
 développement back-end
Tutoriel Python
Comment utiliser l'outil EasyOCR pour reconnaître le texte d'une image en Python
développement back-end
Tutoriel Python
Comment utiliser l'outil EasyOCR pour reconnaître le texte d'une image en Python
Comment utiliser l'outil EasyOCR pour reconnaître le texte d'une image en Python

Qu'est-ce qu'EasyOCR ?
Description : EasyOCR est un module Python permettant d'extraire du texte à partir d'images. Il s'agit d'un OCR à usage général qui peut lire à la fois le texte d'une scène naturelle et le texte dense dans les documents. Prend actuellement en charge plus de 80 langues et tous les scripts d'écriture populaires, notamment : le latin, le chinois, l'arabe, le sanskrit, le cyrillique, etc.
EasyOCR est un outil de reconnaissance optique de caractères (OCR) implémenté dans PyTorch.
Q : Que pouvez-vous faire avec EasyOCR ?
Description : EasyOCR prend en charge deux modes de fonctionnement, l'un est un processeur couramment utilisé et l'autre nécessite la prise en charge du GPU et l'environnement CUDA doit être installé. langue et texte dans les images, comme la reconnaissance d'images et la reconnaissance de plaques d'immatriculation de véhicules dans des mini-programmes (par exemple, un système de gestion des dettes automobiles).
Installer EasyOCR
Dans la fenêtre de commande, utilisez pip pour installer la version stable d'EasyOCR.
pip install easyocr
Lorsque vous utilisez EasyOCR
import easyocr
reader = easyocr.Reader(
['ch_sim', 'en'],
gpu=False,
model_storage_directory='model/.',
user_network_directory='model/.',
)
result = reader.readtext('examples/chinese.jpg')pour exécuter le code ci-dessus, le modèle de détection et de reconnaissance sera automatiquement téléchargé dans le répertoire spécifié via le réseau.
['ch_sim', 'en'], : Spécifiez la langue reconnue
gpu=False, : Définissez s'il faut utiliser le GPU (EasyOCR fonctionne plus efficacement sur le GPU, défini lorsqu'il n'y a pas de GPU ou un GPU insuffisant mémoire) Faux)
model_storage_directory='model/.', : Le chemin de stockage du modèle de détection et de reconnaissance (la valeur par défaut est stockée dans le répertoire ~/.EasyOCR/model lorsqu'elle n'est pas définie)
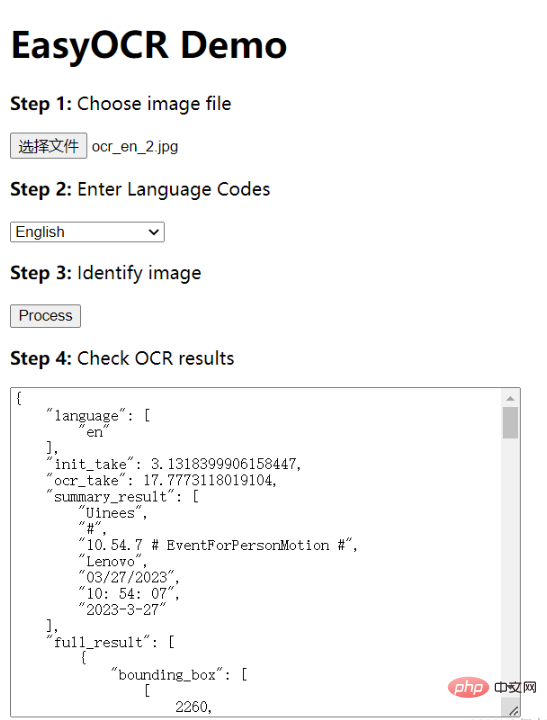
Résultats de la reconnaissance result</code > est une liste, chaque élément de la liste est un résultat de reconnaissance d'une longueur de <code>3, tel que ([[189, 75], [469, 75], [469, 165 ], [189, 165]], 'Yuyuan Road', 0.3754989504814148), qui sont un cadre de délimitation, un texte détecté et Valeur de confiance. result 是一个列表,列表中的每一项都是一个长度为 3 的识别结果,例如 ([[189, 75], [469, 75], [469, 165], [189, 165]], '愚园路', 0.3754989504814148),它们分别是 边界框、检测到的文本 和 置信度 值。
easyocr-server
EasyOCR 服务器是一个用于从图像中提取文本。它是一种通用的 OCR,既可以读取自然场景文本,也可以读取文档中的密集文本。目前支持 80+ 种语言,并且还在扩展。
安装步骤
步骤 0. 从 GitHub 下载 easyocr-server 并安装。
git clone https://github.com/hekaiyou/easyocr-server.git
步骤 1. 使用 PyPI 安装 easyocr、 bottle 和 gevent 模块。
cd easyocr-server pip install -r requirements.txt
验证安装
python main.py
Browser: http://localhost:8080/ocr/
CMD:
easyocr-servercurl http://localhost:8080/ocr/ -F "language=en" -F "img_file=@examples/english.png"
 Étape 0. Téléchargez easyocr-server depuis GitHub et installez-le.
