
 Périphériques technologiques
IA
Les images et les audios se transforment en vidéos en quelques secondes ! SadTalker open source de l'Université Xi'an Jiaotong : mouvements surnaturels de la tête et des lèvres, bilingue en chinois et en anglais, et peut également chanter
Périphériques technologiques
IA
Les images et les audios se transforment en vidéos en quelques secondes ! SadTalker open source de l'Université Xi'an Jiaotong : mouvements surnaturels de la tête et des lèvres, bilingue en chinois et en anglais, et peut également chanter
Les images et les audios se transforment en vidéos en quelques secondes ! SadTalker open source de l'Université Xi'an Jiaotong : mouvements surnaturels de la tête et des lèvres, bilingue en chinois et en anglais, et peut également chanter

Avec la popularité du concept de personnes numériques et le développement continu de la technologie de génération, ce n'est plus un problème de faire bouger les personnages des photos en fonction de l'entrée audio.
Cependant, il existe encore de nombreux problèmes dans la "génération de vidéos d'avatar de personnages parlants à travers des images de visage et un morceau d'audio vocal", tels que des mouvements de tête non naturels, des expressions faciales déformées et des différences faciales excessives entre les vidéos et les images. et d'autres problèmes.
Récemment, des chercheurs de l'Université Jiaotong de Xi'an et d'autres ont proposé le Modèle SadTalker, qui apprend dans un champ de mouvement tridimensionnel à générer des coefficients de mouvement 3D (poses de tête, expressions) de 3DMM à partir de l'audio, et utilise un tout nouveau moteur de rendu de visage 3D pour générer un mouvement de tête.

Lien papier : https://arxiv.org/pdf/2211.12194.pdf
Page d'accueil du projet : https://sadtalker.github.io/
L'audio peut être en anglais, chinois, chansons, et les personnages de la vidéo peuvent également contrôler le taux de clignotement !
Pour apprendre des coefficients de mouvement réalistes, les chercheurs modélisent explicitement la connexion entre l'audio et différents types de coefficients de mouvement séparément : apprentissage de visages précis à partir de l'audio en distillant des coefficients et des expressions de visages rendus en 3D ; mouvements de tête.
Enfin, les coefficients de mouvement tridimensionnels générés sont mappés sur l'espace de points clés tridimensionnels non supervisé du rendu du visage, et la vidéo finale est synthétisée.
Enfin, il a été démontré expérimentalement que cette méthode atteint des performances de pointe en termes de synchronisation de mouvement et de qualité vidéo.
Le plug-in stable-diffusion-webui est également sorti !
Photo + Audio = Vidéo
La création humaine numérique, la vidéoconférence et bien d'autres domaines nécessitent la technologie consistant à "utiliser l'audio vocal pour animer des photos statiques", mais actuellement, cela reste une tâche très difficile.
Les travaux précédents se sont principalement concentrés sur la génération de « mouvements des lèvres », car la relation entre les mouvements des lèvres et la parole est la plus forte. D'autres travaux tentent également de générer des vidéos de visage d'autres mouvements connexes (comme la posture de la tête). La qualité des vidéos obtenues est encore très peu naturelle et limitée par les poses préférées, le flou, la modification de l'identité et les distorsions faciales.
Une autre méthode populaire est l'animation faciale basée sur la latente, qui se concentre principalement sur des catégories spécifiques de mouvements dans l'animation faciale conversationnelle. Il est également difficile de synthétiser des vidéos de haute qualité car, bien que le modèle facial 3D contienne un degré élevé de résolution, Les représentations couplées peuvent être utilisées pour apprendre indépendamment les trajectoires de mouvement de différentes positions sur le visage, mais elles généreront quand même des expressions inexactes et des séquences de mouvements non naturelles.
Sur la base des observations ci-dessus, les chercheurs ont proposé SadTalker (Stylized Audio-Driven Talking-head), un système de génération vidéo stylisé piloté par audio via une modulation implicite de coefficients tridimensionnels.
