
 développement back-end
Tutoriel Python
Algorithme de clustering basé sur la projection sur des ensembles convexes (POCS)
développement back-end
Tutoriel Python
Algorithme de clustering basé sur la projection sur des ensembles convexes (POCS)
Algorithme de clustering basé sur la projection sur des ensembles convexes (POCS)

POCS : Projections sur des ensembles convexes. En mathématiques, un ensemble convexe est un ensemble dans lequel tout segment de droite entre deux points quelconques se trouve dans l'ensemble. La projection est l'opération consistant à mapper un point sur un sous-espace dans un autre espace. Étant donné un ensemble convexe et un point, vous opérez en trouvant la projection du point sur l'ensemble convexe. La projection est le point de l'ensemble convexe qui est le plus proche du point et peut être calculée en minimisant la distance entre ce point et tout autre point de l'ensemble convexe. Puisqu'il s'agit d'une projection, nous pouvons mapper les caractéristiques sur un ensemble convexe dans un autre espace, afin que des opérations telles que le regroupement ou la réduction de dimensionnalité puissent être effectuées.
Cet article passe en revue un algorithme de clustering basé sur la méthode de projection d'ensembles convexes, c'est-à-dire un algorithme de clustering basé sur POCS. L'article original a été publié à l'IWIS2022.
Ensemble convexe
Un ensemble convexe est défini comme un ensemble de points de données, dans lequel le segment de ligne reliant deux points x1 et x2 quelconques dans l'ensemble est complètement inclus dans cet ensemble. Selon la définition de l'ensemble convexe, l'ensemble vide ∅, l'ensemble simple, le segment de droite, l'hyperplan et la sphère euclidienne sont tous considérés comme des ensembles convexes. Un point de données est également considéré comme un ensemble convexe car il s'agit d'un ensemble singleton (un ensemble avec un seul élément). Cela ouvre une nouvelle voie pour appliquer le concept de POCS aux points de données clusterisés.
Projection d'ensembles convexes (POCS)
Les méthodes POCS peuvent être grossièrement divisées en deux types : alternées et parallèles.
1. POC alterné
Partez de n'importe quel point de l'espace de données, et la projection alternée de ce point vers deux (ou plus) ensembles convexes qui se croisent convergeront vers un point dans l'intersection de l'ensemble, comme la figure suivante :
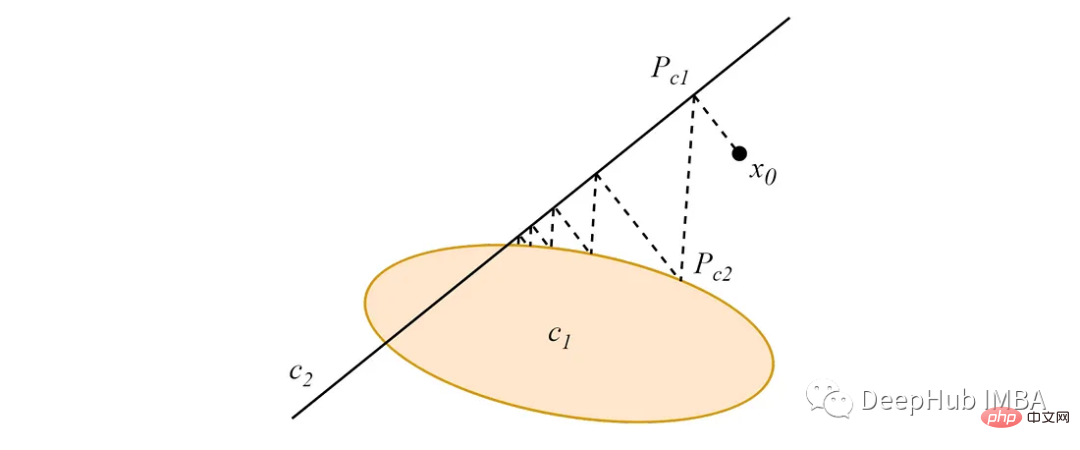
Lorsque les ensembles convexes sont disjoints, les projections alternées convergeront vers des cycles limites gloutons qui dépendent de l'ordre de projection.
