
 développement back-end
Tutoriel Python
Comment utiliser Jieba pour les statistiques de fréquence des mots et l'extraction de mots clés en Python
développement back-end
Tutoriel Python
Comment utiliser Jieba pour les statistiques de fréquence des mots et l'extraction de mots clés en Python
Comment utiliser Jieba pour les statistiques de fréquence des mots et l'extraction de mots clés en Python

1 Statistiques de fréquence des mots
1.1 Statistiques de fréquence des mots simples
1. Importez la bibliothèque jieba et définissez le textejieba库并定义文本
import jieba text = "Python是一种高级编程语言,广泛应用于人工智能、数据分析、Web开发等领域。"
2.对文本进行分词
words = jieba.cut(text)
这一步会将文本分成若干个词语,并返回一个生成器对象words,可以使用for循环遍历所有的词语。
3. 统计词频
word_count = {}
for word in words:
if len(word) > 1:
word_count[word] = word_count.get(word, 0) + 1这一步通过遍历所有的词语,统计每个词语出现的次数,并保存到一个字典word_count中。在统计词频时,可以通过去除停用词等方式进行优化,这里只是简单地过滤了长度小于2的词语。
4. 结果输出
for word, count in word_count.items():
print(word, count)
1.2 加入停用词
为了更准确地统计词频,我们可以在词频统计中加入停用词,以去除一些常见但无实际意义的词语。具体步骤如下:
定义停用词列表
import jieba # 停用词列表 stopwords = ['是', '一种', '等']
对文本进行分词,并过滤停用词
text = "Python是一种高级编程语言,广泛应用于人工智能、数据分析、Web开发等领域。" words = jieba.cut(text) words_filtered = [word for word in words if word not in stopwords and len(word) > 1]
统计词频并输出结果
word_count = {}
for word in words_filtered:
word_count[word] = word_count.get(word, 0) + 1
for word, count in word_count.items():
print(word, count)加入停用词后,输出的结果是:

可以看到,被停用的一种这个词并没有显示出来。
2 关键词提取
2.1 关键词提取原理
与对词语进行单纯计数的词频统计不同,jieba提取关键字的原理是基于TF-IDF(Term Frequency-Inverse Document Frequency)算法。TF-IDF算法是一种常用的文本特征提取方法,可以衡量一个词语在文本中的重要程度。
具体来说,TF-IDF算法包含两个部分:
Term Frequency(词频):指一个词在文本中出现的次数,通常用一个简单的统计值表示,例如词频、二元词频等。词频反映了一个词在文本中的重要程度,但是忽略了这个词在整个语料库中的普遍程度。
Inverse Document Frequency(逆文档频率):指一个词在所有文档中出现的频率的倒数,用于衡量一个词的普遍程度。逆文档频率越大,表示一个词越普遍,重要程度越低;逆文档频率越小,表示一个词越独特,重要程度越高。
TF-IDF算法通过综合考虑词频和逆文档频率,计算出每个词在文本中的重要程度,从而提取关键字。在jieba中,关键字提取的具体实现包括以下步骤:
对文本进行分词,得到分词结果。
统计每个词在文本中出现的次数,计算出词频。
统计每个词在所有文档中出现的次数,计算出逆文档频率。
综合考虑词频和逆文档频率,计算出每个词在文本中的TF-IDF值。
对TF-IDF值进行排序,选取得分最高的若干个词作为关键字。
举个例子:
F(Term Frequency)指的是某个单词在一篇文档中出现的频率。计算公式如下:
T F = ( 单词在文档中出现的次数 ) / ( 文档中的总单词数 )
例如,在一篇包含100个单词的文档中,某个单词出现了10次,则该单词的TF为
10 / 100 = 0.1
IDF(Inverse Document Frequency)指的是在文档集合中出现某个单词的文档数的倒数。计算公式如下:
I D F = l o g ( 文档集合中的文档总数 / 包含该单词的文档数 )
例如,在一个包含1000篇文档的文档集合中,某个单词在100篇文档中出现过,则该单词的IDF为 l o g ( 1000 / 100 ) = 1.0
TFIDF是将TF和IDF相乘得到的结果,计算公式如下:
T F I D F = T F ∗ I D F
需要注意的是,TF-IDF算法只考虑了词语在文本中的出现情况,而忽略了词语之间的关联性。因此,在一些特定的应用场景中,需要使用其他的文本特征提取方法,例如词向量、主题模型等。
2.2 关键词提取代码
import jieba.analyse
# 待提取关键字的文本
text = "Python是一种高级编程语言,广泛应用于人工智能、数据分析、Web开发等领域。"
# 使用jieba提取关键字
keywords = jieba.analyse.extract_tags(text, topK=5, withWeight=True)
# 输出关键字和对应的权重
for keyword, weight in keywords:
print(keyword, weight)在这个示例中,我们首先导入了jieba.analyse模块,然后定义了一个待提取关键字的文本text。接着,我们使用jieba.analyse.extract_tags()函数提取关键字,其中topK参数表示需要提取的关键字个数,withWeightrrreee
2 Segmentez le texte
Cette étape divisera le texte en plusieurs. mots, et renvoie un objet générateur mots, qui peut être utilisé pour parcourir tous les mots en utilisant for. 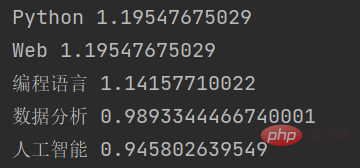