Étape 0. Téléchargez easyocr-server depuis GitHub et installez-le.
docker build -t easyocr-server:latest .
Étape 1. Installez les modules easyocr, bottle et gevent à l'aide de PyPI.
docker run -it -v {DATA_DIR}:/workspace/model -p 8083:8080 easyocr-server:latestVérifier l'installation
rrreee🎜Navigateur : http://localhost:8080/ocr/🎜🎜🎜🎜CMD :curl http:// localhost:8080/ocr/ -F "langue=en" -F "img_file=@examples/english.png"🎜🎜🎜🎜Après une vérification réussie, vous devriez pouvoir voir les résultats d'inférence imprimés dans le navigateur . 🎜🎜🎜🎜🎜Service de déploiement via Docker🎜🎜Nous fournissons un Dockerfile pour construire l'image. 🎜rrreee🎜Exécutez-le. 🎜docker run -it -v {DATA_DIR}:/workspace/model -p 8083:8080 easyocr-server:latest| Language | Code Name |
|---|---|
| Abaza | abq |
| Adyghe | ady |
| Afrikaans | af |
| Angika | ang |
| Arabic | ar |
| Assamese | as |
| Avar | ava |
| Azerbaijani | az |
| Belarusian | be |
| Bulgarian | bg |
| Bihari | bh |
| Bhojpuri | bho |
| Bengali | bn |
| Bosnian | bs |
| Simplified Chinese | ch_sim |
| Traditional Chinese | ch_tra |
| Chechen | che |
| Czech | cs |
| Welsh | cy |
| Danish | da |
| Dargwa | dar |
| German | de |
| English | en |
| Spanish | es |
| Estonian | et |
| Persian (Farsi) | fa |
| French | fr |
| Irish | ga |
| Goan Konkani | gom |
| Hindi | hi |
| Croatian | hr |
| Hungarian | hu |
| Indonesian | id |
| Ingush | inh |
| Icelandic | is |
| Italian | it |
| Japanese | ja |
| Kabardian | kbd |
| Kannada | kn |
| Korean | ko |
| Kurdish | ku |
| Latin | la |
| Lak | lbe |
| Lezghian | lez |
| Lithuanian | lt |
| Latvian | lv |
| Magahi | mah |
| Maithili | mai |
| Maori | mi |
| Mongolian | mn |
| Marathi | mr |
| Malay | ms |
| Maltese | mt |
| Nepali | ne |
| Newari | new |
| Dutch | nl |
| Norwegian | no |
| Occitan | oc |
| Pali | pi |
| Polish | pl |
| Portuguese | pt |
| Romanian | ro |
| Russian | ru |
| Serbian (cyrillic) | rs_cyrillic |
| Serbian (latin) | rs_latin |
| Nagpuri | sck |
| Slovak | sk |
| Slovenian | sl |
| Albanian | sq |
| Swedish | sv |
| Swahili | sw |
| Tamil | ta |
| Tabassaran | tab |
| Telugu | te |
| Thai | th |
| Tajik | tjk |
| Tagalog | tl |
| Turkish | tr |
| Uyghur | ug |
| Ukranian | uk |
| Urdu | ur |
| Uzbek | uz |
| Vietnamese | vi |
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 MySQL doit-il payer
Apr 08, 2025 pm 05:36 PM
MySQL doit-il payer
Apr 08, 2025 pm 05:36 PM
MySQL a une version communautaire gratuite et une version d'entreprise payante. La version communautaire peut être utilisée et modifiée gratuitement, mais le support est limité et convient aux applications avec des exigences de stabilité faibles et des capacités techniques solides. L'Enterprise Edition fournit une prise en charge commerciale complète pour les applications qui nécessitent une base de données stable, fiable et haute performance et disposées à payer pour le soutien. Les facteurs pris en compte lors du choix d'une version comprennent la criticité des applications, la budgétisation et les compétences techniques. Il n'y a pas d'option parfaite, seulement l'option la plus appropriée, et vous devez choisir soigneusement en fonction de la situation spécifique.