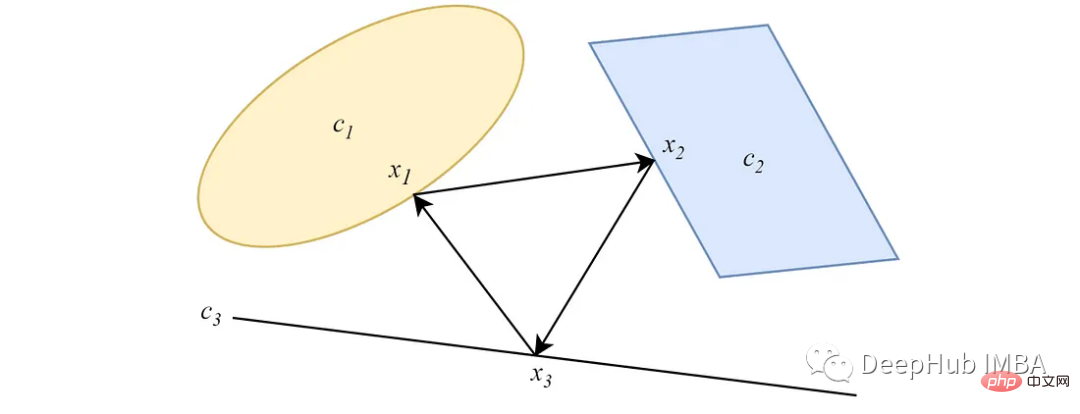
2. POCS parallèles
Différent de la forme alternée, les POCS parallèles projettent simultanément des points de données vers tous les ensembles convexes, et chaque projection a un poids important. Pour deux ensembles convexes sécants non vides, similaire à la version alternée, la projection parallèle converge vers un point à l'intersection des ensembles.
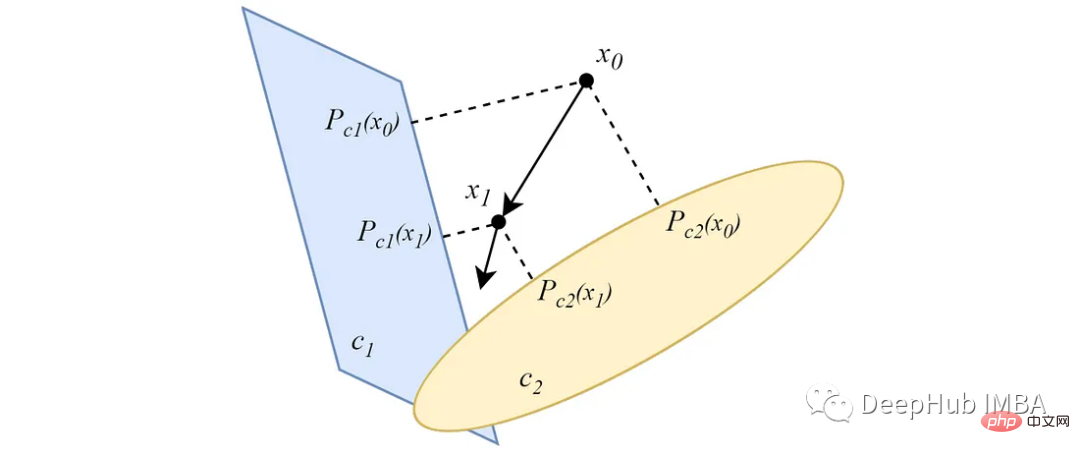
Dans le cas où les ensembles convexes ne se coupent pas, la projection convergera vers une solution minimale. L’idée principale de l’algorithme de clustering basé sur les POC vient de cette fonctionnalité.