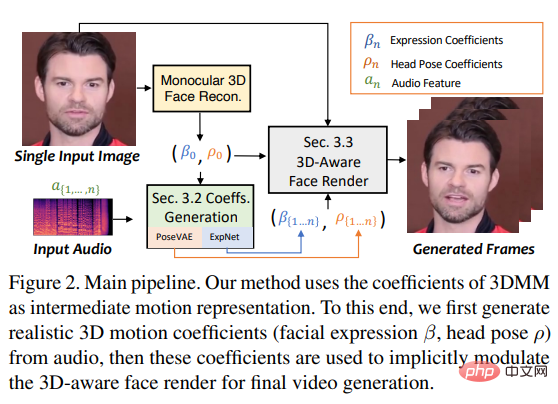
Pour atteindre cet objectif, les chercheurs ont considéré les coefficients de mouvement du 3DMM comme des représentations intermédiaires et ont divisé la tâche en deux parties principales (expressions et gestes), visant à générer des représentations plus réalistes à partir de coefficients de mouvement audio ( comme la posture de la tête, les mouvements des lèvres et les clignements des yeux) et apprenez chaque mouvement individuellement pour réduire l'incertitude.
Enfin, pilote l'image source via un rendu de visage 3D inspiré de face-vid2vid.
Visage 3D
Étant donné que les vidéos réelles sont tournées dans un environnement tridimensionnel, les informations tridimensionnelles sont cruciales pour améliorer l'authenticité des vidéos générées. Cependant, les travaux antérieurs considéraient rarement l'espace tridimensionnel, car un seul ; Il est difficile d’obtenir la rareté 3D originale d’une image plate, et des rendus faciaux de haute qualité sont difficiles à concevoir. Inspirés par les récentes méthodes de reconstruction 3D en profondeur d'une image unique, les chercheurs ont utilisé l'espace des modèles de déformation tridimensionnelle prédite (3DMM) comme représentations intermédiaires.
En 3DMM, la forme tridimensionnelle du visage S peut être découplée comme suit :
#🎜🎜 #
où S est la forme moyenne du visage tridimensionnel, Uid et Uexp sont les habitués de l'identité et de l'expression du modèle morphable LSFM, et les coefficients α (80 dimensions) et β ( 64 dimensions) décrivent respectivement l'identité et l'expression du personnage. Afin de conserver la diversité des postures, les coefficients r et t représentent respectivement la rotation et la translation de la tête afin d'obtenir une génération de coefficients indépendante de l'identité, seuls les paramètres de mouvement sont représentés. modélisé comme {β, r, t}.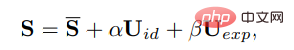
Autrement dit, la pose de la tête ρ = [r, t] et le coefficient d'expression β sont appris séparément de l'audio piloté, puis sont implicitement modulés à l'aide de ces coefficients de mouvement Le rendu du visage a été utilisé pour la composition vidéo finale.
Générer un mouvement clairsemé grâce à l'audio
Coefficients de mouvement tridimensionnels inclure l'en-tête Poses et expressions de la tête, où les poses de la tête sont des mouvements globaux, tandis que les expressions sont relativement locales, donc apprendre pleinement tous les coefficients apportera une énorme incertitude au réseau, car la relation entre les poses de la tête et l'audio est relativement faible et les mouvements des lèvres sont fortement en corrélation avec l'audio.
So SadTalker utilise les PoseVAE et ExpNet suivants pour générer respectivement le mouvement de la posture et de l'expression de la tête.
ExpNet
Apprenez une méthode qui peut être générée à partir de l'audio Un modèle universel de « coefficient d'expression précis » est très difficile pour deux raisons :
1) L'audio vers l'expression n'est pas précis pour différents caractères. tâche de cartographie ;
2) Il existe certaines actions liées à l'audio dans le coefficient d'expression, qui affecteront la précision de la prédiction.
L'objectif de conception d'ExpNet est de réduire ces incertitudes quant à la question de l'identité des personnages, les chercheurs d'abord A ; Le coefficient d'expression du cadre relie le mouvement d'expression à une personne spécifique.
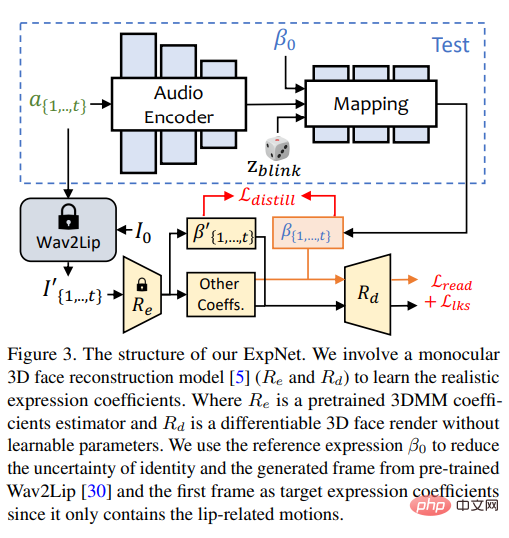
Afin de réduire le poids du mouvement des autres composants du visage dans les conversations naturelles, seuls les coefficients de mouvement des lèvres (mouvement des lèvres uniquement) sont utilisés comme coefficient cible.
