

JMM est un modèle de mémoire Java. Étant donné qu'il existe certaines différences dans l'accès à la mémoire selon les fabricants de matériel et les systèmes d'exploitation, divers problèmes peuvent survenir lorsque le même code s'exécute sur différents systèmes. Par conséquent, le modèle de mémoire Java (JMM) protège les différences d'accès à la mémoire de divers matériels et systèmes d'exploitation afin d'obtenir des effets de concurrence cohérents pour les programmes Java sur diverses plates-formes.
Le modèle de mémoire Java stipule que toutes les variables sont stockées dans la mémoire principale, y compris les variables d'instance et les variables statiques, mais n'inclut pas les variables locales et les paramètres de méthode. Chaque thread possède sa propre mémoire de travail. La mémoire de travail du thread stocke les variables utilisées par le thread et une copie de la mémoire principale. Les opérations du thread sur les variables sont toutes effectuées dans la mémoire de travail. Les threads ne peuvent pas lire ou écrire directement des variables dans la mémoire principale.
Différents threads ne peuvent pas accéder aux variables dans la mémoire de travail de chacun. Le transfert des valeurs des variables entre les threads doit être effectué via la mémoire principale.
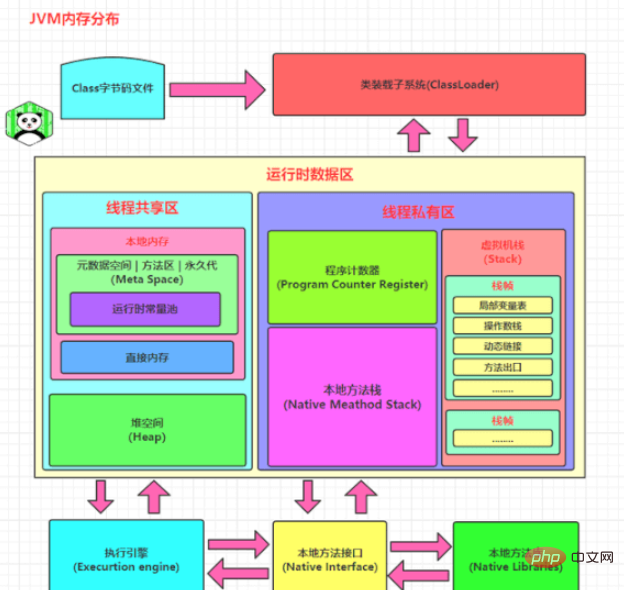
La mémoire de travail de chaque thread est indépendante. Les données d'opération de thread ne peuvent être effectuées que dans la mémoire de travail, puis renvoyées dans la mémoire principale. Il s'agit du fonctionnement de base des threads, tel que défini par le modèle de mémoire Java.
Un rappel chaleureux, certaines personnes ici comprendront mal le modèle de mémoire Java en tant que structure de mémoire Java, puis répondront au tas, à la pile, au garbage collection GC, et finalement c'est loin de la question que l'intervieweur veut poser. En fait, lorsqu'on les interroge sur le modèle de mémoire Java, ils souhaitent généralement poser des questions liées au multithreading et à la concurrence Java.
C'est simple L'ensemble du modèle de mémoire Java est en fait construit autour de trois caractéristiques. Ce sont : l’atomicité, la visibilité et l’ordre. Ces trois caractéristiques peuvent être considérées comme le fondement de toute la concurrence Java.
Atomicité signifie qu'une opération est indivisible et ininterruptible, et qu'un thread ne sera pas interféré par d'autres threads pendant l'exécution.
L'intervieweur a pris un stylo et a écrit un morceau de code Les lignes de code suivantes peuvent-elles garantir l'atomicité ?
int i = 2; int j = i; i++; i = i + 1;
La première phrase est une opération d'affectation de type de base, qui doit être une opération atomique.
La deuxième phrase lit d'abord la valeur de i, puis l'attribue à j. Cette opération en deux étapes ne peut pas garantir l'atomicité.
Les troisième et quatrième phrases sont en fait équivalentes. Lisez d'abord la valeur de i, puis +1, et enfin attribuez la valeur à i. Il s'agit d'une opération en trois étapes et ne peut garantir l'atomicité.
JMM ne peut garantir que l'atomicité de base. Si vous souhaitez garantir l'atomicité d'un bloc de code, il fournit deux instructions de bytecode, monitorenter et monitexit, qui sont le mot-clé synchronisé. Les opérations entre blocs synchronisés sont donc atomiques.
La visibilité signifie que lorsqu'un thread modifie la valeur d'une variable partagée, les autres threads peuvent immédiatement savoir qu'elle a été modifiée. Java utilise le mot-clé volatile pour assurer la visibilité. Lorsqu'une variable est modifiée de manière volatile, la variable sera vidée dans la mémoire principale immédiatement après avoir été modifiée. Lorsque d'autres threads auront besoin de lire la variable, ils liront la nouvelle valeur dans la mémoire principale. Les variables ordinaires ne peuvent pas garantir cela.
En plus du mot-clé volatile, final et synchronisé peuvent également obtenir de la visibilité.