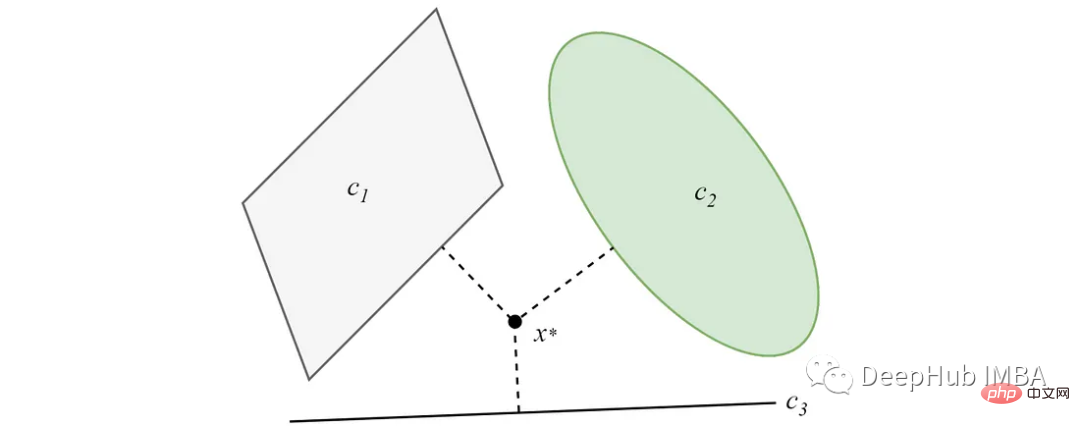
Pour plus de détails sur les POCS, vous pouvez consulter l'article original
Algorithme de clustering basé sur les POC
Profitant de la convergence de la méthode POCS parallèle, l'auteur de l'article a proposé un algorithme de clustering très simple mais efficace dans une certaine mesure. Algorithme de classe. L'algorithme fonctionne de manière similaire à l'algorithme K-Means classique, mais il existe des différences dans la manière dont chaque point de données est traité : l'algorithme K-Means pondère l'importance de chaque point de données de la même manière, mais l'algorithme de clustering basé sur les POC. Chaque point de données est pondéré différemment en importance, qui est proportionnelle à la distance entre le point de données et le prototype du cluster.
Le pseudo-code de l'algorithme est le suivant :

Résultats expérimentaux
L'auteur a testé les performances de l'algorithme de clustering basé sur les POC sur certains ensembles de données de référence publiques. Le tableau ci-dessous résume les descriptions de ces ensembles de données.
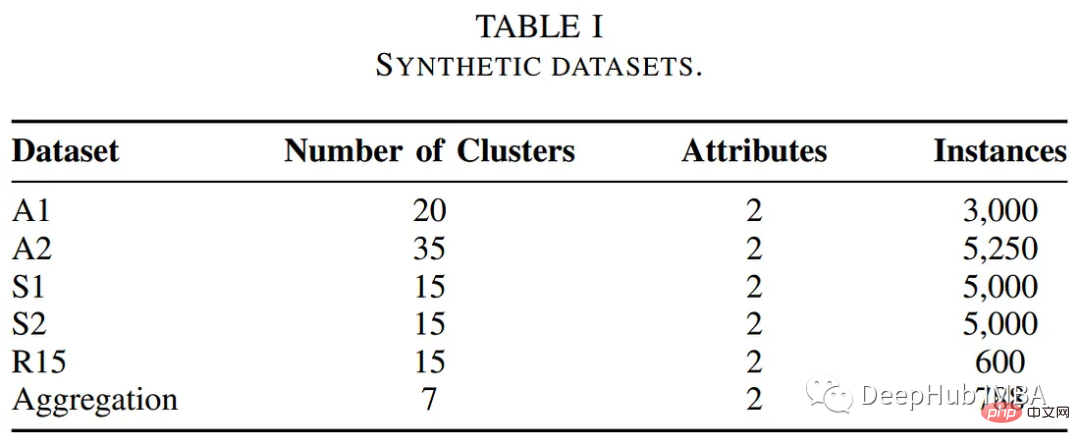
L'auteur a comparé les performances de l'algorithme de clustering basé sur les POC avec d'autres méthodes de clustering traditionnelles, notamment les algorithmes k-means et flous c-means. Le tableau suivant résume l'évaluation en termes de temps d'exécution et d'erreur de clustering.
