

Visualiser des clusters à l'aide de dendrogrammes

Généralement, nous utilisons des nuages de points pour la visualisation de clusters, mais les nuages de points ne sont pas idéaux pour visualiser certains algorithmes de clustering, donc dans cet article, nous expliquons comment utiliser les dendrogrammes (Dendrogrammes) Visualisez nos résultats de clustering.
Dendogramme
Un dendrogramme est un diagramme qui montre les relations hiérarchiques entre des objets, des groupes ou des variables. Un dendrogramme se compose de branches connectées à des nœuds ou des clusters qui représentent des groupes d'observations présentant des caractéristiques similaires. La hauteur d'une branche ou la distance entre les nœuds indique à quel point les groupes sont différents ou similaires. Autrement dit, plus les branches sont longues ou plus la distance entre les nœuds est grande, moins les groupes sont similaires. Plus les branches sont courtes ou plus la distance entre les nœuds est petite, plus les groupes sont similaires.
Les dendogrammes sont utiles pour visualiser des structures de données complexes et identifier des sous-groupes ou des groupes de données présentant des caractéristiques similaires. Ils sont couramment utilisés en biologie, en génétique, en écologie, en sciences sociales et dans d'autres domaines où les données peuvent être regroupées en fonction de leur similarité ou de leur corrélation.
Connaissances de base :
Le mot "dendrogramme" vient des mots grecs "dendron" (arbre) et "gramma" (dessin). En 1901, le mathématicien et statisticien britannique Karl Pearson a utilisé des diagrammes arborescents pour montrer les relations entre différentes espèces végétales. Il a appelé ce graphique un « graphique de cluster ». Cela peut être considéré comme la première utilisation des dendrogrammes.
Préparation des données
Nous utiliserons les cours réels des actions de plusieurs entreprises pour le regroupement. Pour un accès facile, les données sont collectées à l'aide de l'API gratuite fournie par Alpha Vantage. Alpha Vantage fournit à la fois une API gratuite et une API premium. L'accès via l'API nécessite une clé, veuillez vous référer à son site Web.
import pandas as pd
import requests
companies={'Apple':'AAPL','Amazon':'AMZN','Facebook':'META','Tesla':'TSLA','Alphabet (Google)':'GOOGL','Shell':'SHEL','Suncor Energy':'SU',
'Exxon Mobil Corp':'XOM','Lululemon':'LULU','Walmart':'WMT','Carters':'CRI','Childrens Place':'PLCE','TJX Companies':'TJX',
'Victorias Secret':'VSCO','MACYs':'M','Wayfair':'W','Dollar Tree':'DLTR','CVS Caremark':'CVS','Walgreen':'WBA','Curaleaf':'CURLF'}20 entreprises sélectionnées dans les secteurs de la technologie, de la vente au détail, du pétrole et du gaz et d'autres secteurs.
import time
all_data={}
for key,value in companies.items():
# Replace YOUR_API_KEY with your Alpha Vantage API key
url = f'https://www.alphavantage.co/query?function=TIME_SERIES_DAILY_ADJUSTED&symbol={value}&apikey=<YOUR_API_KEY>&outputsize=full'
response = requests.get(url)
data = response.json()
time.sleep(15)
if 'Time Series (Daily)' in data and data['Time Series (Daily)']:
df = pd.DataFrame.from_dict(data['Time Series (Daily)'], orient='index')
print(f'Received data for {key}')
else:
print("Time series data is empty or not available.")
df.rename(columns = {'1. open':key}, inplace = True)
all_data[key]=df[key]Le code ci-dessus définit une pause de 15 secondes entre les appels d'API pour garantir qu'il ne sera pas bloqué trop fréquemment.
# find common dates among all data frames common_dates = None for df_key, df in all_data.items(): if common_dates is None: common_dates = set(df.index) else: common_dates = common_dates.intersection(df.index) common_dates = sorted(list(common_dates)) # create new data frame with common dates as index df_combined = pd.DataFrame(index=common_dates) # reindex each data frame with common dates and concatenate horizontally for df_key, df in all_data.items(): df_combined = pd.concat([df_combined, df.reindex(common_dates)], axis=1)
Intégrez les données ci-dessus dans le DF dont nous avons besoin, qui peut être utilisé directement ci-dessous
Clustering hiérarchique
Le clustering hiérarchique est un algorithme de clustering utilisé pour l'apprentissage automatique et l'analyse des données . Il utilise une hiérarchie de clusters imbriqués pour regrouper des objets similaires en clusters en fonction de leur similarité. L'algorithme peut être aggloméré, en commençant par des objets uniques et en les fusionnant en clusters, ou divisif, en commençant par un grand cluster et en le divisant de manière récursive en clusters plus petits.
