
 Périphériques technologiques
IA
Pratique d'ingénierie d'un modèle d'apprentissage profond à grande échelle pour la publicité à emporter
Périphériques technologiques
IA
Pratique d'ingénierie d'un modèle d'apprentissage profond à grande échelle pour la publicité à emporter
Pratique d'ingénierie d'un modèle d'apprentissage profond à grande échelle pour la publicité à emporter

Auteur : 亚劼英梁成龙 attendez
Introduction
#🎜 🎜# Comme L'activité de livraison de nourriture de Meituan continue de se développer, l'équipe du moteur publicitaire de livraison de nourriture a mené des explorations et des pratiques techniques dans plusieurs domaines et a obtenu certains résultats. Nous le partagerons en série, et le contenu comprend principalement : ① La pratique de la plateforme commerciale ; ② La pratique de l'ingénierie de modèles d'apprentissage profond à grande échelle ; ③ L'exploration et la pratique de l'informatique de proximité ; services de construction d'index à grande échelle et de récupération en ligne ; ⑤ Pratique de la plate-forme d'ingénierie des mécanismes. Il n'y a pas si longtemps, nous avons publié la pratique de la plateforme commerciale (Pour plus de détails, veuillez vous référer à "Exploration et pratique de la plateforme publicitaire à emporter Meituan # 🎜🎜#》一文). Cet article est le deuxième d'une série d'articles.Nous nous concentrerons sur les défis posés par les modèles profonds à grande échelle au niveau des liens complets, en partant de deux aspects : la latence en ligne et l'efficacité hors ligne, et en expliquant l'ingénierie de la publicité à grande échelle. -Modèles profonds à l'échelle Pratique, j'espère que cela pourra apporter de l'aide ou de l'inspiration à tout le monde. 1 Contexte
fait partie des activités principales d'Internet telles que la recherche, la recommandation et la publicité ( est appelé promotion de recherche ). Dans ce scénario, l'exploration de données et la modélisation des intérêts pour fournir aux utilisateurs des services de haute qualité sont devenues des éléments clés pour améliorer l'expérience utilisateur. Ces dernières années, pour le secteur de la recherche et de la promotion, des modèles d'apprentissage profond ont été largement mis en œuvre dans l'industrie à l'aide des dividendes des données et de la technologie matérielle. Dans le même temps, dans les scénarios CTR, l'industrie est progressivement passée du simple DNN petit. des modèles à de grands modèles d'intégration avec des milliards de paramètres ou même des modèles très grands. Le secteur d'activité de la publicité à emporter a principalement connu le processus d'évolution du « modèle LR superficiel (tree model) » -> « modèle d'apprentissage profond » -> « modèle d'apprentissage profond à grande échelle ». L’ensemble de la tendance évolutive passe progressivement de modèles simples basés sur des caractéristiques artificielles à des modèles complexes d’apprentissage en profondeur centrés sur les données. L'utilisation de grands modèles a considérablement amélioré la capacité d'expression du modèle, fait correspondre plus précisément l'offre et la demande et a offert davantage de possibilités de développement commercial ultérieur. Mais à mesure que l'échelle du modèle et des données continue d'augmenter, nous constatons que l'efficacité a la relation suivante avec eux : Comme le montre la figure ci-dessus, lorsque l'échelle des données et l'échelle du modèle augmentent, , la « durée » correspondante deviendra de plus en plus longue. Cette « durée » correspond au niveau hors ligne, reflété dans l'efficacité ; correspond au niveau en ligne, reflété dans la Latence. Et notre travail s'articule autour de l'optimisation de cette « durée ». 
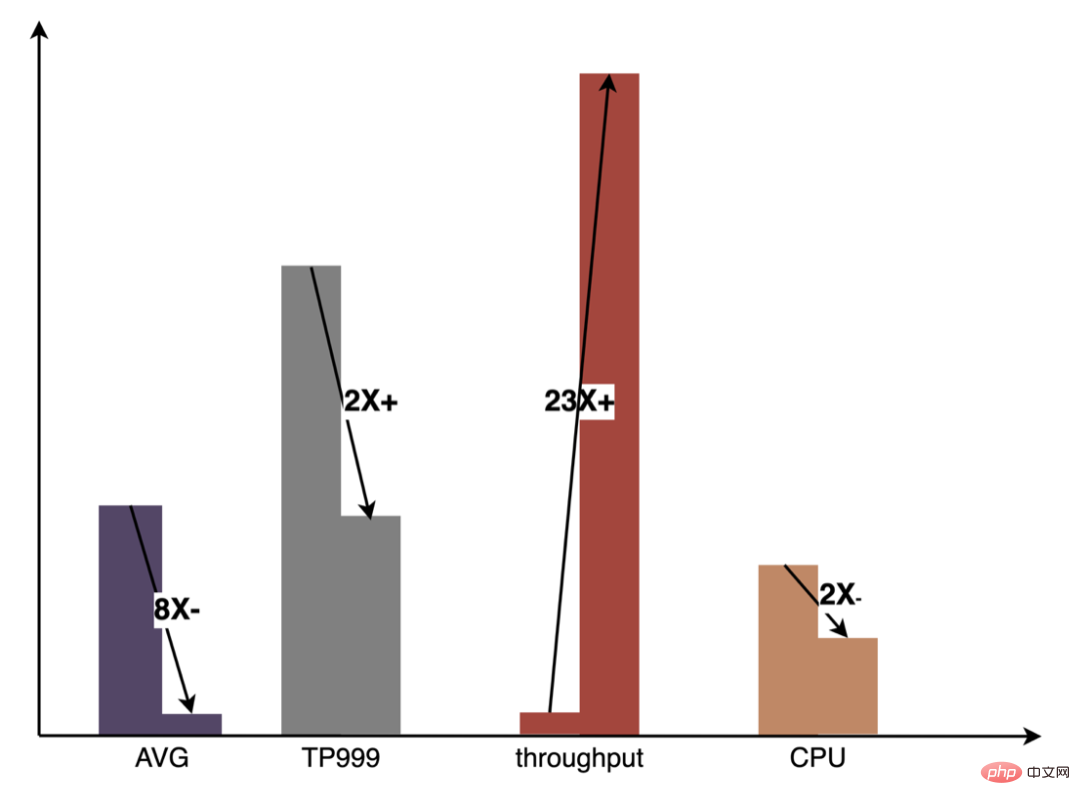
Par rapport aux petits modèles ordinaires, le problème central des grands modèles est le suivant : comme le À mesure que le volume et l'échelle du modèle augmentent des dizaines, voire des centaines de fois, le stockage, la communication et le calcul sur l'ensemble du lien seront confrontés à de nouveaux défis, qui affecteront l'efficacité des itérations hors ligne de l'algorithme. Comment surmonter une série de problèmes tels que les contraintes de retard en ligne ? Analysons d'abord l'ensemble du lien, comme indiqué ci-dessous :
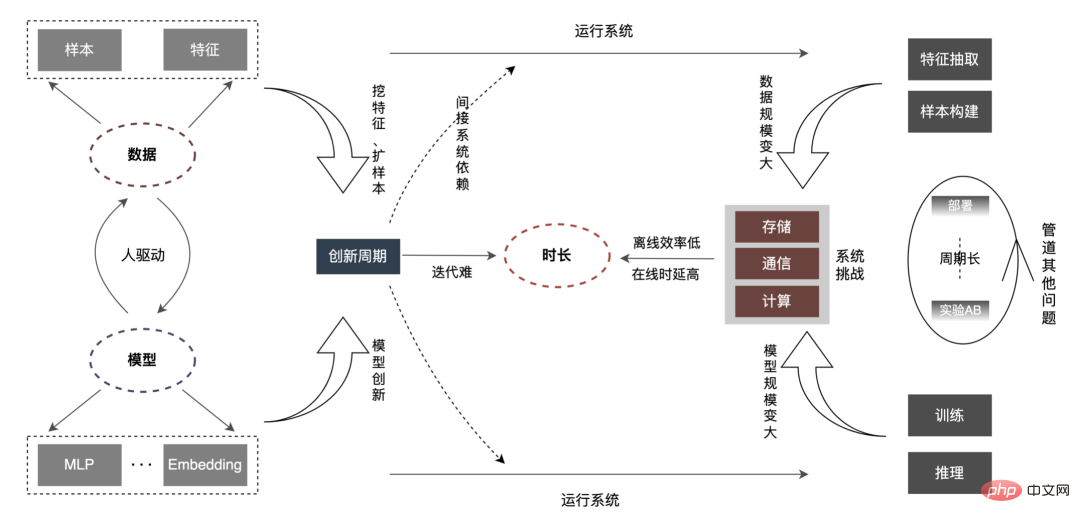
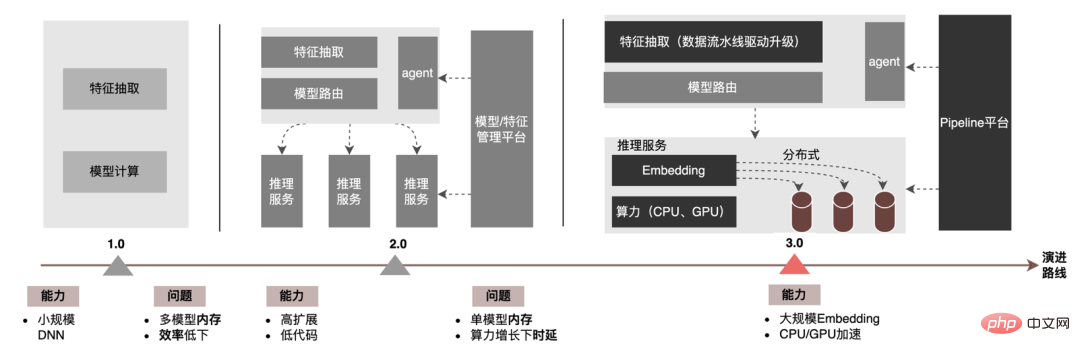
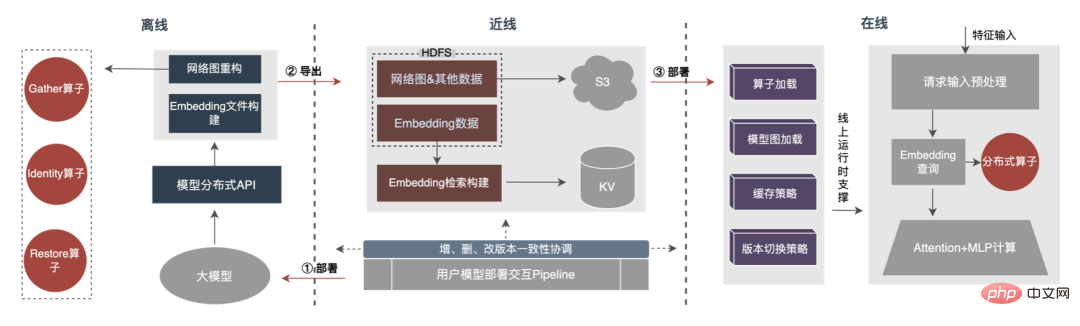
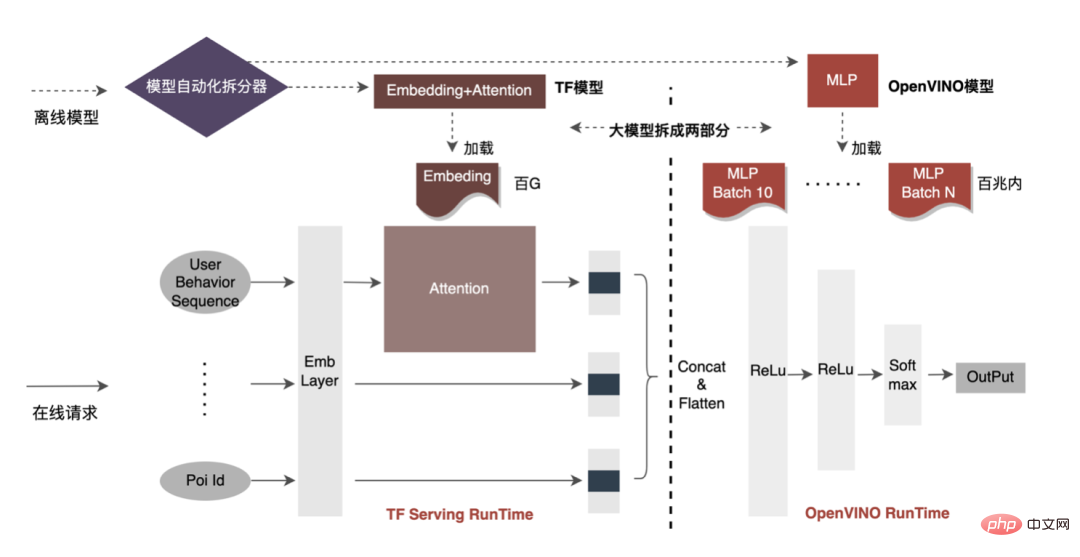
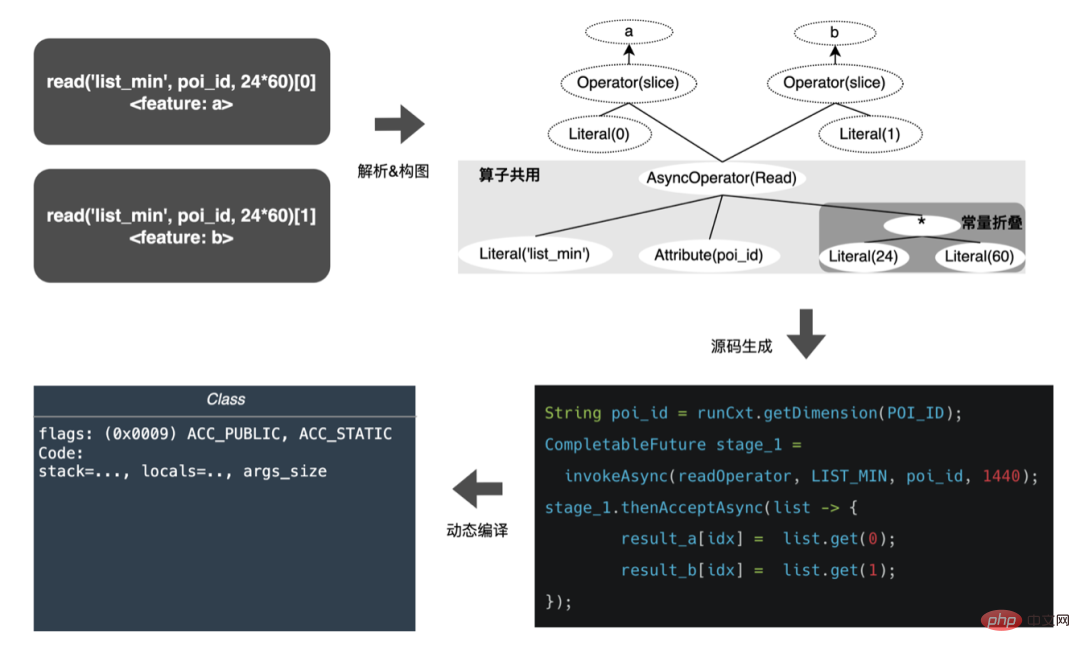
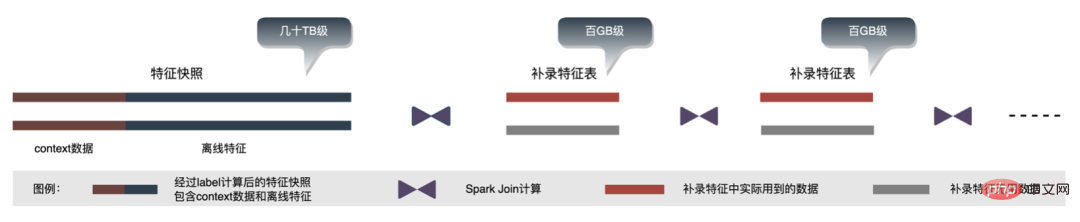
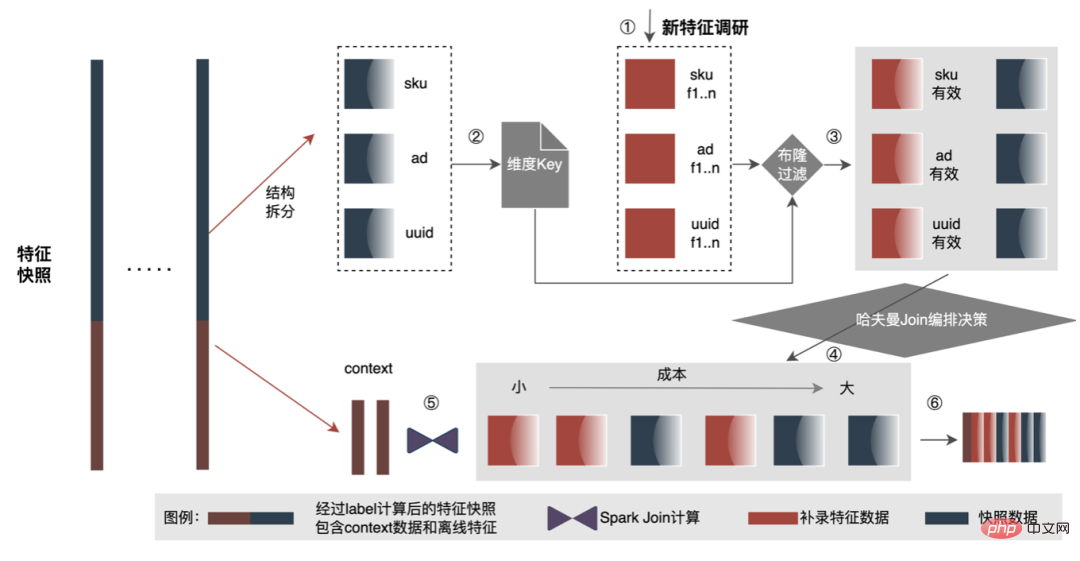
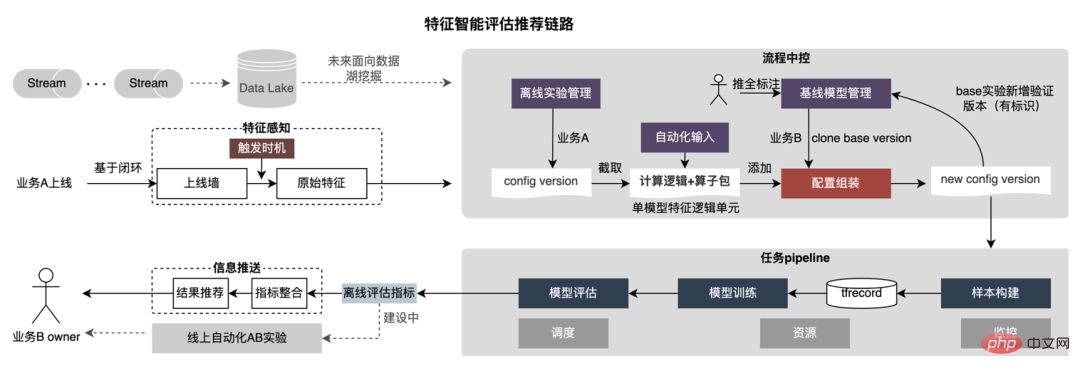
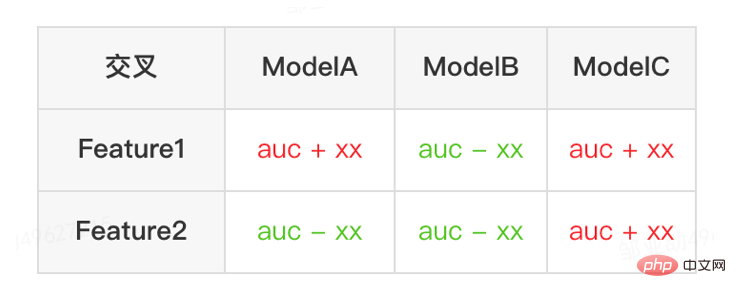
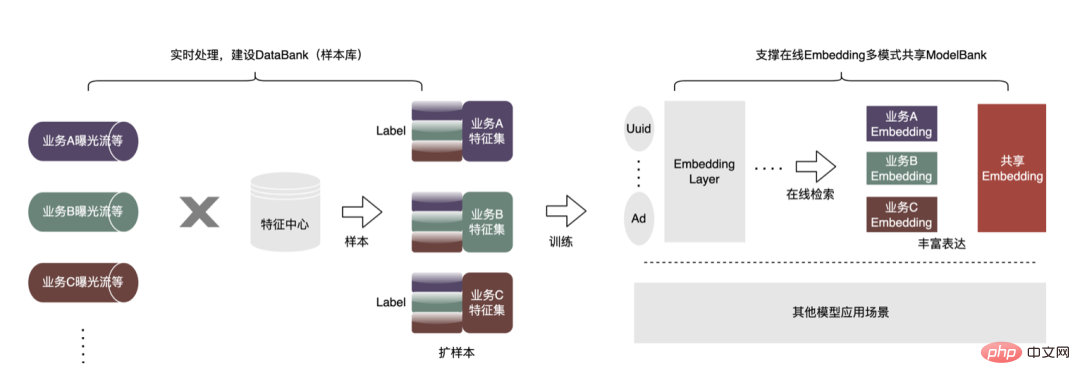
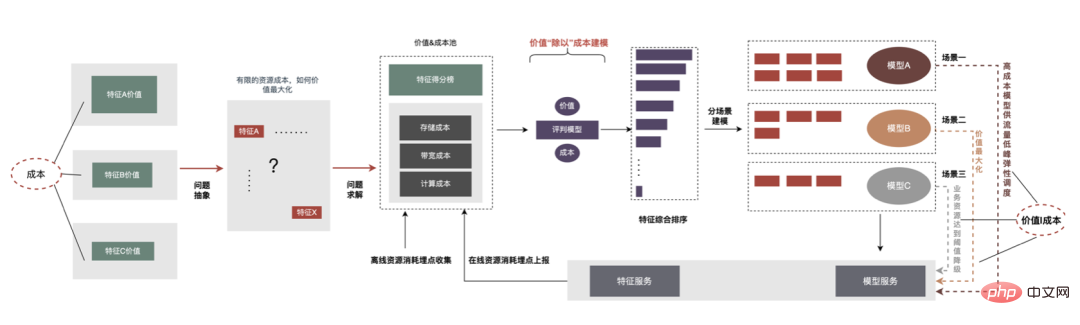
Cet article se concentre sur le retard en ligne (inférence de modèle, service de fonctionnalités), L'efficacité hors ligne (sample construction, préparation des données ) sera réalisée pour expliquer progressivement la pratique d'ingénierie de la publicité sur des modèles profonds à grande échelle. Nous partagerons comment optimiser la « durée » et d’autres problèmes connexes dans les chapitres suivants, alors restez à l’écoute. Au niveau de l'inférence de modèle, la publicité à emporter a connu trois versions. Depuis l'ère 1.0, elle prend en charge les niches. échelle DNN Comme le représente le modèle, à l'ère 2.0, les itérations multiservices à haute efficacité et à faible code étaient prises en charge, et dans l'ère 3.0 d'aujourd'hui, il a progressivement fait face aux besoins de puissance de calcul DNN d'apprentissage en profondeur et de stockage à grande échelle. Les principales tendances d'évolution sont présentées dans la figure ci-dessous : Pour les scénarios d'inférence de grands modèles, les deux problèmes centraux résolus par l'architecture 3.0 sont : "le stockage problème" et "problèmes de performances". Bien sûr, comment itérer sur N centaines de modèles G+, comment assurer la stabilité en ligne lorsque la charge de calcul augmente des dizaines de fois, comment renforcer le Pipeline, etc. sont également des défis auxquels le projet est confronté. Ci-dessous, nous nous concentrerons sur la manière dont l'architecture Model Inference 3.0 résout le problème du stockage de grands modèles via la « distribution » et sur la manière de résoudre les problèmes de performances et de débit grâce à l'accélération CPU/GPU. Les paramètres d'un grand modèle sont principalement divisés en deux parties : les paramètres clairsemés et les paramètres denses. Par conséquent, la clé pour résoudre le problème de la croissance à grande échelle des paramètres de modèle est de transformer les paramètres clairsemés du stockage sur une seule machine en stockage distribué. La méthode de transformation comprend deux parties : ① Conversion de la structure du réseau du modèle ; ② Exportation des paramètres clairsemés ; . Les méthodes de l'industrie pour obtenir des paramètres distribués sont grossièrement divisées en deux types : les services externes obtiennent les paramètres à l'avance et les transmettent au service de prédiction qui transforme en interne