
 Périphériques technologiques
IA
Byte propose un modèle de rééchantillonnage d'images asymétrique, avec des performances anti-compression de pointe en SOTA sur JPEG et WebP
Périphériques technologiques
IA
Byte propose un modèle de rééchantillonnage d'images asymétrique, avec des performances anti-compression de pointe en SOTA sur JPEG et WebP
Byte propose un modèle de rééchantillonnage d'images asymétrique, avec des performances anti-compression de pointe en SOTA sur JPEG et WebP

La tâche Image Rescaling (LR) optimise conjointement les opérations de sous-échantillonnage et de suréchantillonnage d'image. En réduisant et en restaurant la résolution de l'image, elle peut être utilisée pour économiser de l'espace de stockage ou de la bande passante de transmission. Dans des applications pratiques, telles que la distribution multi-niveaux des services d'atlas, les images basse résolution obtenues par sous-échantillonnage sont souvent soumises à une compression avec perte, et la compression avec perte entraîne souvent une diminution significative des performances des algorithmes existants.
Récemment, ByteDance - Volcano Engine Multimedia Laboratory a essayé pour la première fois d'optimiser les performances de rééchantillonnage d'images sous compression avec perte et a conçu un cadre de rééchantillonnage asymétrique réversible, basé sur les deux observations, a en outre proposé l'anti-compression modèle de rééchantillonnage d'images SAIN. Cette étude découple un ensemble de modules de réseau réversibles en deux parties : le rééchantillonnage et la simulation de compression, utilise une distribution gaussienne mixte pour modéliser la perte d'informations conjointe provoquée par la dégradation de la résolution et la distorsion de compression, et la combine avec un opérateur JPEG différenciable pour une analyse de bout en bout. end training , ce qui améliore considérablement la robustesse des algorithmes de compression courants.
Dans les recherches actuelles sur le rééchantillonnage d'images, la méthode SOTA s'appuie sur le Réseau Inversible pour construire une fonction bijective (fonction bijective), dont l'opération positive convertit les images haute résolution (HR) en image basse résolution (LR) et une série de variables cachées obéissant à la distribution normale standard. L'opération inverse échantillonne de manière aléatoire les variables cachées et les combine avec l'image LR pour une restauration par suréchantillonnage.
En raison des caractéristiques du réseau réversible, les opérateurs de sous-échantillonnage et de suréchantillonnage maintiennent un degré élevé de symétrie, ce qui rend l'image LR compressée difficile à restaurer par l'opérateur de suréchantillonnage initialement appris. Afin d'améliorer la robustesse à la compression avec perte, cette étude propose un modèle de rééchantillonnage d'image résistant à la compression SAIN (Self-Asymétrique Invertible Network) basé sur un cadre réversible asymétrique.
Les principales innovations du modèle SAIN sont les suivantes :
- propose un cadre de rééchantillonnage d'images réversible asymétrique, qui résout le problème de dégradation des performances provoqué par une symétrie stricte dans les méthodes précédentes ; propose une amélioration du module réversible (E- ; InvBlock) améliore les capacités d'ajustement du modèle en partant du principe du partage d'un grand nombre de paramètres et d'opérations, et modélise simultanément deux ensembles d'images LR avant et après la compression, permettant au modèle d'effectuer une récupération par compression et un suréchantillonnage via des opérations inverses.
- Construisez une distribution gaussienne mixte apprenable, modélisez la perte d'informations conjointe causée par la réduction de résolution et la compression avec perte, et optimisez directement les paramètres de distribution grâce à des techniques de reparamétrage, qui sont plus cohérentes avec la distribution réelle des variables latentes.
Les performances du modèle SAIN ont été vérifiées sous compression JPEG et WebP, et ses performances sur plusieurs ensembles de données publiques sont nettement supérieures à celles du modèle SOTA qui a été sélectionné pour l'AAAI 2023 Oral.