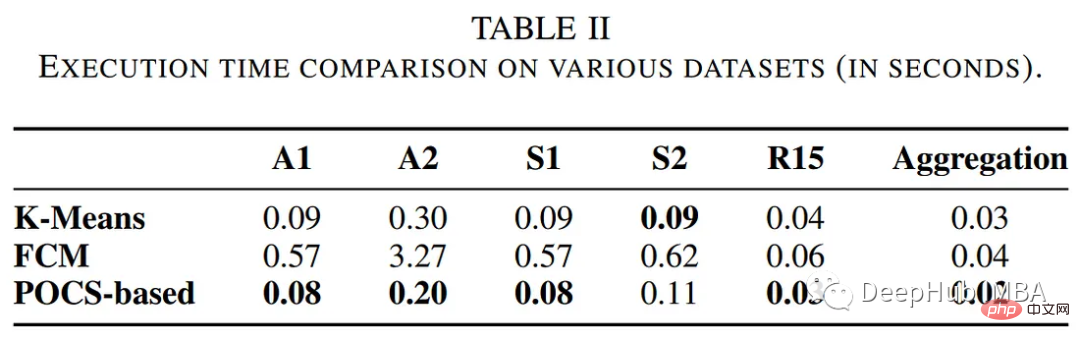
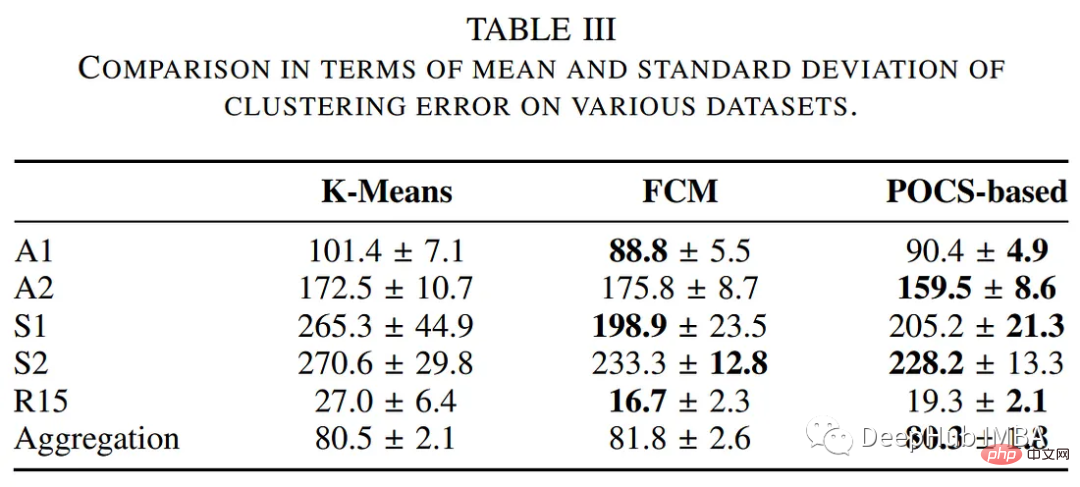
Les résultats du clustering sont présentés ci-dessous :

Exemple de code
Nous utilisons cet algorithme sur un ensemble de données très simple. L'auteur a publié un package à usage direct, que nous pouvons utiliser directement pour des applications :
pip install pocs-based-clustering
Créez un ensemble de données simple de 5000 points de données centré sur 10 clusters :
# Import packages import time import matplotlib.pyplot as plt from sklearn.datasets import make_blobs from pocs_based_clustering.tools import clustering # Generate a simple dataset num_clusters = 10 X, y = make_blobs(n_samples=5000, centers=num_clusters, cluster_std=0.5, random_state=0) plt.figure(figsize=(8,8)) plt.scatter(X[:, 0], X[:, 1], s=50) plt.show()

Effectuez un clustering et affichez les résultats :
# POSC-based Clustering Algorithm centroids, labels = clustering(X, num_clusters, 100) # Display results plt.figure(figsize=(8,8)) plt.scatter(X[:, 0], X[:, 1], c=labels, s=50, cmap='viridis') plt.scatter(centroids[:, 0], centroids[:, 1], s=100, c='red') plt.show()

总结
我们简要回顾了一种简单而有效的基于投影到凸集(POCS)方法的聚类技术,称为基于POCS的聚类算法。该算法利用POCS的收敛特性应用于聚类任务,并在一定程度上实现了可行的改进。在一些基准数据集上验证了该算法的有效性。
论文的地址如下:https://arxiv.org/abs/2208.08888
作者发布的源代码在这里:https://github.com/tranleanh/pocs-based-clustering
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)
Sujets chauds



 CLIP-BEVFormer : superviser explicitement la structure BEVFormer pour améliorer les performances de détection à longue traîne
Mar 26, 2024 pm 12:41 PM
CLIP-BEVFormer : superviser explicitement la structure BEVFormer pour améliorer les performances de détection à longue traîne
Mar 26, 2024 pm 12:41 PM
Écrit ci-dessus et compréhension personnelle de l'auteur : À l'heure actuelle, dans l'ensemble du système de conduite autonome, le module de perception joue un rôle essentiel. Le véhicule autonome roulant sur la route ne peut obtenir des résultats de perception précis que via le module de perception en aval. dans le système de conduite autonome, prend des jugements et des décisions comportementales opportuns et corrects. Actuellement, les voitures dotées de fonctions de conduite autonome sont généralement équipées d'une variété de capteurs d'informations de données, notamment des capteurs de caméra à vision panoramique, des capteurs lidar et des capteurs radar à ondes millimétriques pour collecter des informations selon différentes modalités afin d'accomplir des tâches de perception précises. L'algorithme de perception BEV basé sur la vision pure est privilégié par l'industrie en raison de son faible coût matériel et de sa facilité de déploiement, et ses résultats peuvent être facilement appliqués à diverses tâches en aval.