TF (TensorFlow ; ) opérateur pour obtenir les paramètres du stockage distribué. Afin de réduire le coût de modification architecturale et de réduire l'intrusion dans la structure du modèle existant, nous avons choisi d'obtenir des paramètres distribués en modifiant l'opérateur TF. Dans des circonstances normales, le modèle TF utilisera des opérateurs natifs pour lire les paramètres Sparse. L'opérateur principal est l'opérateur GatherV2. L'entrée de l'opérateur comporte principalement deux parties : ① Liste d'ID à interroger ; tableau des paramètres. La fonction de l'opérateur est de lire les données d'intégration correspondant à l'index de la liste d'ID à partir de la table d'intégration et de les renvoyer. Il s'agit essentiellement d'un processus de requête de hachage. Parmi eux, les paramètres Sparse stockés dans la table Embedding sont tous stockés dans la mémoire mono-machine dans le modèle mono-machine. La transformation de l'opérateur TF est essentiellement une transformation de la structure du réseau modèle. Les points centraux de la transformation comprennent principalement deux parties : ① Reconstruction du graphe de réseau ② Opérateurs distribués personnalisés. 1. Reconstruction du diagramme de réseau : Transformez la structure du réseau du modèle, remplacez l'opérateur TF natif par un opérateur distribué personnalisé et solidifiez la table d'intégration native. Le processus global est illustré dans la figure ci-dessous. Nous garantissons les exigences normales d'itération du grand modèle 100G grâce à la conversion de la structure du modèle distribué hors ligne, à la garantie de cohérence des données de proximité et à la mise en cache des données de point d'accès en ligne. On peut voir que le stockage utilisé par le stockage distribué est une capacité KV externe, qui sera remplacée à l'avenir par le service d'intégration plus efficace, flexible et facile à gérer. En plus des méthodes d'optimisation du modèle lui-même, il existe deux principales méthodes d'accélération du processeur courantes : ① Optimisation du jeu d'instructions, comme l'utilisation du jeu d'instructions AVX2, AVX512 ; ② Utilisation des bibliothèques d'accélération (TVM ; , OpenVINO ). Ci-dessous, nous nous concentrerons sur une partie de notre expérience pratique dans l'utilisation d'OpenVINO pour l'accélération du processeur. OpenVINO est un ensemble de cadres d'optimisation de l'accélération informatique basés sur l'apprentissage profond lancé par Intel, qui prend en charge l'optimisation de la compression, le calcul accéléré et d'autres fonctions des modèles d'apprentissage automatique. Le principe d'accélération d'OpenVINO est simplement résumé en deux parties : la fusion d'opérateurs linéaires et l'étalonnage de la précision des données. L'accélération du processeur accélère généralement l'inférence pour les files d'attente de candidats par lots fixes, mais dans les scénarios de recherche et de promotion, les files d'attente de candidats sont souvent dynamiques. Cela signifie qu'avant l'inférence de modèle, une opération de correspondance par lots doit être ajoutée, c'est-à-dire que la file d'attente dynamique des candidats Batch demandée est mappée sur un modèle Batch le plus proche, mais cela nécessite la construction de N modèles de correspondance, ce qui entraîne N fois l'utilisation de la mémoire. . Le volume du modèle actuel a atteint des centaines de gigaoctets et la mémoire est très limitée. Par conséquent, la sélection d’une structure de réseau raisonnable pour l’accélération est une question clé à prendre en compte. L'image ci-dessous représente la structure opérationnelle globale : À l'heure actuelle, la solution d'accélération CPU basée sur OpenVINO a obtenu de bons résultats dans l'environnement de production : lorsque le CPU est le même que la ligne de base, le débit du service est augmenté de 40 % et le délai moyen est réduit de 15%. Si vous souhaitez faire une certaine accélération au niveau du CPU, OpenVINO est un bon choix. D'une part, avec le développement des entreprises, les formes commerciales deviennent de plus en plus abondantes, le trafic devient de plus en plus élevé, les modèles deviennent plus larges et plus profonds et la consommation de puissance de calcul augmente fortement ; d'autre part, des scénarios publicitaires utilisant principalement le modèle DNN, impliquant un grand nombre d'opérations d'intégration de fonctionnalités clairsemées et de réseaux neuronaux en virgule flottante. En tant que service en ligne d'accès à la mémoire et de calcul intensif, il doit répondre aux exigences de faible latence et de débit élevé tout en garantissant la disponibilité, ce qui constitue également un défi pour la puissance de calcul d'une seule machine. Si ces conflits entre les besoins en ressources informatiques et l'espace ne sont pas bien résolus, ils limiteront considérablement le développement commercial : avant que le modèle ne soit élargi et approfondi, les services d'inférence purement CPU peuvent fournir un débit considérable, mais une fois le modèle élargi et approfondi, les calculs deviennent complexe Afin de garantir une haute disponibilité, une grande quantité de ressources machine doit être consommée, ce qui rend les grands modèles impossibles à appliquer en ligne à grande échelle. À l'heure actuelle, une solution courante dans l'industrie consiste à utiliser le GPU pour résoudre ce problème. Le GPU lui-même est plus adapté aux tâches gourmandes en calcul. L'utilisation de GPU nécessite de résoudre les défis suivants : comment atteindre un débit aussi élevé que possible tout en garantissant une disponibilité et une faible latence, tout en prenant en compte la facilité d'utilisation et la polyvalence. À cette fin, nous avons également réalisé de nombreux travaux pratiques sur les GPU, tels que TensorFlow-GPU, TensorFlow-TensorRT, TensorRT, etc. Afin de prendre en compte la flexibilité de TF et l'effet d'accélération de TensorRT, nous adoptons une conception d'architecture indépendante en deux étapes de TensorFlow+TensorRT. La phase d'inférence de l'apprentissage profond a des exigences très élevées en termes de puissance de calcul et de latence. Si le réseau neuronal formé est directement déployé du côté de l'inférence, il est très probable qu'il sera insuffisant. puissance de calcul pour fonctionner. Ou des problèmes tels qu'un long temps de raisonnement. Par conséquent, nous devons effectuer certaines optimisations sur le réseau neuronal formé. L'idée générale d'optimiser les modèles de réseaux neuronaux dans l'industrie peut être optimisée sous différents aspects tels que la compression des modèles, la fusion de différentes couches de réseau, la fragmentation et l'utilisation de types de données de faible précision. Elle nécessite même une optimisation ciblée. sur les caractéristiques du matériel. Pour cela, nous optimisons principalement autour des deux objectifs suivants : Ce qui suit se concentrera sur les deux objectifs ci-dessus et présentera en détail certains des travaux que nous avons effectués dans optimisation du modèle, optimisation de la fusion et optimisation du moteur. 