
 Périphériques technologiques
IA
Evolution technique du grand modèle temps réel pour la recommandation Weibo
Périphériques technologiques
IA
Evolution technique du grand modèle temps réel pour la recommandation Weibo
Evolution technique du grand modèle temps réel pour la recommandation Weibo


1. Examen de la feuille de route technique
1. Scénarios et caractéristiques commerciaux
Les activités recommandées dont cette équipe est responsable dans Weibo APP comprennent principalement :
① Recommandé sur le page d'accueil Pour tout le contenu de la colonne onglet, les produits de flux d'informations ont généralement une proportion de trafic plus élevée dans le premier onglet
② Un flux d'informations saisi en glissant vers le bas la recherche chaude C'est aussi notre scénario métier. , y compris sur cette page. Autres onglets de flux d'informations, tels que les chaînes vidéo, etc.
③ Recherchez ou cliquez sur les vidéos recommandées dans l'ensemble de l'application pour accéder à la scène vidéo immersive.
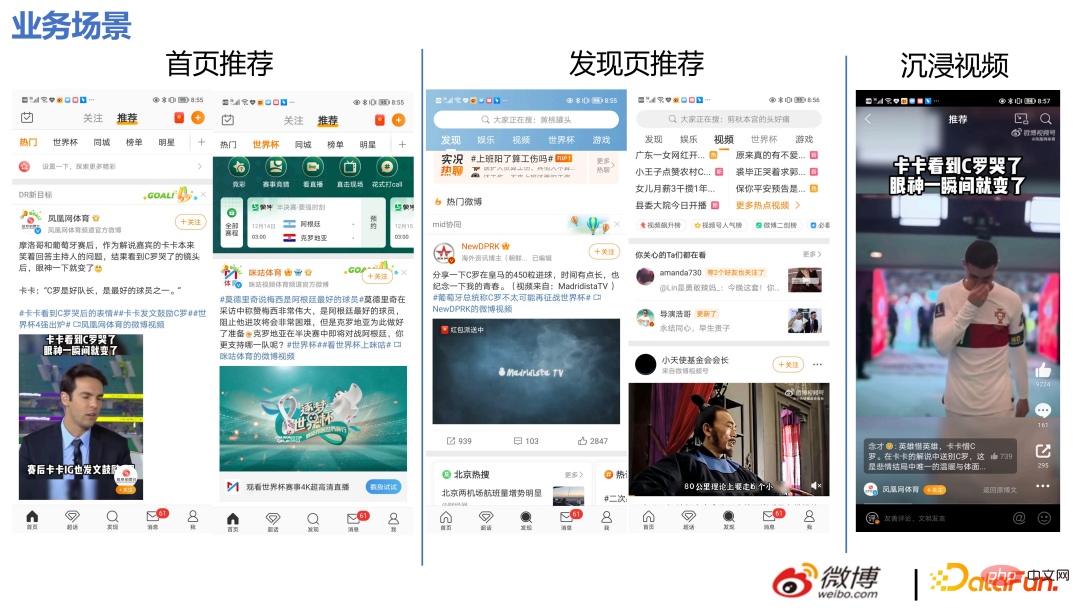
Notre activité présente les caractéristiques suivantes :
(1) Tout d'abord, du point de vue de la mise en œuvre des recommandations :
① Il existe de nombreux scénarios commerciaux.
② Les utilisateurs disposent de diverses opérations et commentaires sur l'interface utilisateur de Weibo. Le contenu peut être cliqué pour accéder à la page de texte à regarder, ou consommé dans le flux. Les commentaires dans le flux sont divers, comme cliquer pour accéder au flux. la page personnelle du blogueur, en cliquant pour accéder à la page de texte, cliquez sur les images, cliquez sur les vidéos, transférez les commentaires et les likes, etc.
③ Il existe de nombreux types de supports pouvant être distribués, tels que des images longues, des images (une ou plusieurs images), des vidéos (vidéos horizontales ou verticales), des articles, etc. page d'accueil.
(2) Du point de vue du positionnement du produit :
① Points chauds de service : les changements de trafic de Weibo sont particulièrement importants avant et après l'apparition des points chauds. Les utilisateurs peuvent consommer en douceur du contenu chaud dans le. recommandations, qui sont des demandes de produits recommandés par l'entreprise.
② Établir des relations : j'espère accumuler des relations sociales dans le Weibo recommandé.
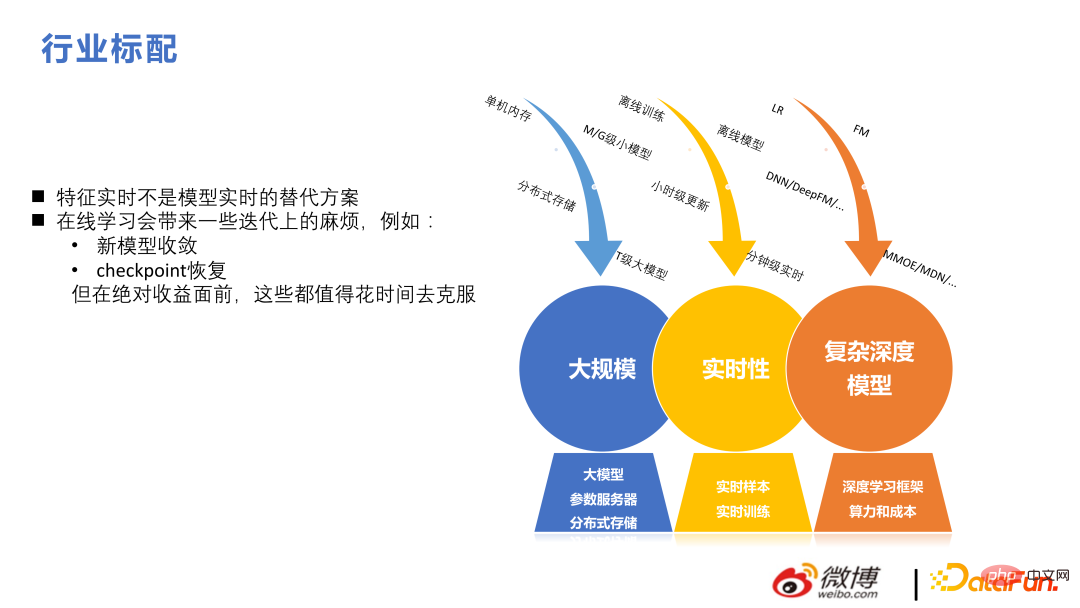
2. Sélection technologiqueL'image ci-dessous montre nos progrès technologiques au cours des dernières années.
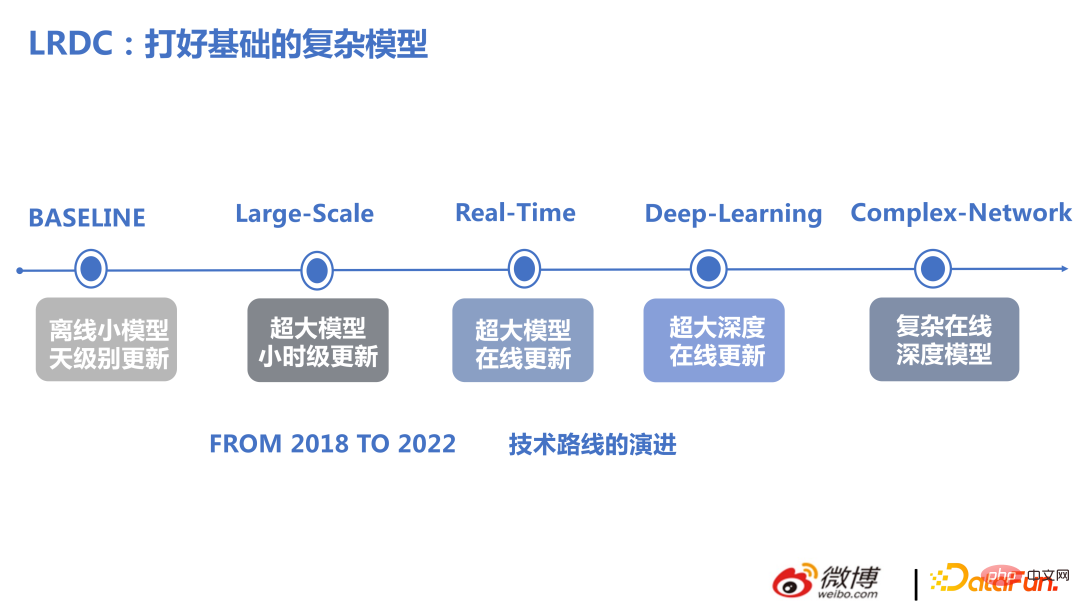
En termes du cadre de recommandation actuel, des centaines de milliards de fonctionnalités et des milliards de paramètres sont standards. Différent du NLP et du CV, les modèles trop volumineux dans ces deux directions ont une grande complexité du réseau lui-même, une bonne parcimonie dans les scénarios recommandés, une taille de modèle relativement grande et la formation utilise souvent le parallélisme des données, et chaque utilisateur n'a pas besoin de servir tous les modèles. paramètres.
L'évolution technique de cette équipe de 2018 à 2022 se présente principalement sous deux aspects : à grande échelle et en temps réel. Sur cette base, réalisez des structures complexes pour obtenir deux fois le résultat avec moitié moins d'effort.
Voici une brève introduction à notre plateforme d'apprentissage en ligne Weidl.
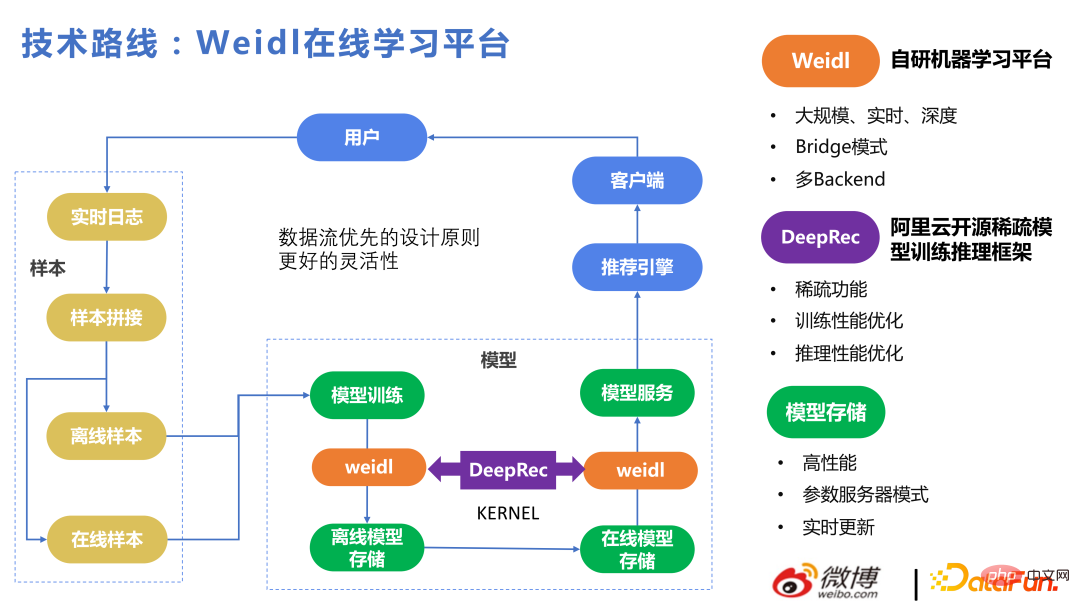
Le processus principal est le suivant : Réunir des échantillons de comportement des utilisateurs, les apprendre pour le modèle, puis les recommander aux utilisateurs pour obtenir des commentaires. Le principe de conception global de la priorité du flux de données est adopté pour obtenir une meilleure flexibilité. Quelle que soit la méthode utilisée pour entraîner KERNEL, la partie mise à jour en temps réel entre le stockage du modèle hors ligne et le PS en ligne existe toujours. Qu'il s'agisse d'un modèle de formation LR ou FM écrit à la main, Tensorflow ou DeepRec, il est possible que le stockage du modèle correspondant soit un ensemble de flux de données construits par nous-mêmes, et le format du modèle est également créé par nous-mêmes, garantissant ainsi plusieurs. Les backends peuvent être téléchargés à partir de La formation du modèle peut être mise à jour en ligne en moins d'une minute et les nouveaux paramètres peuvent être utilisés la prochaine fois que l'utilisateur l'appelle. Selon ce principe de conception, le backend peut être facilement commuté.
Weidl est la plate-forme d'apprentissage automatique auto-développée de Weibo. Le mode Bridge peut appeler des opérateurs de divers frameworks d'apprentissage profond. Vous pouvez également utiliser le mode Bridge sans cela. Il est également très pratique de le remplacer par des opérateurs auto-développés. . Par exemple, lorsque nous utilisions Tensorflow auparavant, nous effectuions une allocation de mémoire et une optimisation des opérateurs sur tf. Nous passerons à DeepRec au cours du second semestre 2022. Après en avoir appris davantage sur DeepRec, nous constaterons que certains des points d'optimisation des performances précédents. basés sur tf sont similaires à ceux de DeepRec.
