

Comment utiliser l'algorithme de tri classique dans le code Java

L'algorithme de tri est l'un des algorithmes les plus basiques de "Structures de données et algorithmes".
Les algorithmes de tri peuvent être divisés en tri interne et tri externe. Le tri interne consiste à trier les enregistrements de données en mémoire, tandis que le tri externe est dû au fait que les données triées sont très volumineuses et ne peuvent pas accueillir tous les enregistrements triés en même temps pendant le processus de tri. , les données externes doivent être accessibles en direct. Les algorithmes de tri internes courants incluent : le tri par insertion, le tri Hill, le tri par sélection, le tri à bulles, le tri par fusion, le tri rapide, le tri par tas, le tri par base, etc. Résumez avec une image :
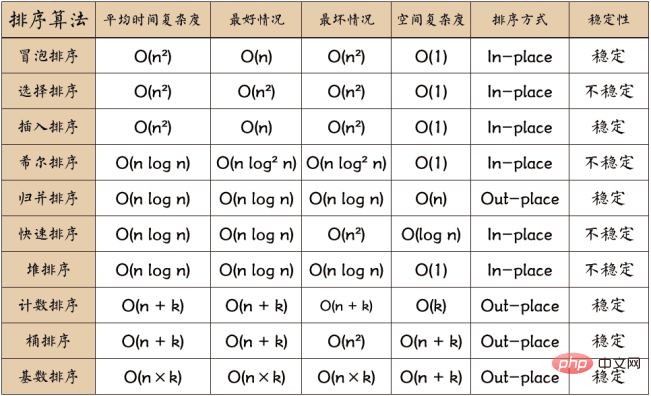
À propos de la complexité temporelle :
tri par ordre carré (O(n2)) Différents types de tri simple : insertion directe, sélection directe et tri à bulles.
Ordre logarithmique linéaire (O(nlog2n)) Tri Tri rapide, tri par tas et tri par fusion.
O(n1+§)) le tri, § est une constante comprise entre 0 et 1. Sorte de colline.
Tri par ordre linéaire (O(n)), tri par base, en plus du tri par seaux et bacs.
À propos de la stabilité :
Algorithmes de tri stables : tri à bulles, tri par insertion, tri par fusion et tri par base.
Pas un algorithme de tri stable : tri par sélection, tri rapide, tri Hill, tri par tas.
Explication des termes :
n : Échelle des données
k : Le nombre de "buckets"
En place : Occupant une mémoire constante, pas de mémoire supplémentaire
Out-place : Occupant de la mémoire supplémentaire
Stabilité : L'ordre de deux valeurs clés égales après le tri est le même que leur ordre avant le tri
1. Tri à bulles
Bubble Sort (Bubble Sort) est également un algorithme de tri simple et intuitif. Il parcourt à plusieurs reprises la séquence à trier, en comparant deux éléments à la fois et en les échangeant s'ils sont dans le mauvais ordre. Le travail de visite du tableau est répété jusqu'à ce qu'aucun échange ne soit plus nécessaire, ce qui signifie que le tableau a été trié. Le nom de cet algorithme vient du fait que les éléments plus petits « flotteront » lentement vers le haut du tableau grâce à l’échange.
En tant que l'un des algorithmes de tri les plus simples, le tri à bulles me donne le même sentiment qu'Abandon apparaît dans un livre de mots. Il se trouve à chaque fois sur la page ***, c'est donc le plus familier. Il existe un autre algorithme d'optimisation pour le tri des bulles, qui consiste à définir un indicateur lorsque les éléments ne sont pas échangés lors d'un parcours de séquence, cela prouve que la séquence est en ordre. Mais cette amélioration ne fait pas grand-chose pour améliorer les performances.
1. Étapes de l'algorithme
Comparez les éléments adjacents. Si le premier est plus grand que le second, échangez-les tous les deux.
Faites de même pour chaque paire d'éléments adjacents, de la première paire au début à la dernière paire à la fin. Une fois cette étape terminée, l'élément *** sera le numéro ***.