1. Calcul et déduplication de transmission : lors de l'inférence, le même lot ne contient qu'une seule information utilisateur, de sorte que les informations utilisateur peuvent être réduites de la taille du lot à 1 avant l'inférence, ce qui est vraiment nécessaire Développez à nouveau pendant l'inférence pour réduire la copie de transmission de données et la surcharge de calcul répétée. Comme le montre la figure ci-dessous, vous pouvez interroger les informations sur les fonctionnalités de la classe User une seule fois avant l'inférence, les couper uniquement dans les sous-réseaux liés à l'utilisateur, puis les développer lorsque vous devez calculer l'association. 2. Optimisation de la précision des données : Étant donné que la formation du modèle nécessite une rétropropagation pour mettre à jour les gradients, la précision des données doit être plus élevée tandis que l'inférence du modèle ne nécessite que l'inférence directe. dans le but d'assurer l'effet, utilisez FP16 ou une précision mixte pour l'optimisation, économisez de l'espace mémoire, réduisez la surcharge de transmission et améliorez les performances et le débit d'inférence. 3. Calculation Pushdown : La structure du modèle CTR est principalement composée de trois couches : Embedding, Attention et MLP. La couche Embedding est orientée vers l'acquisition de données, et l'Attention est partiellement orientée vers la logique et partiellement biaisée. Vers le calcul, afin d'exploiter pleinement le potentiel du GPU, la majeure partie de la logique de calcul d'Attention et MLP dans la structure du modèle CTR est déplacée du CPU vers le GPU pour le calcul, et le débit global est grandement amélioré. Lors de l'inférence de modèle en ligne, le fonctionnement de chaque couche est complété par le GPU. En fait, le CPU termine le calcul en démarrant différents noyaux CUDA. Cependant, le noyau CUDA calcule les tenseurs très rapidement. beaucoup de temps est souvent perdu au démarrage du noyau CUDA et à la lecture et à l'écriture des tenseurs d'entrée/sortie de chaque couche, ce qui provoque un goulot d'étranglement de la bande passante mémoire et un gaspillage des ressources GPU. Ici, nous présenterons principalement la partie TensorRT optimisation automatique et optimisation manuelle. 1. Optimisation automatique : TensorRT est un optimiseur d'inférence d'apprentissage profond haute performance qui peut fournir un déploiement d'inférence à faible latence et à haut débit pour les applications d'apprentissage profond. TensorRT peut être utilisé pour accélérer l'inférence sur des modèles à très grande échelle, des plateformes embarquées ou des plateformes de conduite autonome. TensorRT peut désormais prendre en charge presque tous les frameworks d'apprentissage profond tels que TensorFlow, Caffe, MXNet et PyTorch. La combinaison de TensorRT avec les GPU NVIDIA peut permettre un déploiement et une inférence rapides et efficaces dans presque tous les frameworks. Et certaines optimisations ne nécessitent pas trop de participation de l'utilisateur, comme certaines Layer Fusion, Kernel Auto-Tuning, etc. 2. Optimisation manuelle : Comme nous le savons tous, le GPU convient aux opérateurs gourmands en calculs, mais pas aussi bien aux autres types d'opérateurs (opérateurs de calcul légers, opérateurs d'opérations logiques, etc. .) amical. Lors de l'utilisation des calculs GPU, chaque opération passe généralement par plusieurs processus : le CPU alloue de la mémoire vidéo sur le GPU -> Le CPU envoie des données au GPU -> Le CPU démarre le noyau CUDA -> Le CPU récupère les données -> Le CPU libère la mémoire vidéo du GPU. Afin de réduire les frais généraux tels que la planification, le lancement du noyau et l'accès à la mémoire, une intégration réseau est requise. En raison de la structure flexible et changeante du grand modèle CTR, il est difficile d'unifier les méthodes de fusion de réseaux et seuls des problèmes spécifiques peuvent être analysés en détail. Par exemple, dans le sens vertical, Cast, Unsqueeze et Less sont fusionnés, et TensorRT internal Conv, BN et Relu sont fusionnés ; dans le sens horizontal, les opérateurs d'entrée de même dimension sont fusionnés ; À cette fin, nous utilisons des outils d'analyse des performances liés à NVIDIA (NVIDIA Nsight Systems, NVIDIA Nsight Compute, etc.) pour analyser des problèmes spécifiques en fonction de scénarios commerciaux en ligne réels. Intégrez ces outils d'analyse des performances dans l'environnement d'inférence en ligne pour obtenir le fichier GPU Profing pendant le processus d'inférence. Grâce au fichier Profing, nous pouvons clairement voir le processus d'inférence.Nous avons constaté que le phénomène lié au lancement du noyau de certains opérateurs dans l'ensemble de l'inférence est grave, que les écarts entre certains opérateurs sont importants et qu'il y a place à l'optimisation, comme le montre l'exemple ci-dessous. le chiffre suivant : À cette fin, analysez l'ensemble du réseau à l'aide d'outils d'analyse des performances et de modèles convertis pour découvrir les parties optimisées par TensorRT, puis effectuez l'intégration du réseau sur d'autres sous-structures du réseau qui peuvent être optimisées, tout en garantissant également que ces sous-structures sont L'ensemble du réseau occupe une certaine proportion pour garantir que la densité de calcul puisse augmenter dans une certaine mesure après l'intégration. Quant au type de méthode d'intégration de réseau à utiliser, elle peut être utilisée de manière flexible selon le scénario spécifique. La figure suivante est une comparaison des diagrammes de sous-structure avant et après notre intégration : Le modèle va de la formation hors ligne au chargement final en ligne. L'ensemble du processus est fastidieux et sujet aux erreurs, et le modèle ne peut pas être utilisé universellement. différentes cartes GPU, différentes versions de TensorRT et CUDA. Cela apporte plus de possibilités d'erreurs dans la conversion de modèle. Par conséquent, afin d'améliorer l'efficacité globale de l'itération du modèle, nous avons construit des fonctionnalités pertinentes dans Pipeline, comme le montre la figure ci-dessous : La construction du pipeline comprend deux parties : le processus de fractionnement et de conversion du modèle côté hors ligne et le processus de déploiement du modèle côté en ligne : #🎜🎜 ## 🎜🎜# L'extraction de fonctionnalités est la pré-étape du calcul du modèle. Qu'il s'agisse d'un modèle LR traditionnel ou d'un modèle d'apprentissage en profondeur de plus en plus populaire, les informations doivent être obtenues via l'extraction de fonctionnalités. Dans le blog précédent En nous appuyant sur WholeStageCodeGen de Spark, notre objectif est de compiler l'intégralité du calcul de caractéristiques DSL dans une méthode exécutable, réduisant ainsi la perte de performances lors de l'exécution du code. L'ensemble du processus de compilation peut être divisé en : front-end (FrontEnd), optimiseur (Optimizer) et back-end (BackEnd ). Le front-end est principalement responsable de l'analyse du DSL cible et de la