Il convient de noter que toutes les méthodes de clustering ne sont pas des méthodes de clustering hiérarchiques et que les dendrogrammes ne peuvent être utilisés que sur quelques algorithmes de clustering.
Algorithme de clustering Nous utiliserons le clustering hiérarchique fourni dans le module scipy.
1. Clustering descendant
import numpy as np
import scipy.cluster.hierarchy as sch
import matplotlib.pyplot as plt
# Convert correlation matrix to distance matrix
dist_mat = 1 - df_combined.corr()
# Perform top-down clustering
clustering = sch.linkage(dist_mat, method='complete')
cuts = sch.cut_tree(clustering, n_clusters=[3, 4])
# Plot dendrogram
plt.figure(figsize=(10, 5))
sch.dendrogram(clustering, labels=list(df_combined.columns), leaf_rotation=90)
plt.title('Dendrogram of Company Correlations (Top-Down Clustering)')
plt.xlabel('Companies')
plt.ylabel('Distance')
plt.show()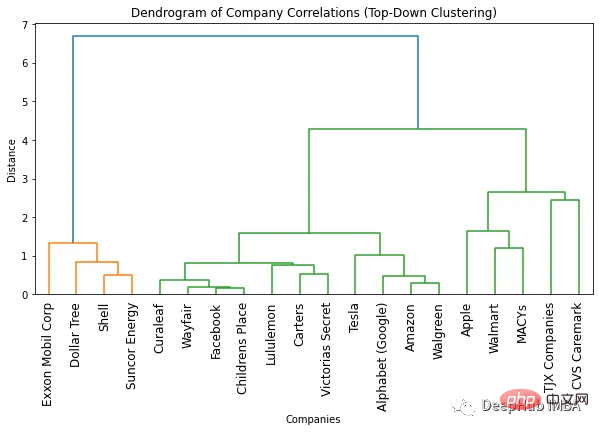
Comment déterminer le nombre optimal de clusters en fonction du dendrogramme
Le moyen le plus simple de trouver le nombre optimal de clusters est de regarder le dendrogramme généré utilisé. nombre de couleurs. Le nombre optimal de clusters est inférieur d’un au nombre de couleurs. Ainsi, d’après le dendrogramme ci-dessus, le nombre optimal de clusters est de deux.
Une autre façon de trouver le nombre optimal de clusters consiste à identifier les points où la distance entre les clusters change soudainement. C'est ce qu'on appelle le « point du genou » ou « le point du coude » et peut être utilisé pour déterminer le nombre de clusters qui capture le mieux la variation des données. Nous pouvons voir dans la figure ci-dessus que le changement de distance maximal entre différents nombres de clusters se produit entre 1 et 2 clusters. Encore une fois, le nombre optimal de clusters est de deux.
Obtenez n'importe quel nombre de clusters à partir d'un dendrogramme
L'un des avantages de l'utilisation d'un dendrogramme est que les objets peuvent être regroupés en n'importe quel nombre de clusters en regardant le dendrogramme. Par exemple, si vous devez trouver deux clusters, vous pouvez regarder la ligne verticale supérieure du dendrogramme et décider des clusters. Par exemple, dans cet exemple, si deux clusters sont requis, il y a quatre sociétés dans le premier cluster et 16 sociétés dans le deuxième cluster. Si nous avons besoin de trois clusters, nous pouvons diviser le deuxième cluster en 11 et 5 entreprises. Si vous avez besoin de plus, vous pouvez suivre cet exemple.