- Adresse papier : https://arxiv.org/abs/2303.02353
- Lien code : https://github.com/yang-jin-hai/SAIN
Cadre de rééchantillonnage asymétrique
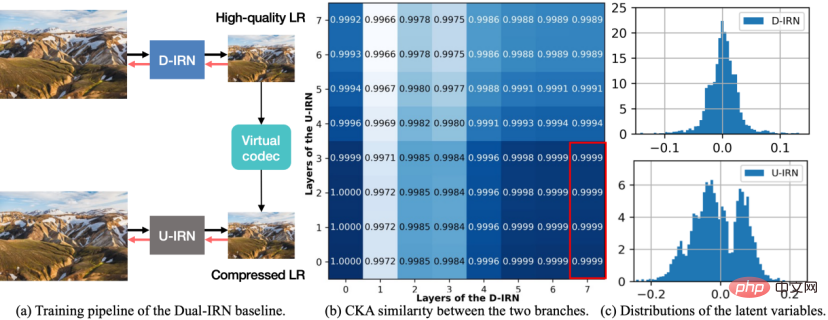
Figure 1 Diagramme du modèle Dual-IRN.
Afin d'améliorer les performances d'anti-compression, cette recherche a d'abord conçu un cadre de rééchantillonnage d'image réversible asymétrique et a proposé le schéma de base du modèle Dual-IRN. Après une analyse approfondie des lacunes de ce schéma, une optimisation supplémentaire a été effectuée. réalisé Le modèle SAIN est proposé. Comme le montre la figure ci-dessus, le modèle Dual-IRN contient deux branches, où D-IRN et U-IRN sont deux ensembles de réseaux réversibles qui apprennent respectivement la bijection entre l'image HR et l'image LR pré-compression/post-compression. .
Pendant la phase d'entraînement, le modèle Dual-IRN fait passer le gradient entre les deux branches via l'opérateur JPEG différentiable. Lors de la phase de test, le modèle utilise D-IRN pour sous-échantillonner afin d'obtenir des images LR de haute qualité. Après une compression réelle dans l'environnement réel, le modèle utilise ensuite U-IRN avec prise en charge de la compression pour terminer la récupération par compression et le suréchantillonnage.
Un tel cadre asymétrique permet aux opérateurs de suréchantillonnage et de sous-échantillonnage d'éviter des relations réversibles strictes. Il résout fondamentalement le problème causé par l'algorithme de compression détruisant la symétrie des processus de suréchantillonnage et de sous-échantillonnage, par rapport à SOTA. Le schéma symétrique s'améliore considérablement. les performances de résistance à la compression.
Par la suite, les chercheurs ont mené une analyse plus approfondie sur le modèle Dual-IRN et ont observé les deux phénomènes suivants :
- Premièrement, les CKA qui mesurent les caractéristiques de la couche intermédiaire des deux branches du D-IRN et de l'U- Les IRN sont de sexe similaire. Comme le montre le point (b) ci-dessus, les caractéristiques de sortie de la dernière couche du D-IRN (c'est-à-dire les images LR de haute qualité générées par le réseau) sont très similaires aux caractéristiques de sortie des couches peu profondes de l'U-IRN, ce qui indique le comportement superficiel de l'U-IRN est plus proche de la simulation de la perte d'échantillonnage, tandis que le comportement profond est plus proche de la simulation de la perte par compression.
- Deuxièmement, comptez la vraie distribution des variables cachées dans la couche intermédiaire des deux branches D-IRN et U-IRN. Comme le montre (c) (d) ci-dessus, les variables latentes du D-IRN sans détection compressée satisfont à l'hypothèse de distribution normale unimodale dans son ensemble, tandis que les variables latentes de l'U-IRN avec détection compressée présentent une forme multimodale. indiquant que la forme de perte d’informations causée par une compression avec perte est plus complexe.
Sur la base de l'analyse ci-dessus, les chercheurs ont optimisé le modèle sous plusieurs aspects. Le modèle SAIN résultant a non seulement réduit le nombre de paramètres du réseau de près de moitié, mais a également permis d'améliorer encore les performances.
Détails du modèle SAIN
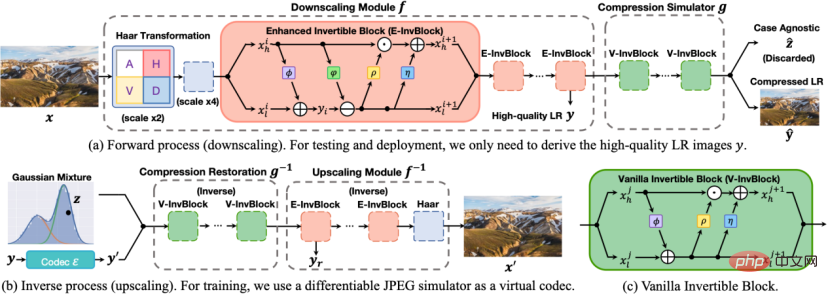
Figure 2 Schéma du modèle SAIN.
