
 développement back-end
Tutoriel Python
Pandas et PySpark unissent leurs forces pour atteindre à la fois fonctionnalité et rapidité !
développement back-end
Tutoriel Python
Pandas et PySpark unissent leurs forces pour atteindre à la fois fonctionnalité et rapidité !
Pandas et PySpark unissent leurs forces pour atteindre à la fois fonctionnalité et rapidité !

Les data scientists ou praticiens des données qui utilisent Python pour le traitement des données ne sont pas étrangers au package de science des données pandas, et il existe également de gros utilisateurs de pandas comme Yun Duojun. La plupart des premières lignes de code écrites au début du projet sont importées. pandas en tant que PD. On peut dire que les pandas sont des adeptes du traitement des données ! Et ses défauts sont également très évidents. Les Pandas ne peuvent être traités que sur une seule machine et ne peuvent pas évoluer de manière linéaire avec la quantité de données. Par exemple, si pandas tente de lire un ensemble de données supérieur à la mémoire disponible d'une machine, il échouera en raison d'une mémoire insuffisante.
De plus, pandas est très lent à traiter des données volumineuses. Bien qu'il existe d'autres bibliothèques comme Dask ou Vaex pour optimiser et améliorer la vitesse de traitement des données, c'est un jeu d'enfant devant le framework divin du traitement du Big Data, Spark.
Heureusement, dans la nouvelle version Spark 3.2, une nouvelle API Pandas est apparue, qui intègre la plupart des fonctions pandas dans PySpark. En utilisant l'interface pandas, vous pouvez utiliser Spark, car l'API Pandas sur Spark utilise Spark en arrière-plan. peut obtenir l'effet d'une coopération forte, qui peut être considérée comme très puissante et très pratique.
Tout a commencé au Spark + AI Summit 2019. Koalas est un projet open source qui utilise Pandas sur Spark. Au début, il ne couvrait qu’une petite partie des fonctionnalités de Pandas, mais sa taille a progressivement augmenté. Désormais, dans la nouvelle version Spark 3.2, Koalas a été fusionné dans PySpark.
Spark intègre désormais l'API Pandas, vous pouvez donc exécuter Pandas sur Spark. Nous n'avons besoin de changer qu'une seule ligne de code :
import pyspark.pandas as ps
Nous pouvons en tirer de nombreux avantages :
- Si nous sommes familiers avec Python et Pandas, mais pas avec Spark, nous pouvons omettre le processus d'apprentissage compliqué et utiliser PySpark immédiatement.
- Une seule base de code peut être utilisée pour tout : petites et grandes données, machines uniques et distribuées.
- Vous pouvez exécuter le code Pandas plus rapidement sur le framework distribué Spark.
Le dernier point est particulièrement remarquable.
D'une part, l'informatique distribuée peut être appliquée au code dans Pandas. Et avec le moteur Spark, votre code sera plus rapide même sur une seule machine ! Le graphique ci-dessous montre la comparaison des performances entre l'exécution de Spark sur une machine avec 96 vCPU et 384 Gio de mémoire et l'appel de pandas seuls pour analyser un ensemble de données CSV de 130 Go.