2. Clustering ascendant
import numpy as np
import scipy.cluster.hierarchy as sch
import matplotlib.pyplot as plt
# Convert correlation matrix to distance matrix
dist_mat = 1 - df_combined.corr()
# Perform bottom-up clustering
clustering = sch.linkage(dist_mat, method='ward')
# Plot dendrogram
plt.figure(figsize=(10, 5))
sch.dendrogram(clustering, labels=list(df_combined.columns), leaf_rotation=90)
plt.title('Dendrogram of Company Correlations (Bottom-Up Clustering)')
plt.xlabel('Companies')
plt.ylabel('Distance')
plt.show()
Le dendrogramme que nous obtenons pour le clustering ascendant est similaire au clustering descendant. Le nombre optimal de clusters est toujours de deux (en fonction du nombre de couleurs et de la méthode du « point d'inflexion »). Mais si nous avons besoin de plus de clusters, des différences subtiles seront observées. Ceci est normal car les méthodes utilisées sont différentes, ce qui entraîne de légères différences dans les résultats.
Résumé
Les dendogrammes sont un outil utile pour visualiser des structures de données complexes et identifier des sous-groupes ou des groupes de données présentant des caractéristiques similaires. Dans cet article, nous utilisons des méthodes de clustering hiérarchique pour montrer comment créer un dendrogramme et déterminer le nombre optimal de clusters. Car nos diagrammes arborescents de données sont utiles pour comprendre les relations entre différentes entreprises, mais ils peuvent également être utilisés dans divers autres domaines pour comprendre la structure hiérarchique des données.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

Video Face Swap
Échangez les visages dans n'importe quelle vidéo sans effort grâce à notre outil d'échange de visage AI entièrement gratuit !

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)
Sujets chauds
 1393
1393
 52
1207
24
52
1207
24

 Quatre outils de programmation assistés par IA recommandés
Apr 22, 2024 pm 05:34 PM
Quatre outils de programmation assistés par IA recommandés
Apr 22, 2024 pm 05:34 PM
Cet outil de programmation assistée par l'IA a mis au jour un grand nombre d'outils de programmation assistée par l'IA utiles à cette étape de développement rapide de l'IA. Les outils de programmation assistés par l'IA peuvent améliorer l'efficacité du développement, améliorer la qualité du code et réduire les taux de bogues. Ils constituent des assistants importants dans le processus de développement logiciel moderne. Aujourd'hui, Dayao partagera avec vous 4 outils de programmation assistés par l'IA (et tous prennent en charge le langage C#). J'espère que cela sera utile à tout le monde. https://github.com/YSGStudyHards/DotNetGuide1.GitHubCopilotGitHubCopilot est un assistant de codage IA qui vous aide à écrire du code plus rapidement et avec moins d'effort, afin que vous puissiez vous concentrer davantage sur la résolution de problèmes et la collaboration. Git
 Quel programmeur IA est le meilleur ? Explorez le potentiel de Devin, Tongyi Lingma et de l'agent SWE
Apr 07, 2024 am 09:10 AM
Quel programmeur IA est le meilleur ? Explorez le potentiel de Devin, Tongyi Lingma et de l'agent SWE
Apr 07, 2024 am 09:10 AM
Le 3 mars 2022, moins d'un mois après la naissance de Devin, le premier programmeur d'IA au monde, l'équipe NLP de l'Université de Princeton a développé un agent SWE pour programmeur d'IA open source. Il exploite le modèle GPT-4 pour résoudre automatiquement les problèmes dans les référentiels GitHub. Les performances de l'agent SWE sur l'ensemble de tests du banc SWE sont similaires à celles de Devin, prenant en moyenne 93 secondes et résolvant 12,29 % des problèmes. En interagissant avec un terminal dédié, SWE-agent peut ouvrir et rechercher le contenu des fichiers, utiliser la vérification automatique de la syntaxe, modifier des lignes spécifiques et écrire et exécuter des tests. (Remarque : le contenu ci-dessus est un léger ajustement du contenu original, mais les informations clés du texte original sont conservées et ne dépassent pas la limite de mots spécifiée.) SWE-A
 Apprenez à développer des applications mobiles en utilisant le langage Go
Mar 28, 2024 pm 10:00 PM
Apprenez à développer des applications mobiles en utilisant le langage Go
Mar 28, 2024 pm 10:00 PM
Didacticiel d'application mobile de développement du langage Go Alors que le marché des applications mobiles continue de croître, de plus en plus de développeurs commencent à explorer comment utiliser le langage Go pour développer des applications mobiles. En tant que langage de programmation simple et efficace, le langage Go a également montré un fort potentiel dans le développement d'applications mobiles. Cet article présentera en détail comment utiliser le langage Go pour développer des applications mobiles et joindra des exemples de code spécifiques pour aider les lecteurs à démarrer rapidement et à commencer à développer leurs propres applications mobiles. 1. Préparation Avant de commencer, nous devons préparer l'environnement et les outils de développement. tête
 Résumé des cinq bibliothèques du langage Go les plus populaires : outils essentiels au développement
Feb 22, 2024 pm 02:33 PM
Résumé des cinq bibliothèques du langage Go les plus populaires : outils essentiels au développement
Feb 22, 2024 pm 02:33 PM
Résumé des cinq bibliothèques du langage Go les plus populaires : des outils essentiels au développement, nécessitant des exemples de code spécifiques. Depuis sa naissance, le langage Go a fait l'objet d'une attention et d'une application généralisées. En tant que langage de programmation émergent, efficace et concis, le développement rapide de Go est indissociable du support de riches bibliothèques open source. Cet article présentera les cinq bibliothèques de langage Go les plus populaires. Ces bibliothèques jouent un rôle essentiel dans le développement Go et offrent aux développeurs des fonctions puissantes et une expérience de développement pratique. Parallèlement, afin de mieux comprendre les usages et les fonctions de ces bibliothèques, nous les expliquerons avec des exemples de codes précis.