 Implémentation d'algorithmes d'apprentissage automatique en C++ : défis et solutions courants
Jun 03, 2024 pm 01:25 PM
Implémentation d'algorithmes d'apprentissage automatique en C++ : défis et solutions courants
Jun 03, 2024 pm 01:25 PM
Les défis courants rencontrés par les algorithmes d'apprentissage automatique en C++ incluent la gestion de la mémoire, le multithread, l'optimisation des performances et la maintenabilité. Les solutions incluent l'utilisation de pointeurs intelligents, de bibliothèques de threads modernes, d'instructions SIMD et de bibliothèques tierces, ainsi que le respect des directives de style de codage et l'utilisation d'outils d'automatisation. Des cas pratiques montrent comment utiliser la bibliothèque Eigen pour implémenter des algorithmes de régression linéaire, gérer efficacement la mémoire et utiliser des opérations matricielles hautes performances.
 Explorez les principes sous-jacents et la sélection d'algorithmes de la fonction de tri C++
Apr 02, 2024 pm 05:36 PM
Explorez les principes sous-jacents et la sélection d'algorithmes de la fonction de tri C++
Apr 02, 2024 pm 05:36 PM
La couche inférieure de la fonction de tri C++ utilise le tri par fusion, sa complexité est O(nlogn) et propose différents choix d'algorithmes de tri, notamment le tri rapide, le tri par tas et le tri stable.
 Pourquoi est-il difficile d'implémenter des fonctions de type collection en langage Go ?
Mar 24, 2024 am 11:57 AM
Pourquoi est-il difficile d'implémenter des fonctions de type collection en langage Go ?
Mar 24, 2024 am 11:57 AM
Il est difficile d’implémenter des fonctions de type collection dans le langage Go, ce qui pose problème à de nombreux développeurs. Comparé à d'autres langages de programmation tels que Python ou Java, le langage Go n'a pas de types de collection intégrés, tels que set, map, etc., ce qui pose certains défis aux développeurs lors de la mise en œuvre des fonctions de collection. Voyons d’abord pourquoi il est difficile d’implémenter des fonctionnalités de type collection directement dans le langage Go. Dans le langage Go, les structures de données les plus couramment utilisées sont les tranches et les cartes. Elles peuvent compléter des fonctions de type collection, mais.