La figure suivante répertorie certaines des versions réalisées par notre équipe au fil des années pour faciliter la compréhension par chacun de l'apport de chaque point technique dans notre métier. La première consiste à utiliser des modèles basés sur FM pour résoudre à grande échelle. problèmes de recommandation en temps réel, suivis de Création d'une structure complexe basée sur la profondeur. À en juger par les résultats, l'utilisation antérieure de modèles non approfondis pour résoudre des problèmes en temps réel en ligne a également apporté de grands avantages.
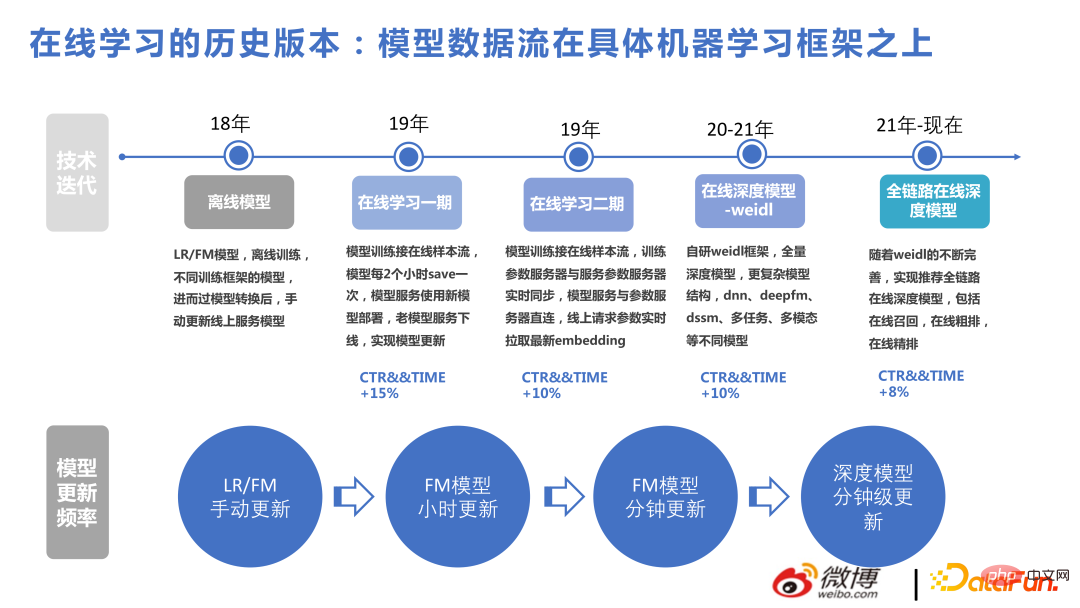
La recommandation de flux d'informations est différente de la recommandation de produits. La recommandation de flux d'informations est fondamentalement une structure profonde en temps réel à grande échelle. Il existe également des difficultés et des différences dans ce domaine. Par exemple, les fonctionnalités en temps réel ne constituent pas une alternative aux modèles en temps réel. Pour les systèmes de recommandation, ce que le modèle apprend est plus important. De plus, l'apprentissage en ligne pose certains problèmes d'itération. Mais avant que des gains absolus puissent être réalisés, ils pourront être surmontés avec le temps.
2. Itération technologique récente des grands modèles
Ce chapitre présentera le modèle d'itération commerciale sous les aspects des objectifs, de la structure et des caractéristiques.
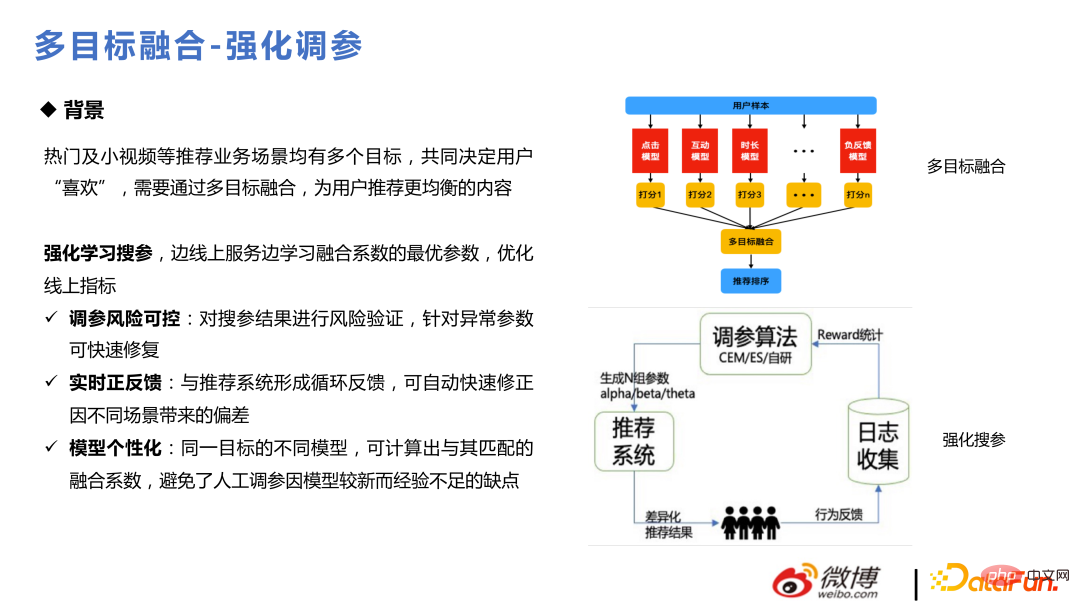
1. Fusion multi-objectifs
Il existe de nombreuses opérations utilisateur dans la scène Weibo. Les utilisateurs expriment leur amour pour les objets à travers de nombreux comportements, tels que l'interaction par clic, la durée, la liste déroulante, etc. l'objectif doit être abordé. La modélisation et l'estimation, et enfin la fusion et le classement global, sont très importants pour le secteur de la recommandation. Lorsque cela a été fait pour la première fois, cela a été effectué par fusion statique et recherche de paramètres hors ligne. Plus tard, cela a été remplacé par une recherche de paramètres dynamique via la méthode d'apprentissage par renforcement. Après cela, une certaine optimisation de la formule de fusion a été effectuée, et plus tard, elle a été améliorée pour en produire. les scores de fusion à travers le modèle attendent.

La méthode de base pour renforcer l'ajustement des paramètres est Divisez le trafic en ligne en petits pools de trafic et utilisez certains paramètres en ligne actuels pour générer de nouveaux paramètres. ces paramètres, collecter des commentaires et itérer. La partie essentielle est le calcul de reward, qui utilise CEM et ES. Plus tard, un algorithme auto-développé a été utilisé pour s’adapter à ses propres besoins commerciaux. Étant donné que l’apprentissage en ligne évolue très rapidement, de gros problèmes surgiront si les paramètres ne peuvent pas changer en conséquence. Par exemple, les préférences de chacun pour le contenu vidéo changent du vendredi soir au samedi matin et du dimanche soir au lundi matin. les paramètres de fusion doivent refléter les changements dans les préférences de l'utilisateur pour quelque chose.
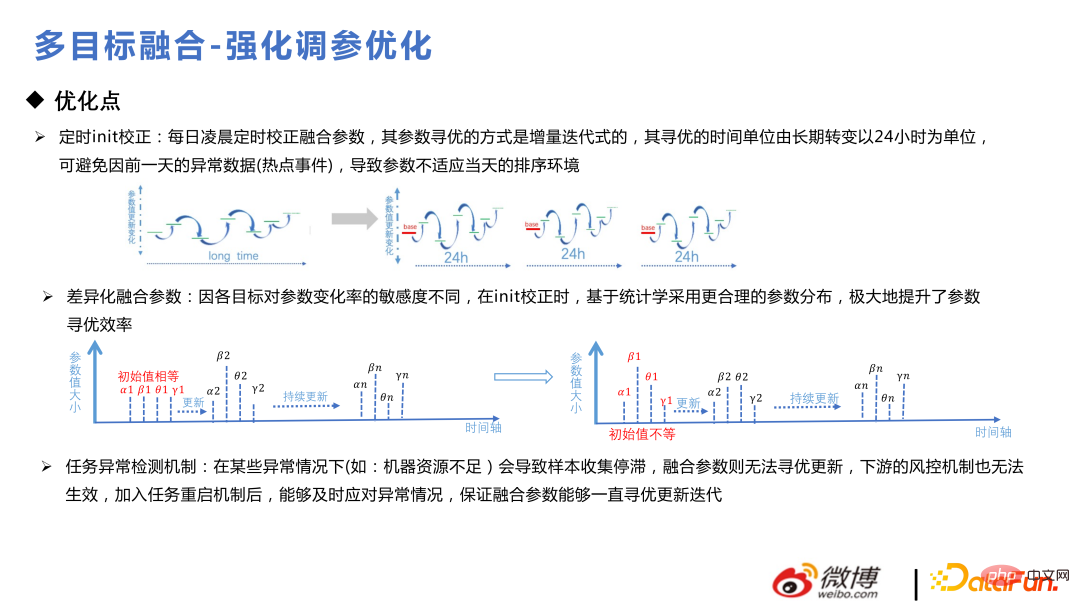
Voici quelques petites astuces d'optimisation du modèle. Les utilisateurs l'utilisent de manière cyclique tous les jours, sinon cela pourrait aller vers une branche plus biaisée ; Lors de l'initialisation des paramètres, ils doivent obéir à la distribution préalable, effectuer d'abord une analyse préalable, puis effectuer une fusion différentielle ; ajouter un mécanisme de détection d'anomalies pour garantir que les paramètres de fusion peuvent être mis à jour de manière cohérente et itérative ;
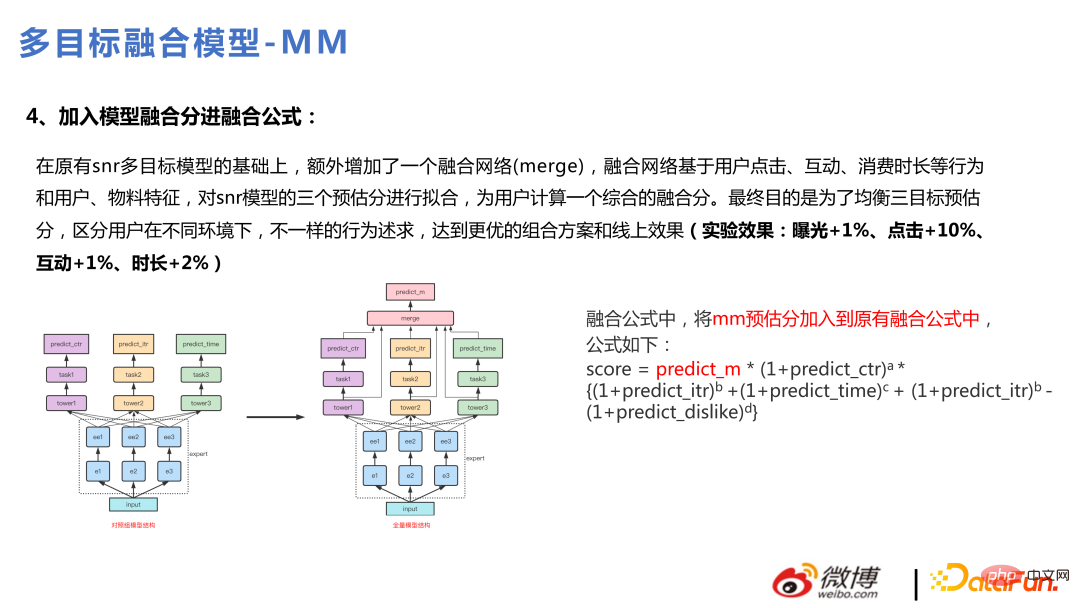
La formule de fusion utilise l'addition à Au début, il n'y avait pas beaucoup d'objectifs commerciaux pour la fusion. Plus tard, à mesure que le nombre d'objectifs augmentait, il s'est avéré que la fusion additive n'était pas pratique pour prendre en charge l'ajout de plus d'objectifs et affaiblirait l'importance de chaque sous-objectif. . La formule de fusion multiplicative a donc été utilisée plus tard. L'effet est affiché en ppt : # Une fois la version complète mise à niveau vers multitâche, cette version est optimisée pour effectuer une fusion cible via le modèle. Grâce à la fusion de modèles, de nombreux éléments non linéaires peuvent être mieux capturés et avoir un meilleur pouvoir expressif. De cette manière, une fusion personnalisée peut également être réalisée, et les éléments fusionnés seront différents pour chaque utilisateur.

2. 🎜 #Le multitâche est un concept devenu populaire depuis 2019 et 2020. Les systèmes de recommandation doivent souvent se concentrer sur plusieurs objectifs en même temps. Par exemple, il y a sept objectifs dans notre scénario commercial : clic, durée,. interaction, diffusion d'achèvement, commentaires négatifs, entrez dans la page d'accueil, déroulez pour actualiser, etc. Former un modèle pour chaque cible consomme plus de ressources et est fastidieux. De plus, certaines cibles sont clairsemées et d'autres sont relativement denses. Si les modèles sont construits séparément, ces cibles clairsemées ne sont généralement pas faciles à bien apprendre. Apprendre ensemble peut résoudre le problème de l'apprentissage des cibles clairsemées.
