

Comment implémenter un framework d'orchestration de processus en Java

Enregistrement du processus
Nous avons mentionné précédemment que nous devons prendre en charge le modèle de processus d'enregistrement sous la forme de yml, de propriétés, de XML, de json et d'interfaces. Afin de refléter le principe de responsabilité unique, nous devons traiter la logique de. un format analysé indépendamment Afin de refléter le bon développement étendu, concernant le principe de fermeture des modifications, nous définissons d'abord un ensemble d'interfaces, puis fournissons la logique d'implémentation correspondante via le modèle d'usine ; , et l'implémentation spécifique est appelée via l'interface, et l'implémentation ici est le fournisseur, et est un ensemble de modes de stratégie.
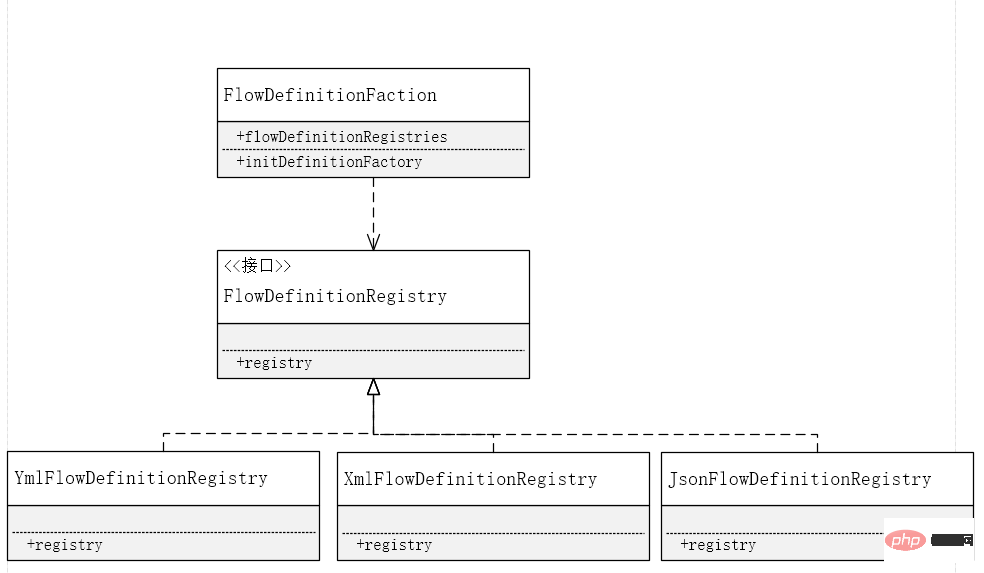
Chargement du processus
Nous devons connaître plusieurs autres exigences fonctionnelles pour le chargement du processus : 1. Fournir une interface d'accès externe unifiée ; 2. Fournir des enregistrements d'exécution et un temps d'exécution 3. Différents nœuds de processus doivent définir différents analyseurs ; ; 4. Créer un type d'analyse via l'usine ; 5. Les nœuds de processus sont exécutés dans l'ordre.
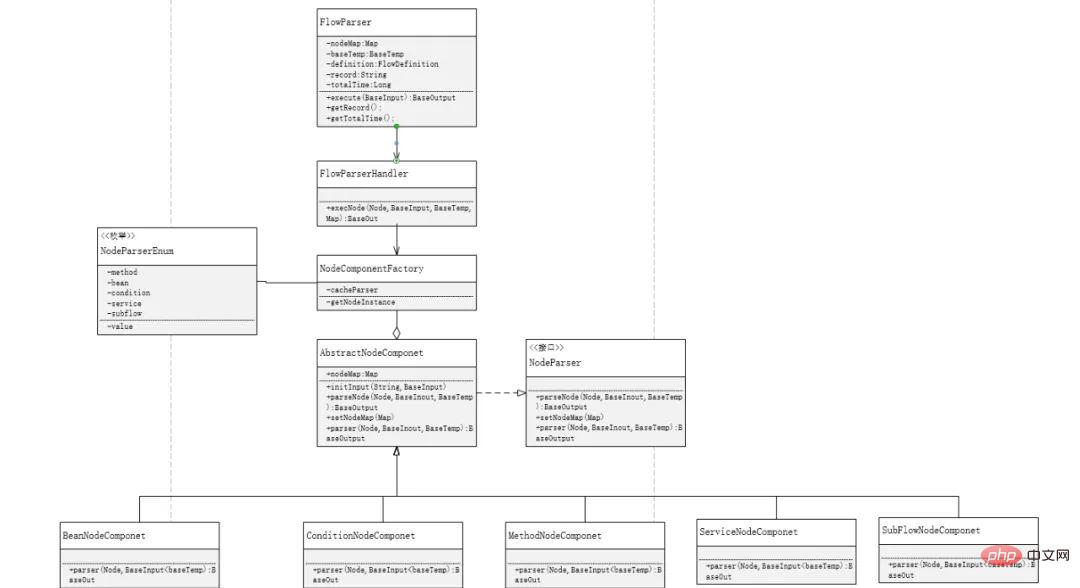
Exécuter différentes méthodes d'analyse via différents types de nœuds Il est évident que nous devons utiliser le mode usine pour créer des classes d'analyse, et nous devons ouvrir le développement et la modification d'extensions externes, et ajouter des nœuds sans toucher aux autres. Code.Logique, ajoutez simplement un analyseur de nœud dans la fonction factory ; en même temps, nous définissons ici une collection Map pour créer l'objet d'analyse lors du chargement de la fonction factory, au lieu de créer un analyseur à chaque fois qu'il est analysé, ce qui réduit les inutiles. Le code de la mémoire
est le suivant :
<code>public class NodeComponentFactory {<br><br> private final static Map<string> cacheParser = new HashMap();<br><br> static {<br> cacheParser.put(NodeParserEnum.method.name(),new MethodNodeComponent());<br> cacheParser.put(NodeParserEnum.bean.name(),new BeanNodeComponent());<br> cacheParser.put(NodeParserEnum.condition.name(),new ConditionNodeComponent());<br> cacheParser.put(NodeParserEnum.service.name(),new ServiceNodeComponent());<br> cacheParser.put(NodeParserEnum.subflow.name(),new SubFlowNodeComponent());<br> }<br><br> public static NodeParser getNodeInstance(String nodeName){<br> return cacheParser.get(nodeName);<br> }<br>}<br></string></code>Lorsque nous constatons que chaque type d'analyse de nœud doit implémenter l'interface de l'analyseur et que chaque nœud a des étapes similaires, alors nous devons envisager d'utiliser ici une usine abstraite, qui est également conforme à un Le Le principe de conception de l'inversion des dépendances est que le module supérieur est accessible via l'interface de dépendance. Le module suivant hérite de la classe abstraite et utilise également le modèle de stratégie pour effectuer des appels d'interface dans le processus logique d'implémentation, nous constaterons que beaucoup ; les étapes sont répétées, telles que l'initialisation. En saisissant les paramètres et en exécutant les enregistrements, nous mettons tout le contenu répété dans des classes abstraites et utilisons le mode modèle pour laisser les nœuds de processus se concentrer uniquement sur le niveau d'analyse