Le principe de synchronisé est qu'une fois l'exécution terminée et avant d'entrer dans le déverrouillage, les variables partagées doivent être synchronisées avec la mémoire principale.
Les champs finaux modifiés, une fois l'initialisation terminée, seront visibles par les autres threads si aucun objet ne s'échappe (ce qui signifie que l'objet peut être utilisé par d'autres threads une fois l'initialisation terminée).
En Java, vous pouvez utiliser synchronisé ou volatile pour garantir l'ordre des opérations entre plusieurs threads. Il existe quelques différences dans les principes de mise en œuvre : Le mot-clé
volatile utilise des barrières de mémoire pour interdire la réorganisation des instructions afin de garantir l'ordre.
Le principe de synchronisé est qu'une fois qu'un thread est verrouillé, il doit être déverrouillé avant que les autres threads puissent se reverrouiller, afin que les blocs de code enveloppés dans synchronisé soient exécutés en série entre plusieurs threads.
Il existe 8 types d'opérations d'interaction mémoire :
lock (lock), qui agit sur les variables de la mémoire principale et marque les variables comme exclusives aux threads.
read (read), qui agit sur les variables de la mémoire principale et transfère la valeur de la variable de la mémoire principale à la mémoire de travail du thread pour une utilisation lors de la prochaine opération de chargement.
load (loading), agit sur les variables de la mémoire de travail, et place les variables de la mémoire principale de l'opération de lecture dans la copie variable de la mémoire de travail.
use (use), qui agit sur les variables de la mémoire de travail et transfère les variables de la mémoire de travail au moteur d'exécution. Cette opération sera effectuée chaque fois que la machine virtuelle rencontrera une instruction de bytecode qui doit utiliser la valeur de. la variable.
assign (affectation), qui agit sur une variable dans la mémoire de travail. Il attribue une valeur reçue du moteur d'exécution à une copie de la variable dans la mémoire de travail chaque fois que la machine virtuelle rencontre une instruction de bytecode qui attribue un. valeur à une variable Cette opération sera effectuée.
store (stockage), qui agit sur les variables de la mémoire de travail. Il transfère la valeur d'une variable de la mémoire de travail vers la mémoire principale pour une utilisation ultérieure en écriture.
write(写入):作用于主内存中的变量,它把store操作从工作内存中得到的变量的值放入主内存的变量中。
unlock(解锁):作用于主内存的变量,它把一个处于锁定状态的变量释放出来,释放后的变量才可以被其他线程锁定。
我再补充一下JMM对8种内存交互操作制定的规则吧:
不允许read、load、store、write操作之一单独出现,也就是read操作后必须load,store操作后必须write。
不允许线程丢弃他最近的assign操作,即工作内存中的变量数据改变了之后,必须告知主存。
不允许线程将没有assign的数据从工作内存同步到主内存。
一个新的变量必须在主内存中诞生,不允许工作内存直接使用一个未被初始化的变量。就是对变量实施use、store操作之前,必须经过load和assign操作。
一个变量同一时间只能有一个线程对其进行lock操作。多次lock之后,必须执行相同次数unlock才可以解锁。
如果对一个变量进行lock操作,会清空所有工作内存中此变量的值。在执行引擎使用这个变量前,必须重新load或assign操作初始化变量的值。
如果一个变量没有被lock,就不能对其进行unlock操作。也不能unlock一个被其他线程锁住的变量。
一个线程对一个变量进行unlock操作之前,必须先把此变量同步回主内存。
很多并发编程都使用了volatile关键字,主要的作用包括两点:
保证线程间变量的可见性。
禁止CPU进行指令重排序。
volatile修饰的变量,当一个线程改变了该变量的值,其他线程是立即可见的。普通变量则需要重新读取才能获得最新值。
volatile保证可见性的流程大概就是这个一个过程:
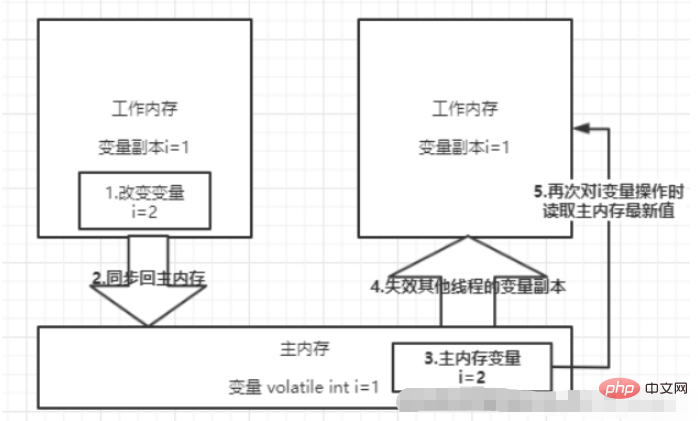
先说结论吧,volatile不能一定能保证线程安全。
怎么证明呢,我们看下面一段代码的运行结果就知道了:
public class VolatileTest extends Thread {
private static volatile int count = 0;
public static void main(String[] args) throws Exception {
Vector<Thread> threads = new Vector<>();
for (int i = 0; i < 100; i++) {
VolatileTest thread = new VolatileTest();
threads.add(thread);
thread.start();
}
//等待子线程全部完成
for (Thread thread : threads) {
thread.join();
}
//输出结果,正确结果应该是1000,实际却是984
System.out.println(count);//984
}
@Override
public void run() {
for (int i = 0; i < 10; i++) {
try {
//休眠500毫秒
Thread.sleep(500);
} catch (Exception e) {
e.printStackTrace();
}
count++;
}
}
}为什么volatile不能保证线程安全?