 Comment les plumes PS contrôlent-elles la douceur de la transition?
Apr 06, 2025 pm 07:33 PM
Comment les plumes PS contrôlent-elles la douceur de la transition?
Apr 06, 2025 pm 07:33 PM
La clé du contrôle des plumes est de comprendre sa nature progressive. Le PS lui-même ne fournit pas la possibilité de contrôler directement la courbe de gradient, mais vous pouvez ajuster de manière flexible le rayon et la douceur du gradient par plusieurs plumes, des masques correspondants et des sélections fines pour obtenir un effet de transition naturel.
 Comment utiliser MySQL après l'installation
Apr 08, 2025 am 11:48 AM
Comment utiliser MySQL après l'installation
Apr 08, 2025 am 11:48 AM
L'article présente le fonctionnement de la base de données MySQL. Tout d'abord, vous devez installer un client MySQL, tel que MySQLWorkBench ou le client de ligne de commande. 1. Utilisez la commande MySQL-UROot-P pour vous connecter au serveur et connecter avec le mot de passe du compte racine; 2. Utilisez Createdatabase pour créer une base de données et utilisez Sélectionner une base de données; 3. Utilisez CreateTable pour créer une table, définissez des champs et des types de données; 4. Utilisez InsertInto pour insérer des données, remettre en question les données, mettre à jour les données par mise à jour et supprimer les données par Supprimer. Ce n'est qu'en maîtrisant ces étapes, en apprenant à faire face à des problèmes courants et à l'optimisation des performances de la base de données que vous pouvez utiliser efficacement MySQL.
 Comment configurer des plumes de PS?
Apr 06, 2025 pm 07:36 PM
Comment configurer des plumes de PS?
Apr 06, 2025 pm 07:36 PM
La plume PS est un effet flou du bord de l'image, qui est réalisé par la moyenne pondérée des pixels dans la zone de bord. Le réglage du rayon de la plume peut contrôler le degré de flou, et plus la valeur est grande, plus elle est floue. Le réglage flexible du rayon peut optimiser l'effet en fonction des images et des besoins. Par exemple, l'utilisation d'un rayon plus petit pour maintenir les détails lors du traitement des photos des caractères et l'utilisation d'un rayon plus grand pour créer une sensation brumeuse lorsque le traitement de l'art fonctionne. Cependant, il convient de noter que trop grand, le rayon peut facilement perdre des détails de bord, et trop petit, l'effet ne sera pas évident. L'effet de plumes est affecté par la résolution de l'image et doit être ajusté en fonction de la compréhension de l'image et de la saisie de l'effet.