Quant aux autres mouvements subtils du visage (comme les clignements des yeux), etc., ils peuvent être introduits dans la perte de repère supplémentaire sur l'image rendue.
PoseVAE Pour apprendre des mouvements de tête stylisés réalistes et conscients de l'identité dans des vidéos parlantes.
En formation, une paire structurelle basée sur un codeur-décodeur est utilisée Fixe n les trames sont utilisées pour la formation de pose VAE, dans laquelle l'encodeur et le décodeur sont tous deux MLP à deux couches. L'entrée contient une pose de tête de trame en T continue, qui est intégrée dans une distribution gaussienne, le réseau est échantillonné à partir du. distribution Apprenez à générer des poses en T.
Il est à noter que PoseVAE ne génère pas directement la pose, mais apprend le résiduel de la pose conditionnelle de la première image, ce qui permet également à cette méthode de générer la pose conditionnelle sous la condition de la première cadre dans le test. Mouvement de tête plus long, plus stable et plus continu.
Selon le CVAE, les fonctionnalités audio et les identifiants de style correspondants sont également ajoutés à PoseVAE en tant que conditions de conscience du rythme et de style d'identité.
Le modèle utilise la divergence KL pour mesurer la distribution du mouvement généré ; il utilise la perte quadratique moyenne et la perte contradictoire pour garantir la qualité de la génération.
Rendu facial compatible 3D
pour générer de vrais trois- Dimensions Après avoir calculé les coefficients de mouvement, les chercheurs ont rendu la vidéo finale grâce à un animateur d'images 3D soigneusement conçu.
La méthode d'animation d'image récemment proposée face-vid2vid peut implicitement apprendre des informations 3D à partir d'une seule image, mais cette méthode nécessite une vraie vidéo comme signal de conduite d'action ; le rendu proposé dans cet article peut être piloté par des coefficients 3DMM.
Les chercheurs proposent mappingNet pour apprendre la relation entre les coefficients de mouvement 3DMM explicites (pose et expression de la tête) et les points clés 3D implicites non supervisés.
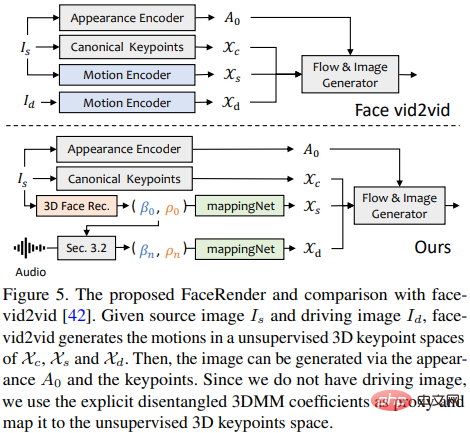
mappingNet est construit à travers plusieurs couches convolutives unidimensionnelles et utilise le coefficient temporel de la fenêtre temporelle pour le lissage comme le traitement PIRenderer ; la différence est que les chercheurs ont découvert que les coefficients de mouvement alignés sur le visage dans PIRenderer affecteront grandement le naturel du mouvement généré par les vidéos audio, donc mappingNet utilise uniquement les coefficients d'expressions et de poses de tête.
La phase de formation se compose de deux étapes : suivez d'abord le document original et entraînez face-vid2vid de manière auto-supervisée, puis gelez l'encodeur d'apparence, l'estimateur canonique de points clés ; et Après tous les paramètres du générateur d'images, mappingNet est formé sur les coefficients 3DMM de la vidéo de vérité terrain de manière reconstruite pour un réglage fin.
Utilise la perte L1 pour la formation supervisée dans le domaine des points clés non supervisés et donne la vidéo finale générée selon sa mise en œuvre originale.
Résultats expérimentaux
Afin de prouver la supériorité de cette méthode, les chercheurs ont sélectionné la distance de démarrage de Frechet (FID) et la détection de flou de probabilité cumulée (CPBD) pour évaluer la qualité de l'image, où FID évalue principalement l'authenticité des images générées, et CPBD évalue la clarté des images générées.