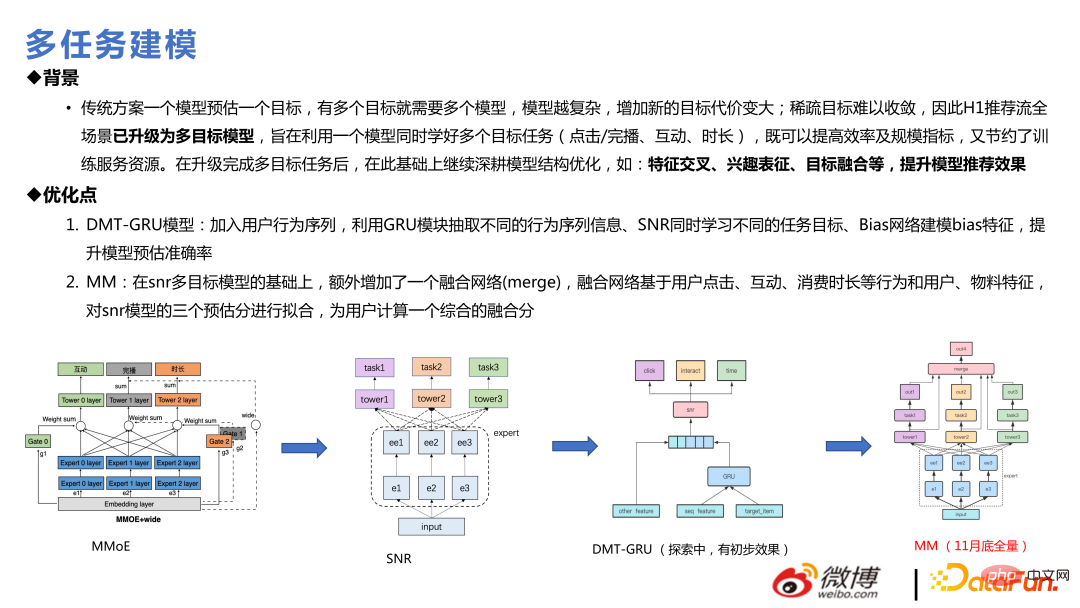
L'introduction recommandée à la modélisation multitâche commence généralement par le MMOE et progresse vers SNR, puis au DMT, et enfin au MM complet, qui est en fait une optimisation du SNR comme les réseaux convergés. Avant de procéder à plusieurs tâches, les questions clés à résoudre comprennent : s'il existe un conflit entre les différentes pertes entre plusieurs cibles et s'il y aura un effet de bascule entre elles, le problème de l'espace d'échantillonnage incohérent ; équilibre, etc Dans l'expérience réelle, les méthodes PCGrad et UWL montreront leurs effets dans les données de test. Cependant, si elles sont élargies à un environnement de production et à un apprentissage et une formation continus en ligne, les effets de ces méthodes diminueront plus rapidement, au contraire. Il n'est pas impossible de définir certaines valeurs dans l'ensemble de l'environnement des stages en ligne. Il n'est pas sûr que cela soit lié à l'apprentissage en ligne ou à la taille de l'échantillon. L'effet du MMOE seul est également relativement bon. Sur la gauche se trouvent quelques points de profit réels dans l'entreprise.

Ce qui suit commence par MMOE Certains évolution technologique. La première étape vers le multitâche consiste en de simples connexions matérielles, suivies du MMOE, puis du SNR ou du PLE. Ce sont des méthodes relativement matures dans l'industrie ces dernières années. Cette équipe utilise SNR et effectue deux optimisations. Dans la moitié inférieure de la figure ci-dessous, la partie la plus à gauche correspond à l'approche du document standard SNR. Nous avons simplifié la transformation au sein de l'expert. Dans le même temps, il y aura des experts exclusifs et des experts partagés. Ici, des analyses seront effectuées sur la base des valeurs réelles et des écarts estimés des conclusions des données renvoyées dans certaines affaires réelles, et des experts indépendants seront réalisés.
3. Technologie multi-scénarios
Nous sommes responsables de nombreux scénarios de recommandation, il est donc naturel de penser à utiliser une technologie multi-scénarios. Le multitâche signifie que certaines cibles sont relativement clairsemées. Le multi-scène signifie que les scènes sont grandes et petites. La convergence des petites scènes n'est pas si bonne en raison d'un volume de données insuffisant, tandis que la convergence des grandes scènes est meilleure. deux scènes ont à peu près la même taille, il y aura un espace au milieu. Certaines d'entre elles impliquent un transfert de connaissances qui profitera à l'entreprise. Il s'agit également d'une tendance récente et présente de nombreuses similitudes techniques avec le multitâche.
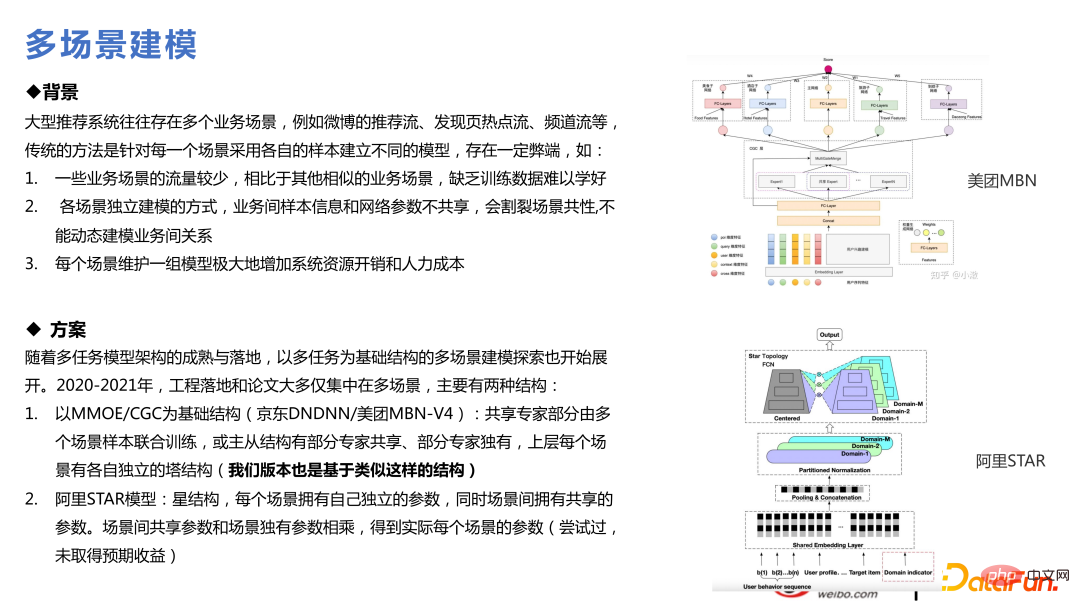
Sur la base de chaque modèle multi-tâches, plusieurs modèles de scènes peuvent être créés. Par rapport à la structure multi-tâches, ce qui est ajouté est la couche Slot-gate dans la figure ci-dessous. L'intégration des passes Slot-gate exprime différentes fonctions pour différents scénarios. La sortie via Slot-gate peut être divisée en trois parties : connexion au réseau expert, connexion à la tâche cible ou connexion aux fonctionnalités.
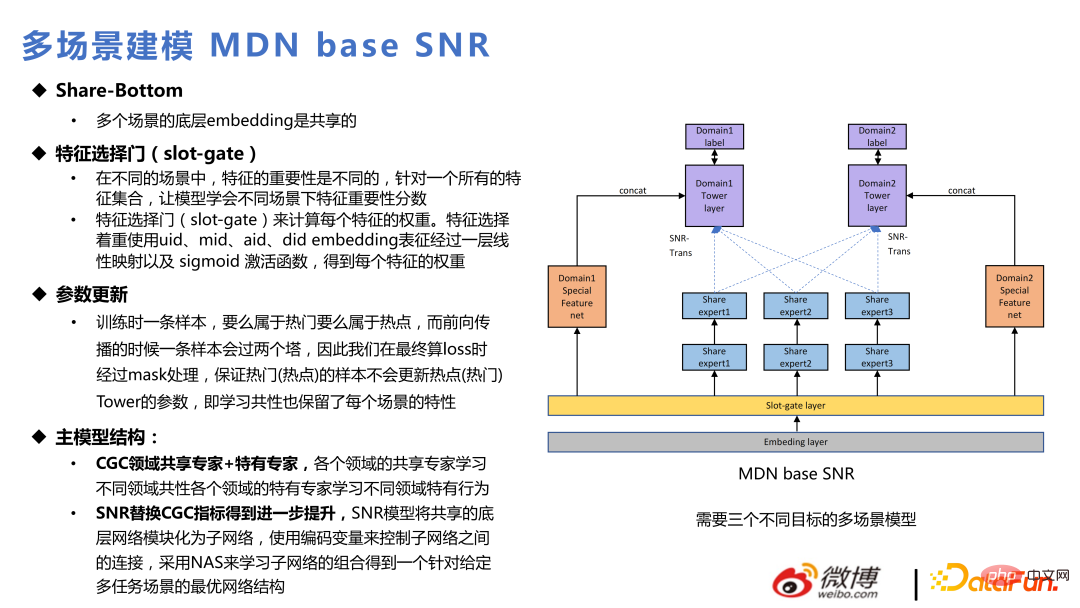
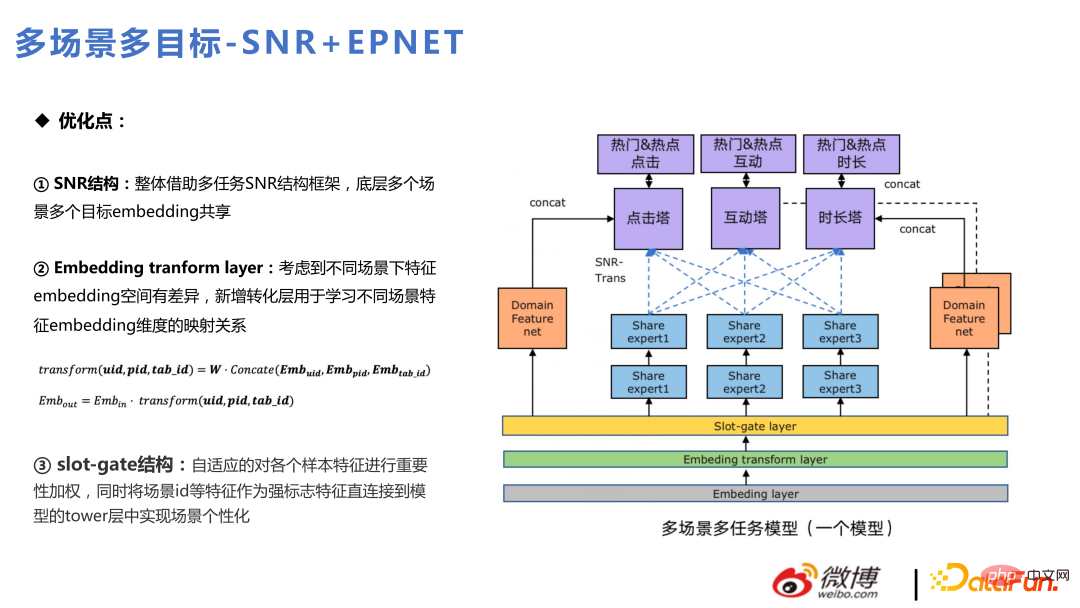
Le modèle principal utilise principalement le SNR pour remplacer le CGC, ce qui est cohérent avec l'itération du multi-tâches. Ce qui suit est l'application actuelle du multitâche et du multi-scénarios mélangés dans deux scénarios commerciaux internes : chaud et populaire. Parmi eux, la recommandation de page d'accueil est un flux populaire et la recommandation de page de découverte est un flux chaud.
La structure globale est similaire à celle du SNR, avec trois tours cibles : clic, interaction et durée. Ces trois tours cibles sont divisées en six cibles pour deux scènes populaires et incontournables. De plus, la couche de transformation d'intégration est ajoutée. Différente de Slot-gate, Slot-gate consiste à trouver l'importance des fonctionnalités, tandis que la couche de transformation d'intégration consiste à prendre en compte les différences d'espace d'intégration dans différents scénarios pour effectuer le mappage d'intégration. Certaines entités ont des dimensions différentes dans les deux scènes et sont transformées via la couche de transformation Embedding.
La représentation des intérêts est une technologie qui a été beaucoup proposée ces dernières années Du DIN d'Alibaba au SIM en passant par le DMT, elle est devenue le courant dominant du comportement des utilisateurs. modélisation de séquences dans l'industrie.