L'architecture du modèle SAIN est présentée dans la figure ci-dessus, et les quatre améliorations principales suivantes ont été apportées :
1. Sur la base de la similitude des caractéristiques de la couche intermédiaire, un ensemble de modules de réseau réversibles est découplé en deux parties : le rééchantillonnage et la simulation de compression, formant une architecture auto-asymétrique pour éviter d'utiliser deux ensembles complets de réseaux réversibles. Dans la phase de test, utilisez la transformation directe
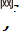
pour obtenir des images LR de haute qualité, utilisez d'abord la transformation inverse
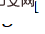
pour la récupération de compression, puis utilisez la transformation inverse
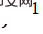
pour le suréchantillonnage.
2. Structure du réseau. E-InvBlock est proposé sur la base de l'hypothèse que la perte de compression peut être récupérée à l'aide d'informations haute fréquence. Une transformation additive est ajoutée au module, de sorte que deux ensembles d'images LR avant et après compression puissent être modélisés efficacement tout en partageant. un grand nombre d'opérations.
3. Modélisation de la perte d'informations. Sur la base de la véritable distribution des variables latentes, il est proposé d'utiliser la distribution gaussienne mixte apprenable pour modéliser la perte d'informations conjointe causée par le sous-échantillonnage et la compression avec perte, et d'optimiser les paramètres de distribution de bout en bout grâce à des techniques de reparamétrage.
4. Fonction objectif . Plusieurs fonctions de perte sont conçues pour limiter la réversibilité du réseau et améliorer la précision de la reconstruction. En même temps, des opérations de compression réelles sont introduites dans la fonction de perte pour améliorer la robustesse des schémas de compression réels.
Évaluation des expériences et des effetsL'ensemble de données d'évaluation est l'ensemble de vérification DIV2K et les quatre ensembles de tests standard de Set5, Set14, BSD100 et Urban100.
Les indicateurs quantitatifs d'évaluation sont :
- PSNR : rapport signal/bruit maximal, rapport signal/bruit maximal, reflétant l'erreur quadratique moyenne de l'image reconstruite et de l'image originale, plus il est élevé, mieux c'est
- SSIM : Mesure d'image de similarité structurelle ; , mesurant la différence entre l'image reconstruite et l'image originale. Plus la similarité structurelle de l'image est élevée, mieux c'est.
Dans les expériences comparatives du tableau 1 et de la figure 3, les scores PSNR et SSIM de SAIN sur tous les ensembles de données sont nettement en avance sur le modèle de rééchantillonnage d'images de SOTA. À un QF relativement faible, les méthodes existantes subissent généralement une grave dégradation des performances, tandis que le modèle SAIN maintient toujours des performances optimales.
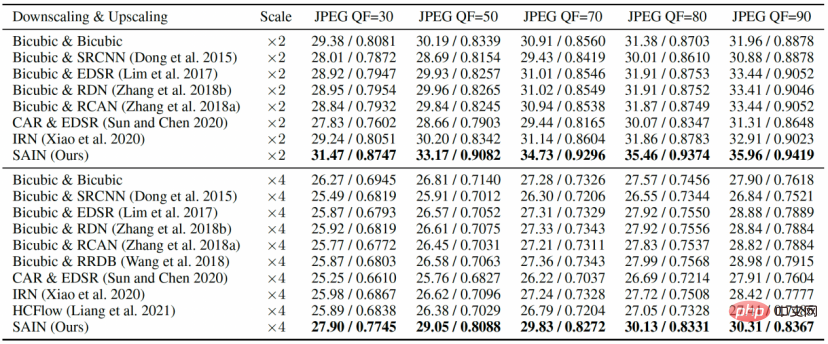
Tableau 1 Expériences comparatives pour comparer la qualité de reconstruction (PSNR/SSIM) sous différentes qualités de compression JPEG (QF) sur l'ensemble de données DIV2K.
Figure 3 Expérience comparative, comparant la qualité de reconstruction (PSNR) sous différents QF JPEG sur quatre ensembles de tests standards.
Dans les résultats de visualisation de la figure 4, on voit clairement que l'image HR restaurée par SAIN est plus claire et plus précise.

Figure 4 Comparaison des résultats de visualisation de différentes méthodes sous compression JPEG (grossissement ×4).
