
 Périphériques technologiques
IA
Comparaison complète de quatre modèles de « recherche ChatGPT » ! Annoté à la main par un médecin chinois de Stanford : New Bing a la maîtrise la plus faible et près de la moitié des phrases ne sont pas citées.
Périphériques technologiques
IA
Comparaison complète de quatre modèles de « recherche ChatGPT » ! Annoté à la main par un médecin chinois de Stanford : New Bing a la maîtrise la plus faible et près de la moitié des phrases ne sont pas citées.
Comparaison complète de quatre modèles de « recherche ChatGPT » ! Annoté à la main par un médecin chinois de Stanford : New Bing a la maîtrise la plus faible et près de la moitié des phrases ne sont pas citées.

Peu de temps après la sortie de ChatGPT, Microsoft a lancé avec succès le « Nouveau Bing ». Non seulement le cours de ses actions a grimpé, mais il a même menacé de remplacer Google et d'inaugurer une nouvelle ère de moteurs de recherche.
Mais New Bing est-il vraiment la bonne façon de jouer à un grand modèle de langage ? Les réponses générées sont-elles réellement utiles aux utilisateurs ? Dans quelle mesure la citation dans la phrase est-elle crédible ?
Récemment, des chercheurs de Stanford ont collecté un grand nombre de requêtes d'utilisateurs provenant de différentes sources et analysé les quatre moteurs de recherche génératifs populaires, Bing Chat), NeevaAI, perplexity.ai et YouChat. mené des évaluations humaines.

Lien papier : https://arxiv.org/pdf/2304.09848.pdf#🎜 🎜#
Les résultats expérimentaux ont révélé que les réponses des moteurs de recherche générés existants étaient fluides et informatives, mais contenaient souvent des déclarations sans preuves et des citations inexactes.
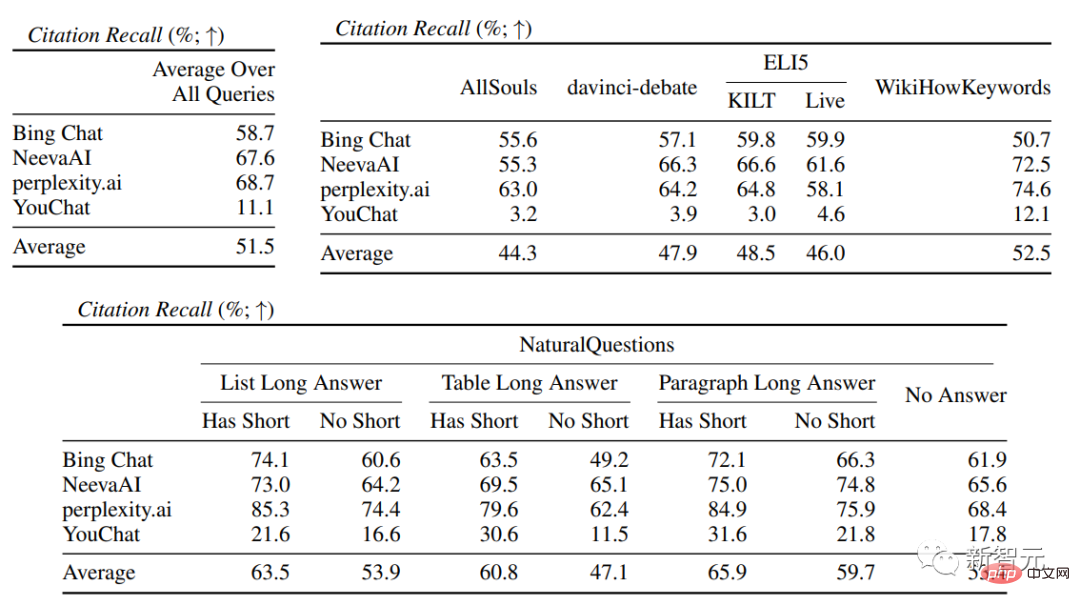
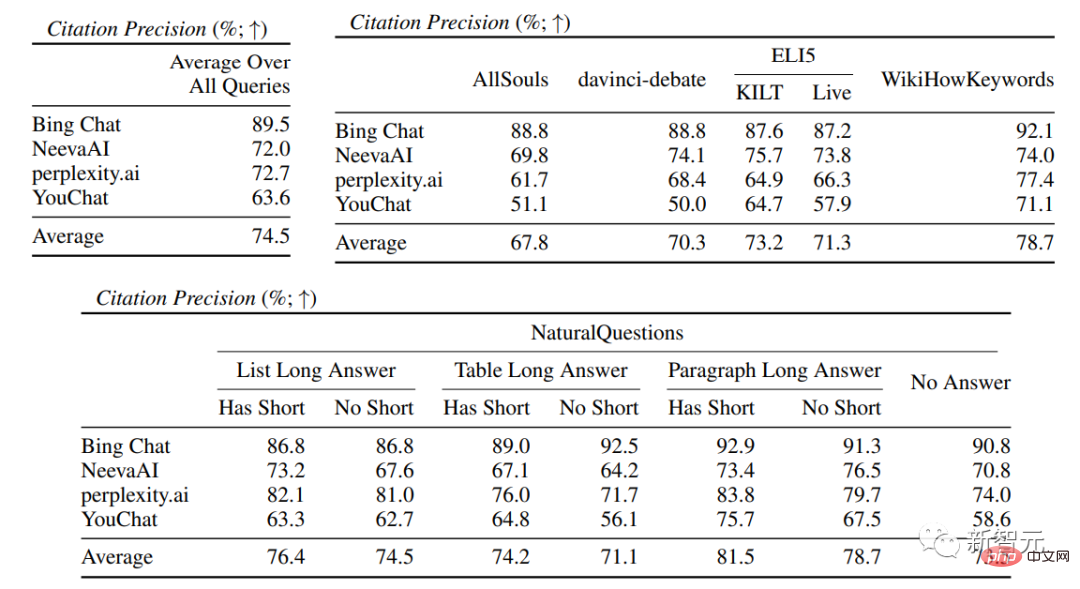
En moyenne, seulement 51,5% des citations peuvent pleinement soutenir les phrases générées, et seulement 74,5% des citations peuvent être utilisées comme preuve à l'appui des phrases associées.
Les chercheurs estiment que ce résultat est trop faible pour un système qui pourrait devenir l'outil principal des utilisateurs en recherche d'informations, d'autant plus que certaines phrases ne sont que superficielles. il faut croire que les moteurs de recherche génératifs ont encore besoin d’être optimisés.