<code>public abstract class AbstractNodeComponent implements NodeParser{<br><br> public Map<string node> nodeMap;<br><br><br> /**<br> * 初始化参数<br> * @param inputUrl<br> * @param baseInput<br> * @return<br> */<br> public BaseInput initInput(String inputUrl, BaseInput baseInput){<br> BaseInput baseInputTarget = ClassUtil.newInstance(inputUrl, BaseInput.class);<br> BeanUtils.copyProperties(baseInput,baseInputTarget);<br> return baseInputTarget;<br> }<br><br><br> /**<br> * 解析节点信息<br> * @param node 节点信息<br> * @param baseInput 请求参数<br> * @param baseTemp 临时上下文<br> * @return<br> */<br> public BaseOutput parserNode(Node node, BaseInput baseInput, BaseTemp baseTemp){<br> baseTemp.setFlowRecord(baseTemp.getFlowRecord().append(FlowConstants.NODEKEY+FlowConstants.NODE+FlowConstants.COLON+node.getId()));<br> BaseOutput baseOutput = parser(node, baseInput, baseTemp);<br> return baseOutput;<br> };<br><br> @Override<br> public void setNodeMap(Map<string node> nodeMap) {<br> this.nodeMap = nodeMap;<br> }<br><br> @Override<br> public abstract BaseOutput parser(Node node, BaseInput baseInput, BaseTemp baseTemp);<br><br>}</string></string></code>Ordre de chargement du processus
; Pour l'exécution du processus, nous devons diviser les composants en plusieurs parties. Finement, il est préférable de diviser la classe qui implémente indépendamment une fonction en un composant, qui incarne le principe de responsabilité unique. Ce n'est qu'en divisant très finement la fonction d'exécution que cela peut être fait. combiné de manière flexible dans chaque processus d'exécution de processus ; dans l'organigramme ci-dessous, vous pouvez voir plusieurs composants, le premier est l'entrée pour une exécution unifiée du processus. Il sera utilisé à deux endroits. , et le deuxième est l'entrée pour l'exécution du sous-processus ; le deuxième composant est le nœud qui charge le composant de gestion de manière unifiée, qui est la classe d'usine mentionnée ci-dessus ; le troisième est le propre analyseur de chaque composant, qui est utilisé pour ; mettre en œuvre le fonctionnement de différents types de nœuds ; dans le processus de conception, vous devez connaître la relation entre le processus, la gestion et les nœuds. Les limites entre les composants réduisent le couplage, afin que les différents composants puissent être composés de manière flexible.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

Video Face Swap
Échangez les visages dans n'importe quelle vidéo sans effort grâce à notre outil d'échange de visage AI entièrement gratuit !

