

Obtenez la requête Ajax et analysez les champs requis dans JSON
Enregistrez les données dans Excel
Enregistrez les données dans MySQL pour une analyse facile
Cinq villes Niveau de salaire moyen des postes Python
Nous saisissons les conditions de requête en utilisant Python comme exemple. Les autres conditions ne sont pas sélectionnées par défaut et vous verrez tous les postes Python. ouvrez la console et cliquez sur l'onglet Réseau. Vous pouvez voir la demande suivante :
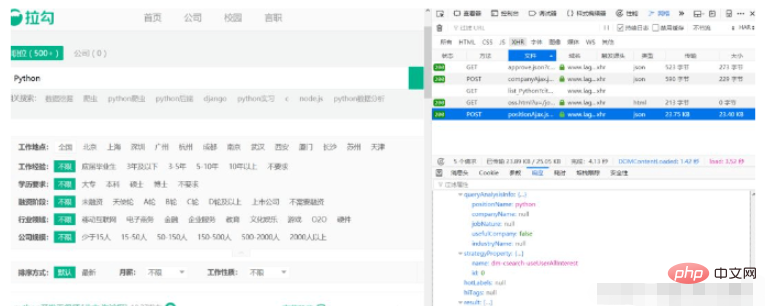
À en juger par les résultats de la réponse, cette demande est exactement ce dont nous avons besoin. Nous pourrons simplement demander cette adresse directement plus tard. Comme le montre l'image, le résultat suivant est l'information de chaque position.
Nous savons désormais où demander des données et où obtenir les résultats. Mais il n'y a que 15 données sur la première page de la liste de résultats. Comment obtenir les données sur d'autres pages ?
Nous cliquons sur l'onglet paramètres, comme suit :
Nous avons constaté que trois données de formulaire ont été soumises. Il est évident que kd est le mot-clé que nous avons recherché et pn est le numéro de page actuel. Par défaut, ne vous inquiétez pas. Il ne reste plus qu'à construire une requête pour télécharger 30 pages de données.
Construire une requête est très simple, nous utilisons toujours la bibliothèque de requêtes pour le faire. Tout d'abord, nous construisons les données du formulaire
data = {'first': 'true', 'pn': page, 'kd': lang_name}, puis utilisons des requêtes pour demander l'adresse URL. Les données JSON analysées sont terminées. Étant donné que Lagou a des restrictions strictes sur les robots d'exploration, nous devons ajouter tous les champs d'en-tête dans le navigateur et augmenter l'intervalle des robots d'exploration. Je l'ai défini à 10 à 20 secondes plus tard, puis les données peuvent être obtenues normalement.
import requests
def get_json(url, page, lang_name):
headers = {
'Host': 'www.lagou.com',
'Connection': 'keep-alive',
'Content-Length': '23',
'Origin': 'https://www.lagou.com',
'X-Anit-Forge-Code': '0',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:61.0) Gecko/20100101 Firefox/61.0',
'Content-Type': 'application/x-www-form-urlencoded; charset=UTF-8',
'Accept': 'application/json, text/javascript, */*; q=0.01',
'X-Requested-With': 'XMLHttpRequest',
'X-Anit-Forge-Token': 'None',
'Referer': 'https://www.lagou.com/jobs/list_python?city=%E5%85%A8%E5%9B%BD&cl=false&fromSearch=true&labelWords=&suginput=',
'Accept-Encoding': 'gzip, deflate, br',
'Accept-Language': 'en-US,en;q=0.9,zh-CN;q=0.8,zh;q=0.7'
}
data = {'first': 'false', 'pn': page, 'kd': lang_name}
json = requests.post(url, data, headers=headers).json()
list_con = json['content']['positionResult']['result']
info_list = []
for i in list_con:
info = []
info.append(i.get('companyShortName', '无'))
info.append(i.get('companyFullName', '无'))
info.append(i.get('industryField', '无'))
info.append(i.get('companySize', '无'))
info.append(i.get('salary', '无'))
info.append(i.get('city', '无'))
info.append(i.get('education', '无'))
info_list.append(info)
return info_listMaintenant que nous comprenons comment analyser les données, il ne reste plus qu'à demander toutes les pages en continu. Nous construisons une fonction pour demander les 30 pages de données.
def main():
lang_name = 'python'
wb = Workbook()
conn = get_conn()
for i in ['北京', '上海', '广州', '深圳', '杭州']:
page = 1
ws1 = wb.active
ws1.title = lang_name
url = 'https://www.lagou.com/jobs/positionAjax.json?city={}&needAddtionalResult=false'.format(i)
while page < 31:
info = get_json(url, page, lang_name)
page += 1
import time
a = random.randint(10, 20)
time.sleep(a)
for row in info:
insert(conn, tuple(row))
ws1.append(row)
conn.close()
wb.save('{}职位信息.xlsx'.format(lang_name))
if __name__ == '__main__':
main()Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
















![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