Page d'accueil personnelle : https://cs.stanford.edu/~nfliu/#🎜 🎜#
Le premier auteur Nelson Liu est un doctorant de quatrième année au sein du groupe de traitement du langage naturel de l'université de Stanford. Son superviseur est Percy Liang. Diplômé d'une licence de l'Université de Washington. Son principal domaine de recherche est la création de systèmes PNL pratiques, en particulier les applications de recherche d'informations.Ne faites pas confiance aux moteurs de recherche génératifs
En mars 2023, Microsoft a signalé qu'« environ un tiers des utilisateurs quotidiens de la version préliminaire utilisent tous [Bing] Chat», et Bing Chat a fourni 45 millions de chats au cours du premier mois de sa préversion publique. En d'autres termes, l'intégration de grands modèles de langage dans les moteurs de recherche est très commercialisable et est très susceptible de changer.

La vérifiabilité est la clé pour améliorer la crédibilité des moteurs de recherche, c'est-à-dire que chaque phrase de la réponse générée fournit des liens externes vers Les citations comme preuves à l’appui permettent aux utilisateurs de vérifier plus facilement l’exactitude des réponses.
Les chercheurs ont collecté des questions provenant de différents types et sources et ont mené des expériences manuelles sur quatre moteurs de recherche génératifs commerciaux (Bing Chat, NeevaAI, perplexity.ai, YouChat). # 🎜🎜 ## 🎜🎜 ## 🎜🎜 ## 🎜🎜 ## 🎜🎜 ## 🎜🎜 ## 🎜🎜 ## 🎜🎜 ## 🎜🎜 ## 🎜🎜 ## 🎜🎜 # Indicateur d'évaluation # 🎜🎜 # # # Il s'agit principalement defluency, c'est-à-dire si le texte généré est cohérent helpfulness
, c'est-à-dire si la réponse du moteur de recherche est utile à l'utilisateur et si le les informations dans la réponse sont Peut résoudre le problème ;Citation rappel , c'est-à-dire la proportion de phrases générées sur des sites Web externes qui contiennent une prise en charge des citations
, c'est-à-dire la proportion de phrases générées sur des sites Web externes qui contiennent une prise en charge des citations
, c'est-à-dire , les citations générées qui soutiennent ses phrases associées Proportion.