Pour évaluer le degré de préservation de l'identité, ArcFace est utilisé pour extraire l'intégration d'identité de l'image, puis la similarité cosinus de l'intégration d'identité (CSIM) est calculée entre l'image source et l'image générée.
Pour évaluer la synchronisation des lèvres et la forme des lèvres, les chercheurs ont évalué les différences de perception des formes des lèvres de Wav2Lip, y compris le score de distance (LSE-D) et le score de confiance (LSE-C ).
Dans l'évaluation du mouvement de la tête, la diversité des mouvements de la tête générés est calculée en utilisant l'écart type des intégrations de caractéristiques de mouvement de la tête extraites par Hopenet à partir des images générées ; Calculez le score Beat Align pour évaluer la cohérence de l’audio et des mouvements de tête générés.
Parmi les méthodes de comparaison, plusieurs méthodes de génération d'avatars parlants les plus avancées ont été sélectionnées, notamment MakeItTalk, Audio2Head et les méthodes de génération audio-expression (Wav2Lip, PC-AVS) , évalué à l'aide de poids de point de contrôle publics.
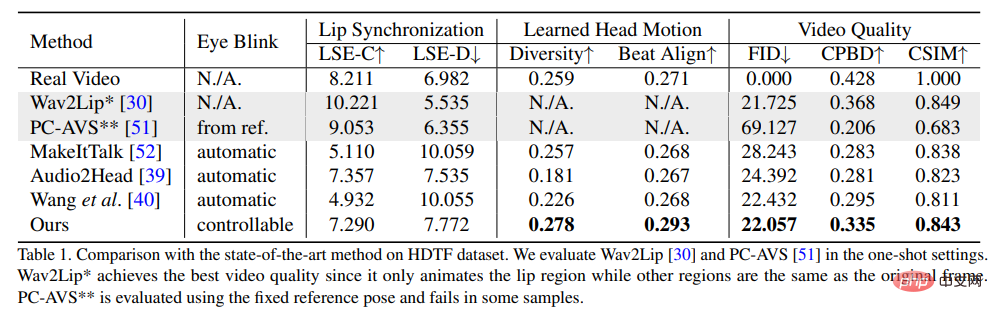
Il ressort des résultats expérimentaux que la méthode proposée dans le L'article peut montrer que cela se traduit par une meilleure qualité vidéo globale et une meilleure diversité de poses de tête, tout en montrant également des performances comparables à d'autres méthodes de génération de tête à part entière en termes de mesures de synchronisation labiale.
Les chercheurs pensent que ces mesures de synchronisation labiale sont si sensibles à l'audio que les mouvements non naturels des lèvres peuvent obtenir de meilleurs scores, mais l'article suggère que la méthode a obtenu des scores similaires à ceux de vraies vidéos. , ce qui démontre également les avantages de cette méthode.

Comme on peut le voir dans les résultats visuels générés par les différentes méthodes, la qualité visuelle de cette méthode est très similaire à la vidéo cible originale, et également très similaire aux différentes poses de tête attendues.
Par rapport à d'autres méthodes, Wav2Lip génère des demi-visages flous ; PC-AVS et Audio2Head ont du mal à conserver l'identité de l'image source ; Audio2Head ne peut générer que des visages parlants frontaux et Audio2Head génère des visages flous en raison de la distorsion 2D ; vidéo de visage.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

Video Face Swap
Échangez les visages dans n'importe quelle vidéo sans effort grâce à notre outil d'échange de visage AI entièrement gratuit !

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)
Sujets chauds



 Comment régler la balance audio dans Win11 ? (Win11 ajuste les canaux de volume gauche et droit)
Feb 11, 2024 pm 05:57 PM
Comment régler la balance audio dans Win11 ? (Win11 ajuste les canaux de volume gauche et droit)
Feb 11, 2024 pm 05:57 PM
Lorsqu'ils écoutent de la musique ou regardent des films sur un ordinateur Win11, si le son des haut-parleurs ou des écouteurs est déséquilibré, les utilisateurs peuvent régler manuellement le niveau de balance en fonction de leurs besoins. Alors comment s’ajuster ? En réponse à ce problème, l'éditeur a proposé un tutoriel de fonctionnement détaillé, dans l'espoir d'aider tout le monde. Comment équilibrer les canaux audio gauche et droit dans Windows 11 ? Méthode 1 : utilisez l'application Paramètres pour appuyer sur la touche et cliquez sur Paramètres. Windows, cliquez sur Système et sélectionnez Son. Sélectionnez plus de paramètres sonores. Cliquez sur vos haut-parleurs/écouteurs et sélectionnez Propriétés. Accédez à l'onglet Niveaux et cliquez sur Solde. Assurez-vous que "à gauche" et
 Expérience de lancement de la Bose Soundbar Ultra : le cinéma maison dès la sortie de la boîte ?