conversion du code source en AST ou IR ; l'optimiseur optimise le code intermédiaire obtenu en fonction du front-end pour rendre le code plus efficace ; code en code natif pour la plate-forme respective. L'implémentation spécifique est la suivante : Après optimisation, la traduction du graphe DAG du nœud, c'est-à-dire le back-end l'implémentation du code, a été décidée pour des performances ultimes. L'une des difficultés réside également dans la raison pour laquelle les moteurs d'expression open source existants ne peuvent pas être utilisés directement : le calcul de caractéristiques DSL n'est pas une expression purement informatique. Il peut décrire le processus d'acquisition et de traitement des fonctionnalités grâce à une combinaison d'opérateurs de lecture et d'opérateurs de conversion : Le processus d'obtention de fonctionnalités du système de stockage est une tâche de type IO. Par exemple, interrogez le système KV distant. CodeGen n'est pas parfait. Le code généré dynamiquement réduit la lisibilité du code et augmente les coûts de débogage. Cependant, avec CodeGen comme couche d'adaptation, il s'ouvre également. espace pour une optimisation plus approfondie. Basé sur CodeGen et l'implémentation asynchrone non bloquante, de bons avantages ont été obtenus en ligne. D'une part, cela réduit le calcul fastidieux des fonctionnalités, d'autre part, cela réduit également considérablement la charge du processeur et améliore le débit du système. À l'avenir, nous continuerons à tirer parti de CodeGen et à procéder à des optimisations ciblées dans le processus de compilation back-end, comme l'exploration de la combinaison d'instructions matérielles (telles que SIMD) ou du calcul hétérogène ( tels que GPU# 🎜🎜#) pour une optimisation plus approfondie. Le service de prédiction en ligne a une architecture à deux couches dans son ensemble. La couche d'extraction de fonctionnalités est responsable du routage du modèle. et calcul des caractéristiques Calcul du modèle La couche est responsable des calculs du modèle. Le processus du système d'origine consiste à regrouper les résultats du calcul des caractéristiques dans une matrice de M (Predicted Batch Size) × N (Sample width), puis à le sérialiser. transmis à la couche informatique. La raison en est, d'une part, des raisons historiques.Le format d'entrée de nombreux premiers modèles simples non-DNN est une matrice, d'autre part, une fois la couche de routage épissée, la couche informatique peut être utilisée directement sans conversion. , le format du tableau est relativement compact et permet de gagner du temps sur la transmission réseau. Afin de résoudre les problèmes ci-dessus, le processus optimisé ajoute une couche de conversion au-dessus de la couche de transmission pour convertir les caractéristiques du modèle calculé dans le format requis en fonction de la configuration de MDFL, comme Tensor, matrice ou utilisation hors ligne. Format CSV, etc. Les fonctionnalités discrètes et les fonctionnalités de séquence peuvent être unifiées en fonctionnalités clairsemées. Au cours de l'étape de traitement des fonctionnalités, les fonctionnalités d'origine seront hachées et transformées en fonctionnalités de type ID. Face à des fonctionnalités comportant des centaines de milliards de dimensions, le processus de concaténation et de hachage de chaînes ne peut pas répondre aux exigences en termes d'espace d'expression et de performances. Sur la base de recherches industrielles, nous avons conçu et appliqué un format d'encodage de fonctionnalités basé sur le codage Slot : Parmi eux, feature_hash est la valeur de la valeur de fonctionnalité d'origine après hachage. Les entités entières peuvent être remplies directement. Les entités non entières ou les entités croisées sont d'abord hachées, puis remplies si le nombre dépasse 44 bits, il sera tronqué. Après le lancement du système de codage Slot, il a non seulement amélioré les performances du calcul des caractéristiques en ligne, mais a également considérablement amélioré l'effet du modèle. Afin de résoudre le problème de cohérence en ligne et hors ligne, l'industrie met généralement en ligne les données de fonctionnalités utilisées pour la notation en temps réel, appelées instantanés de fonctionnalités ; d'utiliser de simples échantillons de construction d'étiquettes hors ligne via l'épissage et le remplissage de fonctionnalités, car cette méthode entraînera une plus grande incohérence des données. L'architecture originale est illustrée dans la figure ci-dessous : À mesure que l'échelle des fonctionnalités devient plus grande et que les scénarios d'itération deviennent de plus en plus complexes, le problème majeur est que le service d'extraction de fonctionnalités en ligne est soumis à une forte pression, suivi de les coûts de collecte de l'ensemble du flux de données sont trop élevés. Ce schéma de collecte d'échantillons présente les problèmes suivants : Afin de résoudre les problèmes ci-dessus, il existe deux solutions courantes dans l'industrie : ①Traitement du flux en temps réel Flink ; ②Traitement secondaire du cache KV. Le processus spécifique est illustré dans la figure ci-dessous : Du point de vue de la réduction des calculs invalides, toutes les données demandées ne seront pas exposées. La stratégie entraîne une demande plus forte en données exposées, de sorte que le transfert du traitement au niveau journalier vers le traitement en flux peut considérablement améliorer le délai de préparation des données. Deuxièmement, à partir du contenu des données, les caractéristiques incluent les données modifiées au niveau de la demande et les données modifiées au niveau du jour. Le lien peut séparer de manière flexible le traitement des deux, ce qui peut considérablement améliorer l'utilisation des ressources. : #🎜 🎜# 1. Répartition des données : Résoudre le problème du grand volume de transmission de données. (Feature Snapshot Streaming Gros problème ), les étiquettes prédites et les données en temps réel correspondent une par une, et les données hors ligne sont accessibles deux fois pendant la redistribution, ce qui peut réduire considérablement la taille du lien flux de données. 2. Consommation différée Méthode Join : Résolvez le problème de l'utilisation importante de la mémoire. 3. Échantillon d'entrée supplémentaire de fonctionnalité : Grâce à Label's Join, le nombre de demandes de fonctionnalité pour une entrée supplémentaire ici est pas à 20 % en ligne ; l'échantillon est retardé et fusionné avec l'exposition pour filtrer la demande de service de modèle d'exposition (Contexte+fonctionnalité en temps réel), puis toutes les fonctionnalités hors ligne sont enregistrées dans formez des exemples de données complets. Écrivez dans HBase. 