fluency
Affiche également la requête de l'utilisateur, la réponse générée et la déclaration "Cette réponse" Est fluide et sémantiquement cohérent. » Les annotateurs ont évalué les données sur une échelle de Likert à cinq points.
utilité (utilité perçue)
# 🎜🎜#Semblable à la maîtrise, les annotateurs doivent évaluer leur accord avec l'affirmation selon laquelle la réponse est utile et informative par rapport à la requête de l'utilisateur. Rappel de citation Fait référence à la proportion de phrases dignes de vérification qui sont entièrement étayées par leurs citations pertinentes. Le calcul de cet indicateur nécessite donc d'identifier les phrases dignes de vérification dans les réponses et d'évaluer si chaque phrase digne de vérification peut être étayée par des citations pertinentes. citations.
En cours de "Identifier les phrases qui méritent d'être vérifiées"
, estiment les chercheurs Chaque phrase générée sur le monde extérieur mérite d'être vérifiée, même celles qui peuvent sembler évidentes et insignifiantes au bon sens, car ce qui peut sembler évident du « bon sens » à certains lecteurs peut en réalité ne pas être correct.L'objectif d'un système de moteur de recherche devrait être de fournir une source de référence pour toutes les phrases générées sur le monde extérieur, permettant aux lecteurs de vérifier facilement tout récit dans la réponse générée. , La vérifiabilité ne peut pas être sacrifiée au profit de la simplicité.
Donc, en fait, les annotateurs vérifient toutes les phrases générées, à l'exception des réponses où le système est la première personne, comme "En tant que modèle de langage, je n'ai pas capacité Do...", ou des questions aux utilisateurs, telles que "Voulez-vous en savoir plus ?", etc. Évaluer
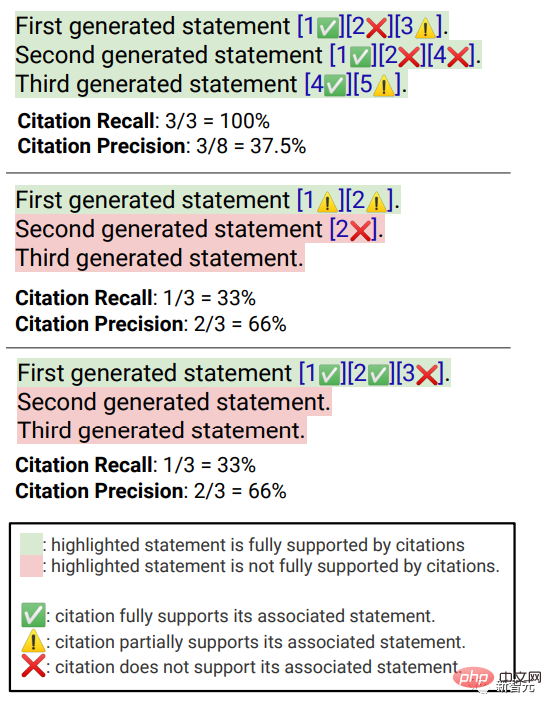
"Si une déclaration digne d'être vérifiée est adéquatement étayée par ses citations pertinentes"peut être attribuée sur la base de Identifié Source (AIS, attribuable aux sources identifiées) Cadre d'évaluation, l'annotateur effectue une annotation binaire, c'est-à-dire que si un public ordinaire convient que "sur la base de la page Web citée, on peut conclure que...", alors la citation peut être entièrement étayée. La réponse. # 🎜🎜 ## 🎜🎜 ## 🎜🎜 ## 🎜🎜 ## 🎜🎜 ## 🎜🎜 # précision de citation # 🎜🎜 ## 🎜🎜 ## 🎜🎜 ## 🎜🎜 ## 🎜🎜 ## 🎜🎜 # # # Pour mesurer l'exactitude des citations, les annotateurs doivent juger si chaque citation fournit un support complet, partiel ou non pertinent à la phrase associée.