word_count. Lors du comptage des fréquences de mots, l'optimisation peut être effectuée en supprimant les mots vides. Ici, les mots d'une longueur inférieure à 2 sont simplement filtrés. 🎜🎜4. Sortie du résultat🎜rrreee🎜🎜🎜1.2 Ajouter des mots vides🎜🎜Afin de compter la fréquence des mots avec plus de précision, nous pouvons ajouter des mots vides aux statistiques de fréquence des mots pour supprimer certains mots courants mais dénués de sens. Les étapes spécifiques sont les suivantes : 🎜🎜 Définir la liste des mots vides 🎜rrreee🎜 Segmenter le texte et filtrer les mots vides 🎜rrreee🎜 Compter la fréquence des mots et afficher les résultats 🎜rrreee🎜 Après avoir ajouté les mots vides, le résultat de sortie est : 🎜🎜 🎜🎜Vous pouvez le constater, le mot désactivé a n'est pas affiché. 🎜🎜2 Extraction de mots-clés🎜🎜2.1 Principe d'extraction de mots-clés🎜🎜 Différent des statistiques de fréquence des mots qui comptent simplement les mots, le principe d'extraction de mots-clés de Jieba est basé sur l'algorithme TF-IDF (Term Frequency-Inverse Document Frequency). L'algorithme TF-IDF est une méthode d'extraction de caractéristiques de texte couramment utilisée qui peut mesurer l'importance d'un mot dans le texte. 🎜🎜Plus précisément, l'algorithme TF-IDF contient deux parties : 🎜- 🎜Fréquence du terme : fait référence au nombre de fois qu'un mot apparaît dans le texte, généralement utilisé. Un simple représentation de valeurs statistiques, telles que la fréquence des mots, la fréquence des mots bigrammes, etc. La fréquence des mots reflète l’importance d’un mot dans le texte, mais ignore la prévalence du mot dans l’ensemble du corpus. 🎜
- 🎜Inverse Document Frequency (fréquence inverse des documents) : désigne l'inverse de la fréquence d'un mot apparaissant dans tous les documents, utilisée pour mesurer la prévalence d'un mot. Plus la fréquence inverse du document est élevée, plus un mot est courant et plus son importance est faible ; plus la fréquence inverse du document est faible, plus le mot est unique et plus son importance est élevée. 🎜
- 🎜 Effectuer une segmentation de mots sur le texte et obtenir les résultats de la segmentation de mots. 🎜
- 🎜Comptez le nombre de fois où chaque mot apparaît dans le texte et calculez la fréquence des mots. 🎜
- 🎜Comptez le nombre de fois que chaque mot apparaît dans tous les documents et calculez la fréquence inverse des documents. 🎜
- 🎜Considération complète de la fréquence des mots et de la fréquence inverse des documents, calculez la valeur TF-IDF de chaque mot dans le texte. 🎜
- 🎜 Triez les valeurs TF-IDF et sélectionnez les mots avec les scores les plus élevés comme mots-clés. 🎜
🎜Par exemple : 🎜F (Term Frequency) fait référence à la fréquence à laquelle un mot apparaît dans un document. La formule de calcul est la suivante : 🎜T F = (le nombre de fois qu'un mot apparaît dans le document) / (le nombre total de mots dans le document) 🎜Par exemple, dans un document contenant 100 mots, si un certain mot apparaît 10 fois, alors le mot Le TF est 🎜10 / 100 = 0,1 🎜IDF (Inverse Document Frequency) fait référence à l'inverse du nombre de documents dans lesquels un certain mot apparaît dans la collection de documents. La formule de calcul est la suivante : 🎜I D F = log (nombre total de documents dans la collection de documents / nombre de documents contenant le mot) 🎜Par exemple, dans une collection de documents contenant 1 000 documents, un certain mot apparaît dans 100 documents, puis le L'IDF d'un mot est l o g (1000 / 100) = 1,0🎜TFIDF est le résultat de la multiplication de TF et IDF La formule de calcul est la suivante :🎜T F I D F = T F ∗ TF-IDF L'algorithme considère uniquement l'occurrence des mots dans le texte et ignore la corrélation entre les mots. Par conséquent, dans certains scénarios d'application spécifiques, d'autres méthodes d'extraction de caractéristiques de texte doivent être utilisées, telles que des vecteurs de mots, des modèles de sujets, etc. 