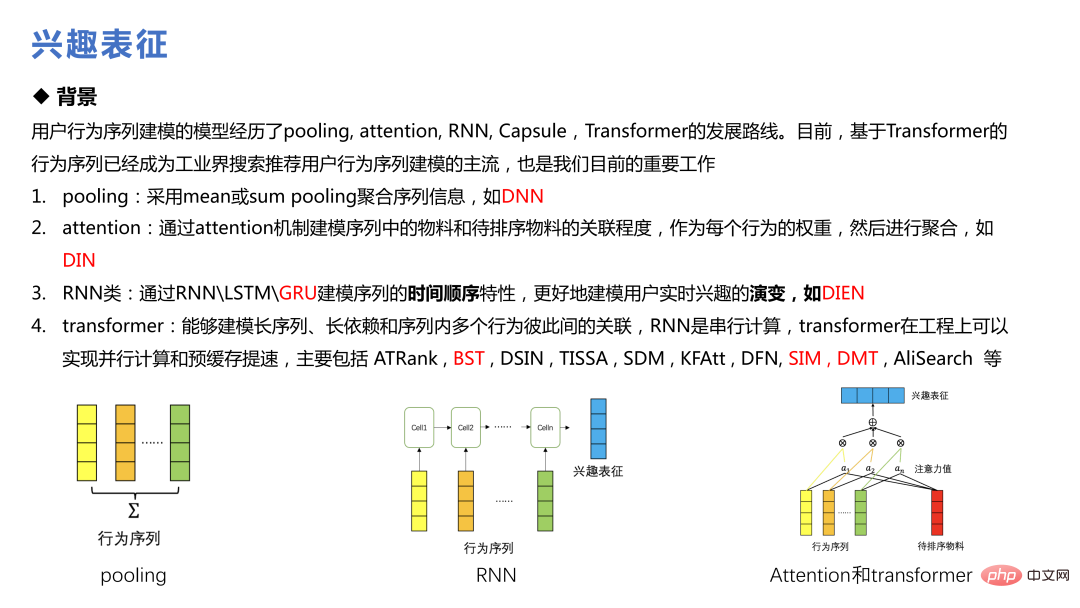
DIN utilisé au début pour construire plusieurs séquences de comportements pour différents comportements. Le mécanisme d'attention a été introduit pour attribuer différents poids aux différents matériaux dans le comportement, et l'unité d'activation locale a été utilisée pour apprendre la répartition du poids de la séquence utilisateur et des matériaux triés candidats actuels, réalisant ainsi une solution de classement fin populaire et réalisant certaines affaires. avantages.
Le cœur de DMT est d'utiliser Transformer en multitâche. Notre équipe a utilisé un modèle DMT simplifié, supprimé le module de biais, remplacé MMoE par SNR et obtenu certains résultats commerciaux après la mise en ligne.
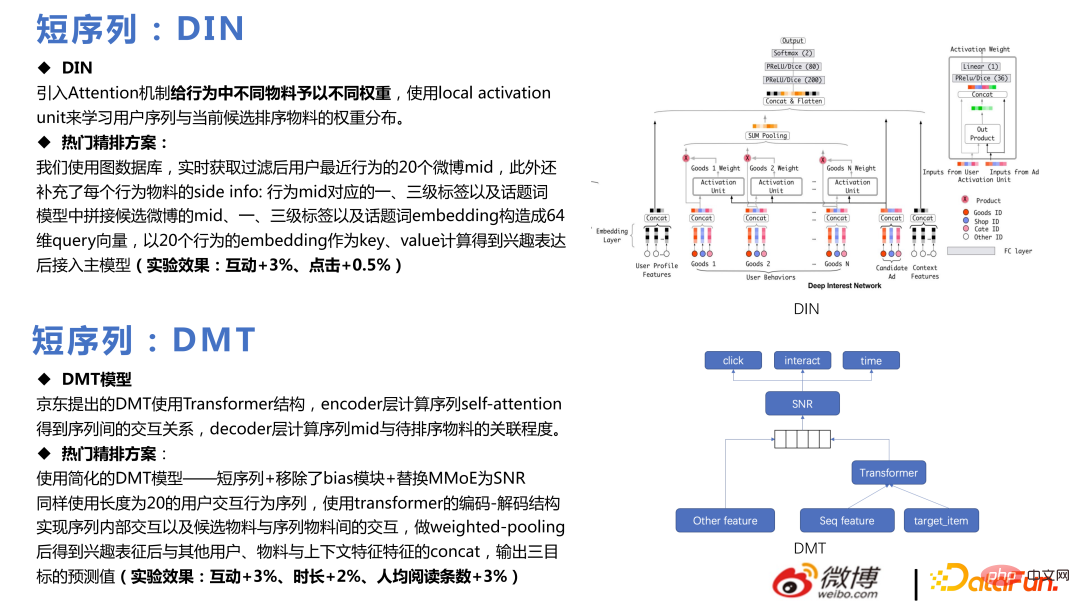
Multi-DIN consiste à étendre plusieurs séquences, à utiliser le milieu, la balise, l'auteur, etc. des matériaux candidats comme requêtes et à accorder une attention particulière à chaque séquence séparément après avoir obtenu la représentation d'intérêt. intégrer d'autres fonctionnalités dans le modèle de séquençage des tâches multi-DIN.
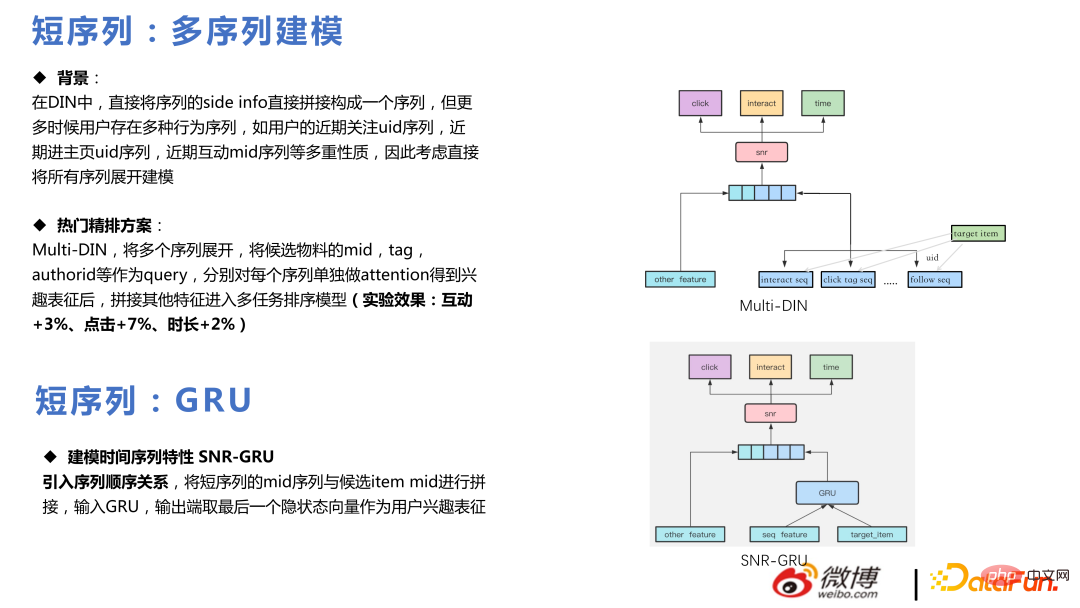
En même temps, nous avons également mené des expériences et constaté qu'en allongeant la séquence, comme en étendant le clic, la durée, la séquence d'interaction, etc., de 20 à 50 pour chaque séquence, l'effet c'est mieux, ce qui est le même que dans l'article. La conclusion est la même, mais des séquences plus longues nécessitent plus de puissance de calcul.
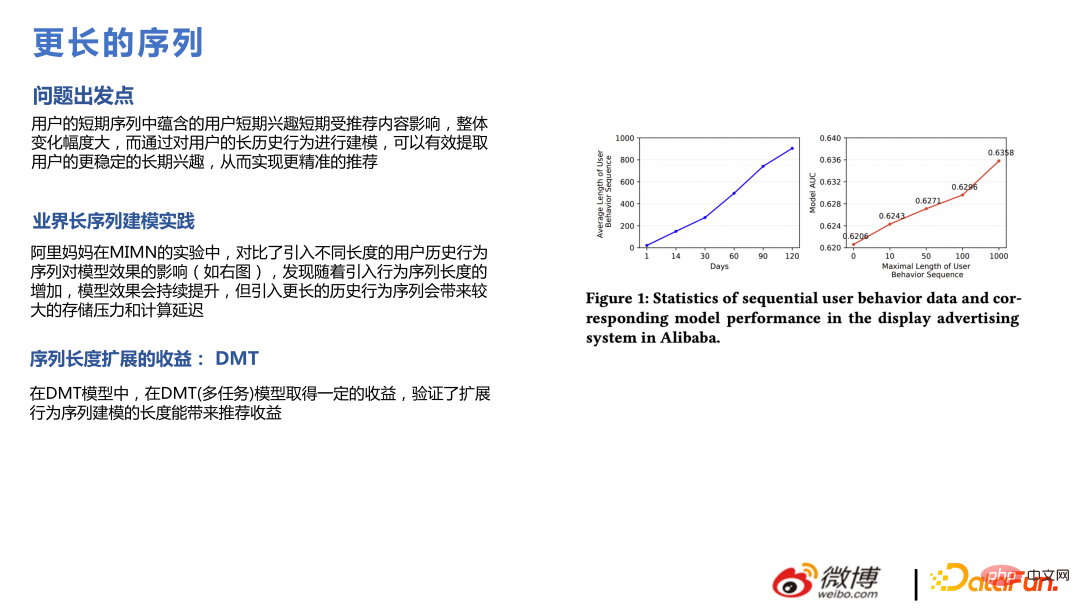
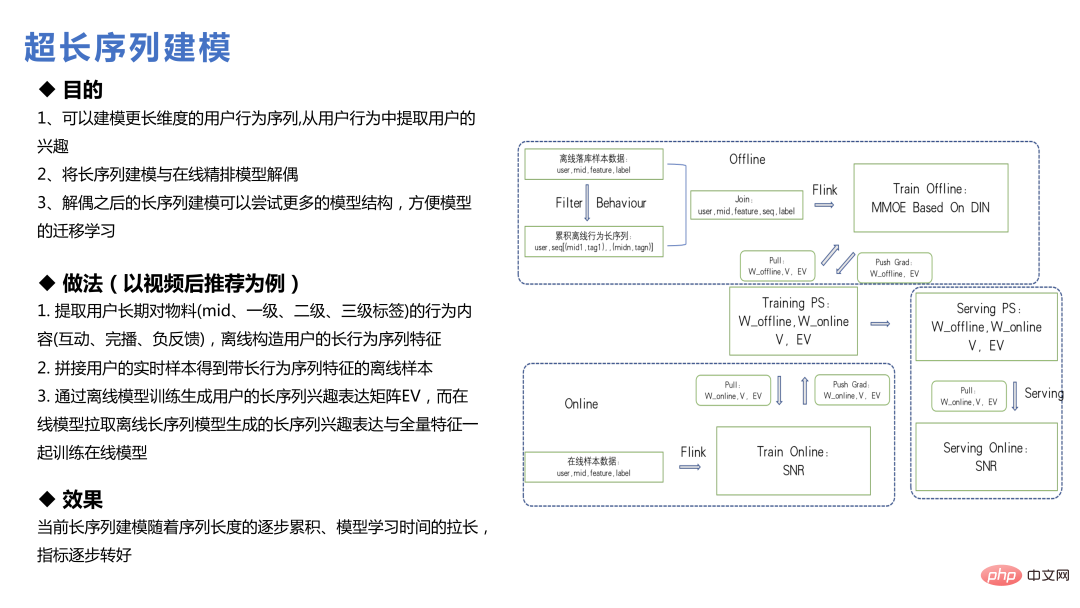
La modélisation de séquences ultra-longues du cycle de vie de l'utilisateur est différente de la modélisation de séquences longues précédente, non Les données peuvent être extraites en demandant des fonctionnalités, mais les fonctionnalités de séquence de comportement longue de l'utilisateur sont construites hors ligne ; ou les fonctionnalités correspondantes sont trouvées via certaines méthodes de recherche, puis l'intégration est générée ou le modèle principal et le modèle de séquence ultra-longue sont modélisés séparément ; , et enfin l'intégration est formée et envoyée au modèle principal.
Dans le business Weibo, la valeur des très longues séquences n'est pas si grande, car les préoccupations de chacun changent vite sur Internet. Par exemple, les éléments recherchés disparaîtront progressivement en un jour ou deux, tandis que les éléments du flux d'informations d'il y a sept jours seront distribués moins fréquemment. Par conséquent, une séquence de comportement utilisateur trop longue affaiblira dans une certaine mesure la valeur estimée de la préférence de l’utilisateur pour l’élément. Mais pour les utilisateurs peu fréquents ou récurrents, cette conclusion est dans une certaine mesure différente.