Support complet
: Toutes les informations contenues dans la phrase sont appuyées par la citation. Support partiel : Certaines informations dans la phrase sont étayées par la citation, mais d'autres parties peuvent être manquantes ou contradictoires.
Support non pertinent (Aucun support) : Si la page Web référencée est complètement hors de propos ou contradictoire.
Pour les phrases comportant plusieurs citations pertinentes, les annotateurs devront également utiliser le cadre d'évaluation AIS pour déterminer si toutes les pages Web de citations pertinentes dans leur ensemble fournissent des informations suffisantes pour le support de la phrase (jugement binaire).
Résultats expérimentauxDans l'évaluation de la fluidité et de l'utilité, on peut voir que chaque moteur de recherche est capable de générer des réponses très fluides et utiles .
Dans l'évaluation spécifique du moteur de recherche, vous pouvez voir Bing Chat avait le note de maîtrise/utilité la plus basse (4,40/4,34), suivi de NeevaAI (4,43/4,48), perplexity.ai (4,51/4,56) et YouChat (4,59/4,62). Dans différentes catégories de requêtes d'utilisateurs, on peut constater que les questions de récupération plus courtes sont généralement plus fluides que les questions longues et ne répondent généralement qu'à des connaissances factuelles ; nécessitent l’agrégation de différents tableaux ou pages Web, et le processus de synthèse réduira la fluidité globale. Dans l'évaluation des citations, on peut constater que les moteurs de recherche génératifs existants ne parviennent souvent pas à citer entièrement ou correctement les pages Web, avec seulement 51,5 % des phrases générées recevant des citations en moyenne. . De soutien complet (rappel), seulement 74,5 % des citations soutiennent pleinement leurs phrases associées (précision). Cette valeur est pour ceux qui ont déjà des millions. est inacceptable pour le système de moteur de recherche de l'utilisateur, en particulier lorsque les réponses générées ont tendance à être relativement informatives. et Il existe de grandes différences dans le rappel et la précision des citations entre les différents moteurs de recherche génératifs , que perplexity.ai implémente a le taux de rappel le plus élevé (68,7), tandis que NeevaAI (67,6), Bing Chat (58,7) et YouChat (11,1) sont inférieurs. D'autre part, Bing Chat a obtenu la plus haute précision (89,5) , suivi de perplexity.ai (72,7), NeevaAI ( 72.0) et YouChat (63.6) Parmi les différentes requêtes des utilisateurs, fait partie des requêtes NaturalQuestions avec des réponses longues et des requêtes non-NaturalQuestions La différence le taux de rappel des citations entre eux est proche de 11 % (58,5 et 47,8 respectivement) ; réponse courte L'écart de rappel de citation entre la requête NaturalQuestions et la requête NaturalQuestions sans réponses courtes est de près de 10 % (63,4 pour les requêtes avec réponses courtes, 53,6 pour les requêtes avec uniquement des réponses longues et 53,6 pour les requêtes sans réponse longue ou courte). réponses) 53.4). Les taux de citation seront plus faibles dans les questions sans support Web, comme lors de l'évaluation des questions à développement ouvertes AllSouls, le moteur de recherche génératif n'a qu'un taux de rappel de citations de 44,3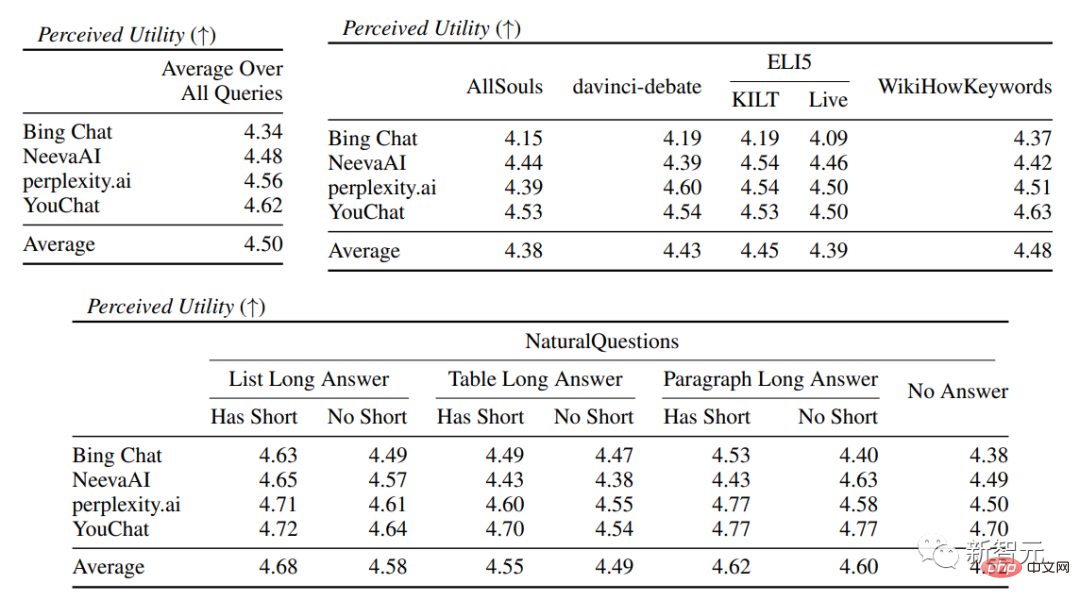
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Quelle méthode est utilisée pour convertir les chaînes en objets dans vue.js?