🎜🎜2.2 Code d'extraction de mots clés🎜rrreee🎜Dans cet exemple, nous avons d'abord importé le modulejieba.analyse, puis défini un textetextpour les mots-clés à extraire. Ensuite, nous utilisons la fonctionjieba.analyse.extract_tags()pour extraire des mots-clés, où le paramètretopKindique le nombre de mots-clés à extraire,withWeight code> Le paramètre indique s'il faut renvoyer la valeur de poids du mot-clé. Enfin, nous parcourons la liste de mots-clés et affichons chaque mot-clé et la valeur de poids correspondante. 🎜Le résultat de sortie de cette fonction est : 🎜🎜🎜🎜<p>Comme vous pouvez le voir, jieba a extrait plusieurs mots-clés dans le texte d'entrée sur la base de l'algorithme TF-IDF et a renvoyé la valeur de poids de chaque mot-clé. </p>
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Undress AI Tool
Images de déshabillage gratuites

Clothoff.io
Dissolvant de vêtements AI

AI Hentai Generator
Générez AI Hentai gratuitement.

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)



 PHP et Python: exemples de code et comparaison
Apr 15, 2025 am 12:07 AM
PHP et Python: exemples de code et comparaison
Apr 15, 2025 am 12:07 AM
PHP et Python ont leurs propres avantages et inconvénients, et le choix dépend des besoins du projet et des préférences personnelles. 1.Php convient au développement rapide et à la maintenance des applications Web à grande échelle. 2. Python domine le domaine de la science des données et de l'apprentissage automatique.
 Python vs JavaScript: communauté, bibliothèques et ressources
Apr 15, 2025 am 12:16 AM
Python vs JavaScript: communauté, bibliothèques et ressources
Apr 15, 2025 am 12:16 AM
Python et JavaScript ont leurs propres avantages et inconvénients en termes de communauté, de bibliothèques et de ressources. 1) La communauté Python est amicale et adaptée aux débutants, mais les ressources de développement frontal ne sont pas aussi riches que JavaScript. 2) Python est puissant dans les bibliothèques de science des données et d'apprentissage automatique, tandis que JavaScript est meilleur dans les bibliothèques et les cadres de développement frontaux. 3) Les deux ont des ressources d'apprentissage riches, mais Python convient pour commencer par des documents officiels, tandis que JavaScript est meilleur avec MDNWEBDOCS. Le choix doit être basé sur les besoins du projet et les intérêts personnels.
 Explication détaillée du principe docker
Apr 14, 2025 pm 11:57 PM
Explication détaillée du principe docker
Apr 14, 2025 pm 11:57 PM
Docker utilise les fonctionnalités du noyau Linux pour fournir un environnement de fonctionnement d'application efficace et isolé. Son principe de travail est le suivant: 1. Le miroir est utilisé comme modèle en lecture seule, qui contient tout ce dont vous avez besoin pour exécuter l'application; 2. Le Système de fichiers Union (UnionFS) empile plusieurs systèmes de fichiers, ne stockant que les différences, l'économie d'espace et l'accélération; 3. Le démon gère les miroirs et les conteneurs, et le client les utilise pour l'interaction; 4. Les espaces de noms et les CGROUP implémentent l'isolement des conteneurs et les limitations de ressources; 5. Modes de réseau multiples prennent en charge l'interconnexion du conteneur. Ce n'est qu'en comprenant ces concepts principaux que vous pouvez mieux utiliser Docker.