Dans les expériences d'ablation du tableau 2, les chercheurs ont également comparé plusieurs autres candidats à un entraînement combiné à une compression réelle. Ces candidats sont plus résistants à la compression que le modèle existant entièrement symétrique (IRN), mais restent inférieurs au modèle SAIN en termes de nombre de paramètres et de précision.
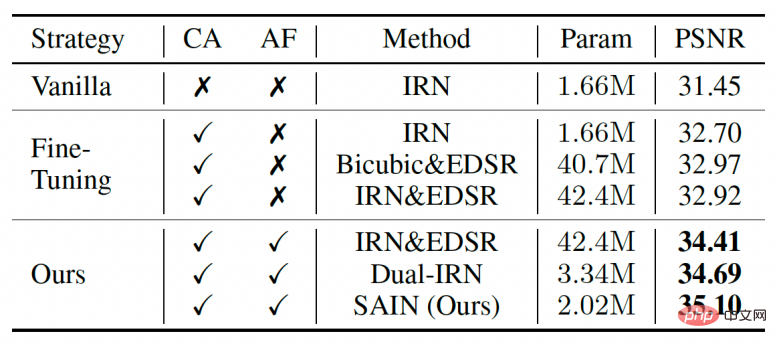
Tableau 2 Expériences d'ablation pour le cadre global et la stratégie de formation.
Dans les résultats de visualisation de la figure 5, les chercheurs ont comparé les résultats de reconstruction de différents modèles de rééchantillonnage d'images sous distorsion de compression WebP. On peut constater que le modèle SAIN affiche également le score de reconstruction le plus élevé sous le schéma de compression WebP et peut restaurer de manière claire et précise les détails de l'image, prouvant la compatibilité deSAIN pour différents schémas de compression.
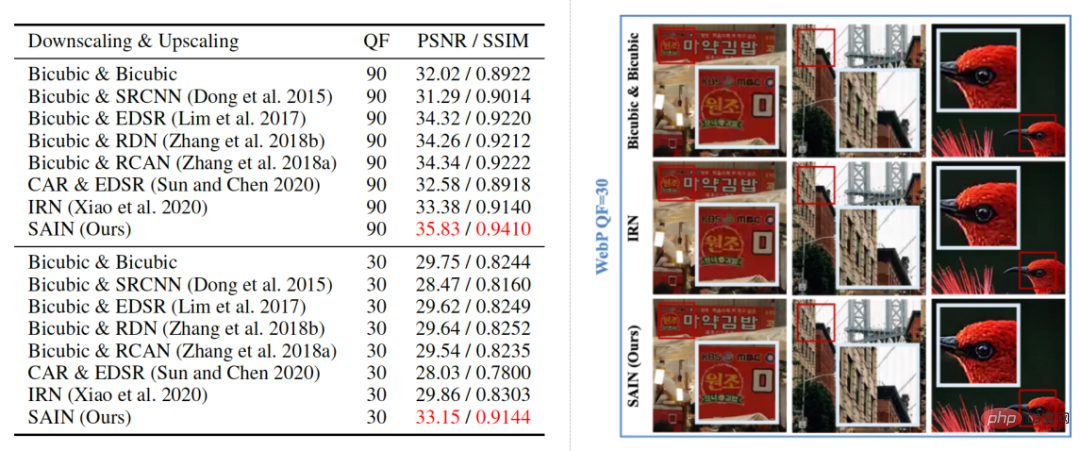
Figure 5 Comparaison qualitative et quantitative de différentes méthodes sous compression WebP (grossissement ×2).