Répétez les étapes ci-dessus pour tous les éléments sauf *** un.
Continuez à répéter les étapes ci-dessus pour de moins en moins d'éléments à chaque fois jusqu'à ce qu'il n'y ait plus de paires de nombres à comparer.
2. Démonstration d'animation
3. Quand est le temps le plus rapide
Lorsque les données d'entrée sont déjà en séquence positive (elles sont déjà en séquence positive, qu'est-ce que je veux que vous fassiez avec tri à bulles) Utilisez-le).
4. Quel est le moment le plus lent
Lorsque les données d'entrée sont dans l'ordre inverse (il suffit d'écrire une boucle for pour sortir les données dans l'ordre inverse, pourquoi devrais-je utiliser le tri à bulles ? Suis-je libre ?).
5. Implémentation du code Java
public class BubbleSort implements IArraySort { @Override public int[] sort(int[] sourceArray) throws Exception { // 对 arr 进行拷贝,不改变参数内容 int[] arr = Arrays.copyOf(sourceArray, sourceArray.length); for (int i = 1; i arr[j + 1]) { int tmp = arr[j]; arr[j] = arr[j + 1]; arr[j + 1] = tmp; flag = false; } } if (flag) { break; } } return arr; } }2. Tri par sélection
Le tri par sélection est un algorithme de tri simple et intuitif Quelles que soient les données saisies, la complexité temporelle est O(n²). Ainsi, lors de son utilisation, plus la taille des données est petite, mieux c'est. Le seul avantage est peut-être qu’il n’occupe pas d’espace mémoire supplémentaire.
1. Étapes de l'algorithme
Trouvez d'abord le plus petit (grand) élément de la séquence non triée et stockez-le à la position de départ de la séquence triée
Continuez ensuite à trouver le plus petit (grand) élément de les éléments non triés restants et placez-les à la fin de la séquence triée.
Répétez la deuxième étape jusqu'à ce que tous les éléments soient triés.
2. Démonstration GIF
3. Implémentation du code Java
public class SelectionSort implements IArraySort { @Override public int[] sort(int[] sourceArray) throws Exception { int[] arr = Arrays.copyOf(sourceArray, sourceArray.length); // 总共要经过 N-1 轮比较 for (int i = 0; i <p><strong>3. tri par sélection, mais son principe devrait être le plus simple à comprendre, car quiconque a joué au poker devrait être capable de le comprendre instantanément. Le tri par insertion est l'algorithme de tri le plus simple et le plus intuitif. Il fonctionne en construisant une séquence ordonnée pour les données non triées, il analyse d'avant en arrière dans la séquence triée pour trouver la position correspondante et l'insérer. </strong></p>Le tri par insertion, comme le tri à bulles, dispose également d'un algorithme d'optimisation appelé insertion divisée en deux. <p></p><p><strong>1. 算法步骤</strong></p>将***待排序序列***个元素看做一个有序序列,把第二个元素到***一个元素当成是未排序序列。