5.2 Stockage structuré Grande pression de stockage; d'un point de vue informatique Il semble que l'utilisation du processus de calcul d'origine, en raison des limitations de ressources du moteur de calcul (Spark) (#🎜🎜 # utilise la lecture aléatoire, les données de la phase d'écriture aléatoire seront déposées sur le disque si la mémoire allouée est insuffisante, des placements multiples et un tri externe se produiront ), ce qui nécessite une mémoire de la même taille que ses propres données et. plus de CU informatiques pour terminer efficacement le calcul, prend beaucoup de mémoire . Le processus de base du processus de construction de l'échantillon est illustré dans la figure ci-dessous : Lors du réenregistrement des fonctionnalités, les problèmes suivants surviennent : Afin de résoudre le problème de l'efficacité lente de la construction d'échantillons, nous commencerons par la gestion de la structure des données à court terme. Le processus détaillé est le suivant : Les ressources de stockage des données hors ligne sont économisées de plus de 80 % et l'efficacité de la construction des échantillons est augmentée de plus de 200 %. Actuellement, l'ensemble des données d'échantillon est également mis en œuvre sur la base du lac de données pour améliorer encore l'efficacité des données. La plateforme a accumulé une grande quantité de contenu précieux tel que des fonctionnalités, des échantillons et des modèles. On espère qu'en réutilisant ces actifs de données, elle pourra aider les stratèges à mieux mener des itérations commerciales et à obtenir de meilleurs revenus commerciaux. . L'optimisation des fonctionnalités représente 40 % de toutes les méthodes utilisées par le personnel chargé des algorithmes pour améliorer les effets du modèle. Cependant, la méthode traditionnelle d'exploration de fonctionnalités présente des problèmes tels qu'une longue consommation de temps, une faible efficacité d'exploration et une extraction de fonctionnalités répétée. la dimension des fonctionnalités. S'il existe un processus expérimental automatisé pour vérifier l'effet de n'importe quelle fonctionnalité et recommander les indicateurs d'effet final aux utilisateurs, cela aidera sans aucun doute les stratèges à gagner beaucoup de temps. Une fois la construction complète du lien terminée, il vous suffit de saisir différents ensembles de fonctionnalités candidates pour générer les indicateurs d'effet correspondants. À cette fin, la plateforme a construit un mécanisme intelligent pour « l'addition », la « soustraction », la « multiplication » et la « division » de caractéristiques et d'échantillons. La recommandation de fonctionnalités est basée sur la méthode de test de modèle, réutiliser les fonctionnalités dans des modèles existants d'autres secteurs d'activité, construire de nouveaux échantillons et modèles ; comparer les effets hors ligne du nouveau modèle et du modèle de base, obtenir Les avantages des nouvelles fonctionnalités sont automatiquement transmis aux dirigeants d'entreprise concernés. Le processus de recommandation de fonctionnalités spécifiques est illustré dans la figure ci-dessous : Après que la recommandation de fonctionnalités ait été implémentée dans la publicité et obtenu certains avantages, nous avons effectué une nouvelle exploration au niveau de l'autonomisation des fonctionnalités. Avec l'optimisation continue du modèle, la vitesse d'expansion des fonctionnalités est très rapide et la consommation de ressources des services de modèle augmente fortement. Il est impératif d'éliminer les fonctionnalités redondantes et de « mincir » le modèle. Par conséquent, la plate-forme a créé un ensemble d’outils de sélection de fonctionnalités de bout en bout. Au final, après 40% des fonctionnalités du modèle interne hors ligne, la baisse des indicateurs d'activité est toujours maîtrisée dans un seuil raisonnable. Afin d'obtenir de meilleurs effets de modèle, de nouvelles explorations ont été lancées dans le domaine de la publicité, notamment les grands modèles, le temps réel, les bibliothèques de fonctionnalités, etc. Il y a un objectif clé derrière ces explorations : le besoin de données plus nombreuses et de meilleure qualité pour rendre les modèles plus intelligents et plus efficaces. À partir de la situation actuelle de la publicité, la construction d'un exemple de base de données (Data Bank) est proposée pour intégrer davantage de types et une plus grande échelle de données externes et l'appliquer aux entreprises existantes. Comme le montre la figure ci-dessous : Nous avons mis en place une plateforme universelle de partage d'échantillons, sur laquelle d'autres secteurs d'activité peuvent être empruntés pour générer des échantillons incrémentiels. Il construit également une architecture de partage d'intégration commune pour réaliser l'intégration commerciale à grande et à petite échelle. Voici un exemple de réutilisation d'échantillons non publicitaires dans le secteur publicitaire. La méthode spécifique est la suivante : Par exemple, en réutilisant des échantillons non publicitaires dans une entreprise de publicité, le nombre d'échantillons a été augmenté plusieurs fois. En combinaison avec l'algorithme d'apprentissage par transfert, l'AUC hors ligne a augmenté de quatre millièmes et le CPM a augmenté. augmenté de 1% après sa mise en ligne. En outre, nous construisons également une bibliothèque d'exemples de thèmes publicitaires pour gérer uniformément les exemples de données générés par chaque entreprise (métadonnées unifiées), exposer la classification unifiée des exemples de thèmes aux utilisateurs, s'inscrire, rechercher et réutiliser rapidement, ainsi qu'un stockage unifié pour le couche inférieure, économisez les ressources de stockage et de calcul, réduisez la jointure des données et améliorez la rapidité. La "soustraction" de fonctionnalités peut éliminer certaines fonctionnalités qui n'ont aucun effet positif, mais grâce à l'observation, on constate qu'il existe encore de nombreuses fonctionnalités de peu de valeur dans le modèle. Par conséquent, nous pouvons aller plus loin en considérant globalement à la fois la valeur et le coût. Sous les contraintes de coût de l’ensemble du lien, nous pouvons éliminer les fonctionnalités avec des entrées et des sorties relativement faibles et réduire la consommation de ressources. Ce processus de résolution sous contraintes de coût est défini comme « division ». Le processus global est illustré dans la figure ci-dessous. Dans la dimension hors ligne, nous avons établi un système d'évaluation de la valeur des fonctionnalités pour donner le coût et la valeur des fonctionnalités. Lors du raisonnement en ligne, nous pouvons utiliser les informations sur la valeur des fonctionnalités pour effectuer des opérations telles que la dégradation du trafic et l'élasticité des fonctionnalités. calculs et effectuer une "division" "Les étapes clés sont les suivantes : Ce qui précède est notre pratique anti-«augmentation» dans les projets d'apprentissage en profondeur à grande échelle pour aider à réduire les coûts des entreprises et à améliorer l'efficacité. À l'avenir, nous continuerons à explorer et à pratiquer dans les aspects suivants :
3.1.1 Conversion de la structure du réseau de modèle
 2. Opérateur distribué personnalisé : modifiez le processus de requête d'intégration en fonction de la liste d'ID, interrogez à partir de la table d'intégration locale et modifiez-le pour interroger à partir du KV distribué.