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)
Sujets chauds
 1393
1393
 52
1207
24
52
1207
24

 Nombre parfait en Java
Aug 30, 2024 pm 04:28 PM
Nombre parfait en Java
Aug 30, 2024 pm 04:28 PM
Guide du nombre parfait en Java. Nous discutons ici de la définition, comment vérifier le nombre parfait en Java ?, des exemples d'implémentation de code.
 Weka en Java
Aug 30, 2024 pm 04:28 PM
Weka en Java
Aug 30, 2024 pm 04:28 PM
Guide de Weka en Java. Nous discutons ici de l'introduction, de la façon d'utiliser Weka Java, du type de plate-forme et des avantages avec des exemples.
 Numéro de Smith en Java
Aug 30, 2024 pm 04:28 PM
Numéro de Smith en Java
Aug 30, 2024 pm 04:28 PM
Guide du nombre de Smith en Java. Nous discutons ici de la définition, comment vérifier le numéro Smith en Java ? exemple avec implémentation de code.
 Questions d'entretien chez Java Spring
Aug 30, 2024 pm 04:29 PM
Questions d'entretien chez Java Spring
Aug 30, 2024 pm 04:29 PM
Dans cet article, nous avons conservé les questions d'entretien Java Spring les plus posées avec leurs réponses détaillées. Pour que vous puissiez réussir l'interview.
 Break or Return of Java 8 Stream Forach?
Feb 07, 2025 pm 12:09 PM
Break or Return of Java 8 Stream Forach?
Feb 07, 2025 pm 12:09 PM
Java 8 présente l'API Stream, fournissant un moyen puissant et expressif de traiter les collections de données. Cependant, une question courante lors de l'utilisation du flux est: comment se casser ou revenir d'une opération FOREAK? Les boucles traditionnelles permettent une interruption ou un retour précoce, mais la méthode Foreach de Stream ne prend pas directement en charge cette méthode. Cet article expliquera les raisons et explorera des méthodes alternatives pour la mise en œuvre de terminaison prématurée dans les systèmes de traitement de flux. Lire plus approfondie: Améliorations de l'API Java Stream Comprendre le flux Forach La méthode foreach est une opération terminale qui effectue une opération sur chaque élément du flux. Son intention de conception est
 Horodatage à ce jour en Java
Aug 30, 2024 pm 04:28 PM
Horodatage à ce jour en Java
Aug 30, 2024 pm 04:28 PM
Guide de TimeStamp to Date en Java. Ici, nous discutons également de l'introduction et de la façon de convertir l'horodatage en date en Java avec des exemples.
 Programme Java pour trouver le volume de la capsule
Feb 07, 2025 am 11:37 AM
Programme Java pour trouver le volume de la capsule
Feb 07, 2025 am 11:37 AM
Les capsules sont des figures géométriques tridimensionnelles, composées d'un cylindre et d'un hémisphère aux deux extrémités. Le volume de la capsule peut être calculé en ajoutant le volume du cylindre et le volume de l'hémisphère aux deux extrémités. Ce tutoriel discutera de la façon de calculer le volume d'une capsule donnée en Java en utilisant différentes méthodes. Formule de volume de capsule La formule du volume de la capsule est la suivante: Volume de capsule = volume cylindrique volume de deux hémisphères volume dans, R: Le rayon de l'hémisphère. H: La hauteur du cylindre (à l'exclusion de l'hémisphère). Exemple 1 entrer Rayon = 5 unités Hauteur = 10 unités Sortir Volume = 1570,8 unités cubes expliquer Calculer le volume à l'aide de la formule: Volume = π × r2 × h (4
 Créer l'avenir : programmation Java pour les débutants absolus
Oct 13, 2024 pm 01:32 PM
Créer l'avenir : programmation Java pour les débutants absolus
Oct 13, 2024 pm 01:32 PM
Java est un langage de programmation populaire qui peut être appris aussi bien par les développeurs débutants que par les développeurs expérimentés. Ce didacticiel commence par les concepts de base et progresse vers des sujets avancés. Après avoir installé le kit de développement Java, vous pouvez vous entraîner à la programmation en créant un simple programme « Hello, World ! ». Une fois que vous avez compris le code, utilisez l'invite de commande pour compiler et exécuter le programme, et « Hello, World ! » s'affichera sur la console. L'apprentissage de Java commence votre parcours de programmation et, à mesure que votre maîtrise s'approfondit, vous pouvez créer des applications plus complexes.