从头到尾依次扫描未排序序列,将扫描到的每个元素插入有序序列的适当位置。(如果待插入的元素与有序序列中的某个元素相等,则将待插入元素插入到相等元素的后面。)
2. 动图演示
3. Java 代码实现
public class InsertSort implements IArraySort { @Override public int[] sort(int[] sourceArray) throws Exception { // 对 arr 进行拷贝,不改变参数内容 int[] arr = Arrays.copyOf(sourceArray, sourceArray.length); // 从下标为1的元素开始选择合适的位置插入,因为下标为0的只有一个元素,默认是有序的 for (int i = 1; i 0 && tmp <p><strong>四、希尔排序</strong></p><p>希尔排序,也称递减增量排序算法,是插入排序的一种更高效的改进版本。但希尔排序是非稳定排序算法。</p><p>希尔排序是基于插入排序的以下两点性质而提出改进方法的:</p>插入排序在对几乎已经排好序的数据操作时,效率高,即可以达到线性排序的效率
但插入排序一般来说是低效的,因为插入排序每次只能将数据移动一位
希尔排序的基本思想是:先将整个待排序的记录序列分割成为若干子序列分别进行直接插入排序,待整个序列中的记录“基本有序”时,再对全体记录进行依次直接插入排序。
1. 算法步骤
选择一个增量序列 t1,t2,……,tk,其中 ti > tj, tk = 1;
按增量序列个数 k,对序列进行 k 趟排序;
每趟排序,根据对应的增量 ti,将待排序列分割成若干长度为 m 的子序列,分别对各子表进行直接插入排序。仅增量因子为 1 时,整个序列作为一个表来处理,表长度即为整个序列的长度。
2. Java 代码实现
public class ShellSort implements IArraySort { @Override public int[] sort(int[] sourceArray) throws Exception { // 对 arr 进行拷贝,不改变参数内容 int[] arr = Arrays.copyOf(sourceArray, sourceArray.length); int gap = 1; while (gap 0) { for (int i = gap; i = 0 && arr[j] > tmp) { arr[j + gap] = arr[j]; j -= gap; } arr[j + gap] = tmp; } gap = (int) Math.floor(gap / 3); } return arr; } }五、归并排序
归并排序(Merge sort)是建立在归并操作上的一种有效的排序算法。该算法是采用分治法(Divide and Conquer)的一个非常典型的应用。
作为一种典型的分而治之思想的算法应用,归并排序的实现由两种方法:
自上而下的递归(所有递归的方法都可以用迭代重写,所以就有了第 2 种方法)
自下而上的迭代
在《数据结构与算法 JavaScript 描述》中,作者给出了自下而上的迭代方法。但是对于递归法,作者却认为:
However, it is not possible to do so in JavaScript, as the recursion goes too deep for the language to handle.
然而,在 JavaScript 中这种方式不太可行,因为这个算法的递归深度对它来讲太深了。
说实话,我不太理解这句话。意思是 JavaScript 编译器内存太小,递归太深容易造成内存溢出吗?还望有大神能够指教。
和选择排序一样,归并排序的性能不受输入数据的影响,但表现比选择排序好的多,因为始终都是 O(nlogn) 的时间复杂度。代价是需要额外的内存空间。
1. 算法步骤
申请空间,使其大小为两个已经排序序列之和,该空间用来存放合并后的序列;
设定两个指针,最初位置分别为两个已经排序序列的起始位置;
比较两个指针所指向的元素,选择相对小的元素放入到合并空间,并移动指针到下一位置;
重复步骤 3 直到某一指针达到序列尾;
将另一序列剩下的所有元素直接复制到合并序列尾。
2. 动图演示
3. Java 代码实现
public class MergeSort implements IArraySort { @Override public int[] sort(int[] sourceArray) throws Exception { // 对 arr 进行拷贝,不改变参数内容 int[] arr = Arrays.copyOf(sourceArray, sourceArray.length); if (arr.length 0 && right.length > 0) { if (left[0] 0) { result[i++] = left[0]; left = Arrays.copyOfRange(left, 1, left.length); } while (right.length > 0) { result[i++] = right[0]; right = Arrays.copyOfRange(right, 1, right.length); } return result; } }六、快速排序
快速排序是由东尼·霍尔所发展的一种排序算法。在平均状况下,排序 n 个项目要 Ο(nlogn) 次比较。在最坏状况下则需要 Ο(n2) 次比较,但这种状况并不常见。事实上,快速排序通常明显比其他 Ο(nlogn) 算法更快,因为它的内部循环(inner loop)可以在大部分的架构上很有效率地被实现出来。
快速排序使用分治法(Divide and conquer)策略来把一个串行(list)分为两个子串行(sub-lists)。
快速排序又是一种分而治之思想在排序算法上的典型应用。本质上来看,快速排序应该算是在冒泡排序基础上的递归分治法。
快速排序的名字起的是简单粗暴,因为一听到这个名字你就知道它存在的意义,就是快,而且效率高!它是处理大数据最快的排序算法之一了。虽然 Worst Case 的时间复杂度达到了 O(n²),但是人家就是优秀,在大多数情况下都比平均时间复杂度为 O(n logn) 的排序算法表现要更好,可是这是为什么呢,我也不知道。