Apr 07, 2025 pm 09:39 PM
Quelle méthode est utilisée pour convertir les chaînes en objets dans vue.js?
Apr 07, 2025 pm 09:39 PM
Lors de la conversion des chaînes en objets dans vue.js, JSON.Parse () est préféré pour les chaînes JSON standard. Pour les chaînes JSON non standard, la chaîne peut être traitée en utilisant des expressions régulières et réduisez les méthodes en fonction du format ou du codé décodé par URL. Sélectionnez la méthode appropriée en fonction du format de chaîne et faites attention aux problèmes de sécurité et d'encodage pour éviter les bogues.
 Comment utiliser MySQL après l'installation
Apr 08, 2025 am 11:48 AM
Comment utiliser MySQL après l'installation
Apr 08, 2025 am 11:48 AM
L'article présente le fonctionnement de la base de données MySQL. Tout d'abord, vous devez installer un client MySQL, tel que MySQLWorkBench ou le client de ligne de commande. 1. Utilisez la commande MySQL-UROot-P pour vous connecter au serveur et connecter avec le mot de passe du compte racine; 2. Utilisez Createdatabase pour créer une base de données et utilisez Sélectionner une base de données; 3. Utilisez CreateTable pour créer une table, définissez des champs et des types de données; 4. Utilisez InsertInto pour insérer des données, remettre en question les données, mettre à jour les données par mise à jour et supprimer les données par Supprimer. Ce n'est qu'en maîtrisant ces étapes, en apprenant à faire face à des problèmes courants et à l'optimisation des performances de la base de données que vous pouvez utiliser efficacement MySQL.
 Comment résoudre MySQL ne peut pas être démarré
Apr 08, 2025 pm 02:21 PM
Comment résoudre MySQL ne peut pas être démarré
Apr 08, 2025 pm 02:21 PM
Il existe de nombreuses raisons pour lesquelles la startup MySQL échoue, et elle peut être diagnostiquée en vérifiant le journal des erreurs. Les causes courantes incluent les conflits de port (vérifier l'occupation du port et la configuration de modification), les problèmes d'autorisation (vérifier le service exécutant les autorisations des utilisateurs), les erreurs de fichier de configuration (vérifier les paramètres des paramètres), la corruption du répertoire de données (restaurer les données ou reconstruire l'espace de la table), les problèmes d'espace de la table InNODB (vérifier les fichiers IBDATA1), la défaillance du chargement du plug-in (vérification du journal des erreurs). Lors de la résolution de problèmes, vous devez les analyser en fonction du journal d'erreur, trouver la cause profonde du problème et développer l'habitude de sauvegarder régulièrement les données pour prévenir et résoudre des problèmes.