5, Caractéristiques#🎜🎜 #
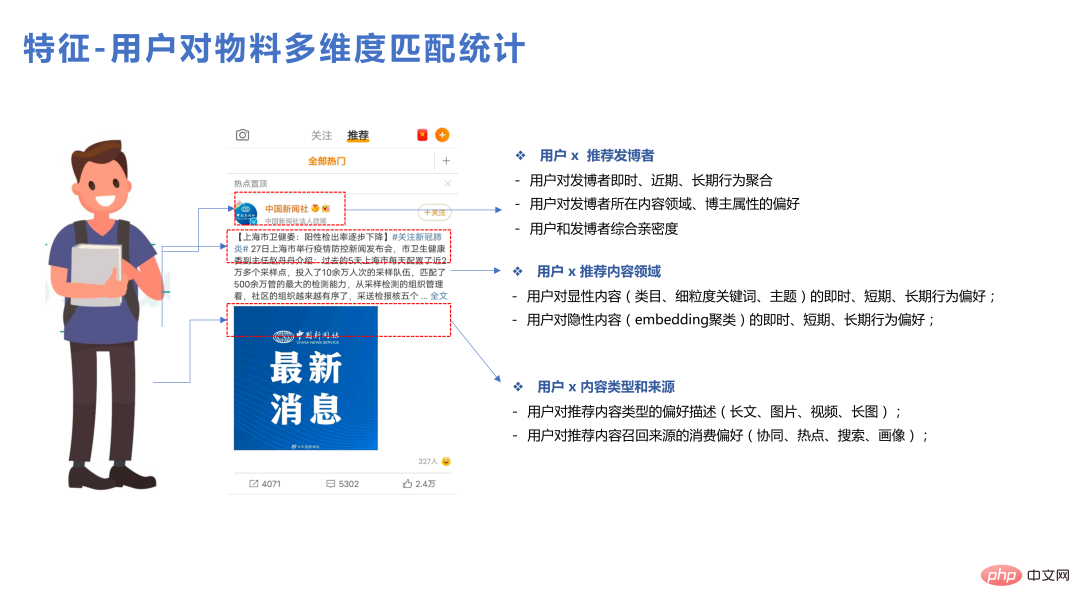
L'utilisation de modèles à très grande échelle posera également quelques problèmes au niveau des fonctionnalités. Par exemple, certaines fonctionnalités sont théoriquement considérées comme utiles au modèle, mais l'effet après leur ajout ne peut pas répondre aux attentes. C'est également la réalité à laquelle est confronté le secteur de la recommandation. Étant donné que l'échelle du modèle est très grande, de nombreuses informations sur la classe d'identification ont été ajoutées au modèle, ce qui a déjà donné une bonne expression à certaines préférences de l'utilisateur. L'ajout de certaines fonctionnalités statistiques à ce stade n'est peut-être pas si facile à utiliser. Parlons de cette équipe Des fonctionnalités relativement simples à utiliser en pratique.
Tout d'abord, les effets des fonctionnalités de correspondance sont relativement bons. Les utilisateurs peuvent établir des comparaisons pour un seul matériau, un seul type de contenu. , et un seul blogueur. Des données statistiques détaillées peuvent apporter certains avantages.
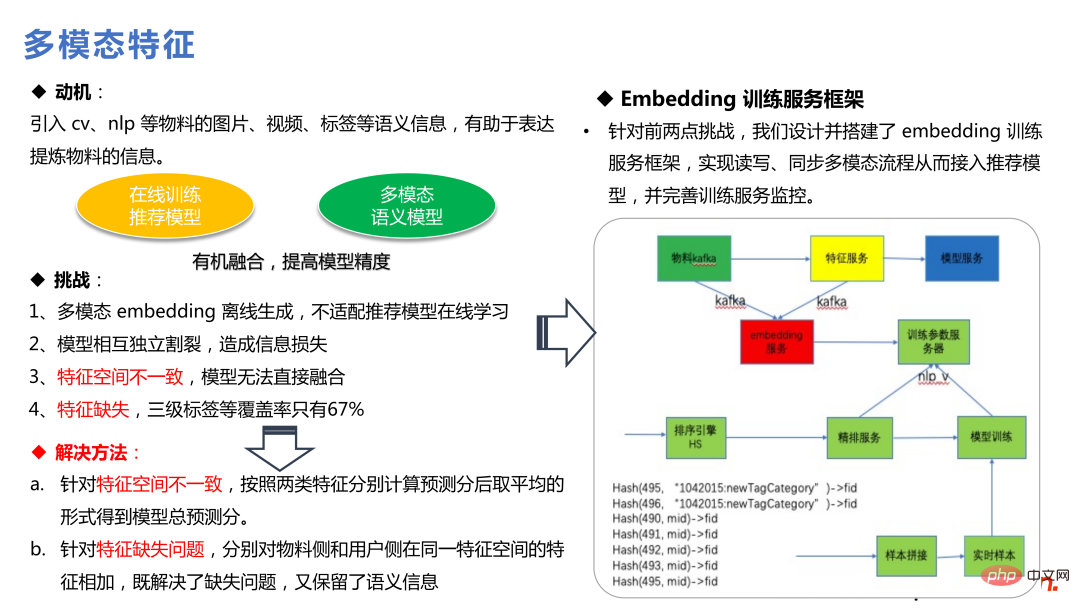
Après l'ajout de fonctionnalités multimodales, le plus grand avantage est la haute qualité. un matériau à faible exposition peut résoudre le problème du démarrage à froid. La recommandation de matériaux relativement peu exposés, que le modèle ne peut pas pleinement apprendre, s'appuiera fortement sur des organismes multimodaux pour apporter plus d'informations, ce qui a également une valeur positive pour l'écologie commerciale.

La co-action est motivée par : J'ai essayé en vain deepfm, Wide Deep et d'autres méthodes de croisement de fonctionnalités. On soupçonne que la fonctionnalité croisée entre en conflit avec l'intégration partagée partielle de DNN. La co-action équivaut à ajouter du stockage et à ouvrir un espace de stockage séparé pour le cross-over. Cela augmente l'espace d'expression et génère également de bons bénéfices dans l'entreprise.

3. Cohérence de l'expression du lien
Cette partie concerne le tri approximatif et le rappel. Pour le secteur des recommandations, bien que la puissance de calcul ne puisse pas prendre en charge le tri fin de millions d'ensembles de candidats et qu'ils soient divisés en rappel, tri grossier et tri fin, la logique est la même. Par exemple, comme le montre la figure ci-dessous, le tri grossier sera tronqué et le contenu final du tri fin ne sera que d'environ 1 000. Si les expressions du tri grossier et du tri fin sont significativement différentes, le score du tri fin sera probablement plus élevé. à l'avenir lors du processus de troncature. Le contenu est tronqué. Les caractéristiques et les structures de modèle du tri fin et du tri grossier sont généralement similaires au cadre de rappel, qui est une structure approximative de récupération vectorielle. Les caractéristiques se croiseront plus tard, et il est naturel que les différences d'expression avec le tri fin soient observées. modèle à apparaître. Si la cohérence peut être améliorée, les indicateurs commerciaux augmenteront également car les deux parties peuvent capter les mêmes tendances changeantes.
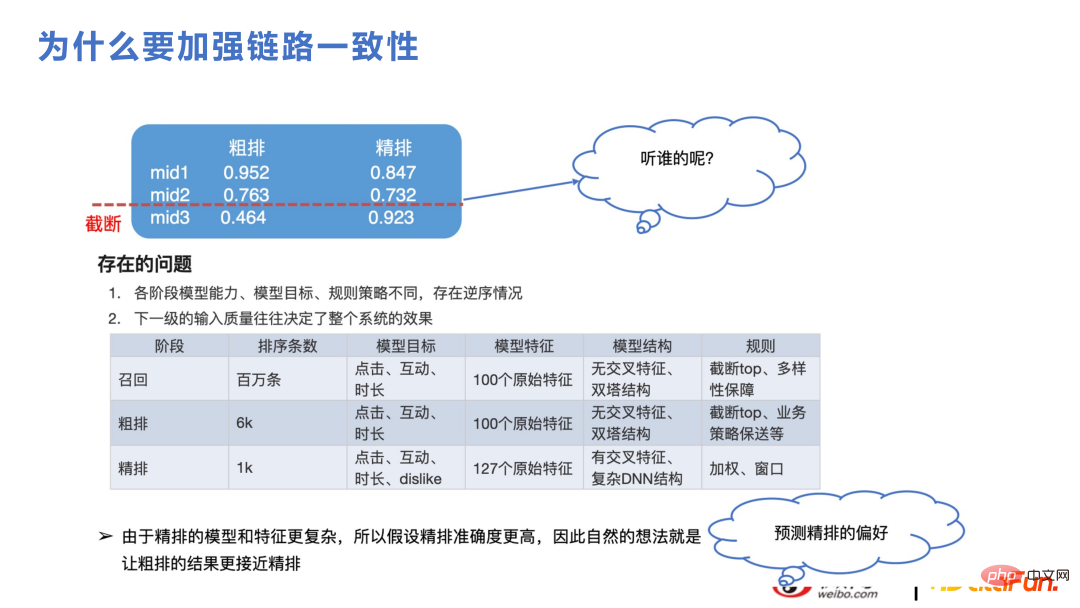
La figure suivante montre le contexte technique dans le processus d'itération de cohérence approximative. Le haut est la ligne technique des Twin Towers et le bas est la ligne technique de DNN. Étant donné que les caractéristiques des Twin Towers interagissent relativement tard, de nombreuses façons de se croiser ont été ajoutées. Cependant, le plafond de la méthode de récupération vectorielle est un peu trop bas, donc à partir de 2022, il y aura une branche DNN pour le tri grossier, ce qui exercera une plus grande pression sur l'architecture d'ingénierie, comme le filtrage des fonctionnalités, l'élagage du réseau, l'optimisation des performances. , etc., et Le nombre d'éléments notés en même temps sera également réduit qu'auparavant, mais les scores sont meilleurs, donc un plus petit nombre d'éléments est acceptable.
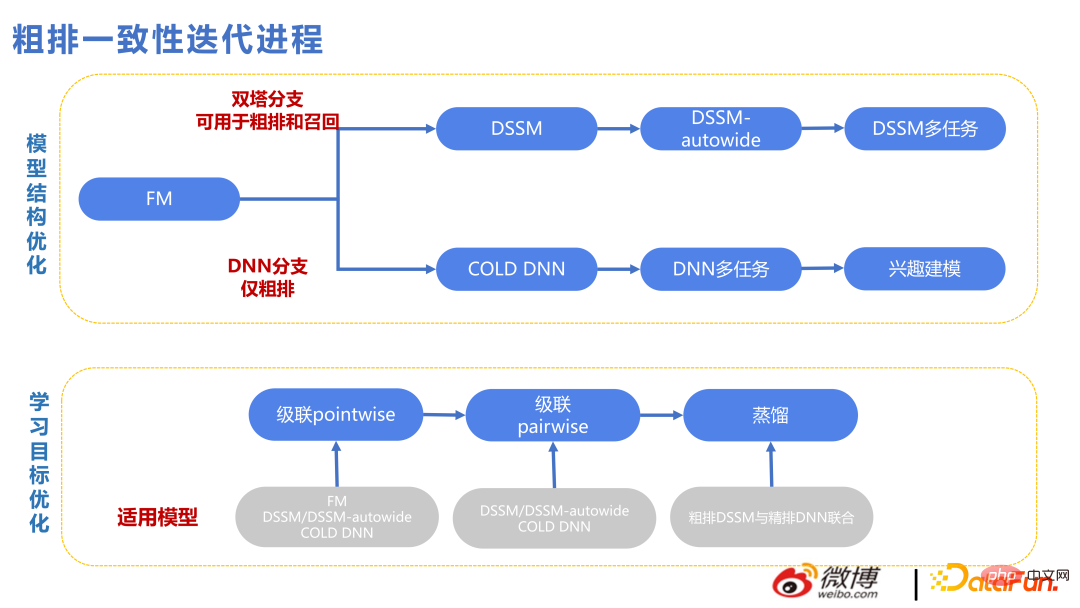
DSSM-autowide est un crossover similaire à Deep-FM basé sur Twin Towers, qui a entraîné une augmentation des indicateurs commerciaux. Cependant, pour le prochain projet, en utilisant une nouvelle méthode de crossover, il n'y aura pas d'amélioration.