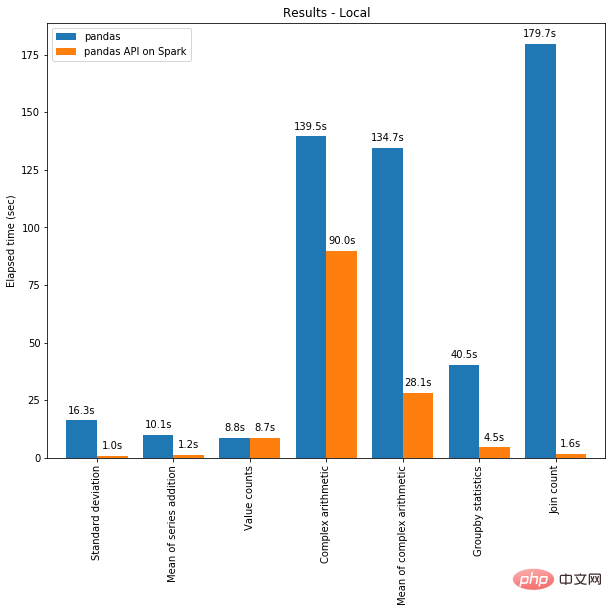
Le multi-threading et Spark SQL Catalyst Optimizer aident tous deux à optimiser les performances. Par exemple, l'opération Join count est 4 fois plus rapide avec la génération de code sur toute l'étape : 5,9 secondes sans génération de code et 1,6 seconde avec génération de code.
Spark présente des avantages particulièrement importants dans les opérations de chaînage. L'optimiseur de requêtes Catalyst reconnaît les filtres pour filtrer les données intelligemment et peut appliquer des jointures basées sur le disque, tandis que Pandas préfère charger toutes les données en mémoire à chaque étape.
Vous avez hâte d'essayer comment écrire du code à l'aide de l'API Pandas sur Spark ? Commençons maintenant !
Basculer entre Pandas / Pandas-on-Spark / Spark
La première chose que vous devez savoir est ce que nous utilisons exactement. Lorsque vous utilisez Pandas, utilisez la classe pandas.core.frame.DataFrame. Lorsque vous utilisez l'API pandas dans Spark, utilisez pyspark.pandas.frame.DataFrame. Bien que les deux soient similaires, ils ne sont pas identiques. La principale différence est que le premier est dans une seule machine, tandis que le second est distribué.
Il est possible de créer un Dataframe à l'aide de Pandas-on-Spark et de le convertir en Pandas et vice versa :
# import Pandas-on-Spark import pyspark.pandas as ps # 使用 Pandas-on-Spark 创建一个 DataFrame ps_df = ps.DataFrame(range(10)) # 将 Pandas-on-Spark Dataframe 转换为 Pandas Dataframe pd_df = ps_df.to_pandas() # 将 Pandas Dataframe 转换为 Pandas-on-Spark Dataframe ps_df = ps.from_pandas(pd_df)
Notez que si vous utilisez plusieurs machines, lors de la conversion d'un Dataframe Pandas-on-Spark en Pandas Dataframe, Data est transféré de plusieurs machines vers une seule machine et vice versa (voir le guide PySpark [1]).
Il est également possible de convertir un Dataframe Pandas-on-Spark en Spark DataFrame et vice versa :
# 使用 Pandas-on-Spark 创建一个 DataFrame ps_df = ps.DataFrame(range(10)) # 将 Pandas-on-Spark Dataframe 转换为 Spark Dataframe spark_df = ps_df.to_spark() # 将 Spark Dataframe 转换为 Pandas-on-Spark Dataframe ps_df_new = spark_df.to_pandas_on_spark()
Comment le type de données change-t-il ?
Les types de données sont fondamentalement les mêmes lors de l'utilisation de Pandas-on-Spark et Pandas. Lors de la conversion d'un DataFrame Pandas-on-Spark en Spark DataFrame, les types de données sont automatiquement convertis vers le type approprié (voir Guide PySpark [2])
L'exemple suivant montre comment les types de données sont convertis à partir d'un DataFrame PySpark lors de la conversion Convertissez en DataFrame pandas-on-Spark.