2. Opérateur distribué personnalisé : modifiez le processus de requête d'intégration en fonction de la liste d'ID, interrogez à partir de la table d'intégration locale et modifiez-le pour interroger à partir du KV distribué.
3.1.2 Exportation de paramètres clairsemés
3.2 Accélération du processeur
3.3 Accélération GPU
3.3.1 Analyse de l'accélération
3.3.2 Objectifs d'optimisation
3.3.3 Optimisation du modèle
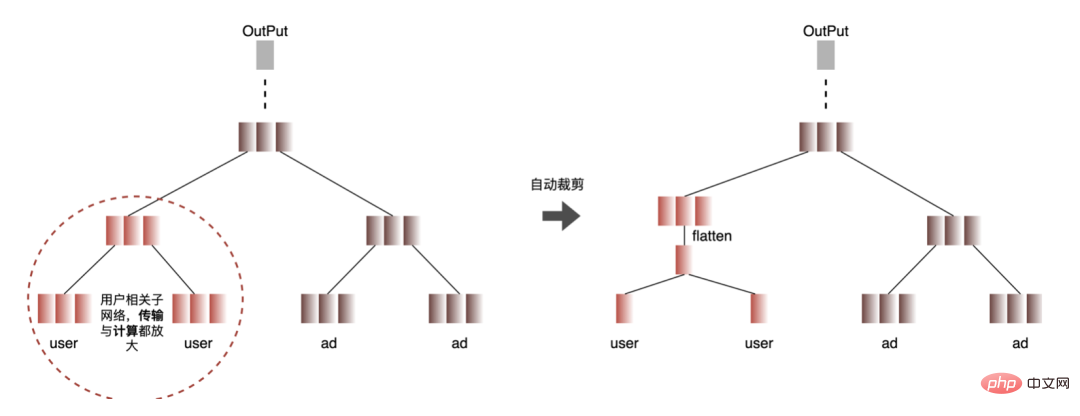
3.3.4 Optimisation de la fusion
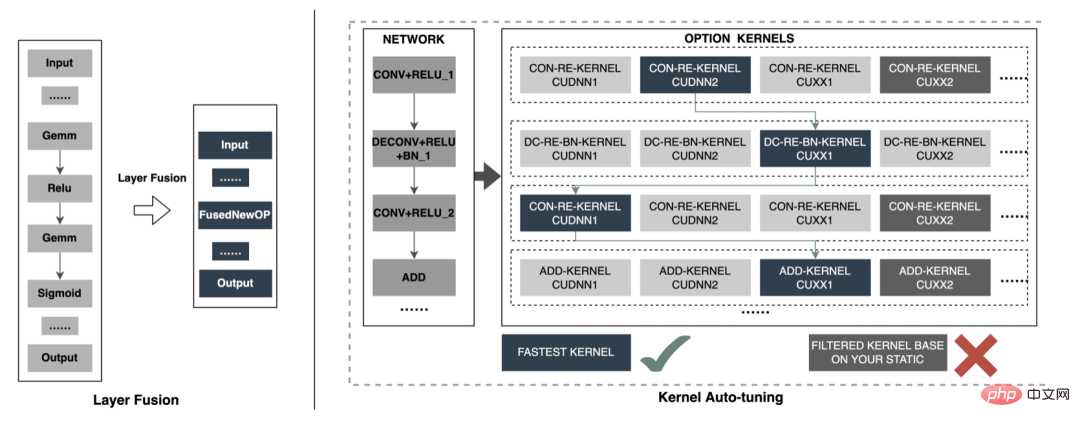
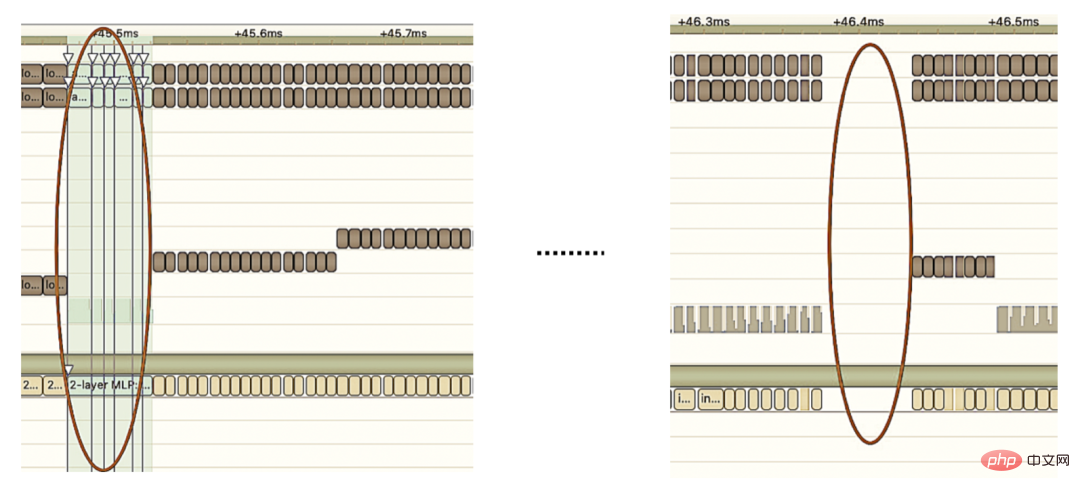
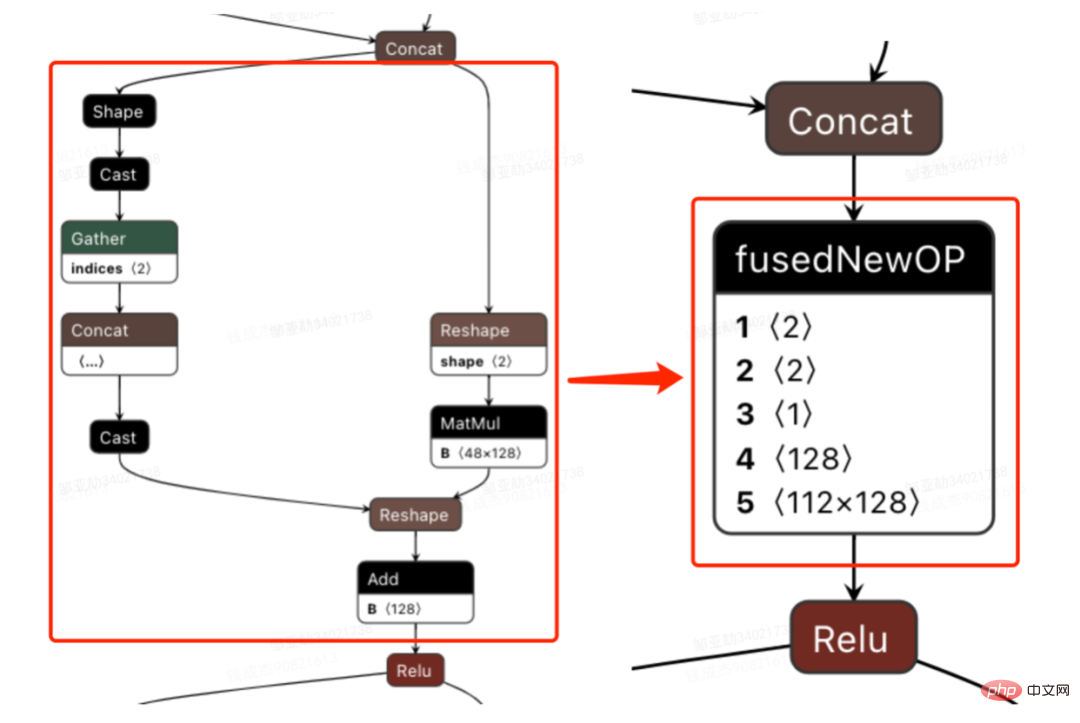
3.3.5 Optimisation du moteur
.