 Algorithme de détection amélioré : pour la détection de cibles dans des images de télédétection optique haute résolution
Jun 06, 2024 pm 12:33 PM
Algorithme de détection amélioré : pour la détection de cibles dans des images de télédétection optique haute résolution
Jun 06, 2024 pm 12:33 PM
01Aperçu des perspectives Actuellement, il est difficile d'atteindre un équilibre approprié entre efficacité de détection et résultats de détection. Nous avons développé un algorithme YOLOv5 amélioré pour la détection de cibles dans des images de télédétection optique haute résolution, en utilisant des pyramides de caractéristiques multicouches, des stratégies de têtes de détection multiples et des modules d'attention hybrides pour améliorer l'effet du réseau de détection de cibles dans les images de télédétection optique. Selon l'ensemble de données SIMD, le mAP du nouvel algorithme est 2,2 % meilleur que YOLOv5 et 8,48 % meilleur que YOLOX, permettant ainsi d'obtenir un meilleur équilibre entre les résultats de détection et la vitesse. 02 Contexte et motivation Avec le développement rapide de la technologie de télédétection, les images de télédétection optique à haute résolution ont été utilisées pour décrire de nombreux objets à la surface de la Terre, notamment des avions, des voitures, des bâtiments, etc. Détection d'objets dans l'interprétation d'images de télédétection
 L'intelligence artificielle peut-elle prédire la criminalité ? Explorez les capacités de CrimeGPT
Mar 22, 2024 pm 10:10 PM
L'intelligence artificielle peut-elle prédire la criminalité ? Explorez les capacités de CrimeGPT
Mar 22, 2024 pm 10:10 PM
La convergence de l’intelligence artificielle (IA) et des forces de l’ordre ouvre de nouvelles possibilités en matière de prévention et de détection de la criminalité. Les capacités prédictives de l’intelligence artificielle sont largement utilisées dans des systèmes tels que CrimeGPT (Crime Prediction Technology) pour prédire les activités criminelles. Cet article explore le potentiel de l’intelligence artificielle dans la prédiction de la criminalité, ses applications actuelles, les défis auxquels elle est confrontée et les éventuelles implications éthiques de cette technologie. Intelligence artificielle et prédiction de la criminalité : les bases CrimeGPT utilise des algorithmes d'apprentissage automatique pour analyser de grands ensembles de données, identifiant des modèles qui peuvent prédire où et quand les crimes sont susceptibles de se produire. Ces ensembles de données comprennent des statistiques historiques sur la criminalité, des informations démographiques, des indicateurs économiques, des tendances météorologiques, etc. En identifiant les tendances qui pourraient échapper aux analystes humains, l'intelligence artificielle peut donner du pouvoir aux forces de l'ordre.
 Application d'algorithmes dans la construction de 58 plateformes de portraits
May 09, 2024 am 09:01 AM
Application d'algorithmes dans la construction de 58 plateformes de portraits
May 09, 2024 am 09:01 AM
1. Contexte de la construction de la plateforme 58 Portraits Tout d'abord, je voudrais partager avec vous le contexte de la construction de la plateforme 58 Portraits. 1. La pensée traditionnelle de la plate-forme de profilage traditionnelle ne suffit plus. La création d'une plate-forme de profilage des utilisateurs s'appuie sur des capacités de modélisation d'entrepôt de données pour intégrer les données de plusieurs secteurs d'activité afin de créer des portraits d'utilisateurs précis. Elle nécessite également l'exploration de données pour comprendre le comportement et les intérêts des utilisateurs. et besoins, et fournir des capacités côté algorithmes ; enfin, il doit également disposer de capacités de plate-forme de données pour stocker, interroger et partager efficacement les données de profil utilisateur et fournir des services de profil. La principale différence entre une plate-forme de profilage d'entreprise auto-construite et une plate-forme de profilage de middle-office est que la plate-forme de profilage auto-construite dessert un seul secteur d'activité et peut être personnalisée à la demande. La plate-forme de mid-office dessert plusieurs secteurs d'activité et est complexe ; modélisation et offre des fonctionnalités plus générales. 2.58 Portraits d'utilisateurs de l'arrière-plan de la construction du portrait sur la plate-forme médiane 58
 Analyse d'algorithme PHP : méthode efficace pour trouver les nombres manquants dans un tableau
Mar 02, 2024 am 08:39 AM
Analyse d'algorithme PHP : méthode efficace pour trouver les nombres manquants dans un tableau
Mar 02, 2024 am 08:39 AM
Analyse d'algorithme PHP : Une méthode efficace pour trouver les nombres manquants dans un tableau. Dans le processus de développement d'applications PHP, nous rencontrons souvent des situations où nous devons trouver des nombres manquants dans un tableau. Cette situation est très courante dans le traitement des données et la conception d'algorithmes, nous devons donc maîtriser des algorithmes de recherche efficaces pour résoudre ce problème. Cet article présentera une méthode efficace pour trouver les nombres manquants dans un tableau et joindra des exemples de code PHP spécifiques. Description du problème Supposons que nous ayons un tableau contenant des nombres entiers compris entre 1 et 100, mais qu'il manque un nombre. Nous devons concevoir un