>>> sdf = spark.createDataFrame([ ... (1, Decimal(1.0), 1., 1., 1, 1, 1, datetime(2020, 10, 27), "1", True, datetime(2020, 10, 27)), ... ], 'tinyint tinyint, decimal decimal, float float, double double, integer integer, long long, short short, timestamp timestamp, string string, boolean boolean, date date') >>> sdf
DataFrame[tinyint: tinyint, decimal: decimal(10,0), float: float, double: double, integer: int, long: bigint, short: smallint, timestamp: timestamp, string: string, boolean: boolean, date: date]
psdf = sdf.pandas_api() psdf.dtypes
tinyintint8 decimalobject float float32 doublefloat64 integer int32 longint64 short int16 timestampdatetime64[ns] string object booleanbool date object dtype: object
Fonctions Pandas-on-Spark vs Spark
DataFrame dans Spark et ses fonctions les plus couramment utilisées dans Pandas-on-Spark. Notez que la seule différence de syntaxe entre Pandas-on-Spark et Pandas est la ligne import pyspark.pandas as ps.
当你看完如下内容后,你会发现,即使您不熟悉 Spark,也可以通过 Pandas API 轻松使用。
导入库
# 运行Spark
from pyspark.sql import SparkSession
spark = SparkSession.builder
.appName("Spark")
.getOrCreate()
# 在Spark上运行Pandas
import pyspark.pandas as ps读取数据
以 old dog iris 数据集为例。
# SPARK
sdf = spark.read.options(inferSchema='True',
header='True').csv('iris.csv')
# PANDAS-ON-SPARK
pdf = ps.read_csv('iris.csv')选择
# SPARK
sdf.select("sepal_length","sepal_width").show()
# PANDAS-ON-SPARK
pdf[["sepal_length","sepal_width"]].head()删除列
# SPARK
sdf.drop('sepal_length').show()# PANDAS-ON-SPARK
pdf.drop('sepal_length').head()删除重复项
# SPARK sdf.dropDuplicates(["sepal_length","sepal_width"]).show() # PANDAS-ON-SPARK pdf[["sepal_length", "sepal_width"]].drop_duplicates()
筛选
# SPARK sdf.filter( (sdf.flower_type == "Iris-setosa") & (sdf.petal_length > 1.5) ).show() # PANDAS-ON-SPARK pdf.loc[ (pdf.flower_type == "Iris-setosa") & (pdf.petal_length > 1.5) ].head()
计数
# SPARK sdf.filter(sdf.flower_type == "Iris-virginica").count() # PANDAS-ON-SPARK pdf.loc[pdf.flower_type == "Iris-virginica"].count()
唯一值
# SPARK
sdf.select("flower_type").distinct().show()
# PANDAS-ON-SPARK
pdf["flower_type"].unique()排序
# SPARK
sdf.sort("sepal_length", "sepal_width").show()