快速排序的最坏运行情况是 O(n²),比如说顺序数列的快排。但它的平摊期望时间是 O(nlogn),且 O(nlogn) 记号中隐含的常数因子很小,比复杂度稳定等于 O(nlogn) 的归并排序要小很多。所以,对绝大多数顺序性较弱的随机数列而言,快速排序总是优于归并排序。
1. 算法步骤
从数列中挑出一个元素,称为 “基准”(pivot);
重新排序数列,所有元素比基准值小的摆放在基准前面,所有元素比基准值大的摆在基准的后面(相同的数可以到任一边)。在这个分区退出之后,该基准就处于数列的中间位置。这个称为分区(partition)操作;
递归地(recursive)把小于基准值元素的子数列和大于基准值元素的子数列排序;
递归的***部情形,是数列的大小是零或一,也就是永远都已经被排序好了。虽然一直递归下去,但是这个算法总会退出,因为在每次的迭代(iteration)中,它至少会把一个元素摆到它***的位置去。
2. 动图演示
3. Java 代码实现
public class QuickSort implements IArraySort { @Override public int[] sort(int[] sourceArray) throws Exception { // 对 arr 进行拷贝,不改变参数内容 int[] arr = Arrays.copyOf(sourceArray, sourceArray.length); return quickSort(arr, 0, arr.length - 1); } private int[] quickSort(int[] arr, int left, int right) { if (left <p><strong>七、堆排序</strong></p><p>堆排序(Heapsort)是指利用堆这种数据结构所设计的一种排序算法。堆积是一个近似完全二叉树的结构,并同时满足堆积的性质:即子结点的键值或索引总是小于(或者大于)它的父节点。堆排序可以说是一种利用堆的概念来排序的选择排序。分为两种方法:</p><ol class=" list-paddingleft-2">
<li><p>鸿蒙官方战略合作共建——HarmonyOS技术社区</p></li>
<li><p>大顶堆:每个节点的值都大于或等于其子节点的值,在堆排序算法中用于升序排列;</p></li>
<li><p>小顶堆:每个节点的值都小于或等于其子节点的值,在堆排序算法中用于降序排列;</p></li>
</ol><p>堆排序的平均时间复杂度为 Ο(nlogn)。</p><p><strong>1. 算法步骤</strong></p><ol class=" list-paddingleft-2">
<li><p>鸿蒙官方战略合作共建——HarmonyOS技术社区</p></li>
<li><p>创建一个堆 H[0……n-1];</p></li>
<li><p>把堆首(***值)和堆尾互换;</p></li>
<li><p>把堆的尺寸缩小 1,并调用 shift_down(0),目的是把新的数组顶端数据调整到相应位置;</p></li>
<li><p>重复步骤 2,直到堆的尺寸为 1。</p></li>
</ol><p><strong>2. 动图演示</strong></p><center><img src="/static/imghw/default1.png" data-src="https://img.php.cn/upload/article/000/887/227/168277254995371.gif" class="lazy" alt="Comment utiliser lalgorithme de tri classique dans le code Java"></center><p><strong>3. Java 代码实现</strong></p><pre class="brush:php;toolbar:false">public class HeapSort implements IArraySort { @Override public int[] sort(int[] sourceArray) throws Exception { // 对 arr 进行拷贝,不改变参数内容 int[] arr = Arrays.copyOf(sourceArray, sourceArray.length); int len = arr.length; buildMaxHeap(arr, len); for (int i = len - 1; i > 0; i--) { swap(arr, 0, i); len--; heapify(arr, 0, len); } return arr; } private void buildMaxHeap(int[] arr, int len) { for (int i = (int) Math.floor(len / 2); i >= 0; i--) { heapify(arr, i, len); } } private void heapify(int[] arr, int i, int len) { int left = 2 * i + 1; int right = 2 * i + 2; int largest = i; if (left arr[largest]) { largest = left; } if (right arr[largest]) { largest = right; } if (largest != i) { swap(arr, i, largest); heapify(arr, largest, len); } } private void swap(int[] arr, int i, int j) { int temp = arr[i]; arr[i] = arr[j]; arr[j] = temp; } }八、计数排序
计数排序的核心在于将输入的数据值转化为键存储在额外开辟的数组空间中。作为一种线性时间复杂度的排序,计数排序要求输入的数据必须是有确定范围的整数。