De plus, l'étude a également mené des expériences d'ablation sur la distribution gaussienne mixte, E-InvBlock et la fonction de perte, prouvant la contribution positive de ces améliorations aux résultats.Résumé et perspectives
Le Volcano Engine Multimedia Laboratory a proposé un modèle basé sur un cadre asymétrique réversible pour le rééchantillonnage d'images anti-compression : SAIN. Le modèle se compose de deux parties : le rééchantillonnage et la simulation de compression. Il utilise une distribution gaussienne mixte pour modéliser la perte d'informations conjointe causée par la réduction de résolution et la distorsion de compression. Il est combiné avec un opérateur JPEG différentiable pour un apprentissage de bout en bout, et E. -InvBlock est proposé pour améliorer le modèle. La capacité d'ajustement améliore considérablement la robustesse des algorithmes de compression courants.Le Laboratoire multimédia Volcano Engine est une équipe de recherche de ByteDance. Il s'engage à explorer les technologies de pointe dans le domaine multimédia et à participer aux travaux de normalisation internationaux. Ses nombreux algorithmes innovants et solutions logicielles et matérielles ont été largement utilisés dans des produits tels que. comme Douyin et Xigua Video et fournit des services techniques aux entreprises clientes de Volcano Engine. Depuis la création du laboratoire, de nombreux articles ont été sélectionnés dans les meilleures conférences internationales et revues phares, et ont remporté plusieurs championnats de compétitions techniques internationales, des prix de l'innovation industrielle et des prix du meilleur article. À l'avenir, l'équipe de recherche continuera d'optimiser les performances du modèle de rééchantillonnage d'images sous compression avec perte et d'explorer davantage des scénarios d'application plus complexes tels que le rééchantillonnage vidéo anti-compression et le rééchantillonnage à grossissement arbitraire.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 Aucune donnée OpenAI requise, rejoignez la liste des grands modèles de code ! UIUC publie StarCoder-15B-Instruct
Jun 13, 2024 pm 01:59 PM
Aucune donnée OpenAI requise, rejoignez la liste des grands modèles de code ! UIUC publie StarCoder-15B-Instruct
Jun 13, 2024 pm 01:59 PM
À la pointe de la technologie logicielle, le groupe de l'UIUC Zhang Lingming, en collaboration avec des chercheurs de l'organisation BigCode, a récemment annoncé le modèle de grand code StarCoder2-15B-Instruct. Cette réalisation innovante a permis une percée significative dans les tâches de génération de code, dépassant avec succès CodeLlama-70B-Instruct et atteignant le sommet de la liste des performances de génération de code. Le caractère unique de StarCoder2-15B-Instruct réside dans sa stratégie d'auto-alignement pur. L'ensemble du processus de formation est ouvert, transparent et complètement autonome et contrôlable. Le modèle génère des milliers d'instructions via StarCoder2-15B en réponse au réglage fin du modèle de base StarCoder-15B sans recourir à des annotations manuelles coûteuses.
 Yolov10 : explication détaillée, déploiement et application en un seul endroit !
Jun 07, 2024 pm 12:05 PM
Yolov10 : explication détaillée, déploiement et application en un seul endroit !
Jun 07, 2024 pm 12:05 PM
1. Introduction Au cours des dernières années, les YOLO sont devenus le paradigme dominant dans le domaine de la détection d'objets en temps réel en raison de leur équilibre efficace entre le coût de calcul et les performances de détection. Les chercheurs ont exploré la conception architecturale de YOLO, les objectifs d'optimisation, les stratégies d'expansion des données, etc., et ont réalisé des progrès significatifs. Dans le même temps, le recours à la suppression non maximale (NMS) pour le post-traitement entrave le déploiement de bout en bout de YOLO et affecte négativement la latence d'inférence. Dans les YOLO, la conception de divers composants manque d’une inspection complète et approfondie, ce qui entraîne une redondance informatique importante et limite les capacités du modèle. Il offre une efficacité sous-optimale et un potentiel d’amélioration des performances relativement important. Dans ce travail, l'objectif est d'améliorer encore les limites d'efficacité des performances de YOLO à la fois en post-traitement et en architecture de modèle. à cette fin
 L'Université Tsinghua a pris le relais et YOLOv10 est sorti : les performances ont été grandement améliorées et il figurait sur la hot list de GitHub
Jun 06, 2024 pm 12:20 PM
L'Université Tsinghua a pris le relais et YOLOv10 est sorti : les performances ont été grandement améliorées et il figurait sur la hot list de GitHub
Jun 06, 2024 pm 12:20 PM
La série de référence YOLO de systèmes de détection de cibles a une fois de plus reçu une mise à niveau majeure. Depuis la sortie de YOLOv9 en février de cette année, le relais de la série YOLO (YouOnlyLookOnce) a été passé entre les mains de chercheurs de l'Université Tsinghua. Le week-end dernier, la nouvelle du lancement de YOLOv10 a attiré l'attention de la communauté IA. Il est considéré comme un cadre révolutionnaire dans le domaine de la vision par ordinateur et est connu pour ses capacités de détection d'objets de bout en bout en temps réel, poursuivant l'héritage de la série YOLO en fournissant une solution puissante alliant efficacité et précision. Adresse de l'article : https://arxiv.org/pdf/2405.14458 Adresse du projet : https://github.com/THU-MIG/yo
 Comment évaluer la rentabilité du support commercial des frameworks Java
Jun 05, 2024 pm 05:25 PM
Comment évaluer la rentabilité du support commercial des frameworks Java
Jun 05, 2024 pm 05:25 PM
L'évaluation du rapport coût/performance du support commercial pour un framework Java implique les étapes suivantes : Déterminer le niveau d'assurance requis et les garanties de l'accord de niveau de service (SLA). L’expérience et l’expertise de l’équipe d’appui à la recherche. Envisagez des services supplémentaires tels que les mises à niveau, le dépannage et l'optimisation des performances. Évaluez les coûts de support commercial par rapport à l’atténuation des risques et à une efficacité accrue.