# PANDAS-ON-SPARK
pdf.sort_values(["sepal_length", "sepal_width"]).head()分组
# SPARK
sdf.groupBy("flower_type").count().show()
# PANDAS-ON-SPARK
pdf.groupby("flower_type").count()替换
# SPARK
sdf.replace("Iris-setosa", "setosa").show()
# PANDAS-ON-SPARK
pdf.replace("Iris-setosa", "setosa").head()连接
#SPARK sdf.union(sdf) # PANDAS-ON-SPARK pdf.append(pdf)
transform 和 apply 函数应用
有许多 API 允许用户针对 pandas-on-Spark DataFrame 应用函数,例如:
DataFrame.transform() DataFrame.apply() DataFrame.pandas_on_spark.transform_batch() DataFrame.pandas_on_spark.apply_batch() Series.pandas_on_spark.transform_batch()
每个 API 都有不同的用途,并且在内部工作方式不同。
transform 和 apply
DataFrame.transform()和DataFrame.apply()之间的主要区别在于,前者需要返回相同长度的输入,而后者不需要。
# transform
psdf = ps.DataFrame({'a': [1,2,3], 'b':[4,5,6]})
def pandas_plus(pser):
return pser + 1# 应该总是返回与输入相同的长度。
psdf.transform(pandas_plus)
# apply
psdf = ps.DataFrame({'a': [1,2,3], 'b':[5,6,7]})
def pandas_plus(pser):
return pser[pser % 2 == 1]# 允许任意长度
psdf.apply(pandas_plus)在这种情况下,每个函数采用一个 pandas Series,Spark 上的 pandas API 以分布式方式计算函数,如下所示。
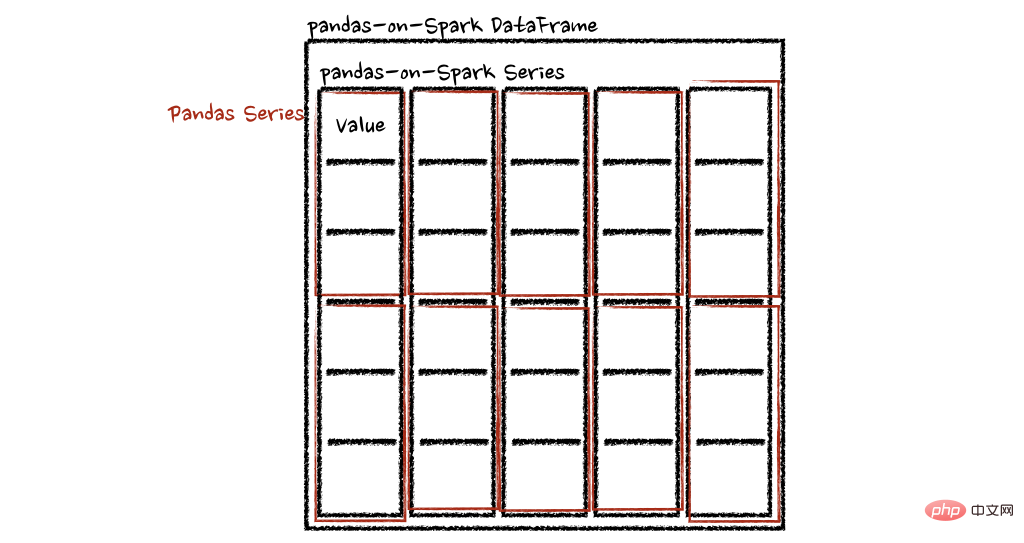
在“列”轴的情况下,该函数将每一行作为一个熊猫系列。
psdf = ps.DataFrame({'a': [1,2,3], 'b':[4,5,6]})
def pandas_plus(pser):
return sum(pser)# 允许任意长度
psdf.apply(pandas_plus, axis='columns')上面的示例将每一行的总和计算为pands Series
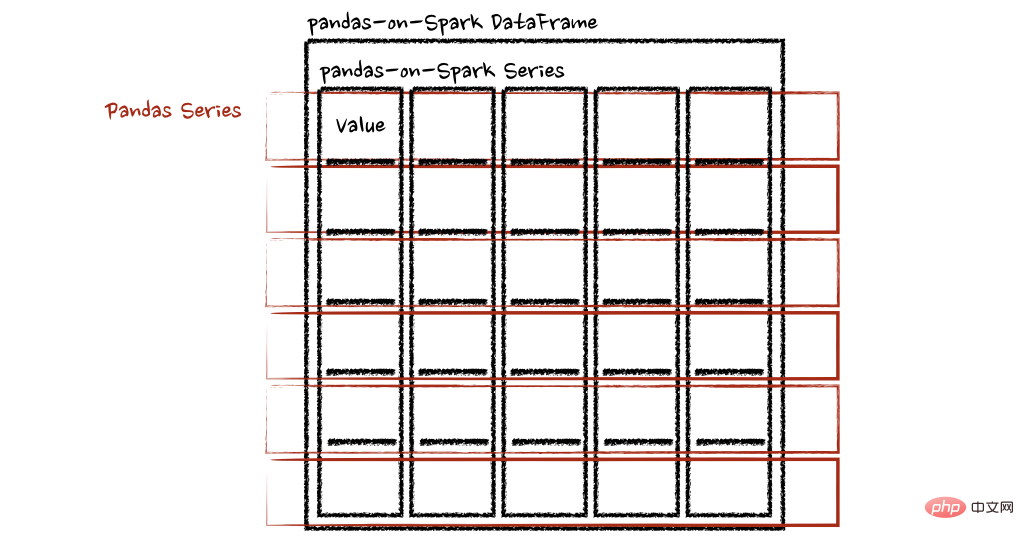
pandas_on_spark.transform_batch和pandas_on_spark.apply_batch
batch 后缀表示 pandas-on-Spark DataFrame 或 Series 中的每个块。API 对 pandas-on-Spark DataFrame 或 Series 进行切片,然后以 pandas DataFrame 或 Series 作为输入和输出应用给定函数。请参阅以下示例:
psdf = ps.DataFrame({'a': [1,2,3], 'b':[4,5,6]})
def pandas_plus(pdf):
return pdf + 1# 应该总是返回与输入相同的长度。
psdf.pandas_on_spark.transform_batch(pandas_plus)
psdf = ps.DataFrame({'a': [1,2,3], 'b':[4,5,6]})
def pandas_plus(pdf):
return pdf[pdf.a > 1]# 允许任意长度
psdf.pandas_on_spark.apply_batch(pandas_plus)两个示例中的函数都将 pandas DataFrame 作为 pandas-on-Spark DataFrame 的一个块,并输出一个 pandas DataFrame。Spark 上的 Pandas API 将 pandas 数据帧组合为 pandas-on-Spark 数据帧。
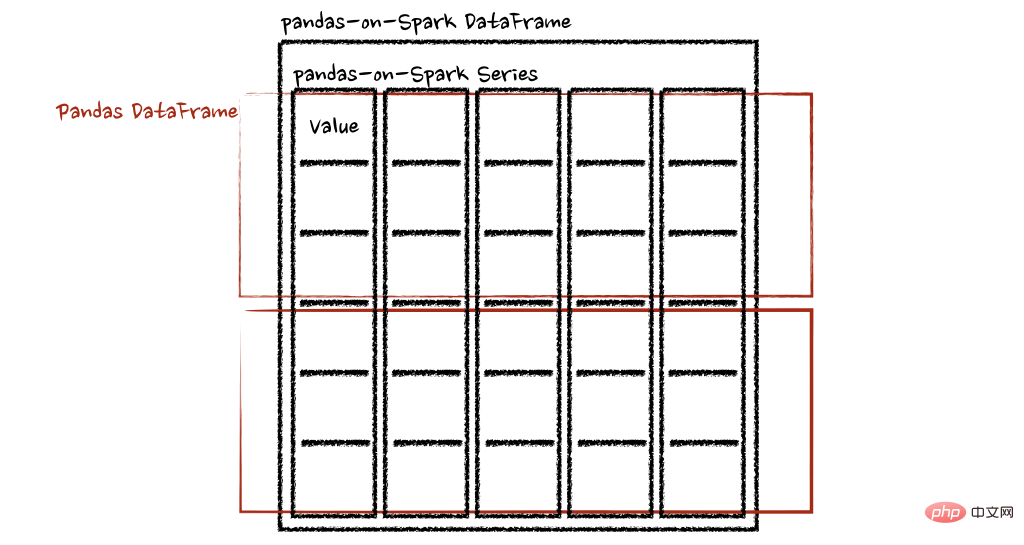
在 Spark 上使用 pandas API的注意事项
避免shuffle
某些操作,例如sort_values在并行或分布式环境中比在单台机器上的内存中更难完成,因为它需要将数据发送到其他节点,并通过网络在多个节点之间交换数据。
避免在单个分区上计算
