utilise un cadre unifié pour réaliser plusieurs tâches dans les systèmes de conduite autonome. Malgré la simplicité et la clarté de ce paradigme, les performances des méthodes de conduite autonome de bout en bout sur les sous-tâches sont encore loin derrière les méthodes à tâche unique. Dans le même temps, les fonctionnalités de vue à vol d'oiseau (BEV) denses, largement utilisées dans les méthodes de bout en bout précédentes, rendent difficile l'adaptation à davantage de modalités ou de tâches. Un paradigme de conduite autonome de bout en bout (SparseAD) centré sur la recherche clairsemée est proposé ici, dans lequel la recherche clairsemée représente entièrement l'ensemble du scénario de conduite, y compris l'espace, le temps et les tâches, sans aucune représentation BEV dense. Plus précisément, une architecture clairsemée unifiée est conçue pour la connaissance des tâches, notamment la détection, le suivi et la cartographie en ligne. De plus, lourd