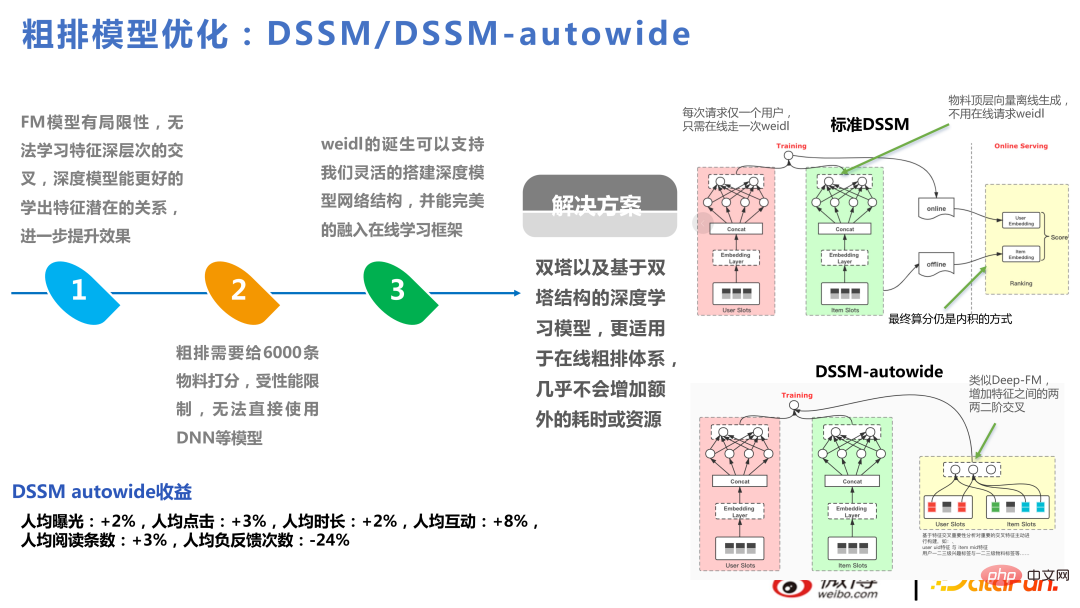
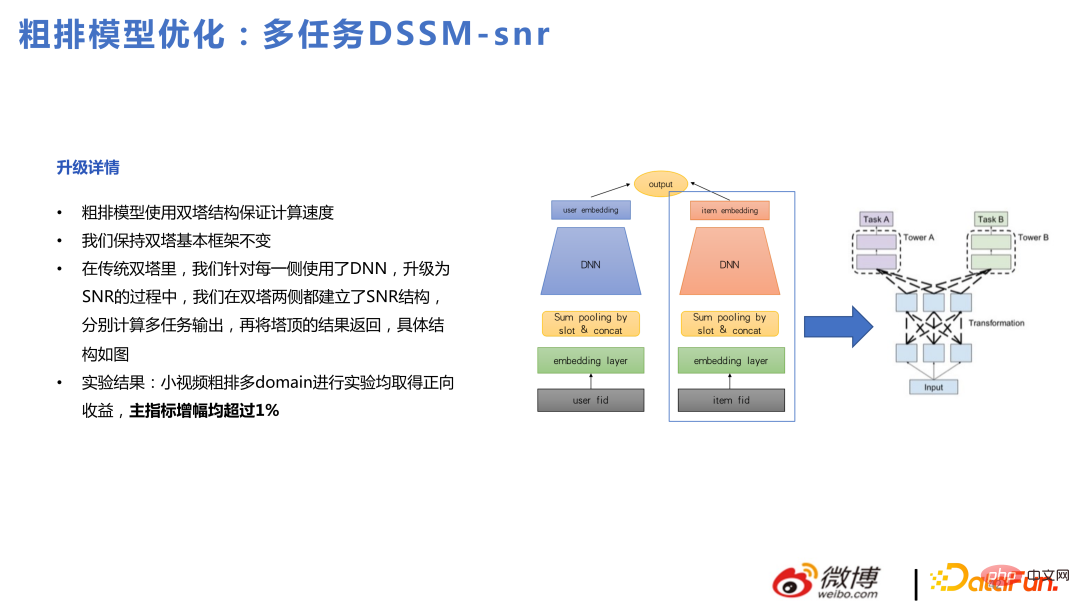
Par conséquent, nous estimons que les bénéfices qui peuvent être tirés des tours jumelles sont relativement limités. Nous avons également essayé un modèle multitâche approximatif basé sur les tours jumelles, mais nous n'avons toujours pas réussi à résoudre le problème des tours jumelles.
Sur la base des problèmes ci-dessus, notre équipe a optimisé le modèle de tri grossier et a utilisé des modèles DNN et en cascade pour créer une architecture d'empilement.
Le modèle en cascade peut être filtré d'abord avec Twin Towers, puis filtré et tronqué au modèle DNN pour un tri grossier, ce qui équivaut à effectuer un tri grossier et un tri fin à l'intérieur du tri grossier. Après le passage à un modèle DNN, il peut prendre en charge des structures plus complexes et s'adapter plus rapidement aux changements d'intérêts des utilisateurs.
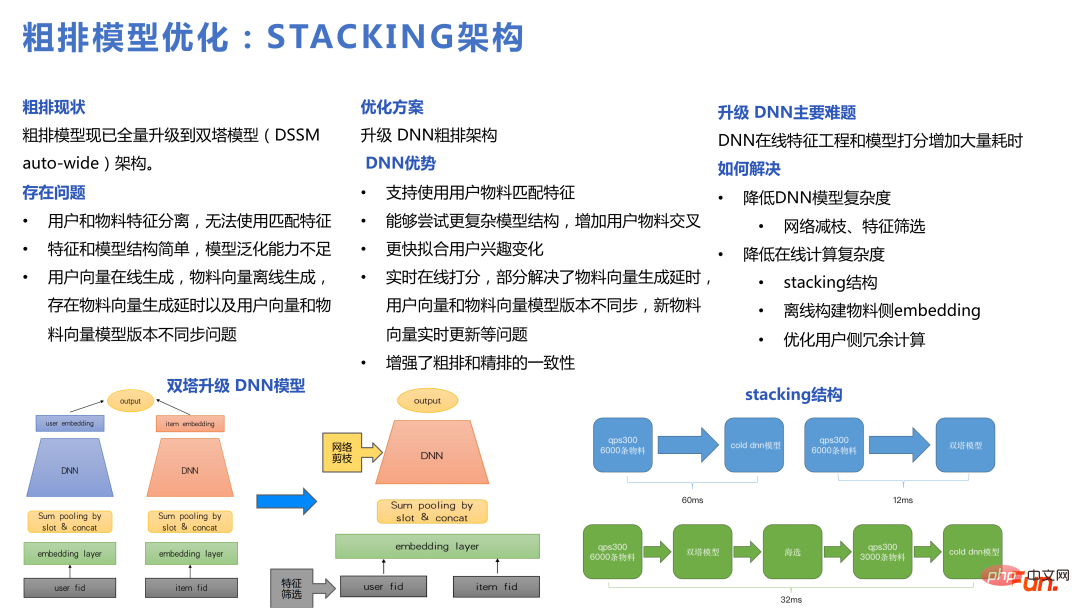
La cascade joue un rôle plus important dans le cadre, s'il n'y a pas de modèle de cascade, il est difficile de sélectionner un petit ensemble de candidats parmi un ensemble de candidats relativement grand pour un DNN approximatif à utiliser. La chose la plus importante dans la cascade est de savoir comment construire l'échantillon. Vous pouvez voir la figure ci-dessous. Dans la bibliothèque de matériaux au niveau d'un million, nous avons rappelé des milliers de matériaux triés grossièrement et finement sur un millier. Enfin, environ 20 éléments ont été exposés, et le nombre d'actions des utilisateurs était à un chiffre. Le processus global était plus important. bibliothèque à l’utilisateur. Lors de la réalisation d'une cascade, l'essentiel est que chaque partie doit être échantillonnée pour former des paires difficiles et des paires relativement simples à apprendre du modèle en cascade.
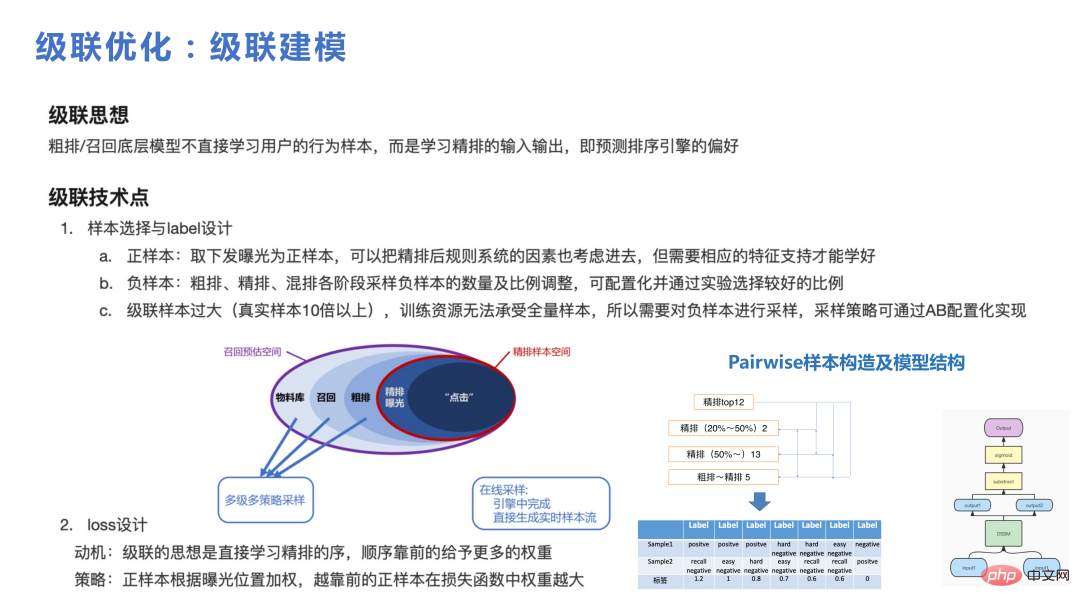
La figure suivante montre les avantages apportés par l'optimisation en cascade et l'échantillonnage négatif global, qui ne seront pas présentés en détail ici.
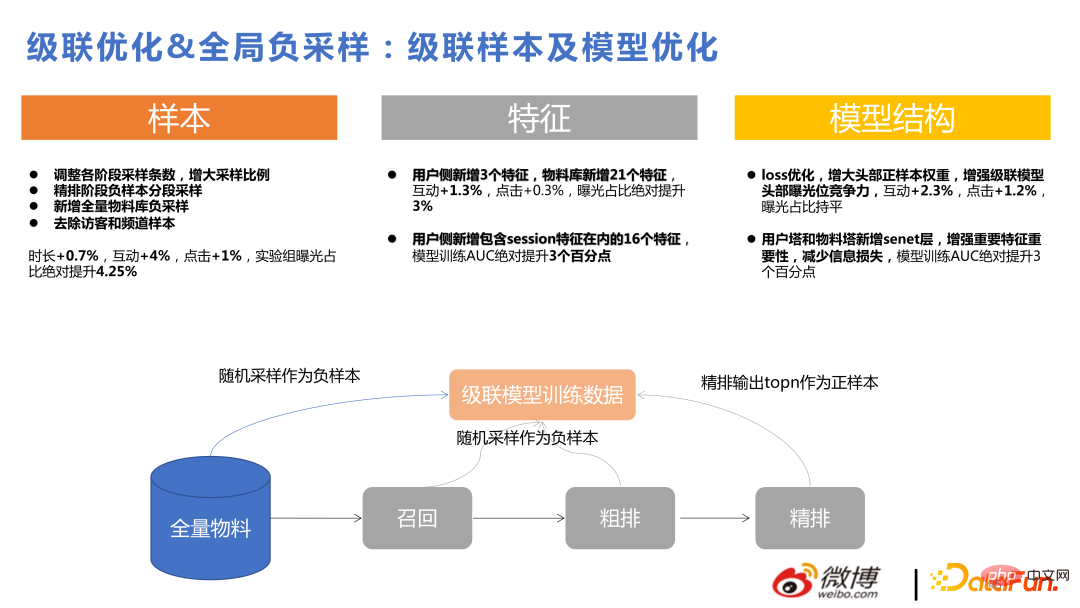
Ce qui suit présente la récente inférence causale populaire.
Notre motivation pour utiliser l'inférence causale est de pousser quelque chose aux utilisateurs. Si nous proposons quelque chose que tout le monde aime, l'effet de clic de l'utilisateur le fera. Ce n'est pas mal, mais les utilisateurs eux-mêmes ont également des intérêts relativement spécialisés. Si vous recommandez ces matériaux de niche aux utilisateurs, les utilisateurs les apprécieront également davantage. Ces deux choses sont les mêmes pour les utilisateurs, mais pour la plate-forme, plus les choses de niche qui peuvent être introduites sont plus personnalisées, et le premier type est plus facile à dériver par le modèle. L'inférence causale est de résoudre ce genre de problème. .
La méthode spécifique consiste à regrouper des paires d'échantillons par paires, les matériaux sur lesquels les utilisateurs cliquent et qui ont une faible popularité, et les matériaux qui sont hautement populaire mais utilisateurs Pour les matériaux non cliqués, la méthode bayésienne est utilisée pour entraîner le modèle de perte.
Dans notre pratique, l'inférence causale est plus facile à obtenir lorsqu'elle est effectuée dans les étapes de tri grossier et de rappel que dans la phase de tri fin. La raison en est que le modèle de classement fin est relativement complexe. Cependant, même si le classement approximatif et le rappel utilisent des DNN, il existe encore des lacunes dans la capacité de personnalisation de l'ensemble du modèle. La capacité de personnalisation est relativement faible. L'effet de l'utilisation de l'inférence causale dans des endroits dotés de fortes capacités de personnalisation est nettement plus évident que de son utilisation dans des endroits dotés de fortes capacités de personnalisation.