另一种常见情况是在单个分区上进行计算。目前, DataFrame.rank 等一些 API 使用 PySpark 的 Window 而不指定分区规范。这会将所有数据移动到单个机器中的单个分区中,并可能导致严重的性能下降。对于非常大的数据集,应避免使用此类 API。
不要使用重复的列名
不允许使用重复的列名,因为 Spark SQL 通常不允许这样做。Spark 上的 Pandas API 继承了这种行为。例如,见下文:
import pyspark.pandas as ps
psdf = ps.DataFrame({'a': [1, 2], 'b':[3, 4]})
psdf.columns = ["a", "a"]Reference 'a' is ambiguous, could be: a, a.;
此外,强烈建议不要使用区分大小写的列名。Spark 上的 Pandas API 默认不允许它。
import pyspark.pandas as ps
psdf = ps.DataFrame({'a': [1, 2], 'A':[3, 4]})Reference 'a' is ambiguous, could be: a, a.;
但可以在 Spark 配置spark.sql.caseSensitive中打开以启用它,但需要自己承担风险。
from pyspark.sql import SparkSession
builder = SparkSession.builder.appName("pandas-on-spark")
builder = builder.config("spark.sql.caseSensitive", "true")
builder.getOrCreate()
import pyspark.pandas as ps
psdf = ps.DataFrame({'a': [1, 2], 'A':[3, 4]})
psdfaA 013 124
使用默认索引
pandas-on-Spark 用户面临的一个常见问题是默认索引导致性能下降。当索引未知时,Spark 上的 Pandas API 会附加一个默认索引,例如 Spark DataFrame 直接转换为 pandas-on-Spark DataFrame。
如果计划在生产中处理大数据,请通过将默认索引配置为distributed或distributed-sequence来使其确保为分布式。
有关配置默认索引的更多详细信息,请参阅默认索引类型[3]。
在 Spark 上使用 pandas API
尽管 Spark 上的 pandas API 具有大部分与 pandas 等效的 API,但仍有一些 API 尚未实现或明确不受支持。因此尽可能直接在 Spark 上使用 pandas API。
例如,Spark 上的 pandas API 没有实现__iter__(),阻止用户将所有数据从整个集群收集到客户端(驱动程序)端。不幸的是,许多外部 API,例如 min、max、sum 等 Python 的内置函数,都要求给定参数是可迭代的。对于 pandas,它开箱即用,如下所示:
>>> import pandas as pd >>> max(pd.Series([1, 2, 3])) 3 >>> min(pd.Series([1, 2, 3])) 1 >>> sum(pd.Series([1, 2, 3])) 6
Pandas 数据集存在于单台机器中,自然可以在同一台机器内进行本地迭代。但是,pandas-on-Spark 数据集存在于多台机器上,并且它们是以分布式方式计算的。很难在本地迭代,很可能用户在不知情的情况下将整个数据收集到客户端。因此,最好坚持使用 pandas-on-Spark API。上面的例子可以转换如下:
>>> import pyspark.pandas as ps >>> ps.Series([1, 2, 3]).max() 3 >>> ps.Series([1, 2, 3]).min() 1 >>> ps.Series([1, 2, 3]).sum() 6
pandas 用户的另一个常见模式可能是依赖列表推导式或生成器表达式。但是,它还假设数据集在引擎盖下是本地可迭代的。因此,它可以在 pandas 中无缝运行,如下所示:
import pandas as pd data = [] countries = ['London', 'New York', 'Helsinki'] pser = pd.Series([20., 21., 12.], index=countries) for temperature in pser: assert temperature > 0 if temperature > 1000: temperature = None data.append(temperature ** 2) pd.Series(data, index=countries)
London400.0 New York441.0 Helsinki144.0 dtype: float64