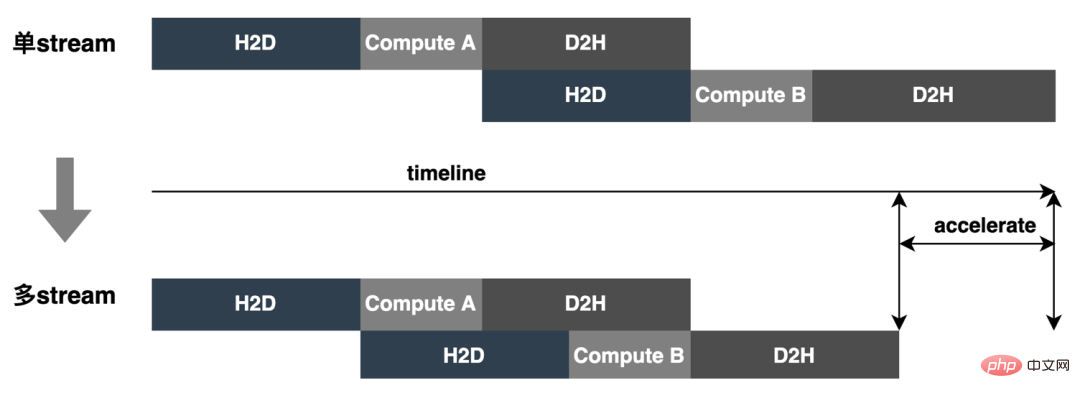
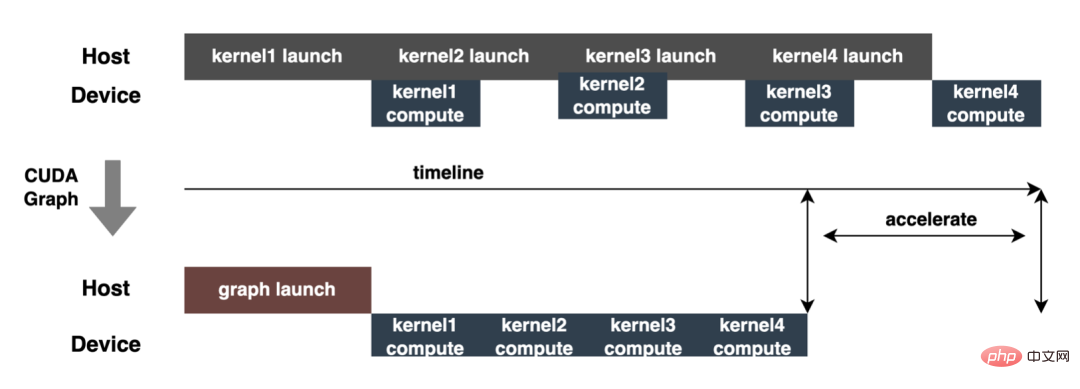
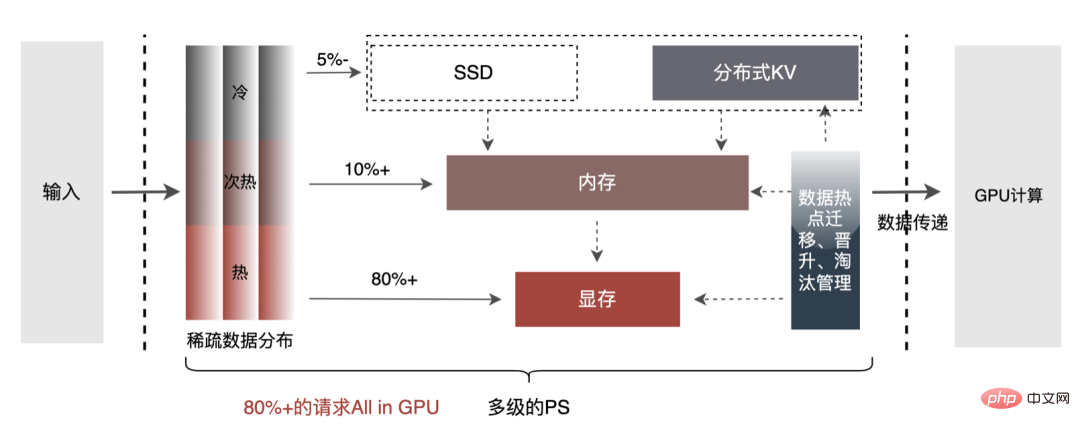
3.3.6 Pipeline
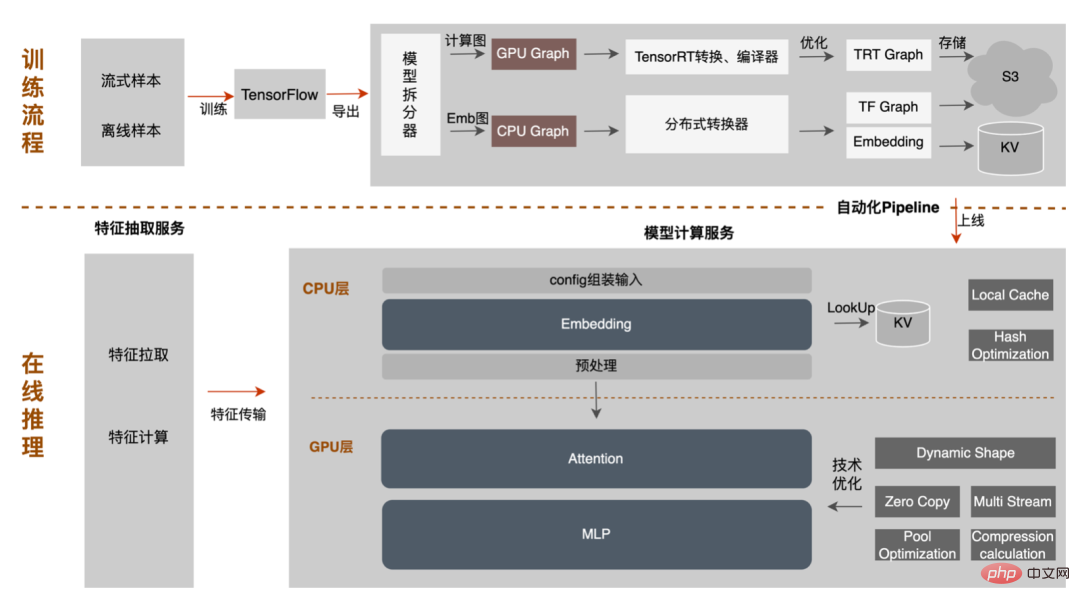
 Cependant, avec le développement itératif des modèles, les modèles DNN sont progressivement devenus courants, et les inconvénients de la transmission matricielle sont également très évidents :
Cependant, avec le développement itératif des modèles, les modèles DNN sont progressivement devenus courants, et les inconvénients de la transmission matricielle sont également très évidents :
 La plupart des modèles en ligne actuels sont des modèles TF Afin de réduire davantage la consommation de transmission, la plateforme a conçu le format Tensor Sequence pour stocker chaque matrice Tensor : parmi eux, r_flag est utilisé pour marquer s'il s'agit d'une fonctionnalité de type élément, et la longueur représente la caractéristique de l'élément. Longueur, la valeur est M (Nombre d'éléments) × NF (Longueur de la caractéristique), les données sont utilisées pour stocker les valeurs réelles des caractéristiques de l'élément, les valeurs des caractéristiques M sont stockées à plat. , et pour les fonctionnalités de type requête, elles sont renseignées directement. Basée sur le format compact Tensor Sequence, la structure des données est plus compacte et la quantité de données transmises sur le réseau est réduite. Le format de transmission optimisé a également obtenu de bons résultats en ligne. La taille des requêtes de la couche de routage appelant la couche informatique a été réduite de plus de 50 % et le temps de transmission du réseau a été considérablement réduit.
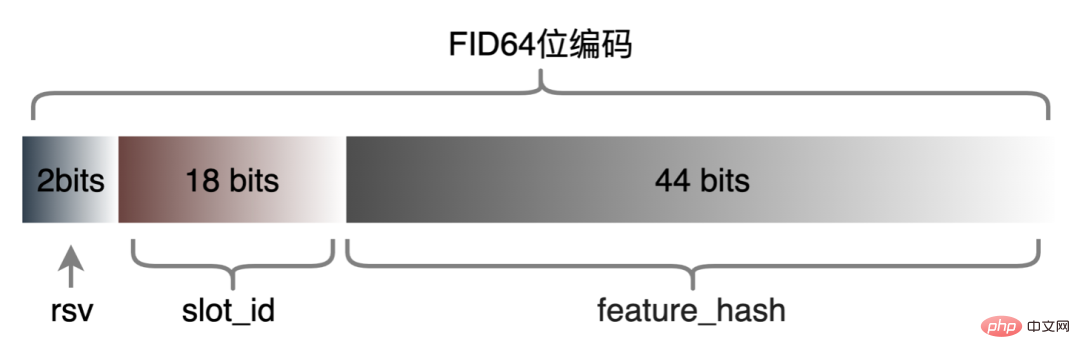
La plupart des modèles en ligne actuels sont des modèles TF Afin de réduire davantage la consommation de transmission, la plateforme a conçu le format Tensor Sequence pour stocker chaque matrice Tensor : parmi eux, r_flag est utilisé pour marquer s'il s'agit d'une fonctionnalité de type élément, et la longueur représente la caractéristique de l'élément. Longueur, la valeur est M (Nombre d'éléments) × NF (Longueur de la caractéristique), les données sont utilisées pour stocker les valeurs réelles des caractéristiques de l'élément, les valeurs des caractéristiques M sont stockées à plat. , et pour les fonctionnalités de type requête, elles sont renseignées directement. Basée sur le format compact Tensor Sequence, la structure des données est plus compacte et la quantité de données transmises sur le réseau est réduite. Le format de transmission optimisé a également obtenu de bons résultats en ligne. La taille des requêtes de la couche de routage appelant la couche informatique a été réduite de plus de 50 % et le temps de transmission du réseau a été considérablement réduit. 4.3 Codage de fonctionnalités d'identification de haute dimension
5 Construction d'échantillons
5.1 Échantillon de streaming

5.1.1 Solutions courantes
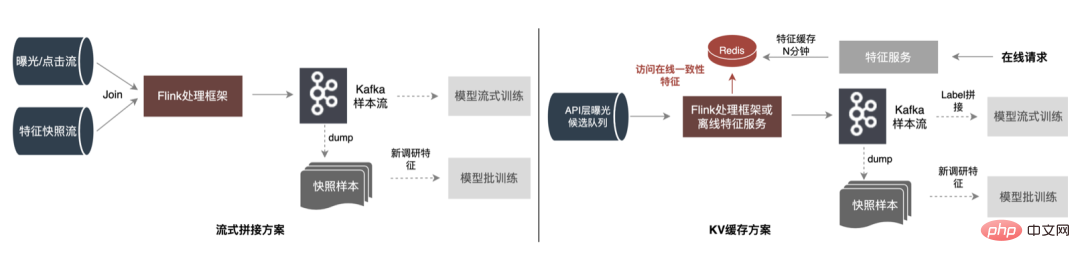
5.1.2 Amélioration et optimisation
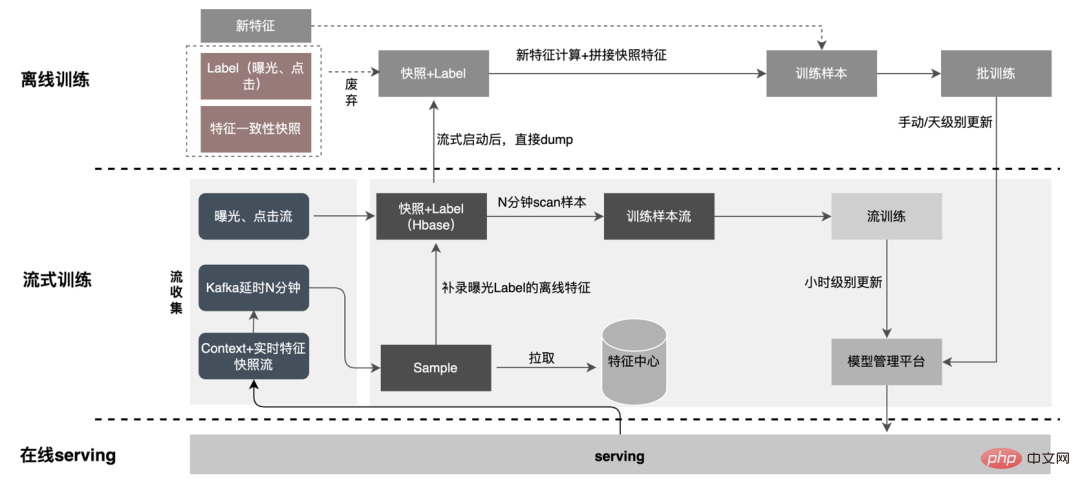
Il n'y a que des fonctionnalités de contexte + temps réel dans l'exemple de flux, ce qui augmente la stabilité du flux de données lu en même temps, puisque. seules les fonctionnalités en temps réel doivent être stockées, le stockage sur le disque dur de Kafka diminue de plus de 10 fois.