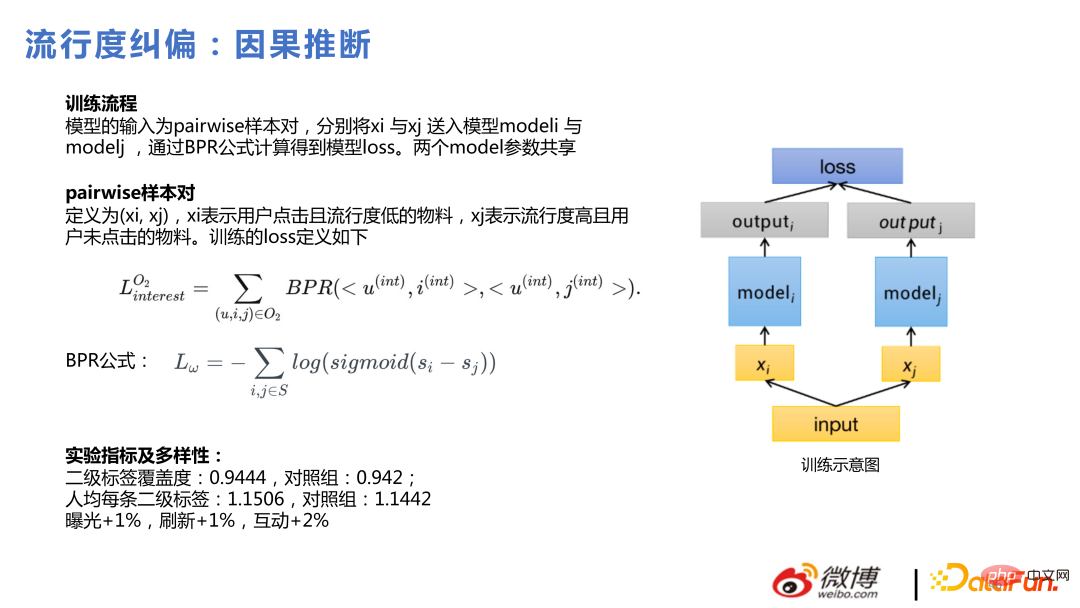
4. Autres points techniques# 🎜🎜#
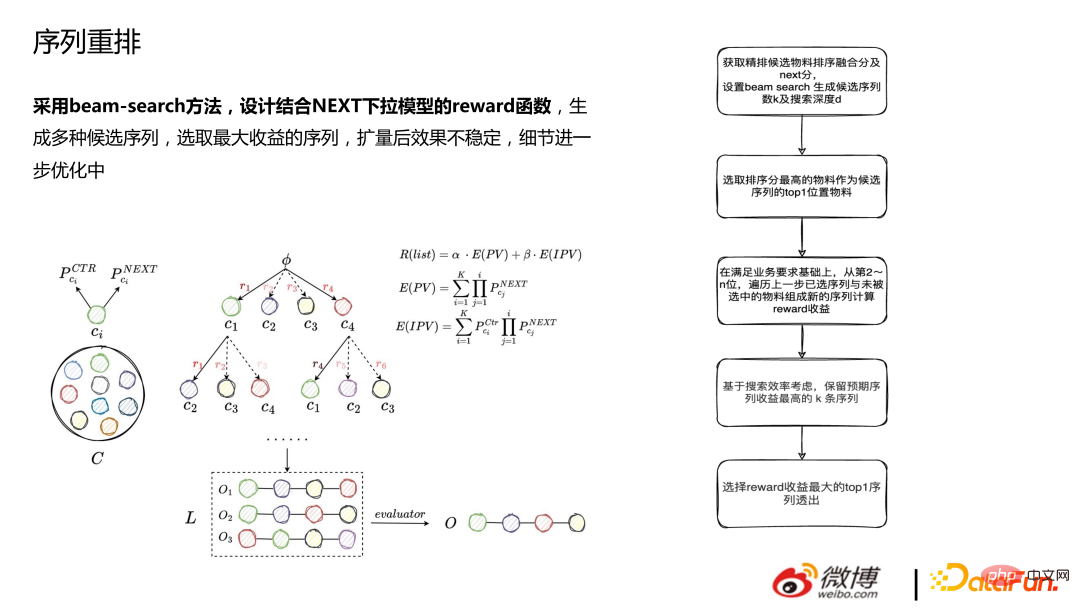
1. Réarrangement de séquence
Le réarrangement utilise la méthode de recherche de faisceau et est conçu pour se combiner avec le Modèle déroulant NEXT La fonction de récompense génère plusieurs séquences candidates et sélectionne la séquence avec le plus grand profit. L'effet est instable après l'expansion et les détails sont encore optimisés.
La technologie graphique comprend principalement deux parties : la base de données graphique et l'intégration de graphiques. Pour les recommandations, il sera plus pratique et moins coûteux d'utiliser une base de données graphiques. L'intégration de graphiques fait référence au processus de marche aléatoire des nœuds de la classe de marche, mappant les données graphiques (généralement des matrices denses de haute dimension) en vecteurs denses de basse dimension. L'intégration de graphiques doit capturer la structure topologique du graphe, la relation entre les sommets et d'autres informations (telles que les sous-graphes, les arêtes, etc.), qui ne seront pas
présentées ici.
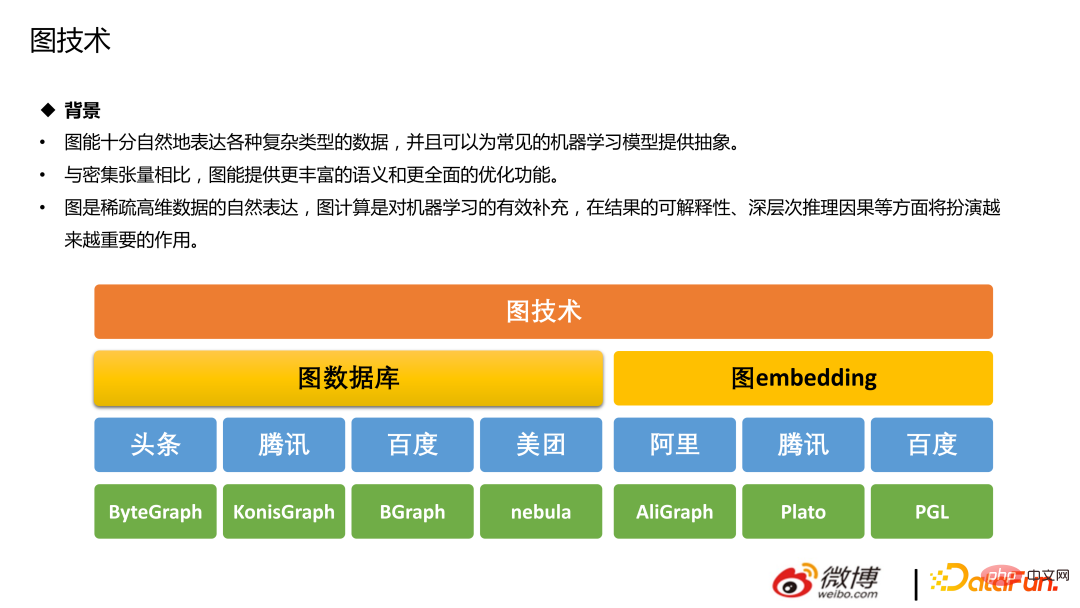
peut être utilisé dans des recommandations basées sur une marche aléatoire, une structure graphique et comparaison de graphiques Apprenez des algorithmes et rappelez les interactions/attention entre les utilisateurs et les articles de blog, les utilisateurs et les auteurs. La méthode courante consiste à intégrer des images, du texte, des utilisateurs, etc., et à ajouter des fonctionnalités au modèle. Il existe également des tentatives plus avancées, telles que la construction directe d'un réseau de bout en bout et l'utilisation de GNN pour les recommandations.
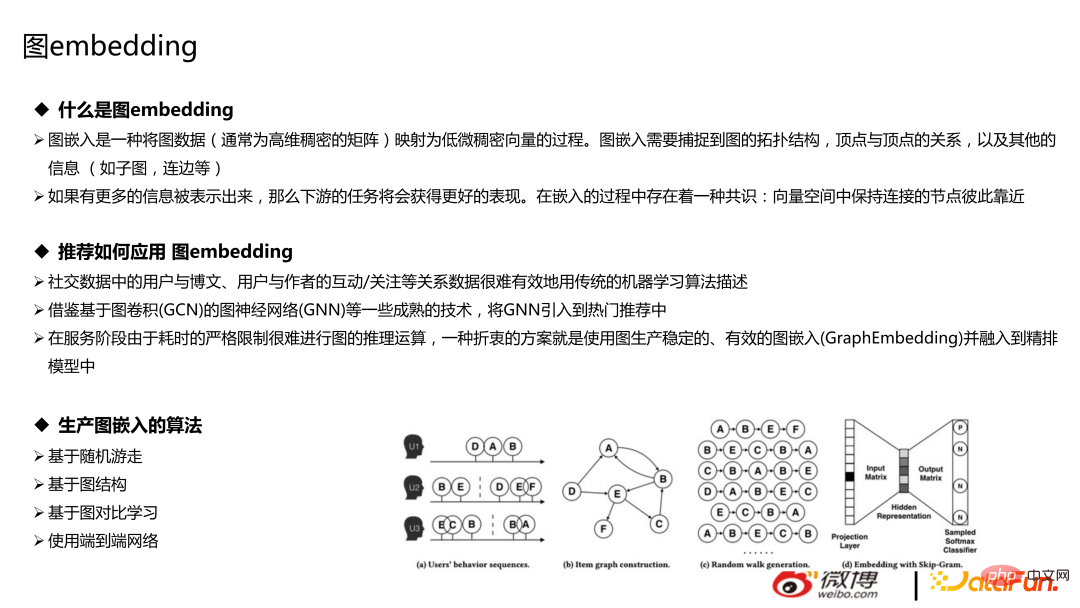
La photo ci-dessous est la photo actuelle arrivée Nous expérimentons encore le modèle de terminal, et ce n'est pas la version en ligne grand public.
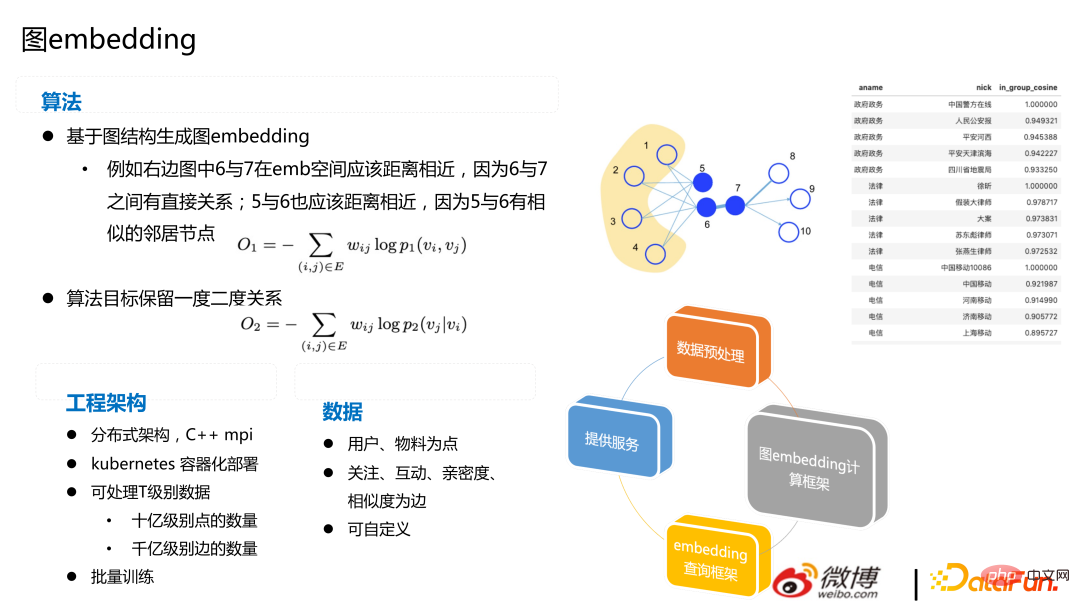
L'image suivante est basée sur le réseau graphique Générer l'intégration. L'image de droite montre la similarité calculée en fonction du domaine du compte. Pour Weibo, il est rentable de calculer l’intégration en fonction de la relation d’attention.
5. Session de questions-réponses
Q1 : Il existe de nombreux éléments dans le flux d'informations recommandé, mais vous ne parcourez que sans cliquer. Comment distinguer si. tu es intéressé ou pas ? Pendant le temps de séjour de l'élément sur la page de liste ?