 Géospatial de Laravel: optimisation des cartes interactives et de grandes quantités de données
Apr 08, 2025 pm 12:24 PM
Géospatial de Laravel: optimisation des cartes interactives et de grandes quantités de données
Apr 08, 2025 pm 12:24 PM
Traiter efficacement 7 millions d'enregistrements et créer des cartes interactives avec la technologie géospatiale. Cet article explore comment traiter efficacement plus de 7 millions d'enregistrements en utilisant Laravel et MySQL et les convertir en visualisations de cartes interactives. Exigences initiales du projet de défi: extraire des informations précieuses en utilisant 7 millions d'enregistrements dans la base de données MySQL. Beaucoup de gens considèrent d'abord les langages de programmation, mais ignorent la base de données elle-même: peut-il répondre aux besoins? La migration des données ou l'ajustement structurel est-il requis? MySQL peut-il résister à une charge de données aussi importante? Analyse préliminaire: les filtres et les propriétés clés doivent être identifiés. Après analyse, il a été constaté que seuls quelques attributs étaient liés à la solution. Nous avons vérifié la faisabilité du filtre et établi certaines restrictions pour optimiser la recherche. Recherche de cartes basée sur la ville
 Comment définir le délai de Vue Axios
Apr 07, 2025 pm 10:03 PM
Comment définir le délai de Vue Axios
Apr 07, 2025 pm 10:03 PM
Afin de définir le délai d'expiration de Vue Axios, nous pouvons créer une instance AxiOS et spécifier l'option Timeout: dans les paramètres globaux: vue.prototype. $ Axios = axios.create ({timeout: 5000}); Dans une seule demande: ce. $ axios.get ('/ api / utilisateurs', {timeout: 10000}).
 Comment optimiser les performances de la base de données après l'installation de MySQL
Apr 08, 2025 am 11:36 AM
Comment optimiser les performances de la base de données après l'installation de MySQL
Apr 08, 2025 am 11:36 AM
L'optimisation des performances MySQL doit commencer à partir de trois aspects: configuration d'installation, indexation et optimisation des requêtes, surveillance et réglage. 1. Après l'installation, vous devez ajuster le fichier my.cnf en fonction de la configuration du serveur, tel que le paramètre innodb_buffer_pool_size, et fermer query_cache_size; 2. Créez un index approprié pour éviter les index excessifs et optimiser les instructions de requête, telles que l'utilisation de la commande Explication pour analyser le plan d'exécution; 3. Utilisez le propre outil de surveillance de MySQL (ShowProcessList, Showstatus) pour surveiller la santé de la base de données, et sauvegarde régulièrement et organisez la base de données. Ce n'est qu'en optimisant en continu ces étapes que les performances de la base de données MySQL peuvent être améliorées.
 Vue.js Comment convertir un tableau de type de chaîne en un tableau d'objets?
Apr 07, 2025 pm 09:36 PM
Vue.js Comment convertir un tableau de type de chaîne en un tableau d'objets?
Apr 07, 2025 pm 09:36 PM
Résumé: Il existe les méthodes suivantes pour convertir les tableaux de chaîne Vue.js en tableaux d'objets: Méthode de base: utilisez la fonction de carte pour convenir à des données formatées régulières. Gameplay avancé: l'utilisation d'expressions régulières peut gérer des formats complexes, mais ils doivent être soigneusement écrits et considérés. Optimisation des performances: Considérant la grande quantité de données, des opérations asynchrones ou des bibliothèques efficaces de traitement des données peuvent être utilisées. MEILLEUR PRATIQUE: Effacer le style de code, utilisez des noms de variables significatifs et des commentaires pour garder le code concis.
 Les ingénieurs de backend senior à distance (plates-formes) ont besoin de cercles
Apr 08, 2025 pm 12:27 PM
Les ingénieurs de backend senior à distance (plates-formes) ont besoin de cercles
Apr 08, 2025 pm 12:27 PM
Ingénieur backend à distance Emploi Vacant Société: Emplacement du cercle: Bureau à distance Type d'emploi: Salaire à temps plein: 130 000 $ - 140 000 $ Description du poste Participez à la recherche et au développement des applications mobiles Circle et des fonctionnalités publiques liées à l'API couvrant l'intégralité du cycle de vie de développement logiciel. Les principales responsabilités complètent indépendamment les travaux de développement basés sur RubyOnRails et collaborent avec l'équipe frontale React / Redux / Relay. Créez les fonctionnalités de base et les améliorations des applications Web et travaillez en étroite collaboration avec les concepteurs et le leadership tout au long du processus de conception fonctionnelle. Promouvoir les processus de développement positifs et hiérarchiser la vitesse d'itération. Nécessite plus de 6 ans de backend d'applications Web complexe
