

Traducteur | Zhu Xianzhong
Chonglou
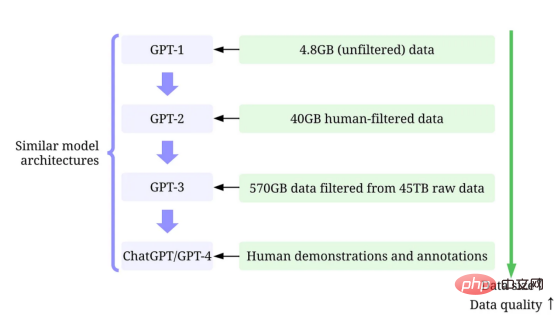
Image de l'article https://www.php.cn/link/f74412c3c1c8 899f3 c130bb30ed0e363, par l'auteur lui-même Fabriqué par
L'intelligence artificielle fait des progrès incroyables en changeant notre façon de vivre, de travailler et d'interagir avec la technologie. Récemment, un domaine qui a connu des progrès significatifs est le développement de grands modèles de langage (LLM) tels que GPT-3, ChatGPT et GPT-4. Ces modèles sont capables d'effectuer des tâches linguistiques telles que la traduction, le résumé de texte et la réponse aux questions avec une précision impressionnante.
Bien qu'il soit difficile d'ignorer la taille toujours croissante des grands modèles de langage, il est tout aussi important de reconnaître que leur succès est en grande partie dû aux grandes quantités de données de haute qualité utilisées pour les entraîner.
Dans cet article, nous fournirons un aperçu des progrès récents dans les modèles de langage à grande échelle du point de vue de l'intelligence artificielle centrée sur les données, en nous référant aux points de vue de notre récent document d'enquête (fin de la littérature 1 et 2) et sur GitHub correspondant ressources techniques. En particulier, nous examinerons de plus près le modèle GPT à travers le prisme de l’intelligence artificielle centrée sur les données, une perspective croissante dans la communauté de la science des données. Nous révélerons le concept d'intelligence artificielle centré sur les données derrière le modèle GPT en discutant de trois objectifs de l'intelligence artificielle centrés sur les données : le développement de données de formation, le développement de données d'inférence et la maintenance des données.
LLM (Large Language Model) est un modèle de traitement du langage naturel qui est entraîné pour déduire des mots dans leur contexte. Par exemple, la fonction la plus basique de LLM est de prédire les jetons manquants en fonction du contexte. Pour ce faire, LLM est formé pour prédire la probabilité de chaque jeton candidat à partir d’énormes quantités de données.

Exemple illustratif de prédiction de la probabilité de jetons manquants à l'aide d'un grand modèle de langage avec contexte (image fournie par l'auteur lui-même)
Le modèle GPT fait référence à une série de modèles de langage à grande échelle créés par OpenAI, tels que GPT-1, GPT-2, GPT -3, InstructGPT et ChatGPT/GPT-4. Comme d'autres modèles de langage à grande échelle, l'architecture du modèle GPT est fortement basée sur des transformateurs, qui utilisent des intégrations de texte et de position comme entrée et utilisent des couches d'attention pour modéliser les relations entre les jetons.
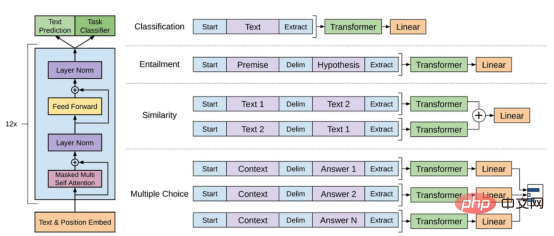
Schéma de l'architecture du modèle GPT-1 Cette image provient du document https://www.php.cn/link/c3bfbc2fc89bd1dd71ad5fc5ac96ae69
Le dernier modèle GPT utilise quelque chose de similaire à. GPT-1 L'architecture utilise simplement plus de paramètres de modèle, comporte plus de couches, une longueur de contexte plus grande, une taille de couche cachée, etc.