Le flux d'exposition est utilisé comme flux principal et écrit dans HBase en même temps, afin de permettre à d'autres flux d'être exposés sur la jointure. dans HBase plus tard, la RowKey est écrite sur Redis ; les flux suivants sont écrits dans HBase via RowKey, et l'épissage de l'exposition, des clics et des fonctionnalités est effectué à l'aide d'un stockage externe pour garantir que le système peut fonctionner de manière stable en fonction de la quantité de les données augmentent.
6 Préparation des données
6.1 Faire un "ajout"
6.2 Faire une "soustraction"

6.3 Faire de la "multiplication"
6.4 Faire une "division"
7 Résumé et perspectives
8
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Le modèle MoE open source le plus puissant au monde est ici, avec des capacités chinoises comparables à celles du GPT-4, et le prix ne représente que près d'un pour cent de celui du GPT-4-Turbo.
May 07, 2024 pm 04:13 PM
Le modèle MoE open source le plus puissant au monde est ici, avec des capacités chinoises comparables à celles du GPT-4, et le prix ne représente que près d'un pour cent de celui du GPT-4-Turbo.
May 07, 2024 pm 04:13 PM
Imaginez un modèle d'intelligence artificielle qui non seulement a la capacité de surpasser l'informatique traditionnelle, mais qui permet également d'obtenir des performances plus efficaces à moindre coût. Ce n'est pas de la science-fiction, DeepSeek-V2[1], le modèle MoE open source le plus puissant au monde est ici. DeepSeek-V2 est un puissant mélange de modèle de langage d'experts (MoE) présentant les caractéristiques d'une formation économique et d'une inférence efficace. Il est constitué de 236B paramètres, dont 21B servent à activer chaque marqueur. Par rapport à DeepSeek67B, DeepSeek-V2 offre des performances plus élevées, tout en économisant 42,5 % des coûts de formation, en réduisant le cache KV de 93,3 % et en augmentant le débit de génération maximal à 5,76 fois. DeepSeek est une entreprise explorant l'intelligence artificielle générale
 Comment obtenir le comptoir à emporter Meituan
Apr 08, 2024 pm 03:41 PM
Comment obtenir le comptoir à emporter Meituan
Apr 08, 2024 pm 03:41 PM
1. Lorsque le livreur place le repas dans le placard, il informera le client de récupérer le repas par SMS, appel téléphonique ou message Meituan. 2. Les clients peuvent scanner le code QR sur l'armoire alimentaire via WeChat ou Meituan APP pour accéder à l'applet de l'armoire alimentaire intelligente. 3. Entrez le code de retrait ou utilisez la fonction « ouverture de l'armoire en un clic » pour ouvrir facilement la porte de l'armoire et sortir les plats à emporter.
 Bonjour, Atlas électrique ! Le robot Boston Dynamics revient à la vie, des mouvements étranges à 180 degrés effraient Musk
Apr 18, 2024 pm 07:58 PM
Bonjour, Atlas électrique ! Le robot Boston Dynamics revient à la vie, des mouvements étranges à 180 degrés effraient Musk
Apr 18, 2024 pm 07:58 PM
Boston Dynamics Atlas entre officiellement dans l’ère des robots électriques ! Hier, l'Atlas hydraulique s'est retiré "en larmes" de la scène de l'histoire. Aujourd'hui, Boston Dynamics a annoncé que l'Atlas électrique était au travail. Il semble que dans le domaine des robots humanoïdes commerciaux, Boston Dynamics soit déterminé à concurrencer Tesla. Après la sortie de la nouvelle vidéo, elle a déjà été visionnée par plus d’un million de personnes en seulement dix heures. Les personnes âgées partent et de nouveaux rôles apparaissent. C'est une nécessité historique. Il ne fait aucun doute que cette année est l’année explosive des robots humanoïdes. Les internautes ont commenté : Les progrès des robots ont fait ressembler la cérémonie d'ouverture de cette année à des êtres humains, et le degré de liberté est bien plus grand que celui des humains. Mais n'est-ce vraiment pas un film d'horreur ? Au début de la vidéo, Atlas est allongé calmement sur le sol, apparemment sur le dos. Ce qui suit est à couper le souffle
 KAN, qui remplace MLP, a été étendu à la convolution par des projets open source
Jun 01, 2024 pm 10:03 PM
KAN, qui remplace MLP, a été étendu à la convolution par des projets open source
Jun 01, 2024 pm 10:03 PM
Plus tôt ce mois-ci, des chercheurs du MIT et d'autres institutions ont proposé une alternative très prometteuse au MLP – KAN. KAN surpasse MLP en termes de précision et d’interprétabilité. Et il peut surpasser le MLP fonctionnant avec un plus grand nombre de paramètres avec un très petit nombre de paramètres. Par exemple, les auteurs ont déclaré avoir utilisé KAN pour reproduire les résultats de DeepMind avec un réseau plus petit et un degré d'automatisation plus élevé. Plus précisément, le MLP de DeepMind compte environ 300 000 paramètres, tandis que le KAN n'en compte qu'environ 200. KAN a une base mathématique solide comme MLP est basé sur le théorème d'approximation universelle, tandis que KAN est basé sur le théorème de représentation de Kolmogorov-Arnold. Comme le montre la figure ci-dessous, KAN a
 L'IA bouleverse la recherche mathématique ! Le lauréat de la médaille Fields et mathématicien sino-américain a dirigé 11 articles les mieux classés | Aimé par Terence Tao
Apr 09, 2024 am 11:52 AM
L'IA bouleverse la recherche mathématique ! Le lauréat de la médaille Fields et mathématicien sino-américain a dirigé 11 articles les mieux classés | Aimé par Terence Tao
Apr 09, 2024 am 11:52 AM
L’IA change effectivement les mathématiques. Récemment, Tao Zhexuan, qui a prêté une attention particulière à cette question, a transmis le dernier numéro du « Bulletin de l'American Mathematical Society » (Bulletin de l'American Mathematical Society). En se concentrant sur le thème « Les machines changeront-elles les mathématiques ? », de nombreux mathématiciens ont exprimé leurs opinions. L'ensemble du processus a été plein d'étincelles, intense et passionnant. L'auteur dispose d'une équipe solide, comprenant Akshay Venkatesh, lauréat de la médaille Fields, le mathématicien chinois Zheng Lejun, l'informaticien de l'Université de New York Ernest Davis et de nombreux autres universitaires bien connus du secteur. Le monde de l’IA a radicalement changé. Vous savez, bon nombre de ces articles ont été soumis il y a un an.
 Google est ravi : les performances de JAX surpassent Pytorch et TensorFlow ! Cela pourrait devenir le choix le plus rapide pour la formation à l'inférence GPU
Apr 01, 2024 pm 07:46 PM
Google est ravi : les performances de JAX surpassent Pytorch et TensorFlow ! Cela pourrait devenir le choix le plus rapide pour la formation à l'inférence GPU
Apr 01, 2024 pm 07:46 PM
Les performances de JAX, promu par Google, ont dépassé celles de Pytorch et TensorFlow lors de récents tests de référence, se classant au premier rang sur 7 indicateurs. Et le test n’a pas été fait sur le TPU présentant les meilleures performances JAX. Bien que parmi les développeurs, Pytorch soit toujours plus populaire que Tensorflow. Mais à l’avenir, des modèles plus volumineux seront peut-être formés et exécutés sur la base de la plate-forme JAX. Modèles Récemment, l'équipe Keras a comparé trois backends (TensorFlow, JAX, PyTorch) avec l'implémentation native de PyTorch et Keras2 avec TensorFlow. Premièrement, ils sélectionnent un ensemble de
 Comment récupérer le mot de passe de paiement oublié de Meituan_Comment récupérer le mot de passe de paiement oublié de Meituan
Mar 28, 2024 pm 03:29 PM
Comment récupérer le mot de passe de paiement oublié de Meituan_Comment récupérer le mot de passe de paiement oublié de Meituan
Mar 28, 2024 pm 03:29 PM
1. Tout d'abord, nous entrons dans le logiciel Meituan, recherchons les paramètres sur la page Mon menu et cliquons pour accéder aux paramètres. 2. Ensuite, nous trouvons les paramètres de paiement sur la page des paramètres et cliquons pour entrer les paramètres de paiement. 3. Entrez dans le centre de paiement, recherchez le paramètre de mot de passe de paiement et cliquez pour saisir le paramètre de mot de passe de paiement. 4. Dans la page de configuration du mot de passe de paiement, recherchez la récupération du mot de passe de paiement et cliquez pour accéder à l'option de la page. 5. Entrez les informations du mot de passe de paiement que vous souhaitez récupérer, cliquez sur Vérifier et vous pourrez récupérer le mot de passe de paiement après l'avoir transmis.
 Les robots Tesla travaillent dans les usines, Musk : Le degré de liberté des mains atteindra 22 cette année !
May 06, 2024 pm 04:13 PM
Les robots Tesla travaillent dans les usines, Musk : Le degré de liberté des mains atteindra 22 cette année !
May 06, 2024 pm 04:13 PM
La dernière vidéo du robot Optimus de Tesla est sortie, et il peut déjà fonctionner en usine. À vitesse normale, il trie les batteries (les batteries 4680 de Tesla) comme ceci : Le responsable a également publié à quoi cela ressemble à une vitesse 20 fois supérieure - sur un petit "poste de travail", en sélectionnant et en sélectionnant et en sélectionnant : Cette fois, il est publié L'un des points forts de la vidéo est qu'Optimus réalise ce travail en usine, de manière totalement autonome, sans intervention humaine tout au long du processus. Et du point de vue d'Optimus, il peut également récupérer et placer la batterie tordue, en se concentrant sur la correction automatique des erreurs : concernant la main d'Optimus, le scientifique de NVIDIA Jim Fan a donné une évaluation élevée : la main d'Optimus est l'un des robots à cinq doigts du monde. le plus adroit. Ses mains ne sont pas seulement tactiles