1. 动图演示
2. Java 代码实现
public class CountingSort implements IArraySort { @Override public int[] sort(int[] sourceArray) throws Exception { // 对 arr 进行拷贝,不改变参数内容 int[] arr = Arrays.copyOf(sourceArray, sourceArray.length); int maxValue = getMaxValue(arr); return countingSort(arr, maxValue); } private int[] countingSort(int[] arr, int maxValue) { int bucketLen = maxValue + 1; int[] bucket = new int[bucketLen]; for (int value : arr) { bucket[value]++; } int sortedIndex = 0; for (int j = 0; j 0) { arr[sortedIndex++] = j; bucket[j]--; } } return arr; } private int getMaxValue(int[] arr) { int maxValue = arr[0]; for (int value : arr) { if (maxValue <p><strong>九、桶排序</strong></p><p>桶排序是计数排序的升级版。它利用了函数的映射关系,高效与否的关键就在于这个映射函数的确定。为了使桶排序更加高效,我们需要做到这两点:</p>在额外空间充足的情况下,尽量增大桶的数量
使用的映射函数能够将输入的 N 个数据均匀的分配到 K 个桶中
同时,对于桶中元素的排序,选择何种比较排序算法对于性能的影响至关重要。
1. 什么时候最快
当输入的数据可以均匀的分配到每一个桶中。
2. 什么时候最慢
当输入的数据被分配到了同一个桶中。
3. Java 代码实现
public class BucketSort implements IArraySort { private static final InsertSort insertSort = new InsertSort(); @Override public int[] sort(int[] sourceArray) throws Exception { // 对 arr 进行拷贝,不改变参数内容 int[] arr = Arrays.copyOf(sourceArray, sourceArray.length); return bucketSort(arr, 5); } private int[] bucketSort(int[] arr, int bucketSize) throws Exception { if (arr.length == 0) { return arr; } int minValue = arr[0]; int maxValue = arr[0]; for (int value : arr) { if (value maxValue) { maxValue = value; } } int bucketCount = (int) Math.floor((maxValue - minValue) / bucketSize) + 1; int[][] buckets = new int[bucketCount][0]; // 利用映射函数将数据分配到各个桶中 for (int i = 0; i <p><strong>十、基数排序</strong></p><p>基数排序是一种非比较型整数排序算法,其原理是将整数按位数切割成不同的数字,然后按每个位数分别比较。由于整数也可以表达字符串(比如名字或日期)和特定格式的浮点数,所以基数排序也不是只能使用于整数。</p><p><strong>1. 基数排序 vs 计数排序 vs 桶排序</strong></p><p>基数排序有两种方法:</p><p>这三种排序算法都利用了桶的概念,但对桶的使用方法上有明显差异:</p>基数排序:根据键值的每位数字来分配桶;
计数排序:每个桶只存储单一键值;
桶排序:每个桶存储一定范围的数值;
2. LSD 基数排序动图演示

3. Java 代码实现
/** * 基数排序 */ public class RadixSort implements IArraySort { @Override public int[] sort(int[] sourceArray) throws Exception { // 对 arr 进行拷贝,不改变参数内容 int[] arr = Arrays.copyOf(sourceArray, sourceArray.length); int maxDigit = getMaxDigit(arr); return radixSort(arr, maxDigit); } /** * 获取***位数 */ private int getMaxDigit(int[] arr) { int maxValue = getMaxValue(arr); return getNumLenght(maxValue); } private int getMaxValue(int[] arr) { int maxValue = arr[0]; for (int value : arr) { if (maxValue Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Nombre parfait en Java
Aug 30, 2024 pm 04:28 PM
Nombre parfait en Java
Aug 30, 2024 pm 04:28 PM
Guide du nombre parfait en Java. Nous discutons ici de la définition, comment vérifier le nombre parfait en Java ?, des exemples d'implémentation de code.