Comparaison de différentes tailles de modèles GPT (image fournie par l'auteur)
L'intelligence artificielle centrée sur les données est une nouvelle façon émergente de réfléchir à la manière de construire des systèmes d'intelligence artificielle. Andrew Ng, pionnier de l’intelligence artificielle, défend cette idée.
L'intelligence artificielle centrée sur les données est la discipline de l'ingénierie systématique des données utilisées pour construire des systèmes d'intelligence artificielle.
——Andrew Ng
Dans le passé, nous nous concentrions principalement sur la création de meilleurs modèles (intelligence artificielle centrée sur le modèle) lorsque les données sont fondamentalement inchangées. Cependant, cette approche peut poser des problèmes dans le monde réel car elle ne prend pas en compte différents problèmes pouvant survenir dans les données, tels que des étiquettes inexactes, des duplications et des biais. Par conséquent, le « surajustement » d’un ensemble de données ne conduit pas nécessairement à un meilleur comportement du modèle.
En revanche, l’IA centrée sur les données se concentre sur l’amélioration de la qualité et de la quantité des données utilisées pour créer des systèmes d’IA. Cela signifie que l’attention sera concentrée sur les données elles-mêmes, alors que le modèle est relativement figé. Une approche centrée sur les données pour développer des systèmes d’IA a un plus grand potentiel dans le monde réel, car les données utilisées pour la formation déterminent en fin de compte les capacités maximales du modèle.
Il convient de noter que le « data-centric » est fondamentalement différent du « data-driven » car ce dernier met uniquement l'accent sur l'utilisation des données pour guider le développement de l'intelligence artificielle, alors que le développement de l'intelligence artificielle repose généralement sur le développement de modèles non centrés sur les données d’ingénierie.
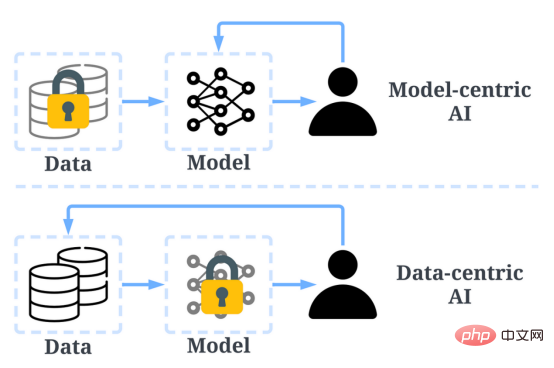
Comparaison de l'intelligence artificielle centrée sur les données et de l'IA centrée sur les modèles (photo de https://www.php.cn/link/f9afa97535cf7c8789a1c50a2cd83787 auteur de l'article)
Dans l'ensemble, le cadre d'intelligence artificielle centrée sur les données comprend trois objectifs :
Cadre d'intelligence artificielle centré sur les données (image tirée du journal https:// Auteur de www.php.cn/link/f74412c3c1c8899f3c130bb30ed0e363)
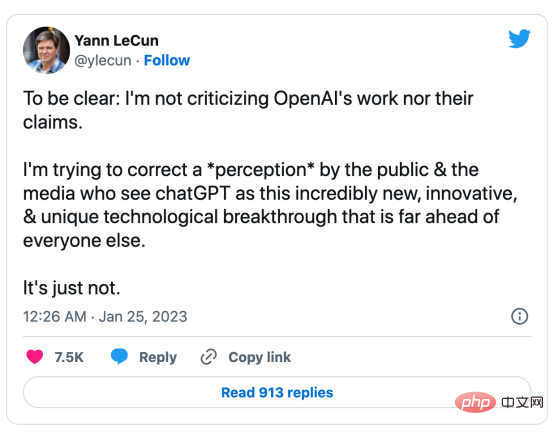
#🎜 🎜#Pourquoi les données sont-elles L’IA centrale qui fait le succès du modèle GPT ? Il y a quelques mois, Yann LeCun, leader de l'industrie de l'intelligence artificielle, déclarait sur son Twitter que ChatGPT n'était pas nouveau. En fait, toutes les techniques utilisées dans ChatGPT et GPT-4 (Ttransformer et apprentissage par renforcement à partir de feedback humain, etc.) ne sont pas de nouvelles technologies. Cependant, ils ont obtenu des résultats incroyables que les modèles précédents ne pouvaient pas atteindre. Alors, qu’est-ce qui motive leur succès ?
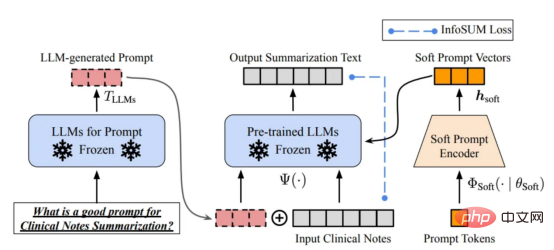
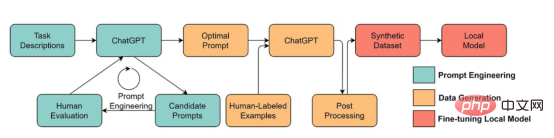
Tout d'abord, renforcez formation# 🎜🎜#Développement de données. Grâce à de meilleures stratégies de collecte de données, d'étiquetage des données et de préparation des données, la quantité et la qualité des données utilisées pour entraîner les modèles GPT ont considérablement augmenté. Deuxièmement, développez des données d'inférence. Étant donné que les modèles GPT récents sont devenus suffisamment puissants, nous pouvons atteindre divers objectifs en ajustant les indices (ou en ajustant les données d'inférence) tout en corrigeant le modèle. Par exemple, nous pouvons effectuer un résumé de texte en fournissant le texte du résumé accompagné d'instructions telles que « résumer » ou « TL;DR » pour guider le processus d'inférence. Mise au point rapide, photos fournies par l'auteur Concevoir les bonnes invites de raisonnement est une tâche difficile. Elle s'appuie fortement sur des techniques heuristiques. Une bonne enquête résume les différentes méthodes d’incitation utilisées jusqu’à présent. Parfois, même