很简单呀,可见性不能保证操作的原子性,前面说过了count++不是原子性操作,会当做三步,先读取count的值,然后+1,最后赋值回去count变量。需要保证线程安全的话,需要使用synchronized关键字或者lock锁,给count++这段代码上锁:
private static synchronized void add() {
count++;
}首先要讲一下as-if-serial语义,不管怎么重排序,(单线程)程序的执行结果不能被改变。
为了使指令更加符合CPU的执行特性,最大限度的发挥机器的性能,提高程序的执行效率,只要程序的最终结果与它顺序化情况的结果相等,那么指令的执行顺序可以与代码逻辑顺序不一致,这个过程就叫做指令的重排序。
重排序的种类分为三种,分别是:编译器重排序,指令级并行的重排序,内存系统重排序。整个过程如下所示:

指令重排序在单线程是没有问题的,不会影响执行结果,而且还提高了性能。但是在多线程的环境下就不能保证一定不会影响执行结果了。
所以在多线程环境下,就需要禁止指令重排序。
volatile关键字禁止指令重排序有两层意思:
当程序执行到volatile变量的读操作或者写操作时,在其前面的操作的更改肯定全部已经进行,且结果已经对后面的操作可见,在其后面的操作肯定还没有进行。
在进行指令优化时,不能将在对volatile变量访问的语句放在其后面执行,也不能把volatile变量后面的语句放到其前面执行。
下面举个例子:
private static int a;//非volatile修饰变量
private static int b;//非volatile修饰变量
private static volatile int k;//volatile修饰变量
private void hello() {
a = 1; //语句1
b = 2; //语句2
k = 3; //语句3
a = 4; //语句4
b = 5; //语句5
//...
}变量a,b是非volatile修饰的变量,k则使用volatile修饰。所以语句3不能放在语句1、2前,也不能放在语句4、5后。但是语句1、2的顺序是不能保证的,同理,语句4、5也不能保证顺序。
并且,执行到语句3的时候,语句1,2是肯定执行完毕的,而且语句1,2的执行结果对于语句3,4,5是可见的。
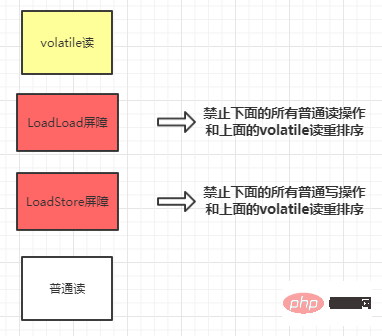
首先要讲一下内存屏障,内存屏障可以分为以下几类:
Barrière LoadLoad : pour les instructions telles que Load1, LoadLoad, Load2. Avant d'accéder aux données à lire dans Load2 et aux opérations de lecture ultérieures, il est garanti que les données à lire dans Load1 ont été lues.
Barrière StoreStore : pour de telles instructions Store1, StoreStore, Store2, avant l'exécution de Store2 et des opérations d'écriture ultérieures, il est garanti que l'opération d'écriture de Store1 est visible par les autres processeurs.
Barrière LoadStore : pour les instructions telles que Load1, LoadStore et Store2, assurez-vous que les données à lire par Load1 sont complètement lues avant Store2 et que les opérations d'écriture ultérieures sont vidées.
Barrière StoreLoad : pour les instructions telles que Store1, StoreLoad et Load2, avant l'exécution de Load2 et de toutes les opérations de lecture ultérieures, l'écriture dans Store1 est garantie d'être visible par tous les processeurs.
Insérez une barrière LoadLoad après chaque opération de lecture volatile et une barrière LoadStore après une opération de lecture.
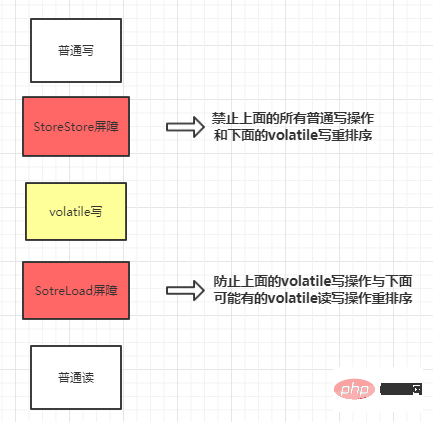
Insérez une barrière StoreStore devant chaque opération d'écriture volatile et une barrière SotreLoad à l'arrière.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
















![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