A1 : Oui, en parlant de flux d'informations, la durée est un indicateur d'optimisation plus important. Il n'est pas pratique d'optimiser directement la durée pendant laquelle les utilisateurs restent sur l'APP dans son ensemble aujourd'hui en utilisant des indicateurs d'optimisation de durée. Ce qui est plus optimisé, c'est la durée pendant laquelle les utilisateurs restent sur les éléments. Si vous ne considérez pas la durée comme un objectif d’optimisation, il sera plus facile de promouvoir de nombreux contenus de consommation superficielle.
Q2 : Y aura-t-il des problèmes de cohérence dans la mise à jour en temps réel du modèle si un basculement se produit pendant la formation ? Comment gérer les problèmes de cohérence des modèles ?
A2 : Actuellement, pour l'apprentissage et la formation recommandés, s'il s'agit d'un CPU, il y en a plus asynchrones, et il est difficile pour tout le monde de faites en sorte que la situation globale soit claire. Après chaque tour, rassemblez-les, mettez-les à jour sur PS, puis lancez le tour suivant. En raison de problèmes de performances, les gens ne le feront pratiquement pas. Qu’il s’agisse d’un apprentissage en temps réel ou en ligne, une forte cohérence ne peut pas être obtenue.
Si un basculement survient pendant votre formation, s'il s'agit d'une formation en streaming, il sera enregistré sur le flux de données, comme par exemple kafka ou flink pour enregistrer la position de votre plan d'entraînement actuel. Votre ps possède également l'enregistrement de votre dernier entraînement, ce qui est similaire à la différence globale.
Q3 : L'utilisation du tri fin pour le rappel réduira-t-elle la limite d'itération du modèle de rappel ?
A3 : La limite supérieure de l'itération est provisoirement comprise comme le plafond de rappel. Ensuite, je comprends que le plafond de rappel ne doit absolument pas dépasser l'amende. classement Par exemple, si cela compte Si le pouvoir est désormais illimité, alors utiliser le tri fin pour marquer 5 millions de matériaux est la meilleure façon de gérer l'entreprise. Lorsque l'investissement dans le rappel n'est pas si important, essayez de trouver les meilleures pièces pour l'expert. Par exemple, laissez-le sélectionner le top 15 parmi les 6 000 du rappel et le top 15 parmi les 5 millions, ce qui est relativement proche. . Le module de rappel fait un meilleur travail. Si tout le monde comprend cela, alors rappeler l'ordre de tri fin ne réduira pas l'itération en ligne, mais se déplacera vers la limite supérieure. Cependant, c'est également notre avis. En fonction de votre propre orientation commerciale, cette conclusion peut ne pas être universellement applicable.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 L'application de grands modèles Tencent Yuanbao est en ligne ! Hunyuan est mis à niveau pour créer un assistant IA complet pouvant être transporté n'importe où
Jun 09, 2024 pm 10:38 PM
L'application de grands modèles Tencent Yuanbao est en ligne ! Hunyuan est mis à niveau pour créer un assistant IA complet pouvant être transporté n'importe où
Jun 09, 2024 pm 10:38 PM
Le 30 mai, Tencent a annoncé une mise à niveau complète de son modèle Hunyuan. L'application « Tencent Yuanbao » basée sur le modèle Hunyuan a été officiellement lancée et peut être téléchargée sur les magasins d'applications Apple et Android. Par rapport à la version de l'applet Hunyuan lors de la phase de test précédente, Tencent Yuanbao fournit des fonctionnalités de base telles que la recherche IA, le résumé IA et l'écriture IA pour les scénarios d'efficacité du travail ; pour les scénarios de la vie quotidienne, le gameplay de Yuanbao est également plus riche et fournit de multiples fonctionnalités d'application IA. , et de nouvelles méthodes de jeu telles que la création d'agents personnels sont ajoutées. « Tencent ne s'efforcera pas d'être le premier à créer un grand modèle. » Liu Yuhong, vice-président de Tencent Cloud et responsable du grand modèle Tencent Hunyuan, a déclaré : « Au cours de l'année écoulée, nous avons continué à promouvoir les capacités de Tencent. Grand modèle Tencent Hunyuan. Dans la technologie polonaise riche et massive dans des scénarios commerciaux tout en obtenant un aperçu des besoins réels des utilisateurs.
 Lancement du grand modèle Bytedance Beanbao, le service d'IA complet Volcano Engine aide les entreprises à se transformer intelligemment
Jun 05, 2024 pm 07:59 PM
Lancement du grand modèle Bytedance Beanbao, le service d'IA complet Volcano Engine aide les entreprises à se transformer intelligemment
Jun 05, 2024 pm 07:59 PM
Tan Dai, président de Volcano Engine, a déclaré que les entreprises qui souhaitent bien mettre en œuvre de grands modèles sont confrontées à trois défis clés : l'effet de modèle, le coût d'inférence et la difficulté de mise en œuvre : elles doivent disposer d'un bon support de base de grands modèles pour résoudre des problèmes complexes, et elles doivent également avoir une inférence à faible coût. Les services permettent d'utiliser largement de grands modèles, et davantage d'outils, de plates-formes et d'applications sont nécessaires pour aider les entreprises à mettre en œuvre des scénarios. ——Tan Dai, président de Huoshan Engine 01. Le grand modèle de pouf fait ses débuts et est largement utilisé. Le polissage de l'effet de modèle est le défi le plus critique pour la mise en œuvre de l'IA. Tan Dai a souligné que ce n'est que grâce à une utilisation intensive qu'un bon modèle peut être poli. Actuellement, le modèle Doubao traite 120 milliards de jetons de texte et génère 30 millions d'images chaque jour. Afin d'aider les entreprises à mettre en œuvre des scénarios de modèles à grande échelle, le modèle à grande échelle beanbao développé indépendamment par ByteDance sera lancé à travers le volcan.
 Cet article vous amènera à comprendre SHAP : explication du modèle pour l'apprentissage automatique
Jun 01, 2024 am 10:58 AM
Cet article vous amènera à comprendre SHAP : explication du modèle pour l'apprentissage automatique
Jun 01, 2024 am 10:58 AM
Dans les domaines de l’apprentissage automatique et de la science des données, l’interprétabilité des modèles a toujours été au centre des préoccupations des chercheurs et des praticiens. Avec l'application généralisée de modèles complexes tels que l'apprentissage profond et les méthodes d'ensemble, la compréhension du processus décisionnel du modèle est devenue particulièrement importante. Explainable AI|XAI contribue à renforcer la confiance dans les modèles d'apprentissage automatique en augmentant la transparence du modèle. L'amélioration de la transparence des modèles peut être obtenue grâce à des méthodes telles que l'utilisation généralisée de plusieurs modèles complexes, ainsi que les processus décisionnels utilisés pour expliquer les modèles. Ces méthodes incluent l'analyse de l'importance des caractéristiques, l'estimation de l'intervalle de prédiction du modèle, les algorithmes d'interprétabilité locale, etc. L'analyse de l'importance des fonctionnalités peut expliquer le processus de prise de décision du modèle en évaluant le degré d'influence du modèle sur les fonctionnalités d'entrée. Estimation de l’intervalle de prédiction du modèle
 Implémentation d'algorithmes d'apprentissage automatique en C++ : défis et solutions courants
Jun 03, 2024 pm 01:25 PM
Implémentation d'algorithmes d'apprentissage automatique en C++ : défis et solutions courants
Jun 03, 2024 pm 01:25 PM
Les défis courants rencontrés par les algorithmes d'apprentissage automatique en C++ incluent la gestion de la mémoire, le multithread, l'optimisation des performances et la maintenabilité. Les solutions incluent l'utilisation de pointeurs intelligents, de bibliothèques de threads modernes, d'instructions SIMD et de bibliothèques tierces, ainsi que le respect des directives de style de codage et l'utilisation d'outils d'automatisation. Des cas pratiques montrent comment utiliser la bibliothèque Eigen pour implémenter des algorithmes de régression linéaire, gérer efficacement la mémoire et utiliser des opérations matricielles hautes performances.
 Pratique avancée du graphe de connaissances industrielles
Jun 13, 2024 am 11:59 AM
Pratique avancée du graphe de connaissances industrielles
Jun 13, 2024 am 11:59 AM
1. Introduction au contexte Tout d’abord, présentons l’historique du développement de la technologie Yunwen. Yunwen Technology Company... 2023 est la période où les grands modèles prédominent. De nombreuses entreprises pensent que l'importance des graphiques a été considérablement réduite après les grands modèles et que les systèmes d'information prédéfinis étudiés précédemment ne sont plus importants. Cependant, avec la promotion du RAG et la prévalence de la gouvernance des données, nous avons constaté qu'une gouvernance des données plus efficace et des données de haute qualité sont des conditions préalables importantes pour améliorer l'efficacité des grands modèles privatisés. Par conséquent, de plus en plus d'entreprises commencent à y prêter attention. au contenu lié à la construction des connaissances. Cela favorise également la construction et le traitement des connaissances à un niveau supérieur, où de nombreuses techniques et méthodes peuvent être explorées. On voit que l'émergence d'une nouvelle technologie ne détruit pas toutes les anciennes technologies, mais peut également intégrer des technologies nouvelles et anciennes.
 Xiaomi Byte unit ses forces ! Un grand modèle de l'accès de Xiao Ai à Doubao : déjà installé sur les téléphones mobiles et SU7
Jun 13, 2024 pm 05:11 PM
Xiaomi Byte unit ses forces ! Un grand modèle de l'accès de Xiao Ai à Doubao : déjà installé sur les téléphones mobiles et SU7
Jun 13, 2024 pm 05:11 PM
Selon les informations du 13 juin, selon le compte public « Volcano Engine » de Byte, l'assistant d'intelligence artificielle de Xiaomi « Xiao Ai » a conclu une coopération avec Volcano Engine. Les deux parties réaliseront une expérience interactive d'IA plus intelligente basée sur le grand modèle beanbao. . Il est rapporté que le modèle beanbao à grande échelle créé par ByteDance peut traiter efficacement jusqu'à 120 milliards de jetons de texte et générer 30 millions de contenus chaque jour. Xiaomi a utilisé le grand modèle Doubao pour améliorer les capacités d'apprentissage et de raisonnement de son propre modèle et créer un nouveau « Xiao Ai Classmate », qui non seulement saisit plus précisément les besoins des utilisateurs, mais offre également une vitesse de réponse plus rapide et des services de contenu plus complets. Par exemple, lorsqu'un utilisateur pose une question sur un concept scientifique complexe, &ldq
 IA explicable : Expliquer les modèles IA/ML complexes
Jun 03, 2024 pm 10:08 PM
IA explicable : Expliquer les modèles IA/ML complexes
Jun 03, 2024 pm 10:08 PM
Traducteur | Revu par Li Rui | Chonglou Les modèles d'intelligence artificielle (IA) et d'apprentissage automatique (ML) deviennent aujourd'hui de plus en plus complexes, et le résultat produit par ces modèles est une boîte noire – impossible à expliquer aux parties prenantes. L'IA explicable (XAI) vise à résoudre ce problème en permettant aux parties prenantes de comprendre comment fonctionnent ces modèles, en s'assurant qu'elles comprennent comment ces modèles prennent réellement des décisions et en garantissant la transparence des systèmes d'IA, la confiance et la responsabilité pour résoudre ce problème. Cet article explore diverses techniques d'intelligence artificielle explicable (XAI) pour illustrer leurs principes sous-jacents. Plusieurs raisons pour lesquelles l’IA explicable est cruciale Confiance et transparence : pour que les systèmes d’IA soient largement acceptés et fiables, les utilisateurs doivent comprendre comment les décisions sont prises
 Afin de fournir un nouveau système de référence et d'évaluation de questions-réponses scientifiques et complexes pour les grands modèles, l'UNSW, Argonne, l'Université de Chicago et d'autres institutions ont lancé conjointement le cadre SciQAG.
Jul 25, 2024 am 06:42 AM
Afin de fournir un nouveau système de référence et d'évaluation de questions-réponses scientifiques et complexes pour les grands modèles, l'UNSW, Argonne, l'Université de Chicago et d'autres institutions ont lancé conjointement le cadre SciQAG.
Jul 25, 2024 am 06:42 AM
L'ensemble de données ScienceAI Question Answering (QA) joue un rôle essentiel dans la promotion de la recherche sur le traitement du langage naturel (NLP). Des ensembles de données d'assurance qualité de haute qualité peuvent non seulement être utilisés pour affiner les modèles, mais également évaluer efficacement les capacités des grands modèles linguistiques (LLM), en particulier la capacité à comprendre et à raisonner sur les connaissances scientifiques. Bien qu’il existe actuellement de nombreux ensembles de données scientifiques d’assurance qualité couvrant la médecine, la chimie, la biologie et d’autres domaines, ces ensembles de données présentent encore certaines lacunes. Premièrement, le formulaire de données est relativement simple, et la plupart sont des questions à choix multiples. Elles sont faciles à évaluer, mais limitent la plage de sélection des réponses du modèle et ne peuvent pas tester pleinement la capacité du modèle à répondre aux questions scientifiques. En revanche, les questions et réponses ouvertes