 Rapport technique Google Gemini 1.5 : prouvez facilement les questions de l'Olympiade mathématique, la version Flash est 5 fois plus rapide que GPT-4 Turbo
Jun 13, 2024 pm 01:52 PM
Rapport technique Google Gemini 1.5 : prouvez facilement les questions de l'Olympiade mathématique, la version Flash est 5 fois plus rapide que GPT-4 Turbo
Jun 13, 2024 pm 01:52 PM
En février de cette année, Google a lancé le grand modèle multimodal Gemini 1.5, qui a considérablement amélioré les performances et la vitesse grâce à l'ingénierie et à l'optimisation de l'infrastructure, à l'architecture MoE et à d'autres stratégies. Avec un contexte plus long, des capacités de raisonnement plus fortes et une meilleure gestion du contenu multimodal. Ce vendredi, Google DeepMind a officiellement publié le rapport technique de Gemini 1.5, qui couvre la version Flash et d'autres mises à jour récentes. Le document fait 153 pages. Lien du rapport technique : https://storage.googleapis.com/deepmind-media/gemini/gemini_v1_5_report.pdf Dans ce rapport, Google présente Gemini1
 Revoir! Résumer de manière exhaustive le rôle important des modèles de base dans la promotion de la conduite autonome
Jun 11, 2024 pm 05:29 PM
Revoir! Résumer de manière exhaustive le rôle important des modèles de base dans la promotion de la conduite autonome
Jun 11, 2024 pm 05:29 PM
Écrit ci-dessus et compréhension personnelle de l'auteur : Récemment, avec le développement et les percées de la technologie d'apprentissage profond, les modèles de base à grande échelle (Foundation Models) ont obtenu des résultats significatifs dans les domaines du traitement du langage naturel et de la vision par ordinateur. L’application de modèles de base à la conduite autonome présente également de grandes perspectives de développement, susceptibles d’améliorer la compréhension et le raisonnement des scénarios. Grâce à une pré-formation sur un langage riche et des données visuelles, le modèle de base peut comprendre et interpréter divers éléments des scénarios de conduite autonome et effectuer un raisonnement, fournissant ainsi un langage et des commandes d'action pour piloter la prise de décision et la planification. Le modèle de base peut être constitué de données enrichies d'une compréhension du scénario de conduite afin de fournir les rares caractéristiques réalisables dans les distributions à longue traîne qui sont peu susceptibles d'être rencontrées lors d'une conduite de routine et d'une collecte de données.
 Comment la courbe d'apprentissage des frameworks PHP se compare-t-elle à celle d'autres frameworks de langage ?
Jun 06, 2024 pm 12:41 PM
Comment la courbe d'apprentissage des frameworks PHP se compare-t-elle à celle d'autres frameworks de langage ?
Jun 06, 2024 pm 12:41 PM
La courbe d'apprentissage d'un framework PHP dépend de la maîtrise du langage, de la complexité du framework, de la qualité de la documentation et du support de la communauté. La courbe d'apprentissage des frameworks PHP est plus élevée par rapport aux frameworks Python et inférieure par rapport aux frameworks Ruby. Par rapport aux frameworks Java, les frameworks PHP ont une courbe d'apprentissage modérée mais un temps de démarrage plus court.
 Comment les options légères des frameworks PHP affectent-elles les performances des applications ?
Jun 06, 2024 am 10:53 AM
Comment les options légères des frameworks PHP affectent-elles les performances des applications ?
Jun 06, 2024 am 10:53 AM
Le framework PHP léger améliore les performances des applications grâce à une petite taille et une faible consommation de ressources. Ses fonctionnalités incluent : une petite taille, un démarrage rapide, une faible utilisation de la mémoire, une vitesse de réponse et un débit améliorés et une consommation de ressources réduite. Cas pratique : SlimFramework crée une API REST, seulement 500 Ko, une réactivité élevée et un débit élevé.