Feb 06, 2024 pm 05:30 PM
Expérience de lancement de la Bose Soundbar Ultra : le cinéma maison dès la sortie de la boîte ?
Feb 06, 2024 pm 05:30 PM
D'aussi loin que je me souvienne, j'ai eu une paire de grandes enceintes sur pied chez moi. J'ai toujours pensé qu'un téléviseur ne pouvait être appelé téléviseur que s'il était équipé d'un système audio complet. Mais lorsque j’ai commencé à travailler, je ne pouvais pas me permettre un son professionnel à domicile. Après m'être renseigné et compris le positionnement du produit, j'ai trouvé que la catégorie barre de son me convient très bien. Elle répond à mes besoins en termes de qualité sonore, de taille et de prix. J’ai donc décidé d’opter pour la barre de son. Après une sélection minutieuse, j'ai sélectionné ce produit de barre de son panoramique lancé par Bose début 2024 : l'enceinte de divertissement à domicile Bose Ultra. (Source photo : photographié par Lei Technology) De manière générale, si nous voulons expérimenter l'effet Dolby Atmos « original », nous devons installer chez nous un son surround + plafond mesuré et calibré.
 Comment résoudre le problème de l'enregistrement automatique des images lors de la publication sur Xiaohongshu ? Où est l'image enregistrée automatiquement lors de la publication ?
Mar 22, 2024 am 08:06 AM
Comment résoudre le problème de l'enregistrement automatique des images lors de la publication sur Xiaohongshu ? Où est l'image enregistrée automatiquement lors de la publication ?
Mar 22, 2024 am 08:06 AM
Avec le développement continu des médias sociaux, Xiaohongshu est devenue une plateforme permettant à de plus en plus de jeunes de partager leur vie et de découvrir de belles choses. De nombreux utilisateurs sont gênés par des problèmes de sauvegarde automatique lors de la publication d’images. Alors, comment résoudre ce problème ? 1. Comment résoudre le problème de l'enregistrement automatique des images lors de la publication sur Xiaohongshu ? 1. Vider le cache Tout d'abord, nous pouvons essayer de vider les données du cache de Xiaohongshu. Les étapes sont les suivantes : (1) Ouvrez Xiaohongshu et cliquez sur le bouton « Mon » dans le coin inférieur droit (2) Sur la page du centre personnel, recherchez « Paramètres » et cliquez dessus (3) Faites défiler vers le bas et recherchez « ; "Vider le cache". Cliquez sur OK. Après avoir vidé le cache, entrez à nouveau dans Xiaohongshu et essayez de publier des photos pour voir si le problème de sauvegarde automatique est résolu. 2. Mettez à jour la version Xiaohongshu pour vous assurer que votre Xiaohongshu
 Comment publier des photos dans les commentaires TikTok ? Où se trouve l'entrée des photos dans la zone commentaire ?
Mar 21, 2024 pm 09:12 PM
Comment publier des photos dans les commentaires TikTok ? Où se trouve l'entrée des photos dans la zone commentaire ?