 Cinq sélections d'outils de visualisation pour explorer Kafka
Feb 01, 2024 am 08:03 AM
Cinq sélections d'outils de visualisation pour explorer Kafka
Feb 01, 2024 am 08:03 AM
Cinq options pour les outils de visualisation Kafka ApacheKafka est une plateforme de traitement de flux distribué capable de traiter de grandes quantités de données en temps réel. Il est largement utilisé pour créer des pipelines de données en temps réel, des files d'attente de messages et des applications basées sur des événements. Les outils de visualisation de Kafka peuvent aider les utilisateurs à surveiller et gérer les clusters Kafka et à mieux comprendre les flux de données Kafka. Ce qui suit est une introduction à cinq outils de visualisation Kafka populaires : ConfluentControlCenterConfluent
 Quelle distribution Linux est la meilleure pour le développement Android ?
Mar 14, 2024 pm 12:30 PM
Quelle distribution Linux est la meilleure pour le développement Android ?
Mar 14, 2024 pm 12:30 PM
Le développement d'Android est un travail chargé et passionnant, et le choix d'une distribution Linux adaptée au développement est particulièrement important. Parmi les nombreuses distributions Linux, laquelle est la plus adaptée au développement Android ? Cet article explorera ce problème sous plusieurs aspects et donnera des exemples de code spécifiques. Tout d’abord, jetons un coup d’œil à plusieurs distributions Linux actuellement populaires : Ubuntu, Fedora, Debian, CentOS, etc. Elles ont toutes leurs propres avantages et caractéristiques.
 Explorer la technologie front-end du langage Go : une nouvelle vision du développement front-end
Mar 28, 2024 pm 01:06 PM
Explorer la technologie front-end du langage Go : une nouvelle vision du développement front-end
Mar 28, 2024 pm 01:06 PM
En tant que langage de programmation rapide et efficace, le langage Go est très populaire dans le domaine du développement back-end. Cependant, peu de gens associent le langage Go au développement front-end. En fait, l’utilisation du langage Go pour le développement front-end peut non seulement améliorer l’efficacité, mais également ouvrir de nouveaux horizons aux développeurs. Cet article explorera la possibilité d'utiliser le langage Go pour le développement front-end et fournira des exemples de code spécifiques pour aider les lecteurs à mieux comprendre ce domaine. Dans le développement front-end traditionnel, JavaScript, HTML et CSS sont souvent utilisés pour créer des interfaces utilisateur.
 Comprendre VSCode : à quoi sert cet outil ?
Mar 25, 2024 pm 03:06 PM
Comprendre VSCode : à quoi sert cet outil ?
Mar 25, 2024 pm 03:06 PM
« Comprendre VSCode : à quoi sert cet outil ? » 》En tant que programmeur, que vous soyez débutant ou développeur expérimenté, vous ne pouvez pas vous passer de l'utilisation d'outils d'édition de code. Parmi les nombreux outils d'édition, Visual Studio Code (VSCode en abrégé) est très populaire parmi les développeurs en tant qu'éditeur de code open source, léger et puissant. Alors, à quoi sert exactement VSCode ? Cet article approfondira les fonctions et les utilisations de VSCode et fournira des exemples de code spécifiques pour aider les lecteurs.