 Weka en Java
Aug 30, 2024 pm 04:28 PM
Weka en Java
Aug 30, 2024 pm 04:28 PM
Guide de Weka en Java. Nous discutons ici de l'introduction, de la façon d'utiliser Weka Java, du type de plate-forme et des avantages avec des exemples.
 Numéro de Smith en Java
Aug 30, 2024 pm 04:28 PM
Numéro de Smith en Java
Aug 30, 2024 pm 04:28 PM
Guide du nombre de Smith en Java. Nous discutons ici de la définition, comment vérifier le numéro Smith en Java ? exemple avec implémentation de code.
 Questions d'entretien chez Java Spring
Aug 30, 2024 pm 04:29 PM
Questions d'entretien chez Java Spring
Aug 30, 2024 pm 04:29 PM
Dans cet article, nous avons conservé les questions d'entretien Java Spring les plus posées avec leurs réponses détaillées. Pour que vous puissiez réussir l'interview.
 Break or Return of Java 8 Stream Forach?
Feb 07, 2025 pm 12:09 PM
Break or Return of Java 8 Stream Forach?
Feb 07, 2025 pm 12:09 PM
Java 8 présente l'API Stream, fournissant un moyen puissant et expressif de traiter les collections de données. Cependant, une question courante lors de l'utilisation du flux est: comment se casser ou revenir d'une opération FOREAK? Les boucles traditionnelles permettent une interruption ou un retour précoce, mais la méthode Foreach de Stream ne prend pas directement en charge cette méthode. Cet article expliquera les raisons et explorera des méthodes alternatives pour la mise en œuvre de terminaison prématurée dans les systèmes de traitement de flux. Lire plus approfondie: Améliorations de l'API Java Stream Comprendre le flux Forach La méthode foreach est une opération terminale qui effectue une opération sur chaque élément du flux. Son intention de conception est
 Horodatage à ce jour en Java
Aug 30, 2024 pm 04:28 PM
Horodatage à ce jour en Java
Aug 30, 2024 pm 04:28 PM
Guide de TimeStamp to Date en Java. Ici, nous discutons également de l'introduction et de la façon de convertir l'horodatage en date en Java avec des exemples.
 Programme Java pour trouver le volume de la capsule
Feb 07, 2025 am 11:37 AM
Programme Java pour trouver le volume de la capsule
Feb 07, 2025 am 11:37 AM
Les capsules sont des figures géométriques tridimensionnelles, composées d'un cylindre et d'un hémisphère aux deux extrémités. Le volume de la capsule peut être calculé en ajoutant le volume du cylindre et le volume de l'hémisphère aux deux extrémités. Ce tutoriel discutera de la façon de calculer le volume d'une capsule donnée en Java en utilisant différentes méthodes. Formule de volume de capsule La formule du volume de la capsule est la suivante: Volume de capsule = volume cylindrique volume de deux hémisphères volume dans, R: Le rayon de l'hémisphère. H: La hauteur du cylindre (à l'exclusion de l'hémisphère). Exemple 1 entrer Rayon = 5 unités Hauteur = 10 unités Sortir Volume = 1570,8 unités cubes expliquer Calculer le volume à l'aide de la formule: Volume = π × r2 × h (4
 Comment exécuter votre première application Spring Boot dans Spring Tool Suite?
Feb 07, 2025 pm 12:11 PM
Comment exécuter votre première application Spring Boot dans Spring Tool Suite?
Feb 07, 2025 pm 12:11 PM
Spring Boot simplifie la création d'applications Java robustes, évolutives et prêtes à la production, révolutionnant le développement de Java. Son approche "Convention sur la configuration", inhérente à l'écosystème de ressort, minimise la configuration manuelle, allo