Mar 21, 2024 pm 09:12 PM
Avec la popularité des courtes vidéos Douyin, les interactions des utilisateurs dans la zone de commentaires sont devenues plus colorées. Certains utilisateurs souhaitent partager des images en commentaires pour mieux exprimer leurs opinions ou émotions. Alors, comment publier des photos dans les commentaires TikTok ? Cet article répondra à cette question en détail et vous fournira quelques conseils et précautions connexes. 1. Comment publier des photos dans les commentaires Douyin ? 1. Ouvrez Douyin : Tout d'abord, vous devez ouvrir l'application Douyin et vous connecter à votre compte. 2. Recherchez la zone de commentaire : lorsque vous parcourez ou publiez une courte vidéo, recherchez l'endroit où vous souhaitez commenter et cliquez sur le bouton "Commentaire". 3. Saisissez le contenu de votre commentaire : saisissez le contenu de votre commentaire dans la zone de commentaire. 4. Choisissez d'envoyer une photo : Dans l'interface de saisie du contenu des commentaires, vous verrez un bouton « image » ou un bouton « + », cliquez sur
 7 façons de réinitialiser les paramètres sonores sous Windows 11
Nov 08, 2023 pm 05:17 PM
7 façons de réinitialiser les paramètres sonores sous Windows 11
Nov 08, 2023 pm 05:17 PM
Bien que Windows soit capable de gérer le son sur votre ordinateur, vous souhaiterez peut-être toujours intervenir et réinitialiser vos paramètres sonores au cas où vous rencontreriez des problèmes ou des problèmes audio. Cependant, avec les changements esthétiques apportés par Microsoft à Windows 11, il est devenu plus difficile de se concentrer sur ces paramètres. Voyons donc comment rechercher et gérer ces paramètres sur Windows 11 ou les réinitialiser en cas de problème. Comment réinitialiser les paramètres sonores dans Windows 11 de 7 manières simples Voici sept façons de réinitialiser les paramètres sonores dans Windows 11, en fonction du problème auquel vous êtes confronté. Commençons. Méthode 1 : Réinitialiser les paramètres de son et de volume de l'application. Appuyez sur le bouton de votre clavier pour ouvrir l'application Paramètres. Cliquez maintenant
 6 façons de rendre les images plus nettes sur iPhone
Mar 04, 2024 pm 06:25 PM
6 façons de rendre les images plus nettes sur iPhone
Mar 04, 2024 pm 06:25 PM
Les iPhones récents d'Apple capturent des souvenirs avec des détails, une saturation et une luminosité nets. Mais parfois, vous pouvez rencontrer des problèmes qui peuvent rendre l’image moins claire. Bien que la mise au point automatique sur les appareils photo iPhone ait parcouru un long chemin, vous permettant de prendre des photos rapidement, l'appareil photo peut se concentrer par erreur sur le mauvais sujet dans certaines situations, rendant la photo floue dans les zones indésirables. Si vos photos sur votre iPhone semblent floues ou manquent globalement de netteté, l’article suivant devrait vous aider à les rendre plus nettes. Comment rendre les images plus claires sur iPhone [6 méthodes] Vous pouvez essayer d'utiliser l'application Photos native pour nettoyer vos photos. Si vous souhaitez plus de fonctionnalités et d'options
 Comment faire sortir les images ppt une par une
Mar 25, 2024 pm 04:00 PM
Comment faire sortir les images ppt une par une
Mar 25, 2024 pm 04:00 PM
Dans PowerPoint, il est courant d'afficher les images une par une, ce qui peut être réalisé en définissant des effets d'animation. Ce guide détaille les étapes de mise en œuvre de cette technique, y compris la configuration de base, l'insertion d'images, l'ajout d'une animation et l'ajustement de l'ordre et du timing de l'animation. De plus, des paramètres et ajustements avancés sont fournis, tels que l'utilisation de déclencheurs, l'ajustement de la vitesse et de l'ordre de l'animation et la prévisualisation des effets d'animation. En suivant ces étapes et conseils, les utilisateurs peuvent facilement configurer les images pour qu'elles apparaissent les unes après les autres dans PowerPoint, améliorant ainsi l'impact visuel de la présentation et attirant l'attention du public.
 Que dois-je faire si les images de la page Web ne peuvent pas être chargées ? 6 solutions
Mar 15, 2024 am 10:30 AM
Que dois-je faire si les images de la page Web ne peuvent pas être chargées ? 6 solutions
Mar 15, 2024 am 10:30 AM
Certains internautes ont constaté que lorsqu'ils ouvraient la page Web du navigateur, les images de la page Web ne pouvaient pas être chargées pendant une longue période. Que s'est-il passé ? J'ai vérifié que le réseau est normal, alors quel est le problème ? L'éditeur ci-dessous vous présentera six solutions au problème de l'impossibilité de charger les images de pages Web. Les images de la page Web ne peuvent pas être chargées : 1. Problème de vitesse Internet La page Web ne peut pas afficher les images. Cela peut être dû au fait que la vitesse Internet de l'ordinateur est relativement lente et qu'il y a davantage de logiciels ouverts sur l'ordinateur et que les images auxquelles nous accédons sont relativement volumineuses. peut être dû à un délai de chargement. Par conséquent, l'image ne peut pas être affichée. Vous pouvez désactiver le logiciel qui utilise la vitesse du réseau et le vérifier dans le gestionnaire de tâches. 2. Trop de visiteurs Si la page Web ne peut pas afficher d'images, c'est peut-être parce que les pages Web que nous avons visitées ont été visitées en même temps.