 Comment exécuter des programmes dans Terminal Vscode
Apr 15, 2025 pm 06:42 PM
Comment exécuter des programmes dans Terminal Vscode
Apr 15, 2025 pm 06:42 PM
Dans VS Code, vous pouvez exécuter le programme dans le terminal via les étapes suivantes: Préparez le code et ouvrez le terminal intégré pour vous assurer que le répertoire de code est cohérent avec le répertoire de travail du terminal. Sélectionnez la commande Run en fonction du langage de programmation (tel que Python de Python your_file_name.py) pour vérifier s'il s'exécute avec succès et résoudre les erreurs. Utilisez le débogueur pour améliorer l'efficacité du débogage.
 Le code Visual Studio peut-il être utilisé dans Python
Apr 15, 2025 pm 08:18 PM
Le code Visual Studio peut-il être utilisé dans Python
Apr 15, 2025 pm 08:18 PM
VS Code peut être utilisé pour écrire Python et fournit de nombreuses fonctionnalités qui en font un outil idéal pour développer des applications Python. Il permet aux utilisateurs de: installer des extensions Python pour obtenir des fonctions telles que la réalisation du code, la mise en évidence de la syntaxe et le débogage. Utilisez le débogueur pour suivre le code étape par étape, trouver et corriger les erreurs. Intégrez Git pour le contrôle de version. Utilisez des outils de mise en forme de code pour maintenir la cohérence du code. Utilisez l'outil de liaison pour repérer les problèmes potentiels à l'avance.
 Python: automatisation, script et gestion des tâches
Apr 16, 2025 am 12:14 AM
Python: automatisation, script et gestion des tâches
Apr 16, 2025 am 12:14 AM
Python excelle dans l'automatisation, les scripts et la gestion des tâches. 1) Automatisation: La sauvegarde du fichier est réalisée via des bibliothèques standard telles que le système d'exploitation et la fermeture. 2) Écriture de script: utilisez la bibliothèque PSUTIL pour surveiller les ressources système. 3) Gestion des tâches: utilisez la bibliothèque de planification pour planifier les tâches. La facilité d'utilisation de Python et la prise en charge de la bibliothèque riche en font l'outil préféré dans ces domaines.
 Peut-on exécuter le code sous Windows 8
Apr 15, 2025 pm 07:24 PM
Peut-on exécuter le code sous Windows 8
Apr 15, 2025 pm 07:24 PM
VS Code peut fonctionner sur Windows 8, mais l'expérience peut ne pas être excellente. Assurez-vous d'abord que le système a été mis à jour sur le dernier correctif, puis téléchargez le package d'installation VS Code qui correspond à l'architecture du système et l'installez comme invité. Après l'installation, sachez que certaines extensions peuvent être incompatibles avec Windows 8 et doivent rechercher des extensions alternatives ou utiliser de nouveaux systèmes Windows dans une machine virtuelle. Installez les extensions nécessaires pour vérifier si elles fonctionnent correctement. Bien que le code VS soit possible sur Windows 8, il est recommandé de passer à un système Windows plus récent pour une meilleure expérience de développement et une meilleure sécurité.
 L'extension VScode est-elle malveillante?
Apr 15, 2025 pm 07:57 PM
L'extension VScode est-elle malveillante?
Apr 15, 2025 pm 07:57 PM
Les extensions de code vs posent des risques malveillants, tels que la cachette de code malveillant, l'exploitation des vulnérabilités et la masturbation comme des extensions légitimes. Les méthodes pour identifier les extensions malveillantes comprennent: la vérification des éditeurs, la lecture des commentaires, la vérification du code et l'installation avec prudence. Les mesures de sécurité comprennent également: la sensibilisation à la sécurité, les bonnes habitudes, les mises à jour régulières et les logiciels antivirus.