 Le fichier de téléchargement MySQL est endommagé et ne peut pas être installé. Réparer la solution
Apr 08, 2025 am 11:21 AM
Le fichier de téléchargement MySQL est endommagé et ne peut pas être installé. Réparer la solution
Apr 08, 2025 am 11:21 AM
Le fichier de téléchargement mysql est corrompu, que dois-je faire? Hélas, si vous téléchargez MySQL, vous pouvez rencontrer la corruption des fichiers. Ce n'est vraiment pas facile ces jours-ci! Cet article expliquera comment résoudre ce problème afin que tout le monde puisse éviter les détours. Après l'avoir lu, vous pouvez non seulement réparer le package d'installation MySQL endommagé, mais aussi avoir une compréhension plus approfondie du processus de téléchargement et d'installation pour éviter de rester coincé à l'avenir. Parlons d'abord de la raison pour laquelle le téléchargement des fichiers est endommagé. Il y a de nombreuses raisons à cela. Les problèmes de réseau sont le coupable. L'interruption du processus de téléchargement et l'instabilité du réseau peut conduire à la corruption des fichiers. Il y a aussi le problème avec la source de téléchargement elle-même. Le fichier serveur lui-même est cassé, et bien sûr, il est également cassé si vous le téléchargez. De plus, la numérisation excessive "passionnée" de certains logiciels antivirus peut également entraîner une corruption des fichiers. Problème de diagnostic: déterminer si le fichier est vraiment corrompu
 Solutions au service qui ne peuvent pas être démarrées après l'installation de MySQL
Apr 08, 2025 am 11:18 AM
Solutions au service qui ne peuvent pas être démarrées après l'installation de MySQL
Apr 08, 2025 am 11:18 AM
MySQL a refusé de commencer? Ne paniquez pas, vérifions-le! De nombreux amis ont découvert que le service ne pouvait pas être démarré après avoir installé MySQL, et ils étaient si anxieux! Ne vous inquiétez pas, cet article vous emmènera pour le faire face calmement et découvrez le cerveau derrière! Après l'avoir lu, vous pouvez non seulement résoudre ce problème, mais aussi améliorer votre compréhension des services MySQL et vos idées de problèmes de dépannage, et devenir un administrateur de base de données plus puissant! Le service MySQL n'a pas réussi et il y a de nombreuses raisons, allant des erreurs de configuration simples aux problèmes système complexes. Commençons par les aspects les plus courants. Connaissances de base: une brève description du processus de démarrage du service MySQL Service Startup. Autrement dit, le système d'exploitation charge les fichiers liés à MySQL, puis démarre le démon mysql. Cela implique la configuration
 MySQL ne peut pas être installé après le téléchargement
Apr 08, 2025 am 11:24 AM
MySQL ne peut pas être installé après le téléchargement
Apr 08, 2025 am 11:24 AM
Les principales raisons de la défaillance de l'installation de MySQL sont les suivantes: 1. Problèmes d'autorisation, vous devez s'exécuter en tant qu'administrateur ou utiliser la commande sudo; 2. Des dépendances sont manquantes et vous devez installer des packages de développement pertinents; 3. Conflits du port, vous devez fermer le programme qui occupe le port 3306 ou modifier le fichier de configuration; 4. Le package d'installation est corrompu, vous devez télécharger et vérifier l'intégrité; 5. La variable d'environnement est mal configurée et les variables d'environnement doivent être correctement configurées en fonction du système d'exploitation. Résolvez ces problèmes et vérifiez soigneusement chaque étape pour installer avec succès MySQL.
 Comment optimiser les performances de la base de données après l'installation de MySQL
Apr 08, 2025 am 11:36 AM
Comment optimiser les performances de la base de données après l'installation de MySQL
Apr 08, 2025 am 11:36 AM
L'optimisation des performances MySQL doit commencer à partir de trois aspects: configuration d'installation, indexation et optimisation des requêtes, surveillance et réglage. 1. Après l'installation, vous devez ajuster le fichier my.cnf en fonction de la configuration du serveur, tel que le paramètre innodb_buffer_pool_size, et fermer query_cache_size; 2. Créez un index approprié pour éviter les index excessifs et optimiser les instructions de requête, telles que l'utilisation de la commande Explication pour analyser le plan d'exécution; 3. Utilisez le propre outil de surveillance de MySQL (ShowProcessList, Showstatus) pour surveiller la santé de la base de données, et sauvegarde régulièrement et organisez la base de données. Ce n'est qu'en optimisant en continu ces étapes que les performances de la base de données MySQL peuvent être améliorées.