但是,对于 Spark 上的 pandas API,它的工作原理与上述相同。上面的示例也可以更改为直接使用 pandas-on-Spark API,如下所示:
import pyspark.pandas as ps import numpy as np countries = ['London', 'New York', 'Helsinki'] psser = ps.Series([20., 21., 12.], index=countries) def square(temperature) -> np.float64: assert temperature > 0 if temperature > 1000: temperature = None return temperature ** 2 psser.apply(square)
London400.0 New York441.0 Helsinki144.0
减少对不同 DataFrame 的操作
Spark 上的 Pandas API 默认不允许对不同 DataFrame(或 Series)进行操作,以防止昂贵的操作。只要有可能,就应该避免这种操作。
写在最后
到目前为止,我们将能够在 Spark 上使用 Pandas。这将会导致Pandas 速度的大大提高,迁移到 Spark 时学习曲线的减少,以及单机计算和分布式计算在同一代码库中的合并。
参考资料
[1]PySpark 指南: https://spark.apache.org/docs/latest/api/python/user_guide/pandas_on_spark/pandas_pyspark.html
[2]PySpark 指南: https://spark.apache.org/docs/latest/api/python/user_guide/pandas_on_spark/types.html
[3]默认索引类型: https://spark.apache.org/docs/latest/api/python/user_guide/pandas_on_spark/options.html#default-index-type
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Résoudre les problèmes courants d'installation de pandas : interprétation et solutions aux erreurs d'installation
Feb 19, 2024 am 09:19 AM
Résoudre les problèmes courants d'installation de pandas : interprétation et solutions aux erreurs d'installation
Feb 19, 2024 am 09:19 AM
Tutoriel d'installation de Pandas : analyse des erreurs d'installation courantes et de leurs solutions, des exemples de code spécifiques sont requis Introduction : Pandas est un puissant outil d'analyse de données largement utilisé dans le nettoyage des données, le traitement des données et la visualisation des données, il est donc très respecté dans le domaine de la science des données. Cependant, en raison de problèmes de configuration de l'environnement et de dépendances, vous pouvez rencontrer des difficultés et des erreurs lors de l'installation de pandas. Cet article vous fournira un didacticiel d'installation de pandas et analysera certaines erreurs d'installation courantes et leurs solutions. 1. Installez les pandas
 méthode d'installation de python pandas
Nov 22, 2023 pm 02:33 PM
méthode d'installation de python pandas
Nov 22, 2023 pm 02:33 PM