des signaux sémantiquement similaires peuvent avoir des résultats très différents. Dans ce cas, un étalonnage basé sur des repères logiciels peut être nécessaire pour réduire l’écart. Calibrage basé sur une invite logicielle. Cette image provient de l'article https://arxiv.org/abs/2303.13035v1, avec la permission de l'auteur original La recherche sur le développement de données d'inférence de modèles de langage à grande échelle en est encore à ses débuts . Dans un avenir proche, davantage de techniques de développement de données d’inférence déjà utilisées dans d’autres tâches pourraient être appliquées au domaine des grands modèles de langage. En termes de maintenance des données, ChatGPT/GPT-4, en tant que produit commercial, n'est pas seulement une formation réussie, mais nécessite une mise à jour et une maintenance continues. Évidemment, nous ne savons pas comment la maintenance des données est effectuée en dehors d'OpenAI. Par conséquent, nous discutons de certaines stratégies générales d'IA centrées sur les données qui sont susceptibles d'avoir été utilisées ou seront utilisées dans les modèles GPT : Le système ChatGPT/GPT-4 est capable de collecter les commentaires des utilisateurs via les deux boutons d'icône « pouce vers le haut » et « pouce vers le bas », comme indiqué sur l'image pour promouvoir davantage le développement de leur système. La capture d'écran ici provient de https://chat.openai.com/chat. Le succès des modèles linguistiques à grande échelle a révolutionné l'intelligence artificielle. À l’avenir, les grands modèles linguistiques pourraient révolutionner davantage le cycle de vie de la science des données. À cette fin, nous faisons deux prédictions : Utilisez un grand modèle de langage pour générer des données synthétiques pour entraîner le modèle, l'image ici provient de l'article https://arxiv.org/abs/2303.04360, avec l'autorisation de l'auteur original J'espère que cet article vous inspirera dans votre propre travail. Vous pouvez en savoir plus sur les frameworks d'IA centrés sur les données et sur leurs avantages pour les grands modèles de langage dans les articles suivants : [1]Une revue de l'intelligence artificielle centrée sur les données. [2]Les perspectives et les défis de l'intelligence artificielle centrée sur les données. Notez que nous maintenons également un Référentiel de code GitHub, qui mettra régulièrement à jour les ressources d'intelligence artificielle pertinentes centrées sur les données. Dans les prochains articles, j'approfondirai les trois objectifs de l'intelligence artificielle centrée sur les données (développement de données de formation, développement de données d'inférence et maintenance des données) et présenterai des méthodes représentatives. Zhu Xianzhong, rédacteur en chef de la communauté 51CTO, blogueur expert 51CTO, conférencier, professeur d'informatique dans une université de Weifang et vétéran de l'industrie de la programmation indépendante. Titre original : Quels sont les concepts d'IA centrés sur les données derrière les modèles GPT ?, auteur : Henry Lai

Que peut apprendre la communauté de la science des données de cette vague de grands modèles de langage ?
Informations de référence
Présentation du traducteur
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
 Application de l'intelligence artificielle dans la vie
Application de l'intelligence artificielle dans la vie
 Inscription ChatGPT
Inscription ChatGPT
 Encyclopédie ChatGPT nationale gratuite
Encyclopédie ChatGPT nationale gratuite
 Quel est le concept de base de l'intelligence artificielle
Quel est le concept de base de l'intelligence artificielle
 Comment installer chatgpt sur un téléphone mobile
Comment installer chatgpt sur un téléphone mobile
 Chatgpt peut-il être utilisé en Chine ?
Chatgpt peut-il être utilisé en Chine ?
 Utilisation de l'instruction delete
Utilisation de l'instruction delete
 Comment résoudre le problème selon lequel document.cookie ne peut pas être obtenu
Comment résoudre le problème selon lequel document.cookie ne peut pas être obtenu








![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