Python peut installer des pandas en utilisant pip, en utilisant conda, à partir du code source et en utilisant l'outil de gestion de packages intégré IDE. Introduction détaillée : 1. Utilisez pip et exécutez la commande pip install pandas dans le terminal ou l'invite de commande pour installer pandas ; 2. Utilisez conda et exécutez la commande conda install pandas dans le terminal ou l'invite de commande pour installer pandas ; installation et plus encore.
 Lisez des fichiers CSV et effectuez une analyse de données à l'aide de pandas
Jan 09, 2024 am 09:26 AM
Lisez des fichiers CSV et effectuez une analyse de données à l'aide de pandas
Jan 09, 2024 am 09:26 AM
Pandas est un puissant outil d'analyse de données qui peut facilement lire et traiter différents types de fichiers de données. Parmi eux, les fichiers CSV sont l’un des formats de fichiers de données les plus courants et les plus utilisés. Cet article expliquera comment utiliser Pandas pour lire des fichiers CSV et effectuer une analyse de données, et fournira des exemples de code spécifiques. 1. Importez les bibliothèques nécessaires Tout d'abord, nous devons importer la bibliothèque Pandas et les autres bibliothèques associées qui peuvent être nécessaires, comme indiqué ci-dessous : importpandasaspd 2. Lisez le fichier CSV à l'aide de Pan
 Comment lire correctement le fichier txt à l'aide de pandas
Jan 19, 2024 am 08:39 AM
Comment lire correctement le fichier txt à l'aide de pandas
Jan 19, 2024 am 08:39 AM
Comment utiliser pandas pour lire correctement les fichiers txt nécessite des exemples de code spécifiques. Pandas est une bibliothèque d'analyse de données Python largement utilisée. Elle peut être utilisée pour traiter une variété de types de données, notamment des fichiers CSV, des fichiers Excel, des bases de données SQL, etc. En même temps, il peut également être utilisé pour lire des fichiers texte, tels que des fichiers txt. Cependant, lors de la lecture de fichiers txt, nous rencontrons parfois quelques problèmes, comme des problèmes d'encodage, des problèmes de délimiteur, etc. Cet article explique comment lire correctement le txt à l'aide de pandas.
 Comment installer des pandas en python
Dec 04, 2023 pm 02:48 PM
Comment installer des pandas en python
Dec 04, 2023 pm 02:48 PM
Étapes pour installer pandas en python : 1. Ouvrez le terminal ou l'invite de commande ; 2. Entrez la commande "pip install pandas" pour installer la bibliothèque pandas ; 3. Attendez la fin de l'installation et vous pourrez importer et utiliser la bibliothèque pandas. dans le script Python ; 4. Utiliser Il s'agit d'un environnement virtuel spécifique. Assurez-vous d'activer l'environnement virtuel correspondant avant d'installer pandas ; 5. Si vous utilisez un environnement de développement intégré, vous pouvez ajouter le code « importer des pandas en tant que pd » ; importez la bibliothèque pandas.
 Conseils pratiques pour lire les fichiers txt à l'aide de pandas
Jan 19, 2024 am 09:49 AM
Conseils pratiques pour lire les fichiers txt à l'aide de pandas
Jan 19, 2024 am 09:49 AM
Conseils pratiques pour lire les fichiers txt à l'aide de pandas, des exemples de code spécifiques sont requis Dans l'analyse et le traitement des données, les fichiers txt sont un format de données courant. L'utilisation de pandas pour lire les fichiers txt permet un traitement des données rapide et pratique. Cet article présentera plusieurs techniques pratiques pour vous aider à mieux utiliser les pandas pour lire les fichiers txt, ainsi que des exemples de code spécifiques. Lire des fichiers txt avec des délimiteurs Lorsque vous utilisez pandas pour lire des fichiers txt avec des délimiteurs, vous pouvez utiliser read_c
 Pandas lit facilement les données de la base de données SQL
Jan 09, 2024 pm 10:45 PM
Pandas lit facilement les données de la base de données SQL
Jan 09, 2024 pm 10:45 PM
Outil de traitement des données : Pandas lit les données dans les bases de données SQL et nécessite des exemples de code spécifiques. À mesure que la quantité de données continue de croître et que leur complexité augmente, le traitement des données est devenu une partie importante de la société moderne. Dans le processus de traitement des données, Pandas est devenu l'un des outils préférés de nombreux analystes de données et scientifiques. Cet article explique comment utiliser la bibliothèque Pandas pour lire les données d'une base de données SQL et fournit des exemples de code spécifiques. Pandas est un puissant outil de traitement et d'analyse de données basé sur Python
 Révéler la méthode efficace de déduplication des données dans Pandas : conseils pour supprimer rapidement les données en double
Jan 24, 2024 am 08:12 AM
Révéler la méthode efficace de déduplication des données dans Pandas : conseils pour supprimer rapidement les données en double
Jan 24, 2024 am 08:12 AM
Le secret de la méthode de déduplication Pandas : un moyen rapide et efficace de dédupliquer les données, qui nécessite des exemples de code spécifiques. Dans le processus d'analyse et de traitement des données, une duplication des données est souvent rencontrée. Les données en double peuvent induire en erreur les résultats de l'analyse, la déduplication est donc une étape très importante. Pandas, une puissante bibliothèque de traitement de données, fournit une variété de méthodes pour réaliser la déduplication des données. Cet article présentera certaines méthodes de déduplication couramment utilisées et joindra des exemples de code spécifiques. Le cas le plus courant de déduplication basée sur une seule colonne dépend de la duplication ou non de la valeur d'une certaine colonne.
